[Obtaining data]
- Question: How much data can we obtain in k days?
- Unless you know how many examples you need.
- Brainstorm list of data sources.
- Labeling data: In-house / outsourced / crowedsourced
[Data pipelines]
-
Raw data → Pre-processing → ML train → test set performance → Post-processing → Product
-
POC(proof-of-concept)
- Goal is to decide if the application is workable and worth deploying.
- It's ok if data pre-processing is manual. But take extensive notes/comments.
-
Production phase
- After project utility is established, use more sophisticated tools to make sure the data pipeline is replicable. (e.g., Tensorflow Transform, Apache Bean, Airflow, ...)
[Meta-data, data provenance and lineage]
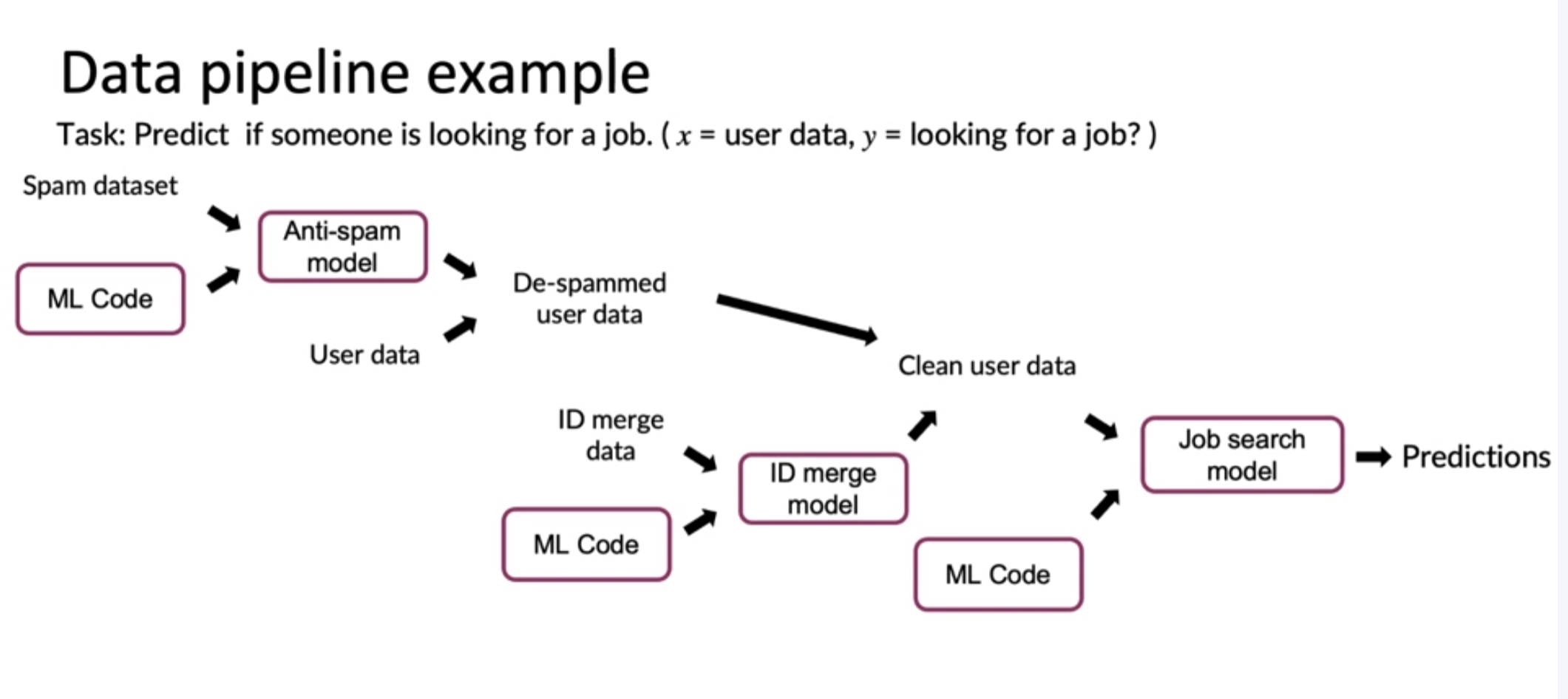
-
Keep track of data provenance and lineage (Hard!)
- provenance: where it comes from
- lineage: sequence of steps
-
Make extensive use of Meta-data
-
for error analysis. Spotting unexpected effects.
-
for keeping track of data provenance.
- Manufacturing visual inspection: Time, factory, line #, camera settings, inspector ID, ...
- Speech recognition: Device type, labeler ID, VAD model ID, ...
-
[Balanced train/dev/test splits]
- If data is too small, random split might result in skewed target distribution in one of the splits. So make sure the target proportion is the same over the splits.
- If data is large, random split is fine, but still need to check the proportions.

yozzum