1. 네이버 API 사용 등록
- 네이버 개발자 센터 접속 (https://developers.naver.com/main/)
- 어플리케이션 등록
- 이름
- 사용 API 선택
- 검색, 데이터랩(검색어트렌드),데이터랩(쇼핑인사이트) , 이후 필요에 따라 더 추가
- 환경추가
- WEB 설정
- 주소 설정
- Client ID, Client Secret 이 발급되면 이를 기억해두고 사용하면 됨
2. 네이버 검색 API 사용하기
- 개발 가이드 사이트에 있는 예시를 활용해보자
https://developers.naver.com/docs/serviceapi/search/blog/blog.md#%EB%B8%94%EB%A1%9C%EA%B7%B8
# 네이버 검색 API 예제 - 블로그에서 검색
import os
import sys
import urllib.request
client_id = "m19f_M7BacBlDgpT6SMu"
client_secret = "cQjt07FwM3"
encText = urllib.parse.quote("파이썬")
url = "https://openapi.naver.com/v1/search/blog?query=" + encText # JSON 결과
# url = "https://openapi.naver.com/v1/search/blog.xml?query=" + encText # XML 결과
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
print(response_body.decode('utf-8'))
else:
print("Error Code:" + rescode)urllib http 프로토콜에 따라서 서버의 요청/응답을 처리하기 위한 모듈
urllib.request 클라이언트의 요청을 처리하는 모듈
urllib.parse url 주소에 대한 분석
response 정상작동했다면 <http.client.HTTPResponse at 0x1d4095aa430>이러한 형태로 출력됨
response.getcode(), response.code, response.status 출력되는 숫자로 오류원인 파악가능
response_body.decode('utf-8')
글자로 읽을 경우, decode utf-8 설정
책, 카페, 백과사전, 쇼핑 등등 네이버에서 지원하는 API로 모두 검색이 가능하고, 영화는 API 지원을 종료했다고 한다.
다른 API도 코드는 동일하게 사용가능하고 url주소에서 API값만 맞춰서 바꿔주면 된다.
결과는 실제 네이버에서 검색하면 나오는 결과대로 딕셔너리 형태로 보여준다.
3. 상품 검색
쇼핑 API를 이용하여 "몰스킨"이라는 상품 검색해보기
# 네이버 검색 API 예제 - 쇼핑
import os
import sys
import urllib.request
client_id = ""
client_secret = ""
encText = urllib.parse.quote("몰스킨")
url = "https://openapi.naver.com/v1/search/shop?query=" + encText # JSON 결과
# url = "https://openapi.naver.com/v1/search/blog.xml?query=" + encText # XML 결과
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
print(response_body.decode('utf-8'))
else:
print("Error Code:" + rescode)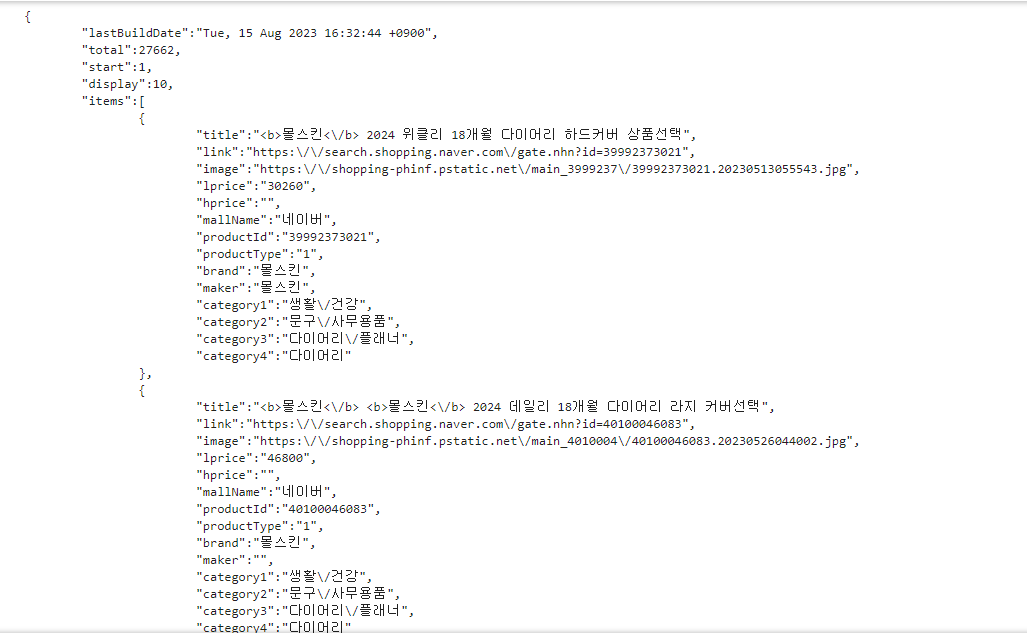
4. 상품 검색을 함수로 표현
<절차>
1. generate url
2. get data on one page
3. convert pandas data frame
4. all data gathering
5. export to excel
위 절차를 함수로 나타내면 다음과 같다.
gen_search_url(): 검색 url을 만드는 함수get_result_onepage(): 페이지에 나오는 검색 결과를 저장하는 함수get_fields(): 검색 결과로 데이터프레임을 만드는 함수actMain(): 1,2,3번 함수를 실행시켜서 데이터를 수집하는 포괄 함수to_excel(): 엑셀파일로 저장하는 함수
(1) gen_search_url()
참고
https://developers.naver.com/docs/serviceapi/search/shopping/shopping.md#%EC%87%BC%ED%95%91
encText = urllib.parse.quote("몰스킨")
url = "https://openapi.naver.com/v1/search/shop?query=" + encText # JSON 결과위 주소처럼 만들어야 한다.
#api_node : 검색할 카테고리 명 ex. 쇼핑, 책, 블로그, 카페 등등
#search_text : 검색어
#start_num : 검색 시작 위치
#disp_num : 한 번에 표시할 검색 결과 개수, 10~100개 범위
def gen_search_url(api_node, search_text, start_num, disp_num):
base = "https://openapi.naver.com/v1/search"
node = "/" + api_node + ".json"
param_query = "?query=" + urllib.parse.quote(search_text)
param_start = "&start=" + str(start_num)
param_disp = "&display=" + str(disp_num)
return base + node + param_query + param_start + param_disp
gen_search_url('shop', 'TEST', 10, 3)결과
'https://openapi.naver.com/v1/search/shop.json?query=TEST&start=10&display=3'
(2) get_result_onepage()
import json
import datetime
def get_result_onpage(url):
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
print("[%s] Url Request Success" % datetime.datetime.now()) #[현재시간] 이 찍힘
return json.loads(response.read().decode("utf-8"))url = gen_search_url('shop', '몰스킨', 1, 5)
one_result1,2번까지 실행한 결과
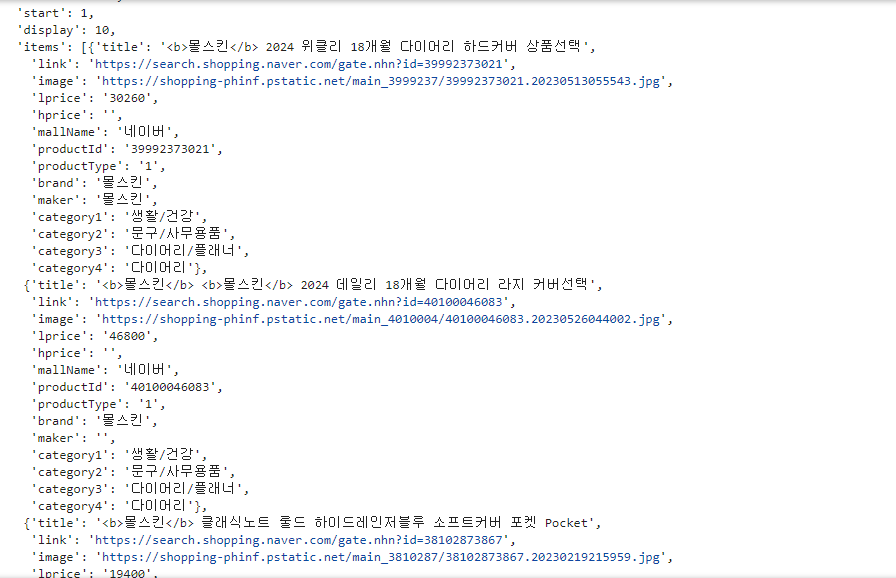
출력결과를 보면 큰 틀은 딕셔너리형태인데, 아이템 value 값부터 리스트가 들어있는 형태이다.
이를 이용하면 아래와 같이 상품이름, 링크, 가격, 쇼핑몰이름 등의 정보를 얻을 수 있다.
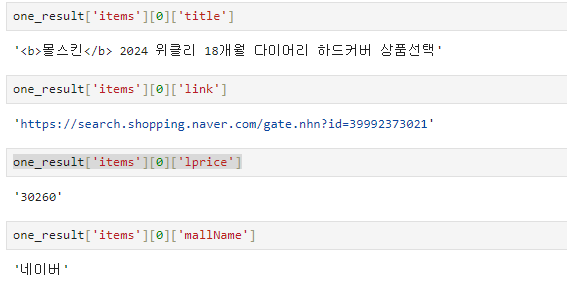
이를 이용하여 데이터프레임을 만든다.
(3) get_fields()
검색한 결과의 정보를 이용하여 data frame 만들기
import pandas as pd
def get_fields(json_data):
title = [each["title"]for each in json_data["items"]]
link = [each["link"]for each in json_data["items"]]
lprice = [each["lprice"]for each in json_data["items"]]
mall_name = [each["mallName"]for each in json_data["items"]]
result_pd = pd.DataFrame({
"title" : title,
"link" : link,
"lprice" : lprice,
"mall" : mall_name
}, columns=["title", "lprice", "link", "mall"])
return result_pd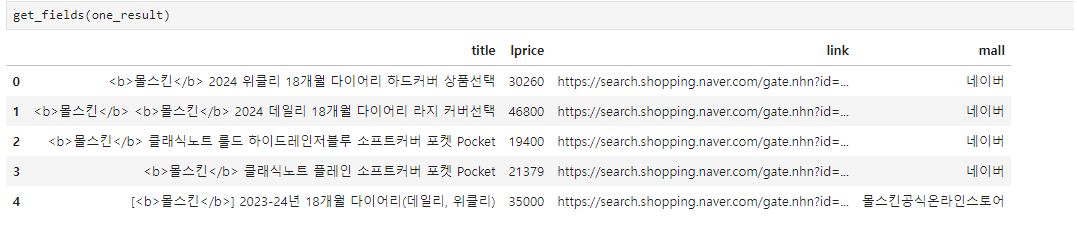
데이터 프레임을 만들었는데 title에서 태그가 같이 출력 되었다. 이를 제거해주기 위한 태그 제거 함수를 만들어 보자
def delete_tag(input_str):
input_str = input_str.replace('<b>', '')
input_str = input_str.replace('</b>', '')
return input_str
#title에 위 함수를 적용
import pandas as pd
def get_fields(json_data):
title = [delete_tag(each["title"])for each in json_data["items"]]
link = [each["link"]for each in json_data["items"]]
lprice = [each["lprice"]for each in json_data["items"]]
mall_name = [each["mallName"]for each in json_data["items"]]
result_pd = pd.DataFrame({
"title" : title,
"link" : link,
"lprice" : lprice,
"mall" : mall_name
}, columns=["title", "lprice", "link", "mall"])
return result_pd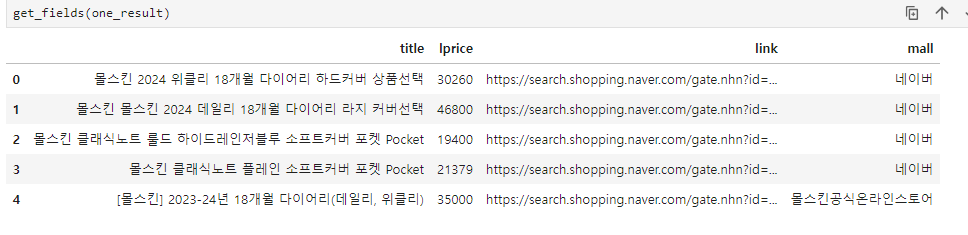
1,2,3 함수를 실행한 결과
url = gen_search_url('shop', '몰스킨', 1, 5)
json_result = get_result_onpage(url)
pd_result = get_fields(json_result)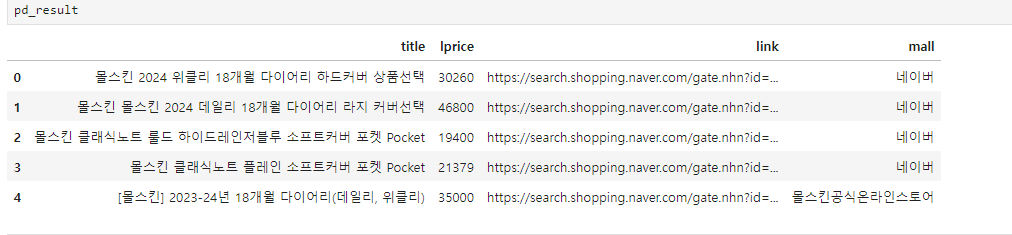
(4) actMain()
for n in range(1, 1000, 100):
1부터 999까지 100단위로 반복
result_mol = []
for n in range(1, 1000, 100):
url = gen_search_url('shop', '몰스킨', n, 100)
#n은 10개의 값이 들어오고, 한 페이지에 100개가 나오도록 설정 -> 총 1000개 검색 결과가 나옴
json_result = get_result_onpage(url)
pd_result = get_fields(json_result)
result_mol.append(pd_result)
result_mol = pd.concat(result_mol)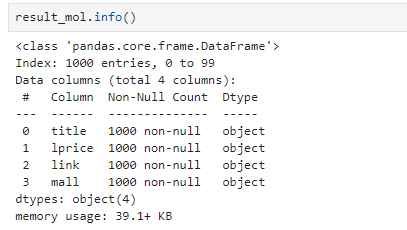
결과는 1000개인데, 인덱스는 99까지 있어서 재설정 해야할 것 같고, 가격 연산이 필요할 경우를 대비해서 가격 컬럼 형변환도 필요할 것 같다.
# drop=True : 인덱스 재정렬 후, 기존 인덱스 컬럼 삭제
result_mol.reset_index(drop=True, inplace=True)
#가격 컬럼 형변환
result_mol['lprice'] = result_mol['lprice'].astype('float64') (5) to_excel()
파이썬으로 엑셀파일 만들기
설치 !pip install xlsxwriter
writer = pd.ExcelWriter("../data/06_molskin_diary_in_naver_shop.xlsx", engine="xlsxwriter")
result_mol.to_excel(writer, sheet_name="Sheet1")
workbook = writer.book
worksheet = writer.sheets["Sheet1"]
# 행:열 , 간격
worksheet.set_column("A:A", 4)
worksheet.set_column("B:B", 60)
worksheet.set_column("C:C", 10)
worksheet.set_column("D:D", 10)
worksheet.set_column("E:E", 50)
worksheet.set_column("F:F", 10)
worksheet.conditional_format("C2:C1001", {"type": "3_color_scale"})
writer.close()
#save()는 판다스에서 삭제돼서 사용 불가능하다고 한다.
대신 close()를 쓴다.다음과 같이 엑셀파일이 만들어져서 저장되었다.
가격에 색깔이 나타나도록 색 범위를 지정해주었고, 설정한 간격에 따라 칸 간격이 설정되었다.
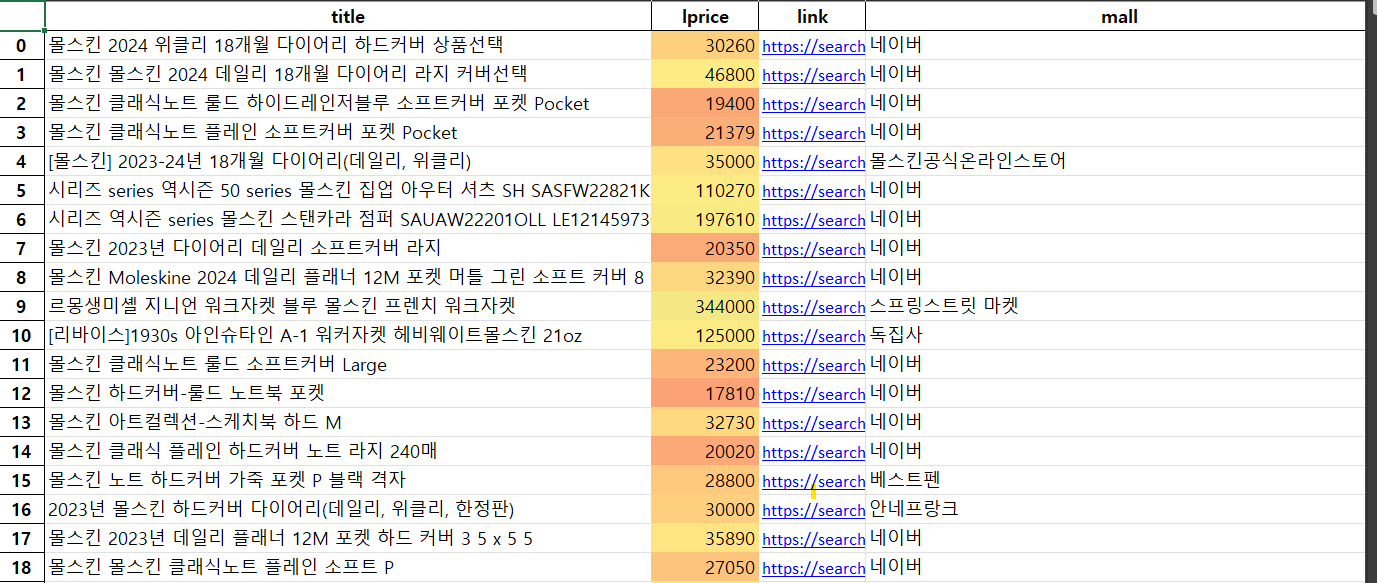
5. 엑셀 파일을 시각화
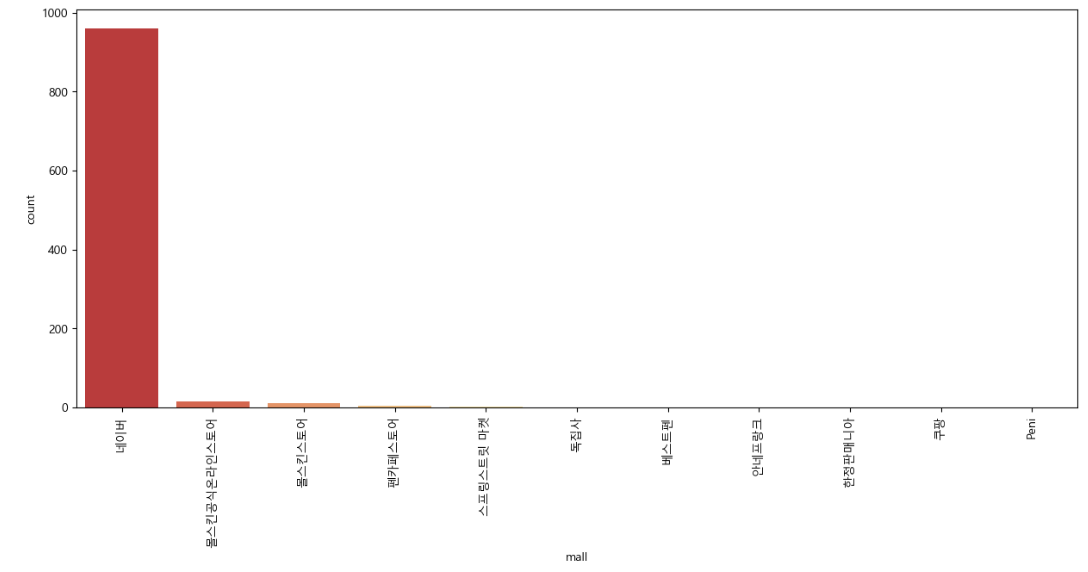
판매처별로 얼마나 판매하고 있는지 알아본다.
import seaborn as sns
import platform
import matplotlib.pyplot as plt
import set_matplotlib_hangul
%matplotlib inline
plt.figure(figsize=(15,6))
sns.countplot(
x = result_mol["mall"],
data=result_mol,
palette="RdYlGn",
order=result_mol["mall"].value_counts().index
)
plt.xticks(rotation=90) #x축 값들을 90도 돌려서 나타냄
plt.show()