OCR
-
Optical Character Recognition
-
사람이 글자를 읽을 때
- 먼저 글자를 찾고
- 찾을 글자를 인식한다.
-
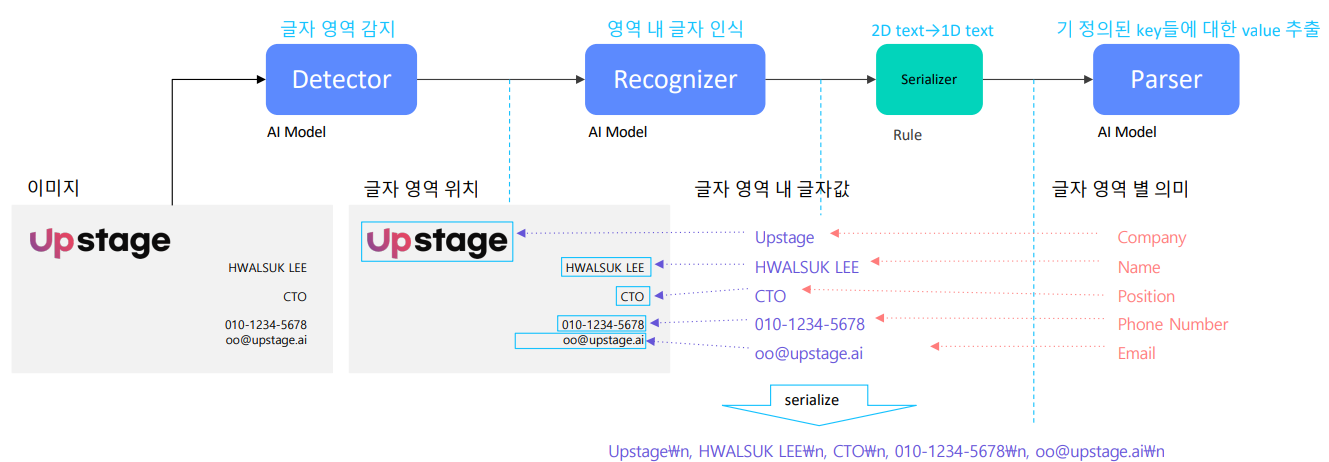
따라서, OCR도 글자를 찾는 모듈과 글자를 인식하는 모듈로 이루어져 있다.
-
글자를 읽는다 = 글자 영역 찾기 + 영역 내 글자 인식 = OCR

- Offline Handwriting
- 이미지를 입력하고 글자값 출력
- Online Handwriting
- 좌표 시퀀스를 입력하고 글자값 출력
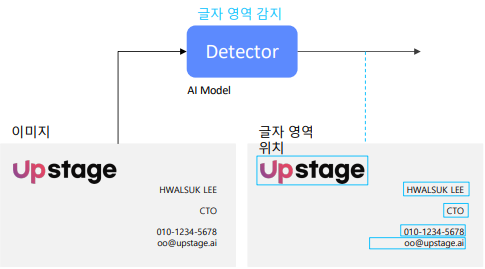
Text Detector
-
단일 객체 검출
- 이미지에 하나의 객체가 있는데, 이 객체가 어떤 class에 속하는지, 또 어떤 위치에 있는지를 예측하는 task
-
다중 객체 검출
- 이미지 내 여러 객체에 대해 각 개체가 어떤 class에 속하는지, 또 어떤 위치에 있는지를 예측하는 task
-
글자 영역 검출
-
이를 객체 검출에 비유하면 글자 영역 다수 객체 검출이 된다.
-
이는 단순히 글자 영역이냐 아니냐의 여부이기 때문에 단일 class 문제이며, 여러 글자 영역에 대해서 예측하는 task이다.
-
일반 객체 검출과의 차이점
-
글자의 특성 상 영역 표시를 할 때 가로 세로의 비율이 굉장히 다르다.

-
또한, 글자이기 때문에 일반 객체 검출보다 밀집도가 상당히 크다.

-
-
Text Recognizer
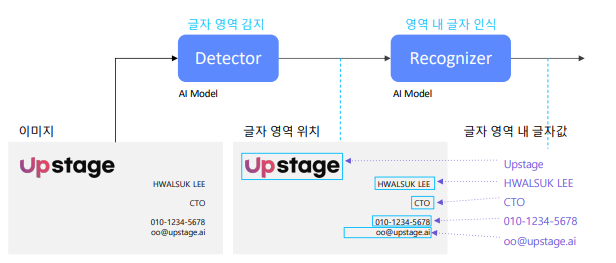
- 글자 인식기
- 하나의 글자 영역 이미지 입력에 해당 영역 글자 열이 출력인 모델
- 글자 영역 별로 입력을 받아서 글자가 무엇인지 알아낸다.
- 검출기는 이미지 전체가 입력이었지만, 인식기는 이미지 전체가 아닌 글자 영역 별로 이미지를 자른 부분이 입력이다.
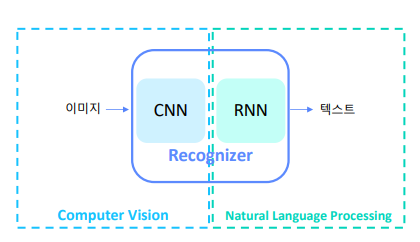
- 글자 인식기는 Computer vision 기술과 Natural language processing의 교집합의 영역이다.
- 입력은 이미지이지만, 출력이 글자이기 때문에 이 두 영역이 복합적으로 쓰인다.
- 따라서, 모델 구조 앞쪽에는 이미지를 다루는 모델 구조로 이루어져 있으며, 뒤쪽은 NLP에서 다루는 모델 구조를 많이 사용한다.
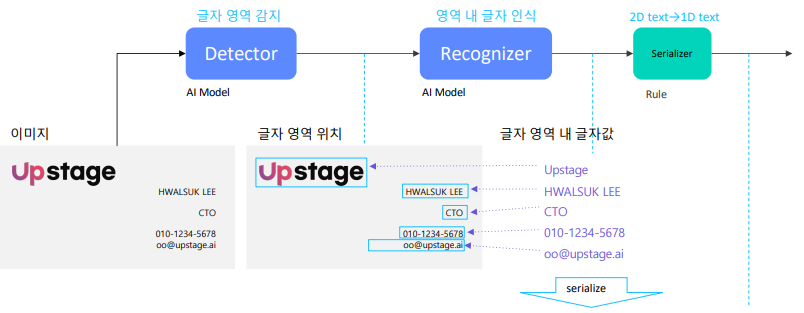
Serializer
-
글자 인식기에서 나타난 결과는 어느 위치에 어느 글자가 있다는 정보만을 가지고 있다.
-
이를 글자로 출력하기 위해서는 일렬로 정렬해주어 시퀀스한 형태로 만들어주어야 하는데, 이 역할을 Serializer가 한다.
-
이 부분은 AI로 구현하지 않고 일일히 rule을 생각해서 구현한다.
- 기본적인 Rule base : 사람이 읽는 순서대로 정렬한다.
- Grouping : 단락끼리 묶음
- 단락 간 정렬
- 단락 내 정렬 : 좌상단에서 우하단으로
- 기본적인 Rule base : 사람이 읽는 순서대로 정렬한다.
-
이렇게 하는 이유는 뒤에 자연어 처리 모듈을 붙이기 위해서 이다.
- 이로 인해 ‘이미지가 들어왔을때 여기에 금칙어가 포함되어있다’ 와 같은 판단을 하는 것과 같은 다양한 시나리오를 가능하게 한다.
- 금칙어 처리, 요약, 글자 의미 파악 등
Text parser
-
마지막으로 자연어 처리 모듈을 붙이는데 이 때 쓰이는 상업적으로 많이 쓰는 자연어 처리 module은 key들에 대한 value를 추출하는 것이다.
-
이미 정보들이 정의되어 있고, 이 중 표현하고 싶은 정보가 뭔지 key를 이용해 추출한다.
-
명함 이미지에서 뽑고 싶은 정보는 사람의 이름, 연락처, 이메일 등의 정보를 추출하고 싶을 것이고, 이를 AI가 자동으로 뽑아준다.
-
Parser 의 동작
-
BIO 태깅을 활용하여 개체명을 인식
- 문장에서 기 정의된 개체에 대한 값 추출
- 이미 정의된 개체에 대해 이에 해당하는 것이 무엇인지를 추출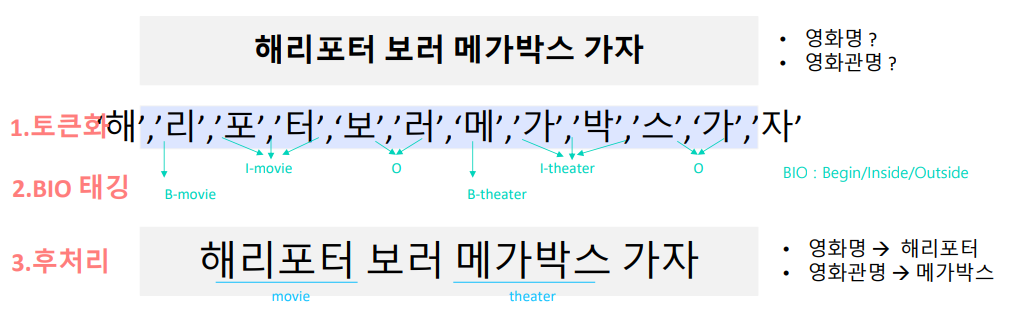
-
- 글자 단위로 쪼개어, BIO 태깅할 아이템들을 만든다.
- Begin/Inside/Outside(BIO) 태깅을 진행
- 후처리
- Process of Parser : BIO - tagging

- 다음과 같은 영수증 이미지를 OCR을 통해 각 글자와 위치를 추출한다.
- OCR의 결과를 Serialization을 통해 일렬로 정렬한다.
- 글자 영역 별로 BIO 태깅을 추론하여 나타낸다.
- 이를 후처리를 하면 영수증에 대한 key, value를 추출할 수 있다.
OCR Services
-
Copy & Paste
- 이미지 안에 있는 글자를 복사하고 붙여넣는 기능을 수행
- 모르는 다른 언어를 입력할 수 있다.
- 다량의 글자를 입력하기에 편리하다.
-
Search
- 글자를 추출한 후 이를 검색에 활용할 수 있다.
- 미리 이미지를 OCR을 돌려놓으면 해당 단어를 검색하면 이미지도 결과로 나타난다.
-
Matching
- 음악 플레이 리스트를 옮기기 유용하다.
-
금칙어 처리
- 광고성/혐오성 이미지를 제거할 수 있다.
-
번역
- 외국어가 담긴 이미지를 찍으면 외국어를 typing할 수 있고, 이를 번역기에 넣으면 번역까지 할 수 있다.
-
Key-value extractor
- 위의 NLP모듈을 붙여 사용하는 것 중에서도 Key-value를 뽑는 목적이 상업적으로 많이 이용된다
- 신용카드
- 핸드폰으로 카드를 찍으면 자동으로 카드 번호와 유효기간이 자동으로 입력된다.
- 신분증
- 카드와 마찬가지로 신분증의 정보를 자동으로 입력해주며, 유효성 검사까지 수행한다.
- 수기 입력 대체
- 사업자 등록증, 영수증 등 수기로 입력해야 할 것들을 자동으로 입력할 수 있다.
