[Data-centric AI development]

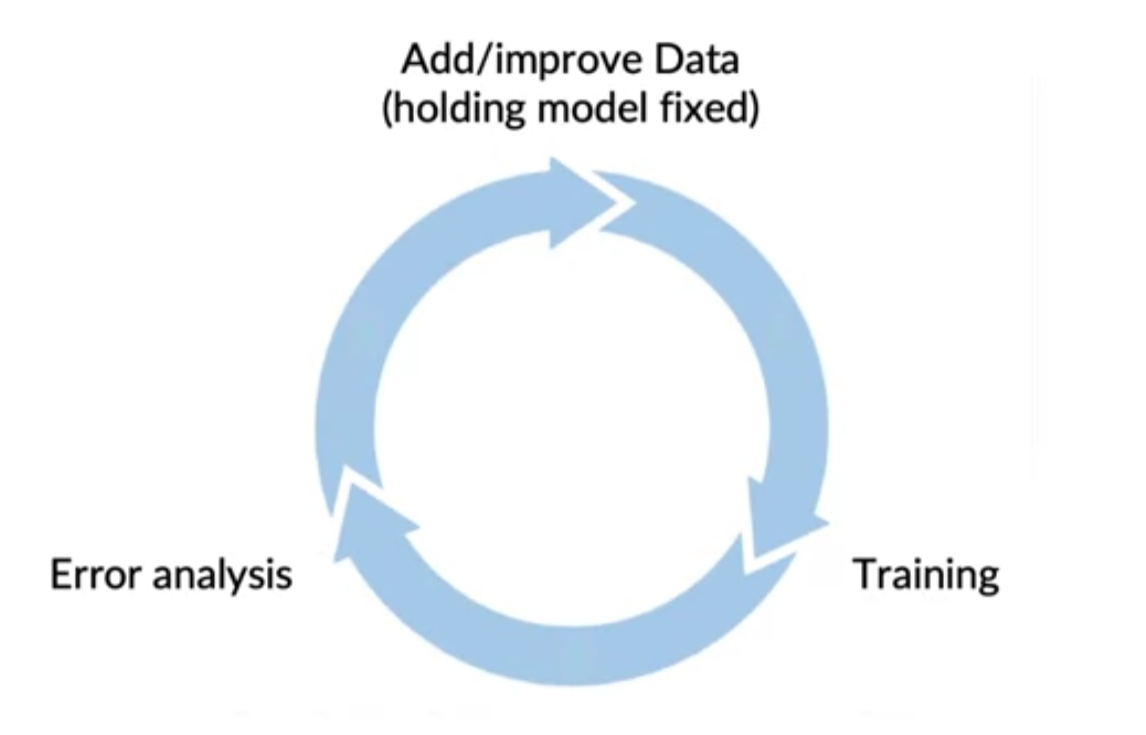
[A useful picture of data augmentation]
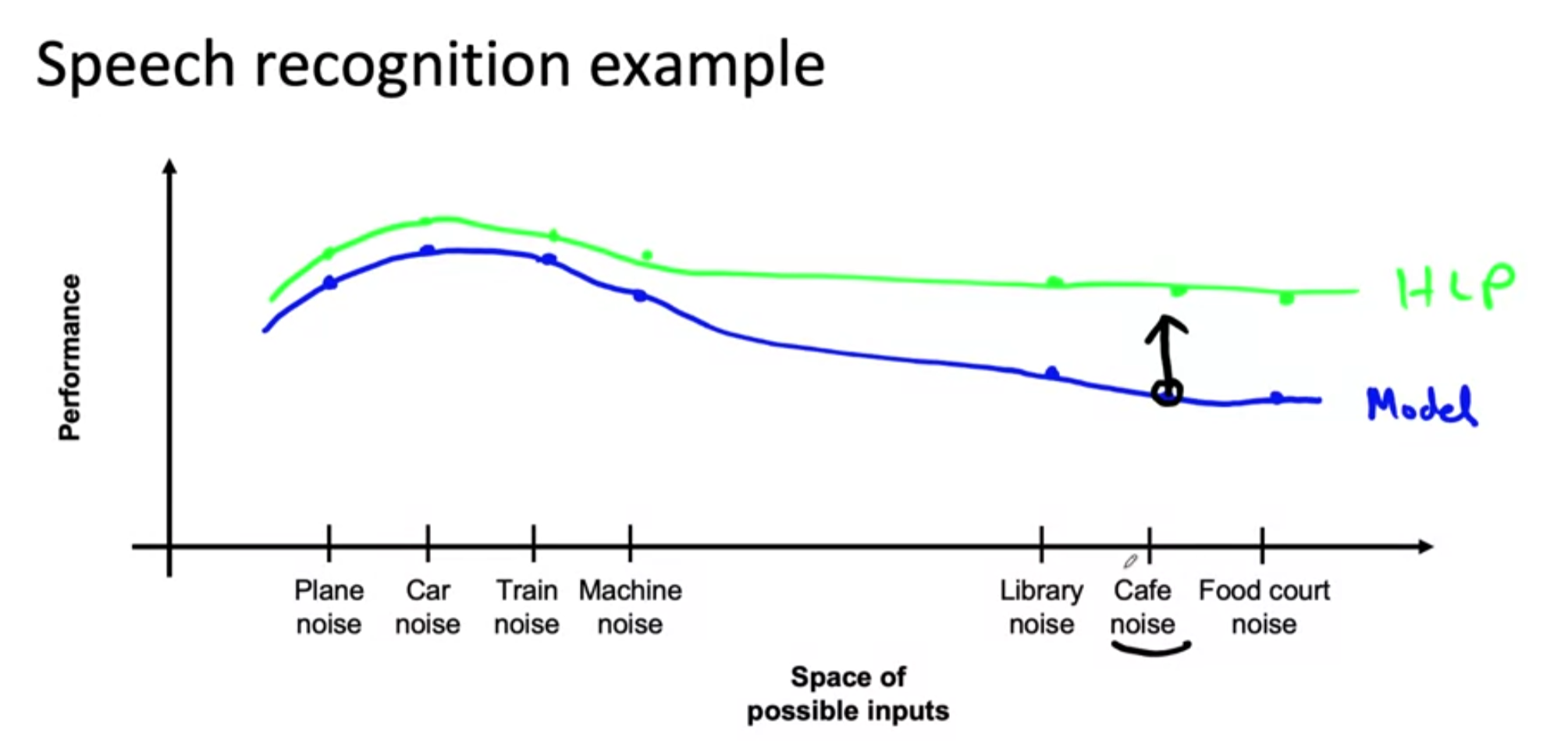
- Getting more data with Cafe noise and improve the model can result in improvement on other categories too.
- So work on 1 category at a time and evaluate the performance.
[Data augmentation]
-
Goal: Create realistic examples that (i) the algorithm does poorly on, but (ii) humans (or other baseline) do well on.
-
Checklist
- Is it realistic?
- Is the x > y mapping clear?
- Is the algorithm currently doing poorly on it?
[Can adding data hurt?]
- For unstructured data problems, if
- The model is large (low bias)
- The mapping x > y is clear (e.g., given only the input x, humans can make accurate predictions).
- Then, adding data rarely hurts accuracy.
[Adding features]
- For structured data problems
- Restaurant recoomendation example
- problem: Vegetarians are frequently recommended restaurants with only meat options.
-
Check for possible features to add
- Is person vegetarian (based on past orders)?
- Does restaurant have vegetarian options (based on menu)?
-
Product recommendation
- Collaborative Filtering (old)
- Content based filtering (trend)
★ There's been a trend in product recommendations of a shift from collaborative filtering approaches to what content based filtering approaches. Collaborative filtering approaches is loosely an approach that looks at the user, tries to figure out who is similar to that user and then recommends things to you that people like you also liked. In contrast, a content based filtering approach will tend to look at you as a person and look at the description of the restaurant or look at the menu of the restaurants and look at other information about the restaurant, to see if that restaurant is a good match for you or not. The advantage of content based filtering is that even if there's a new restaurant or a new product that hardly anyone else has liked by actually looking at the description of the restaurant, rather than just looking at who else like the restaurants, you can more quickly make good recommendations. This is sometimes also called the Cold Start Problem. How do you recommend a brand new product that almost no one else has purchased or like or dislike so far? And one of the ways to do that is to make sure that you capture good features for the things that you might want to recommend. Unlike collaborative filtering, which requires a bunch of people to look at the product and decide if they like it or not, before it can decide whether a new user should be recommended the same product.

[Experiment tracking]
- What to track?
- Algorithm/code versioning
- Dataset used
- Hyperparameters
- Results
- Tracking tools
- Text files
- Spreadsheet
- Experiment tracking system (sagemaker studio...)
- Desirable features
- Information needed to replicate results
- Experiment results, ideally with summary metrics/analysis
- Perhaps also: Resource monitoring, visualization, model error analysis
[From Big Data to Good Data]
-
Try to ensure consistently high-quality data in all phases of the ML project lifecycle.
-
Good data
- Covers important cases(good coverage of inputs x)
- Is defined consistently (definition of labels y is unambiguous)
- Has timely feedback from production data (distribution covers data drift and concept drift)
- Is sized appropriately
