
Intro. Generative AI(생성 AI) 란?
그림 그려주는 인공지능 DALL-E, 목소리를 재현해주는 인공지능 VALL-E, 그리고 최근 화제가 되고 있는 텍스트 생성 인공지능 ChatGPT까지, 모두 세상에 없는 무언가를 뚝딱 만들어냅니다. 바로 이러한 것들이 인공지능 생성 모델인데요.
입력된 데이터를 바탕으로 무언가를 예측하거나 추천해주는 AI가 전통적인 Analytical AI라면, Generative AI는 입력된 데이터를 학습해 새로운 것을 ‘창작’합니다. Auto Encoder(AE)와 Generative Adversarial Nets, 즉 GAN을 시작으로 Transformer 기반의 GPT를 발판삼아 DALL-E, Midjourney, Stable Diffusion이 나왔고, 이 외에도 VALL-E, Phenaki, Imagen 등 수많은 Generative AI가 쏟아져 나왔습니다. 단연 가장 화제가 되었던 것은 2022년 11월 OpenAI가 발표한 ChatGPT로, 인간에 필적하는 지능을 보여주며 많은 이들에게 놀라움을 안겨주었습니다.
💫 DALL-E로 생성한 이미지
출처: https://time.com/collection/best-inventions-2022/6225486/dall-e-2/
💫 VALL-E로 생성한 음성 데모
https://www.youtube.com/watch?v=fPSOlZyTOJ4
출처: https://www.thedailypost.kr/news/articleView.html?idxno=91008
💫 chatGPT를 활용한 질문과 답변
출처: http://the-edit.co.kr/50072
💡Generative AI의 핵심은 "충분히 있을 법한" 무언가를 생성하는 것입니다.
진짜같은 무언가를 만들어내는 Generative AI의 메커니즘에 대해 간단히 설명드리면, 핵심은 데이터의 분포에 있습니다. 먼저 데이터를 입력 받아, 입력 받은 데이터의 분포와 유사한 분포를 따르는 새로운 데이터를 생성하는 것입니다. 따라서 주어진 데이터의 분포를 잘 학습하는 모델이 더 좋은 성능을 가진 생성 모델이 되는 것입니다.
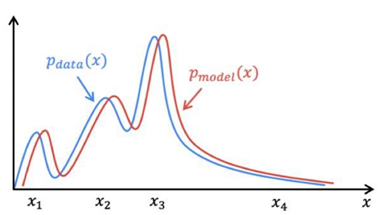
[출처 : NaverD2 "Generative adversarial Networks" 최윤제님 강의자료]
이번 포스팅에서는 Generative AI 시리즈의 첫번째 이야기로, 2014년 혜성같이 등장해 딥러닝 학계의 주목을 받았던 모델, Generative Adversarial Nets(이하 GAN)에 대해서 알아보겠습니다.
GAN의 구조
앞서 말씀드렸듯이, GAN이란 Generative Adversarial Networks의 약자입니다. 한국어로 번역한다면 ‘생성적 적대 신경망’이라고 할 수 있는데요. ‘적대’라는 단어에서 알 수 있듯이, GAN에는 서로 적대적인 관계의 두가지 요소가 등장합니다.
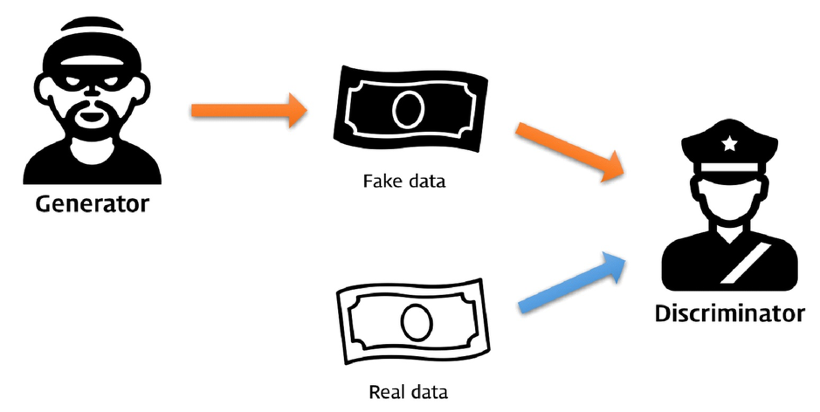
[출처 : https://files.slack.com/files-pri/T25783BPY-F9SHTP6F9/picture2.png?pub_secret=6821873e68]
GAN의 원본 논문에서는 이 두가지 요소를 가짜 돈을 찍어내는 🥷🏻지폐 위조범과, 진짜 돈과 가짜 돈을 구별해야 하는 👮🏻♂️경찰에 비유했습니다. 이 둘을 각각 🥷🏻생성자(Generator, 이하 G)와 👮🏻♂️판별자(Discriminator, 이하 D)로 칭합니다. 이 생성자와 판별자는 학습 과정에서 서로 경쟁하며, 최종적으로 양측의 손익을 합하면 0이 되는 제로섬 게임을 이어나갑니다.
지폐 위조범인 생성자는 최대한 진짜같은 지폐를 만들어 판별자인 경찰을 속이려 하고, 반대로 판별자인 경찰은 속지 않기 위해 점점 위조 지폐 판별 능력을 키워나갑니다. 여기서 💰위조 지폐가 생성자가 만들어낸 가짜 이미지, 💸진짜 지폐가 입력으로 들어온 실제 이미지가 되는 것이죠.
누구나 처음부터 잘 할수는 없기에, 생성자 G가 초기에 생성해 낸 결과물은 다소 어설프고, 형편없을 것입니다. 이 단계에서의 판별자 D는 진짜와 가짜를 구별하는 데에 큰 어려움이 없습니다. 그러나, 시간이 지남에 따라 생성자 G의 솜씨가 출중해질 것입니다. 위조 지폐가 점점 더 정교해지겠죠. 판별자 D는 진짜와 가짜를 구별하는 데에 점차 어려움을 겪게 되고, 섬세한 판별을 위해 노하우를 학습합니다. 이처럼 생성자 G와 판별자 D 두 모델이 마치 게임을 하듯 서로 경쟁을 하며 동시에 점차 개선되어가는 것입니다.
이 과정을 계속 반복하다보면, 판별자가 구별해 낸 ‘진짜’와 ‘가짜’의 비율이 비슷해집니다. 판별자가 어떤 것이 ‘진짜’이고 어떤 것이 ‘가짜’인지 더 이상 구별할 수 없을 정도로 학습이 진행된 것이죠. 드디어 ‘진짜같은 가짜’를 만들어내는 생성자가 학습된 것입니다!
바로 이것이 GAN의 구조이자, 핵심 아이디어입니다.
GAN의 학습과정
본격적으로 GAN의 학습이 어떻게 이루어지는지에 대해 살펴보겠습니다.
여기서 한가지 의문점이 생깁니다.
💡 ‘진짜같은’ 이미지를 만들어내기 위해 GAN의 생성자는 어떤 방법을 사용할까요?
👉🏻 바로 '노이즈'를 입력으로 받아, 학습을 통해 그럴듯하게 만들어가는 것입니다!
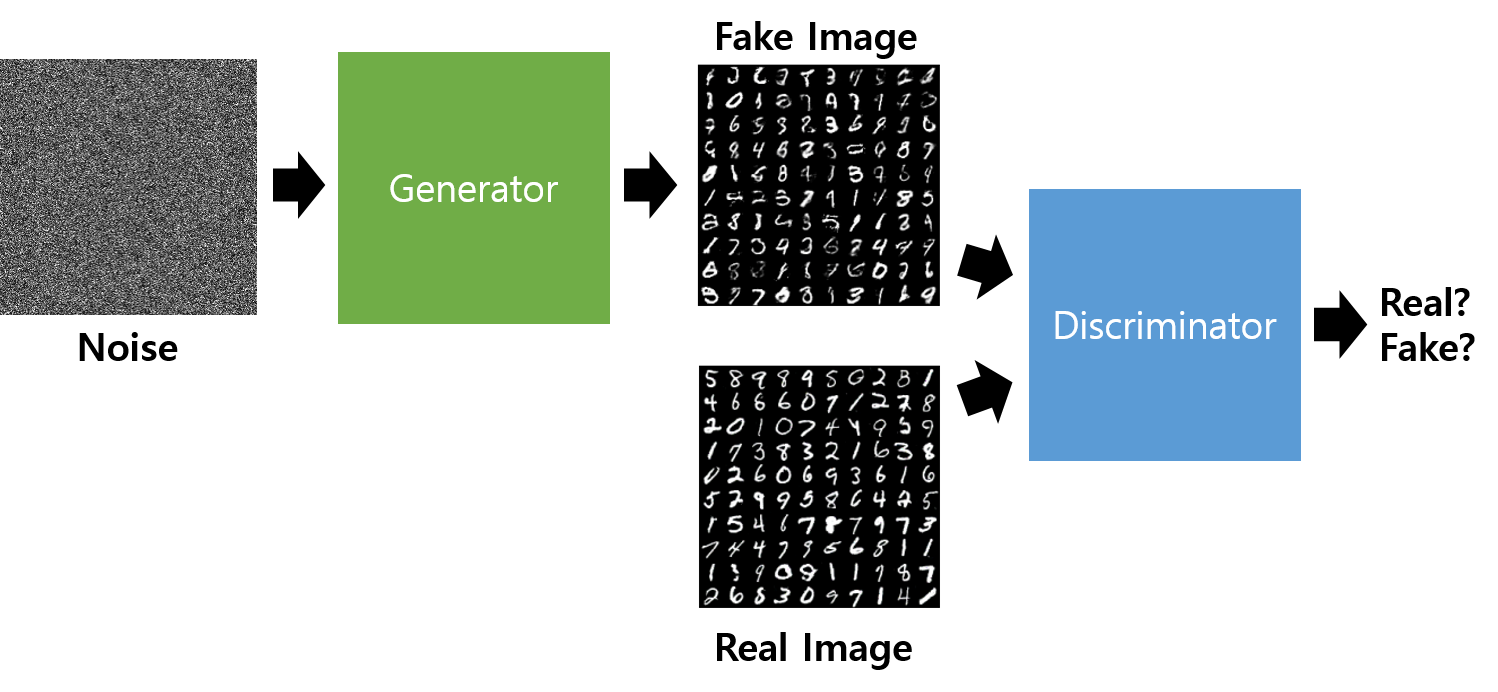
[출처 : https://hyeongminlee.github.io/post/gan001_gan/]
학습의 전반적인 흐름은 먼저 판별자 D를 학습시킨 후, 생성자 G를 학습시키는 과정을 반복하는 식으로 흘러갑니다. 여기서 판별자 D의 학습은 크게 두 가지 단계로 이루어집니다. ☝🏻첫 번째는 Real data를 입력해 ‘진짜’를 ‘진짜’로 분류하도록 학습시키는 과정이고, ✌🏻두 번째는 생성자가 생성한 Fake data를 입력해 ‘가짜’를 ‘가짜’로 분류하도록 학습시키는 과정입니다. “이렇게 생긴 것이 ‘진짜’고, 이렇게 생긴 것이 ‘가짜’야”🤓라고 판별자 D에게 친절히 알려주는 것이죠.
판별자를 학습시킨 다음에는 이 판별자를 속이라는 임무를 쥐어주고 생성자 G를 학습시킵니다. 생성자에 랜덤한 노이즈를 생성해내는 벡터 z를 입력으로 넣어 만들어진 가짜 이미지를 판별자 D에 입력합니다. 그리고 이 가짜 이미지가 진짜라고 분류될 정도로 진짜와 유사한 이미지를 만들어내는 방향으로 생성자 G를 학습시킵니다.
이 과정에서 판별자는 진짜 이미지의 출력값을 1로 설정하고, 이미지가 얼마나 진짜같은지에 대한 수치를 0과 1 사이의 확률값으로 나타냅니다. 생성자는 자신이 생성한 이미지에 대한 판별자의 출력값이 1에 가까워지는 방향으로 학습되겠죠.
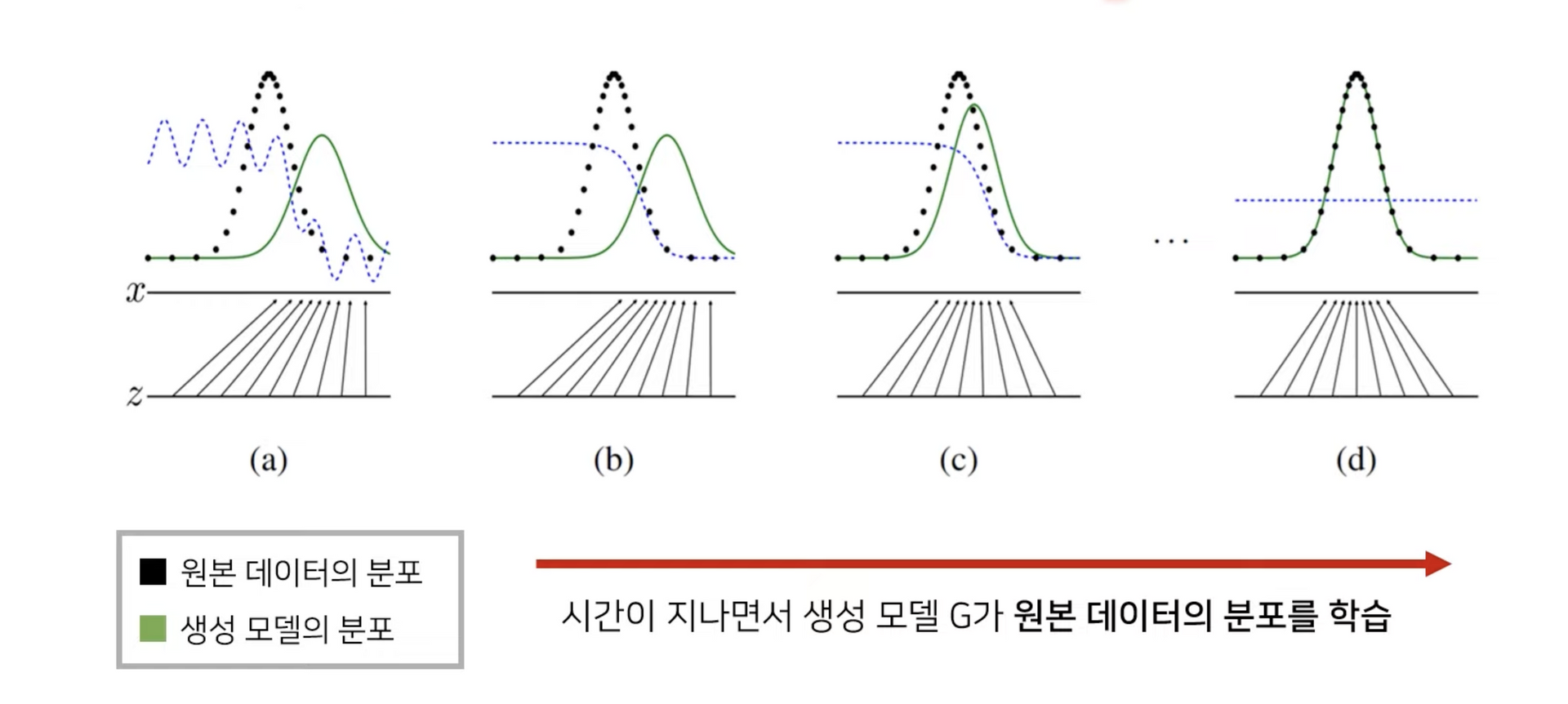
이 과정을 반복하면 판별자 D와 생성자 G가 서로를 적대적인 경쟁자로 인식하여 서로 발전하게 되고, 어느 순간 두 모델 모두 더 이상 개선되지 않는 어떤 균형점(Nash Equilibrium)에 이르게됩니다. 이 단계에 이르면 학습이 마무리되고, 결과적으로 생성자 G가 만들어내는 데이터의 분포가 처음에는 원본 데이터의 분포를 크게 벗어나 있었으나, 점차 원본 데이터의 분포를 근사할 수 있도록 학습된 것을 확인할 수 있습니다.
GAN의 Loss Function
다음으로, 딥러닝 모델의 핵심. Loss function에 대해 살펴보겠습니다.
GAN에서 사용하는 Loss function은 Minimax loss입니다.
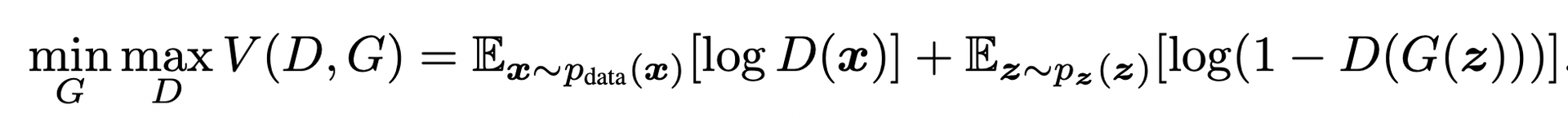
우리가 결과적으로 GAN 학습을 통해 얻고자 하는 것은 잘 학습된 생성자입니다. 판별자가 아닙니다. 때문에 생성자 G의 loss를 최소화(min)하고, 판별자 D의 loss를 최대화(max)하는 방향으로 학습하도록 하는 Loss function을 사용해야 하죠. 다소 복잡해 보일 수 있는 식이지만, 궁극적인 의미는 위와 같습니다.
여기서 잠깐, 위 Loss function의 구조를 살펴봅시다. 크게 보면 두 개의 log 함수가 덧셈으로 연결되어 있는 구조이죠. ☝🏻첫번째 항은 Real data인 x를 판별자 D에 넣었을 때 나오는 결과값에 log를 취해 얻은 기댓값이고, ✌🏻두번째 항은 Fake data인 z를 생성자 G에 넣어 생성된 Fake data를 판별자 D에 넣었을 때 나오는 결과값을 1에서 뺀 후 log를 취해 얻은 기댓값입니다.

우리가 살펴본 식에서 log 함수의 인자로 들어오는 D(x)와 D(G(z))는
0과1사이의 값입니다. 따라서 위의 그래프를 참고했을 때,[0, 1]의 범위에서 log(x)의 최댓값은 x가 1일 때 0이고, 최솟값은 x가 0일 때 임이 확인됩니다
이를 위 Loss function 식에 적용해봅시다.
❗자연스럽게 V(D, G)의 최댓값도 0이 되고, 최솟값은 가 되겠죠?
이제 이 방정식을 판별자 D, 생성자 G의 입장에서 각각 살펴보겠습니다.
✅ 먼저 D의 입장에서 살펴보면, D의 목표는 Real 이미지에는 1을, Fake 이미지에는 0을 출력하는 것입니다. 따라서 Real 이미지 x가 입력된 경우 D(x)의 출력값이 높게(1에 가깝게) 나오도록 학습되고, Fake 이미지 G(z)가 입력된 경우 D(G(z))의 출력값이 낮게(0에 가깝게) 나오도록 학습이 진행됩니다. 그렇게 되면, 학습이 가장 이상적으로 잘 된 경우에 ☝🏻첫번째 항은 D(x)가 1이 되므로 항 전체가 0이 되고, ✌🏻두번째 항도 D(G(z))가 0이 되므로 항 전체가 0이 되어 사라집니다. 앞서 말씀드렸듯이, D의 Loss가 최댓값 0이 됨을 확인할 수 있습니다.
✅ G의 입장에서도 살펴보겠습니다. G의 목표는, 자신이 생성한 이미지 G(z)에 대한 D의 판별 결과 D(G(z))가 최대한 1에 가까워지는 것입니다.
G가 학습이 잘 된 경우, D가 이를 진짜라고 판별한다면, D(G(z))가 1이 되므로 ✌🏻두번째 항이 가 됩니다. ☝🏻첫번째 항의 경우 G의 영향이 미치지 않으므로 무시하겠습니다. 결과적으로, G의 Loss가 최솟값 가 됨을 확인할 수 있습니다.
Outro
Generative AI의 기초라고도 할 수 있는 GAN, 지폐 위조범과 경찰의 속고 속이는 게임을 통해 ‘진짜같은 가짜’를 만들어간다는 발상이 정말 흥미롭지 않나요?🤭 끝 부분의 수식은 다소 어렵게 느껴질수도 있지만, 핵심은 ‘원본 데이터의 분포를 잘 학습하는 것’이라는 것!
2014년, GAN이 처음 발표되었을 때만 해도 혁신적인 아이디어라고 평가받으며 DCGAN, StyleGAN, CycleGAN 등 수많은 후속 연구들이 이루어질 정도였는데요. 이후 Transformer 기반의 DALL-E, ChatGPT를 비롯해 다양한 생성 모델들이 쏟아져 나오면서 지금은 관심이 덜해졌지만, 그래도 Generative AI의 역사에 한 획을 그은, 많은 의미를 담고 있는 모델이니만큼 한 번쯤 접해보시면 좋을 것 같습니다. 이것으로 이번 포스팅을 마무리 하겠습니다🫡
참고문헌 및 출처
[1] Generative Adversarial Networks 논문: [1406.2661] Generative Adversarial Networks (arxiv.org)
[2] GAN 개념 관련 아티클: [외부기고] [새로운 인공지능 기술 GAN] ② GAN의 개념과 이해 (samsungsds.com)
[3] GAN 논문 리뷰 영상: GAN: Generative Adversarial Networks (꼼꼼한 딥러닝 논문 리뷰와 코드 실습) - YouTube
