TIL 5/12
오늘은 알고리즘, SQL 2문제씩 풀었다.
SQL 첫 문제는
동물 보호소에 들어온 동물 중, 이름이 없는 채로 들어온 동물의 ID를 조회하는 SQL 문을 작성해주세요. 단, ID는 오름차순 정렬되어야 합니다.
였다. 이름이 없는 채로 들어온 동물의 ID는 NULL이므로,
SELECT ANIMAL_ID FROM ANIMAL_INS WHERE NAME IS NULL
위와 같이 작성할 수 있다.
두번째 문제는
USER_INFO 테이블에서 2021년에 가입한 회원 중 나이가 20세 이상 29세 이하인 회원이 몇 명인지 출력하는 SQL문을 작성해주세요.
였다.
AGE가 20<=AGE && AGE >= 29이고, JOINED에 '2021'이 들어가면 되므로
SELECT COUNT(*) AS USERS FROM USER_INFO WHERE AGE >= 20 && AGE <= 29 AND JOINED LIKE '2021%'
와 같이 작성할 수 있다.
그리고 원하님이 SQL을 풀다가 왜 틀린건지 모르겠다고 하셔서 그 문제를 같이 풀어보았다.
동물 보호소에 들어온 동물 중 고양이와 개가 각각 몇 마리인지 조회하는 SQL문을 작성해주세요. 이때 고양이를 개보다 먼저 조회해주세요.
라는 문제였는데,
원하님이 쓰셨던 코드는
SELECT ANIMAL_TYPE, COUNT(*) AS COUNT
FROM ANIMAL_INS
GROUP BY ANIMAL_TYPE 였다.
출력결과도 잘 나와서 왜 틀린걸까 하고 생각해봤고, 혹시 몰라 ORDER BY 구문을 같이 넣어줬더니 정답이었다.
SELECT ANIMAL_TYPE, COUNT(*) AS COUNT
FROM ANIMAL_INS
GROUP BY ANIMAL_TYPE
ORDER BY ANIMAL_TYPE;위와 같이 하면 정답이다.
알고리즘 첫 문제는 서울에서 김서방 찾기였다.
String형 배열 seoul의 element중 "Kim"의 위치 x를 찾아, "김서방은 x에 있다"는 String을 반환하는 함수, solution을 완성하세요. seoul에 "Kim"은 오직 한 번만 나타나며 잘못된 값이 입력되는 경우는 없습니다.
제한 사항
seoul은 길이 1 이상, 1000 이하인 배열입니다.
seoul의 원소는 길이 1 이상, 20 이하인 문자열입니다.
"Kim"은 반드시 seoul 안에 포함되어 있습니다.seoul 배열이 주어졌고, 배열의 크기는 랜덤으로 주어지므로 seoul.length으로 둘 수 있다.
배열을 돌려가면서 Kim이 나올때, answer에 넣어주고 break로 for문에서 빠져나오고, answer을 리턴한다.
class Solution {
public String solution(String[] seoul) {
String answer = "";
for (int i = 0; i < seoul.length; i++) {
if (seoul[i].equals("Kim")) {
answer = "김서방은 " + i + "에 있다";
break;
}
}
return answer;
}
}제출한 코드는 위와 같다.
두번째 문제는 나누어 떨어지는 숫자 배열이었다.
array의 각 element 중 divisor로 나누어 떨어지는 값을 오름차순으로 정렬한 배열을 반환하는 함수, solution을 작성해주세요.
divisor로 나누어 떨어지는 element가 하나도 없다면 배열에 -1을 담아 반환하세요.
제한사항
arr은 자연수를 담은 배열입니다.
정수 i, j에 대해 i ≠ j 이면 arr[i] ≠ arr[j] 입니다.
divisor는 자연수입니다.
array는 길이 1 이상인 배열입니다.처음에는
class Solution {
public int[] solution(int[] arr, int divisor) {
int[] answer = new int[0];
int temp = 0;
for (int i = 0; i < arr.length; i++) {
if (arr[i] % divisor == 0) {
answer[temp] = arr[i];
temp++;
}
}
return answer;
}
}
프로토 타입 수정 없이 간단한 로직만 짜서 위와 같이 했는데, answer의 크기를 0으로 놓았기 때문에 값을 할당할 수 없다. answer의 크기를 알기 위해, 먼저 count를 써서 배열의 크기를 만들어주고, 값을 하나씩 넣어주는 식으로 구현할 수 있다.
오름차 순으로 정렬해야하는데, array.sort를 쓰거나 버블정렬을 활용하여 정렬할 수 있다.
더 간단한 건 array.sort겠지만, import 없이 풀고 싶어서 버블 정렬을 활용하였다.
class Solution {
public int[] solution(int[] arr, int divisor) {
int count = 0;
for (int i = 0; i < arr.length; i++) {
if (arr[i] % divisor == 0) {
count++;
}
}
if (count == 0) {
return new int[]{-1};
}
int[] answer = new int[count];
int temp = 0;
for (int i = 0; i < arr.length; i++) {
if (arr[i] % divisor == 0) {
answer[temp] = arr[i];
temp++;
}
}
for (int i = 0; i < answer.length - 1; i++) { //버블정렬-오름차순 정렬
for (int j = 0; j < answer.length - 1 - i; j++) {
if (answer[j] > answer[j + 1]) {
int temp_1 = answer[j];
answer[j] = answer[j + 1];
answer[j + 1] = temp_1;
}
}
}
return answer;
}
}정답 코드는 위와 같다.
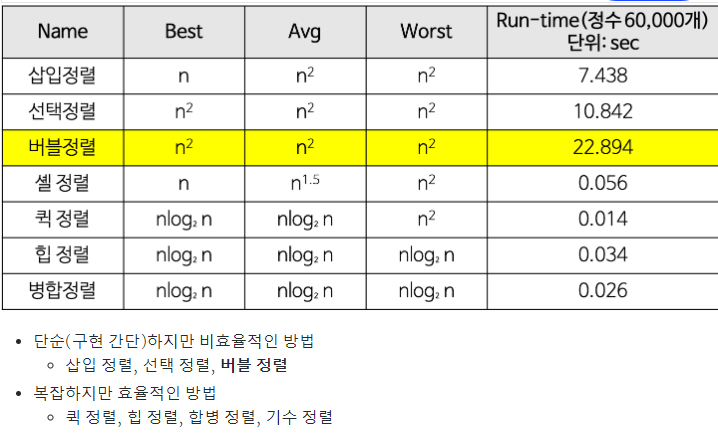
오늘 버블 정렬을 사용했으므로, 버블 정렬에 대해 알아보도록 하겠다.
버블 정렬
서로 인접한 두 원소를 검사하여 정렬하는 알고리즘이다.
인접한 2개의 레코드를 비교하여 크기가 순서대로 되어 있지 않으면 서로 교환하는 방식이다.
(이 때 temp 등의 저장할 변수을 두는 방식으로 swap한다)
버블 정렬은 첫 번째 자료와 두 번째 자료를, 두 번째 자료와 세 번째 자료를, 세 번째와 네 번째를, … 이런 식으로 (마지막-1)번째 자료와 마지막 자료를 비교하여 교환하면서 자료를 정렬한다.
1회전을 수행하고 나면 가장 큰 자료가 맨 뒤로 이동하므로 2회전에서는 맨 끝에 있는 자료는 정렬에서 제외되고, 2회전을 수행하고 나면 끝에서 두 번째 자료까지는 정렬에서 제외된다. 이렇게 정렬을 1회전 수행할 때마다 정렬에서 제외되는 데이터가 하나씩 늘어난다.
버블 정렬(bubble sort) 알고리즘의 예제
배열에 7, 4, 5, 1, 3이 저장되어 있다고 가정하고 자료를 오름차순으로 정렬해 보자.
ex)
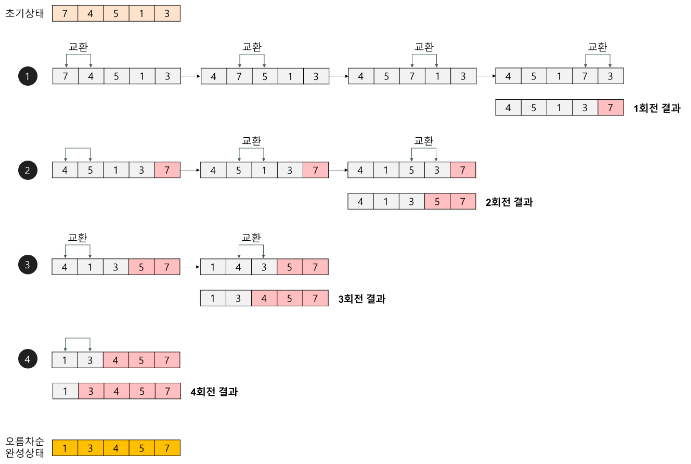
1회전
첫 번째 자료 7을 두 번째 자료 4와 비교하여 교환하고, 두 번째의 7과 세 번째의 5를 비교하여 교환하고, 세 번째의 7과 네 번째의 1을 비교하여 교환하고, 네 번째의 7과 다섯 번째의 3을 비교하여 교환한다. 이 과정에서 자료를 네 번 비교한다. 그리고 가장 큰 자료가 맨 끝으로 이동하므로 다음 회전에서는 맨 끝에 있는 자료는 비교할 필요가 없다.
2회전
첫 번째의 4을 두 번째 5와 비교하여 교환하지 않고, 두 번째의 5와 세 번째의 1을 비교하여 교환하고, 세 번째의 5와 네 번째의 3을 비교하여 교환한다. 이 과정에서 자료를 세 번 비교한다. 비교한 자료 중 가장 큰 자료가 끝에서 두 번째에 놓인다.
3회전
첫 번째의 4를 두 번째 1과 비교하여 교환하고, 두 번째의 4와 세 번째의 3을 비교하여 교환한다. 이 과정에서 자료를 두 번 비교한다. 비교한 자료 중 가장 큰 자료가 끝에서 세 번째에 놓인다.
4회전
첫 번째의 1과 두 번째의 3을 비교하여 교환하지 않는다.
버블 정렬의 특징
장점
구현이 매우 간단하다.
단점
1. 순서에 맞지 않은 요소를 인접한 요소와 교환한다.
2. 하나의 요소가 가장 왼쪽에서 가장 오른쪽으로 이동하기 위해서는 배열에서 모든 다른 요소들과 교환되어야 한다.
3. 특히 특정 요소가 최종 정렬 위치에 이미 있는 경우라도 교환되는 일이 일어난다.
4. 일반적으로 자료의 교환 작업(SWAP)이 자료의 이동 작업(MOVE)보다 더 복잡하기 때문에 버블 정렬은 단순성에도 불구하고 거의 쓰이지 않는다.
버블 정렬의 시간복잡도
비교 횟수
1. 최상, 평균, 최악 모두 일정
2. n-1, n-2, … , 2, 1 번 = n(n-1)/2
교환 횟수
1. 입력 자료가 역순으로 정렬되어 있는 최악의 경우, 한 번 교환하기 위하여 3번의 이동(SWAP 함수의 작업)이 필요하므로 (비교 횟수 * 3) 번 = 3n(n-1)/2
2. 입력 자료가 이미 정렬되어 있는 최상의 경우, 자료의 이동이 발생하지 않는다.
T(n) = O(n^2)