Part 09. 머신러닝 - 교차검증, 하이퍼파라미터 튜닝, 모델평가(ROC와 AUC)
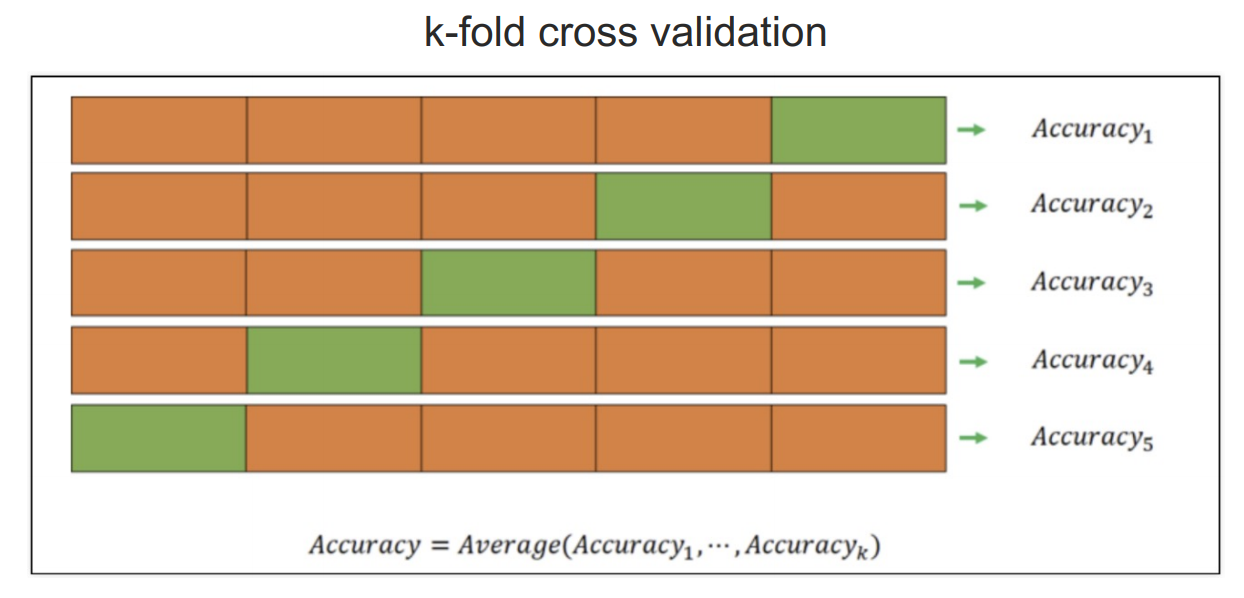
교차검증
과적합 : 모델이 학습 데이터에만 과도하게 최적화된 현상
그로 인해 일반화된 데이터에서는 예측 성능이 과하게 떨어지는 현상
교차 검증은 하이퍼파라미터 튜닝 과정에서 모델의 일반화 성능을 평가하고 최적의 하이퍼파라미터를 선택하는 데 필수적인 요소
하이퍼파라미터 튜닝을 할 때 교차 검증을 함께 사용하면 모델의 성능을 더욱 정확하게 평가할 수 있고, 과적합을 방지할 수 있다

from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import KFold
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
wine_tree.fit(X_train, y_train)
y_pred_tr = wine_tree.predict(X_train)
y_pred_test = wine_tree.predict(X_test)
# KFold 객체 생성 (5개의 폴드로 나누기)
kfold = KFold(n_splits=5)
wine_tree_cv = DecisionTreeClassifier(max_depth=2, random_state=13)
# 각 폴드에 대한 훈련 데이터와 테스트 데이터의 길이 출력
for train_idx, test_idx in kfold.split(X):
print(len(train_idx), len(test_idx))
# 교차 검증을 사용하여 결정 트리 분류기의 정확도 평가
cv_accuracy=[]
for train_idx, test_idx in kfold.split(X):
X_train = X.iloc[train_idx]
X_test = X.iloc[test_idx]
y_train = y.iloc[train_idx]
y_test = y.iloc[test_idx]
wine_tree_cv.fit(X_train, y_train)
pred = wine_tree_cv.predict(X_test)
cv_accuracy.append(accuracy_score(y_test, pred))
cv_accuracy
np.mean(cv_accuracy)
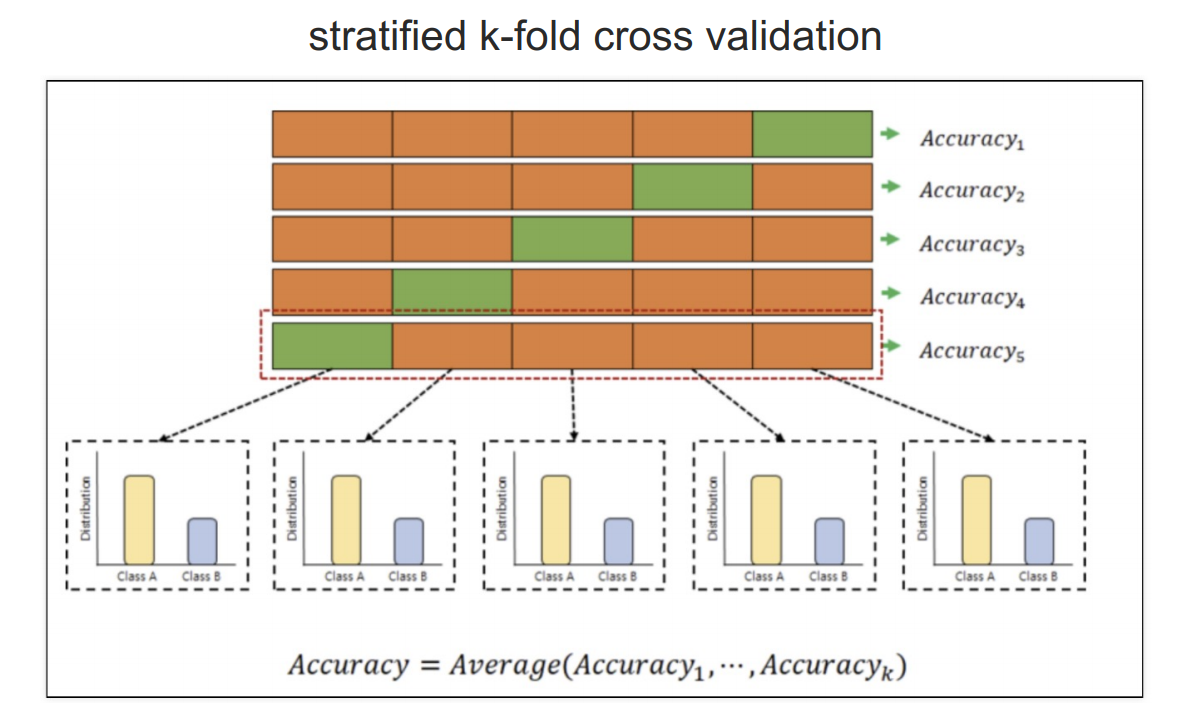
# StratifiedKFold : 각 폴드가 원래 데이터셋의 클래스 비율을 유지 => 보다 신뢰성 있는 평가 가능
from sklearn.model_selection import StratifiedKFold
skfold = StratifiedKFold(n_splits=5)
wine_tree_cv = DecisionTreeClassifier(max_depth=2, random_state=13)
cv_accuracy=[]
for train_idx, test_idx in skfold.split(X,y):
X_train = X.iloc[train_idx]
X_test = X.iloc[test_idx]
y_train = y.iloc[train_idx]
y_test = y.iloc[test_idx]
wine_tree_cv.fit(X_train, y_train)
pred = wine_tree_cv.predict(X_test)
cv_accuracy.append(accuracy_score(y_test, pred))
cv_accuracy
np.mean(cv_accuracy)
--------------------------------------------------------------------
# 간단한 방법
from sklearn.model_selection import cross_val_score
skfold = StratifiedKFold(n_splits=5)
wine_tree_cv = DecisionTreeClassifier(max_depth=2, random_state=13)
cross_val_score(wine_tree_cv, X, y, cv=skfold)
# array([0.55230769, 0.68846154, 0.71439569, 0.73210162, 0.75673595])
from sklearn.model_selection import cross_validate
cross_validate(wine_tree_cv, X, y, cv=skfold, return_train_score=True)
# {'fit_time': array([0.01579952, 0.01399755, 0.01633835, 0.01520157, 0.01450634]),
# 'score_time': array([0.00200248, 0.00200224, 0.00200129, 0.00200915, 0.00254345]),
# 'test_score': array([0.50076923, 0.62615385, 0.69745958, 0.7582756 , 0.74903772]),
# 'train_score': array([0.78795459, 0.78045026, 0.77568295, 0.76356291, 0.76279338])}
# train 데이터는 높은데 test 데이터는 낮음 => 과적합 현상 보임하이퍼파라미터 튜닝
모델의 학습 과정에 영향을 미치는 매개변수로 모델의 성능을 확보하기 위해 조절하는 설정 값
예) 결정 트리 모델 : 트리의 최대 깊이나 노드 분할 기준 등
하이퍼파라미터를 적절히 튜닝하여 모델의 성능을 최적화할 수 있다
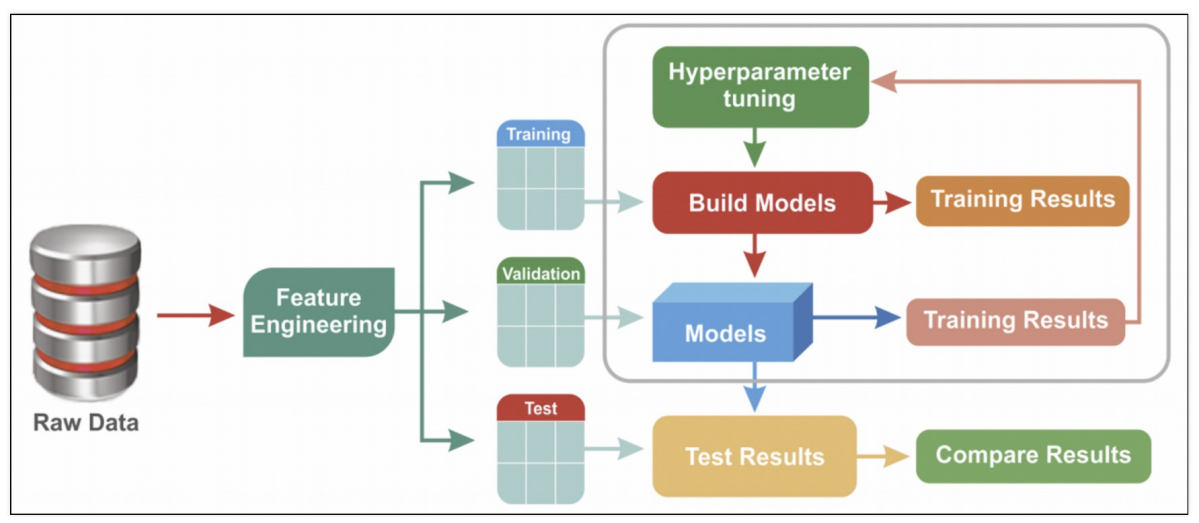
GridSearch CV
GridSearchCV는 교차 검증(cross validation)을 통해 각 파라미터 조합에 대한 성능을 평가하며, 이때 데이터를 자동으로 여러 개의 fold로 나눠 교차 검증을 수행한다
- 다양한 파라미터를 모두 실행해 볼 수 있다
- GridSearchCV에는 cross validation 옵션이 있다
- 이 기능을 수행한 후 결과에 대한 report가 제공된다
## GridSearch CV
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier
params = {'max_depth' : [2,4,7,10]}
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
# train, search, split 사용 필요 x, gridsearch가 알아서 해줌
gridsearch = GridSearchCV(estimator=wine_tree, param_grid = params, cv=5)
gridsearch.fit(X,y)
## GridSearchCV 결과
import pprint
pp = pprint.PrettyPrinter(indent=4)
pp.pprint(gridsearch.cv_results_)
# max_depth가 커진다고 좋은건 아님
gridsearch.best_estimator_
gridsearch.best_score_
gridsearch.best_params_
# 만약 pipeline을 적용한 모델에 GridSearch를 적용하고 싶다면
from sklearn.pipeline import Pipeline
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import StandardScaler
estimators = [
('scaler', StandardScaler()),
('clf', DecisionTreeClassifier())
]
pipe = Pipeline(estimators)
param_grid = [{'clf__max_depth' : [2,4,7,10]}]
GridSearch = GridSearchCV(estimator=pipe, param_grid=param_grid, cv=5)
GridSearch.fit(X,y)
GridSearch.best_estimator_
GridSearch.best_score_
GridSearch.best_params_
# 표로 성능 결과 정리
import pandas as pd
score_df = pd.DataFrame(GridSearch.cv_results_)
score_df[['params', 'rank_test_score', 'mean_test_score', 'std_test_score']]

모델평가
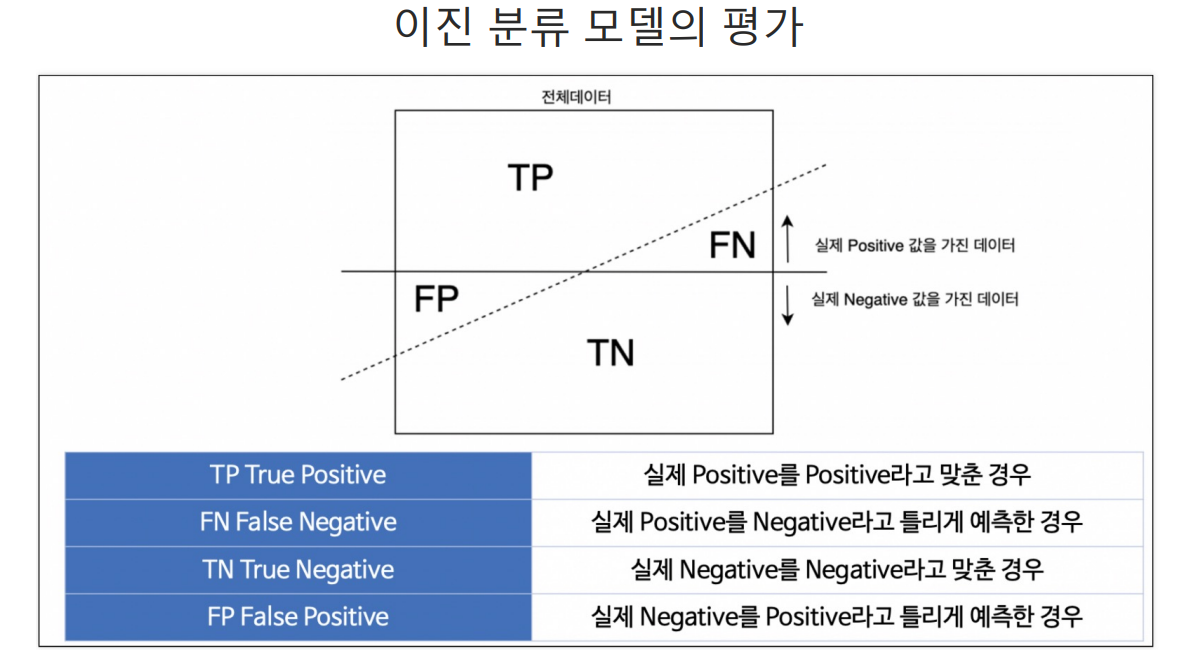
Type 1 error = FP
Type 2 error = FN
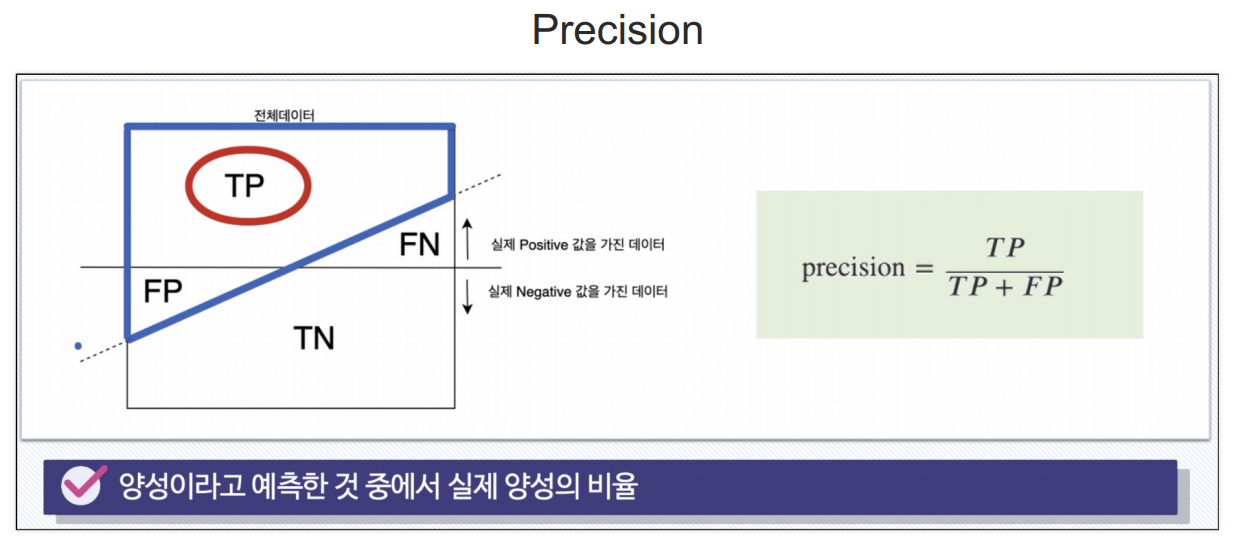

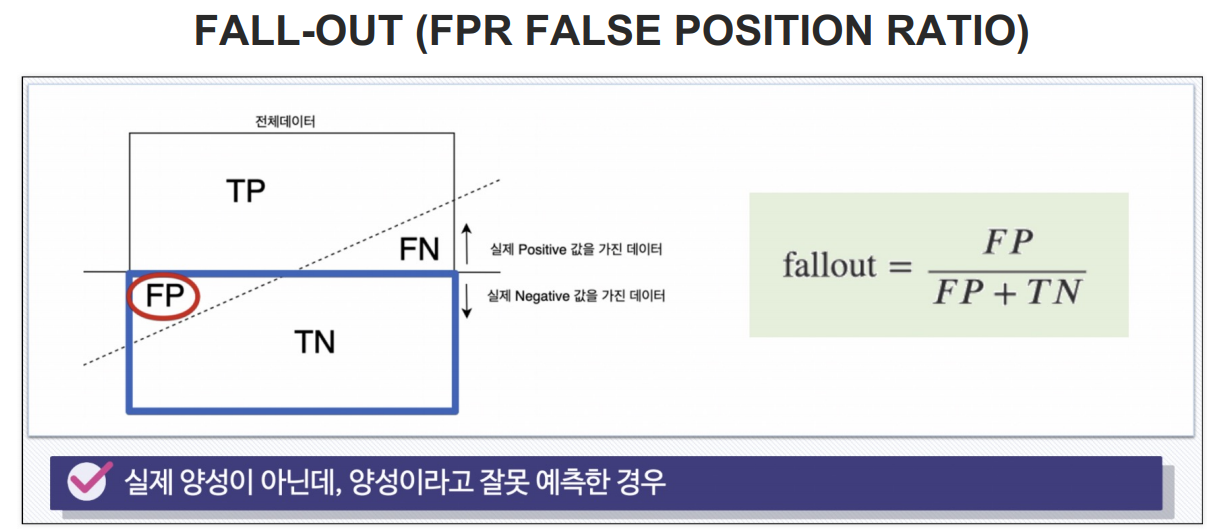
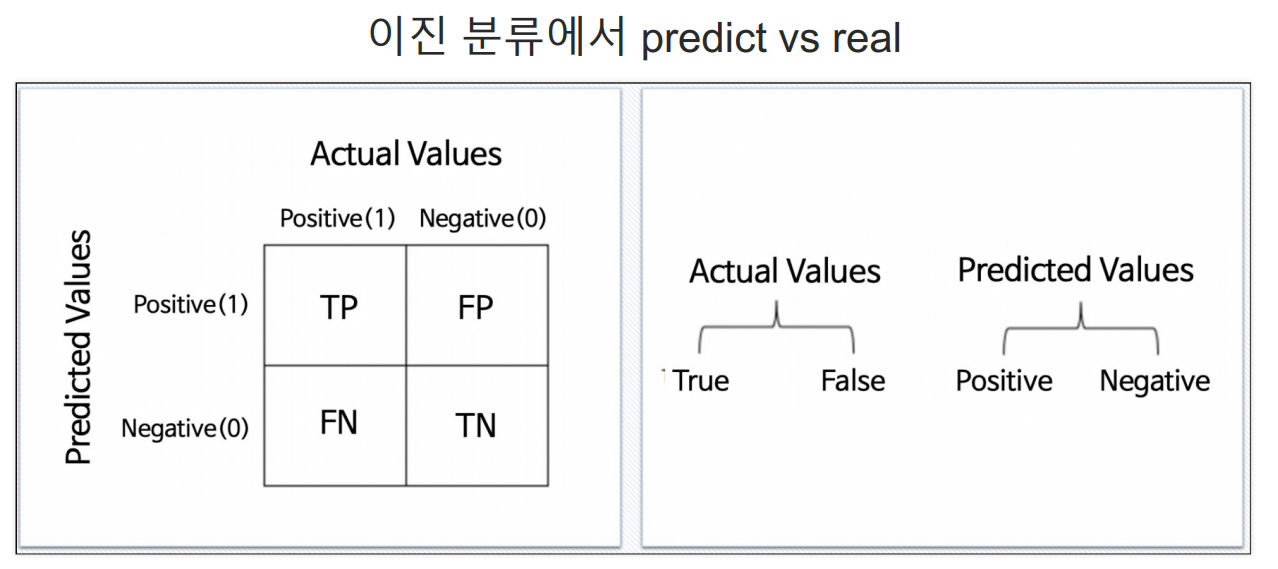
분류모델은 그 결과를 속할 비율(확률)을 반환한다
threshold : 특정 확률 이상을 긍정(또는 1)으로 분류하고 그 미만을 부정(또는 0)으로 분류할 때 기준이 되는 확률 값
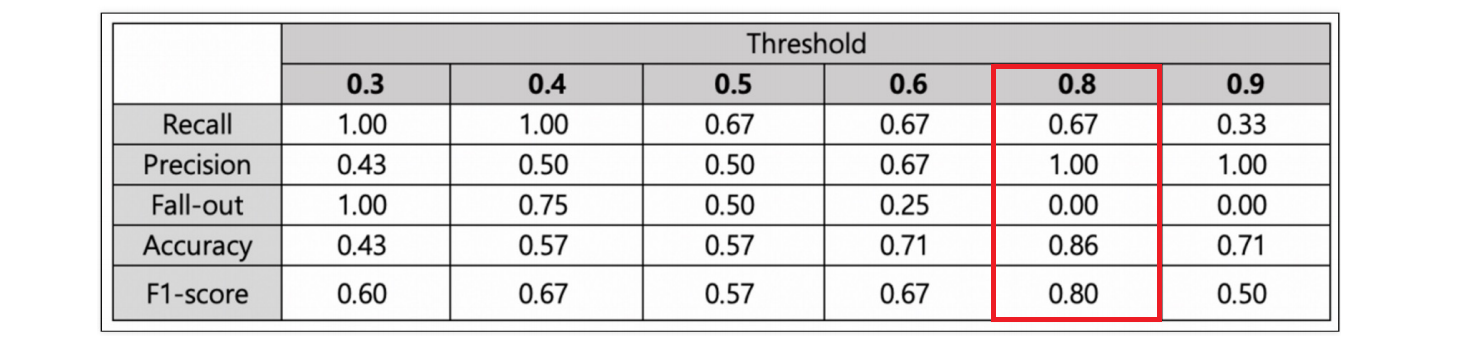
Recall과 Precision은 서로 영향을 주기 때문에 한 쪽을 극단적으로 높게 설정해서는 안됨

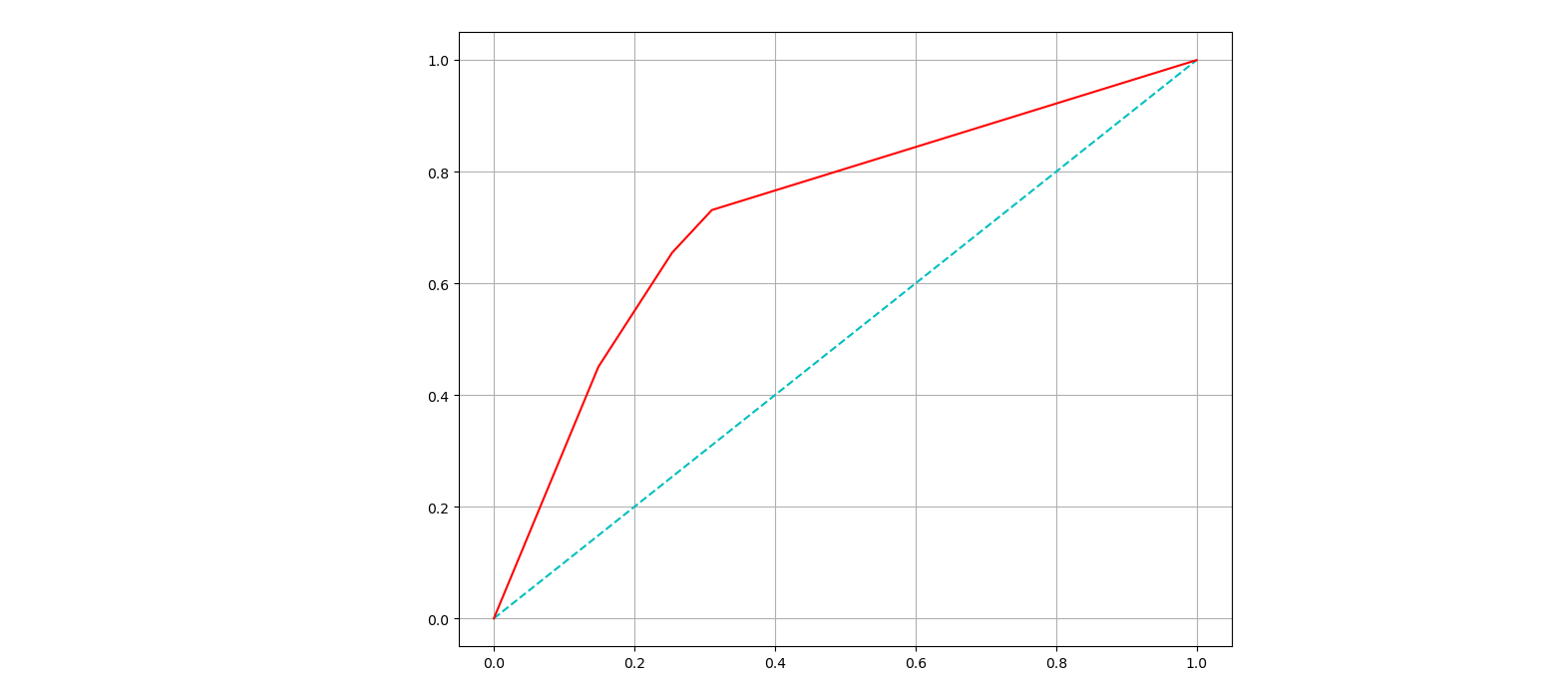
ROC와 AUC
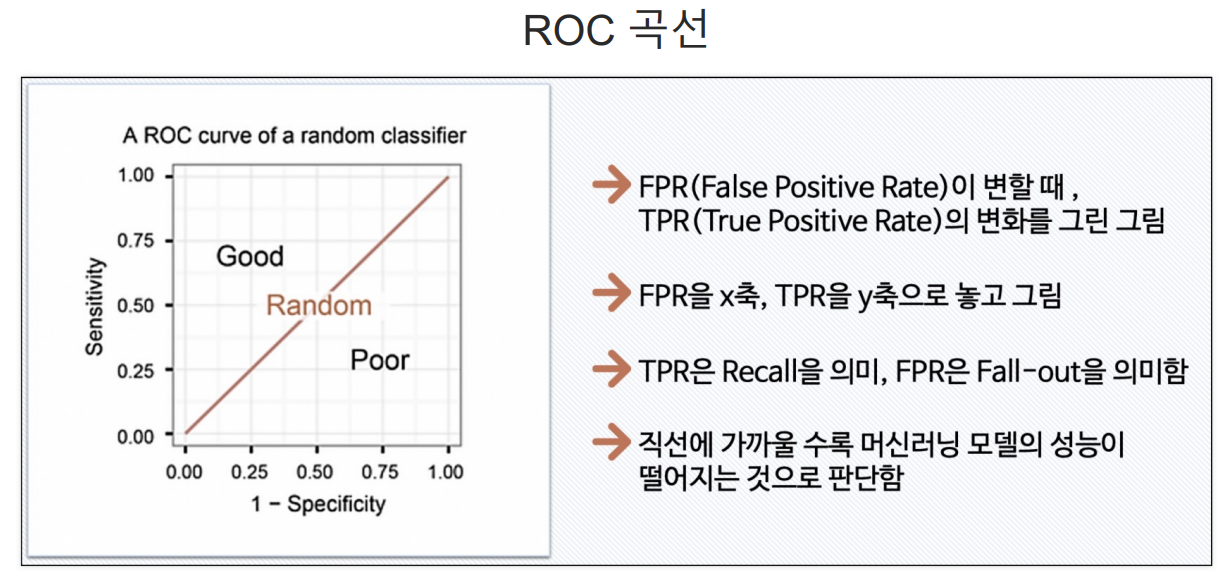
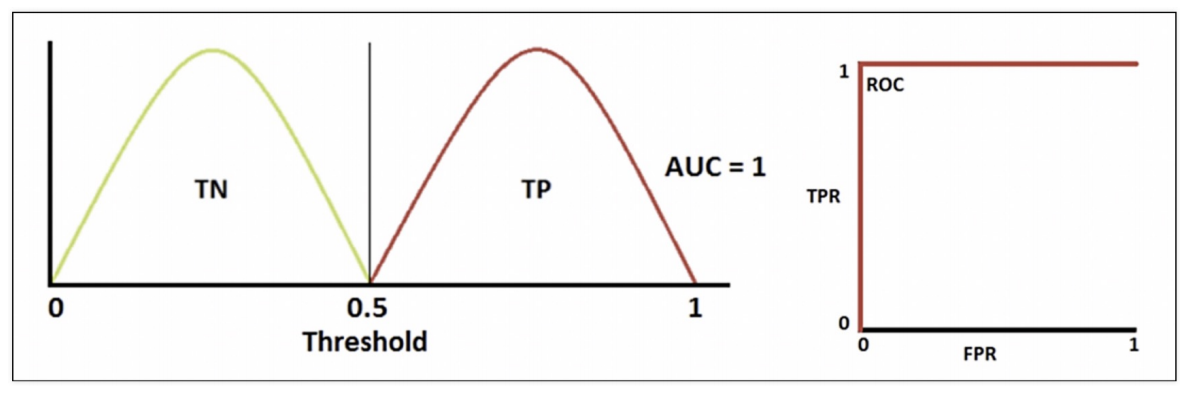
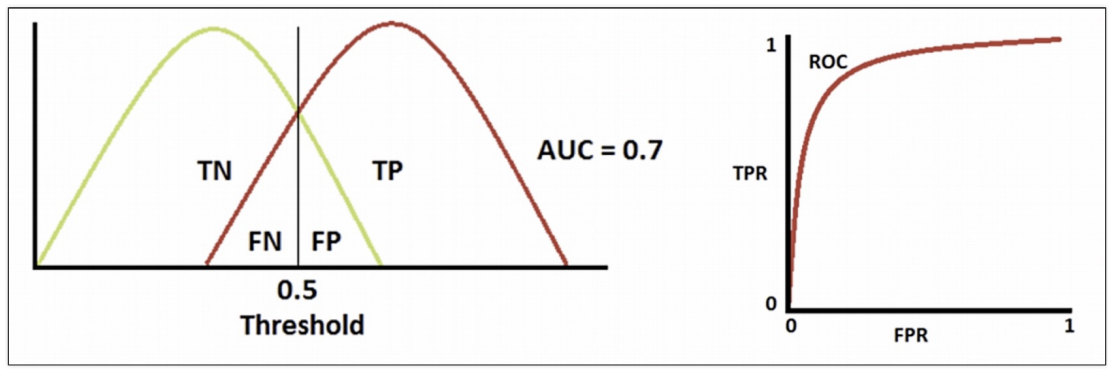
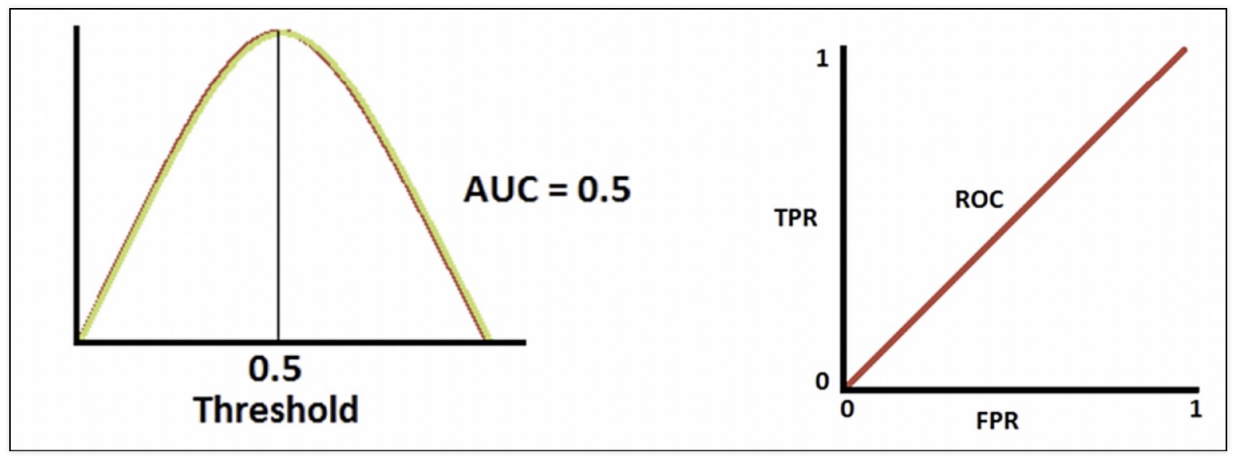
AUC : ROC곡선 아래의 면적
기울기가 1인 직선 아래의 면적이 0.5 (AUC는 0.5보다 커야 함)
AUC =1 : 완벽하게 분류
AUC = 0.5 : 분류 성능이 나쁨
=> AUC는 일반적으로 1에 가까울 수록 좋은 수치
FALLOUT(FPR)값이 같을 때 RECALL(TPR)값이 큰 걸 선택
# 각 수치 구해보기
from sklearn.metrics import accuracy_score, precision_score
from sklearn.metrics import recall_score, f1_score
from sklearn.metrics import roc_auc_score, roc_curve
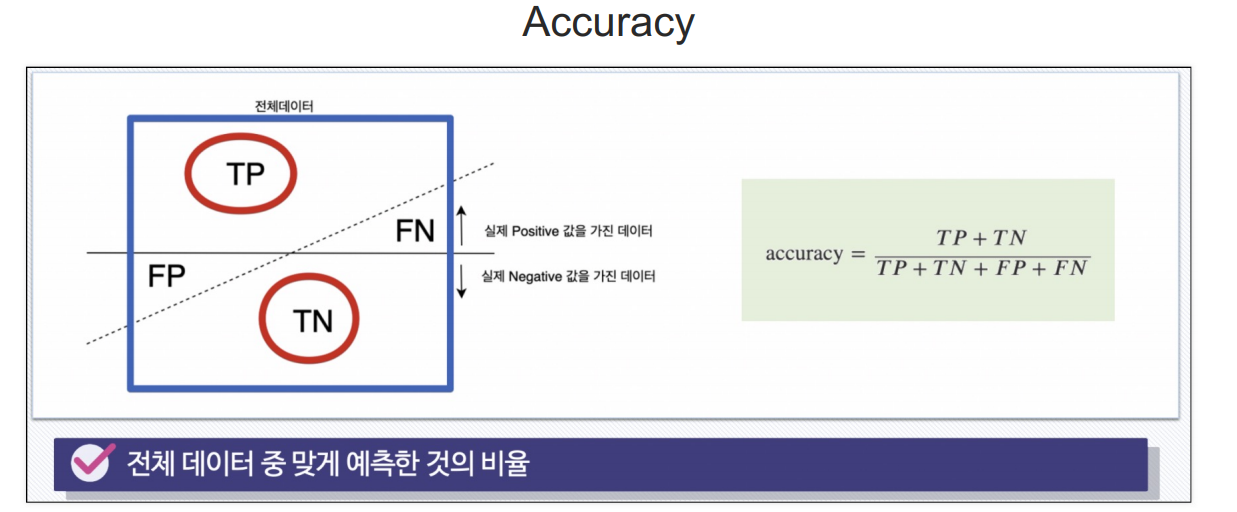
print('Accuracy : ', accuracy_score(y_test, y_pred_test))
print('Recall : ', recall_score(y_test, y_pred_test))
print('Precision : ', precision_score(y_test, y_pred_test))
print('AUC score : ', roc_auc_score(y_test, y_pred_test))
print('F1 score : ', f1_score(y_test, y_pred_test))
# 0일 확률, 1일 확률 중 1일 확률만 출력
wine_tree.predict_proba(X_test)[:, 1]
# ROC 커브 그리기
import matplotlib.pyplot as plt
pred_prob = wine_tree.predict_proba(X_test)[:, 1]
fpr, tpr, thresholds = roc_curve(y_test, pred_prob)
plt.figure(figsize=(10, 8))
plt.plot([0,1],[0,1], 'c', ls='dashed')
plt.plot(fpr, tpr, 'r')
plt.grid()
plt.show()