- MapReduce
-
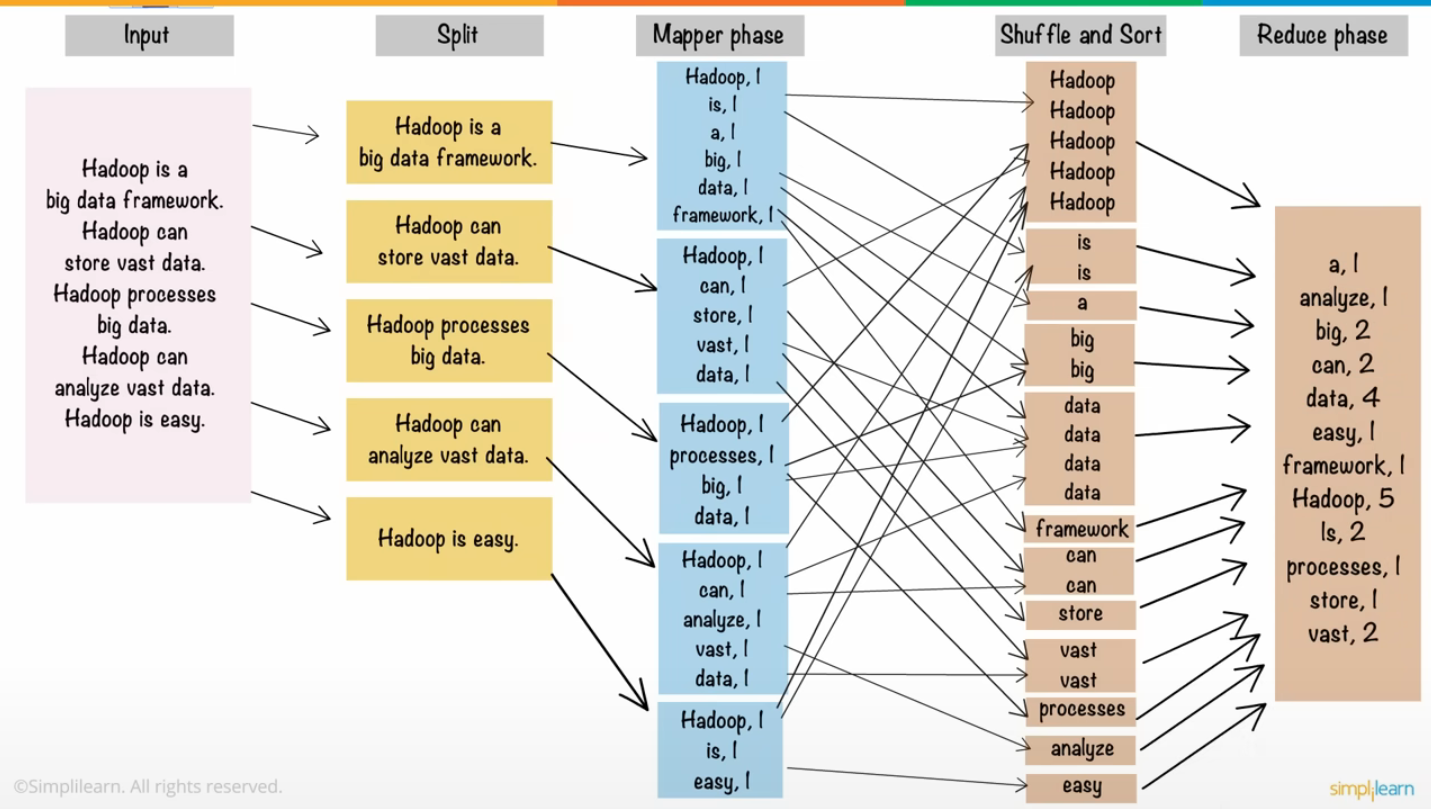
Input : 말 그대로 입력 파일이다. 이 입력 파일은 block 단위로 HDFS에 적재되어있다.
※ 보통은 text를 많이 처리하지만, 경우에 따라서는 이미지, 통계 자료 등 여러가지가 MapReduce의 입력 데이터가 될 수 있다. -
InputSplit : 크기가 큰 input file을 작은 단위의 chunk들로 나누는 과정이다. 병렬 처리를 위해 여러 node에서 (순차적으로) block을 입력으로 받는데, block 안의 text file을 정의된 input format 단위로 분할한다. 하나의 inputsplit은 map task에 의해 load 되는 하나의 덩어리이다. split 수 만큼 Map task들이 worker로부터 fork된다.
※ 보통 split 단위는 block size인 64/128mb -
Map : 입력 데이터를 원하는 Key-Value 형태로 만드는 작업이다. Map의 결과는 HDFS가 아닌 Local Disk에 저장된다.
- ex) 키, 값(vocabulary, 1)의 데이터를 반환한다.
-
Partitioning : 각 Mapper에서 나온 출력 레코드들이 어느 Reducer로 가야할지를 정하는 작업으로, Key를 기준으로 같은 데이터들끼리 모아 정렬한다. Key를 해시코드로 바꾼 뒤, 리듀서의 갯수로 그 해시코드를 나눠서 나온 나머지로 리듀서를(파티셔닝!) 정한다.
-
Shuffling : Partitioning 결과에 맞도록 데이터를 shuffle한다.
-
Sorting : Reduce 작업을 하기 전에 정렬을 수행한다. Reducer에 도착한 record들을 key 값을 기준으로 정렬한다. 그 이유는 매우 간단한데, Reduce 작업을 용이하게 하기 위해서이다.
-
Reduce : (단어, 개수)를 count 하여 각 block에서 특정 단어가 몇 번 나왔는지를 계산한다. 그렇게 분산되어 처리된 결과 값들을 다시 하나로 합쳐주는 과정이다.
-
Write : HDFS에 파일로 결과를 저장한다. Reducer가 모든 작업을 끝내면 각 Reducer들은 처리한 record들을 파일로 출력한다. 각 Reducer마다 part-r-...... 의 포맷으로 결과를 출력한다. 예를들어 Reducer의 갯수가 3개라면 총 3개의 출력파일 : part-r-00001~03이 있을것이다.
※ 맵과 리듀스 사이에 Combiner 함수를 사용할 수 있다. 예를 들어 연도별 최고 기온을 찾는 데이터 처리를 할때, 각 map의 결과는 1992년 기온을 가지고 있을 것이다. ex) map1 : (1992, [10, 5, 2]), map2 : (1992, [40,20,4])
이 때 이 결과를 Reduce 함수로 바로 보내지 않고 각 map 결과에서 최고 기온만 뽑아서 Reduce로 보낸다면 제한된 네트워크 대역폭에 대해 데이터 전송을 최소화 할 수 있다. ex) combine1 : (1992, [10]), combine2 : (1992, [40])
Combiner는 Reduce 결과에 영향을 미치지 않는 선에서만 사용될 수 있다. 최소/최대값에는 활용될 수 있지만, 데이터 수가 중요한(분모이기때문에) 평균과 같은 데이터처리에는 사용될 수 없다.
