Constitutional AI: Harmlessness from AI Feedback
Constitutional AI: Harmlessness from AI Feedback
AI 피드백으로부터 얻어낸 무해성
Abstract
- 레이블을 사용하지 않고, self-improvement 방식을 통해 무해한 AI assistant를 훈련시킴.
- 규칙 또는 원칙 목록이 유일한 human oversight이기 때문에, 이 방법을 ‘Constitutional AI’라고 부른다.
- 두 단계로 구성된다: supervised learning, reinforcement learning
- SL(Supervised Learning) phase
- initial 모델(→Pretrained LM)에서 샘플을 얻어서,
- 자체 비평(self-critiques)과 수정 사항(revisions)을 생성하고
→ 피드백 생성 - 수정 사항(revised response)에 대해 original(initial) 모델을 finetune한다.
→ 피드백 반영
- RL(Reinforcement Learning) phase
- fine-tuned 모델에서 샘플을 얻어서,
- 모델을 사용해 두 샘플 중 어떤 것이 더 나은지 평가한 다음,
→ AI 선호도 생성 - AI 선호도(preferences) 데이터셋으로 선호도 모델(PM)을 훈련시킨다.
- 그리고 나서 선호도 모델을 보상 신호(reward signal)로 삼아 RL 훈련을 진행한다.
- 즉, ‘RL from AI Feedback(RLAIF)’ (AI 피드백을 통한 강화학습)
- 결과적으로 유해한 질문에 대한 반대 의견(objections)을 설명함으로써 무해하지만 둘러대지 않는(회피하지 않는) AI assistant를 훈련시킬 수 있다.
- SL 및 RL 방식은 Chain-of-Thought 스타일의 추론을 활용하여 AI 의사 결정의 human-judged 성능과 투명성을 향상시킬 수 있다.
- 이러한 방법은 훨씬 더 적은 수의 (human)레이블로 AI 행동을 보다 정확하게 제어할 수 있게 한다.
- SL(Supervised Learning) phase
- critiques과 AI 피드백 모두 constitution(헌법)에서 도출된 몇가지 원칙에 의해 조종된다.
- SL 단계의 목표는
- 초기 모델의 성능 향상
- 잠재적 exploration 문제를 해결함으로써 RL 단계의 초기 행동을 제어하는 것
- RL 단계에서는
- 성능과 신뢰성 향상
Introduction
- AI의 능력이 인간을 능가하게 되더라도, 도움이 되고, 정직하며, 무해한 상태로 남아있는 AI 시스템을 훈련시키고 싶다.
- helpful, honest and harmless AI
- 인간의 도움 없이 AI의 모든 행동을 관리감독해서, 유해한 행동을 자동적으로 테스트하고 견고함을 향상시킬 수 있는 기술이 필요할 것이다.
- 바람직한 AI의 행동을 단순하고 투명한 형태로 encode해서, AI 의사 결정 과정을 더 쉽게 이해하고 평가하는 방법을 개발하는 것이 목표
- “without any human feedback labels for harms”
- Constitutional AI를 통해
- 유해함에 대한 그 어떤 인간의 피드백 레이블 없이
- 둘러대지 않으며 비교적 무해한 AI assistant를 훈련시킨다.
- Constitutional이라는 용어를 선택한 이유는
- 몇가지 원칙 또는 지시사항. 즉 헌법을 통해 덜 해로운 시스템 전체를 훈련시킬 수 있기 때문에
- 인간이 마땅히 따라야 할 규칙을 헌법으로 제정해 놓았듯이, AI가 지켜야 할 규칙을 헌법으로 정해 훈련시키자는 아이디어
- 일반적인 AI 개발 및 출시 과정에서 숨겨져 있거나 암묵적인 사실에 대해서도 원칙을 제정하는 것이 불가피하기 때문도 있음. 마치 헌법처럼.
- motivation
- AI를 감독하는 데에 AI를 사용하는 것에 대한 조금의 가능성을 연구해서 그것을 확장한다.
- 이전 연구인 ‘무해한 AI assistant’를 개선:
- 회피적 대응을 제거하고
- 유용함과 무해함 사이의 격차를 줄여서
- AI가 유해한 요청에 대한 반대 의견을 설명하도록 한다.
- AI 행동을 관리하는 원칙과 그 구현을 보다 투명하게 만든다.
- AI 목적 변경 시 새로운 인간의 피드백 레이블을 수집할 필요를 없애 반복 작업에 소모되는 시간을 줄인다.
1.1 Motivations
Scaling Supervision
- '감독 스케일링'이라는 용어를 사용하여 시스템이 보다 적은 양의 고품질 인간 감독으로 바람직한 방식으로 행동하도록 훈련할 수 있다.
- 적지만 고품질의 인간 개입을 통해 AI가 바람직한 방식으로 행동하도록
- 이 방식이 유용한 이유:
- 인간의 피드백을 일일이 수집하는 것보다 더 효율적
→ 인간은 집약적이고 고품질의 관리만 조금 하면 됨 - AI가 인간의 능력에 필적할 정도로 점점 강력해지고 있기 때문에, 이들을 관리할 수 있는 방안을 지금 당장 마련해야 함.
→ supervisor의 능력이 actor의 능력에 비례해 확장될 수 있고, supervisor가 의도된 목표에 도달한다면, 이것이 하나의 방안이 될 수 있음.
- 인간의 피드백을 일일이 수집하는 것보다 더 효율적
- scaling supervision은 AI 의사 결정을 더 자동화(그리고 상당히 모호하게)하는 것을 의미하기 때문에, 단점과 위험을 가질 수 있다.
- 의사 결정 과정을 더 알아보기 쉽게 하기 위해 chain-of-thought 추론 방식을 사용한다.
- 어떤 의미에서, RL의 보상 신호(Reward Signal)는 실제로 인간의 직접적인 감독이 아닌 AI 선호 모델(PM)에서 나오기 때문에, 인간 피드백으로부터의 강화 학습에 대한 연구는 이미 확장된 감독 방향으로 한 걸음 나아갔다.
- 그러나 RLHF는 일반적으로 수만 개의 인간 선호도 레이블을 사용한다.
- 인간의 개입을 완전히 제거한다기 보다는, 무해함에 대한 직접적인 인간의 감독을 대부분 제거한다.
- 거시적인 목표는 인간의 감독을 최대한 효과적으로 만드는 것!
A Harmless but Non-Evasive (Still Helpful) Assistant
- 모든 질문에 “I don’t know”로 대답하는 AI 비서는 물론 무해하겠지만, 전혀 쓸모가 없다.
- (인간 피드백을 활용한)이전 연구에서의 AI는 종종 논란이 될 만한 질문에는 답변을 거부했고, 유용성과 무해성 사이에 간격이 있음을 알게 됨.
- 게다가, 불쾌한 질문을 한 번 마주치면, 나머지 대화 동안 계속해서 회피적인 반응을 하기도 했다.
- 이것이 인간 피드백을 통한 강화 학습의 단점. 논란이 될 만한 질문에 답변을 회피하면 보상을 받았기 때문.
- 그래서 유용성과 무해성을 모두 가져가면서도 절대로 답변을 회피하지 않는 AI를 훈련시키는 것을 이 연구의 목표로 삼았다.
- 기존의 AI들이 비윤리적인 질문과 공격적인 언어에 대해 사용자를 좋은 방향으로 이끌려는 시도를 삼갔던 반면,
- 헌법적 AI는 ‘왜 그러한 질문을 거절해야 하는지’를 친절히 설명한다.
Simplicity and Transparency
- 널리 사용되는 인간 피드백을 통한 강화학습(RLHF) 방식은 사용된 레이블이 공개 되어있지 않고, 공개되더라도 아무도 이 수많은 정보를 요약하거나 이해할 수 없기 때문에 그리 도움이 되지 못한다.
- 그래서 이 상황(레이블이 효과적으로 쓰이지 못하는)을 3가지 방식으로 개선하고자 한다.
- 자연어로 된 간단한 지침 또는 원칙 리스트를 통해 훈련 목표를 인코딩
- chain-of-thought 추론을 통해 훈련 과정 동안의 AI 의사 결정 과정을 명시
- AI assistant가 유해한 질문을 왜 거절했는지 직접 설명하도록 훈련시킴
1.2 The Constitutional AI Approach
- 감독의 규모를 극단적으로 늘려 실험했고, 이것을 Constitutional AI(CAI)라고 부르기로 했다.
- 인간은 few-shot 프롬프팅을 사용한 몇가지 예시와 함께 원칙 리스트(헌법)을 통해서만 AI의 행동을 감독한다는 아이디어다.
- 이 원칙들이 모여 여기서 말하는 헌법을 형성한다.
- 훈련 과정은 두 단계로 구성되는데, 첫 번째 지도학습 단계는 모델을 “on-distribution” 상태로 만들고, 두 번째 강화학습 단계는 모델을 정제하며 성능을 크게 향상시킨다.
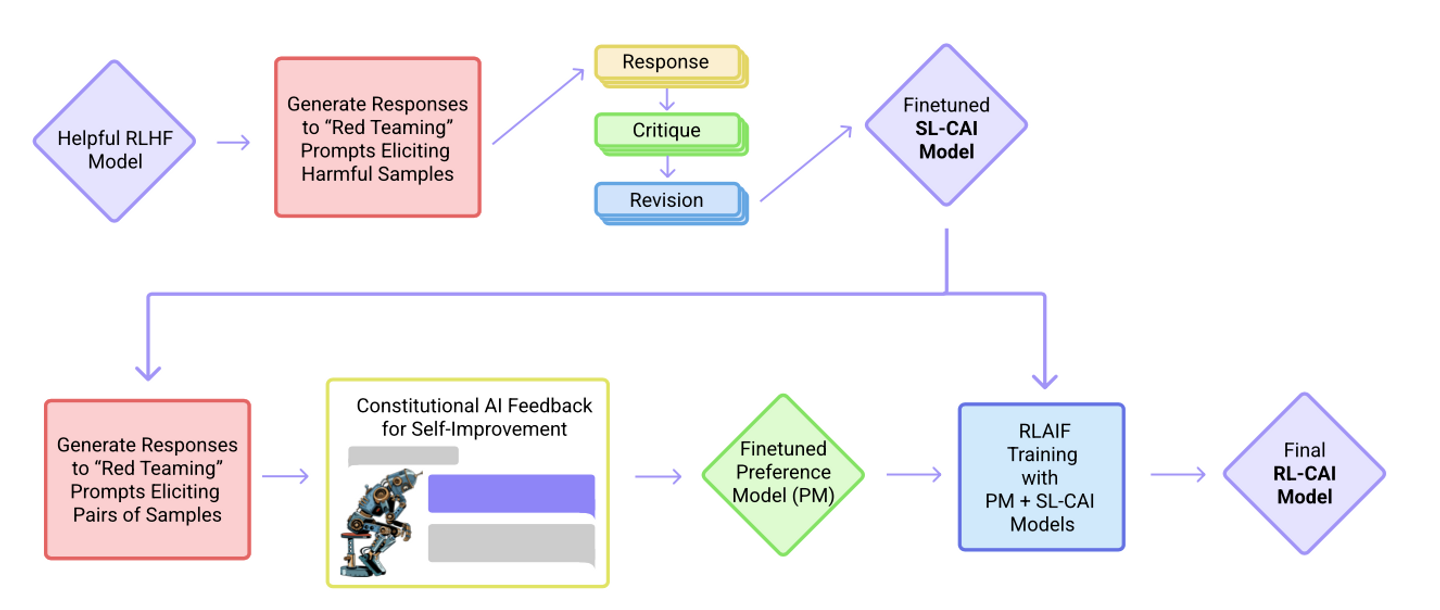
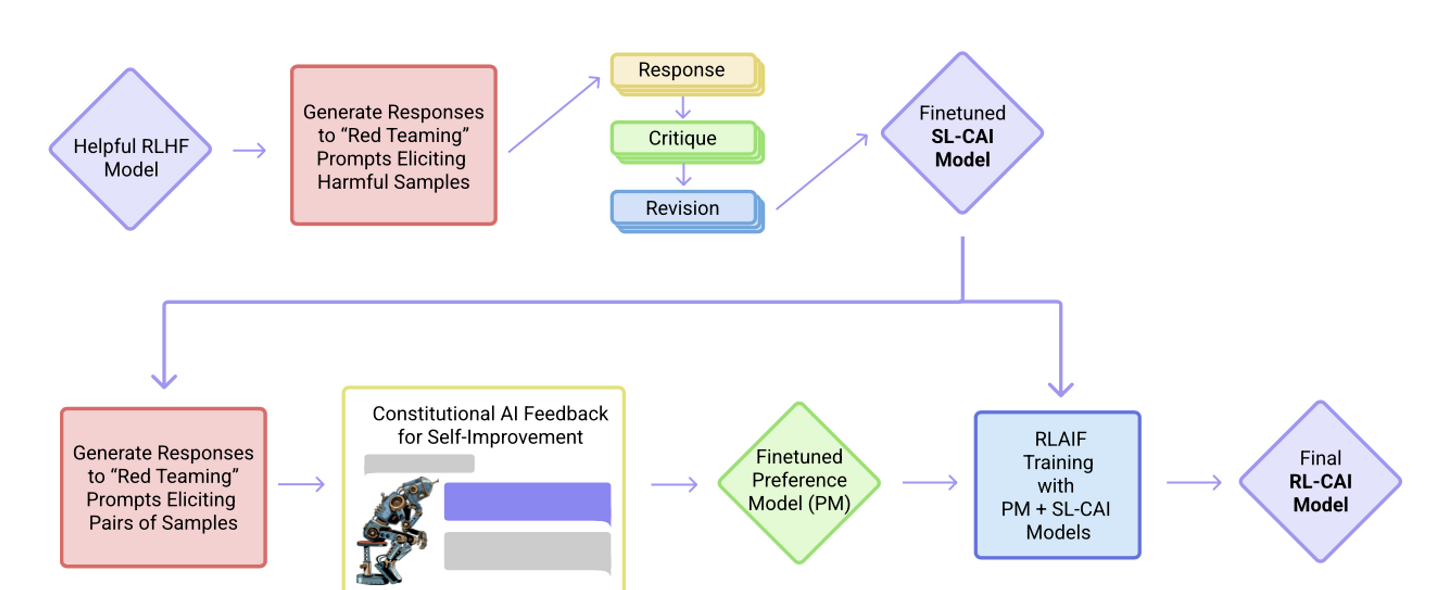
(Supervised Stage) Critique → Revision → Supervised Learning
- 첫번째로, 유용하게만 학습된(helpful-only) AI 비서를 이용해 유해한 프롬프트에 대한 응답을 생성한다.
- 이 초기 응답은 상당히 유해할 것(harmful and toxic)
- 다음으로 모델이 constitution의 원칙에 따라 초기 응답에 대해 비평(critique)하게 한다.
- 그리고 이 비평에 비추어 초기 응답을 수정한다.
- 어떤 시퀀스 안에서 반복적으로 응답을 수정하는데, 이 시퀀스의 각 단계에서 헌법으로부터 무작위로 원칙을 가져온다.
- 마지막으로, 최종 수정된 응답에 대한 SL을 통해 사전학습된 언어 모델을 미세조정한다.
- 이 단계의 핵심 목표는 모델 응답의 분포를 쉽고 유연하게 변경해 다음 RL 단계에서의 탐색의 필요성과 총 학습 시간을 줄이는 것
(RL Stage) AI Comparison Evaluations → Preference Model → Reinforcement Learning
- 이 단계는 무해함에 대한 사람의 선호를 ‘AI 피드백’으로 대체했다는 점을 제외하면 RLHF와 비슷하다. → RLAIF
- AI 피드백이란 AI가 일련의 원칙 목록에 따라 응답을 평가하는 것
- RLHF가 사람의 선호를 정제하여 단일 선호도 모델(PM)을 만드는 것 같이, 이 단계에서는 일련의 원칙에 대한 LM의 해석을 정제하여 하이브리드 human/AI PM을 만든다.
- We could mix human and AI labels for both harmlessness and helpfulness, but since our goal is to demonstrate the efficacy of the technique, we do not use human labels for harmlessness.
- 첫번째 단계에서 SL을 통해 훈련된 AI assistant를 가지고 시작
- 유해한 프롬프트 데이터셋의 각 프롬프트에 대한 한 쌍의 응답을 생성
- 각 프롬프트와 응답 쌍을 multiple choice question 형식으로 만든다.
- 헌법의 원칙에 따르면 어떤 응답이 best인지를 묻는 질문
- AI가 생성한 무해함에 대한 선호도 데이터셋이 만들어지고, 이것과 기존의 인간 피드백 기반 유용성 데이터셋을 섞는다.
- 이 comparison 데이터에 대한 선호도를 학습시키고, 결과적으로 어떤 샘플이 주어져도 점수를 할당하는 PM이 된다.
- 최종적으로, 이 PM에 대한 RL을 통해 첫번째 단계의 SL 모델을 미세조정한다.

중요한 것은 꺾이지 않는 런타임