1. 문제 소개


1930. Unique Length-3 Palindromic Subsequences
2. 나의 풀이
처음 생각했던 것은 Counter를 사용해 1차적으로 필터링하는 것이었다.
그러나 힌트와 set을 사용하는 것이 낫다고 판단하고 다음과 같이 풀었다.
전체적으로 시간복잡도는 를 따라간다.
class Solution:
def countPalindromicSubsequence(self, s: str) -> int:
meet = set() # 이미 바깥 문자로 사용한 문자(ch)들을 기록하는 집합
n, ans = len(s), 0 # n: 문자열 길이, ans: 결과(서로 다른 길이 3 팰린드롬 수)
for i, ch in enumerate(s): # i: 왼쪽 인덱스, ch: s[i] (바깥 문자 후보)
end = n - 1 # end: 오른쪽에서부터 같은 문자 ch를 찾기 위한 포인터
# i와 end가 만나기 전까지, 그리고 아직 ch를 바깥 문자로 처리하지 않았을 때만 탐색
while i != end and ch not in meet:
if ch == s[end]: # 오른쪽 끝에서 같은 문자 ch를 찾은 경우 (s[i] == s[end])
meet.add(ch) # 이 문자 ch는 이제 바깥 문자로 한 번 처리했으므로 meet에 기록
dupe = set() # 중간 문자들의 중복을 막기 위한 집합 (해당 ch에 대해 한 번만 카운트)
for c in s[i + 1:end]:
# i와 end 사이의 모든 문자 c를 확인하며,
# 아직 등장하지 않은 가운데 문자라면 ans를 1 증가
if c not in dupe:
ans += 1 # (ch, c, ch) 형태의 새로운 길이 3 팰린드롬 하나 발견
dupe.add(c)
# print(ch, c, ch) # 디버깅용 출력(주석 처리)
break # 해당 ch에 대해 가장 오른쪽 end를 찾고 처리했으므로 while 종료
end -= 1 # 아직 같은 문자를 못 찾은 경우 오른쪽 포인터를 한 칸 왼쪽으로 이동
return ans # 최종적으로 서로 다른 길이 3 팰린드롬 수를 반환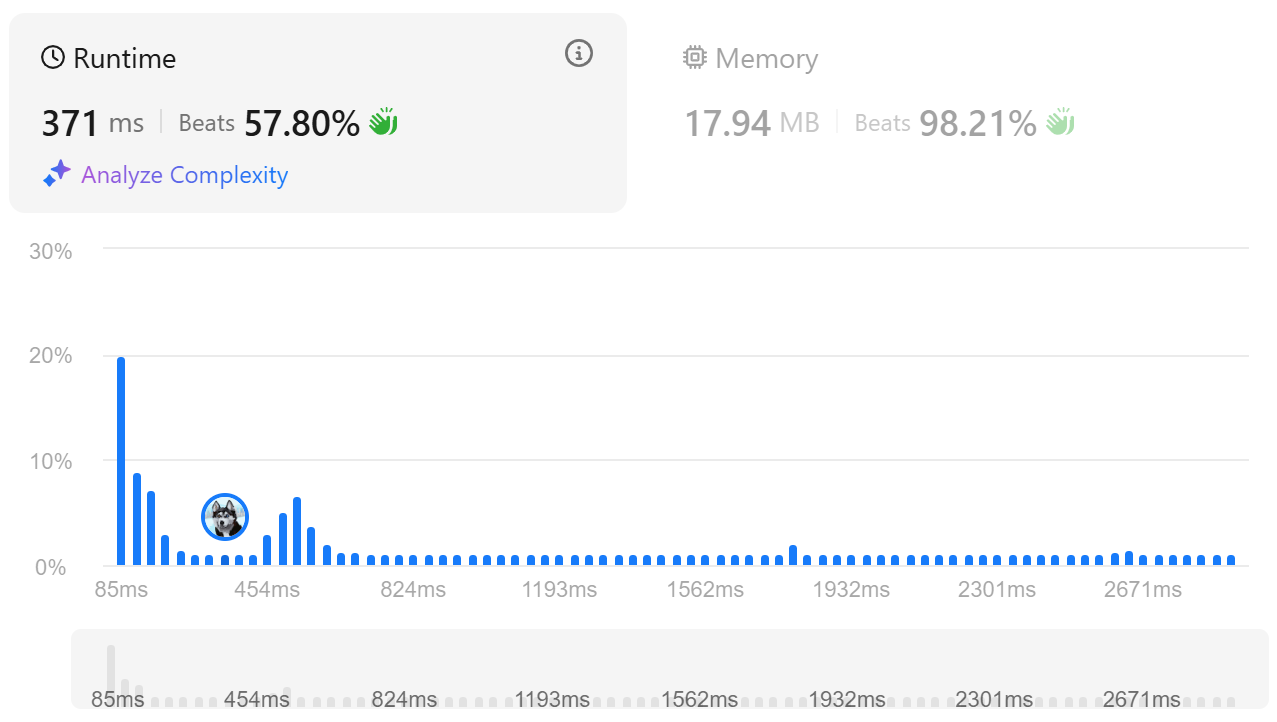
3. 다른 풀이
처음 풀이는 Editorial의 풀이이다.
나와 비슷한 방법론을 사용한 것인데, 파이썬의 set, index, rindex를 사용해 단순하다.
하지만 시간복잡도는 최악의 경우 이 될 수 도 있다.
class Solution:
def countPalindromicSubsequence(self, s: str) -> int:
letters = set(s) # 문자열에 등장하는 문자 종류 집합
ans = 0
for letter in letters: # 각 문자(letter)를 바깥 문자로 삼고
i, j = s.index(letter), s.rindex(letter)
# letter가 처음/마지막 등장하는 인덱스 (O(n)씩 걸린다는 문제가 있음)
between = set() # 가운데 위치에서 등장하는 서로 다른 문자 집합
for k in range(i + 1, j): # 첫 등장과 마지막 등장 사이 구간을 순회
between.add(s[k]) # 그 구간에 등장하는 문자들을 모음
ans += len(between) # 서로 다른 가운데 문자 개수가 곧 (letter, b, letter) 종류 수
return ans
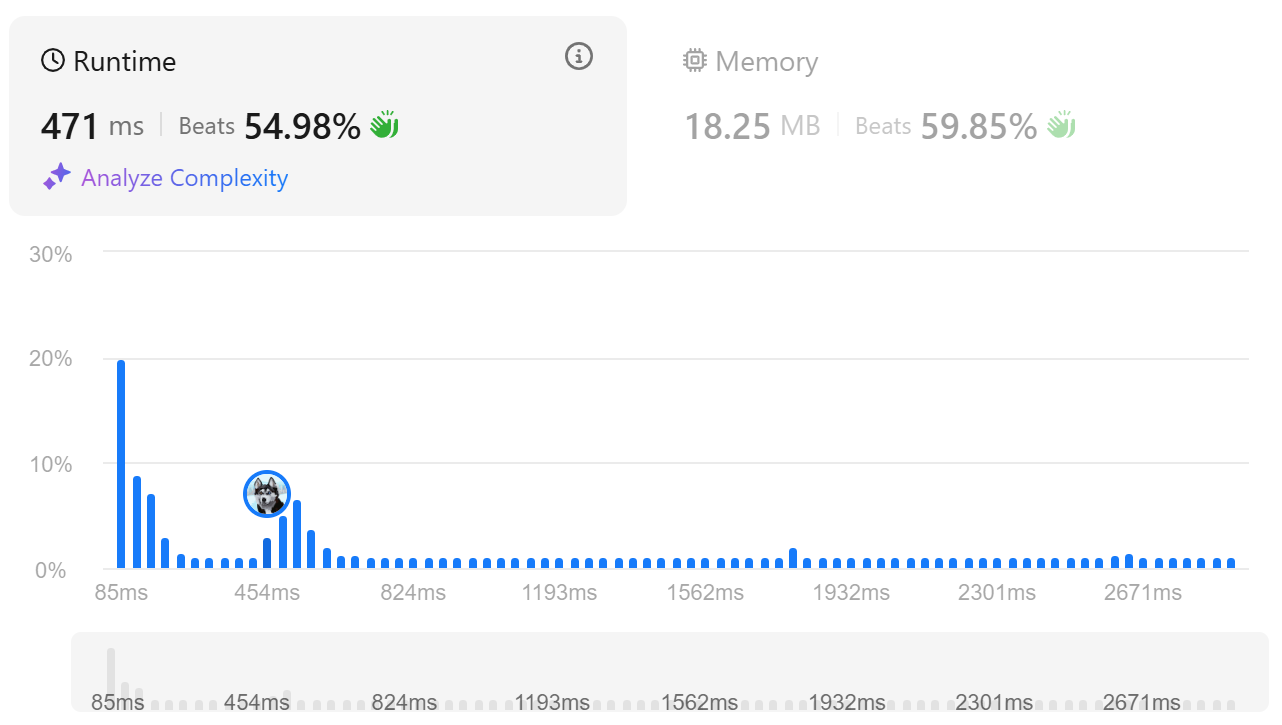
두 번째 풀이(first/last + bitmask)는 각 문자에 대해 first/last 인덱스를 에 한 번만 계산하고, 중간 문자들은 비트마스크로 관리해 중복 제거를 에 처리한다.
공간도 적고 매우 빠르며 최악 → 사실상 에 수렴한다.
가장 최적화된 풀이로 LeetCode 상위권이 사용하는 방식이라고 한다.
class Solution:
def countPalindromicSubsequence(self, s: str) -> int:
n = len(s)
first = [-1] * 26 # 각 문자 a~z 첫 등장 위치
last = [-1] * 26 # 각 문자 a~z 마지막 등장 위치
for i, ch in enumerate(s): # 문자열 전체를 한 번만 스캔
c = ord(ch) - ord('a') # 문자 → 0~25 인덱스로 변환
if first[c] == -1: # 아직 첫 등장 위치가 없다면 업데이트
first[c] = i
last[c] = i # 마지막 등장 위치는 계속 갱신
ans = 0
for c in range(26): # 각 문자(a~z)를 바깥 문자로 삼기
if first[c] != -1 and last[c] - first[c] > 1:
# 바깥 문자가 최소 두 번 등장해야 하고, 가운데 공간이 있어야 함
mask = 0 # 가운데 문자 집합을 비트마스크로 표현
for i in range(first[c] + 1, last[c]):
# 첫 등장과 마지막 등장 사이 문자를 스캔
mask |= 1 << (ord(s[i]) - ord('a'))
# 가운데 문자 종류를 bit 1로 기록 → 중복 자동 제거
ans += bin(mask).count("1")
# mask에서 bit 1의 개수 = 서로 다른 가운데 문자 종류 수
return ans
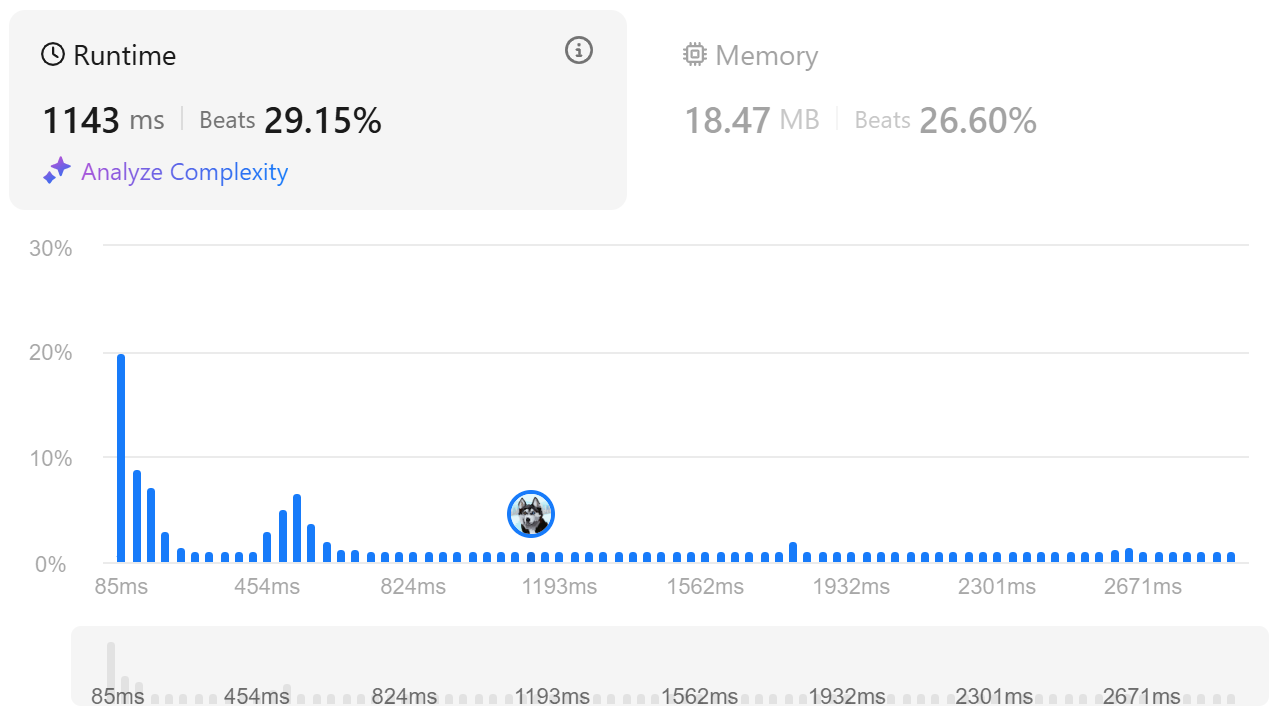
4. 결론
다양한 풀이방법도 배우고, 내 힘으로도 풀어서 기분이 좋다.

Junior AI Engineer