Object detection
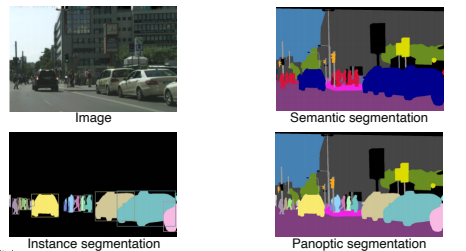
- 지금까지의 기술은 영상을 인식하고 semantic segmentation까지 할 수 있었다.
- 여기서 더 advance된 기법은 자동차들 중에 같은 종류의 자동차가 있는지와 같은 인스턴스 구분이 가능해진 Instance segmentation과 panoptic segmentation이 있다.
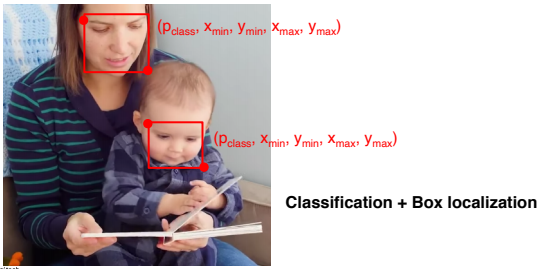
- Object detection은 classification과 bounding box를 동시에 추정하는 문제
- 특정 객체들을 바운딩 박스 형태로 위치를 측정하고 해당 박스 안의 객체의 category까지 측정하는 기술
- 이렇게 찾은 위치 정보와 category 정보는 특히 자율 주행과 같은 곳에 사용되며, 산업 가치가 크기 때문에 주목 받는 기술이다.
- 글자를 인식하는 OCR의 경우에도 복잡한 배경 속에서 글자 위치를 특정해야하기 때문에 object detection이 사용된다.
two-stage detector
-
과거에는 영상의 경계선을 특징으로 잘 모델링을 하여 알고리즘을 설계하거나, selective serach와 같은 bounding box를 제안해주는 방법을 사용하였다.
-
image classification이 큰 성공을 이룬 이후 그 방법을 object detection에 적용한 R-CNN 모델이 나타났다.
One-stage detector
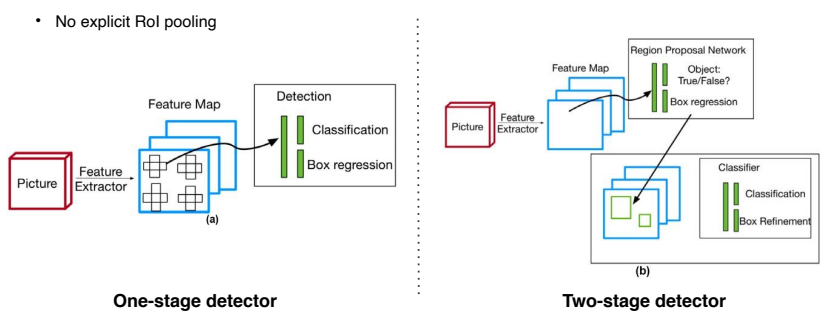
- 정확도를 조금 포기를 하는 대신 속도를 확보하여 실시간 객체 탐지를 목표로 한다.
- region proposal을 기반으로 하는 ROI pooling을 사용하지 않고, 곧바로 box regression과 classfication을 하기 때문에 구조가 간단하고 빠른 실행 시간을 보여준다.
You only look once(YOLO)
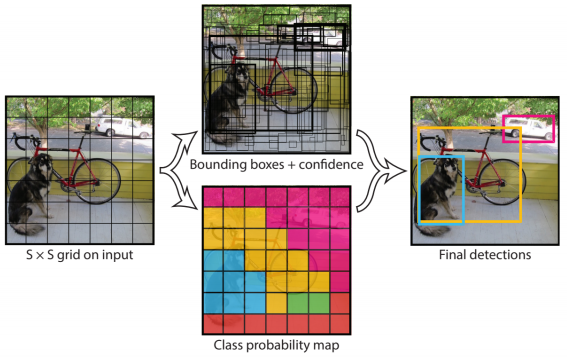
- input image를 s x s grid로 나누어 B개의 box 즉, 4개의 좌표와 confidence score를 예측하고, 이에 따른 class score를 따로 예측한다.
- 이전에 봤던 anchor box와 유사한데, 미리 각 위치의 bounding box의 형태로 B개의 box를 정해놓고, 이에 대해 regression을 해주는 부분도 포함되어 있다.
- 최종 결과는 이전과 마찬가지로 NMS 알고리즘으로 통해 나타난 bounding box만을 출력한다.
- faster rcnn에서 사용했던 방식과 동일하게 ground truth와 매치된 box를 positive로 간주하고 학습 레이블을 positive로 걸어준다
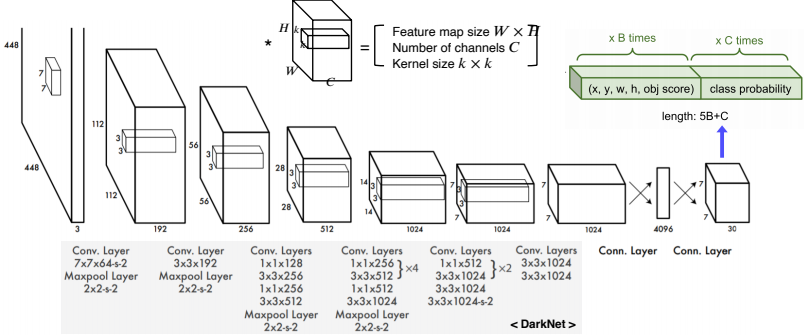
- 일반 CNN의 구조와 동일하며 간단한 구조이다.
- 여기서는 2개의 anchor box를 생성하고, 20개의 class를 분류하기 때문에 최종적으로 총 30개의 channel을 가진다.
- 맨처음 s x s 로 grid를 나눈다고 하였는데 여기서의 s 는 7로 마지막 convolution layer의 해상도로 s가 결정이 된다.
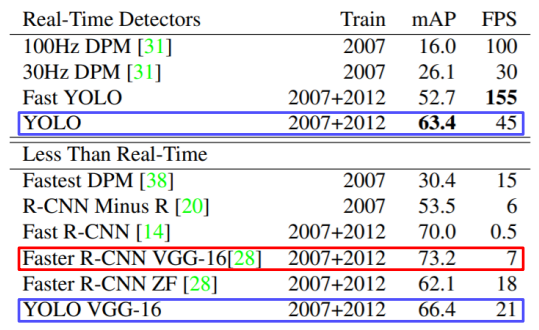
- faster rcnn보다 정확도는 낮지만 속도가 훨씬 빠른 것을 볼 수 있다.
Single Shot MultiBox Detector (SSD)
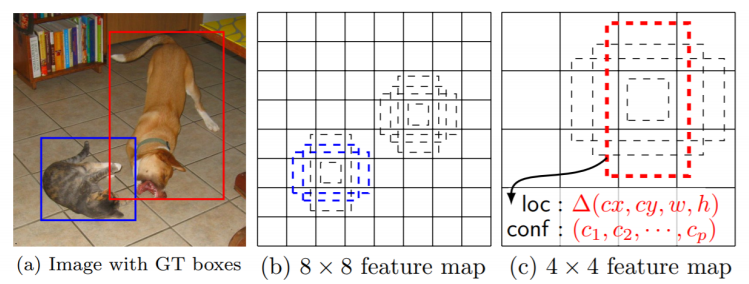
- SSD는 multi scale object를 더 잘 처리하기 위해 중간 교차맵을 각 해상도의 적절한 bounding box들을 출력할 수 있게 만들었다.
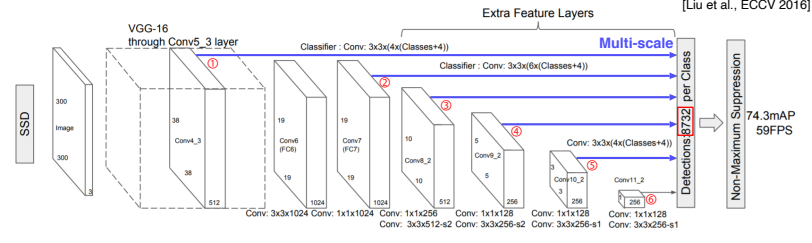
- VGG를 Backbone으로 각 layer별로 object detection 결과가 바로 출력으로 나타나며, 이를 통해 여러 개의 feature map에 따라 다양한 bounding box shape들을 고려할 수 있게 되었다.
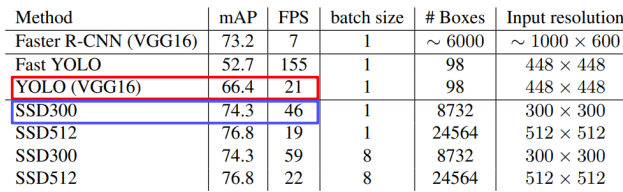
- 결과적으로 YOLO보다 높은 성능과 속도를 보이며, 심지어 Faster R-CNN보다도 성능이 높은 것을 볼 수 있다.
Two-stage detector vs One-stage detector
- single stage 방법들은 ROI pooling이 없으니 모든 영역에 대해 loss가 계산되고 일정 gradient가 발생한다.
- 일반적인 영상은 배경이 더 넓고 실제 객체는 일부분만을 차지하고 있기에, positive sample은 엄청나게 적은 반면 배경에서 오는 부분들은 유용한 정보도 없으면서 엄청나게 많은 개수로 classifier imblance를 야기한다.
- 이러한 문제를 해결하기 위해 Focal loss가 제안된다.
Focal loss
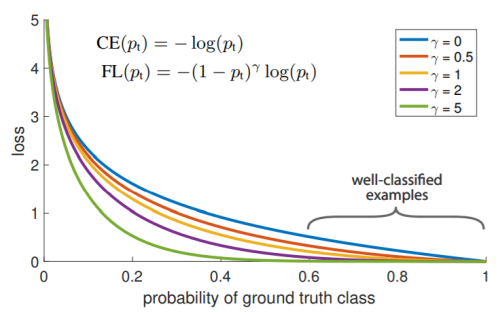
- CrossEntropy의 확장이라고 볼 수 있으며, 앞에 확률term을 붙여서 잘 맞춘 애들은 더 loss를 낮게 만들고, 반대로 맞추지 못하면 더 sharp 한 loss를 주게 된다.
- 감마에 따라 값이 확확 바뀌는데, 감마가 클수록 굉장히 샤프하게 나타난다.
RetinaNet
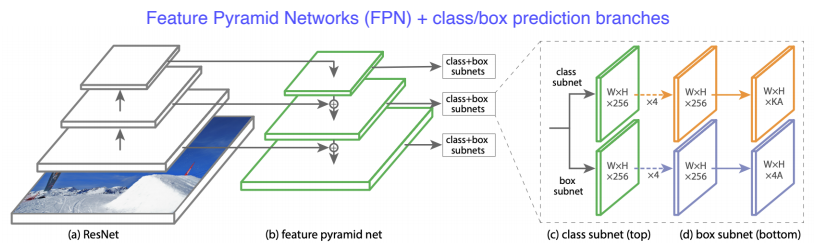
- Focal loss와 같은 논문에서는 FPN이라는 아키텍처도 제안한다.
- U-net과 매우 유사한 구조로 low level의 특징과 high level의 특징을 잘 활용하여 각 scale별로 물체를 찾기 위한 multi scale 구조로 되어있다.
- 이 두 특징을 concat하는 것이 아닌 더하기로 융합되며, class head와 box head가 따로 구성이 되어서 이 둘을 dense하게 쌓았다.
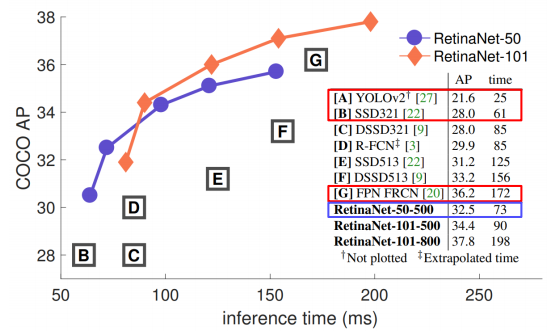
- 결과적으로 SSD보다 높은 성능과 속도를 보였다.
Detection with Transformer
-
최근에 NLP에서 큰 성공을 거둔 transformer를 어떻게 하면 CV에 적용해서 또 다른 성공 사례를 발생시킬 수 있을까?
-
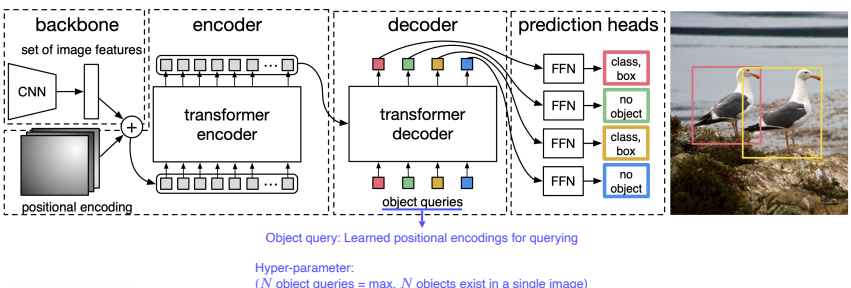
DETR
- transfomer를 object detection에 적용한 사례
- CNN의 feature와 각 위치에 multi dimension으로 표현한 encoding을 쌍으로 하여 입력 토큰을 만들어 준다.
- 이후 encoder에서 추출된 특징들을 decoder에 넣어 object queries를 생성하고, 이를 이용해 컴퓨터에 질문하여 해당 위치에 물체가 있는지를 나타낼 수 있다.