1) 데이터 다운로드
cd /home/ubuntu/data
sudo wget https://raw.githubusercontent.com/good593/course_data_engineering/main/hadoop%20ecosystem/samples/7.%20Pig%20%EC%82%AC%EC%9A%A9%ED%95%98%EA%B8%B0/SalesJan2009.csv
2) ubuntu -> hadoop
hdfs dfs -mkdir -p /pig/sales/input/
hdfs dfs -put /home/ubuntu/data/SalesJan2009.csv /pig/sales/input/SalesJan2009.csv
3) pig 접속 후 데이터 import
pig
rawSalesTable = LOAD '/pig/sales/input/SalesJan2009.csv' USING PigStorage(',')
AS (Transaction_date:chararray,Product:chararray,Price:chararray,Payment_Type:chararray,
Name:chararray,City:chararray,State:chararray,Country:chararray,Account_Created:chararray,
Last_Login:chararray,Latitude:chararray,Longitude:chararray);
salesTable = FOREACH rawSalesTable GENERATE
TRIM(Transaction_date) as Transaction_date, TRIM(Product) as Product, TRIM(Price) as Price, TRIM(Payment_Type) as Payment_Type
, TRIM(Name) as Name, TRIM(City) as City, TRIM(State) as State, TRIM(Country) as Country, TRIM(Account_Created) as Account_Created
, TRIM(Last_Login) as Last_Login, TRIM(Latitude) as Latitude, TRIM(Longitude) as Longitude;
DUMP salesTable;
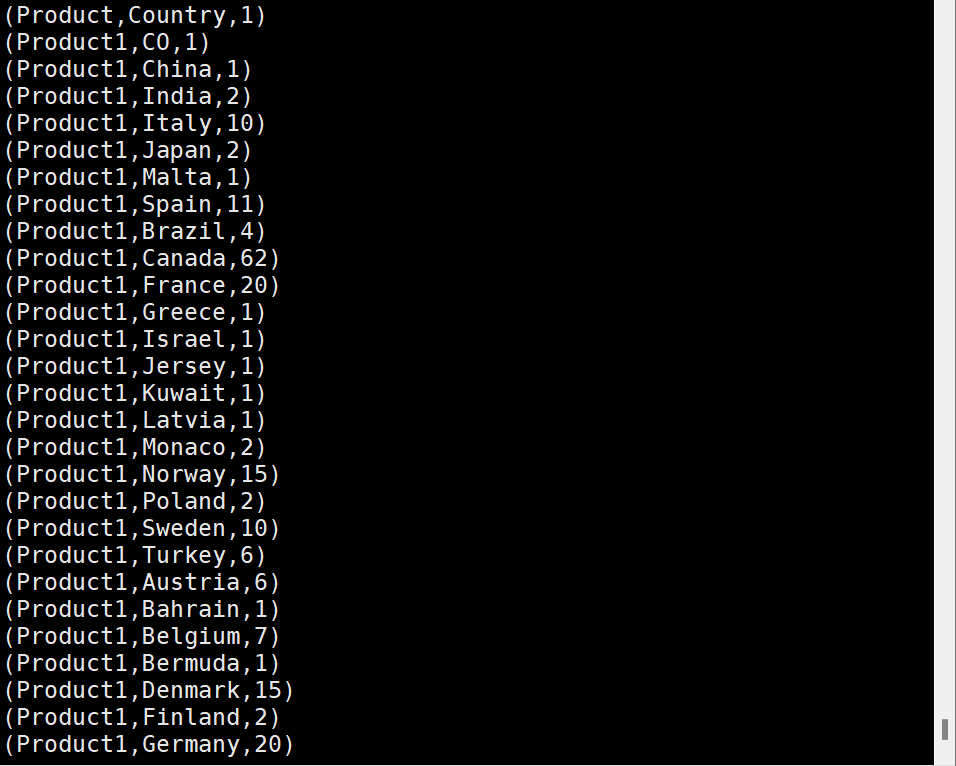
4) 상품, 나라별 데이터 수
GroupByProduct = GROUP salesTable BY (Product,Country);
CountByGroup = FOREACH GroupByProduct
GENERATE (chararray)group.Product, (chararray)group.Country, COUNT(salesTable) as CNT;
5) 상품별 min/max count
CnTMinByProduct = FOREACH (GROUP CountByGroup by Product)
GENERATE group as Product, MIN(CountByGroup.CNT) as cnt_min;
CnTMaxByProduct = FOREACH (GROUP CountByGroup by Product)
GENERATE group as Product, MAX(CountByGroup.CNT) as cnt_max;
JoinByProduct = FOREACH (JOIN CnTMinByProduct BY Product, CnTMaxByProduct BY Product)
GENERATE $0 as Product, $1 as cnt_min, $3 as cnt_max;
dump JoinByProduct;

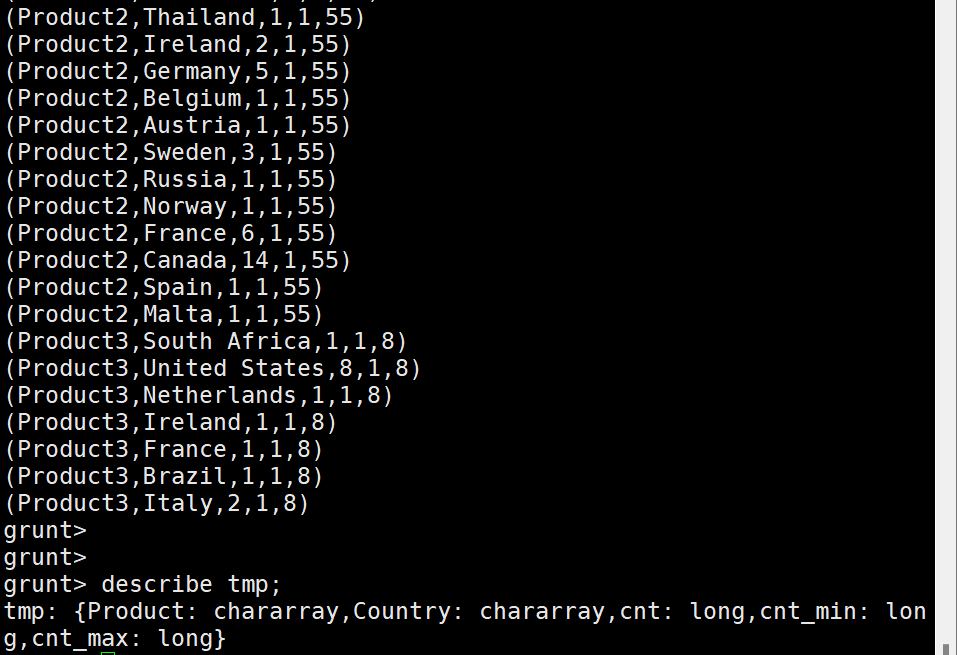
6) 모든 데이터에 상품별 Min/Max Column 추가
tmp = FOREACH (JOIN CountByGroup BY Product LEFT OUTER, JoinByProduct BY Product)
GENERATE $0 as Product, $1 as Country, $2 as cnt , $4 as cnt_min, $5 as cnt_max;
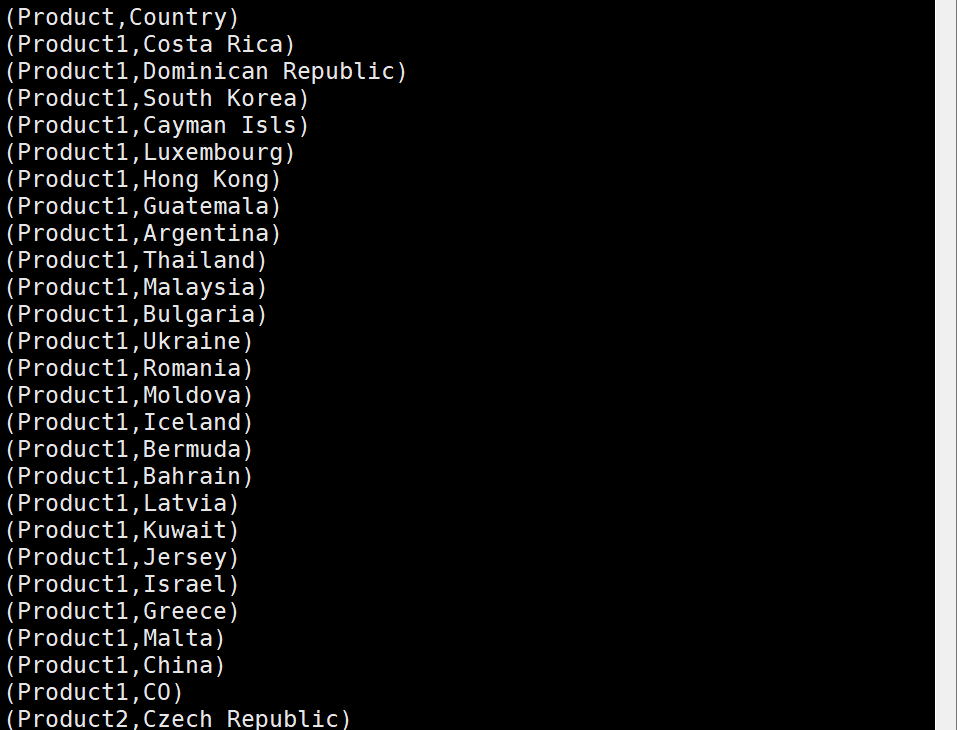
7) cnt == cnt_min / cnt == cnt_max인 데이터 조회
CountryMinByProduct = FOREACH (FILTER tmp By cnt == cnt_min)
GENERATE $0 as Product, $1 as Country_min;
dump CountryMinByProduct;
CountryMaxByProduct = FOREACH (FILTER tmp By cnt == cnt_max)
GENERATE $0 as Product, $1 as Country_max;
dump CountryMaxByProduct;

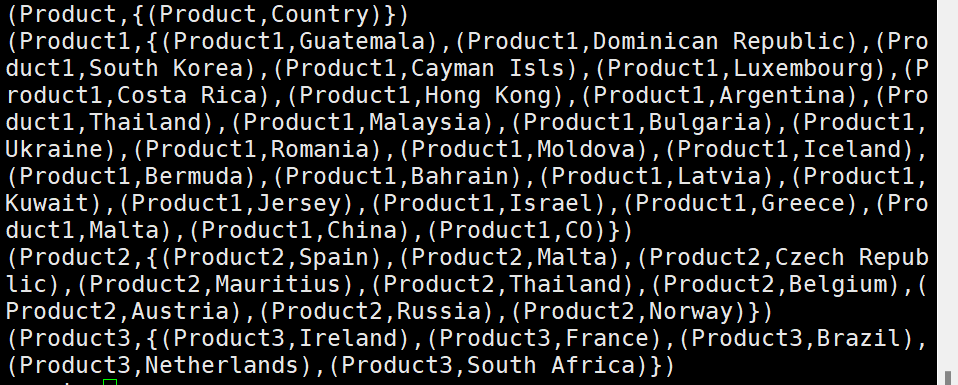
8) Product별 Min/Max Country 구하기
GroupByCountryMin = FOREACH (GROUP (DISTINCT CountryMinByProduct) BY Product)
GENERATE $0 as Product, $1 as CountryMinByProduct;
dump GroupByCountryMin;
GroupByCountryMax = FOREACH (GROUP (DISTINCT CountryMaxByProduct) BY Product)
GENERATE $0 as Product, $1 as CountryMaxByProduct;
dump GroupByCountryMax;

9) Product별 Min/Max Country 합치기
RawResult = FOREACH (JOIN GroupByCountryMin BY Product, GroupByCountryMax BY Product)
GENERATE $0 as Product,
BagToString(CountryMinByProduct.Country_min,'/') as country_min,
BagToString(CountryMaxByProduct.Country_max,'/') as country_max;
dump RawResult;
10) 상품별 가장 많이 판매된 나라이름과, 가장 적게 판매된 나라이름 조회
Result = FOREACH RawResult
GENERATE Product, CONCAT('country_min: ', country_min), CONCAT('country_max: ', country_max);
dump Result;

