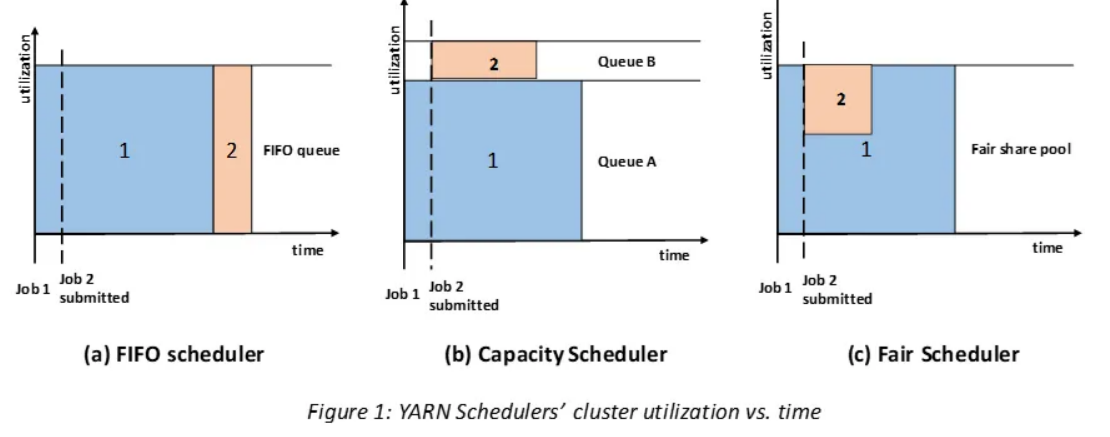
- FIFO Scheduler
- 애플리케이션을 큐에 하나씩 넣고 제출된 순서에 따라 순차적으로 실행한다.
- 단순하지만 공유 클러스터 환경에서는 부적합하다.
- Capacity Scheduler
- 자원을 나누어 큐로 나누고, Job이 제출되면 지정된 큐의 자원을 활용해서 실행한다.
- 활용되고 있지 않은 큐에 대해서는 IDLE 상태의 자원이 존재하기에 전체 클러스터의 효율성은 떨어진다.
- Fair Scheduler
- 실행중인 모든 Job의 자원을 동적으로 분배한다.
- 대형 Job의 경우 클러스터의 모든 자원을 얻을 수 있다.
- 대형 Job이 실행되는 도중에 작은 Job이 추가로 시작되면 페어 스케줄러는 클러스터 자원의 절반을 이 Job에 해당한다. ex. 대형 Job이 사용하고 있는 컨테이너의 자원이 완전히 해제될 때까지 기다리긴 해야한다.
- 작은 Job이 끝나면 대형 Job은 다시 클러스터의 전체 자원을 활용할 수 있게 된다.
※ Capacity Scheduler
- 회사의 조직체계에 맞게 가용량을 지정해서 각 조직은 그들만의 queue를 할당 받는다.
- queue는 2단계 이상의 계층 구조로 분리될 수 있으므로 세부조직에 대해서도 나눌 수 있다.
- 단일 큐 내부에 있는 애플리케이션들은 FIFO 방식으로 스케줄링 된다.
- 큐 안에 다수의 잡이 존재하고 현재 가용할 수 있는 자원이 클러스터에 남아있다면 해당 큐에 있는 잡을 위해 여분의 자원을 할당할 수 있다. (queue의 가용량 초과) 이런 방식을 queue 탄력성이라고 한다.
- 다른 큐의 가용량을 너무 많이 잡아먹지 않도록 큐에 최대 가용량을 설정할 수 있다.

yozzum