Autoencoder
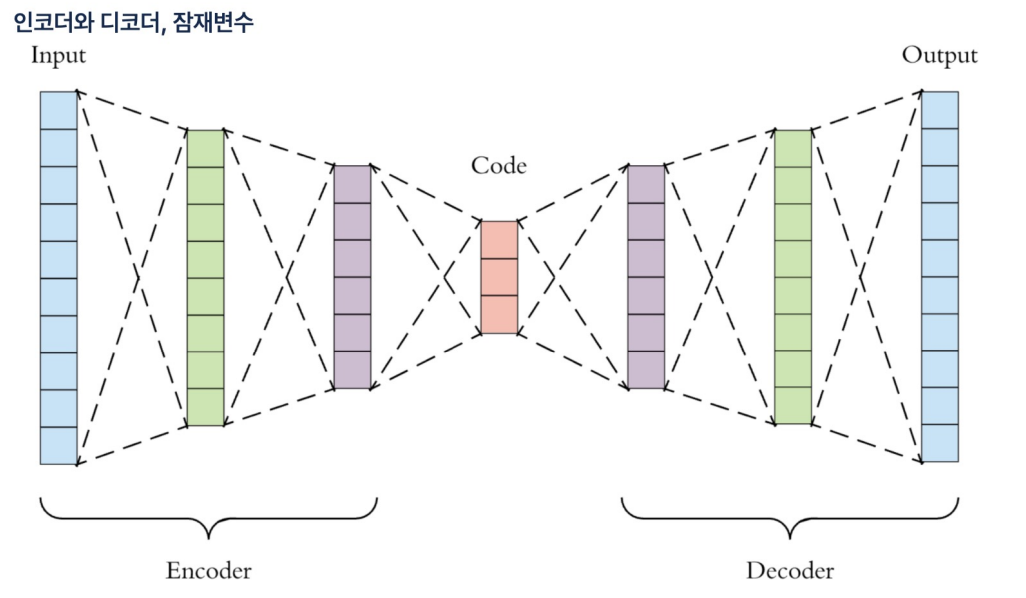
- Encoder : 입력에서 작아지는 지점까지
- Decoder : 출력하는 지점까지
- 잠재변수(Latent Vector) : 위 그림에서 가장 작은 지점
- encoder는 특징추출기와 같은 역할, decoder는 압축된 데이터를 다시 복원하는 역할을 한다
- autoencoder는 자기 자신을 재생성하는 네트워크로 입력과 출력이 동일하다.
이미지 증강
YOLO

-
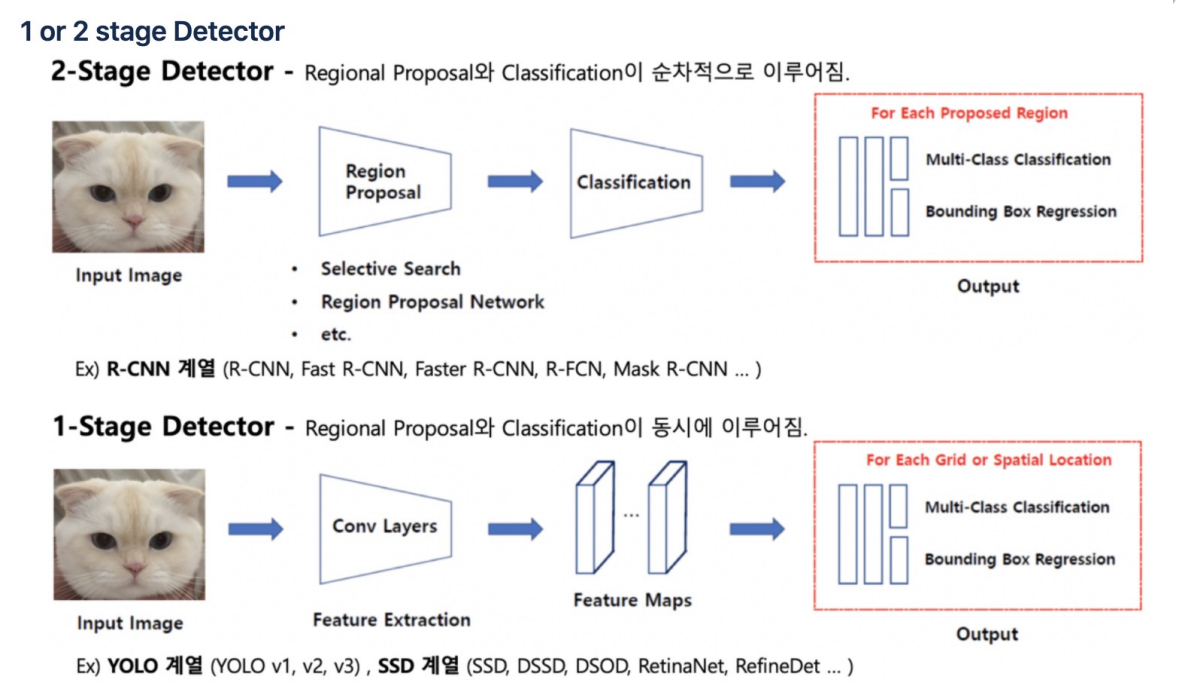
2 stage Detector
: 2 stage Detector는 먼저 사물이 위치한 곳을 찾아내고(Region Proposal), 해당 사물이 무엇인지 분류하여(Classification) 딥러닝이 2번 돌게되고, 속도가 느리다. -
1 stage Detector
: 1 stage Detector는 딥러닝이 1번만 돈다.
Multiclass는 classification, Bounding Box는 Regressor로 해결한다.
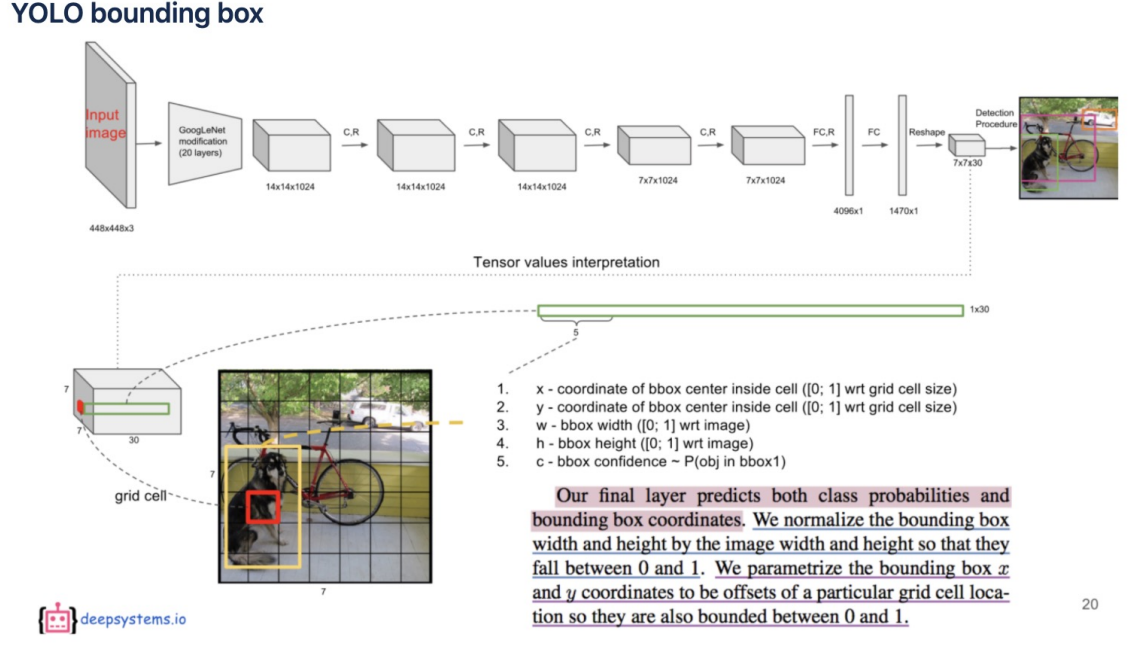
YOLO는 아래 사진과 같은 작업을 한 번에 한다.
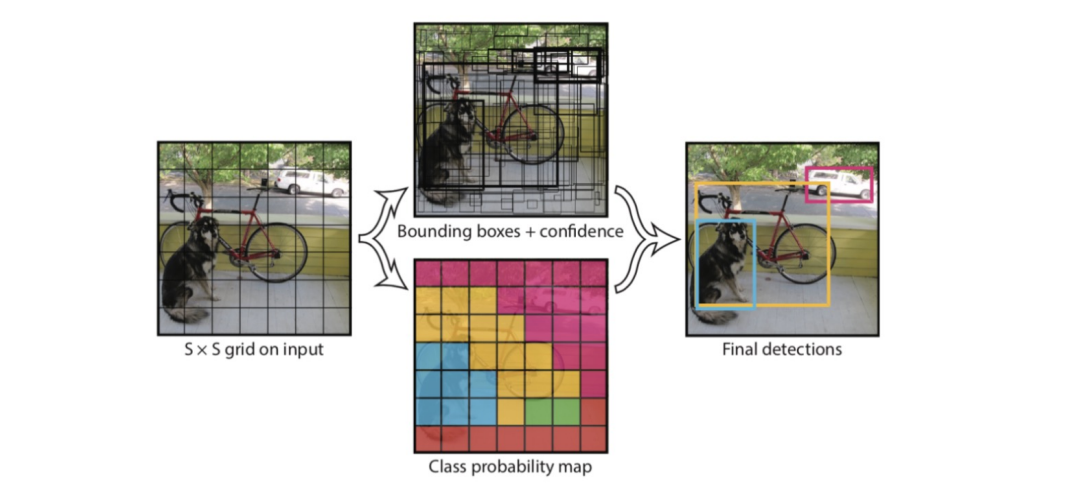
-초기에 앵커박스를 생성하여 bounding box 예측
- 초기 앵커박스 생성시 해당 박스의 신뢰도
- 해당 그리드에 물체가 있을 확률 Pr과 예측한 박스의 Ground Truth박스와의 겹치는 영역을 비율을 나타내는 loU를 곱해서 계산
- 각각의 그리드마다 C개의 클래스에 대하여 해당 클래스의 확률 계산
YOLO 실제로 사용해보기
YOLOv3 를 배포하신 원작자분의 깃허브에서
clone하거나 다운
!python image.py
!python video.py