cs 스터디
1.[cs 스터디] 1-1. 디자인 패턴 - 싱글톤 패턴

디자인 패턴 디자인 패턴이 머냐ㅇㅇ 프로그램 설계할 때 발생했던 문제점들을 객체 간 상호 관계 등을 이용하여 해결할 수 있도록 하나의 '규약' 형태로 만들어 놓은 것을 의미한다 싱글톤 패턴(singleton pattern) > 하나의 클래스에 오직 하나의 인스턴스만 가
2.[cs 스터디] 1-1. 디자인 패턴 - 팩토리 패턴
팩토리 패턴(factory pattern) > 객체 생성 로직을 사용하는 코드와 분리하여 유연성과 재사용성을 높이는 객체 생성 패턴. 이를 통해 코드의 결합도를 낮추고 유지보수와 확장이 용이해진다. 팩토리 패턴의 주요 특징 1. 객체 생성의 추상화 > * 객체를 생성
3.[cs 스터디] 1-1. 디자인 패턴 - 전략 패턴
전략 패턴(strategy pattern) > 전략패턴은 정책 패턴(policy pattern)이라고도 하며, 객체의 행위를 변경하거나 확장하고자 할 때 직접 수정하지 않고, 다양한 알고리즘 또는 전략을 캡슐화하여 실행 방식을 변경할 수 있도록 하는 디자인 패턴이다.
4.[cs 스터디] 1-1. 디자인 패턴 - 옵저버 패턴
옵저버 패턴(observer pattern) > 옵저버 패턴은 주체가 어떤 객체(subject)의 상태 변화를 관찰하다가 상태 변화가 있을 때마다 메서드 등을 통해 옵저버 목록에 있는 옵저버들에게 변화를 알려주는 디자인패턴이다. 옵저버 패턴을 사용하면 주체의 상태 변화
5.[cs 스터디] 1-1. 디자인 패턴 - 프록시 패턴과 프록시 서버
옵저버 패턴에서 설명한 프록시 객체는 디자인 패턴 중 하나인 프록시 패턴이 녹아들어 있는 객체이다. 프록시 패턴 > 프록시 패턴(proxy pattern)은 대상 객체에 접근하기 전에 그 접근을 제어하거나 조작하는 디자인 패턴이다. 프록시는 대상 객체(Subject)
6.[cs 스터디] 1-1. 디자인 패턴 - 이터레이터 패턴
이터레이터 패턴(iterator pattern) > 이터레이터 패턴은 이터레이터를 사용하여 컬렉션의 요소들에 접근하는 디자인 패턴이다. 컬렉션(List, Set, Map 등) 내부의 구현 방식에 상관 없이 요소들을 일관된 방식으로 순회할 수 있도록 해준다. 순회할 수
7.[cs 스터디] 1-1. 디자인 패턴 - 노출모듈 패턴
노출모듈 패턴 > 노출모듈 패턴(revealing module pattern)은 즉시 실행 함수를 통해private, public 같은 접근 제어자를 만드는 디자인 패턴이다. 이 패턴을 통해 자바스크립트에서 private 변수나 함수와 public 변수 및 함수를 명확
8.[cs 스터디] 1-1. 디자인 패턴 - MVC 패턴 / MVP 패턴 / MVVM 패턴
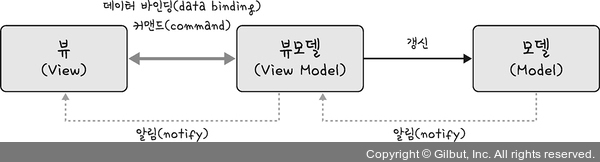
MVC 패턴 > MVC 패턴은 모델(Model), 뷰(View), 컨트롤러(Controller)로 이루어진 디자인 패턴이다. > 모델 애플리케이션의 데이터와 비즈니스 로직을 담당한다. 데이터에 접근하고 조작하며 데이터베이스와 연결하여 데이터를처리 뷰 사용자 인터페이스
9.[cs 스터디] 1-2. 프로그래밍패러다임
프로그래밍 패러다임 > 프로그래밍 패러다임(programming paradigm)은 프로그래머에게 프로그래밍의 관점을 갖게해주는 역할을 하는 개발 방법론이다. 각각의 패러다임은 특정 목표나 문제 해결 방식에 적합하게 설계되었다. 주요 프로그래밍 패러다임 객체지향 프로
10.[cs 스터디] 1-2. 프로그래밍 패러다임 - 선언형과 함수형 프로그래밍
선언형 프로그래밍 > 선언형 프로그래밍(declarative programming)은 '무엇을' 풀어내는가에 집중하는 패러다임으로 "프로그램은 함수로 이루어진 것이다."라는명제가 담겨있는 패러다임 이기도 하다. 함수형 프로그래밍(functional programming
11.[cs 스터디] 1-2. 프로그래밍 패러다임 - 객체지향 프로그래밍
객체지향 프로그래밍 > 객체지향 프로그래밍(Object-Oriented Programming, OOP)은 객체들의 집합을 통해 프로그램의 상호작용을 표현하고, 데이터를 객체로 취급하여 해당 객체 내부에 선언된 메서드를 활용하는 프로그래밍 방식이다. 객체지향 설계는 시간
12.[cs 스터디] 1-2. 프로그래밍 패러다임 - 절차형 프로그래밍 / 패러다임의 혼합
절차형 프로그래밍은 로직이 순차적이고 연속적인 계산 과정으로 이루어져 있으며 일이 진행되는 방식을 그대로 코드로 구현하는 접근 방식이다.절차에 따라 코드가 실행되기 때문에 가독성이 좋고 실행 속도가 빠르다는 장점이 있다. 다만 모듈화가 어렵고 유지보수성이 떨어진다는 단
13.[cs 스터디] 2-1. 네트워크의 기초 - 처리량과 지연 시간
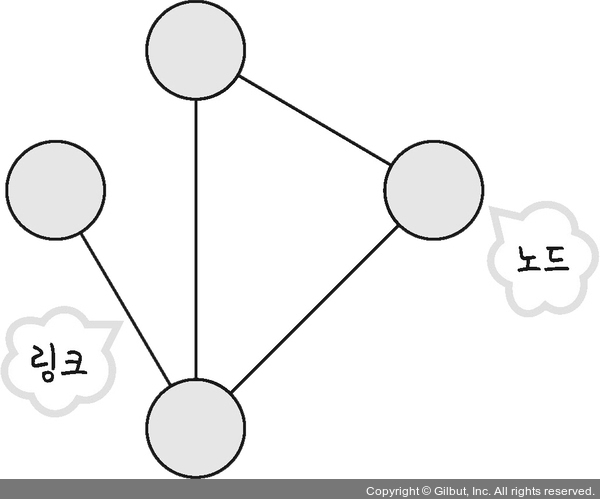
노드(node)와 링크(link)가 서로 연결되어 있으며 리소스를 공유하는 집합을 의미노드 - 서버, 라우터, 스위치 등 네트워크 장치링크 - 유선, 무선네트워크를 구축할 때는 좋은 네트워크로 만드는 것이 중요하다.좋은 네트워크란 많은 처리량을 처리할 수있고, 지연 시
14.[cs 스터디] 2-1. 네트워크의 기초 - 네트워크 토폴로지와 병목 현상
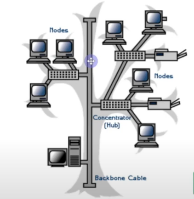
2-1-2. 네트워크 토폴로지와 병목 현상 네트워크 토폴로지 >네트워크 토폴로지(network topology)는 노드와링크가 어떻게 배치되어 있는지에 대한 방식이자 연결 형태를 의미 트리 토폴로지 버스 토폴로지 스타 토폴로지 링형 토폴로지 메시 토폴로지 트리 토폴
15.[cs 스터디] 2-3. 네트워크 기기 - 네트워크 기기의 처리 범위, 애플리케이션 계층을 처리하는 기기
네트워크는 여러 개의 네트워크 기기를 기반으로 구축된다. 네트워크 기기의 처리 범위 네트워크 기기는 계층별로 처리 범위를 나눌 수 있다. 상위 계층을 처리하는 기기는 하위 계층을 처리할 수 있지만 그 반대는 안된다. 애플리케이션 계층: L7 스위치 인터넷 계층: 라우터
16.[cs 스터디] 2-2. TCP/IP 4계층 모델 - PDU, OSI 7계층, MTU, MSS, PMTUD

네트워크의 어떠한 계층에서 계층으로 데이터가 전달될 때 한 덩어리의 단위를 PDU(Protocol Data Unit)라고 한다.PDU는 헤더, 페이로드로 구성되어 있다.헤더: 제어 관련 정보 포함페이로드: 데이터계층마다 부르는 명칭이 다르다.애플리케이션: 메시지전송:
17.[cs 스터디] 2-3. 네트워크 기기 - 인터넷 계층을 처리하는 기기
인터넷 계층을 처리하는 기기: 라우터, L3 스위치: 여러 개의 네트워크를 연결, 분할, 구분시켜주는 역할다른 네트워크에 존재하는 장치끼리 데이터를 주고 받을 때 패킷 소모를 최소화하고 경로를 최적화하여 최소 경로로 패킷을 포워딩한다.: L2 스위치의 기능과 라우팅 기
18.[cs 스터디] 2-3. 네트워크 기기 - 데이터링크 계층을 처리하는 기기
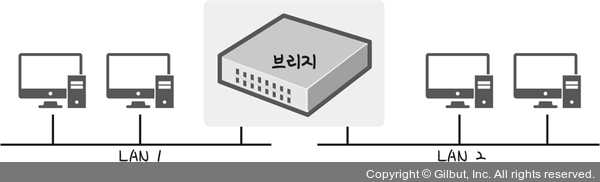
데이터링크 계층을 처리하는 기기: L2 스위치, 브리지: 장치들의 MAC 주소를 MAC 주소 테이블을 통해 관리한다.연결된 장치로부터 패킷이 왔을 때 패킷을 전송하는 담당이다.L2 스위치는 IP 주소를 이해하지 못해 IP 주소 기반의 라우팅은 불가능하며 단순히 패킷의
19.[cs 스터디] 2-3. 네트워크 기기 - 물리 계층을 처리하는 기기
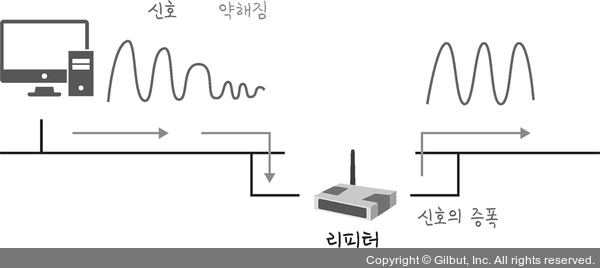
물리 계층을 처리하는 기기: NIC, 리피터, AP: LAN카드라고 하는 네트워크 인터페이스 카드(NIC, Network Interface Card)는 2대 이상의 컴퓨터 네트워크를 구성하는 데 사용한다.네트워크와 빠른 속도로 데이터를 송수신 할 수 있도록 컴퓨터 내에
20.[cs 스터디] 2-4. IP 주소 - ARP
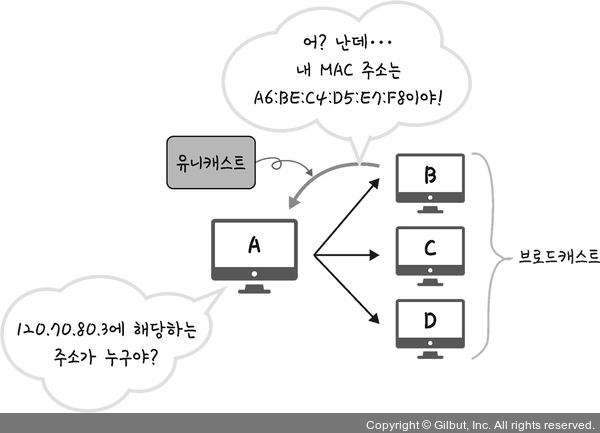
인터넷 계층에서 쓰이는 IP 주소에 대해 더 알아보자.컴퓨터와 컴퓨터 간의 통신은 IP 주소에서 ARP를 통해 MAC 주소를 찾아 MAC 주소를 기반으로 통신을 한다.ARP(Address Resolution Protocol)란 IP 주소로부터 MAC 주소를 구하는 IP
21.[cs 스터디] 2-4. IP 주소 - 홉바이홉 통신
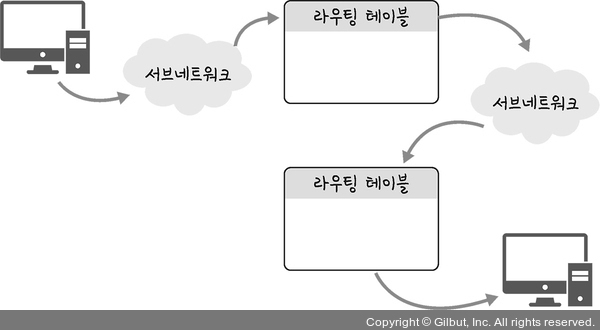
IP 주소를 통해 통신하는 과정을 홉바이홉 통신이라고 한다.서브네트워크 안에 있는 라우터의 라우팅 테이블 IP를 기반으로 패킷을 전달하고 또 전달해 나가며 라우팅을 수행하여 최종 목적지까지 패킷을 전달한다. 통신 장치에 있는 '라우팅 테이블'의 IP를 통해 시작주소부터
22.[cs 스터디] 2-4. IP 주소 - IP 주소 체계

IP 주소 체계IPv4IPv6IPv4 - 32비트를 8비트 단위로 점을 찍어 표기 (예 - 123.45.67.89)IPv6 - 64비트를 16비트 단위로 점을 찍어 표기 (예 - 2001:db8::ff00:42:8329)추세는 IPv6이지만 현재 가장 많이 쓰이는 주소
23.[cs 스터디] 2-5. HTTP - HTTP/1.0, HTTP/1.1
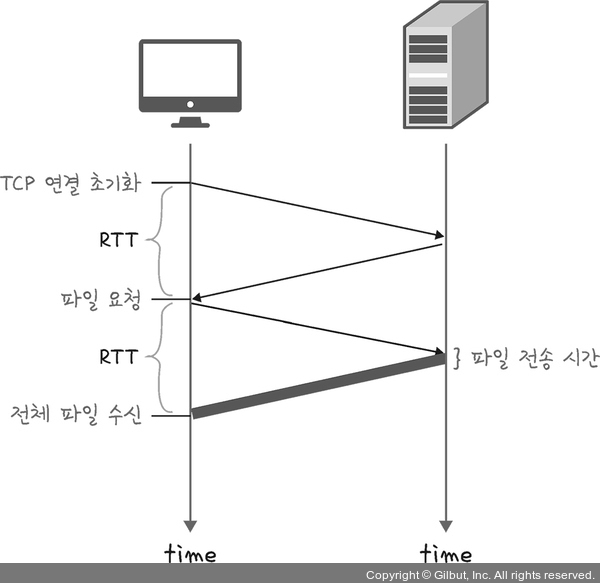
기본적으로 HTTP는 전송 계층 위에 있는 애플리케이션 계층으로서 웹 서비스 통신에 사용된다.HTTP/1.0은 기본적으로 한 연결당 하나의 요청을 처리하도록 설계 되었다. -> 서버로부터 파일을 가져올 때마다 TCP의 3-웨이 핸드셰이크를 계속 해서 열어야 하기 때문에
24.[cs 스터디] 2-5. HTTP - HTTP/2
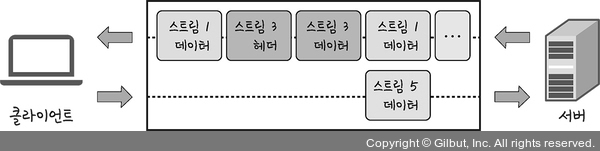
HTTP/2는 SPDY 프로토콜에서 파생된 HTTP/1.x보다 지연 시간을 줄이고 응답 시간을 더 빠르게 할 수 있으며 멀티플렉싱, 헤더 압축, 서버 푸시, 요청의 우선순위 처리를 지원하는 프로토콜이다.여러 개의 스트림을 사용하여 송수신 한다는 것이다.이를 통해 특정
25.[cs 스터디] 2-5. HTTP - HTTPS
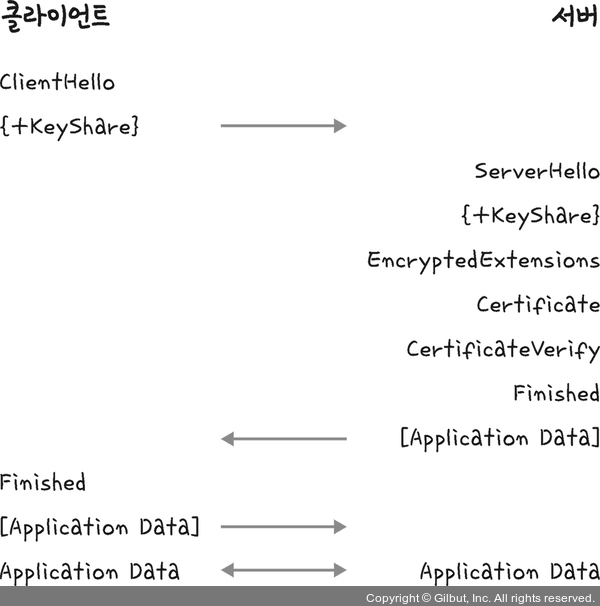
HTTP/2는 HTTPS 위에서 동작한다.애플리케이션 계층과 전송 계층 사이에 신뢰 계층인 SSL/TLS 계층을 넣은 신뢰할 수 있는 HTTP 요청을 말한다. 이를 통해 '통신을 암호화'한다.SSL(Secure Socket Layer)은 SSL 1.0부터 시작해서 SS
26.[cs 스터디] 2-5. HTTP - HTTP/3
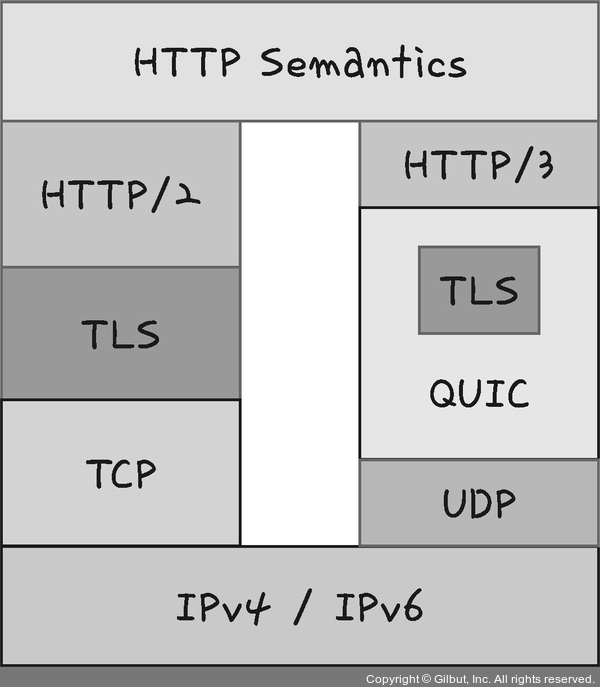
World Wide Web에서 정보를 교환하는 데 사용되는 HTTP의 세 번째 버전이다.TCP 위에서 돌아가는 HTTP/2와는 달리 HTTP/3은 QUIC이라는 계층 위에서 돌아가며, TCP 기반이 아닌 UDP 기반으로 돌아간다.HTTP/2의 장점이었던 멀티플랙싱이 가
27.[cs 스터디] 2-2. TCP/IP 4계층 모델 - 계층 구조
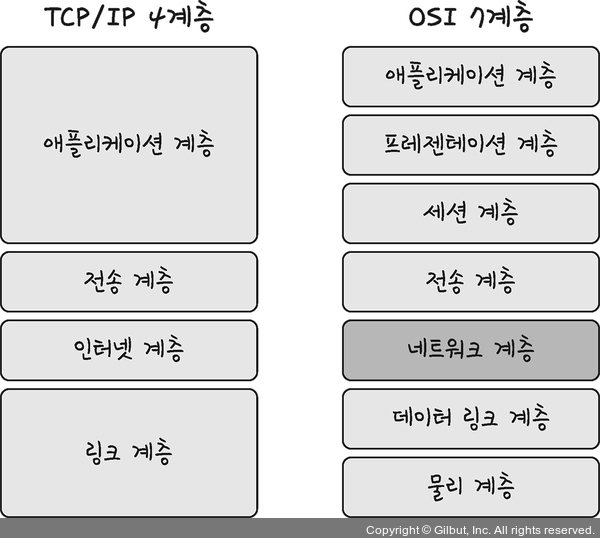
인터넷 프로토콜 스위트(internet protocol suite)는 인터넷에서 컴퓨터들이 서로 정보를 주고받는 데 쓰이는 프로토콜의 집합이다. 이를 TCP/IP 4계층 모델로 설명하거나 OSI 7계층 모델로 설명하기도 한다. 여기서는 TCP/IP(Transmissio
28.[cs 스터디] 3-1. 운영체제와 컴퓨터 - 운영체제의 역할과 구조
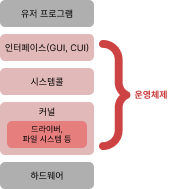
CPU 스케줄링과 프로세스 관리: CPU 소유권을 어떤 프로세스에 할당할지, 프로세스의 생성과 삭제, 지원 할당 및 반환을 관리한다.메모리 관리: 한정된 메모리를 어떤 프로세스에 얼만큼 할당해야 하는지 관리한다.디스크 파일 관리: 디스크 파일을 어떠한 방법으로 보관할지
29.[cs 스터디] 3-1. 운영체제와 컴퓨터 - 컴퓨터의 요소
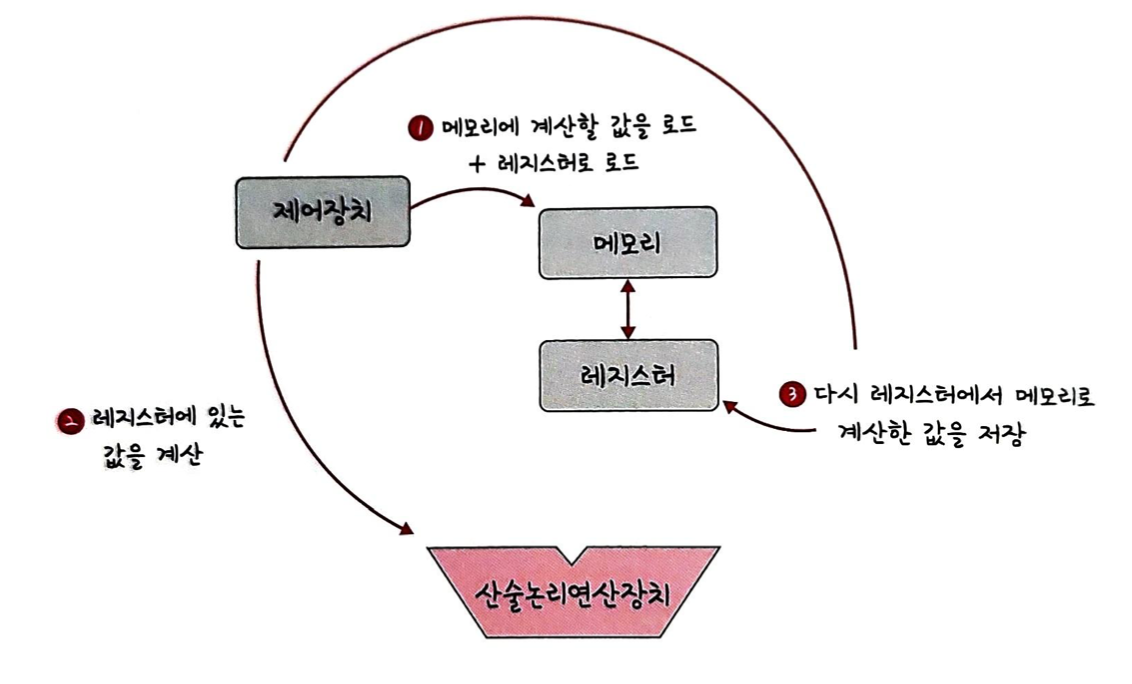
컴퓨터의 구성 요소: CPU, DMA 컨트롤러, 메모리, 타이머, 디바이스 컨트롤러 등CPU(Central Processing Unit)는 산술논리 연산장치, 제어장치, 레지스터로 구성되어 있는 컴퓨터 장치이다.인터럽트에 의해 단순히 메모리에 존재하는 명령어를 해석해서
30.[cs 스터디] 3-2. 메모리 - 메모리 계층

메모리 계층 구성: 레지스터, 캐시, 메모리, 저장장치상위 계층일수록 가격 ↑, 용량 ↓, 속도 ↑계층이 있는 이유 -> 경제성과 캐시 때문데이터를 미리 복사해 놓는 임시 저장소이자 빠른 장치와 느린 장치에서 속도 차이에 따른 병목 현상을 줄이기 위한 메모리이다.데이터
31.[cs 스터디] 3-2. 메모리 - 메모리 관리
가상 메모리 가상 메모리(virtual memory)는 메모리 관리 기법의 하나이다. 컴퓨터가 실제로 이용 가능한 메모리 자원을 추상화하여 이를 사용하는 사용자들에게 매우 큰 메모리로 보이게 만드는 것을 말한다. 가상 주소(logical address): 가상적으로
32.[cs 스터디] 3-3. 프로세스와 스레드 - 프로세스와 컴파일 과정
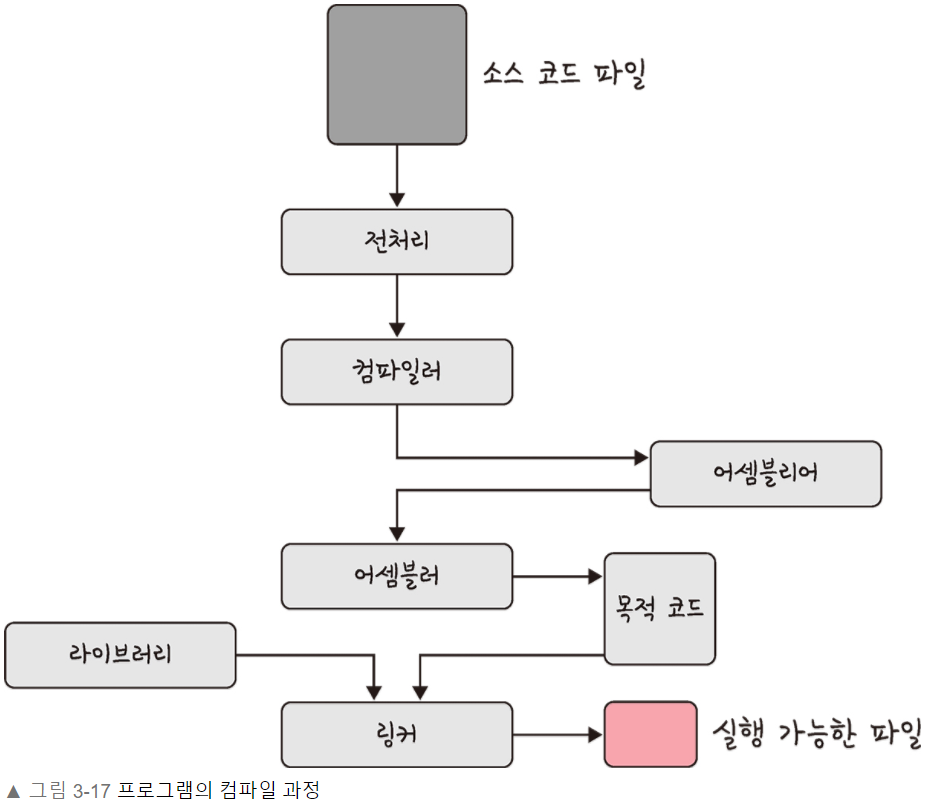
프로세스: 컴퓨터에서 실행되고 있는 프로그램CPU 스케줄링의 대상이되는 작업이라는 용어와 거의 같은 의미로 쓰인다.스레드: 프로세스 내 작업의 흐름프로그램이 메모리에 올라감프로그램 -> 프로세스 => 인스턴스화가 일어남운영체제의 CPU 스케줄러에따라 CPU가 프로세스를
33.[cs 스터디] 3-3. 프로세스와 스레드 - 프로세스의 상태
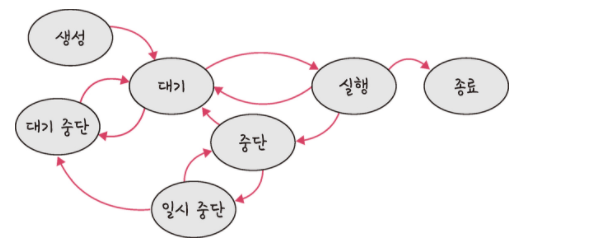
생성 상태(create): 프로세스가 생성된 상태fork(), exec() 함수를 통해 생성이때 PCB가 할당된다fork(): 부모 프로세스의 주소 공간을 그대로 복사하며 새로운 자식 프로세스를 생성하는 함수이다. 주소 공간만 복사부모 프로세스의 비동기 작업 등을 상속
34.[cs 스터디] 3-3. 프로세스와 스레드 - 프로세스의 메모리 구조
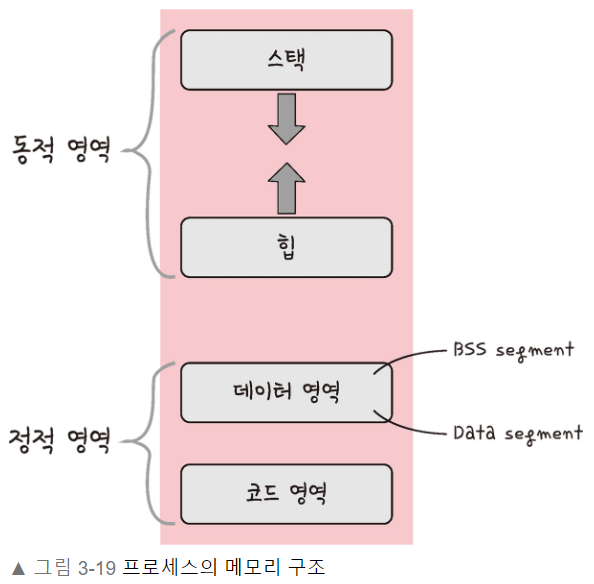
운영체제는 위 구조를 기반으로 프로세스에 적절한 메모리를 할당한다.스택은 위 주소부터 할당힙은 아래 주소부터 할당동적 할당이 되는 영역동적 할당: 런타임 단계에서 메모리를 할당 받는 것스택: 지역 변수, 매개변수, 실행되는 함수에 의해 늘어나거나 줄어드는 메모리 영역
35.[cs 스터디] 3-3. 프로세스와 스레드 - PCB
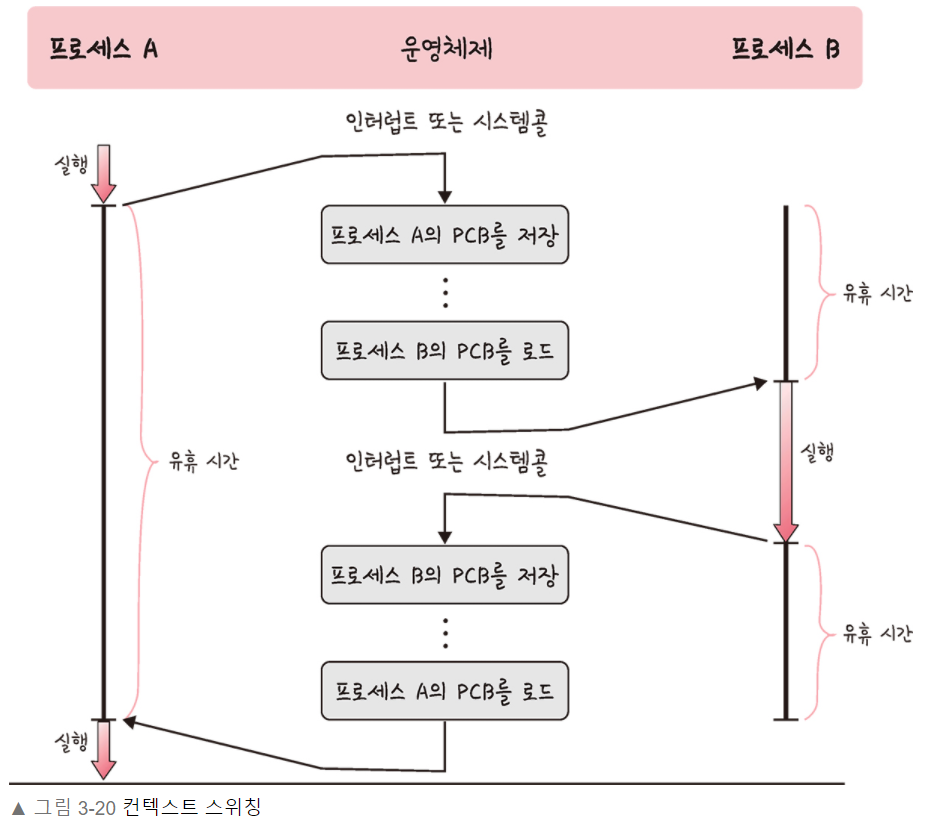
PCB(Process Control Block, 프로세스 제어 블록): 운영체제에서 프로세스에 대한 메타데이터를 저장한 '데이터'를 말한다.프로세스가 생성 -> 운영체제는 해당 PCB를 생성프로그램 실행 -> 프로세스 생성프로세스 주소 값들에 스택, 힙 등의 구조를 기
36.[cs 스터디] 3-3. 프로세스와 스레드 - 멀티 프로세싱
멀티 프로세싱은 여러 개의 프로세스, 즉 멀티 프로세스를 통해 동시에 두 가지 이상의 일을 수행할 수 있는 것을 말한다.이를 통해 하나 이상의 일을 병렬로 처리할 수 있으며 특정 프로세스의 메모리, 프로세스의 일부 중 문제가 발생되더라도 다른 프로세스를 이용해 처리할
37.[cs 스터디] 3-3. 프로세스와 스레드 - 스레드와 멀티스레딩
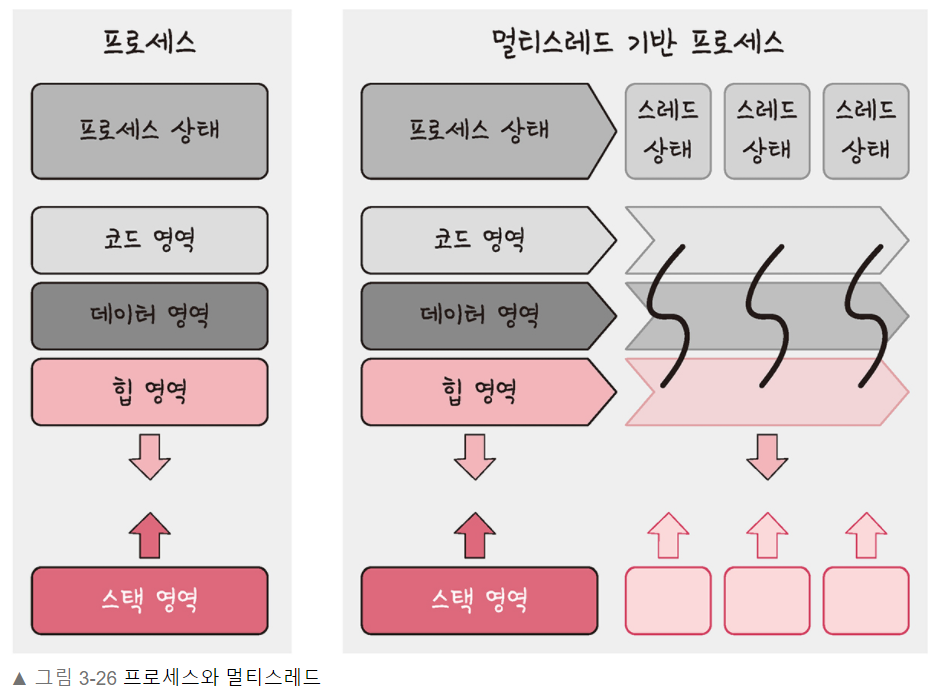
: 프로세스의 실행 가능한 가장 작은 단위프로세스는 여러 스레드를 가질 수 있다.프로세스와의 차이점: 프로세스는 코드 , 데이터, 스택, 힙을 각각 생성하지만 스레드는 코드, 데이터, 힙을 서로 공유한다. 그 외의 영역은 각각 생성한다.: 프로세스 내 작업을 여러 개의
38.[cs 스터디] 3-3. 프로세스와 스레드 - 공유 자원과 임계 영역
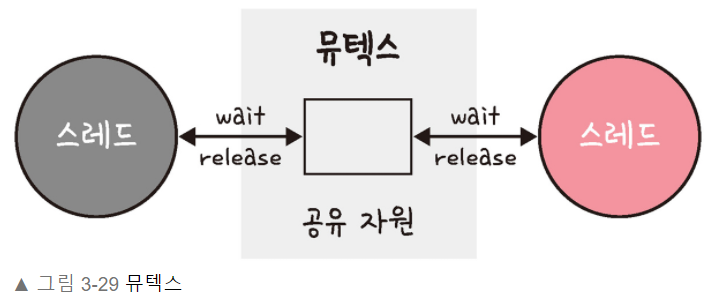
:공유 자원은(shared resource)은 시스템 안에서 각 프로세스, 스레드가 함께 접근할 수 있는 모니터, 프린터, 메모리, 파일 데이터 등의 자원이나 변수 등을 의미한다.경쟁 상태(race condition): 공유 자원을 두 개 이상의 프로세스가 동시에 읽거
39.[cs 스터디] 3-3. 프로세스와 스레드 - 교착 상태
교착 상태(deadlock): 두개 이상의 프로세스들이 서로가 가진 자원을 기다리며 중단된 상태를 말한다.상호 배제: 한 프로세스가 자원을 독점하고 있으며 다른 프로세스들은 접근이 불가능 하다.점유 대기: 특정 프로세스가 점유한 자원을 다른 프로세스가 요청하는 상태이다
40.[cs 스터디] 3-4. CPU 스케줄링 알고리즘 - 비선점형 방식, 선점형 방식
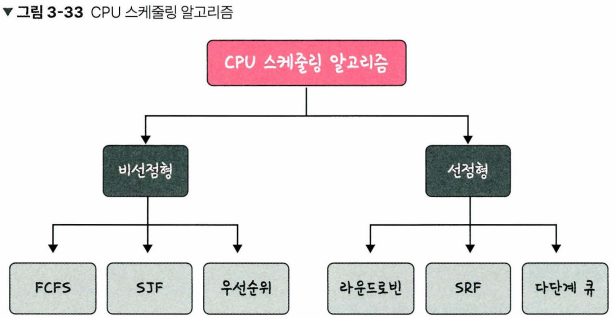
CPU 스케줄러는 CPU 스케줄링 알고리즘에 따라 프로세스에서 해야 하는 일을 스레드 단위로 CPU에 할당한다. 프로그램이 실행될 떄 CPU 스케줄링 알고리즘이 어떤 프로그램에 CPU 소유권을 줄 지 결정한다.CPU 스케줄링 알고리즘 목표CPU 이용률은 높게주어진 시간
41.[cs 스터디] 4-1. 데이터베이스의 기본
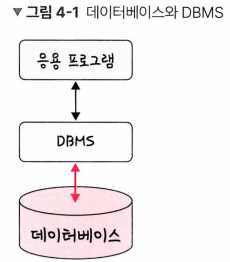
데이터베이스(DB, DataBase): 일정한 규칙, 혹은 규약을 통해 구조화되어 저장되는 데이터의 모음DBMS(DataBase Management System): 해당 데이터베이스를 제어, 관리하는 통합 시스템데이터베이스 안에 있는데이터들은 특정 DBMS마다 정의된
42.[cs 스터디] 4-2. ERD와 정규화 과정
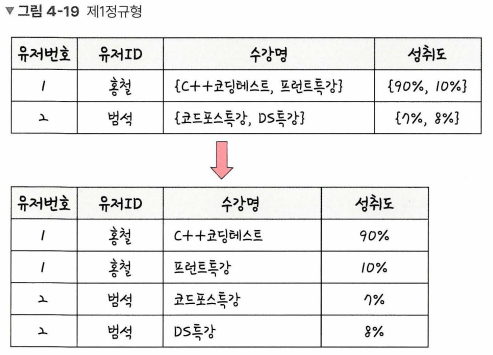
ERD(Entity Relationship Diagram): 데이터베이스를 구축할 때 가장 기초적인 뼈대 역할. 릴레이션 간의 관계를 정의한 것정규화란 릴레이션 간 잘못된 종속 관계로 인해 데이터베이스 이상 현상이 일어나서 이를 해결하거나, 저장 공간을 효율적으로 사용
43.[cs 스터디] 4-3. 트랜잭션과 무결성
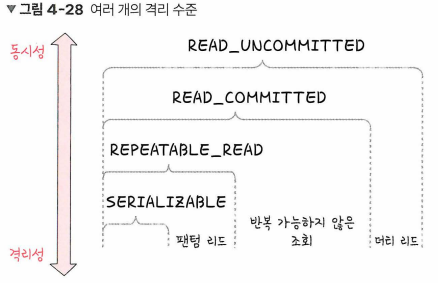
트랜잭션: 데이터베이스에서 하나의 논리적 기능을 수행하기 위한 작업의 단위데이터베이스의 접근하는 방법: 쿼리=> 여러 개의 쿼리를 하나로 묶는 단위를 말한다."all or nothing"원자성(atomicity): 트랜잭션과 관련된 일이 모두 수행되었거나 되지 않았거나
44.[cs 스터디] 4-4. 데이터베이스의 종류
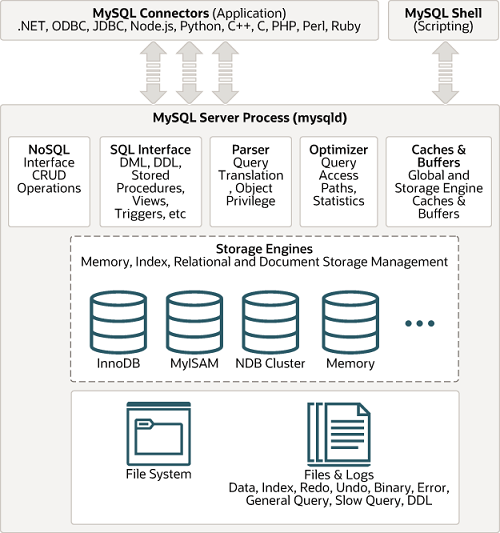
관계형 데이터베이스: 행과 열을 가지는 표 형식 데이터를 저장하는 형태. SQL을 써서 조작함MySQL, PostgreSQL, 오라클, SQL Server, MSSQL: 대부분의 운영체제와 호환되며 현재 가장 많이 사용하는 데이터베이스대용량 데이터베이스를 위해 설계되어
45.[cs 스터디] 4-5. 인덱스
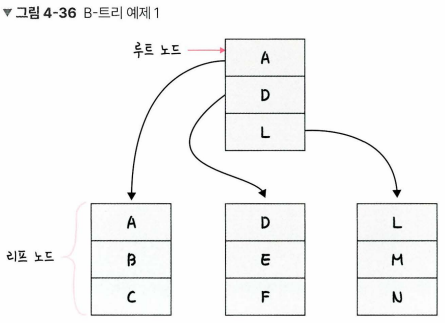
인덱스: 데이터를 빠르게 찾을 수 있는 하나의 장치인덱스는 보통 B-트리 자료구조로 이루어져 있다.루트 노드, 리프 노트, 브랜치 노드로 나뉨 E 탐색하기: 전체 테이블을 탐색하는 것이 아니라 E가 있을 법한 리프 노드로 들어가서 E를 탐색한다.자료 구조 없이 이를 행
46.[cs 스터디] 4-6. 조인의 종류
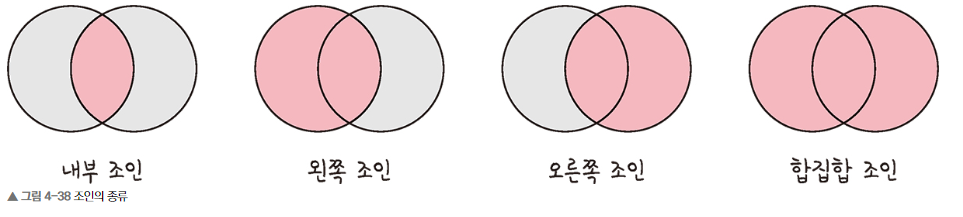
조인: 하나의 테이블이 아닌 두 개 이상의 테이블을 묶어서 하나의 결과물을 만들어 내는 것MySQL - JOIN / MongDB - lookup(\* 참고로 MongoDB의 lookup은 되도록 사용 X -> 조인 연산을 하는게 관계형 데이터베이스에 비해 성능이 좋
47.[cs 스터디] 4-7. 조인의 원리
조인의 원리: 중첩 루프 조인, 정렬 병합 조인, 해시 조인: 중첩 루프 조인(NLJ, Nested Loop Join)은 중첩 for문과 같은 원리로 조건에 맞는 조인을 하는 방법랜덤 접근에 대한 비용이 많이 증가 -> 대용량 테이블에서는 사용X중첨 루프 조인에서 발전
48.[cs 스터디] 5-1. 복잡도
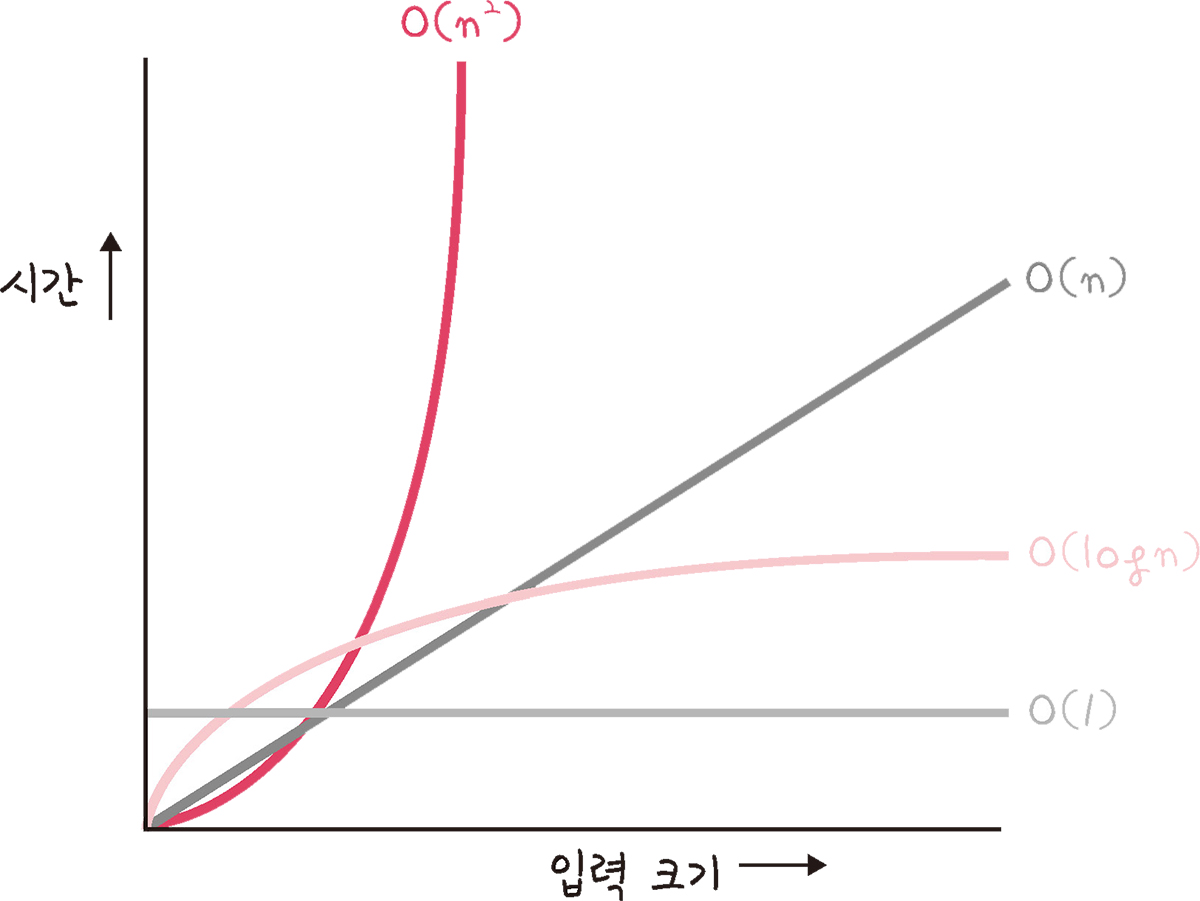
시간 복잡도: 입력 크기에 대해 어떠한 알고리즘이 실행되는 데 걸리는 시간주요 로직의 반복 횟수를 중점으로 측정된다.위 코드의 시간 복잡도를 빅오 표기법으로 나타내면 $O(n^2)$이 된다.\-> '가장 영향을 많이 끼치는' 항의 상수 인자를 빼고 나머지 항을 없앰효율
49.[cs 스터디] 5-2. 선형 자료 구조
선형 자료 구조 : 요소가 일렬로 나열되어 있는 자료 구조 연결 리스트 연결 리스트는 데이터를 감싼 노드를 포인터로연결해서 공간적인 효율성을 극대화 시킨 자료구조이다. >싱글 연결 리스트, 이중 연결 리스트, 원형 이중 연결 리스트 싱글 연결 리스트: next 포
50.[cs 스터디] 5-3. 비선형 자료 구조
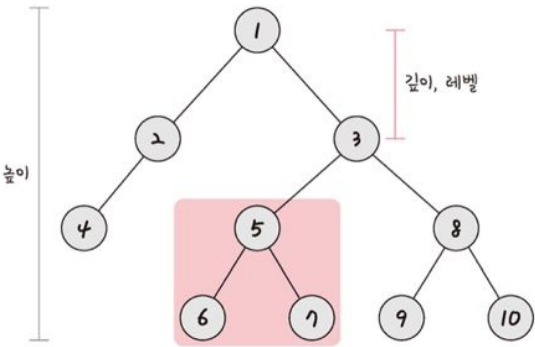
비선형 자료구조: 일렬로 나열하지 않고 자료 순서나 관계가 복잡한 구조예 - 트리, 그래프정점과 간선으로 이루어진 자료구조어떠한 곳에서 어떠한 곳으로 무언가를 통해서 간다.어떠한 곳: 정점(vertex)무언가: 간선(edge)단방향 간선, 양방향 간선이 있음정점으로 나
51.[cs 스터디] 2-1. 네트워크의 기초 - 유니캐스트, 멀티캐스트, 브로드캐스트
유니캐스트란 1:1 통신을 말함. 대표적으로 HTTP통신이 있음 -> 내가 네이버 드가면?(정확히는 HTTPS) HTTP 요청한거임 이게 1ㄷ1 유니캐스트가장 일반적인 전송 형태멀티캐스트란 1:N 통신을 말함. N이지만 모든 노드들에게 데이터를 전달하지는 않고 특정 그
52.[cs 스터디] 2-1. 네트워크의 기초 - 네트워크 분류
네트워크는 규모를 기반으로 분류할 수 있다.LAN(Local Area Network): 사무실이나 개인적으로 소유 가능한 규모MAN(Metropolitan Area Network): 서울시 등 시 정도의 규모WAN(Wide Area Network): 세계 규모근거리 통
53.[cs 스터디] 2-5. HTTP - HTTP헤더
우리가 http 요청할때 그냥 하는게 아님헤더랑 바디로 구분된 녀석을 보냄받을때도 헤더랑 바디헤더가 무엇인가html, xml, json 등 본문 -> http bodygeneral, response/request headers에 담기는게 header헤더는 콜론으로 구분
54.웹브라우저의 캐시 #1. 로컬 스토리지
브라우저마다 저장되는 데이터. 같은 오리진끼리 로컬스토리지를 공유함(오리진에 종속됨)크롬 브라우저 로컬스토리지에다가 큰돌 천재라고 저장 했다 -> 익스플로러에서 못봄로컬스토리지는 key, value 형태특징하나의 키에 오로지 하나의 값만 저장됨데이터는 사용자가 브라우저
55.웹브라우저의 캐시 #2. 세션스토리지
웹브라우저의 캐시 - 세션스토리지
56.웹브라우저의 캐시 #3. 쿠키(Cookie)
브라우저의 작은 데이터 조각.쿠키는 보통 어떻게 설정되냐 사용자가 서버에 요청사용자가 서버 페이지 내놔하면 서버는 set-cookie라는 응답헤더에 설정한 쿠키를 보낸다.다음부터 이 사용자가 쓰고있는 브라우저는 해당 쿠키값을 가지고 있게 됨그 다음 서버에다가 요청을 할
57.웹브라우저의 캐시 #4. 로컬스토리지, 세션스토리지, 쿠키의 공통점과 차이점
브라우저에 캐싱을 함으로써 서버에 대한 요청을 줄여 서버부하를 방지할 수 있다.세 개 모두 어떤 브라우저의 데이터 조각임이걸 기반으로 뭘 할수있냐서버에다가 요청을 한다 치자요청해야할 정보를 이미 쿠키 등에 캐싱을 해두었기때문에 요청할 필요가 없으니 서버부하가 감소한다는
58.로그인 #1. 세션기반인증방식
네이버에서 로그인하고 로그인한 상태로 새로고침 -> 유지가된다어떻게 구현할까?로그인을 유지하는건 두가지 방식이 대표적이다.세션기반인증방식과 토큰기반인증방식HTTP의 특징중 하나는 상태가 없음(stateless)하다라는 것즉 HTTP 요청을 통해 데이터를 주고받을 때 요
59.로그인 #2. 토큰기반인증방식(access토큰, refresh토큰)
토큰기반은 유저의 상태를 토큰에 담아놓고 서버들은 stateless하게 가자라는 이론이 담긴 기법임이 토큰에다가 유저의 상태값을 다 넣음이걸 기반으로 유저가 유효한지아닌지를 확인어떻게 구현하냐면MSA기반으로 설명장바구니, 결제 서버가 있다토큰을 관리하는 서버도 한대 존
60.HTTP 상태코드(status code)
서버가 요청을 잘 받았으며 해당 프로세스를 계속 이어가며 처리하는 것을 의미한다.100: 계속함을 의미서버가 요청을 잘 받았고 이를 기반으로 클라이언트에게 성공적으로 데이터를 보낸 것을 의미한다.200 OK: 요청이 성공적으로 되었음을 의미201 Created: 요청
61.HTTP 메서드 #1. GET과 POST / PUT과 PATCH
url을 기반으로 하기때문에 길이제한(2000자미만)이 있다.성공시 HTTP 상태코드 200을 반환한다.캐싱이 가능하다.url을 기반으로 요청하기 때문에 해당 요청의 파라미터가 브라우저 기록에 남는다.url을 기반으로 요청하기 때문에 요청할 때 ASCII문자열만을 보낼
62.네트워크를 이루는 장치의 이해
네트워크 기기는 계층별로 나눌 수 있다.상위 계층을 처리하는 기기는 하위 계층을 처리할 수 있지만 그 반대는 불가하다.L7 스위치는 L4 스위치가 하는 기능을 할 수 있음 -> 위 계층은 아래 계층이 하는 일을 할 수 있다.
63.네트워크를 이루는 장치 #1. 애플리케이션, 전송, 인터넷, 데이터링크, 물리 계층
로드밸런서라고도 함. 서버의 부하를 분산하는 기기.강점: 서버 이중화, 보안IP, Port 뿐만이 아니라 url, 헤더, 쿠키 등을 기반으로 트래픽을 분산한다.헬스체크를 통해 장애가 발생한 서버를 확인하고 해당 서버로 트래픽을 보내지 못하게 하는 역할을 한다.로드밸런서
64.유선 LAN #1. 전이중화 통신, CSMA/CD, 케이블
전이중화(full duplex) 통신은 양쪽 장치가 동시에 송수신할 수 있는 방식을 말한다.동축케이블, 광케이블 등을 기반으로 만들어진 유선LAN을 이루는 이더넷은 IEEE802.3 프로토콜을 기반으로 전이중화 통신을 쓴다.충전기 생각하면됨. 충전기 보통 USB C타입
65.무선 LAN #1. 반이중화 통신, CSMA/CA, 와이파이
무선랜은 IEEE802.11 표준규격을 따름. 반이중화 통신을 사용양쪽 장치는 서로 통신할 수 있지만 동시에는 할 수 없음 한번에 한 방향만 통신CSMA/CA: 반이중화 통신 중 하나장치에서 데이터를 보내기 전에 사전에 가능한 충돌 방지를 하는 방식CSMA/CA로 프레