Hyperparameter of Transformer
-
(hidden_size): 트랜스포머 모델에서 각 토큰의 임베딩 벡터 차원을 나타낸다. 즉, 입력과 출력의 벡터 크기이다. 트랜스포머의 encoder와 decoder에서 정해진 입력과 출력의 크기로 embedding vector의 차원과 동일하며, encoder와 decoder 내에서 값이 전달될 때의 차원 또한 동일하다.
-
num_layers(num_encoder_layers): encoder 또는 decoder에 있는 layer의 수이다. (구현한 코드에서는 encoder의 layer 수를 의미함.)
-
num_heads: 트랜스포머에서는 attention을 사용할 때, 하나로 진행하는 것보다 여러 개의 attention을 병렬로 진행하고 독립적으로 수행한 결과값을 하나로 합친다. 이때 multi-head attention에서 병렬로 attention을 수행하는 head의 개수이다.
-
: 트랜스포머 내부에는 Feed-Forward Neural Network (FFN)가 존재한다. 이때의 은닉층 크기를 의미하는 하이퍼 파라미터이다. 즉, 차원에서 차원으로 임베딩이 진행된다. (이 내용은 아래의 내용을 읽으면서 이해하는 것이 빠르다.) 는 (hidden size)의 4배로 설정되는데, 이는 Transformer paper 'AttentionIs All You Need'에서 제안된 기본 구조 때문이다. 각 트랜스포머 레이어의 FFN을 두 개의 선형 변환과 ReLU 활성화 함수로 구성하며, 이때 중간층의 크기()는 입력 및 출력 크기인 (hidden size)의 4배로 설정된다. 이 설계 방식은 모델이 더 많은 특징을 학습할 수 있게 하여 성능을 향상시키기 위함이다.
Structure of Transformer
트랜스포머 모델은 주로 두 가지 주요 구성 요소로 나뉜다:
1. Multi-Head Attention 메커니즘
2. Feed-Forward Neural Network (FFN)
각 트랜스포머 레이어는 위의 두 가지 구성 요소로 구성되어 있다.
이 구성 요소가 작동하는 방식은 아래와 같다.
1. 임베딩 및 Multi-Head Attention
- 입력 시퀀스는 처음에 임베딩 층을 거쳐
hidden_size(또는d_model) 크기의 벡터로 변환된다. - 각 입력 벡터는 포지셔널 인코딩을 더하여 시퀀스 내에서의 위치 정보를 포함한다.
- 이렇게 임베딩된 벡터들은 Multi-Head Attention 메커니즘에 입력으로 들어간다.
2. Feed-Forward Neural Network (FFN)
FFN은 트랜스포머 레이어의 중요한 부분이다. 각 트랜스포머 레이어는 다음과 같은 구조를 가진다:
여기서 W_1과 W_2는 선형 변환을 위한 weight이고, b_1과 b_2는 bias이다.
FFN의 동작 방식
-
입력 벡터 ( x ):
- 각 토큰에 대한 임베딩 벡터로, 차원은
hidden_size(또는d_model)이다.
- 각 토큰에 대한 임베딩 벡터로, 차원은
-
첫 번째 선형 변환 및 활성화 함수:
- 입력 벡터 ( x )는 첫 번째 선형 변환을 거쳐
d_ff차원의 은닉층 벡터로 변환된다. - 이 변환은 다음과 같다:
여기서W_1의 크기는(hidden_size, d_ff)이고,h의 크기는d_ff이다. 활성화 함수로 ReLU가 사용된다.
- 입력 벡터 ( x )는 첫 번째 선형 변환을 거쳐
-
두 번째 선형 변환:
- 은닉층 벡터 ( h )는 두 번째 선형 변환을 거쳐 다시
hidden_size차원의 출력 벡터로 변환된다:
여기서W_2의 크기는(d_ff, hidden_size)이고,y의 크기는hidden_size이다.
- 은닉층 벡터 ( h )는 두 번째 선형 변환을 거쳐 다시
따라서, 피드포워드 네트워크는 hidden_size 차원의 입력을 받아 d_ff 차원으로 확장한 후, 다시 hidden_size 차원으로 축소하는 역할을 한다. 이는 다음과 같은 과정을 통해 이뤄진다:
hidden_size차원의 입력 벡터 →d_ff차원의 은닉층 →hidden_size차원의 출력 벡터
예시
-
입력 임베딩 벡터 (hidden_size = 256):
-
FFN의 첫 번째 선형 변환 (hidden_size → d_ff = 1024):
여기서 ( h )는 활성화 함수(ReLU)를 통과한 후의 벡터입니다. -
FFN의 두 번째 선형 변환 (d_ff → hidden_size):
따라서 d_ff는 피드포워드 신경망의 중간층 크기를 의미하며, 이 중간층은 hidden_size의 4배로 설정되는 것이 일반적이다.
Code
위의 설명을 코드에 반영하면, EncoderLayer 클래스는 다음과 같이 구성된다:
class EncoderLayer(nn.Module):
def __init__(self, config):
super().__init__()
self.hidden_size = config.hidden_size
self.self_attn = MultiHeadAttention(config)
self.self_attn_layer_norm = nn.LayerNorm(self.hidden_size)
self.activation_fn = nn.ReLU()
# 피드포워드 신경망의 첫 번째 선형 변환: hidden_size → d_ff
self.fc1 = nn.Linear(self.hidden_size, config.d_ff)
# 피드포워드 신경망의 두 번째 선형 변환: d_ff → hidden_size
self.fc2 = nn.Linear(config.d_ff, self.hidden_size)
self.final_layer_norm = nn.LayerNorm(self.hidden_size)
self.dropout = nn.Dropout(0.1)
def forward(self, hidden_states, enc_self_mask):
residual = hidden_states
hidden_states = self.self_attn(
query_states=hidden_states,
key_value_states=hidden_states,
attention_mask=enc_self_mask
)
hidden_states = self.dropout(hidden_states)
hidden_states = residual + hidden_states
hidden_states = self.self_attn_layer_norm(hidden_states)
residual = hidden_states
hidden_states = self.activation_fn(self.fc1(hidden_states))
hidden_states = self.dropout(hidden_states)
hidden_states = self.fc2(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = residual + hidden_states
hidden_states = self.final_layer_norm(hidden_states)
return hidden_states이 구조는 트랜스포머 레이어 내의 FFN가 hidden_size 차원의 입력을 받아 d_ff 차원으로 확장한 후, 다시 hidden_size 차원의 출력으로 변환하는 과정을 반영한다. 이를 통해, 모델은 더 많은 특징을 학습할 수 있으며, 성능을 높이는 데 기여한다.
Positional Encoding
기존의 다른 방법론들은 각 단어의 임베딩 벡터를 바로 input으로 받지만, Transformer에서는 encoder와 decoder에서 임베딩 벡터의 값을 조정하여 input으로 받는다. 이를 Positional Encoding이라고 한다.
Transformer는 단어를 순차적으로 입력받지 않기 때문에, 단어의 위치 정보를 다른 방식으로 알려주어야 한다. Transformer는 해당 단어의 위치 정보를 임베딩 벡터에 더하여 모델의 최종적인 입력으로 사용한다.
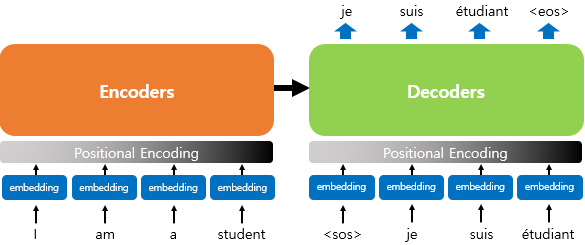
위 그림처럼, 단어들의 임베딩 벡터가 Transformer의 input으로 들어가기 전에 positional encoding 값이 더해진다.
Positional Encoding에는 다양한 종류들이 있지만, 기본적으로 sin, cos 함수를 이용하여 위치 정보를 전달한다.
=
=
- : 입력 문장에서 임베딩 벡터의 위치(e.g., I는 'I am a student'의 첫 번째 위치)
- : 임베딩 벡터 내 차원의 index
- : Transformer의 모든 layer의 output 차원을 나타내는 하이퍼 파라미터
Positional Encoding 방법을 이용할 경우에는 순서 정보가 보존된다. 예를 들어, 같은 임베딩 벡터(단어)라도 positional encoding 값을 더하게 되면 최종적으로 Transformer의 input 값은 달라진다.
Pytorch code of Positional Encoding
import torch
import matplotlib.pyplot as plt
import numpy as np
from torch import nn
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len, device):
"""
sin, cos encoding 구현
parameter
- d_model : model의 차원
- max_len : 최대 seaquence 길이
- device : cuda or cpu
"""
super(PositionalEncoding, self).__init__() # nn.Module 초기화
# input matrix(자연어 처리에선 임베딩 벡터)와 같은 size의 tensor 생성
# 즉, (max_len, d_model) size
self.encoding = torch.zeros(max_len, d_model, device=device)
self.encoding.requires_grad = False # encoding의 gradient는 필요 없음.
# 위치 indexing용 벡터
# pos는 max_len의 index를 의미함.
pos = torch.arange(0, max_len, device =device)
# 1D : (max_len, ) size -> 2D : (max_len, 1) size -> word의 위치를 반영하기 위해
pos = pos.float().unsqueeze(dim=1) # int64 -> float32 (없어도 됨.)
# i는 d_model의 index를 의미한다. _2i : (d_model, ) size
# 즉, embedding size가 512일 때, i = [0,512]
_2i = torch.arange(0, d_model, step=2, device=device).float()
# (max_len, 1) / (d_model/2 ) -> (max_len, d_model/2)
self.encoding[:, ::2] = torch.sin(pos / (10000 ** (_2i / d_model)))
self.encoding[:, 1::2] = torch.cos(pos / (10000 ** (_2i / d_model)))
def forward(self, x):
# self.encoding
# [max_len = 512, d_model = 512]
# batch_size = 128, seq_len = 30
batch_size, seq_len = x.size()
# [seq_len = 30, d_model = 512]
# [128, 30, 512]의 size를 가지는 token embedding에 더해질 것임.
#
return self.encoding[:seq_len, :]
Attention
Transformer에는 3가지의 Attention이 사용된다.
- Self-Attention of Encoder
- Masked Self-Attention of Decoder
- Co-Attention Between Encoder and Decoder.
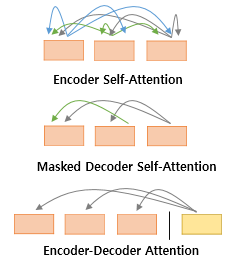
Self-Attention은 Query, Key, Value가 동일한 경우(이 때, Query, Key, Value가 동일하다는 것은 서로 값이 같다는 것이 아닌, 출처 자체가 Encoder에서만 나오거나, Decoder에서만 나오거나 한다는 것)를 말하며,
Co-Attention은 Query가 Decoder의 Vector, Key, Value가 Encoder의 Vector가 된다.
Encoder
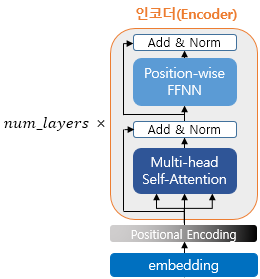
Encoder는 하이퍼 파라미터 num_layers에 따라서 해당하는 개수만큼 Encoder layers를 쌓는다. 하나의 lay를 기준으로 봤을 때에는 Self-Attention layer와 Feed-Forward Network layer로 나뉜다.
Self-Attention of Encoder
Self-Attention이란?
Attention 함수는 주어진 Query에 대해 모든 Key와의 유사도를 각각 구한다. 이 유사도는 weight로 사용하여 Key와 매핑되어 있는 Value와 가중합을 하게 된다.
-
기존 Attention:
= Query: 시점의 decoder cell에서의 hidden state
= Keys: 모든 시점의 encoder cell의 hidden states
= Values: 모든 시점의 encoder cell의 hidden states -
Self-Attention:
= Querys: 모든 시점의 decoder cell에서의 hidden states
= Keys: 모든 시점의 encoder cell의 hidden states
= Values: 모든 시점의 encoder cell의 hidden states
이처럼 기존 Attention에서 Query 는 decoder cell의 hidden state이고, 는 encoder cell의 hidden state이기 때문에 , 는 서로 다른 값을 가진다.
하지만, Self-Attention에서는 , , 가 모두 동일하다.
- : input sentence의 모든 단어 벡터들 (input sequence)
- : input sentence의 모든 단어 벡터들
- : input sentence의 모든 단어 벡터들
그렇다면, 왜 input sequence에 대해서 스스로 attention 과정을 거칠까?

위 이미지의 it은 animal일까, street일까?
Self-Attention은 위처럼 하나의 input sentence 내에서 특정 단어들끼리의 유사도를 구함으로써 위와 같이 it이 어떤 단어인지 파악할 수 있다.
Self-Attention은 encoder의 초기 input인 차원의 sequence를 바로 사용하는 것이 아니라, 더 작은 차원의 , , 벡터를 얻는다.
이는 _에 의해 결정된다.
예를들어, 초기 input sequence의 차원 = 과 Attention의 = 을 사용한다면, 각 , , 벡터의 차원은 = / = 가 된다.
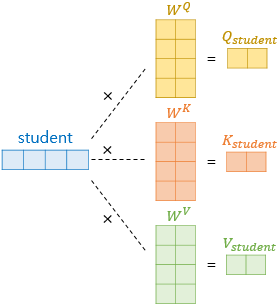
기존의 차원에서 차원으로 줄이기 위해 weight matrix ( X )를 곱해주면 된다.
위와 같은 과정을 거쳐 각 단어는 낮은 차원의 , , 로 변환된다.
[reference] https://velog.io/@sjinu/Transformer-in-Pytorch#5-%EC%9D%B8%EC%BD%94%EB%8D%94encoder
