Imagen Video: High Definition Video Generation With Diffusion Models 리뷰
https://arxiv.org/abs/2210.02303
Text-to-Video 생성 모델 Imagen Video에 대해 공부할 겸 논문을 읽어보았다.
간단히 말하면
1. T5를 이용해 텍스트를 인코딩한 다음,
2. Video Diffusion 모델로 저해상도의 비디오를 생성한 뒤,
3. Spatial and Temporal Super-Resolution Diffusion 모델을 통해 업샘플링 하여 최종적으로 1280x768의 고해상도 영상을 생성한다.
구글의 Text-to-Image 모델 Imagen의 비디오 생성 버전이니만큼 여기서도 Diffusion 모델을 사용했다.

Abstract
Video Diffusion 모델에 기초한 텍스트 기반 비디오 생성 시스템, Imagen Video를 제안한다.
Imagen Video는, 텍스트 프롬프트가 주어지면
1. base video generation model (-> Diffusion Model)
2. 일련의 상호배치된 spatial and temporal video super-resolution models
을 이용해 고화질의 비디오를 생성한다.
이전 연구인 Diffusion 기반 이미지 생성에서 얻은 것들을 비디오 생성에 적용시켰다.
-> Diffusion 기반 Text-to-Image 연구를 Video 생성에 맞게 확장한 것
-> Temporal Super-Resoulution, 즉 시간의 개념이 추가되었다. 이미지와 달리 비디오는 각 프레임들이 연속된 시간 안에서 순서를 가지고 배치된 것이기 때문에 시간의 흐름에 따른 처리를 해주기 위함.
빠르고 품질 높은 샘플링을 위해 classifier-free guidance를 사용한다.
Imagen Video는 1) 좋은 품질의 비디오 생성 뿐만 아니라, 여러 스타일과 3D Object에 대한 이해를 통한 2) 다양한 비디오 및 텍스트 애니메이션 생성을 포함해 3) 높은 수준의 controllability와 world knowledge를 가진다.
1 Introduction
Generative Modeling은 DALL-E 2, Imagen, Parti, CogView, Latent Diffusion 등 Text-to-Image 시스템과 함께 엄청나게 발전했는데, 이 중에서도 Diffusion 모델은 다수의 Generative Modeling 태스크에서 주목할만한 성과를 거뒀다. 태스크의 예로 Density Estimation, Text-to-Speech, Image-to-Image, Text-to-Image 등이 있다.
이 연구는 텍스트로부터 비디오를 생성하는 것이 목표로, Diffusion 모델이 이 분야에서 적당한 해상도의 비디오 생성에 대한 가능성을 보여줬다. 함께 언급되는 Make-A-Video 모델 또한 Diffusion 모델을 사용해 Text-to-Video 모델링을 했지만, Make-A-Video는 사전학습된 Text-to-Image 모델을 기반으로 한다는 것이 차이점이다.
Imagen Video는 Video Diffusion 모델에 기반한 Text-to-Video 생성 시스템이며, 높은 frame fidelity와 강한 temporal consistency, 그리고 deep language에 대한 이해를 가진 고화질 비디오를 생성할 수 있다.
이전 연구의 결과물은 초당 24프레임으로 구성된 64프레임 128x128 비디오였던 반면, Imagen Video는 초당 24프레임으로 구성된 128 프레임 1280x768 고화질 비디오로 업그레이드 했다.
-> 계산해보면 총 128 프레임에 초당 24프레임이므로 최대 약 5.3초의 비디오 생성 가능
간단한 아키텍처를 가지고 있다.
- A Frozen T5 Text Encoder
- A Base Video Diffusion Model
- Interleaved Spatial and temporal Super-Resolution Diffusion Models
Key Contributions:
- 고화질 비디오를 생성하는 Diffusion 비디오 모델들의 간결성과 효율성을 입증한다.
- Frozen Encoder Text Conditioning, Classfier-free Guidance의 효율성과 같은 Text-to-Image 분야의 최근 연구 결과가 비디오 생성으로 Transfer 됨을 확인한다.
- 1) Sample의 품질을 위한 V-Prediction 파라미터화의 효율성, 2) 텍스트에 따른(text-conditioned) 비디오 생성을 위한 Guided Diffusion 모델의 점진적인 Distillation의 효율성과 같이 일반적으로 Diffusion 모델에 영향을 비치는 비디오 Diffusion 모델에 대한 새로운 발견을 보인다.
- 3D Object에 대한 이해, 텍스트 애니메이션 생성, 다양한 스타일의 비디오 생성과 같은 Imagen Video의 정성적 제어가능성(qualitative controllability)을 입증한다.
2 Imagen Video
Imagen Video는 비디오 Diffusion 모델이며, 7개의 sub-models로 구성된다.
각 sub-model들은 다음과 같은 일을 수행한다:
1. Text-Conditional Video Generation (텍스트 기반 비디오 생성)
2. Spatial Super-Resolution (공간적 초해상도)
3. Temporal Super-Resolution (시간적 초해상도)
결과적으로 Imagen Video는 초당 24프레임으로 구성된 128 프레임(약 5.3초)의 1280x768 고해상도 비디오를 생성한다. (약 126 million(1억 2600) 픽셀)
2.1 Diffusion Models
Imagen Video는 Diffusion 모델을 연속된 시간(비디오)에 적용한 것이다.
Diffusion 모델은 Latent 로 이루어진 Latent Variable 모델이며, 는 를 따르는 데이터 에서 시작하는 Forward Process 를 따른다.
여기서 Forward Process는 Markovian 구조를 만족하는 Gaussian Process이다.
- 는 노이즈 schedule을 정한다.
- log signal-to-noise-raito 는 에 따라 단조 감소 (until )
- cosine noise schedule의 연속 시간 버전을 사용
- Forward Process를 시간의 역방향에 맞춰 학습한 모델이 생성 모델이 된다.
( 에서 시작해 에서 끝남, 를 생성)
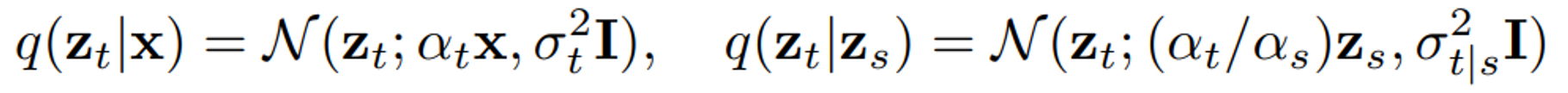
Generative Modeling by Estimating Gradients of the Data Distribution과 후속 연구에서처럼, 간단한 noise-prodiction loss를 최소화함으로써 모델을 최적화했다.
- notation을 단순화하기 위해 에 대한 의존도를 줄여나감
- 실제로는, 이나 를 직접적으로 예측하기 보다는 v-parameterization의 관점에서 모델을 파라미터화 할 것이다.
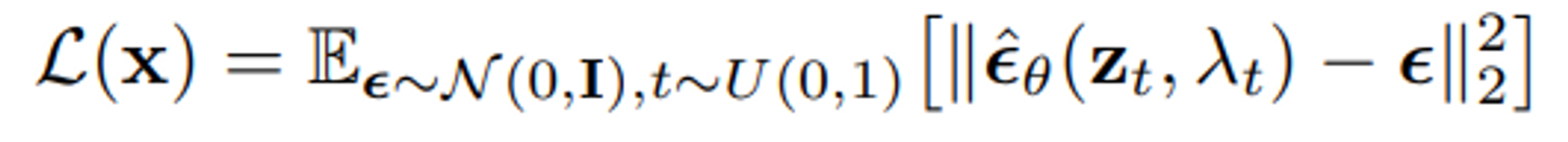
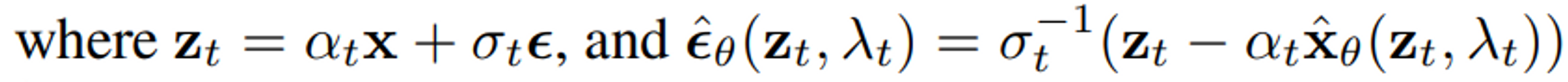
조건부 생성 모델링(Conditional generative modeling)을 위해, 와 함께 conditioning information 를 모델에 전달하며, ( 형태로) spatial and temporal super-resolution을 위해 이러한 Conditional Diffusion 모델을 사용한다. 이 경우 는 텍스트와 더불어 이전 단계의 저해상도 비디오에 대한 정보, 에 더해지는 Conditioning Augmntation의 강도에 대한 정보인 도 가진다.
2.2 Cascaded Diffusion Models and Text Conditioning
Cascaded diffusion models for high fidelity image generation는 고해상도의 결과를 출력하기 위해 Diffusion 모델의 scaling에 사용되는 효과적인 방법으로, DALL-E2 (Hierarchical TextConditional Image Generation with CLIP Latents)에서도 사용된 방법이다.
Cascaded Diffusion Model(계단식 확산 모델)은 일단 저해상도의 이미지 또는 비디오를 생성한 다음, 일련의 Super-resolution Diffusion 모델을 통해 순차적으로 해상도를 증가시켜 나가는 방식이다.
- 또한 각 하위 모델을 비교적 단순하게 유지하면서 매우 높은 차원의 문제를 모델링할 수 있다.
- Imagen에서도 Cascaded Diffusion Model과 함께 large frozen language model의 텍스트 임베딩을 조건화함으로써 text description으로부터 고품질의 1024x1024 이미지를 생성할 수 있음을 보였다.
- 이것을 비디오 생성에 확장한 것
추가 예정...
