- AI system = Code(algorithem/model) + Data
- Model-centric AI deployment
- Data-centric AI deployment
[Key Challenges - why low average error isn't good enough]
- The performance of models should be based on the business objectives and aspects.
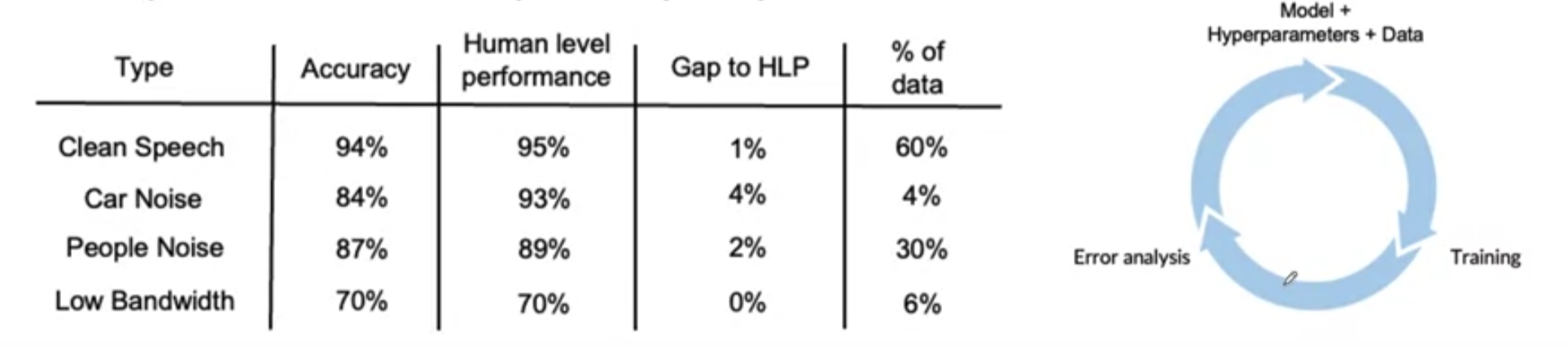
- Rare class issues (skewed data distributions) need to be evaluated with the right metrics
[Establish a baseline]
- Human level performance(HLP)
- Literature search for for sota/open source
- Quick and dirty implementation
- Performance of older system
[Tips getting started on modeling]
- Literature search to see what's possible (courses, blogs, open-source projects).
- Find open-source implementations if available.
- A reasonable algorithm with good data will often outperform a great algorithm with no so good data.
★ Sanity check for code and algorithm
- Try to overfit a small training dataset betform training on a large one.
[Error analysis example]
-
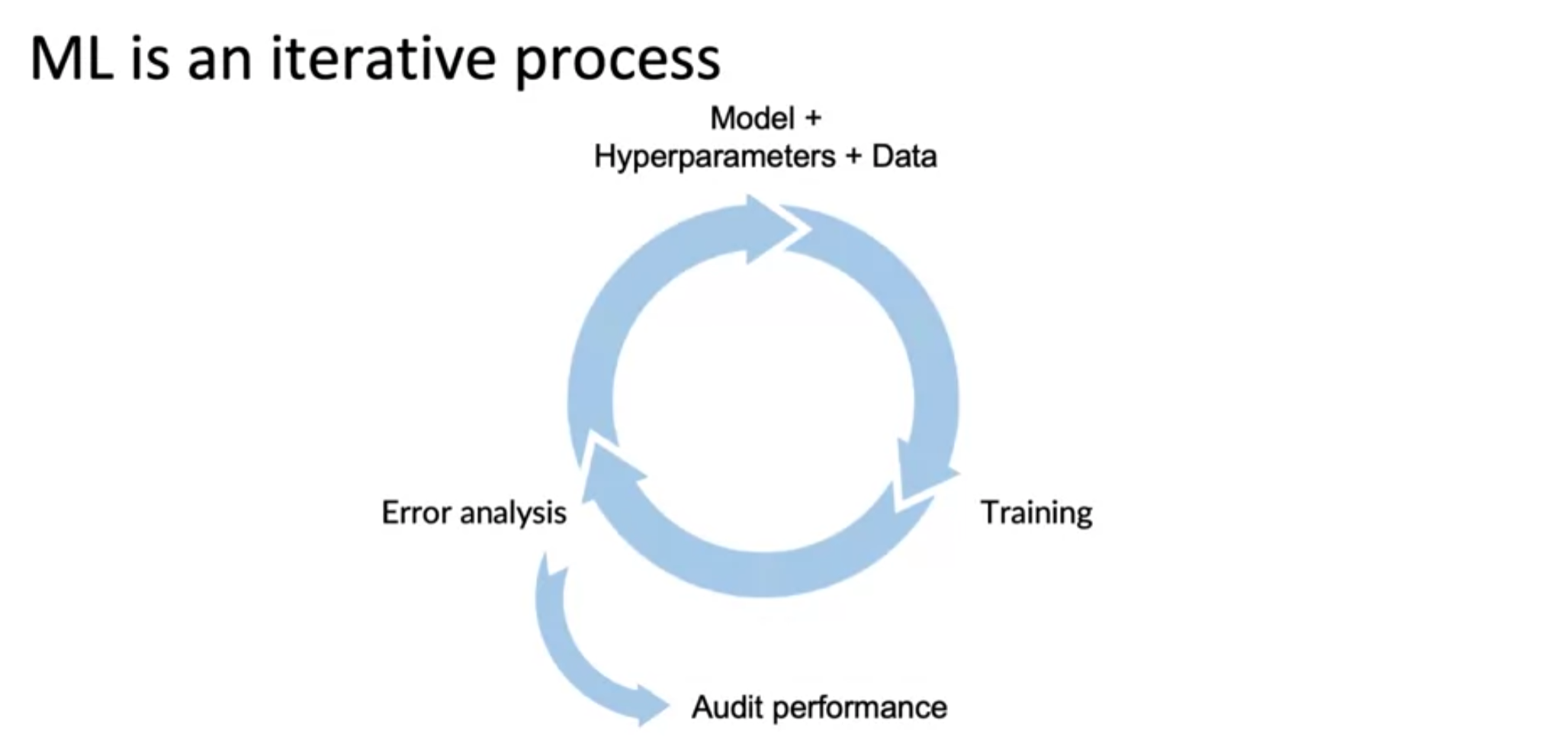
Iterative process of error analysis
- Examine/tag examples ↔ Propose tags
-
ex1. Visual inspection
- Specific class labels (scratch, dent, etc)
- Image properties (blurry, dark background, light background, reflection, ...)
- Other meta-data: phone model, factory
-
ex2. Product recommendations
- User demographics
- Product features/category
-
Useful metrics for each tag
- What fraction of errors has that tag?
- Of all data with that tag, what fraction is misclassfied?
- How much room for improvement is there on data with that tag?
[Prioritizing what to work on]
-
Decide on most important categories to work on based on
- How much room for improvement there is
- How frequently that category appears
- How easy is to imrpove accuracy in that category
- How important it is to improve in that category
-
Adding/improving data for specific categories
- Collect more data
- Use data augmentation to get more data
- Improve label accuracy/data quality
[Skewed datasets]
- Examples of skewed datasets
- Manufacturing
- Medical diagnosis
- Speech Recognition
- ...
- Use Confusion matrix and focus on Precision and Recall / F1-score according to the business objectives.
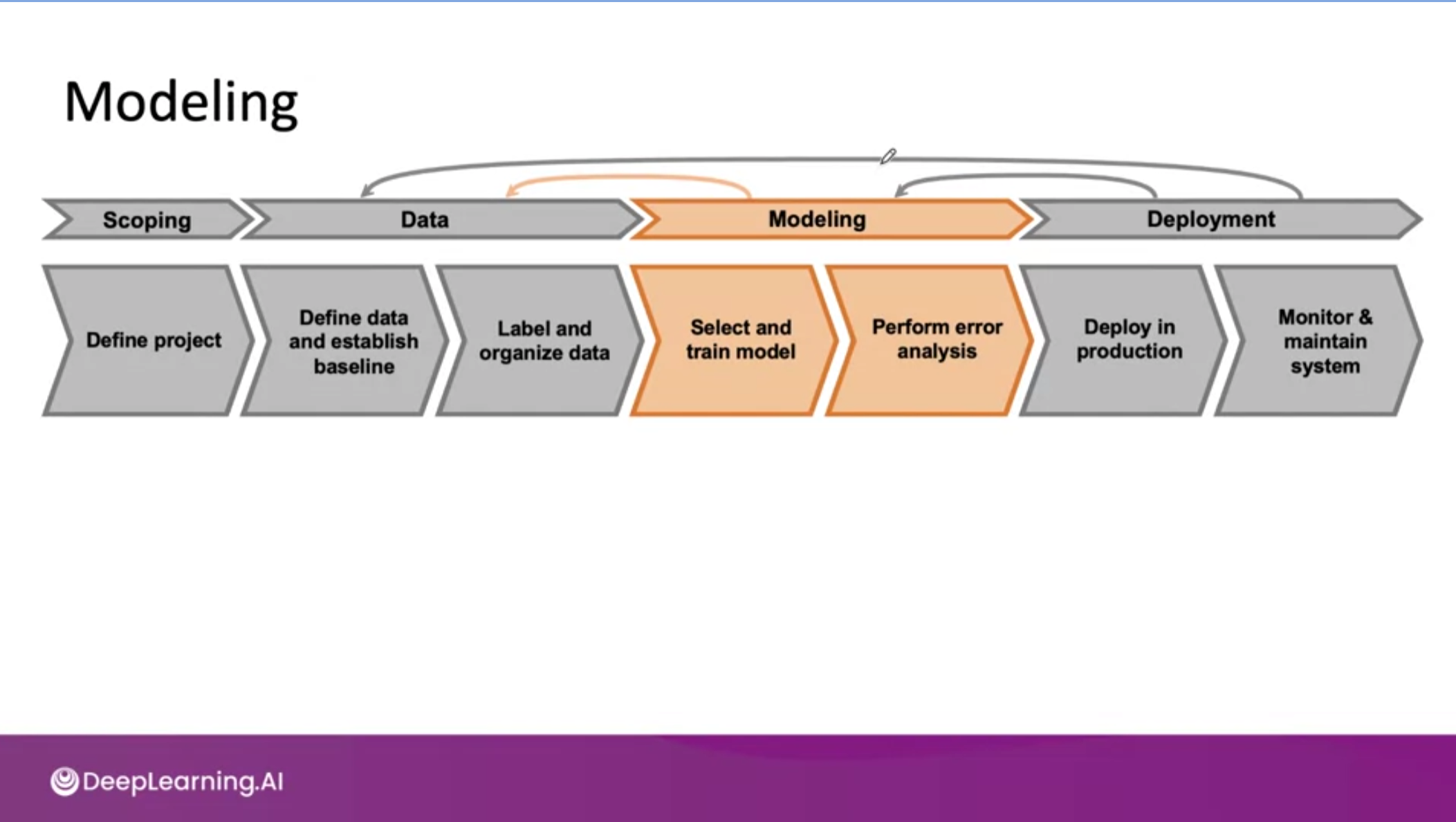
[Performance auditing]
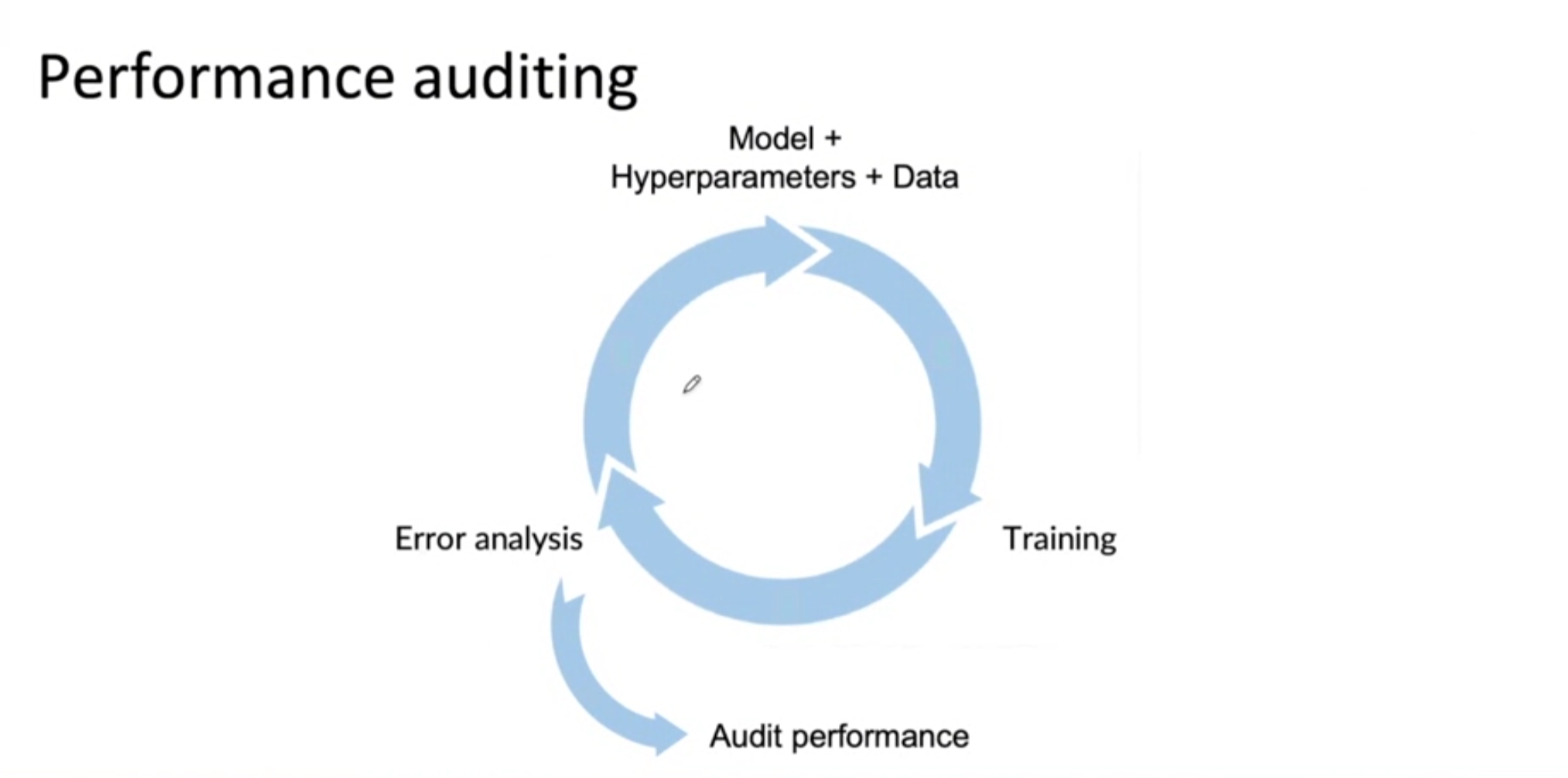
- Auditing framework: Check for accuracy, fairness/bias, and other problems
- Brainstorm the ways the system might go wrong
- Performance on subsets of data (e.g., ethnicity, gender)
- How common are certain errors(e.g., FP, FN)
- Performnace on rare classes
- Establish metrics to assess performnace against these issues on appropriate slices of data.
- Get business/product owner buy-in.

yozzum