
안녕하세요🫡
오늘은 Generative AI 시리즈의 두 번째 이야기, 초거대 언어 모델 GPT-3에 대해 함께 알아봅시다.
INTRO
💫 <사피엔스>의 작가 '유발 하라리' 의 실험

모두 어디선가 한 번쯤 이 책을 본 적이 있을 겁니다.😲
바로 히브리대 역사학과 교수 '유발 하라리' 의 세계적인 베스트셀러 <사피엔스>라는 책인데요. 뜬금없이 이 책을 소개하는 이유는, 2022년 10월에 출간 소식이 전해진 '사피엔스' 10주년 특별판에 추가된 📜서문 때문입니다.

"인공지능의 시대, 새로운 이야기가 필요하다"라는 제목의 서문에는 그간 인류의 기원과 잠재력을 탐구해온 하라리의 고민을 그대로 압축해 놓은 듯한 내용이 담겨 있습니다.
“나는 다시 출발점으로 돌아가 상상 속의 질서와 지배적 구조를 창조해내는 인류의 독특한 능력을 재검토해야겠다는 생각이 들었다.” -'사피엔스' 특별판 서문 일부
하라리가 '사피엔스' 특별판을 펴 내면서 느꼈던 바가 잘 정리되어 있죠. 이 서문은 누가 봐도 하라리가 쓴 것으로 보입니다.
❗ 하지만, 실제 하라리가 쓴 서문은 위 서문 바로 아래에 붙어 있었습니다.
"위 글은 나, 유발 노아 하라리가 쓴 것이 아니다. 나처럼 쓰라는 주문을 받은 강력한 인공지능이 쓴 것이다."
사실, 하라리는 'AI가 나의 글쓰기를 대체할 수 있을까' 라는 질문에 대한 답을 얻기 위해 실험을 하나 했습니다. '<사피엔스> 출간 10주년을 기념하는 서문을 "하라리 스타일"로 써 달라'고 GPT-3에게 주문한 것이죠. GPT-3는 하라리의 책과 논문, 인터뷰 등을 끌어모아 서문을 완성했고, 그 결과는 놀라웠습니다.
위 사진에서 보셨다시피, AI가 썼다고 하기에는 꽤나 자연스러운 글이 완성되었고,
어떠한 수정없이 <사피엔스> 10주년 특별판의 서문으로 출간되었습니다.
[자료 출처
https://www.hankyung.com/life/article/2022101737901
https://www.aitimes.com/news/articleView.html?idxno=147427]
💫 텍스트 생성 모델 GPT-3
GPT-3가 어떤 모델인지 🍊감이 조금 오시나요?
맞습니다. GPT-3는 텍스트 생성 AI 모델입니다.
Generative Pre-trained Transformer 3 의 약자로, 사전 학습된 Transformer를 이용하여 텍스트를 생성하는 모델이라고 할 수 있습니다.
지난 번 Generative AI의 첫번째 이야기로 다루었던 GAN을 비롯해 GPT-3 이전의 다른 생성 모델들과 다른 점은 GPT-3가 🙆🏻♀️'초거대' 모델이라는 점입니다.
2020년 OpenAI가 발표한 최초의 초거대 AI 모델 GPT-3를 기점으로 수많은 대기업에서 앞다투어 초거대 AI 모델을 발표하기도 했었죠. 대표적으로 구글의 Switch Transformers, 카카오의 KoGPT, 네이버의 HyperCLOVA가 있습니다.
이 정도면 GPT-3가 초거대 AI 모델 시장에 불을 지핀 도화선과 같은 역할을 했다고 볼 수 있을 것 같습니다.
자, 이제 GPT-3가 도대체 무엇인지, 🙆🏻♀️'초거대 모델'을 키워드로 삼아 자세히 들여다봅시다.
1. 초거대 AI 모델
💡 '초거대' AI 모델, 무엇이 거대하다는 걸까요?
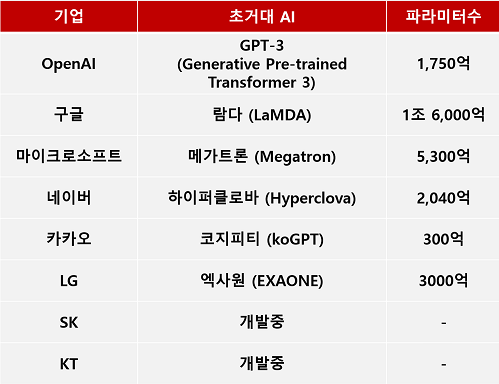
👏🏻 바로, 딥러닝 모델의 '파라미터 수'입니다.
[출처: https://www.2e.co.kr/news/articleView.html?idxno=302260]
초거대 AI의 시작은, '딥러닝 모델에 최대한 많은 데이터를 학습시켜보자'는 시도에서 비롯되었습니다. 그래서 대규모 데이터를 입력으로 받아 스스로 학습할 수 있는 모델을 개발하게 된 것이죠.
실제로 GPT-3는 인터넷에서 얻을 수 있는 거의 모든 텍스트 데이터를 이용해 사전 학습 되었습니다. 커먼 크롤링(Common Crawling), 위키피디아 등으로부터 얻은 텍스트를 포함해 학습에 사용된 데이터셋이 무려 3,000억 개라고 합니다.
여기서, 모델에 입력되는 데이터가 늘어나면 당연히 모델 내에서 일어나는 연산의 수도 많아지겠죠?
🌀파라미터가 바로 그 연산에 쓰이는 모델 내부의 변수입니다.
알고리즘을 통해 각 파라미터의 값을 최적화하는 것이 곧 우리가 흔히 딥러닝 모델을 학습시킨다고 하는 것과 같은 말인 셈입니다.
초거대 AI는 딥러닝 모델의 파라미터 수를 수천억 개에서 수조 개까지 늘린 것을 말합니다. 위의 자료를 보면, 우리의 GPT-3는 1,750억개, 네이버의 Hyperclova는 2,040억개, 구글의 LaMDA는 1조 6,000억개나 되는 파라미터를 가진 것을 볼 수 있습니다.
🙆🏻♀️초거대 AI의 파라미터가 다른 AI 모델들과 비교해 얼마나 많은 것인지 잘 와닿지 않는다고요?
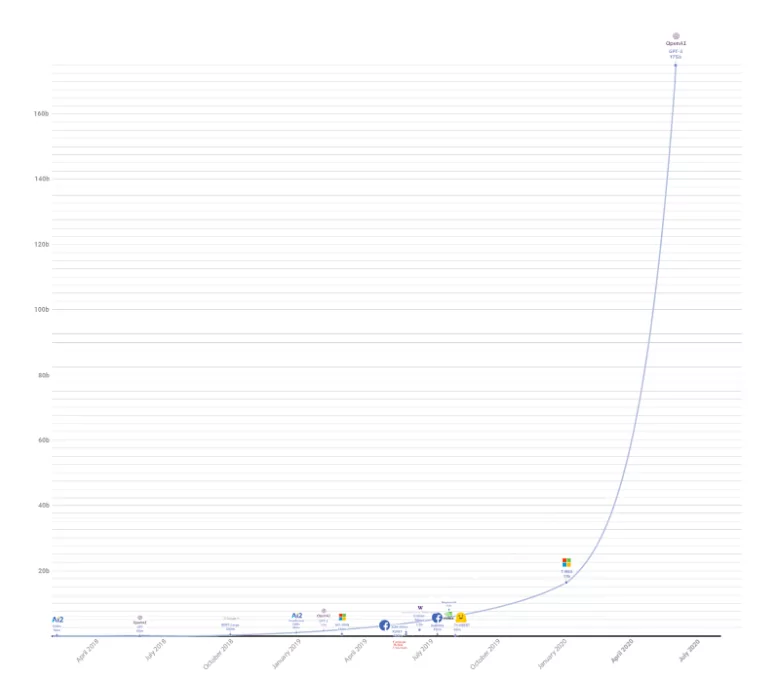 위 그림의 오른쪽 상단에 홀로 있는 것이 OpenAI의 GPT-3입니다.
위 그림의 오른쪽 상단에 홀로 있는 것이 OpenAI의 GPT-3입니다.
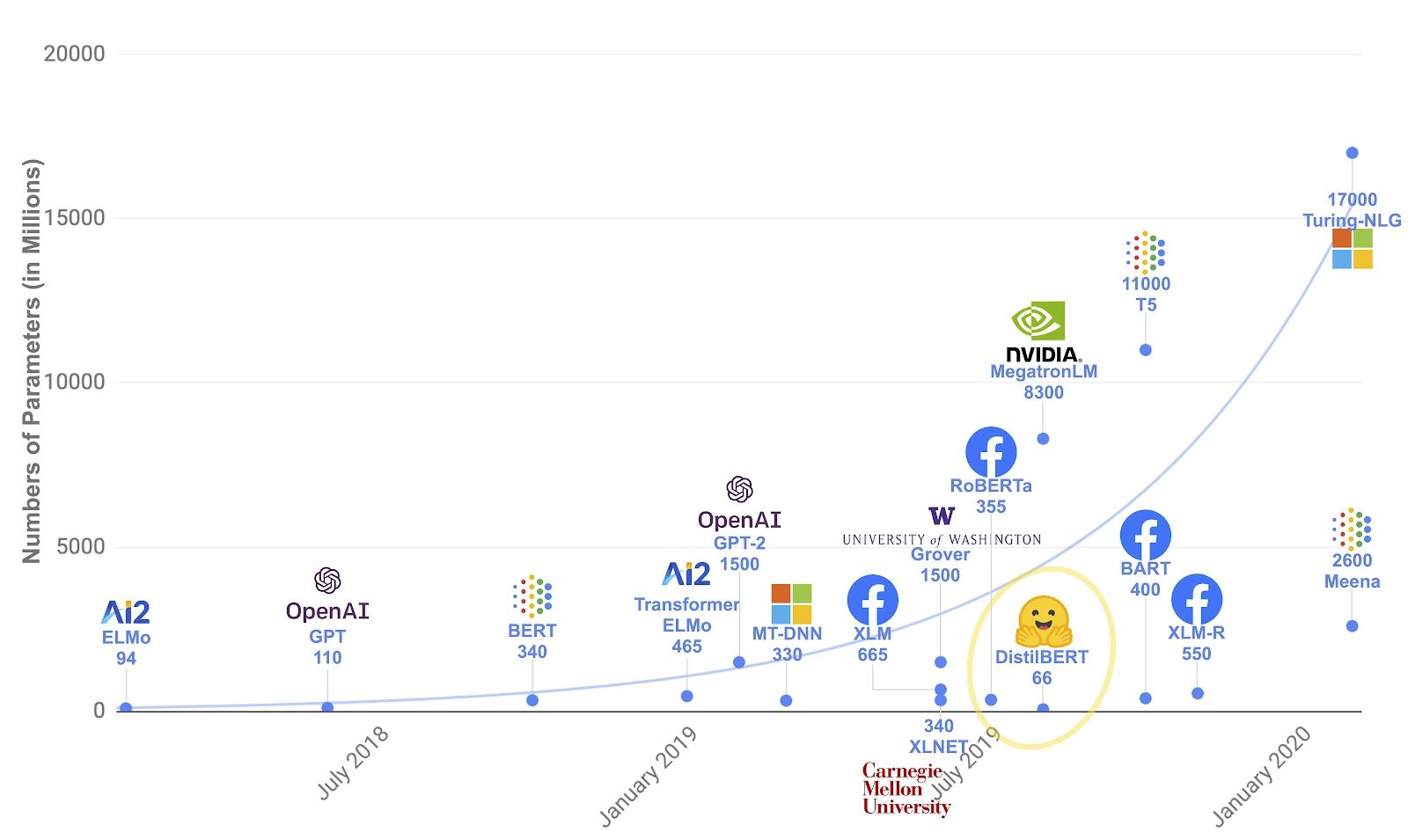 밑부분을 확대하면 이렇습니다. GPT-3의 전신인 GPT, GPT-2도 보이고, 구글의 BERT, Microsoft의 Turing-NLG도 있네요. GPT-3가 얼마나 혁신적으로 파라미터 수를 늘렸는지 확인할 수 있습니다.
밑부분을 확대하면 이렇습니다. GPT-3의 전신인 GPT, GPT-2도 보이고, 구글의 BERT, Microsoft의 Turing-NLG도 있네요. GPT-3가 얼마나 혁신적으로 파라미터 수를 늘렸는지 확인할 수 있습니다.
여담이지만, GPT-3의 파라미터 수가 사람 뇌의 뉴런 개수(약 1,000억 개)보다 많다고 합니다.
[이미지 출처: https://research.aimultiple.com/gpt/]
이렇게 파라미터의 수를 늘리는 이유는, 이론상 파라미터 수가 많을수록 AI의 지능이 높아지고, 더 정교한 학습을 할 수 있기 때문입니다.
정리하자면,
'초거대' 모델이란, 딥러닝 모델의 파라미터 수가 '초거대'하다는 것이고,
모델의 파라미터 수가 많을수록 AI의 성능이 좋아지는 경향을 보인다고 할 수 있겠네요.
물론, 무작정 모델의 크기만 계속 키우는 것에는 한계가 있습니다. 학습에 들어가는 비용이 너무 커지기 때문이죠. 참고할만한 글
2. GPT-3의 텍스트 생성 원리
💡 대규모 데이터와 1,750억 개나 되는 파라미터를 가지고 GPT-3는 어떻게 텍스트를 생성할까요?
기본적으로 GPT-3는 언어 모델(Language Model)입니다. 언어 모델이란, 쉽게 말해 기계가 인간의 언어를 이해하고 구사할 수 있도록하는 AI 모델입니다. 우리가 일상 생활에서 볼 수 있는 예로, ‘시리’나 ‘빅스비’와 같은 음성 비서, 챗봇 또는 자동 번역 등이 AI 언어 모델로 만들어진 기술입니다.
조금 더 구체적으로 살펴 보면, AI 언어 모델이 하는 일은 단어들로 이루어진 텍스트(시퀀스)에 확률을 할당하는 일이라고 할 수 있습니다. 어떤 텍스트가 주어졌을 때, 언어 모델이 각 단어에 확률을 부여함으로써 다음 단어를 예측할 수 있도록 하는 것이죠. 이렇게 다음에 올 단어를 하나씩 예측하는 과정을 반복해 가장 자연스러운 단어 시퀀스를 찾아내는 작업을 언어 모델링(Language Modeling)이라고 합니다.
단어 시퀀스에 확률을 부여하는 일이 왜 필요할까요? 어떤 텍스트가 주어졌을 때, 우리 인간은 그간 살아오면서 축적해 온 경험을 통해 해당 텍스트의 맥락을 자연스럽게 파악하는 능력을 기본적으로 갖추고 있습니다. 그래서 특별한 노력을 들이지 않아도 맥락을 통한 유추가 가능하죠.
❓ 예를 들어, “딥다이브는 흥미로운 딥러닝 논문들을 ____.” 라는 문장이 주어졌을 때,
빈 칸에 가장 적절한 말은 무엇일까요?
✅ 1. 소개한다
✅ 2. 파괴한다
✅ 3. 먹는다
✅ 4. 좋다
✅ 5. 아니다
1번 “소개한다”가 가장 자연스럽습니다. 너무 쉽죠?😅 이제 컴퓨터에게 같은 문제를 냈다고 생각해봅시다. 컴퓨터에게는 모든 텍스트가 그저 0과 1로 이루어진 코드에 불과할 뿐입니다. 숫자로 표현된 명확한 기준이 있어야 유추가 가능하죠. 그래서, 학습을 통해 단어에 확률을 부여하는 것입니다. 이 확률이 컴퓨터가 ‘자연스러움’을 판단할 척도가 되어주는 것이죠.
만일 학습이 된 언어 모델에게 위 문제가 주어진다면, 해당 모델은 먼저 빈 칸에 들어갈 후보 단어들이 빈 칸에 올 확률을 각각 부여할 것입니다. 1번 ‘소개한다’는 95%, 2번 ‘파괴한다’는 23%, … 등등 모든 후보에 대해 확률을 계산한 뒤 가장 높은 확률을 가진 후보를 채택할 것입니다. 학습이 잘 된 모델이라면 당연히 1번 ‘소개한다’를 가장 높은 확률로 예측하겠죠?
정리하자면, 언어 모델 GPT-3가 텍스트를 생성하는 방식은 주어진 시퀀스를 바탕으로, 확률에 기반해, ‘다음에 올 단어를 예측’하는 것입니다. N개의 단어를 가지고 N+1번 째에 올 단어를 예측하는 것이죠. 이해를 돕기 위해, GPT-3가 하는 일을 아이폰의 자동 완성 기능에 비유할 수 있습니다. 자동 완성 배너에 뜨는 단어 중 가장 자연스러운(높은 확률을 가진) 단어만을 계속 선택해 나가며 텍스트를 완성해 나가는 것과 같은 일을 하는 것입니다.
[출처: https://support.apple.com/ko-kr/HT207525]
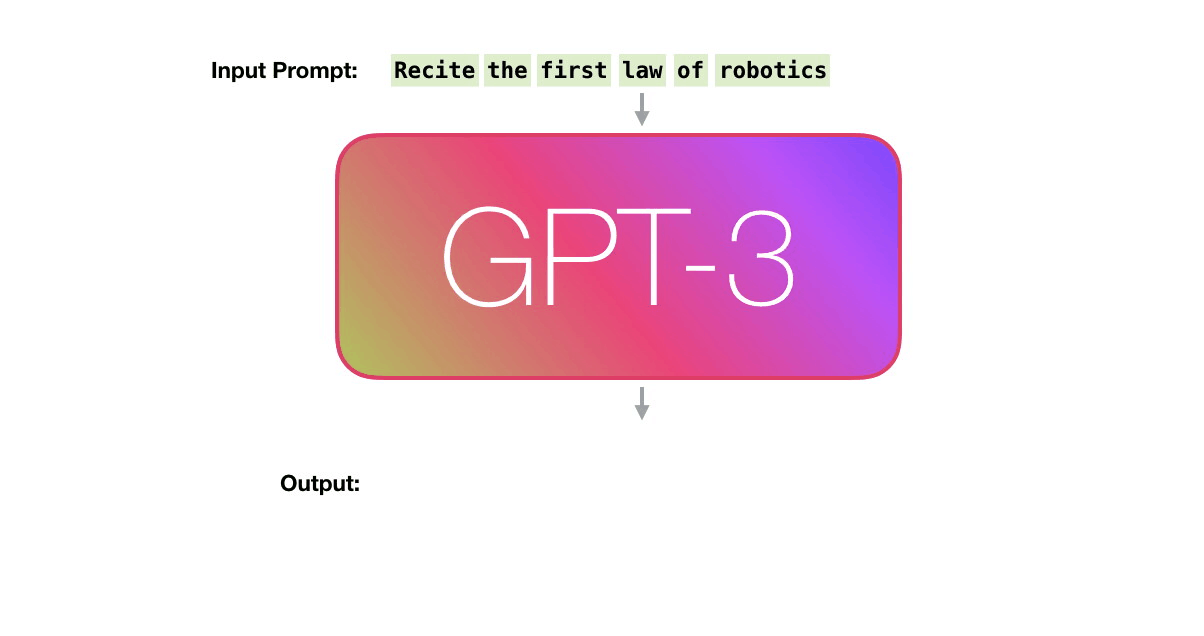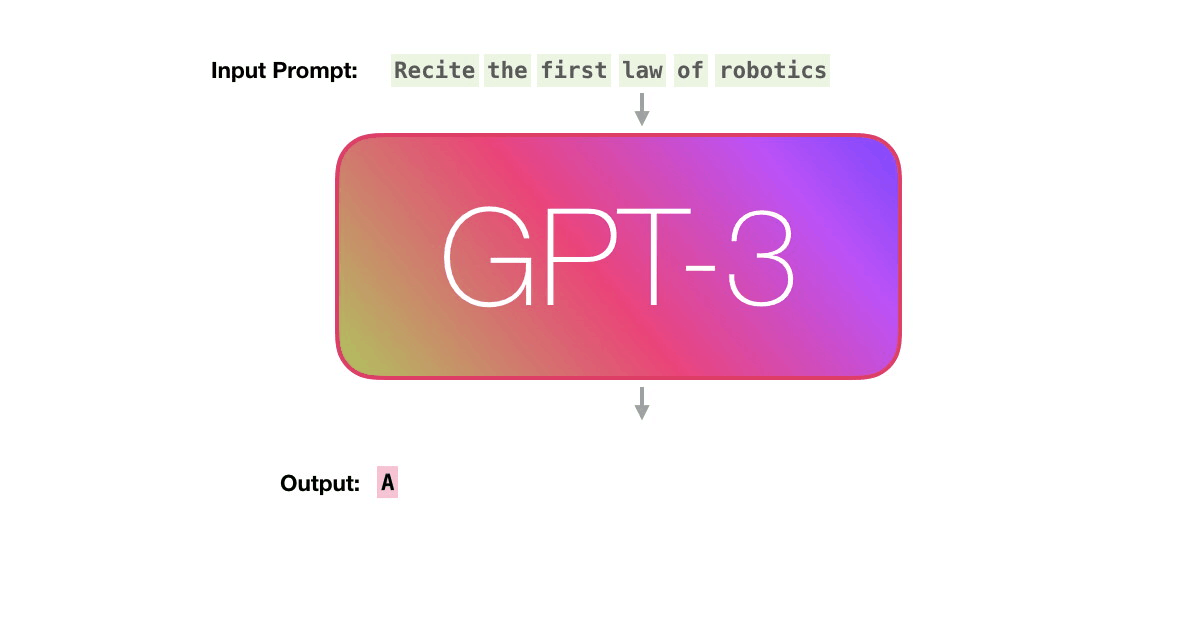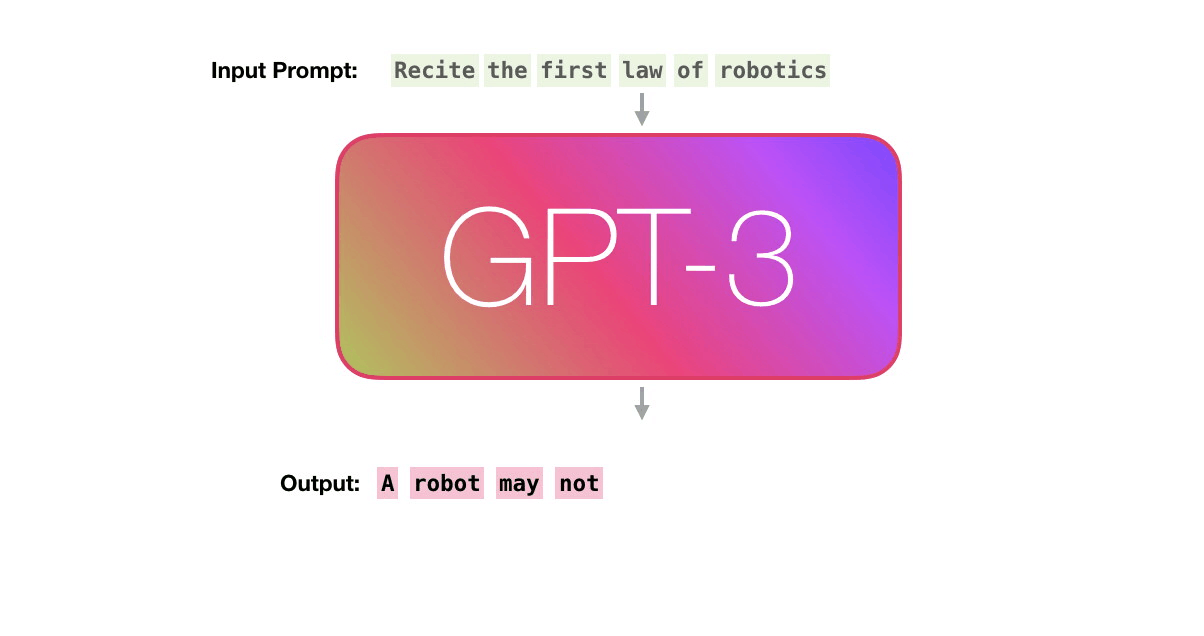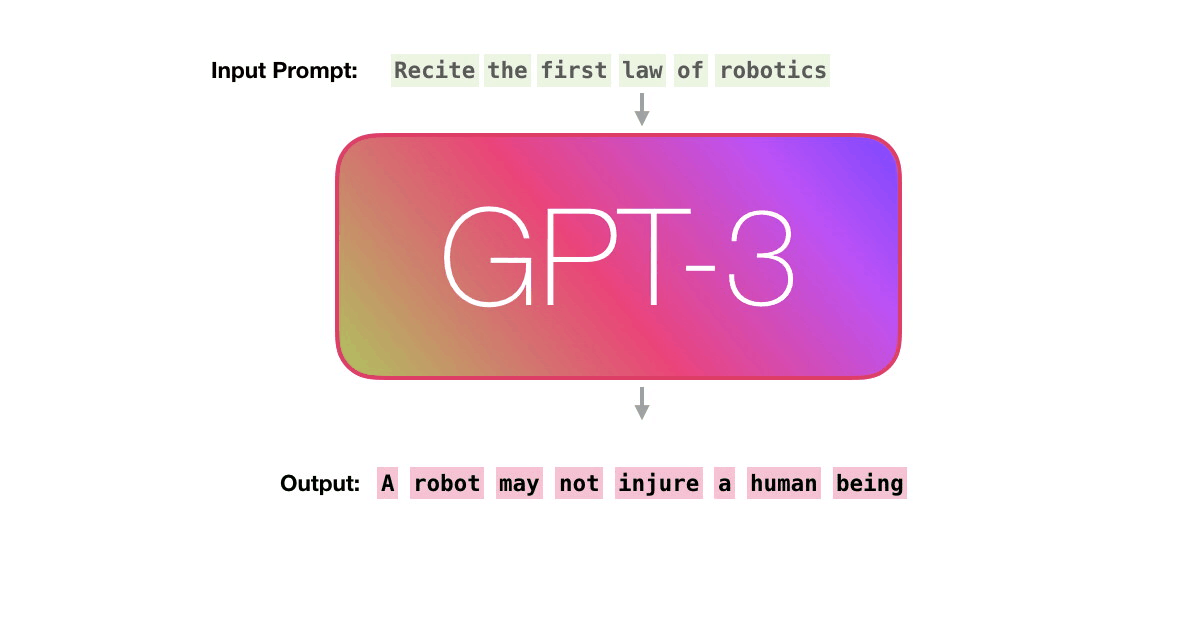
3. GPT-3의 기반, Transformer 구조
앞서 GPT-3를 비롯한 언어 모델들이 확률을 기반으로 다음에 올 단어를 예측한다고 말씀드렸습니다. 그렇다면, GPT-3는 이 확률을 어떻게 계산하는 걸까요? 그 핵심은 GPT-3의 기반인 Transformer에 있습니다. Transformer는 2017년 구글이 발표한 논문 ‘Attention Is All You Need’에서 소개된 딥러닝 모델로, 현재 자연어 처리 분야에서 매우 중요한 역할을 하고 있는 모델 중 하나입니다.
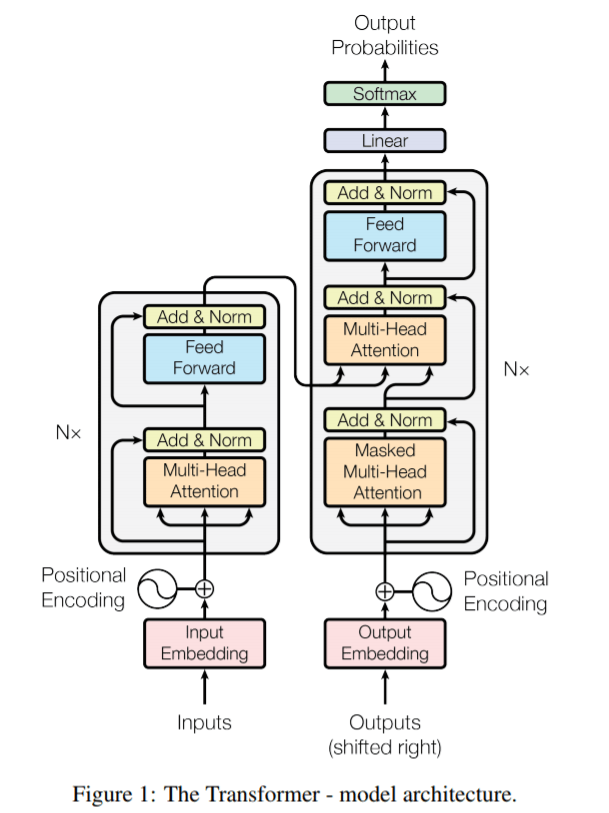
☝🏻 먼저, Transformer는 크게 인코더(왼쪽)와 디코더(오른쪽) 두 부분으로 구성됩니다. 인코더에서는 텍스트 데이터를 입력으로 받아 이를 벡터화 시키고, 디코더에서는 벡터화 된 정보를 바탕으로 다른 형태의 텍스트 데이터를 출력합니다. 우리가 살펴보고 있는 GPT-3는 이 중에서도 디코더만을 쌓아올린 것인데요. 디코더만을 사용했다는 것은, 충분한 양의 데이터를 사전에 학습시킨 뒤, 새로운 샘플이 들어왔을 때 벡터화 된 내용을 바탕으로 그에 해당하는 텍스트를 새로 생성해내는 데에 초점이 맞춰져 있다고 할 수 있습니다. 참고로 벡터화(Vectorizing)란, 쉽게 말해 텍스트 데이터를 인간이 이해하기 쉬운 형태(텍스트)에서 딥러닝 모델이 이해하기 쉬운 형태(벡터)로 변환하는 과정을 말합니다.
✌🏻 Transformer의 또 다른 특징으로 Attention 기법이 있습니다. Attention이란, ‘해당 시퀀스의 어느 부분에 집중할 것인가’와 관련이 있습니다. 사람이 텍스트 번역을 할 때에도, 매 순간 모든 단어에 집중하지 않죠. 현재 번역하려는 단어와 관련있는 단어에 가장 집중하면서 번역을 할 것입니다. 바로 이 점을 이용한 것이 Attention 기법입니다. GPT 계열 모델에서 사용하는 Attention은 Self Attention을 여러 번 수행하는 것을 의미하는 Multi-Head Attention인데요. Self Attention은, 간단히 말해 시퀀스 내 단어들 간의 연관성을 파악해 점수로 나타내는 작업을 말합니다. 이 점수(Attention Score)를 통해 현재 시점에서 어떤 단어에 집중해야 할지 알 수 있게 되는 것이죠.
이제 위 그림을 자세히 보면, Transformer의 디코더 안에 Embedding, Positional Encoding, Multi-Head Attention, Feed Forward등 여러 layer가 있는 것을 볼 수 있습니다. 어떤 텍스트를 입력하면, 이 layer들로 구성된 N개의 디코더 블록들을 거쳐 최종적으로 예측된 확률, 즉 Output Probabilities가 되어 나오는 것입니다. 우리의 목표는 GPT-3에 대한 전반적인 이해이므로, Transformer에 대한 설명은 여기서 마무리 하겠습니다🙂
💡 중요한 것은 Transformer의 디코더가 일련의 layer들을 거쳐 최종적으로 뒤에 올 단어에 대한 예측 결과를 출력한다는 것입니다!
4. GPT-3가 일으킨 변화
GPT-3는 특정한 목적에 맞춰 설계된 AI가 아니라, 어떠한 목적의 작업에도 준수한 성능을 보이는 범용 인공지능(AGI, Artificial General Intelligence) 모델입니다. 이는 바둑을 두는 일에만 특화된 ‘알파고’와 달리, 인간과 비슷한 지능으로 사고하고 판단하며 폭 넓은 작업을 수행하는 AI라는 뜻입니다.
GPT-3 이전의 사전 학습 모델들에서는, 수행하고자 하는 작업에 맞게 추가로 학습을 진행하는 Fine-Tuning(미세 조정) 과정이 필요했는데요. 이를 위한 데이터셋을 만드는 데에도 상당한 자원과 비용이 들어간다는 문제점이 있었습니다.
그러나 GPT-3는 ‘초거대’ 모델이라는 명색에 맞게 ‘초거대’한 데이터셋을 이용해 학습되었기 때문에, Fine-Tuning을 거치지 않고, 몇가지 예시만 받아 바로 작업을 수행하는 Few-Shot Learning 방식으로도 웬만한 성능을 낸다는 이점을 가집니다. 이를 통해 수행하고자 하는 특정 작업, 즉 Downstream Task를 어떻게 수행할 것인가에 있어 모델에게 적절한 질문을 함으로써 답을 이끌어내는 프롬프트 엔지니어링(Prompt Engineering)의 중요성 또한 새롭게 대두되었습니다.
‘프롬프트’ 하면 떠오르는, 요즘 가장 화제가 되고 있는 모델이 있습니다. 2022년 11월 공개되어 현재 가장 많은 화제와 논란을 불러 일으키고 있는 대화형 인공지능 ChatGPT인데요. 이 또한 프롬프트에 텍스트를 입력하면, 그에 대한 답변이 출력되는 방식이죠. ChatGPT도 GPT-3를 기반으로 만들어졌습니다.
물론, 엄밀히 말하면 GPT-3를 서비스 가능한 챗봇으로 만들기 위해 오류를 교정하고, 편향을 완화해 업그레이드한 GPT-3.5를 기반으로 만들어졌다고 할 수 있죠. 어쨋든, 마치 사람이 쓴 것 같은 글을 만들어내며 연일 세상을 놀래키고 있는 ChatGPT의 저변에도 GPT-3가 있습니다.
미국의 유니콘 기업 Jasper(재스퍼)는 GPT-3를 기반으로 카피라이트를 만들어주는 콘텐츠 생성 도구 Jasper.ai를 2021년 개발했습니다. 사용자는 Jasper 서비스를 이용해 블로그 글, 소셜 미디어 게시물, 이메일 등 개인 또는 기업의 디지털 콘텐츠에 포함될 텍스트를 생성할 수 있다고 하는데요. 미국의 비즈니스 전문 매체 잉크(Inc.)는 2022년 8월, Inc.5000을 통해 Jasper를 ‘가장 빠르게 성장하는 미국의 민간 기업 중 하나’로 선정하기도 했습니다. 이는 GPT-3를 기반으로 한 서비스가 단순한 사실을 전달하는 텍스트를 넘어, 창작성을 요하는 분야에서도 효율적으로 텍스트를 생성해 낼 수 있음을 뜻합니다.
국내에서도 GPT-3를 이용한 한국어 모델 개발이 이루어졌습니다. 대표적으로 카카오브레인의 KoGPT와 SK텔레콤의 에이닷이 있습니다. KoGPT는 카카오의 자회사인 카카오브레인에서 21년 11월 발표된 모델이고, 에이닷은 SK텔레콤에서 22년 5월 발표된 모델로, 두 모델 모두 GPT-3의 ‘한국어 특화 버전’이라고 할 수 있습니다. GPT-3가 영어로만 사전 학습되었기 때문에, GPT-3를 이용한 한국어 서비스를 만들기 위해서는 이와 같은 한국어 특화 모델의 필요성이 클 수 밖에 없습니다. 이 모델들을 기점으로 국내에서도 GPT-3를 기반으로 한 많은 한국어 서비스가 개발될 수 있기 때문에, 그 의미가 크다고 할 수 있습니다.
OUTRO
지금까지 초거대 언어 생성 모델, GPT-3에 대해 알아 보았습니다🙂 GPT-3는 모델의 규모와 그 성능으로 많은 관심을 받으며, AI 업계에 새로운 혁신을 불러 일으켰죠. GPT-3 기반 서비스들의 활약상을 보며, 앞으로 얼마나 더 ‘인간다운’ 텍스트를 생성하는 모델들이 나올지 정말 기대가 됩니다🧙🏻♂️
The GPT-3 hype is way too much. It’s impressive (thanks for the nice compliments!) but it still has serious weaknesses and sometimes makes very silly mistakes. AI is going to change the world, but GPT-3 is just a very early glimpse. We have a lot still to figure out.
- OpenAI CEO Sam Altman
마지막으로 GPT-3를 개발한 OpenAI 사의 대표 Sam Altman이 트위터에 남긴 말을 소개하며 이번 포스팅을 마무리 하겠습니다. Sam Altman에 따르면, GPT-3는 여전히 약점이 있고, 실수를 하기도 하며, AI가 세상을 바꾸는 여정에 GPT-3가 그저 첫 발을 내딛은 것 뿐이라고 합니다. GPT-3를 비롯한 AI 생성 모델들이 마치 ‘요술지팡이’ 같아 보이는 요즘이지만, 우리는 아직 나아가야 할 길이 많이 남아 있습니다. Generative AI의 발전은 현재진행형입니다!🫡
참고문헌 및 출처
[1] GPT-3 관련 논문: [2005.14165] Language Models are Few-Shot Learners (arxiv.org)
[2] 언어 모델 관련 위키독스: 03-01 언어 모델(Language Model)이란? - 딥 러닝을 이용한 자연어 처리 입문 (wikidocs.net)
[3] 초거대 AI 관련 기사: 구글, 네이버, LG 등 국내의 초거대 AI 개발ㅣ딥러닝ㅣ파라미터ㅣ람다ㅣ하이퍼클로바ㅣOpenAI - 투이컨설팅 (2e.co.kr)
[4] GPT-3 관련 아티클: [테크 스토리] 에이닷에 적용된 거대언어모델 GPT-3가 무엇일까? – SK텔레콤 뉴스룸 (sktelecom.com)
