스레드 풀(thread pool)
Thread Per Request Model
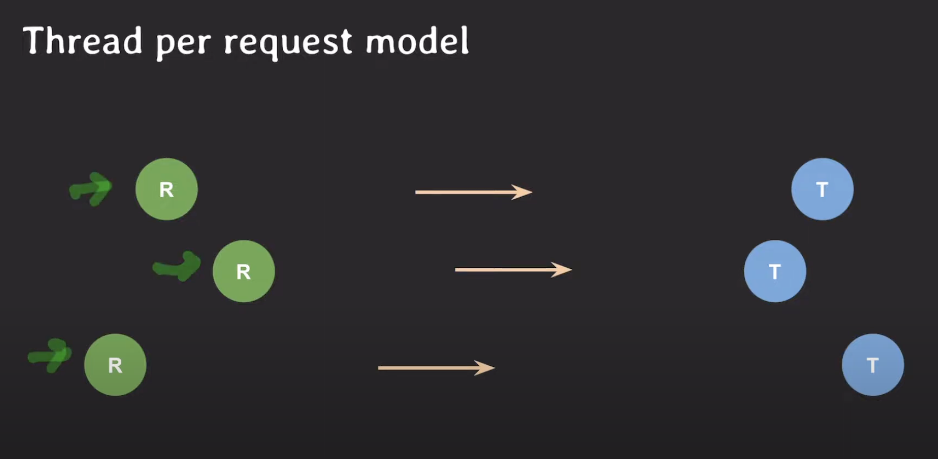
서버 API에 요청들이 들어왔을 때 요청을 처리하는 여러 방법 중 하나이다.
요청마다 스레드를 하나씩 할당해서 하나의 요청을 하나의 스레드가 처리하도록 하는 모델이다.
즉, 요청과 스레드가 1:1 맵핑되는 것이다.
만약 Thread Per Request Model이 서버에 들어오는 요청마다
스레드를 새로 만들어서 처리하고 처리가 끝난 스레드는 버리는 식으로 동작한다면?
- 스레드 생성에 소요되는 시간 때문에 요청 처리가 더 오래 걸리는 문제가 발생한다.
그리고 서버의 처리 속도보다 더 빠르게 요청이 늘어나는 상황이 발생하면
-
스레드 수가 증가하고 컨텍스트 스위칭이 자주 발생해 CPU 오버헤드가 증가한다.
결과적으로 어느 순간 서버 전체가 응답 불가능한 상태에 빠진다. -
스레드가 계속 생성되고 메모리가 점점 고갈되는 문제가 발생한다.
Thread Pool
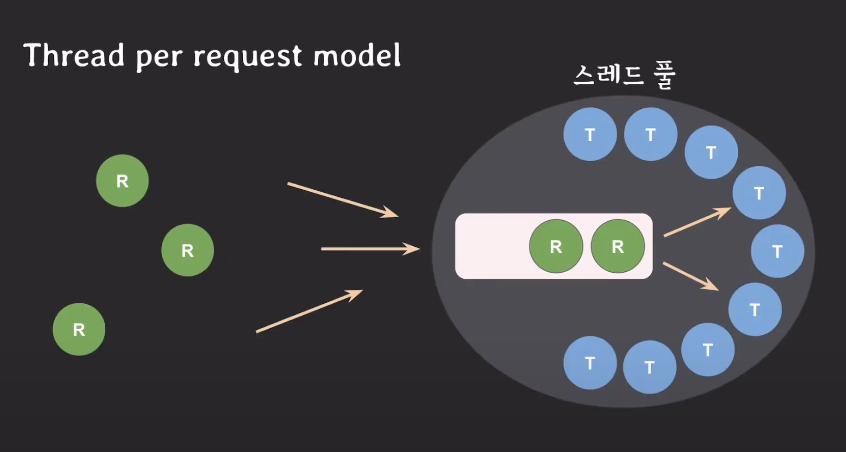
T는 스레드이고 R은 요청이다.
스레드 풀은 제한된 개수만큼 스레드를 미리 만들어 놓는다.
외부에서 요청들(R)이 들어오게 되면 서버에서 관리하는 큐(Queue)에 요청이 쌓인다.
큐에 있는 요청들은 스레드 풀에서 일하지 않는 스레드에 할당되어 요청을 처리한다.
일을 끝마친 스레드는 스레드 풀로 돌아온 후 새로운 요청을 기다린다.
이렇게 스레드를 요청마다 새로 생성하는 것이 아니라
재사용하는 방식이 스레드 풀이다.
스레드 풀의 장점은 아래와 같다.
1) 스레드 생성 시간을 절약
2) 스레드가 무제한으로 생성되는 것을 방지(제한된 개수)
3) 메모리 절약
Thread Pool을 사용하는 경우
스레드 풀을 사용하는 경우는 여러 작업을 동시에 처리해야할 때이다.
즉, task를 subtask로 나눠서 동시에 처리하는 경우나
순서에 상관없이 동시에 실행 가능한 task를 처리할 때 사용한다.
Thread Pool 사용팁
-
스레드 풀에 몇 개의 스레드를 만들어 두는게 적절한가?
CPU의 코어 개수와 task의 성향에 따라 다르다.
만일 CPU-bound task라면 코어 개수만큼 혹은 그보다 몇 개 더 많은 정도로 설정하는 것을 추천
만일 I/O-bound task라면 코어 개수보다 1.5 ~ 3배 사이에서 경험적으로 찾는 것을 추천 -
스레드 풀에서 실행될 task 개수에 제한이 없다면?
스레드 풀의 큐 사이즈 제한이 있는지 확인해야 한다
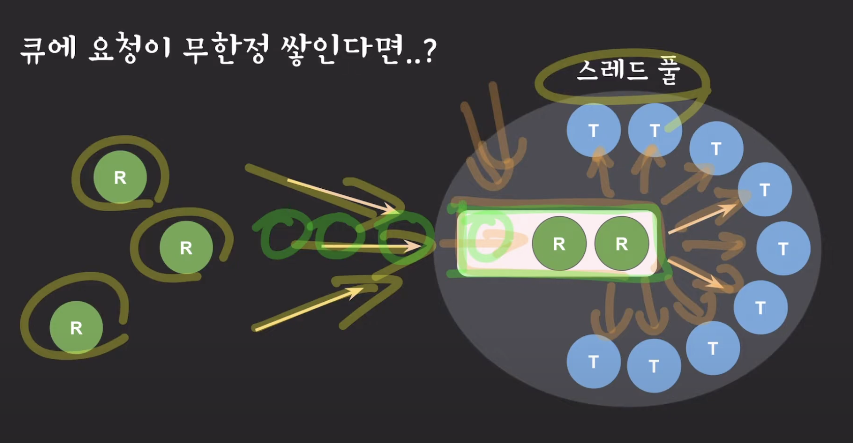
만일 위와 같이 스레드 풀의 모든 스레드가 요청을 처리하고 있는데,
스레드 풀의 큐에 요청이 계속해서 쌓이게 되면
나중에 메모리를 고갈시킬 수 있는 위험요인이 된다.
따라서 큐 사이즈의 제한이 있는지 확인하고 제한을 둬야만 한다.
추후 들어오는 요청은 받지말고 버려서 전체 시스템을 보호해야 한다.
pool 개념이 사용되는 곳
- Connection Pool
: TCP connection을 맺을 때, 시간이 걸리기 때문에,
미리 연결을 만들어 놓는 것 - Process Pool
: 프로세스를 미리 여러 개 만들어 놓는 것
출처
