Problem
Given the head of a sorted linked list, delete all nodes that have duplicate numbers, leaving only distinct numbers from the original list. Return the linked list sorted as well.
Example
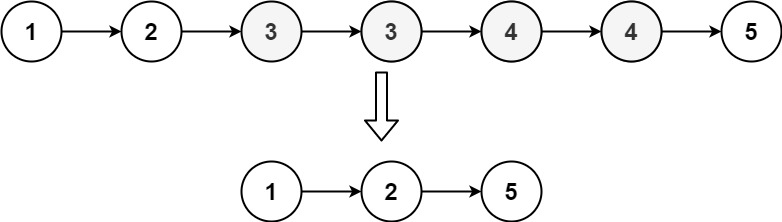
Input: head = [1,2,3,3,4,4,5]
Output: [1,2,5]Approach
- Foremost, we remove the head in case it has an duplicate (For example,
[1, 1, 1, 2, 3, 4]). - We remove the internal duplicates inside the list.
For this process, I first check whether the head.val and head.next.val are equivalent, determining if step number 1 must be processed. Here, I simply reallocated the head to the nodes coming after the duplicates.
During the second step, I created two nodes prev and curr, each keeping track of duplicates. In the case of a duplicate (checked through curr), I followed a similar process where I take out the entire section covered by curr.
Solution Code
def deleteDuplicates(self, head):
if head == None: return head
if head.next == None: return head
## duplicate -> remove
while head and head.next != None and head.val == head.next.val:
while head and head.next != None and head.val == head.next.val:
head = head.next
head = head.next
if head == None: return head
if head.next == None: return head
prev = head
curr = head.next
while curr:
#print(head)
if curr.next and curr.val == curr.next.val:
while curr.next and curr.val == curr.next.val:
curr = curr.next
prev.next = curr.next
curr = prev.next
else:
prev = prev.next
curr = curr.next
return head
될때까지 모든 걸 다시 한번