TIL 5/11
오늘 헬스장 가서 PT등록을 하고, 맛난 저녁을 먹고 노래방 갔다 왔다. 오랜만에 밖에 나가니 기분이 새로웠다.
오늘 푼 SQL 문제는
'FOOD_PRODUCT 테이블에서 가격이 제일 비싼 식품의 식품 ID, 식품 이름, 식품 코드, 식품분류, 식품 가격을 조회하는 SQL문을 작성해주세요.'
였다.
여기서 출력해야하는 애트리뷰트는 모두이고, WHERE절에서 MAX함수를 사용하여 가격이 가장 높은 투플을 찾아낼 수 있었다.
SELECT * FROM FOOD_PRODUCT WHERE PRICE = (SELECT MAX(PRICE) FROM FOOD_PRODUCT)알고리즘 문제는 콜라츠 추측이라는 문제였는데, 아래와 같다.
1937년 Collatz란 사람에 의해 제기된 이 추측은, 주어진 수가 1이 될 때까지 다음 작업을 반복하면, 모든 수를 1로 만들 수 있다는 추측입니다.
작업은 다음과 같습니다.
1-1. 입력된 수가 짝수라면 2로 나눕니다.
1-2. 입력된 수가 홀수라면 3을 곱하고 1을 더합니다.
2. 결과로 나온 수에 같은 작업을 1이 될 때까지 반복합니다.
예를 들어, 주어진 수가 6이라면 6 → 3 → 10 → 5 → 16 → 8 → 4 → 2 → 1 이 되어 총 8번 만에 1이 됩니다.
위 작업을 몇 번이나 반복해야 하는지 반환하는 함수, solution을 완성해 주세요.
단, 주어진 수가 1인 경우에는 0을, 작업을 500번 반복할 때까지 1이 되지 않는다면 –1을 반환해 주세요.
입력된 수, num은 1 이상 8,000,000 미만인 정수입니다.처음에는 단순히 아래와 같이 요구사항에 맞는 코드를 작성하였다.
class Solution {
public int solution(int num) {
int answer = 0;
while (num != 1 && answer <= 500) {
if (num % 2 == 0) {
num = num / 2;
answer++;
} else {
num = num * 3 + 1;
answer++;
}
}
if (answer > 500) {
answer = -1;
}
return answer;
}
}그런데 626331이 들어가면 결과값이 488이 되어 오답처리가 되었다.
int값이 -2147483648~2147483647인데, 만약 8백만이라는 값이 테스트케이스로 들어간다면 오버플로우가 날 수 있다.
class Solution {
public int solution(long num) {
int answer = 0;
while (num != 1 && answer <= 500) {
if (num % 2 == 0) {
num = num / 2;
} else {
num = num * 3 + 1;
}
answer++;
}
if (answer >= 500) {
answer = -1;
}
return answer;
}
}위와같이 answer을 하나로 통일해주어 코드를 깔끔하게 만들어주고, num의 타입을 long으로 바꿔주어 문제를 해결할 수 있었다.
중간에 시간초과가 떠서 fail한 경우도 있었는데, 왜 그런지 친한 선배에게 물어봤었다.
800만같은 큰 수가 들어갈 경우 시간복잡도가 크기때문에 시간초과가 뜰 수도 있다고, 최적의 시간복잡도를 요구하는 문제였다면 fail이 뜰 수도 있다고 답변해주었다. 그러면서 '다이나믹 프로그래밍' 이라는 것을 한번 알아보라고 하셨다.
다이나믹 프로그래밍(DP)이란?
다이나믹 프로그래밍(동적 계획법)이란 bottom-up 방식으로 복잡한 문제를 더 작은 하위 문제로 나누어 해결하는 알고리즘 설계 기법이다.
최적화 이론의 한 기술이며, 특정 범위까지의 값을 구하기 위해서 그것과 다른 범위까지의 값을 이용하여 효율적으로 값을 구하는 알고리즘 설계 기법이다. (구했던 답 재활용하기)
알고리즘 설계 기법 : 문제 해결을 위해 알고리즘을 설계하는 방법이나 접근 방식
ex)분할 정복, 동적 계획법, 탐욕적 알고리즘, 백트래킹 등
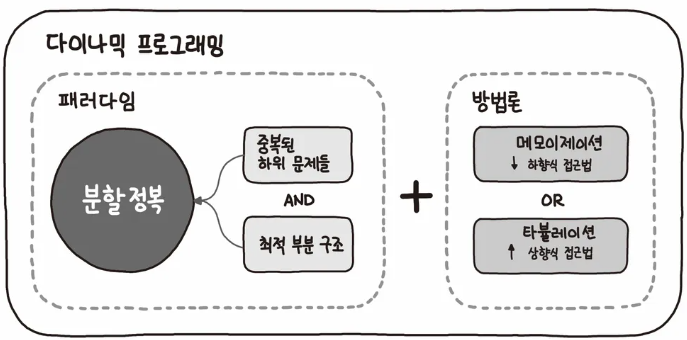
DP의 주요 개념은 '메모이제이션(Memoization), 타뷸레이션(Tabulation)'이다.
동일한 계산을 반복해야 할 경우 한번 계산한 결과를 메모리에 저장해 두었다가 꺼내씀으로써 중복 연산을 방지하여 시간복잡도를 줄일 수 있다. 대신 공간 복잡도는 조금 늘어날 수 있다.
하위 문제에 대한 정답을 계산했는지 확인해가며 하향식으로 문제를 자연스럽게 풀어나가는 방식을 메모이제이션(Memoization)이라고 한다. 캐싱(cashing)과 동의어이다.
재귀적 호출, DP에 쓰인다.
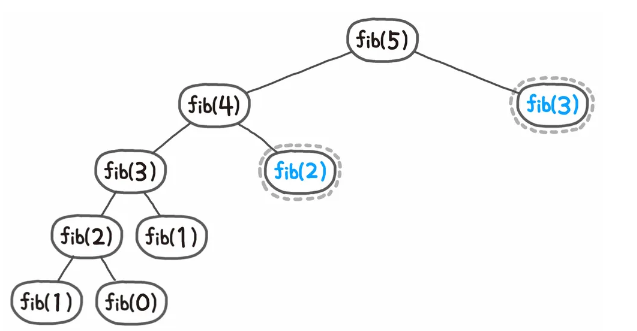
이미 문제를 풀어봤는지 확인하면서 같은 문제의 풀이는 재활용하는 형태로 문제를 풀이하면 그림과 같이 9번의 계산만을 수행하면 되며, 이 중에서도 2번은 계산 없이 기존에 풀이했던 동일한 문제의 정답을 가져오기만 하면 된다.
타뷸레이션(tabulation)이라는 것도 있다. 메모이제이션은 결과가 필요해질 때 계산하지만, 타뷸레이션은 필요하지 않은 값도 미리 계산해둔다. 시간복잡도가 O(1)로 아주 빠르다.
메모이제이션과 타뷸레이션의 비교
메모이제이션을 통한 피보나치 함수는 여러 번의 함수 호출로 메모리 공간의 스택을 차지하고 메모이제이션을 위한 공간까지 차지하기 때문에 메모리를 더 많이 사용한다. 반면 타뷸레이션을 통한 피보나치 함수는 적은 메모리 사용인데도 불구하고 빠른 시간을 보인다.
그럼 동적 프로그래밍이 필요한 분할 정복 문제를 풀 때 메모이제이션과 타뷸레이션 중 어떤 것이 더 좋은 접근 방식일까?
메모이제이션의 장점은 재귀를 이용해 문제를 하향식으로 해결하여 복잡한 문제를 쉽게 해결할 수 있는 장점이 있다. 재귀만 이용한다면 중복 계산을 하기 때문에 성능에 문제가 발생하는데, 계산 결과를 저장하는 방식으로 단점을 해결했다.
그렇기 때문에 분할 정복을 해결할 때 재귀가 더 직관적이라면 메모이제이션을 이용하는 것이 유리하다. 하지만 재귀가 직관적이지 않은 문제라면, 타뷸레이션을 이용해 메모리도 절약하고 속도도 빠르게 해결할 수 있다.
메모이제이션의 핵심 개념
- 저장 : 함수의 결과를 특정 자료 구조에 저장한다.
- 확인 : 함수를 호출하기 전에 해당입력에 대한 결과가 이미 저장되어 있는지 반환한다.
- 재활용 : 저장된 결과가 있다면, 다시 계산하지 않고 저장된 값을 반환한다.
DP기법을 적용시킬 수 있는 조건
-
중복되는 부분 문제(Overlapping Subproblems)
DP는 기본적으로 문제를 나누고 그 문제의 결과 값을 재활용해서 전체 답을 구한다. 그래서 동일한 작은 문제들이 반복하여 나타나는 경우에 사용이 가능하다. -
최적 부분 구조(Optimal Substructure)
부분 문제의 최적 결과 값을 사용해 전체 문제의 최적 결과를 낼 수 있는 경우 사용이 가능하다.
DP로 문제 푸는 방법
-
메모하기
변수 값에 따른 결과를 저장할 배열 등을 미리 만들고 그 결과를 나올 때마다 배열 내에 저장하고 그 저장된 값을 재사용하는 방식으로 문제를 해결해 나간다. -
변수 간 관계식(점화식) 만들기
예를 들어 피보나치 수열의 f(n) = f(n-1) + f(n-2) 라는 식
DP는 재귀적 호출과 상반되는 구조이다. 재귀는 보통 피보나치 수열을 짜며 배우게 된다. 아래는 재귀함수로 짠 피보나치 수열이다. 메모이제이션을 활용하였다.
#define MAX_INDEX 100 // 충분한 범위로 설정
int memo[MAX_INDEX]; // 메모이제이션을 위한 배열
int ft_fibonacci_recur(int index)
{
if (index == 0)
return 0;
if (index == 1)
return 1;
if (memo[index] != 0) // 이미 계산된 값이 있다면 바로 반환
return memo[index];
memo[index] = ft_fibonacci_recur(index - 1) + ft_fibonacci_recur(index - 2); // 값을 계산하고 메모이제이션
return memo[index];
}
int ft_fibonacci(int index)
{
memset(memo, 0, sizeof(memo)); // 메모이제이션 배열 초기화
return ft_fibonacci_recur(index);
}index가 100이라고 가정했을 때, 100, 99, 98 ... 으로 줄어들고 있다. 이를 top-down 방식이라고 한다.
큰 수에서 인덱스를 하나씩 줄여가면서 값을 저장한다.
반면 dp로 짠 피보나치 수열은 아래와 같다. 마찬가지로 메모이제이션을 활용하였다.
function fibonacci(n) {
// 🌟 메모이제이션 🌟
// 피보나치 수열을 저장할 배열
const dp = new Array(n + 1);
// 초기값 설정
dp[0] = 0;
dp[1] = 1;
// 🌟 점화식 🌟
// 피보나치 수열 계산
for (let i = 2; i <= n; i++) {
dp[i] = dp[i - 1] + dp[i - 2];
}
// 결과 반환
return dp[n];
}index가 2, 3, 4 ... 로 늘어나고 있다. 이를 bottom-top 방식이라고 한다. 0부터 인덱스를 하나씩 늘여가면서 값을 저장한다.
타뷸레이션을 활용한 피보나치 수열 구현은 아래와 같다.
function fibonacci(n) {
if(n <= 1) return n;
let table = [0, 1];
for(let i = 2; i <= n; i ++) {
table[i] = table[i - 2] + table[i - 1];
}
return table[n];
}