1. RDD Transformation
-
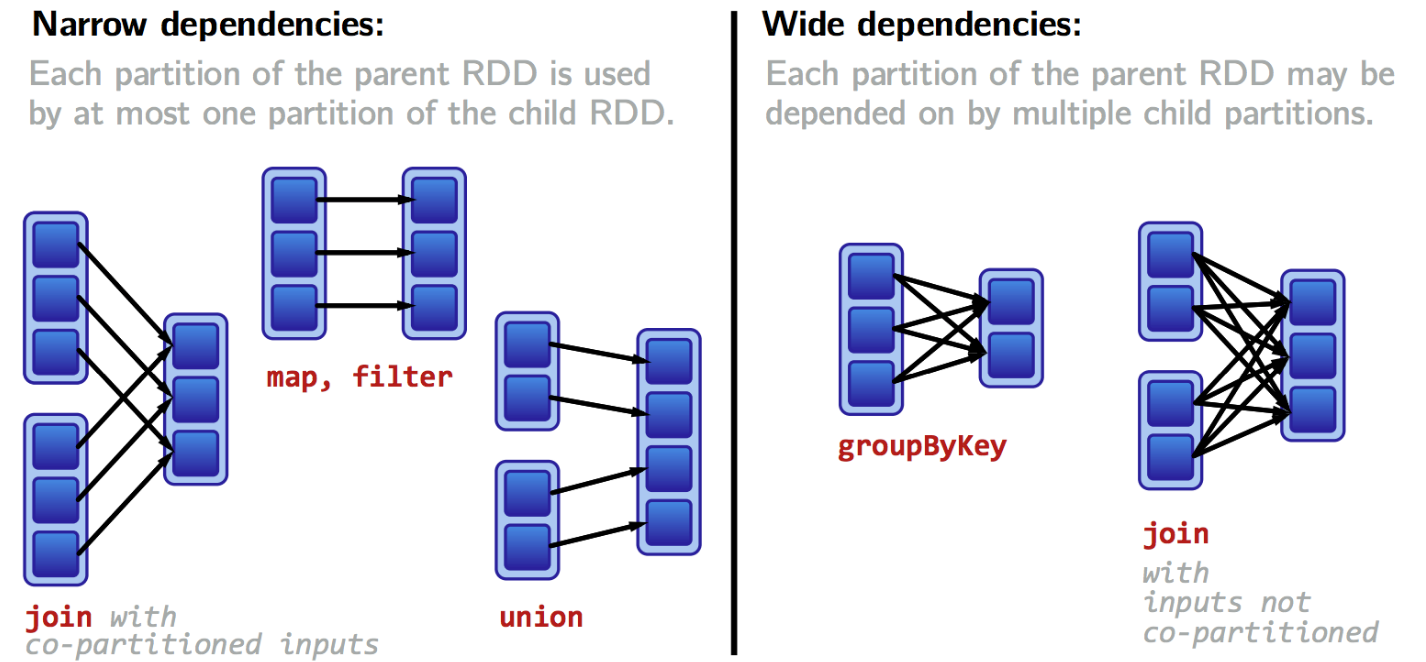
좁은 의존성
- 하나의 입력 파티션이 하나의 출력파티션에만 영향을 미친다.
- 파이프라이닝을 통해 모든 작업이 메모리에서 일어난다.
- where(), filter(), map()
-
넓은 의존성
- 하나의 입력 파티션이 여러 출력 파티션에 영향을 미친다.
- 셔플을 통해 셔플의 결과를 디스크에 저장한다.
- groupby(), reducebykey(), sort(), join()
2. Action
- 실제 연산을 수행하기 위한 명령이다.
- show(), count(), collect(), write(), toPandas(), take()
- ※ write()와 같은 함수를 사용하면, 결과 데이터를 Driver로 모으는 대신에 데이터소스(DB, 파일시스템)로 내보낼 수 있다.
3. Lazy Evaluation
- Transformation 명령이 내려지면, 스파크는 즉시 데이터를 수정하지 않고, 원천 데이터에 적용할 트랜스포메이션의 논리적 실행 계획을 생성한다.
- 이 과정을 거치며 전체 데이터 흐름을 최적화하는 엄청난 강점을 가지고 있다.
- 한 예시는 조건절 푸시다운이다. 특정 필터조건을 데이터 소스로 위힘하는 최적화 작업을 자동으로 수행한다.

yozzum