Spark
1.[HADOOP] MAP REDUCE
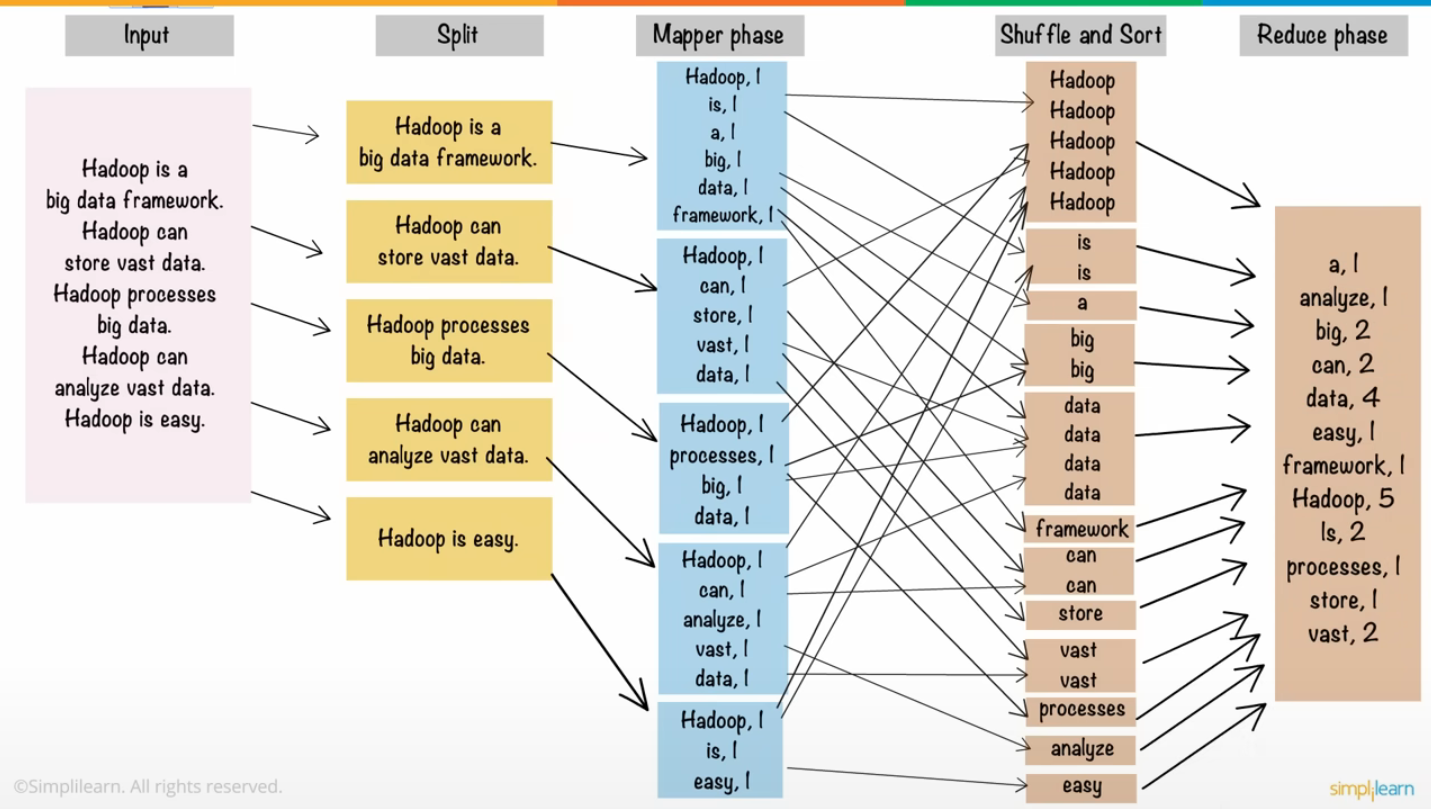
MapReduceInput : 단어의 개수를 세기 위한 텍스트 파일들을 HDFS에 업로드하고, 각각의 파일은 블록단위로 나누어 저장된다.Split : 순차적으로 블록을 입력으로 받는데, Spitting 과정을 통해 블록 안의 텍스트 파일을 한 줄 단위로 분할한다. 크기
2.[HADOOP] YARN 기초
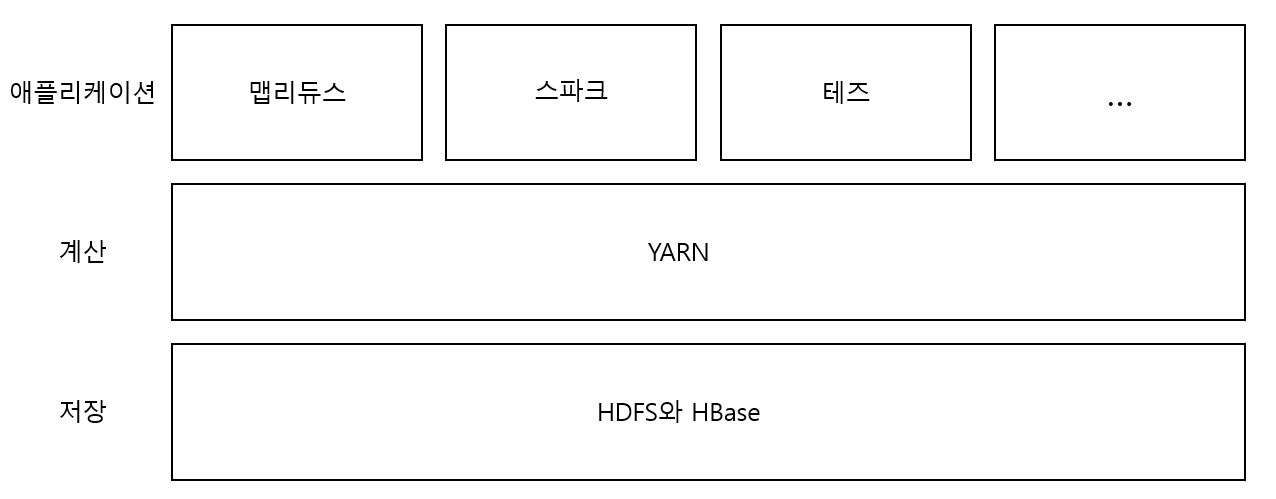
아파치 YARN은 하둡의 클러스터 자원 관리 시스템이다. 맵리듀스 뿐만 아니라, 다른 분산 컴퓨팅 도구도 지원한다.클러스터의 자원을 요청하고 사용하기 위한 API를 제공한다.사용자 코드에서 이 API를 사용할 수는 없고, YARN이 내장된 분산 컴퓨팅 프레임워크에서 고
3.[HADOOP] YARN 스케줄러
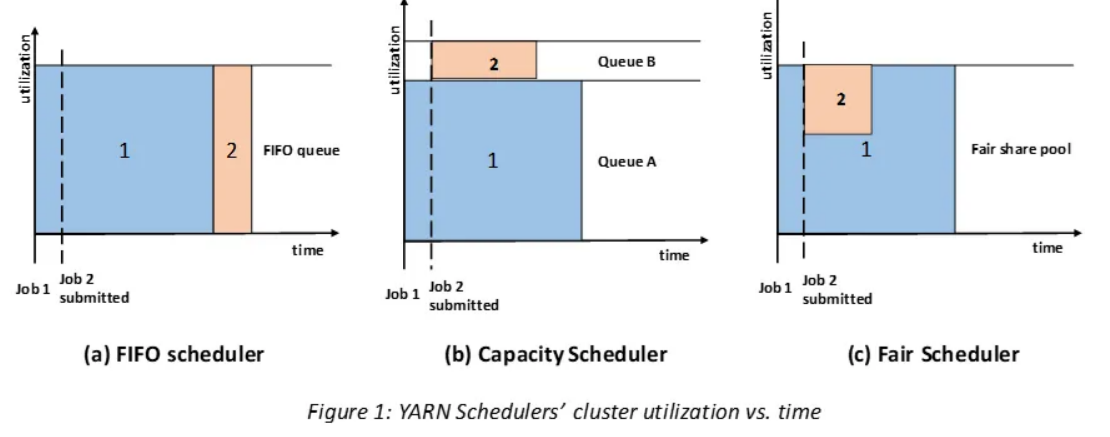
FIFO Scheduler애플리케이션을 큐에 하나씩 넣고 제출된 순서에 따라 순차적으로 실행한다.단순하지만 공유 클러스터 환경에서는 부적합하다.Capacity Scheduler자원을 나누어 큐로 나누고, Job이 제출되면 지정된 큐의 자원을 활용해서 실행한다.활용되고
4.[HADOOP] SPARK

개요Apache Spark는 대용량 데이터 처리를 위한 클러스터 컴퓨팅 프레임워크이자 실행 엔진으로 MapReduce를 사용하지 않는다. 대신 클러스터를 기반으로 작업을 실행하는 자체 분산 런타임 엔진이 있다. (MapReduce와 비슷하긴하다)스파크는 Job 사이의
5.[HADOOP] SPARK RDD
RDD(Resilient Distributed Dataset)클러스터 내 다수의 머신에 분할되어 저장된 읽기 전용 컬렉션스파크 프로그램은 하나 이상의 RDD를 입력받고 일련의 변환 작업을 거쳐 목표 RDD 집합으로 변환된다. 이 과정에서 결과를 계산하거나 그 결과를 영
6.[HADOOP] Job, Stage, Task
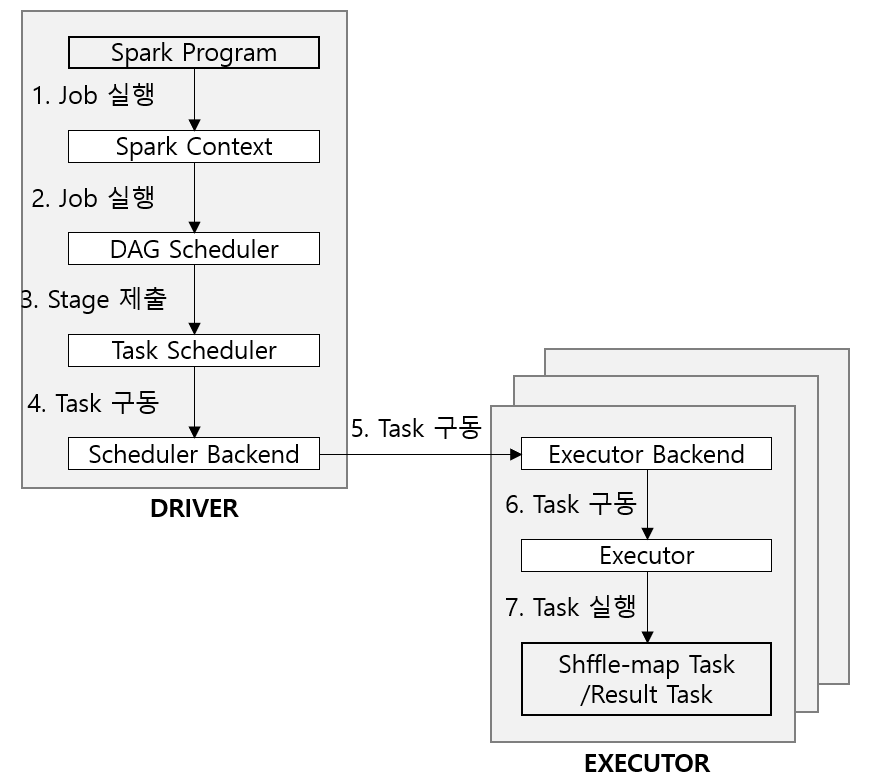
Spark Application, Job, Stage, Task하나의 애플리케이션은 하나 이상의 Job을 수행할 수 있으며, 동일한 애플리케이션에서 수행된 이전 잡에서 캐싱된 RDD에 접근할 수 있는 매커니즘도 있다. Job은 항상 RDD 및 공유변수를 제공하는 애플리
7.[HADOOP] SPARK DAG Scheduler
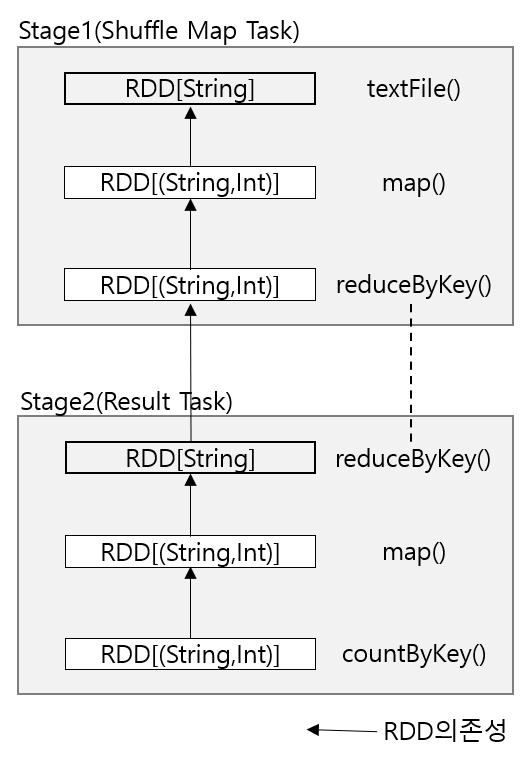
DAG 구성 Job이 Stage로 구분되는 방법을 이해하려면 먼저 Stage에서 실행되는 Task의 종류를 알아야한다.두 종류의 Task가 있다 ; Shuffle Map Task와 Result Task이다. Shuffle Map Task : 맵리듀스 셔플의 맵 부분과
8.APACHE LIVY
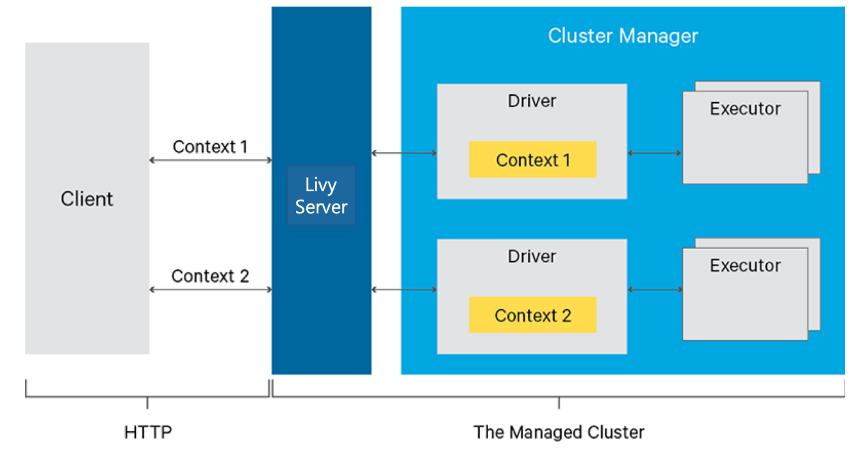
REST API를 이용해서 스파크 작업을 요청하는 서비스여러 개의 Spark Context를 관리할 수 있음.
9.[Spark] Architecture
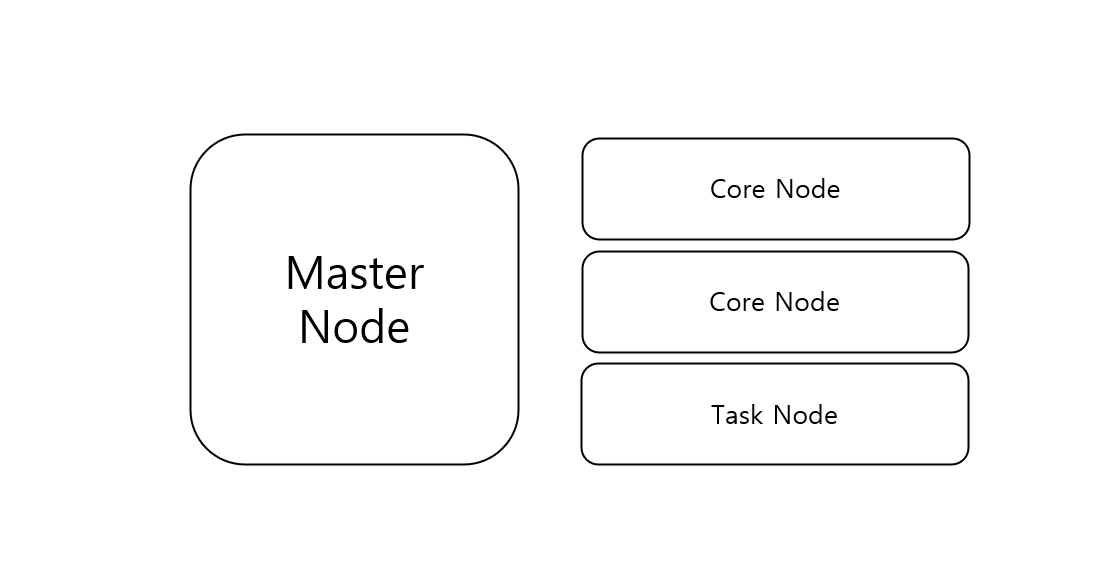
EMR 스파크 물리 구성EMR에서는 Master, Core, Task node를 각각 스펙과 함께 선택할 수 있다. Core와 Task는 둘 다 Worker node로, HDFS가 있고 없음의 차이이다.스파크 논리 구성주요 구성은 Driver, Executor, Clu
10.[Spark] Application Lifecycle
Spark Application Life Cycle스파크 어플리케이션 잡 제출 드라이버 프로세스를 생성하는 것이 목적입니다.스파크 어플리케이션은 컴파일된 JAR나 라이브러리 파일이다.제플린/주피터에서 코드를 실행하여 클러스터 매니저에 제출을 요청한다.이 과정에서 스파크
11.[Spark] EMR Configuration
1\. spark > maximizeResourceAllocation executor가 클러스터의 각 노드에서 최대의 리소스를 활용하도록 합니다.이 설정을 하면 executor의 최대의 컴퓨팅, 메모리 리소스를 계산합니다.이에 대응되는 spark-default 세팅을
12.[Spark] jdbc parallelism
EMR Zeppelin에서 Spark를 실행해서 jdbc를 통해 데이터베이스(Redshift) 데이터를 병렬로 가지고 오는 방법Spark에서 제공하는 partitionColumn, lowerBound, upperBound, numPartitions 파라미터를 사용해서
13.[Spark] PushdownQuery
pushdownQuery client(spark 어플리케이션)에서 쿼리를 날리지만, 해당 쿼리를 원천 소스(database)에서 쿼리가 수행되도록 위임하는 것이다. 이렇게 하면 client에서는 필요한 데이터만 읽어올 수 있다. 다만, database에 부하가 생길 수
14.[Spark] Data Partitioning
Partitioning s3에 데이터를 저장할 때 where 조건절에 자주 쓰이면서 유니크한 수가 많지 않은 칼럼을 기준으로 파티셔닝을 해서 저장할 수 있다. UNLOAD : saveAsTable : spark write : 이렇게 저장하면 S3경로를
15.[Spark] Join Strategies
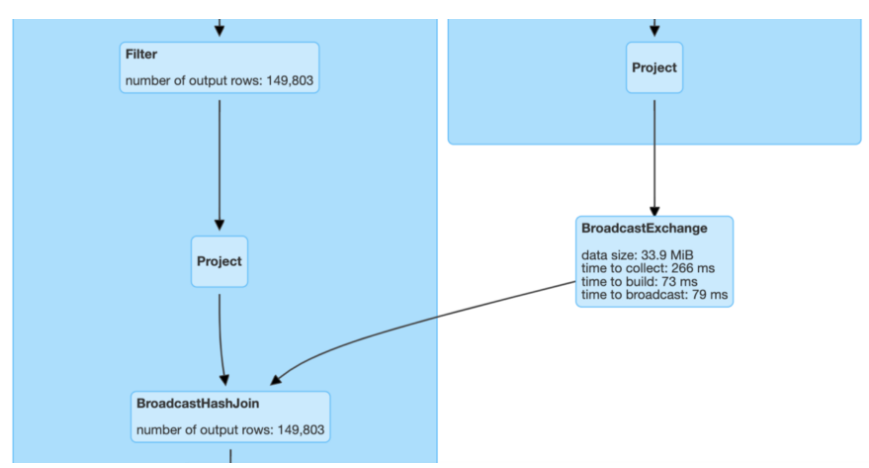
1\. Broadcast Join 모든 executor의 메모리에 복사하여 shuffle 없이 join하는 방식모든 executor와 driver의 memory에 충분한 공간이 있어야함.일반적으로 사이즈가 작은 master성 테이블(dimemsion 테이블)에 적용하나
16.Spark Monitoring
수없이 다양한 원인과 에러가 발생합니다. 주요 이슈와 해결 방법을 확인합니다.● 모니터링 대상어플리케이션의 프로세스 (CPU, 메모리 사용률 등)프로세스 내부의 쿼리 실행 과정 (Job과 Task)● 디버깅 및 응급처치느리거나 뒤처진 태스크 : 머신 간에 작업이 균등하
17.[Spark] Tuning examples
select case when 안에 기간을 쓰는 경우 모든 레코드에 대해 case when 조건을 체크하기 때문에 비효율적입니다.where 조건절을 활용해 두개의 쿼리로 나누고 합치는 것이 좋습니다.
18.[Spark] Others
Resource Manager YARN dprovides Uptime and PortUptime : how long is has been running.port : 8088 for incoming client requests and communication with N
19.[Spark] Transformation and Action
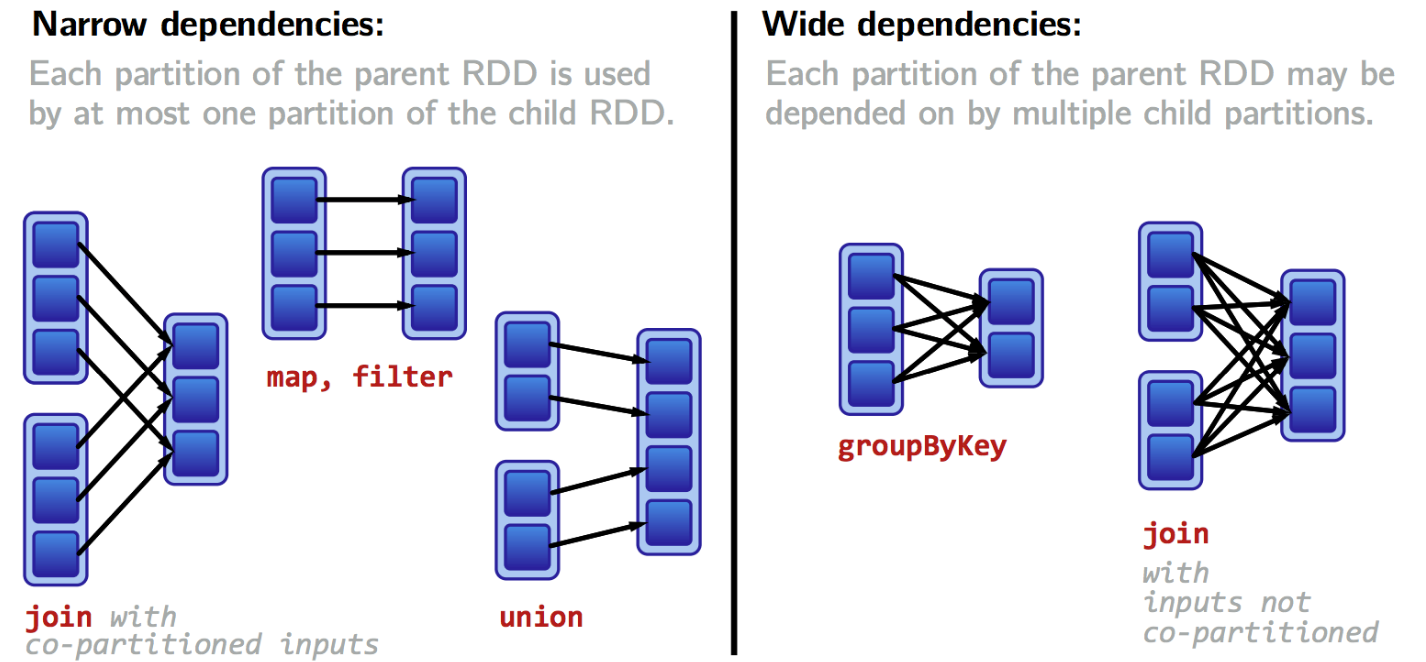
Transformation1.1 좁은 의존성각 입력 파티션이 하나의 출력파티션에만 영향을 미친다.파이프라이닝을 통해 모든 작업이 메모리에서 일어난다.where(), filter(), map()1.2 넓은 의존성하나의 입력 파티션이 여러 출력 파티션에 영향을 미친다.셔플
20.[Spark] Other tips
sortWithinPartitions("COL")transformation을 처리하기 전에 성능을 최적화하기 위해 partition별 정렬을 수행하기도 한다.repartition and coalescerepartition은 무조건 전체 데이터를 셔플한다. 파티션 수를
21.[Glue] No space left on device
SituationApache Spark uses local disk on AWS Glue workers to spill data from memory that exceeds the heap space defined by the spark.executor.memory c