Translating an image given “condition”

-
sketch된 영상을 실제 사진과 같은 이미지로 변환해주는 과정을 생각해보자
-
어떻게 보면 언어가 다를 때 번역하는 것과 같아서 서로 다른 두 도메인을 translation한다는 task이다.
-
이 때 하나의 정보가 주어졌기 때문에, 이것을 condition되었다 또는 조건이 주어졌다고 한다.
-
이 조건에 해당하는 결과가 나오는 형태를 conditional generative model이라 한다.
- generative model은 일반적으로 확률분포를 모델링하는 기법이기 때문에, 확률표현을 빌려와서 sketch가 주어진 상태에서 X인 이미지가 나올 확률로 표현할 수 있다.
- 이렇게 확률 분포를 모델링이 되면 여기서 샘플링을 할 수 있으므로, 어떠한 sketch가 주어지면 아마도 이런 sample이 나올 것이다 라는 것을 알 수 있을 것이다.
-
Generative Model vs Conditional generative model

- Generative Model
- 기본적인 generate model은 단순히 영상이나 샘플을 생성할 수는 있지만, 이를 조작하여 생성할 수는 없었다.
- Conditional generative model
- 생성이 더 유용하게 쓰이기 위해서는 어떤 형태로든 사용자의 의도가 반영되어야 한다.
Conditional generative model 예시
- audio super resolution
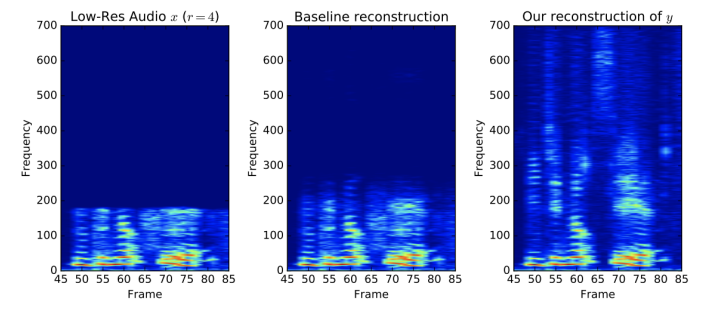
- 저퀄리티의 audio를 고퀄리티의 audio로 높여주는 모델도 conditional generative model의 예시이다.
- P(high resolution audio | low resolution audio)
- machine translation
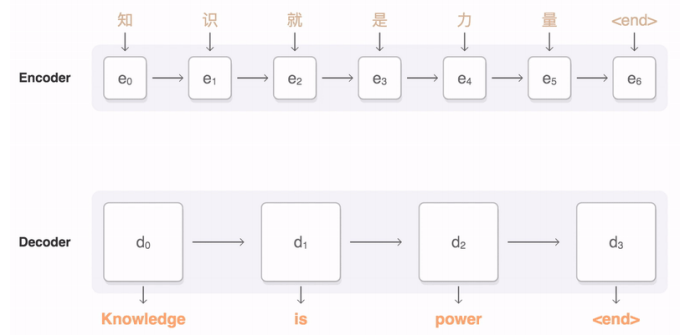
- 한자로 주어진 중국어를 영어 문장으로 번역하는 대표적인 conditional generative model이다
- P(English sentence | Chinese sentence)
- article generation with the title

- title만 주어져 있을때 나머지 글을 생성해봐라 하는 것도 conditional generative model 중 하나이다.
GAN
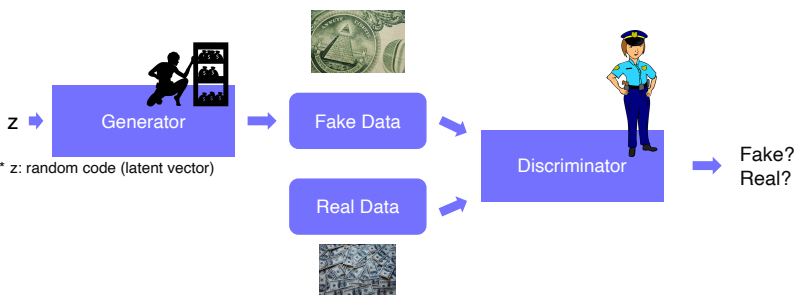
- 이전에 배웠던 대표적인 생성모델을 회상하면 GAN이 생각날 것이다.
- 위조지폐범과 경찰과의 관계로 예를 많이 드는데, 생성자인 위조지폐범이 위조지폐를 만들고, 경찰인 discriminator가 지폐의 진위여부를 판단하는 판별자 역할을 한다.
- 이를 학습하게 되면 위조지폐범은 경찰이 지폐를 진짜라고 판별하게끔 학습하고, 반대로 경찰은 위조지폐를 더 잘 찾아내게끔 학습이 되어 서로 상호작용을 통해 생성자와 판별자 모두 성능이 좋아지게 된다. 이를 적대적 학습 방법이라 한다.
GAN vs Conditional generative model
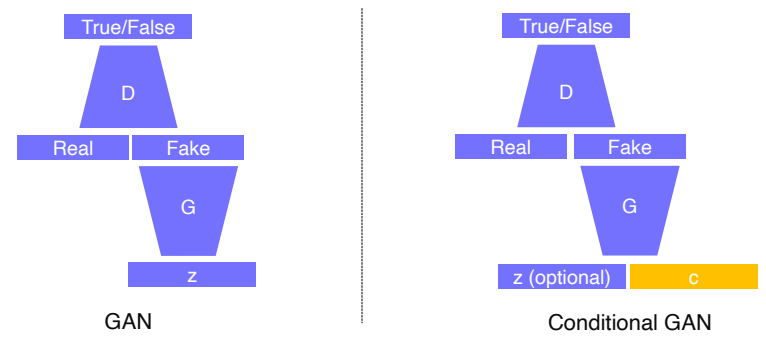
- conditional generative model의 학습 과정은 condition 정보를 제공하기 위해 c라는 conditional input을 넣어주는 것만 다르고 나머지는 GAN과 동일하다
Image-to-Image translation

- 이미지가 들어오면 그 이미지를 다른 스타일의 이미지로 변환할 수 있다.
- 이것을 게임에 응용하면 같은 장면을 다양한 테마로 나타낼 수 있다.
Example : Super resolution

- conditonal Gan을 잘 이해하기 위해 Super resolution이라는 예제 문제를 풀어보겠다.
- 저해상도 이미지가 입력되면 고해상도 이미지로 출력하는 문제
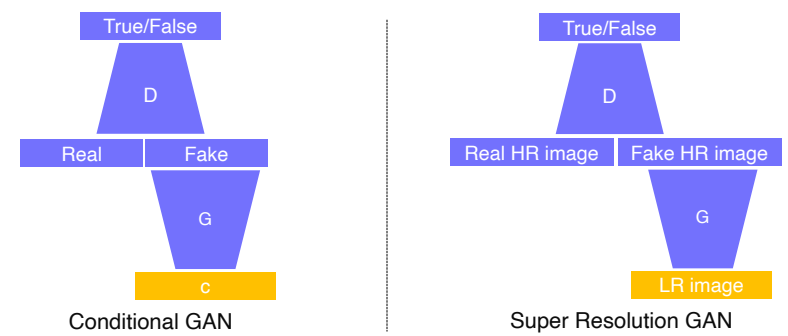
- 구조를 살펴보면 입력 컨디션이 주어지는 GAN에서 real data로는 고해상도 이미지를 주어서 판별기가 현재 주어진 생성 영상이 실제 고해상도 영상과 비슷한 통계적 특성을 갖는지를 따지는 형태로 이루어져 있다.
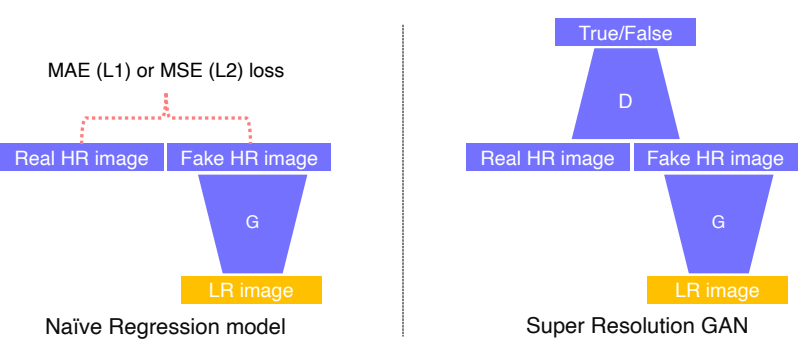
- 이전에는 CNN 구조를 활용해서 단순한 L1(MAE), L2(MSE) loss를 사용해서 학습을 시켰었다.
- 이러한 모델을 regression model이라 한다.
-
MAE : GT가 주어졌을때 생성된 영상과의 오차 절대값의 평균,
-
MSE : GT가 주어졌을때 생성된 영상과의 오차의 제곱합의 평균,
-
이렇게 regression model을 사용하면 해상도는 높아지는 것 같지만, 굉장히 blurry한 이미지를 얻게 된다.
-
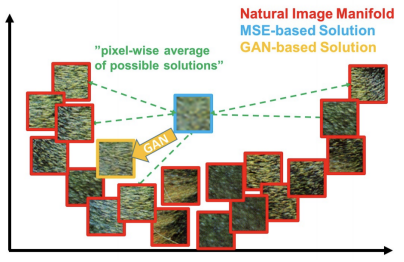
픽셀 자체의 intensity 차이를 이용하기 때문에 평균 error를 구하다 보니 출력 결과와 비슷한 error를 가지는 많은 patch들이 존재하게 된다. 그래서 구분성이 떨어지게 된다.
- 위의 그림과 같이 실제 이미지의 분포가 U처럼 생겼을때, MAE와 MSE를 사용하여 생성하면 모든 결과를 만족시키기 위해 중간지점인 어정쩡한 이미지가 정답이 되어버리게 된다.
-
하지만, GAN을 이용하면 판별자가 그동안 보았던 real data와 구분을 못하게 하는 것만이 목적이므로 real data와 가장 비슷한 이미지쪽으로 생성하면 되기 때문에 blurry한 이미지가 생성될 확률이 상대적으로 적어지게 된다.
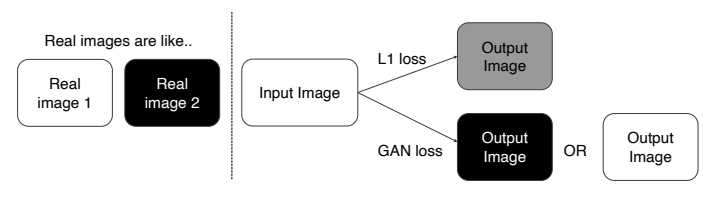
- 조금 더 잘 이해하기 위해 입력 영상이 흰색과 검은색으로 이루어진 경우를 생각해보자
- 이 경우에 L1, L2 loss를 사용하면 그 중간값인 회색이 나타난다.
- 하지만 GAN Loss를 사용하면 discriminator가 회색 이미지는 본적이 없는데? 와 같이 거짓 이미지를 바로 판별하게 되므로 회색은 출력하지 않게 되고, 흰색 또는 검은색을 출력하게 된다.
Image Translation Gans

- 한 이미지 스타일을 다른 이미지 스타일로 변환하는 것을 의미한다.
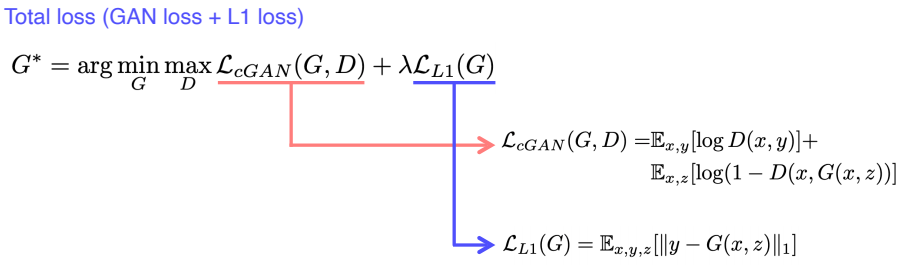
Pix2Pix
- CNN 구조를 이용해서 학습 기반으로 연구해서 2017년 처음 나타난 것이 Pix2Pix이다.

-
GAN Loss는 입력된 x와 y를 직접 비교하지 않고 독립적으로 real과 fake만을 판별하기 때문에 입력이 뭐가 들어와도 GT인 y와 비교하지 않으므로 Gan loss만 사용해서는 y와 비슷한 이미지를 생성할 수 없다.
-
따라서, MAE loss가 blurry한 이미지를 만들 수 있지만, 적당한 가이드로는 쓸 수 있다고 판단하여 사용하고, 여기에 GAN Loss를 더해서 조금 더 현실적인 이미지를 만들 수 있게 하였다.
-
또한, GAN만으로 학습하는 것이 굉장히 불안전하고 어려웠었는데 blurry한 L1 Loss를 추가함으로 가이드라인을 제시하여 조금 더 안정적인 학습이 이루어질 수 있게 하였다.
-
여기서 이전의 GAN loss와의 차이점은 Generative 모델에 z만 들어가는 것이 아닌 x도 함께 들어간다.
CycleGAN
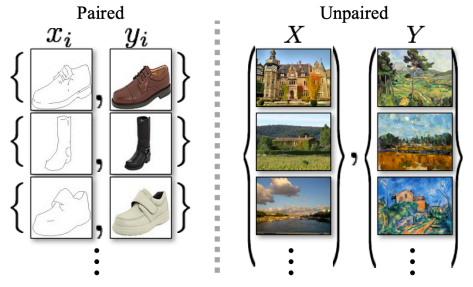
- 지금까지 살펴본 Pix2Pix는 supervised learning으로 x와 y가 있는 pairwise data가 필요했었다.
- 하지만 실제로는 이러한 pairwise data를 얻는 것은 어렵기 때문에, 어떻게 하면 대응관계 없이 활용할 수 있을까 해서 나타난 것이 CycleGan이다.

- Cycle Gan은 도메인 간의 직접적인 1:1 대응관계가 존재하지 않는 data set의 집합들만으로 translation이 가능케 하는 방법을 제시한다.
CycleGAN Loss
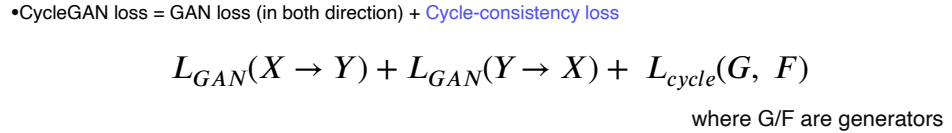
-
CycleGan Loss는 기존의 Gan loss와 같이 G,D가 존재하지만, Cycle-consistency loss가 추가되었다.
-
,
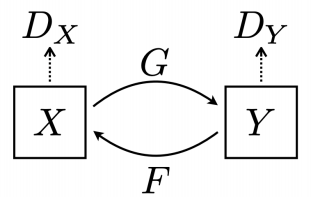
-
GAN loss에 방향성이 존재하는데, X에서 Y로 가는 방향과 Y에서 X로 가는 방향 동시에 학습을 진행한다.
-
하지만 GAN loss만 사용하게 되면 Mode Collapse 문제가 발생한다.
💡 Mode Collapse -
Discriminator가 특정한 output하나만 출력했을 때 굉장히 낮은loss를 갖게 되는 형태가 생긴다.
-
그렇게 되면 Generator는 자신이 잘 생성하고 있다고 판단하고 아무런 학습이 되지 않는다. Generator와 Discriminator 반대의 경우도 마찬가지!
-
따라서, input에 상관없이 하나의 output만 계속 출력되는 문제가 발생한다!
-
-
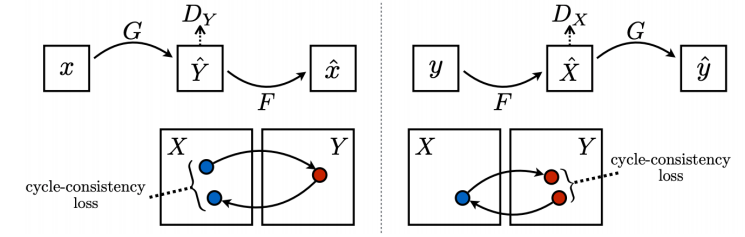
- Mode Collapse 문제를 해결하기 위해 이미지 안의 style 뿐만 아니라 contents를 유지해야 한다는 것을 강조하기 위해 생긴 Loss
- 즉, 원본 이미지와 translation한 이미지를 거쳐 다시 복원한 이미지가 동일해야 한다는 의미를 가지는 Loss
-
이처럼 Cycle Gan은 X라는 style의 dataset와 Y라는 style의 dataset만이 주어졌을 때 이 두 dataset의 translation 관계를 학습할 수 있는 획기적인 방법이다.
Perceptual loss
-
일반적으로 Conditional Gan을 사용하는 이유는 regression을 사용한 결과보다 훨씬 더 선명하고 퀄리티가 좋기에 사용한다.
-
하지만, GAN은 generator와 discriminator를 반복하여 학습해야 하기 때문에 학습하기 어렵다는 문제가 있다.
-
이렇게 high quality output을 출력하는 다른 학습 방법은 없을까?? 해서 나온 것이 Perceptual loss이다.
-
Gan loss
- 튜닝이 조금 더 필요하기에 상대적으로 학습하기 어렵다
- 대신 어떠한 pretrained network가 필요하지 않기 때문에, 다양한 application없이 데이터만 주어지면 활용이 가능하다는 장점이 있다. → 학습과정 중에 G,D가 알아서 균형을 맞춘다.
-
Perceptual loss
- 심플한 forward와 backward로 이루어져 있어 학습하기 쉽고 편하다.
- 대신에 pretrained network를 사용해야 한다는 단점이 있다.

- perceptual loss가 발전되는 기원을 살펴보면, pretrained image classification 모델의 filter 형태가 사람의 visual perception과 굉장히 유사하다는 것을 볼 수 있었다.
- pretrained model의 early layer filter를 살펴보면 위의 그림과 같이 방향성과 색을 나타내는 filter를 볼 수 있었다.
- 이를 이용하여 이미지를 우리 사람과 비슷한 시각으로 바라볼 수 있게 변환할 수 있다는 아이디어로부터 시작되었다.
perceptual loss 학습 방법
-
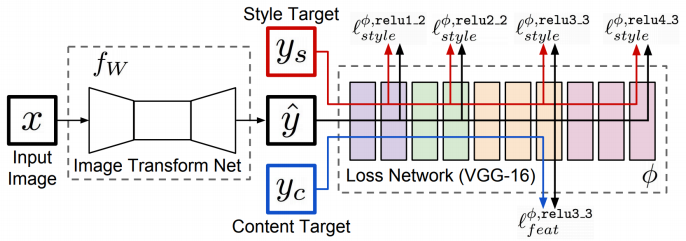
Image transform network
- input 이미지가 주어지면 단 하나의 원하는 스타일로 변환할 수 있는 네트워크
- style은 데이터에 따라 달라진다.
-
Loss Network
- 우리가 학습될 loss를 측정하기 위해 pretrained model(VGG)을 사용한다
- 우선 pretrained model에서 feature를 뽑고 이를 style target과 content target을 이용하여 loss를 측정한다.
- 학습하는 동안 pretrained model은 fix되어서 update되지 않으며, 오로지 생성한 y_hat만을 업데이트하기 위해 loss가 학습된다.
-
이제 Loss를 측정하는 부분을 조금 더 자세히 보자
-
위에서 input X로 부터 y_hat을 생성해냈는데 이 생성된 y_hat이 우리 의도대로 transform 되기 위해 VGG를 사용하여 feature를 뽑게 되고 loss를 측정하여 transform을 하려는 function(x)를 학습하게 된다.
-
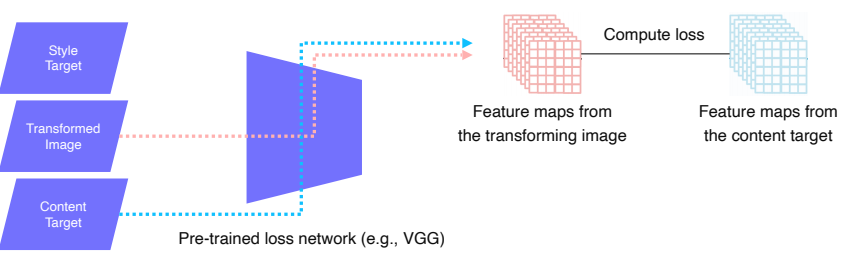
Feature reconstruction loss
- transform 된 이미지가 content를 유지하고 있는지를 판단하는 loss e.g.) 강아지가 input이면 output에서도 강아지가 남아있게 유지하는 loss
- 원본 이미지 X를 VGG에 넣어 feature map을 생성하고, y_hat인 transform된 이미지도 VGG에 넣어 feature map을 생성한다.
- 이후 이 두 feature map을 비교해서 loss를 측정한다.
- transform 된 이미지가 content를 유지하고 있는지를 판단하는 loss e.g.) 강아지가 input이면 output에서도 강아지가 남아있게 유지하는 loss
-
Style reconstruction loss
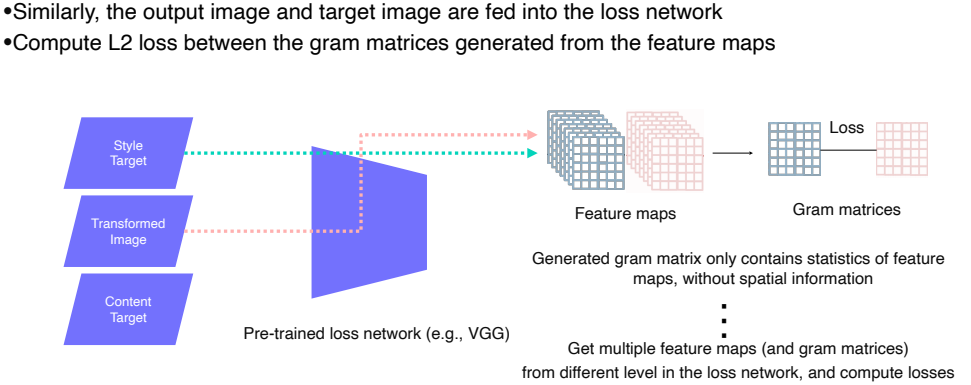
- 우리가 원하는 style이 유지되게 하는 loss
- 우리가 변환하고 싶어하는 style 이미지를 input으로 넣는다.
- 이후 이 이미지와 transform된 이미지를 VGG에 넣어 feature map을 생성한다.
- 여기서는 그대로 feature map의 loss를 비교하는 것이 아니라 style이라는 것을 담기 위해 이를 디자인 한다.
-
feature map의 공간적인 특징들을 통계적으로 담기 위해 디자인 한 것
-
영상의 공간에 따른 각각의 스타일이 다른지를 보고 싶은 것이 아닌 영상의 전체적인 스타일을 보고 싶은 것이기 때문에 각 feature map의 공간적인 특징을 제거한다.
-
이는 Pooling을 통해 제거할 수 있다.
1. 각 feature map을 C x H x W로 reshape한다.
2. 이들을 각각 자신의 전치행렬을 곱해주게 되면 C x C 행렬이 나타난다.
- 각 채널은 사람의 눈, 코, 입과 같은 서로 다른 특징들을 담고 있다.
- 이 채널들을 C x C로 나타냄으로써 각각의 특징 별 상관관계를 확인할 수 있다.
3. 이렇게 생성된 두 C x C 행렬을 비교하여 loss를 측정한다.
- transform을 적용한 이미지 특징의 C x C를 우리가 원하는 style 특징의 C x C와 닮게 학습함으로써 원하는 style과 비슷하게 출력하는 것이 가능해졌다.
이 외에도 style reconstruction loss를 사용하지 않고 feature reconstruction loss만을 사용해서 L2 loss대신 사용하기도 한다.
- supervised resolution과 같이 style은 변하지 않고 content는 유지하되 perceptron quality를 향상시킬때 사용
Various GAN applications
- Deepfake

-
존재하지 않는 사람의 얼굴을 high quality로 생성해 낼 수 있을 뿐만 아니라, 비디오에 적용하여 애니메이션에 맞게 목소리까지 낼 수 있는 강력한 기술이다.
- 이를 악용하면 거짓 대통령 연설을 생성할 수 있고 이는 사회적 불안을 초래할 수도 있다.
-
그래서 이런 안 좋은 영향들을 방지하기 위해 윤리적인 부분을 고려하여 어떻게 하면 디펜스 매커니즘을 만들 수 있을지에 대한 연구가 계속되고 있다.
-
이를 통해 GAN은 오남용이 충분히 될 수 있음으로 항상 주의해서 사용해야 한다는 교훈을 얻을 수 있었다.
-
Face de-identification
-
사람의 프라이버시를 보호해주는 것과 같은 선한 영향력을 줄 수도 있다.

-
사람의 얼굴을 약간씩 변형하여 실제로 이 사람이 누군지 인식하지 못하게 할 수 있다.
-
-
face anonymization with passcode
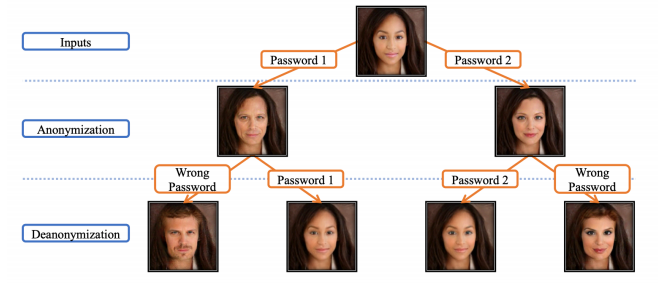
- passcode에 따라 다른 얼굴이 나오게 되고, 결국 제대로 된 passcode를 입력해야만 제대로 된 이미지를 얻을 수 있다.
