0) hadoop 시작
# /home/ubuntu
. cluster-start-all.sh1) /home/ubuntu/data에 데이터 다운로드
# /home/ubuntu/data
sudo wget https://raw.githubusercontent.com/good593/course_data_engineering/main/hadoop%20ecosystem/samples/5.%20Hive%20with%20MySQL/Master.csv
ls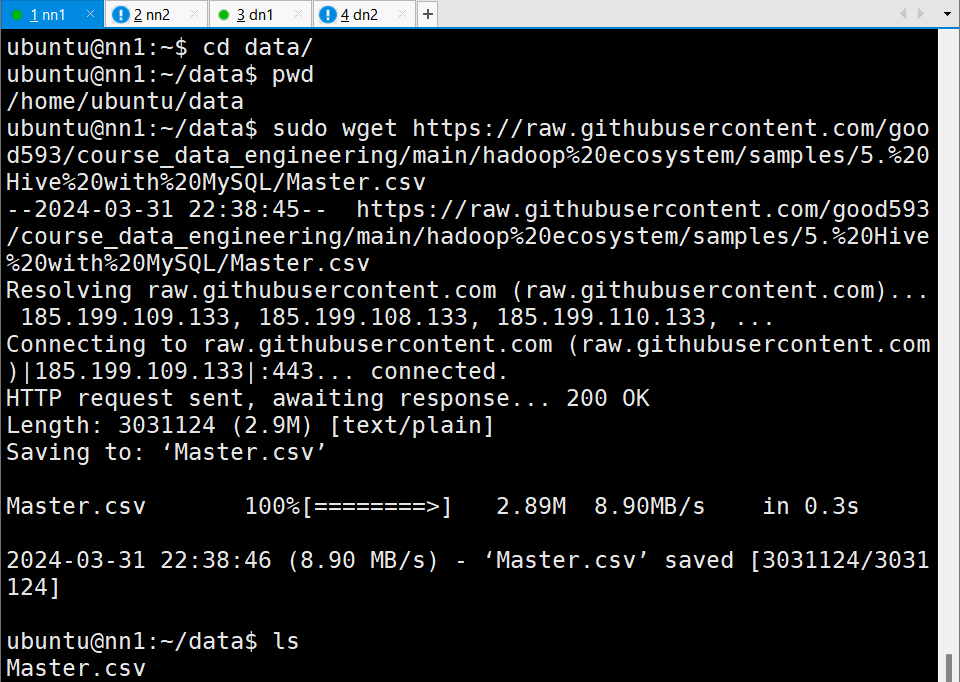
2) 데이터 확인
- 상위 10개 데이터
head /home/ubuntu/data/Master.csv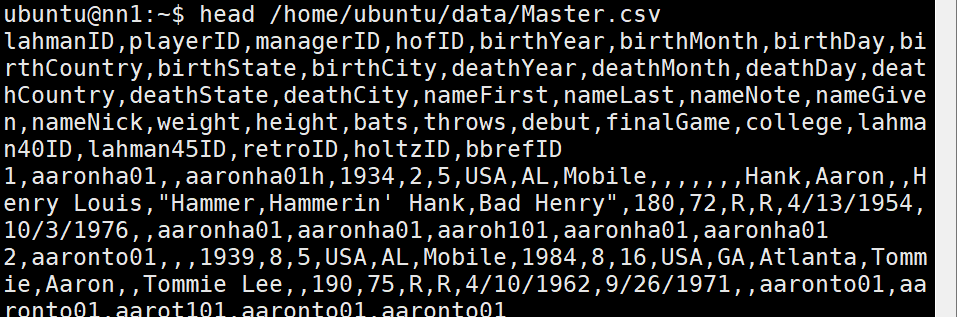
3) Master.csv column명 제거
# /home/ubuntu/data
tail -n +2 Master.csv > tmp && mv tmp /home/ubuntu/data/Master.csv
ls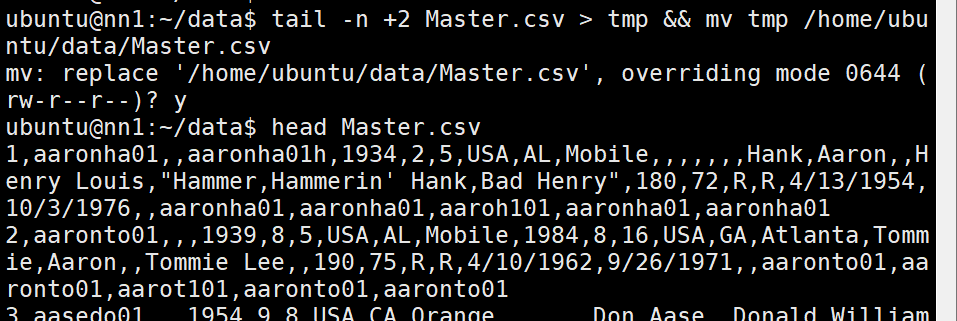
4) hadoop에 Master.csv 전달
## 디렉토리 생성
hdfs dfs -mkdir -p /hive/baseball/input
# Master.csv (ubuntu -> hadoop)
hdfs dfs -put /home/ubuntu/data/Master.csv /hive/baseball/input/Master.csv
# 확인
hdfs dfs -ls -R /hive/baseball/input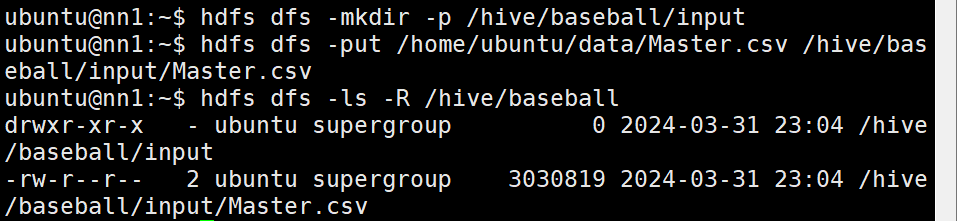
5) hive에 Master 테이블 생성
# hive 접속
hive
# baseball 데이터베이스 생성
create database baseball;
# baseball 데이터베이스 접속
use baseball;# Master 테이블 생성
CREATE TABLE IF NOT EXISTS Master
(lahmanID INT,
playerID STRING,
managerID STRING,
hofID STRING,
birthYear INT,
birthMonth INT,
birthDay INT,
birthCountry STRING,
birthState STRING,
birthCity STRING,
deathYear INT,
deathMonth INT,
deathDay INT,
deathCountry STRING,
deathState STRING,
deathCity STRING,
nameFirst STRING,
nameLast STRING,
nameNote STRING,
nameGiven STRING,
nameNick STRING,
weight INT,
height INT,
bats STRING,
throws STRING,
debut STRING,
finalGame STRING,
college STRING,
lahman40ID STRING,
lahman45ID STRING,
retroID STRING,
holtzID STRING,
bbrefID STRING)
COMMENT 'Master Player Table'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;# 확인
show tables;
describe Master;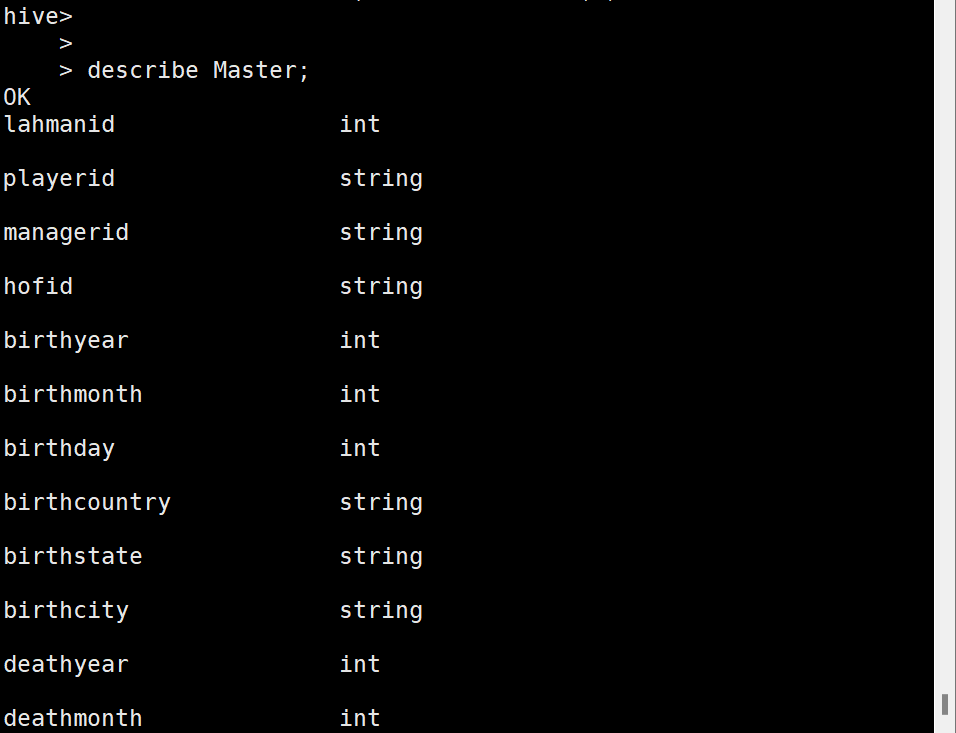
6) Master 테이블에 Master.csv import
# import (hadoop -> hive)
LOAD DATA INPATH '/hive/baseball/input/Master.csv' OVERWRITE INTO TABLE Master;
# 확인
select * from Master limit 5;
# hive 종료
quit;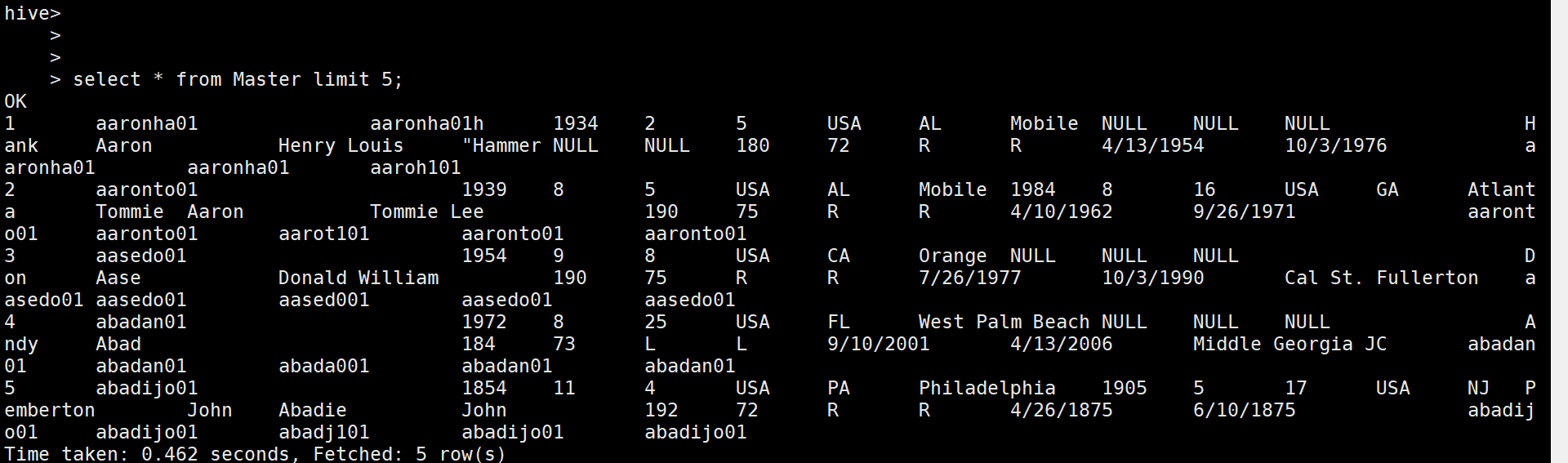
7) 같은 방식으로 hive에 Salaries.csv import
cd /home/ubuntu/data
# Data 다운로드
sudo wget https://raw.githubusercontent.com/good593/course_data_engineering/main/hadoop%20ecosystem/samples/5.%20Hive%20with%20MySQL/Salaries.csv
# Column명 제거
tail -n +2 Salaries.csv > tmp && mv tmp /home/ubuntu/data/Salaries.csv
# Salaries.csv (ubuntu -> hadoop)
hdfs dfs -put /home/ubuntu/data/Salaries.csv /hive/baseball/input/Salaries.csv# hive 접속
hive
# DB 접속
use baseball;
# Table 생성
CREATE TABLE IF NOT EXISTS Salaries
(yearID INT, teamID STRING, lgID STRING, playerID STRING, salary INT)
COMMENT 'Salary Table for Players'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
# import (hadoop -> hive)
LOAD DATA INPATH '/hive/baseball/input/Salaries.csv' OVERWRITE INTO TABLE Salaries;
# 확인
select * from Salaries limit 5;
8) Join (한국인 선수들의 연도별 연봉 정보 출력)
select Salaries.yearID, Salaries.teamID, Salaries.lgID, Master.birthcountry, Master.nameFirst, Master.nameLast, Salaries.salary
from Master join Salaries on (Master.playerID = Salaries.playerID)
where birthcountry = "South Korea";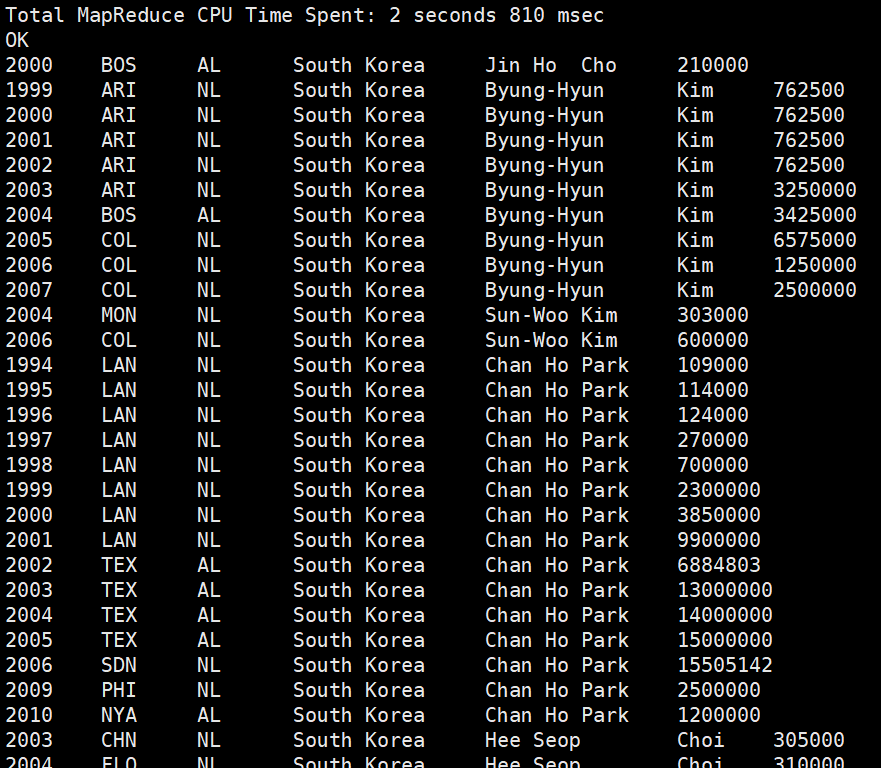
9) export (hive -> hadoop)
위에서 확인한 정보를 hadoop에 import
INSERT OVERWRITE DIRECTORY '/hive/baseball/output' ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
select Salaries.yearID, Salaries.teamID, Salaries.lgID, Master.birthcountry, Master.nameFirst, Master.nameLast, Salaries.salary
from Master join Salaries on (Master.playerID = Salaries.playerID)
where birthcountry = "South Korea";
# hive 종료
quit;10) export 확인
hdfs dfs -text /hive/baseball/output/*
