
순위검색
링크: https://school.programmers.co.kr/learn/courses/30/lessons/72412
문제분류 : 구현, 파라메트릭 서치
난이도 : Level 2
결과: 실패
회고
파라메트릭 서치를 이용해야 한다는 건 알고 있었다. 다만, 데이터의 전처리를 비효율적으로 한게 크다.
또 파라메트릭 서치를 써서 효율성 테스트를 통과했다면 모르겠지만 효율성도 통과하지 못했다.
결국 모범답안을 확인했는데, 파라메트릭 서치는 단 한번만 사용했고 데이터의 전처리를 효과적으로 했다.
예전에 백준을 풀 때부터 파라메트릭 서치 문제만 나오면 맥없이 틀렸었다.
하지만 이 문제의 코드를 분석하면서 파라메트릭 서치의 개념을 다시 한 번 짚어보니
예전부터 내가 헷갈려했던 범위체크에 관한 고질적인 문제를 해결 할 수 있었다.
똑같은 실수를 또 하지 않기 위해 내 창피한(?) 코드를 공개하고 모범답안과 비교하고자 한다.
내 코드
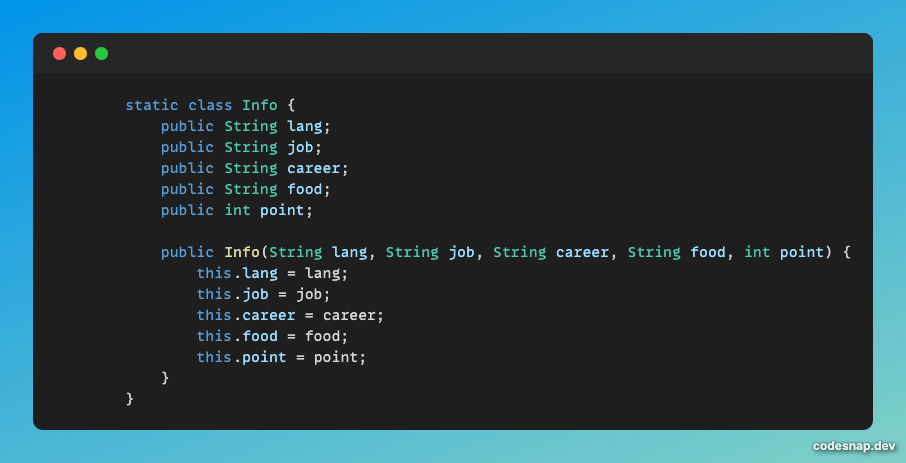
나는 입력으로 주어진 info 배열과 query 배열을 파싱해서 Info 클래스에 저장해두었다.
이렇게 저장해두면 info 배열에 의해 만들어진 Info 객체에는 각 사람의 데이터가 들어간다.
그리고 query 배열에 의해 만들어진 Info에는 찾고자하는 사람들의 조건이 들어간다.
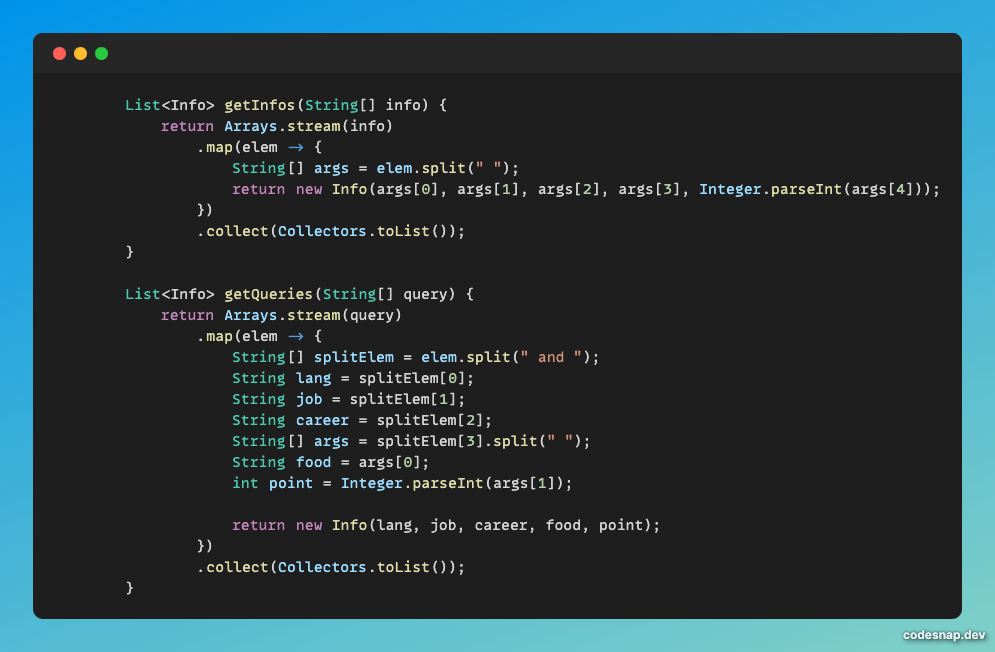
데이터 파싱은 위와 같이 해주었다. 이 부분에 관해서는 설명을 생략하겠다.
for문을 사용해서 조건 별로 파싱하지 않고 stream의 map을 사용해서 String에서 데이터를 파싱하고
객체로 만들어 List< Info>로 반환해주었다.
이제 데이터 전처리는 끝냈으니, 답만 구하면 된다. 하지만...
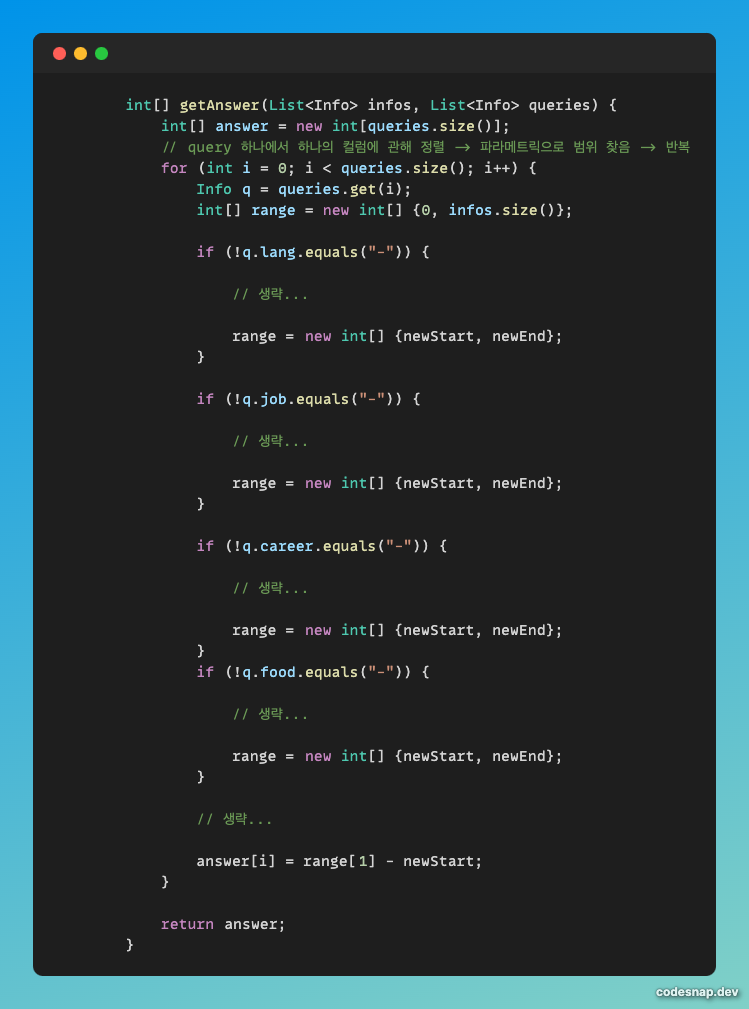
내가 작성한 로직이다. 생략이라고 한 이유는 너무 길어서이다
망한 알고리즘 풀이 특징 : 완전탐색도 아닌데 풀이가 너무 김
내가 생각한 아이디어는 아래와 같다.
-
Info 클래스에 있는 찾고자하는 검색어를 기준으로 문자열들은 사전순으로 정렬을 한다.
(단, '-'가 있을 경우에는 정렬을 하지 않는다.) -
정렬 후 키워드에 따라 파라메트릭 서치를 진행한다.
lower bound와 upper bound의 인덱스를 모두 알아야범위가 점점 좁혀지기 때문에
lower bound와 upper bound 모두 구해야 한다. -
구한 lower bound와 upper bound의 범위로 다음 검색어에 관해 1과 2를 반복한다.
얼추 그림으로 표현하면 아래와 같다.
-
lang에 관해 사전순으로 정렬
(java, cpp python, cpp, java, java, ....) > (cpp, cpp, java, java, java, python ...)
검색어가 java라면 파라메트릭 서치로 java의 upper bound와 lower bound를 구한다.
[start, end) > [2, 5) -
다른 검색어들(job, career, food)에 관해서 1의 방법 반복
(java, java, java) > (java, java) -> (java)
이런 식으로 범위가 좁혀질거라 생각함 -
point에 관해서는 lower bound만 찾아서 upper bound - lower bound를 계산한 후 answer 배열에 저장
어떻게 잘 구현하면 풀릴 수도 있을거 같지 않은가?(나만 그런가)
알고리즘으로 코드를 정확하게 짜면 정확도 테스트는 합격할 수 있지만 효율성 테스트에서 실패한다.
사실 시간복잡도가 1억을 넘어선다는 것을 계산했지만, 다른 풀이 방법이 생각안나 울며 겨자먹기로 풀었다.
내 풀이의 시간복잡도를 한 번 계산해보자.
일단 조건으로 주어지는 info 배열의 최대 길이는 5만이다.
따라서 시간 복잡도는 O('split의 시간복잡도' * 5만)이다.
query 배열에 관한 파싱도 비슷하다.
시간복잡도가 O('split의 시간복잡도' * 10만)이다.
데이터 파싱에만 O(15만 이상)이 들어간 것이다.
그래도 아직까지는 괜찮다고 생각할 수 있다.
하지만 문제는 답을 구하는 과정이다.
나는 파라메트릭 서치를 하나의 문자열 필드에 관해 2번 진행한다.
문자열 필드는 총 4개가 있기 때문에 8번 진행한다.
또 하나의 필드마다 정렬을 한다. 정렬의 시간복잡도는 NlogN이다.
따라서 4개의 문자열 필드에 관해서 시간복잡도는 4 (NlogN + 2 logN) 이 된다.
아직 안끝났다...! point에 관해서도 정렬하고 파라메트릭 서치를 해야 한다.
여기서는 파라메트릭 서치가 한 번만 일어나서 NlogN + logN으로
여기에 query 배열의 최대 개수인 10만을 곱하면?
말도 안되는 시간복잡도가 나온다.
완전탐색보다도 못한 결과이다.
또한 코드의 중복이 너무 많아진다.
파라메트릭 서치를 lower bound와 upper bound 둘 다 진행하게 되는데
클래스에 데이터를 배열로 만들어서 저장한 것도 아니라
반복적으로 추상화를 할 수 없다.
그래서 억지로 복붙한 풀이가 나왔다.
윽 최악이다...
모범 답안
이 풀이는 정말 깔끔하다. 언제쯤 이런 경지에 도달할 수 있을까... ㅎㅎ
모범답안의 핵심 아이디어는 참가자들의 점수에 주목하고 이 부분에서 시간복잡도를 확실하게 줄인 것이다.
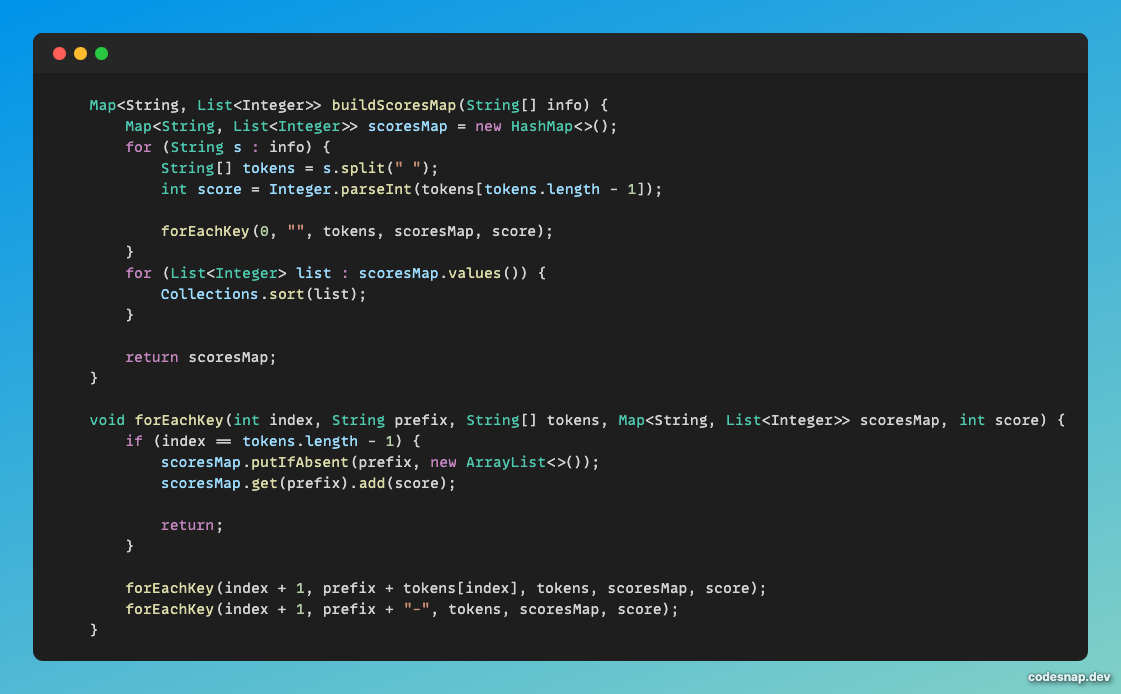
먼저 buildScoresMap과 forEachKey의 역할에 관해 알아보자.
buildScoresMap은 데이터 파싱을 하는 역할이다.
info 배열에서 참가자의 정보를 꺼낸다.
split으로 String 데이터들을 파싱하고 마지막에 나오는 점수는 Integer로 변환한다.
변환한 점수를 어떻게 저장해야 효과적일까?
위의 코드에서는 Map을 활용했다.
Key는 검색하려는 키워드들을 조합한 값이고 Value는 key에 맞는 참가자가 얻은 점수를 List로 넣어놓는다.
그도 그럴 것이 검색조건은 유일한 조합이기 때문에 Map에 List를 value로 넣어 모음을 만들 수 있다.
forEachKey 메서드는 완전한 Key를 조합하기 위한 재귀 메서드이다.
query 배열에서 등장할 수 있는 경우는 '사용자가 가질 수 있는 값 + '-' '다.
모든 조합을 만드는 시간복잡도는 O(4 3 3 * 3)이므로 충분하다.
참가자들의 점수 배열에 관해서는 만들어줄 필요가 없기 때문에
if (index == tokens.length - 1)로 종료조건을 설정하면 된다.
이 if문 안에서 완전히 조합된 Key(변수명 prefix)에 해당하는 List에 점수를 넣으면 된다.
forEachKey의 안쪽에서 재귀를 두 번 들어가는 이유는 '-' 관해서도 만들어야 하기 때문이다.
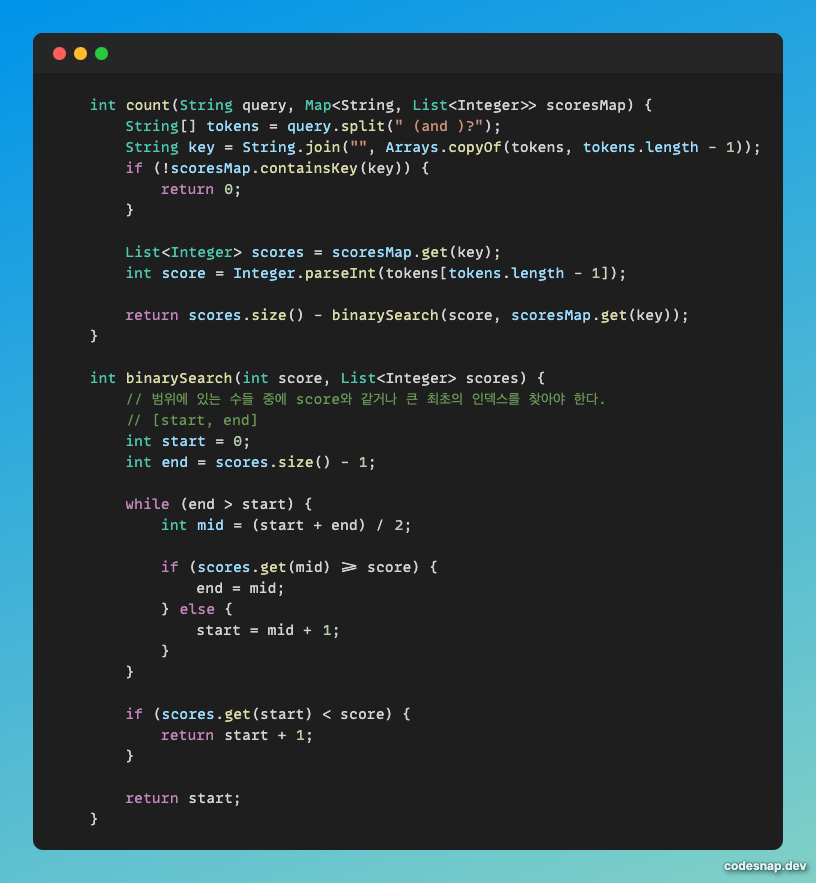
데이터 전처리가 끝났기 때문에 답을 구하면 된다. query 배열도 전처리가 필요하다.
위에서 구한 scoresMap의 key에 맞는 형식으로 바꿔야 한다.
그래서 query 배열에서 하나의 원소를 집어 넣고 파싱을 한다.
split(" (and )?")는 정규표현식을 활용해 파싱한 것이다.
공백 하나 + 'and '가 0개 또는 1개 일때를 기준으로 split하는 것이다.
이러한 정규표현식으로 split을 하면 마지막에 점수에 관해서 따로 처리하지 않아도 된다.
하지만 정규표현식을 잘 모르면 마지막 점수 부분만 잘 파싱하면 상관 없다.
그 후 tokens 배열을 String.join에 넣어 완전한 key를 만든다.
scoresMap.containsKey(key)로 해당 key에 관한 List가 존재하는지 확인한다.
만일 없다면 검색조건이 없는 것이므로 0을 반환하면 된다.
존재한다면 Key에 관한 List를 반환한다.
그리고 List에서 찾고자하는 값(score)보다 크거나 같은 최초의 인덱스를 찾으면 된다.
여기서 파라메트릭 서치로 lower bound를 찾으면 된다.
파라메트릭 서치부분은 모두가 잘 이해하고 있을거라 생각해서 넘어가겠다.
count의 return은 List의 크기 - lower bound이다.
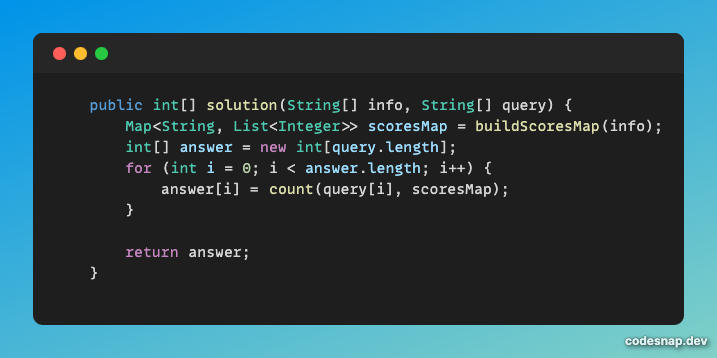
마지막 solution 메서드이다. for문에서 answer의 인덱스 별로 답을 넣고 있는 것만 확인하면 된다.
조합이 필요한 문제는 거의 Map을 이용할 때 깔끔하게 풀리는 경우가 많다.
조합에 관한 문제에서 풀이가 잘 안떠오르면 Map을 떠올려보자.
