Transaction Isolation level
1. Dirty Read
다음의 상황을 생각해보자.
데이터베이스에 x=10, y=20이 저장되어있다.
트랜잭션1과 트랜잭션2는 동시에 작업을 진행하고 있다.
트랜잭션1은 x+y를 x에 저장하는 명령을 수행한다.
트랜잭션2는 y의 값을 70으로 변경하는 명령을 수행한다.
- 트랜잭션1이 먼저 x의 값을 읽었다. 이때 x의 값은 10이다.
- 이때 트랜잭션2가 y의 값을 70으로 바꿨다.
- 트랜잭션1이 바뀐 y의 값을 읽어온 후 x에 더하는 명령을 수행하여 x의 값이 80이 되었다. 그리고 커밋을 하였다.
- 트랜잭션2가 롤백을 수행하였다. y의 값은 20으로 롤백되었다.
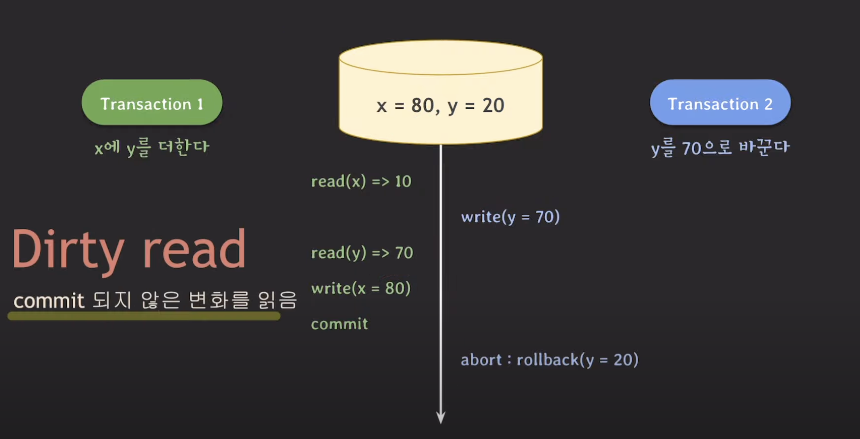
원래 트랜잭션1에 의해 x의 값은 30이 되어야 한다.
하지만 트랜잭션2에 의해 변경된 y값인 70을 읽었다. 그리고 x에 더했다.
데이터의 정합성이 깨진 이 상황은 unrecoverable하다.
이러한 문제가 발생한 이유는 트랜잭션1이 커밋되지 않은 데이터를 읽었기 때문이다.
이렇게 커밋되지 않은 데이터를 읽은 것을 Dirty Read라고 한다.
2. Non-Repeatable Read
다음의 상황을 생각해보자.
데이터베이스에 x=50이 저장되어 있다.
트랜잭션1은 x의 값을 두 번 읽는 명령을 수행한다.
트랜잭션2는 x에 40을 더하는 명령을 수행한다.
- 트랜잭션1이 x의 값을 읽어온다. 이때 x의 값은 50이다.
- 동시에 트랜잭션2가 x에 40을 더하기 위해 값을 읽어왔다. 이때 x는 10이다.
- 트랜잭션2는 읽어온 데이터에 40을 더하였고 커밋하였다.
- 트랜잭션1이 커밋된 x의 데이터를 읽어왔다. 이때 값은 50이다.
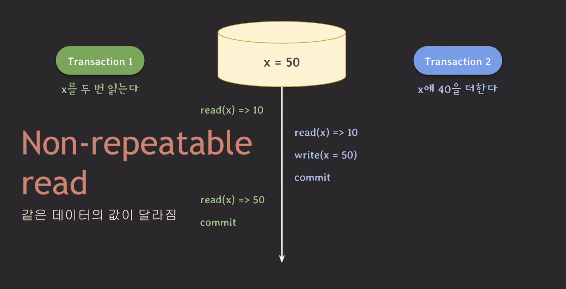
그런데 곰곰이 생각해보면 이 상황은 ACID 원칙중 Isolation에 어긋난다.
Isolation은 여러 트랜잭션이 동시에 작업을 수행하더라도
마치 하나의 트랜잭션만이 작업을 진행하는 것처럼 만들어야 한다.
하지만, 트랜잭션1에서 읽어온 x의 값은 서로 다르다.
이러한 현상을 Non-Repeatable Read라고 말한다.
3. Phantom Read
이번에도 아래의 상황을 생각해보자.
튜플인 t1과 t2가 있고 v라는 컬럼을 가지고 있다.
t1의 v값은 10, t2의 v값은 50이다.
트랜잭션1은 v가 10인 데이터를 두 번 읽는 명령을 수행한다.
트랜잭션2는 t2의 v값을 10으로 바꾼다.
- 트랜잭션1이 v가 10인 값을 찾아서 읽는다. 이때 데이터는 t1이 읽힌다.
- 트랜잭션2가 t2의 v를 10으로 바꾼다. 그리고 커밋을 한다.
- 트랜잭션1이 다시 v가 10인 값을 찾아서 읽는다.
이때, 읽히는 튜플은 t1, t2가 된다. 그리고 커밋한다.
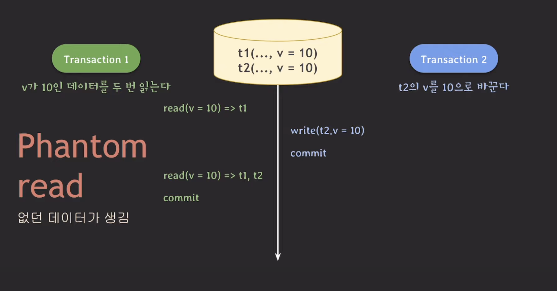
만일 t2가 v=10인 튜플을 하나 더 생성하는 명령을 수행한다고 해보자.
이때는 트랜잭션1이 조회하는 데이터는 3개가 됐을 것이다.
이 상황은 Isolation의 관점에서는 이상하다.
트랜잭션 내에서 조회 조건에 의해 처음 데이터를 찾았을 때, 하나의 튜플만 읽혔다.
하지만, 다시 똑같은 조회 명령을 수행하니 조회되는 튜플이 2개가 됐다.
이렇게 하나의 트랜잭션 내에서 똑같은 조건으로 조회를 했을 때
없던 데이터가 갑자기 생기는 것을 Phantom Read라고 한다.
문제점과 해결방법
위와 같이 Isolation 정의에 어긋나는 현상이 일어나는 건 바람직하지 않다.
따라서 위의 문제가 일어나지 않도록 조절을 해야한다.
하지만 이런 현상들이 모두 발생하지 않게 만들면
제약사항이 많아져서 동시 처리 가능한 트랜잭션의 수가 줄어든다.
결국 DB의 전체적인 처리량(Throughput)이 하락하게 된다.
따라서 일부 이상 현상은 허용하도록 몇 가지 레벨을 만들어서
사용자가 필요에 따라 적절하게 선택할 수 있도록 하였다.
Isolation Level
Isolation Level은 3개의 이상현상
1. Dirty Read, 2. Non-Repeatable Read, 3. Phantom Read
중 몇 개를 허용하냐에 따라 구분된다.
1. Read Uncommitted
3개의 이상현상을 모두 허용하는 레벨이다.
모두 허용하는 대신, 동시성처리가 높아 처리량(Throughput)이 높다.
2. Read Committed
이름의 뜻 대로 커밋된 데이터만 읽는 것을 허용한 것이다.
즉, Dirty Read 문제가 발생하지 않는다.
하지만 그 외의 Non-Repeatable Read, Phantom Read는 허용한다.
3. Repeatable Read
Dirty Read, Non-Repeatable Read 문제가 발생하지 않는다.
하지만 Phantom Read는 허용한다.
4. Serializable
Dirty Read, Non-Repeatable Read, Phantom Read 문제가 모두 발생하지 않는다.
그리고 사실상 이 레벨은 위의 세가지 현상뿐만 아니라
그 외 이상 현상 자체가 발생하지 않는 레벨을 의미한다.
아래는 Isolation Level을 정리한 표이다.

이 표를 통해 Isolation Level의 특징을 정리하면,
레벨이 엄격해질수록 허용하지 않는 현상들이 늘어난다.
따라서 애플리케이션 설계자는
level을 조절하여 전체 처리량(Throughput)과 데이터 일관성 사이의 트레이드 오프를 해야한다.
하지만 위의 Isolation level은 추가적인 이상현상을
반영하지 못해 비판을 받았다고 한다.
아래의 추가적인 이상현상들에 관해 알아보자.
추가적인 이상현상들
1) Dirty Write
다음의 상황을 생각해보자.
데이터베이스에 x=0이 저장되어있다.
트랜잭션1은 x의 값을 10으로 바꾸는 명령을 수행한다.
트랜잭션2는 x의 값을 100으로 바꾸는 명령을 수행한다.
- 트랜잭션1이 x의 값을 10으로 바꿨다. 이때 x의 값은 10이다.
- 트랜잭션2가 x의 값을 100으로 바꿨다. 이때 x의 값은 100이다.
- 트랜잭션1이 롤백(abort)을 했다. x의 값은 100인데,
트랜잭션1이 시작되기 이전의 x의 값은 0이다.
그래서 트랜잭션2가 작업한 내용을 되돌리기 싫어 x=100인 상태로 뒀다고 해보자.- 트랜잭션2가 롤백(abort)를 했다고 하자.
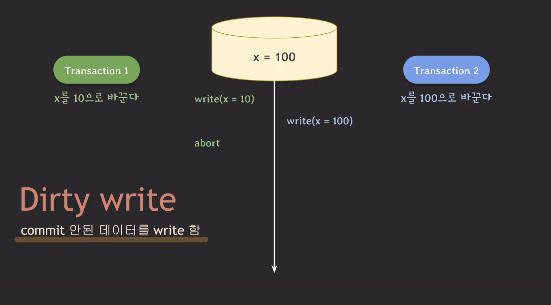
트랜잭션2가 롤백했기 때문에, x의 값은 100이 되기 전의 값인 10이 되어야 한다.
하지만 10도 abort 된 값이므로 x는 10이 되어서는 안된다.
이러한 현상을 Dirty Write라고 한다.
Dirty Write는 커밋이 안된 데이터를 write했기 때문에 발생한다.
롤백을 할때 정상적인 데이터 recovery가 중요하다.
따라서 모든 Isolation level에서는 Dirty Write를 허용하면 안된다.
2) Lost Update
다음의 상황을 생각해보자.
데이터베이스에 x=50이 저장되어있다.
트랜잭션1은 x에 50을 더하는 작업을 한다.
트랜잭션2는 x에 150을 더하는 작업을 한다.
- 트랜잭션1이 먼저 x의 값을 읽는다. 이때 x는 50이다.
- 트랜잭션2가 그 다음 동시에 x의 값을 읽는다. 이때 x는 50이다.
- 트랜잭션2가 x에 150을 더해서 x=200으로 업데이트하고 커밋한다.
- 트랜잭션1이 읽은 x값 50에 50을 더한다. 따라서 x는 100이 된다. 그리고 커밋한다.
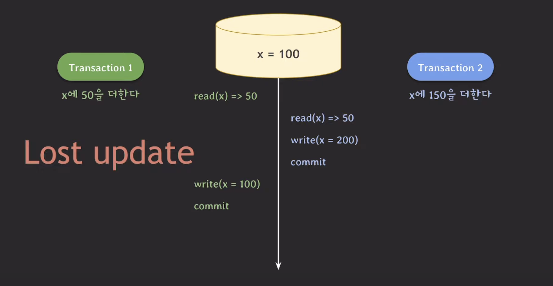
위 상황에서 트랜잭션2의 작업 내용은 트랜잭션1에 의해 모두 사라졌다.
만일, 트랜잭션1과 2가 순차적(serial)으로 실행되었다면, x의 값은 250이 되었을 것이다.
즉, 트랜잭션2의 작업 내용이 보존됐을 것이다.
이와 같이 현상을 Lost update라고 부른다. 이 현상은 특히 위험하다.
만일 계좌이체에서 이런 현상이 발생한다면, 큰 문제로 이어진다.
3) 확장된 Dirty Read
일반적으로 발생하는 Dirty Read 상황 말고
확장된 개념의 Dirty Read가 발생할 수 있다.
아래의 상황을 생각해보자.
데이터베이스에 x=50, y=50란 값이 있다.
트랜잭션1은 x에서 40을 빼서 y에 더하는 작업을 한다.
트랜잭션2는 x와 y의 데이터를 읽는 작업을 한다.
- 트랜잭션1이 x에서 값을 읽고 40을 뺀다. 이때 x의 값은 10이 된다.
- 트랜잭션2가 x의 값을 읽고 y의 값을 읽고 트랜잭션을 종료한다.
이때 x의 값은 10, y의 값은 50이 조회된다.- 트랜잭션1은 y의 값을 읽고 40을 더한다.
이때 y의 값은 90이 된다. 그 후 커밋하고 트랜잭션을 종료한다.

위의 예시는 확장된 Dirty Read의 결과를 얘기한다.
트랜잭션2에서 읽은 x와 y의 값은 최종 커밋된 x와 y값과는 다르다.
즉, 커밋되지 않은 x와 y의 값을 읽었기 때문에 최종 결과와 다른 데이터를 읽게 된 것이다.
이것 또한 Dirty Read로 개념을 확장해서 보는 것이다.
4) Read Skew
3번과 똑같은 상황에서 아래의 작업을 한다고 생각해보자.
- 트랜잭션2가 x의 값을 읽었다. 이때 x의 값은 50이다.
- 트랜잭션1이 x의 값을 읽고 40을 뺐다. 이때 x의 값은 10이 된다.
- 그리고 y의 값을 읽어 40을 더했다. 이때 y의 값은 90이 된다.
그리고 커밋하여 트랜잭션1을 종료한다.- 트랜잭션2가 y의 값을 읽는다. 이때 y의 값은 90이다.
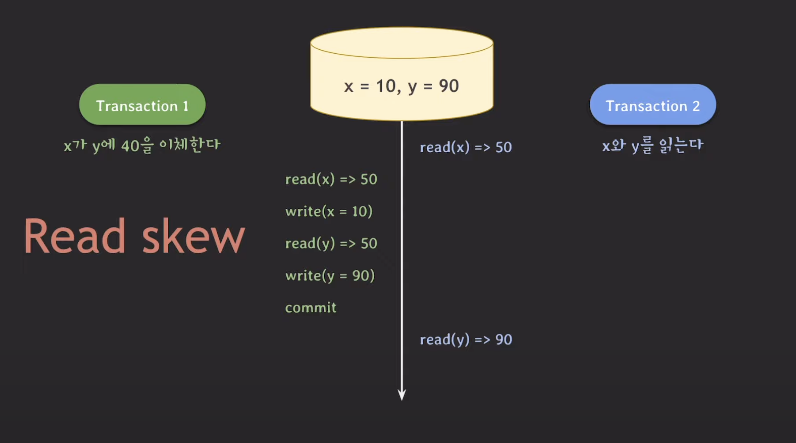
위의 상황에서 데이터베이스에서 x, y의 합은 100이지만,
트랜잭션2 내에서 읽은 x와 y의 합은 140이 된다.
이 상황은 Non-Repeatable Read와 비슷한 상황이다.
이러한 현상을 Read Skew라고 한다. 즉, 불일치하는 데이터를 읽은 것이다.
5) Write Skew
아래의 상황을 생각해보자.
데이터베이스에 x=50, y=50이 저장되어 있다.
이때 x+y는 0이상이라는 조건이 붙어있다.
트랜잭션1은 x에서 80을 빼는 작업을 한다.
트랜잭션2는 y에서 90을 빼는 작업을 한다.
- 트랜잭션1이 x의 값을 읽는다.
이때, x에서 80을 빼기 전에 x+y가 0이상인지 체크하기 위해
y의 값을 읽은 후 x와 더해서 조건을 체크한다.- 이때 트랜잭션2도 작업을 진행한다. 트랜잭션1과 같은 방식으로 조건을 체크한다.
- 조건을 만족했기 때문에, 트랜잭션1이 x에서 80을 뺀다. x의 값은 -30이 된다.
- 트랜잭션2도 마찬가지로 y에서 90을 뺀다. y의 값은 -40이 된다.
- 트랜잭션1,2 모두 커밋을 한다.
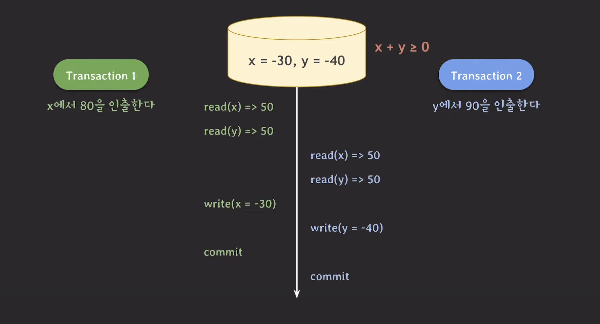
최종 반영된 데이터는 x+y가 0이상인 조건을 위반하고 있다.
만일 DBMS가 Serialize하게 동작했다면,
트랜잭션이 조건을 위반했을 때 Abort 했을 것이다.
위와 같은 현상을 Write Skew라고 부른다.
데이터 불일치를 유발하는 쓰기 작업을 말한다.
6) 확장된 Phantom Read
아래의 상황을 생각해보자.
데이터베이스에 t1이란 튜플이 있고 v=7인 컬럼이 있다.
cnt는 v>10인 튜플의 개수이다. 현재 cnt=0이다.
따라서 현재 데이터베이스에는 v>10인 튜플이 없는 것이다.
트랜잭션1은 v>10 데이터를 읽고 cnt를 읽는 작업을 한다.
트랜잭션2는 v=15인 튜플 t2를 추가하고 cnt를 1 증가하는 작업을 한다.
- 트랜잭션1이 v>10인 튜플을 읽는다. 하지만 없기 때문에 아무 결과도 나타나지 않는다.
- 트랜잭션2가 v=15인 튜플을 추가한다.
- 트랜잭션2가 cnt를 읽는다. cnt는 1로 읽힌다. 그리고 커밋하고 종료한다.
- 트랜잭션1이 cnt를 읽는다. 이때 값은 1이다. 그리고 커밋하고 종료한다.
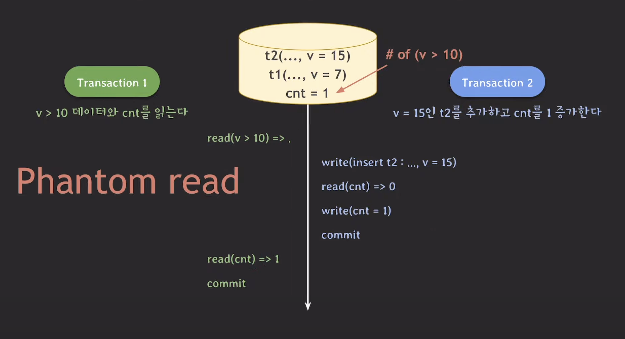
위에서 트랜잭션1이 처음 v>10인 데이터를 읽으려 했을 때
아무런 데이터도 읽지 못했지만 나중에 cnt 데이터를 읽으니 1이 있었다.
같은 데이터를 읽은 것이 아니라도 서로 연관된 데이터를 읽었을 때
갑자기 없던 데이터가 생긴 것도 Phantom Read로 봐야 한다는 것이다.
Snapshot Isolation
기존의 표준에서 정의한 Isolation level이 아니라
Concurrency Control이 어떻게 동작하는지
구현을 바탕으로 Isolation level을 정의한 것이다.
기존의 Isolation Level은 이상현상들을 기준으로 정의했지만,
Snapshot Isolation은 Concurrency Control의 동작에 따라 구분했다.
예를 들어 아래의 상황을 생각해보자.
데이터베이스에 x=50, y=50이 있다.
트랜잭션1은 X에서 40을 빼고 y에 더하는 작업을 한다.
트랜잭션2는 y에 100을 더하는 작업을 한다.
Snapshot은 특정시점에서의 형상을 의미한다.
여기서 특정시점은 트랜잭션이 시작하는 시점을 기준으로 한다.
따라서 트랜잭션에서 일어나는 작업은 데이터베이스에 기록하는 것이 아니라
트랜잭션이 끝날 때까지 만들어 놓은 스냅샷에 기록해서 관리한다.
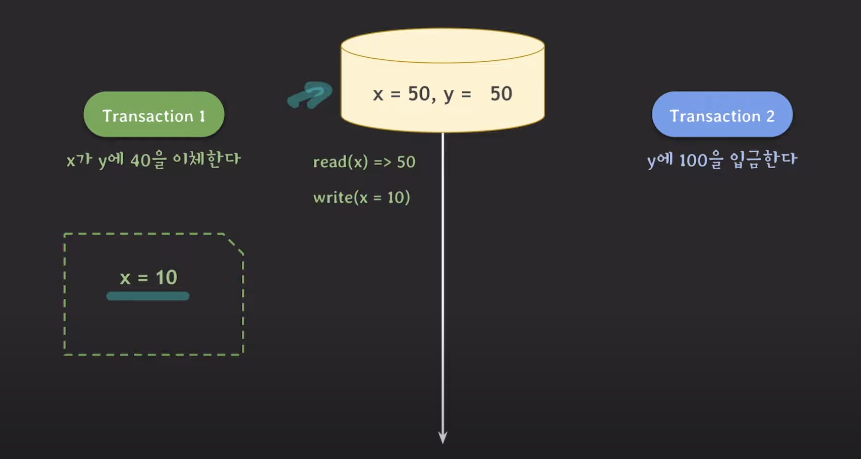
트랜잭션1이 트랜잭션을 시작하는 시점에 x=50, y=50이었다.
이때 데이터베이스에 바로 기록되는 것이 아니라 스냅샷에 저장된다.
따라서 스냅샷으로부터 x는 50을 읽고 x에서 40을 빼서 x를 10으로 만든다.
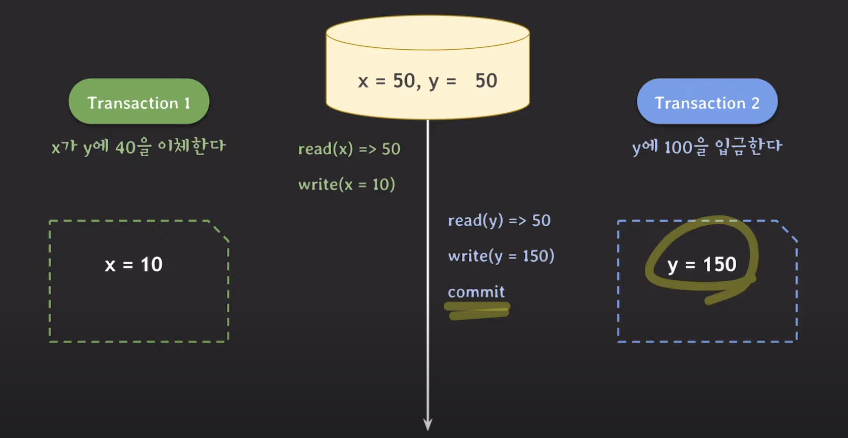
트랜잭션2가 그 다음에 트랜잭션을 시작한다.
이때 데이터베이스의 x=50, y=50이다. 이 시점을 기준으로 스냅샷을 만든다.
y에 100을 더하는 작업을 하면 스냅샷의 y값이 150이 된다.
그리고 커밋을 하면 스냅샷의 값이 데이터베이스에 반영된다. 데이터베이스의 y값은 150이 된다.
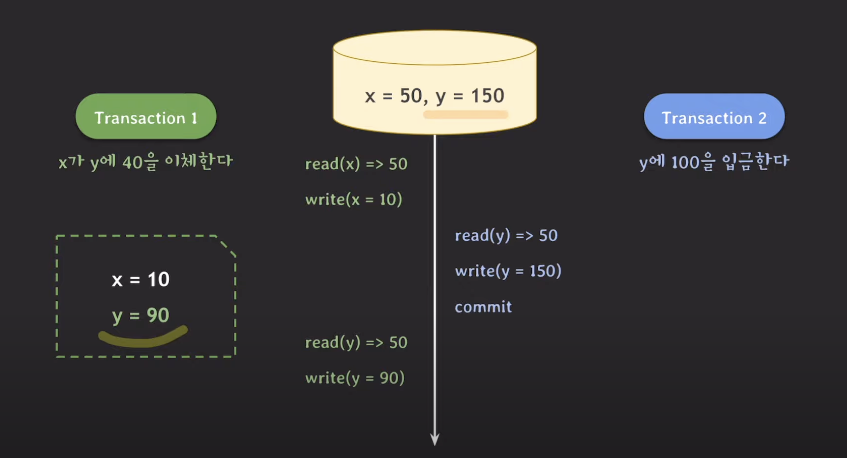
다시 트랜잭션1에서 y값을 읽는다. 이때 읽는 y는 데이터베이스에 저장된 150이 아니라
트랜잭션이 시작될 때 만들어졌던 스냅샷에 기록된 y의 값인 50이다.
여기에 40을 더하는 작업을 해서 스냅샷에 y값이 90이 된다. 그리고 트랜잭션1이 커밋을 한다.
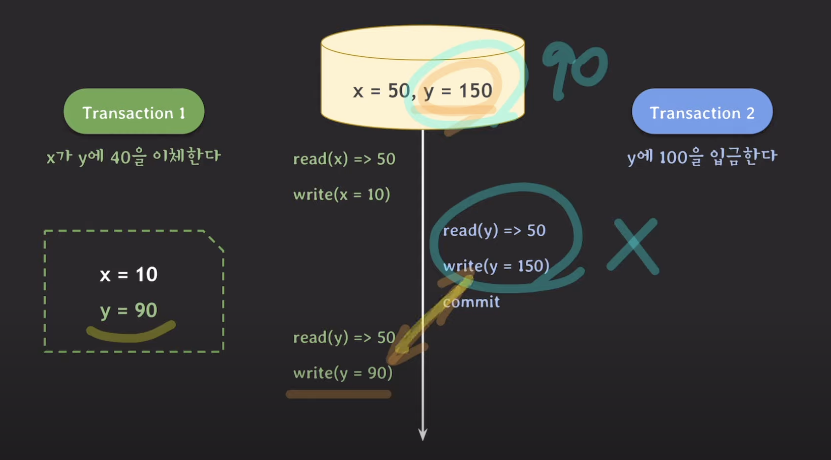
여기서 y의 값이 충돌하는 것을 볼 수 있다.
같은 데이터인 y에 관해 두 트랜잭션이 write를 했기 때문이다.(write conflict)
만일 트랜잭션1의 데이터를 반영하게 되면 lost update가 발생해서
트랜잭션2가 작업한 데이터가 사라지게 된다.
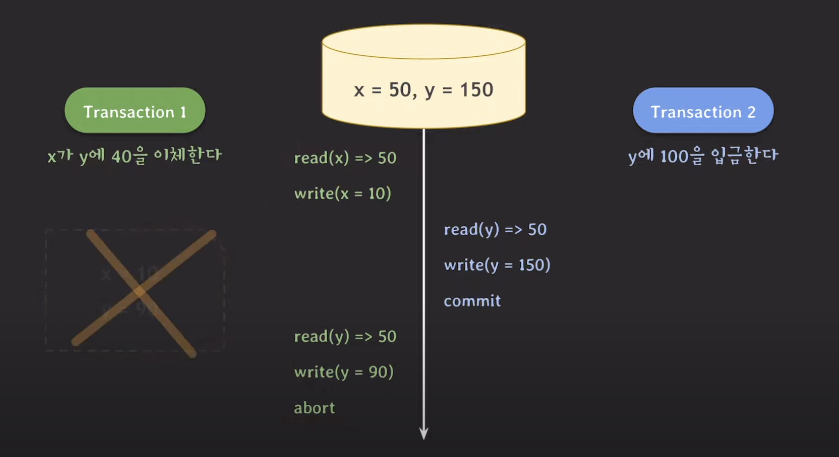
하지만 스냅샷 아이솔레이션은 같은 데이터에 관해 Write를 할 때,
먼저 커밋된 트랜잭션만 반영한다.
즉, 여기서는 트랜잭션2의 작업만 반영되는 것이다. 따라서 트랜잭션1은 Abort된다.
이것이 Snapshot isolation이다.
Snapshot isolation은 MVCC(Multi Version Concurency Control)의 한 종류이다.
출처
