
참고문헌
마이클 알바다 『AI 에이전트 엔지니어링 』 한빛미디어(2026), 168-180
도입배경
기존 Baseline RAG 문제점
베이스라인 RAG 시스템은 문서를 청크로 나누고, 각 청크를 벡터 공간에 임베딩한 뒤 쿼리 시점에 시맨틱하게 유사한 청크를 검색해 LLM 프롬프트에 추가하는 방식으로 동작한다.
장점
- 단순한 사실 조회가 빠름
- 질의 응답에 효과적
단점
- 답이 여러 문서에 흩어져 있고, 정보를 연결해야 할 때
- 쿼리가 데이터셋 전체에 걸친 상위 수준의 의미론적 주제를 요구, 분석 할 때
- 데이터 셋이 개별적인 사실이 아니라 서사형 구조로 구성되어 있는 경우
예를 들어 "스티브 잡스가 무슨 일을 해왔는가?" 라는 질문에 스티브 잡스가 한 일에 대한 사실만으로 시맨틱 청킹이 되어 있지 않다면, 스티브 잡스의 다른 정보가 LLM 프롬프트에 섞인다.
GraphRAG 지식그래프의 해결
그래프 데이터베이스나 지식 그래프를 이용해 서로 연결된 데이터를 저장, 조회
데이터 안의 복잡한 관계와 컨텍스트를 표현하는 그래프에서 노드와 엣지를 분석
특화 기능
- 멀티홉 추론
- 관계 체이닝
- 구조화된 요약
GraphRAG 구축과정
기존 Baseline RAG를 구축할 때와 마찬가지로 다음 과정이 필요
- 데이터 ETL 과정이 필요
- 정기적인 유지보수 및 업데이트 주기 결정이 필요
프로세스
1. 데이터 수집
- 데이터베이스, 텍스트 문서, 웹사이트, 사용자 콘텐츠 등 다양한 소스에서 데이터 확보
2. 데이터 전처리
- 관련성이 없거나 중복된 정보 제거, 오류 수정
- 데이터의 노이즈를 줄여 데이터 형식을 표준화
3. 엔티티 추출
- 지식 그래프에서 노드 역할을 하는 엔티티를 식별
- 구조화되지 않는 텍스트 -> NER 딥러닝 모델을 통해서 엔티티 추출
- RDF(Resource Description Framework) 데이터 모델링의 Sementic Triple을 추출
- 웹상의 자원(Resource)을 주어(Subject)-서술어(Predicate)-목적어(Object)의 3요소(Triple) 구조로 표현하는 시맨틱 웹 표준 모델
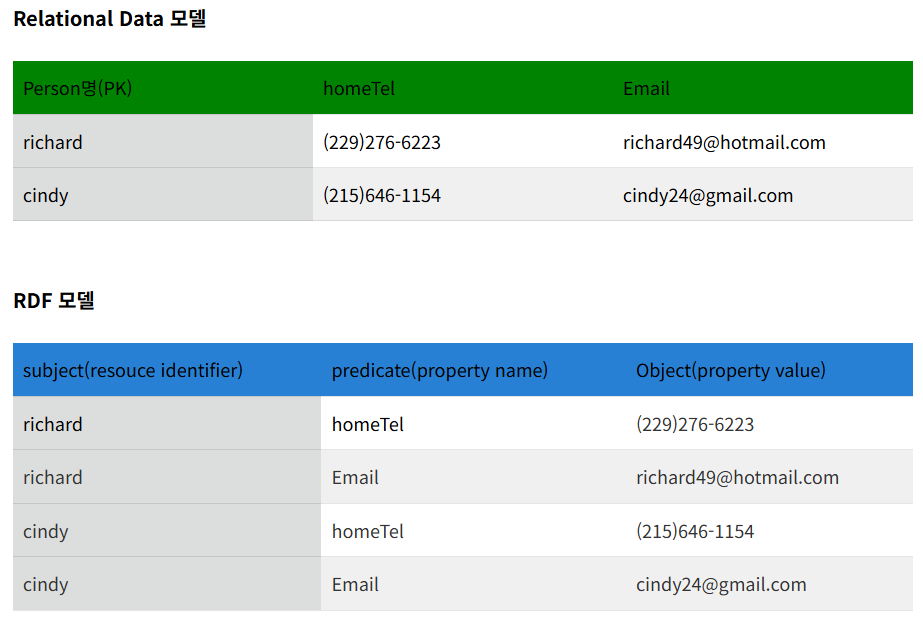
- 웹상의 자원(Resource)을 주어(Subject)-서술어(Predicate)-목적어(Object)의 3요소(Triple) 구조로 표현하는 시맨틱 웹 표준 모델
4. 관계 추출
- 데이터를 파싱해서 엔티티를 연결하는 서술어를 추출, 그래프 엣지로 구성
- 복잡한 비정형 데이터에서는 파운데이션 모델이 효과적으로 처리할 수 있음
5. Ontology 설계
- 온톨로지는 지식 그래프 내의 범주와 관계를 정의하며 그래프의 뼈대 역할을 함
- 엔티티 유형과 이들 사이에 가능한 관계 유형을 포괄하는 스키마를 정의
6. 그래프 생성
- 온톨로지 구조에 따라 그래프 데이터베이스에 노드와 엣지 생성
- neo4j, OrientDB, Amazon Neptune 사용 가능
7. 통합 및 검증
- 기존 시스템과 통합하고 정확성과 유용성 검증
- 중복된 엔티티 해결, 실제 지식 도메인을 정확하게 반영하는지 확인
- 사용자 테스트, 점검 자동화 이용
8. 유지보수와 업데이트
- 최신 상태를 유지하기 위한 정기적인 업데이트와 온톨로지 유지보수 필요
- 새로운 데이터를 추가, 기존 정보를 갱신, 새로운 유형의 엔티티나 관계 추가
Neo4j Cypher 쿼리 문법
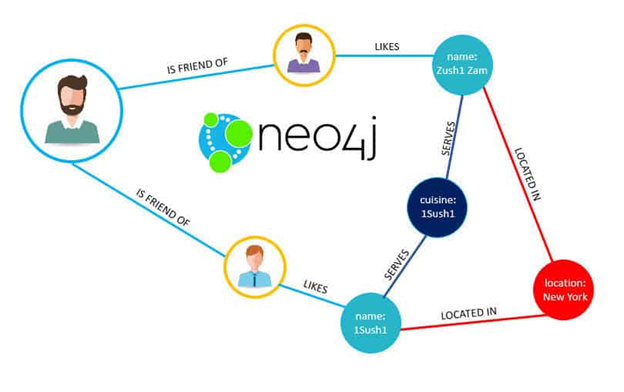
GraphRAG 시스템 구축을 위한 Neo4j Cypher 쿼리의 기초 문법, 제약 조건, 변수 범위, 그리고 벡터 유사도 기반의 지능형 홉 탐색 전략을 정리
1. 기본 문법 (CREATE & MATCH)
(p:Entity {id: "E001"})-[:OWNED_BY]->(related)
- (): 엔티티, []: 관계
- p: 단일 쿼리내 지역변수
- Entity: 엔티티 label
- id: 엔티티 속성
- OWNED_BY: 관계 타입
1.1 데이터 생성 (CREATE & MERGE)
- CREATE: 노드와 관계를 생성합니다. 중복 체크를 하지 않습니다.
- MERGE: 데이터가 있으면 가져오고, 없으면 생성하는 'Upsert' 방식입니다. 중복 방지를 위해 권장됩니다.
// 노드 생성 예시
MERGE (p:Entity {id: "E001"})
ON CREATE SET p.name = "Elon Musk", p.type = "Person"
// 관계 생성 예시
MATCH (a:Entity {name: "Tesla"}), (b:Entity {name: "Elon Musk"})
MERGE (a)-[r:OWNED_BY]->(b)
SET r.share = "13%"1.2 데이터 조회 (MATCH)
패턴 매칭을 통해 데이터를 검색합니다. 화살표 방향을 통해 관계를 명시합니다.
// 특정 노드와 연결된 모든 이웃 찾기
MATCH (e:Entity {name: "Tesla"})-[r]->(neighbor)
RETURN e.name, type(r) AS relationship, neighbor.name2. 노드와 관계의 속성 및 제약 조건
2.1 라벨과 타입 확인
- labels(node): 노드의 라벨을 리스트 형태로 반환합니다.
- type(relationship): 관계의 종류(이름)를 문자열로 반환합니다.
2.2 제약 조건 (Constraints)
데이터 무결성을 위해 특정 규칙을 강제합니다.
| 제약 종류 | Cypher 예시 | 설명 |
|---|---|---|
| Unique | CREATE CONSTRAINT FOR (e:Entity) REQUIRE e.id IS UNIQUE | 특정 속성값 중복 방지 |
| Existence | CREATE CONSTRAINT FOR (p:Person) REQUIRE p.name IS NOT NULL | 속성 필수 존재 강제 |
| Node Key | CREATE CONSTRAINT FOR (c:City) REQUIRE (c.id) IS NODE KEY | Unique + Existence 결합 |
3. 변수 범위 및 홉(Hop) 탐색
3.1 변수 범위 (Scope)
- Cypher 변수는 단일 쿼리 실행 단위 내에서만 유효합니다.
- 중간 결과를 다음 단계로 넘기려면
WITH절을 사용해야 합니다.
3.2 홉 탐색 (Variable-length patterns)
특정 깊이까지의 연결 고리를 추적합니다.
// 1~3홉 사이의 모든 경로 탐색 (무방향)
MATCH path = (n:Entity {name: "AI"})-[*1..3]-(related)
RETURN path3.3 홉 탐색 (Variable-length patterns)
두 엔티티 사이의 가장 짧은 연결 고리를 찾습니다. 복잡한 관계 속에서 두 개념이 어떻게 가장 밀접하게 연관되었는지 추출할 때 유용합니다.
MATCH (a:Entity {name: "Microsoft"}), (b:Entity {name: "OpenAI"})
MATCH p = shortestPath((a)-[*..5]-(b))
RETURN p4. 지능형 벡터 유사도 탐색 (Advanced)
Neo4j에 노드별 임베딩(LIST<FLOAT>)이 저장되어 있을 때, 사용자 질문과의 유사도를 실시간으로 계산하며 탐색하는 기법입니다.
4.0 Neo4j에 임베딩 저장 및 설정
Neo4j 버전 5.x 이상부터는 LIST 형식으로 임베딩 벡터를 속성에 저장할 수 있으며, 이를 위한 Vector Index를 생성할 수 있습니다.
CREATE VECTOR INDEX entity_embeddings FOR (e:Entity) ON (e.embedding)
OPTIONS {indexConfig: {
`vector.dimensions`: 1536,
`vector.similarity_function`: 'cosine'
}}4.1 탐색 중 유사도 필터링 (Pruning)
전체 그래프를 탐색하되, 질문 벡터와 유사도가 낮은 노드는 경로에서 제외합니다.
// 모든 경로상의 노드가 질문과 유사도 0.8 이상인 경우만 탐색
// 방법 A: 반복적 홉 탐색 (탐색의 매 단계마다 유사도를 체크하여 '가지치기'를 수행)
MATCH (current:Entity {id: $currentId})-[r]->(next:Entity)
WITH next, vector.similarity.cosine(next.embedding, $queryVector) AS similarity
WHERE similarity > 0.8
RETURN next.id, next.name, similarity
// 방법 B: 하이브리드 탐색 (전체 경로 후 필터링)
MATCH path = (start:Entity {name: "시작지점"})-[*1..3]-(target:Entity)
WHERE ALL(n IN nodes(path) WHERE vector.similarity.cosine(n.embedding, $queryVector) > 0.8)
RETURN path, target.name4.2 인덱스 기반 하이브리드 탐색
벡터 인덱스로 후보군을 먼저 좁힌 후, 그 주변 홉을 탐색하여 효율을 높입니다.
// 1. 질문과 유사한 노드 Top 5를 먼저 찾음
CALL db.index.vector.queryNodes('entity_embeddings', 5, $queryVector)
YIELD node AS startNode, score
// 2. 찾은 노드들로부터 1~2홉 이내의 지식만 확장
MATCH (startNode)-[r*1..2]-(neighbor)
RETURN startNode.name, type(last(r)), neighbor.name5. 주요 팁 요약
- 방향성: 데이터 저장 시 방향이 있어도, 조회 시에는
(a)-(b)처럼 화살표를 생략하여 양방향 탐색이 가능합니다. - 관계 이름(Type): 홉 탐색 시 특정 관계 이름(
[:WORKS_AT*])을 명시하면 탐색 속도가 비약적으로 향상됩니다. - 성능: 가변 길이 탐색(
*) 사용 시 반드시 최대 깊이(*..3)를 제한하여 무한 루프를 방지해야 합니다.
