여러 딥러닝 프레임워크 중에 Tensorflow, Pytorch를 배워보자.
딥러닝 프레임워크의 기본은 다음과 같다.
1.Tensor 생성하고 다루기
2. 연산 정의
3. 최적화(미분)
4. 데이터 다루기
Tensorflow
1. tensor 다루기
tensor란? 구조적으로 쌓여있는 숫자의 집합
shape, dtype은 항상 체크, 두 가지 모두 동일해야 연산 가능
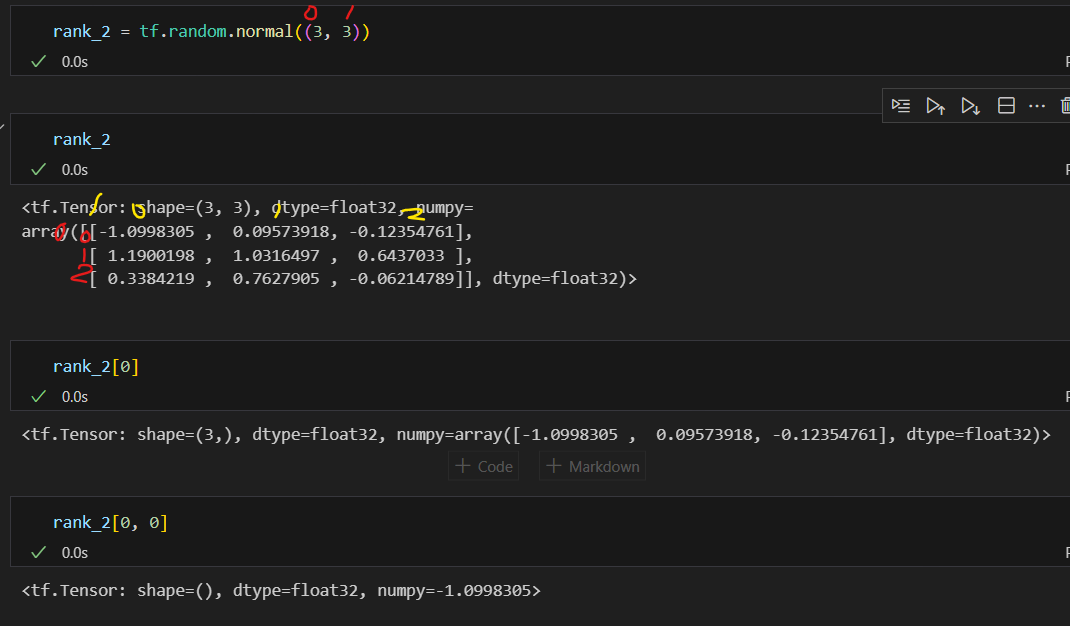
Rank 수 확인 : .ndim
constant
tf.constant()
dtype
dtype은 변수 생성 시, 미리 설정해줄 수도 있고 tf.cast(변수명, tf.float64)로 변경 가능
특정 값의 Tensor 생성
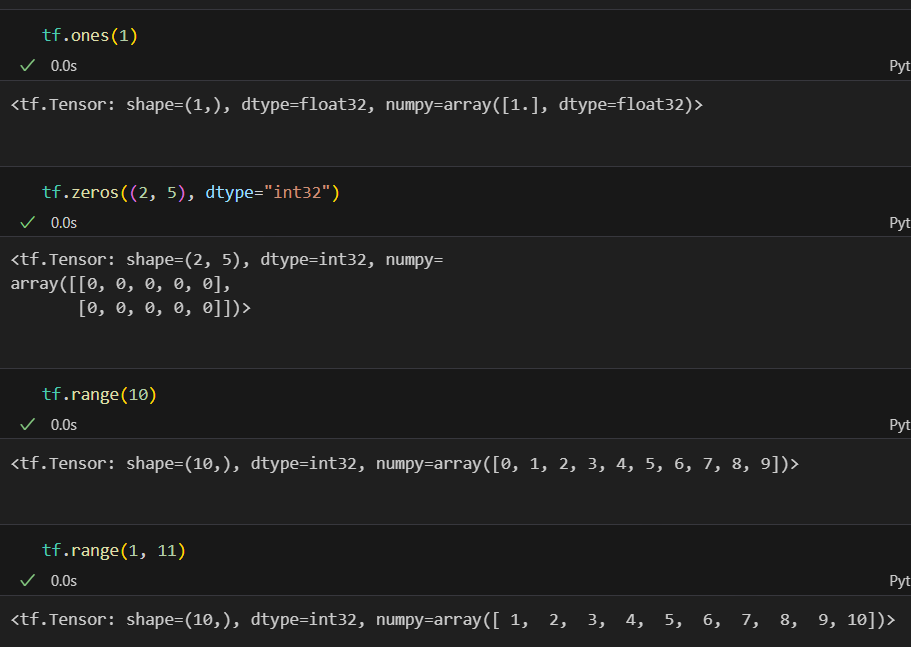
tf.ones()
tf.zeros()
tf.range()
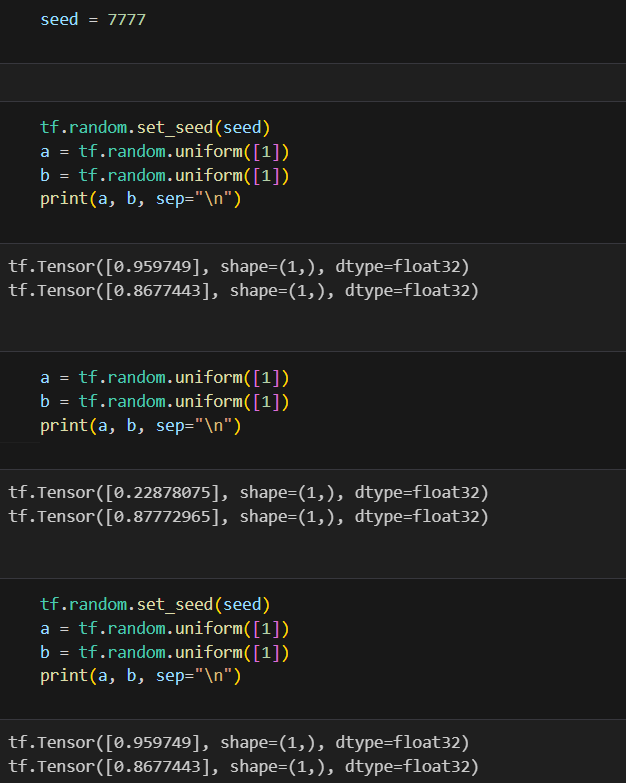
Random Value(난수)
- 무작위 값을 생성할 때 필요.
- Noise를 재현 한다거나, test를 한다거나 할 때 많이 사용됨
- 데이터 타입은 상수형태로 반환됨
tf.random 에 구현 되어 있음.

*Random seed 관리 하기**
tf.random.set_seed({seed_number})
- Random value로 보통 가중치를 초기화
- 이외에도 학습과정에서 Random value가 많이 사용됨.
- 이를 관리 안해주면, 자신이 했던 작업이 동일하게 복구 또는 재현이 안됨.
- 항상 Random seed를 고정해두고 개발 한다
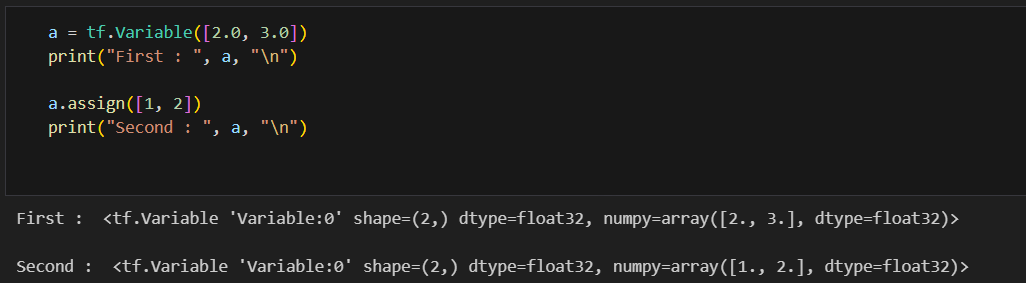
Variable(변수)
tf.Variable()
- 미지수, 가중치를 정의할 때 사용
- 직접 사용할 일이 많지는 않음
- 변수 정의는 변수 생성 + 초기화
이 변수에 텐서를 할당 할 때,
텐서는 기존 메모리의 크기(shape)이 동일해야하고, dtype은 달라도 됨. 변수에 맞게 텐서의 dtype이 재할당됨
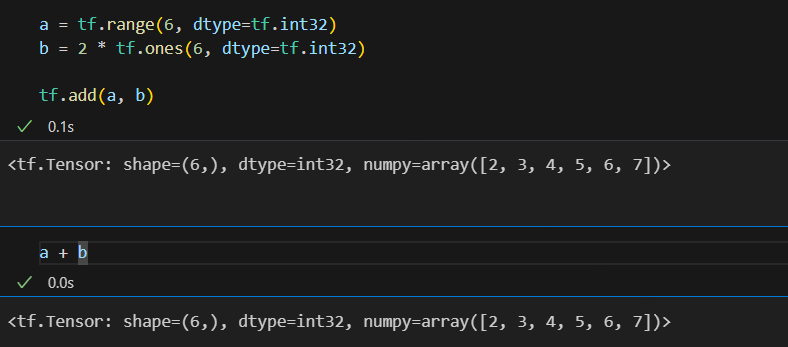
Tensor 연산
아래 기본연산은 연산자 기호 사용가능
tf.add: 덧셈tf.subtract: 뺄셈tf.multiply: 곱셈tf.divide: 나눗셈tf.pow: n-제곱tf.negative: 음수 부호
그 외 여러가지 연산
tf.abs: 절대값tf.sign: 부호tf.round: 반올림tf.ceil: 올림tf.floor: 내림tf.square: 제곱tf.sqrt: 제곱근tf.maximum: 두 텐서의 각 원소에서 최댓값만 반환.tf.minimum: 두 텐서의 각 원소에서 최솟값만 반환.tf.cumsum: 누적합tf.cumprod: 누적곱
Axis 이해하기
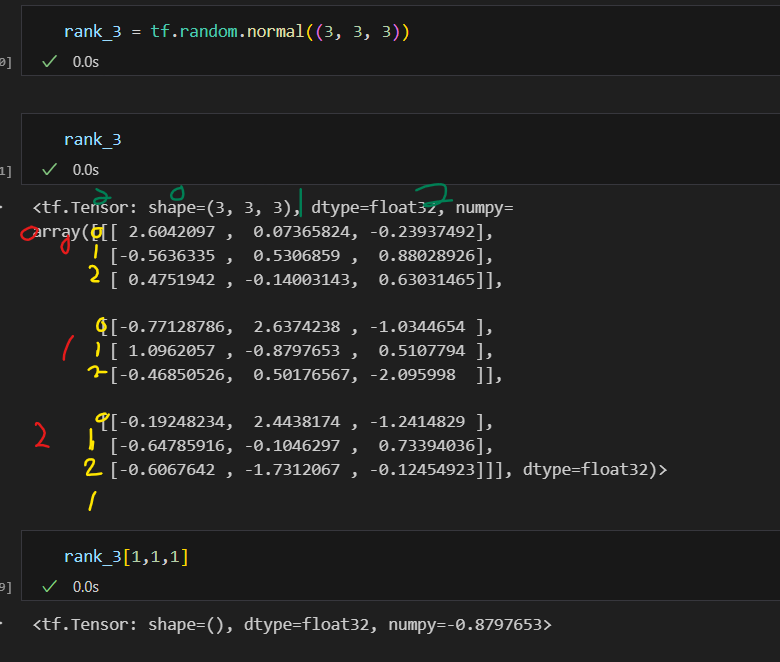
차원 축소 연산
tf.reduce_mean: 설정한 축의 평균을 구한다.tf.reduce_max: 설정한 축의 최댓값을 구한다.tf.reduce_min: 설정한 축의 최솟값을 구한다.tf.reduce_prod: 설정한 축의 요소를 모두 곱한 값을 구한다.tf.reduce_sum: 설정한 축의 요소를 모두 더한 값을 구한다.
행렬과 관련된 연산
tf.matmul: 내적tf.linalg.inv: 역행렬
크기 및 차원을 바꾸는 명령
tf.reshape: 벡터 행렬의 크기 변환tf.transpose: 전치 연산tf.expand_dims: 지정한 축으로 차원을 추가tf.squeeze: 벡터로 차원을 축소
a = tf.range(6, dtype=tf.int32) # [0, 1, 2, 3, 4, 5]
print("a :", a, "\n")
a_2d = tf.reshape(a, (2, 3)) # 1차원 벡터는 2x3 크기의 2차원 행렬로 변환
print("a_2d :", a_2d, "\n")
a_2d_t = tf.transpose(a_2d) # 2x3 크기의 2차원 행렬을 3x2 크기의 2차원 행렬로 변환
print("a_2d_t:", a_2d_t, "\n")
a_3d = tf.expand_dims(a_2d, 0) # 2x3 크기의 2차원 행렬을 1x2x3 크기의 3차원 행렬로 변환
print("a_3d :", a_3d, "\n")
a_4d = tf.expand_dims(a_3d, 3) # 1x2x3 크기의 3차원 행렬을 1x2x3x1 크기의 4차원 행렬로 변환, 3대신 -1 써도 됨
print("a_4d :", a_4d, "\n")
a_1d = tf.squeeze(a_4d) #크기가 1인 차원만 줄이는
print("a_1d :", a_1d, "\n") # 1x2x3x1 크기의 4차원 행렬을 1차원 벡터로 변환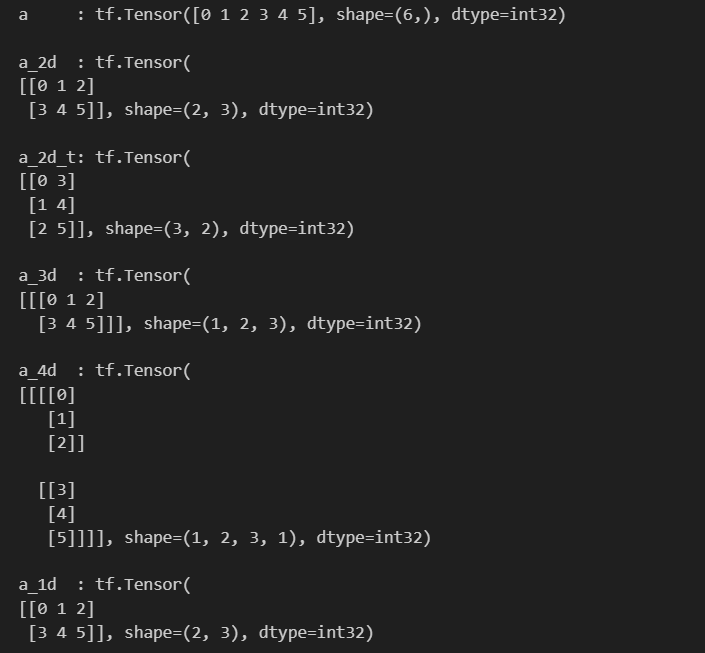
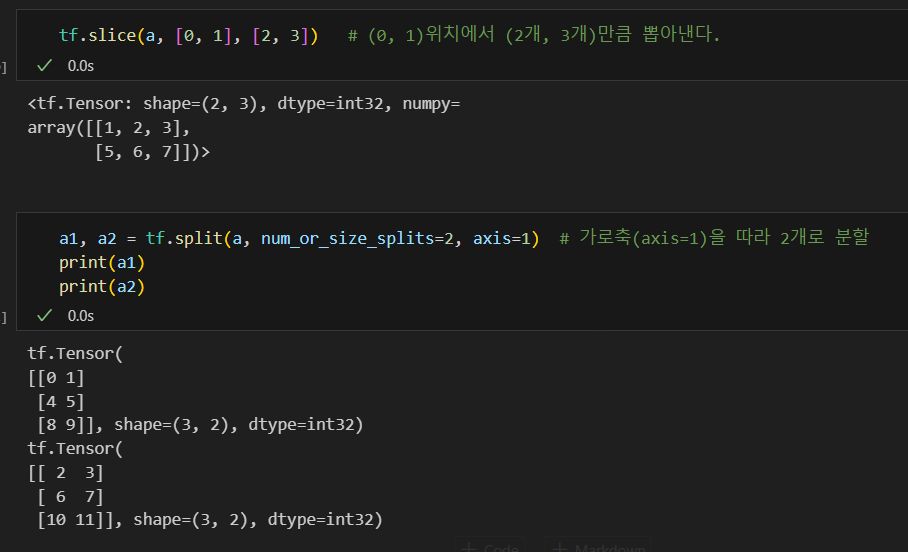
텐서를 나누거나 두 개 이상의 텐서를 합치는 명령
tf.slice: 특정 부분을 추출tf.split: 분할tf.concat: 합치기tf.tile: 복제-붙이기tf.stack: 합성tf.unstack: 분리
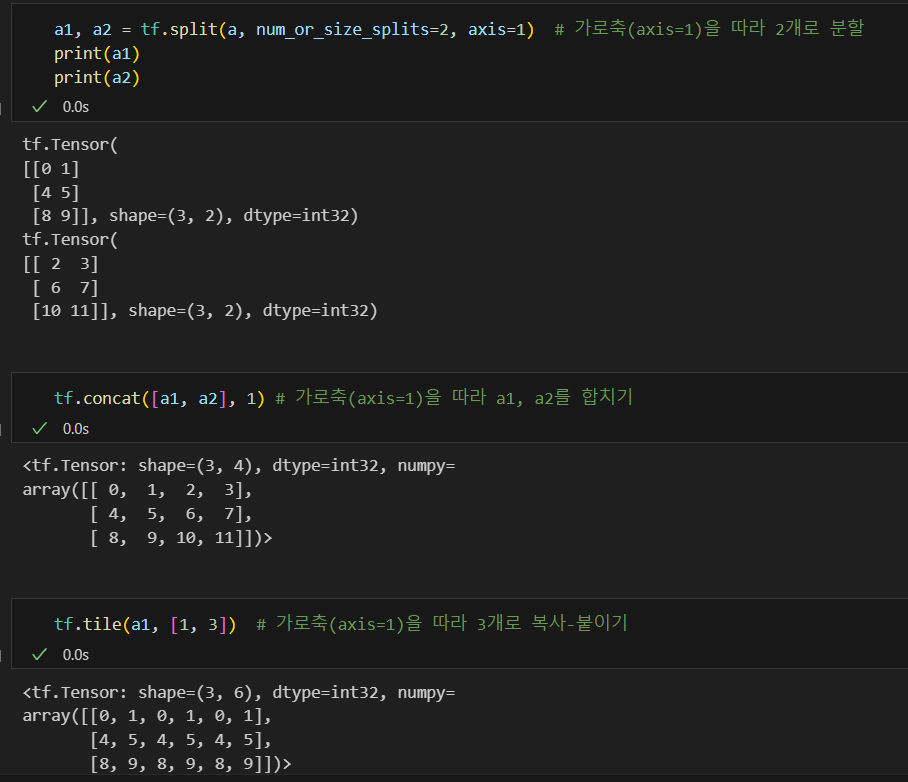
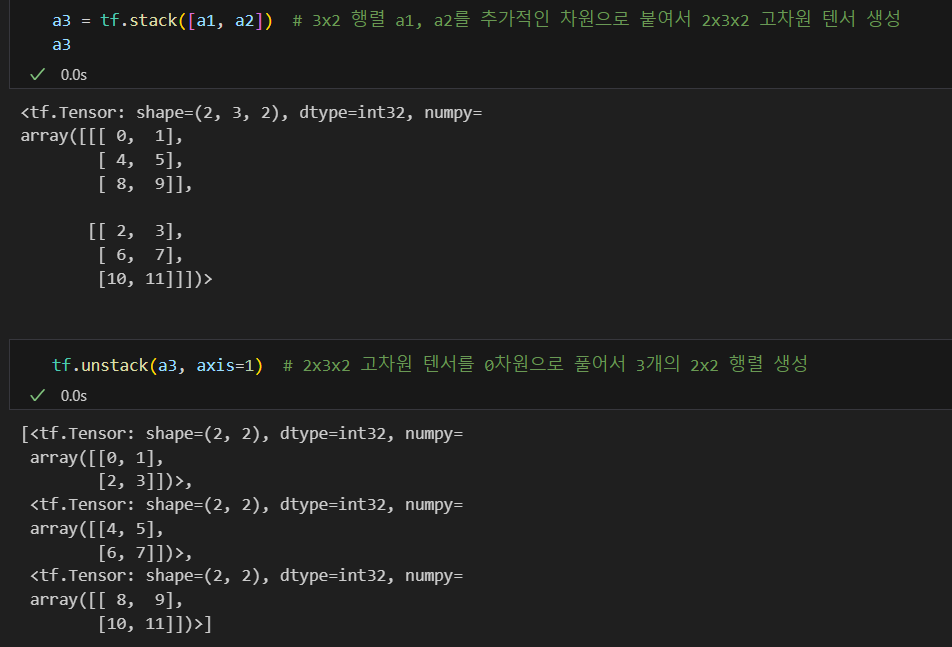
2. 최적화
자동미분
필요한 연산 기록 tf.GradientTape
미분 tape.gradient()
tf.GradientTape는 컨텍스트(context) 안에서 실행된 모든 연산을 테이프(tape)에 "기록"
그 다음 후진 방식 자동 미분(reverse mode differentiation)을 사용해 테이프에 "기록된" 연산의 그래디언트를 계산
scaler를 scalar로 미분
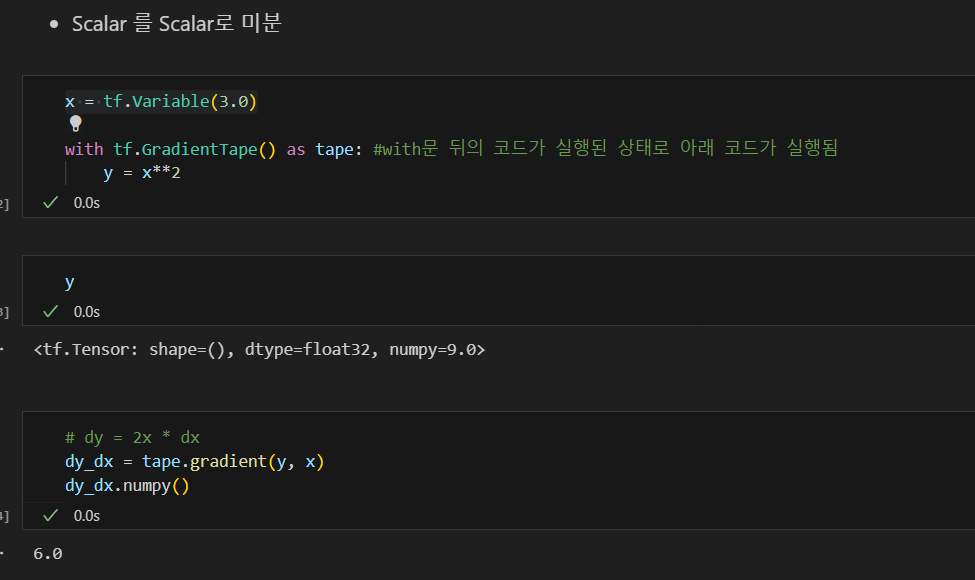
scaler를 vector로 미분
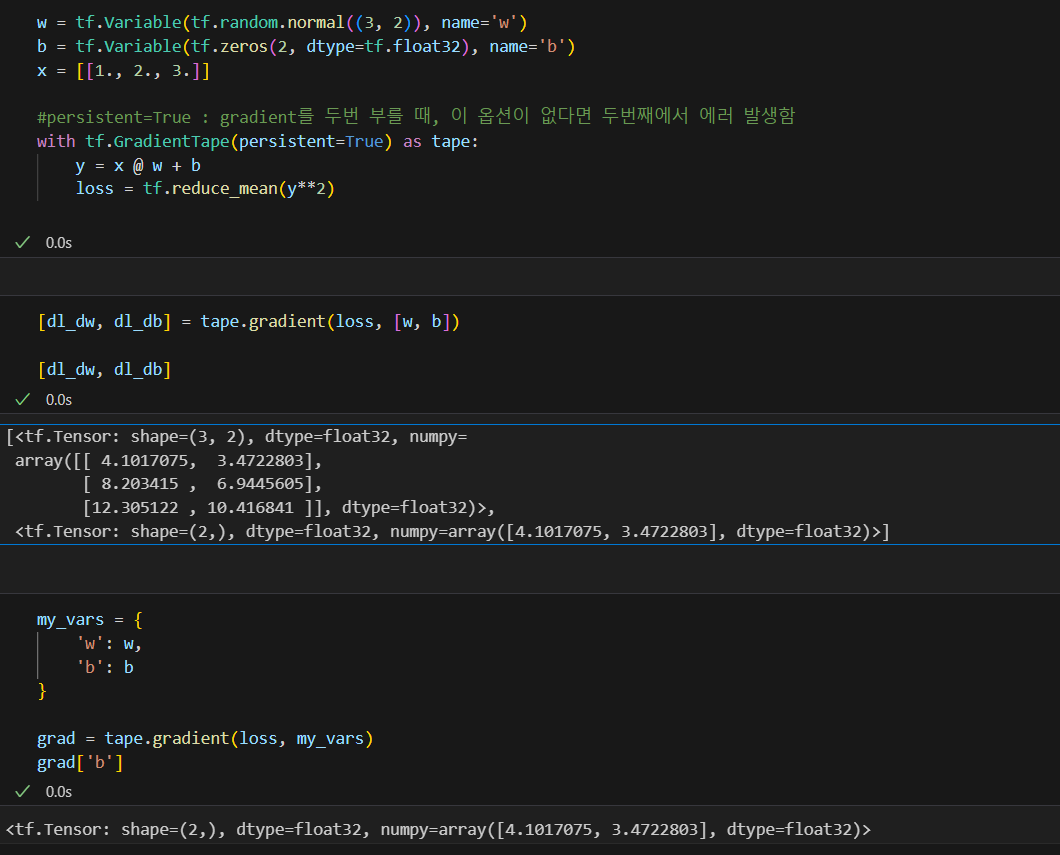
자동미분 컨트롤 하기
tf.Variable만 기록- A variable + tensor 는 tensor를 반환하므로 기록x
trainable조건으로 미분 기록을 제어
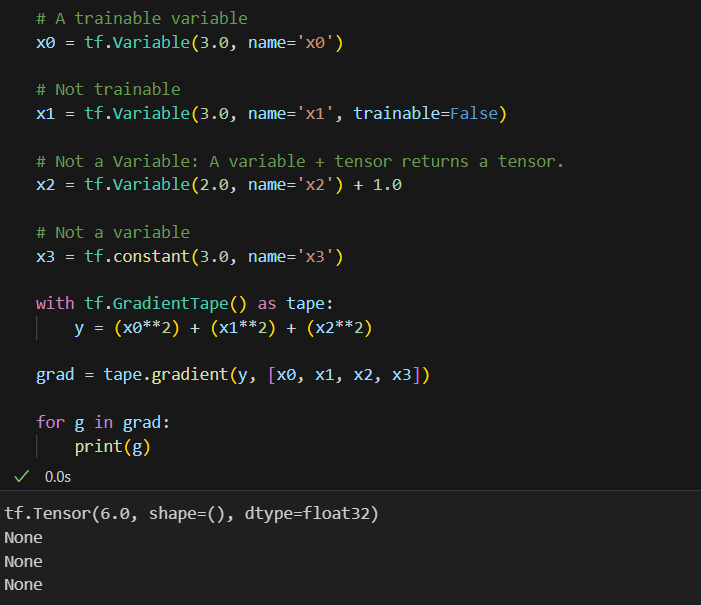
기록되고 있는 variable 확인하기
tape.watched_variables()
Linear Regression
가상의 데이터셋으로 실습
#가상 데이터 생성
W_true = 3.0
B_true = 2.0
X = tf.random.normal((500,1)) #데이터 개수 500, feature 1
noise = tf.random.normal((500,1))
y = X * W_true + B_true + noise
#학습을 진행할 변수
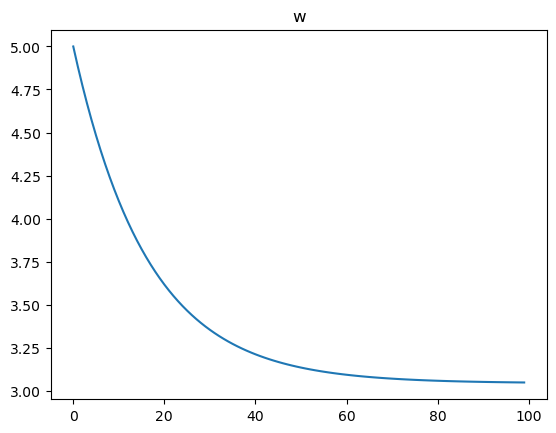
w = tf.Variable(5.)
b = tf.Variable(0.)
#학습현황을 기록하기 위함
w_records = []
b_records = []
loss_records = []
lr = 0.03
for epoch in range(100):
#매 epoch마다 한 번씩 학습
with tf.GradientTape() as tape:
y_hat = X * w + b
loss = tf.reduce_mean(tf.square(y - y_hat))
w_records.append(w.numpy())
b_records.append(b.numpy())
loss_records.append(loss.numpy())
dw, db = tape.gradient(loss, [w,b])
#assign(w-lr*dw) = assign_sub(lr*dw)
w.assign(w - lr*dw)
b.assign_sub(lr *db)결과확인
plt.plot(loss_records)
plt.title('loss')
plt.show()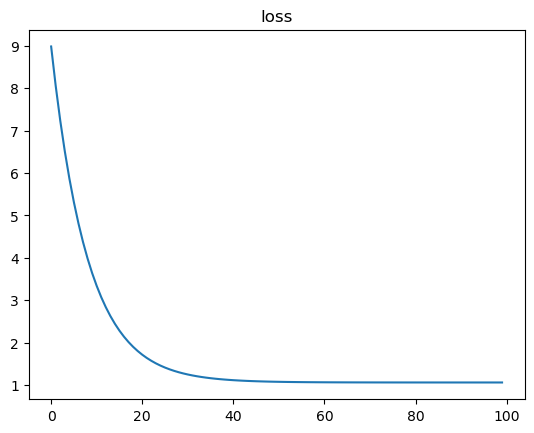
Dataset 당뇨병 진행도 예측 하기
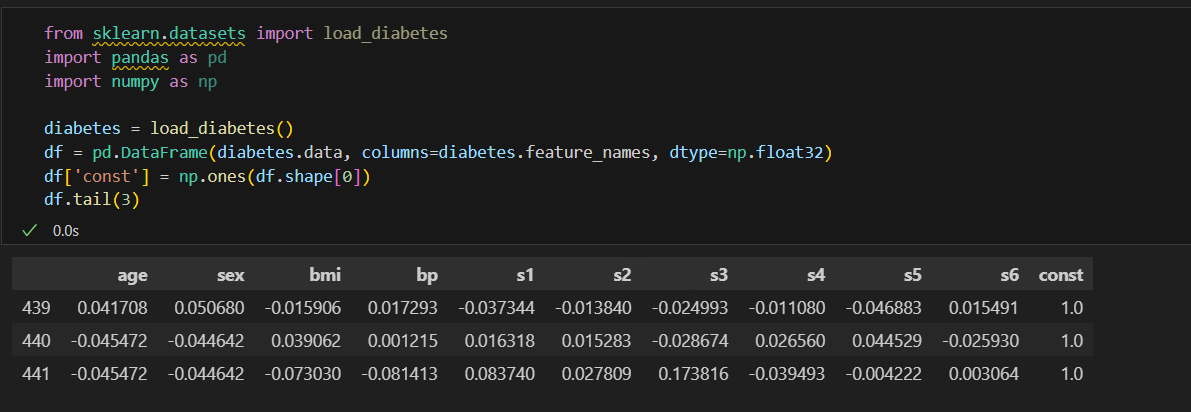

shape
X = df
y = tf.expand_dims(diabetes.target,axis=1)
X.shape, y.shape
#((442, 11), TensorShape([442, 1]))예측
XT = tf.transpose(X)
w = tf.matmul(tf.matmul(tf.linalg.inv(tf.matmul(XT,X)),XT),y)
y_pred = tf.matmul(X, w)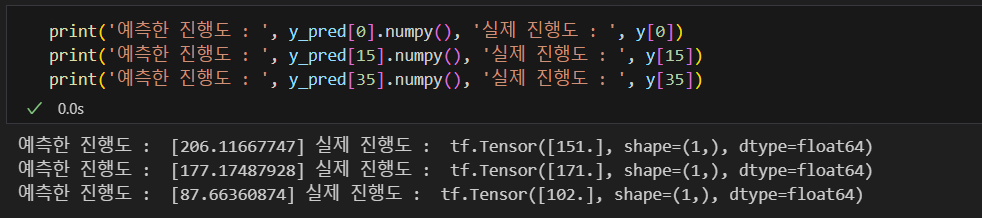
이번에는 SGD 방식으로 구현
- steepest gradient descents(전체 데이터 사용)
- 가중치는 Gaussian normal distribution에서의 난수로 초기화함.
- step size == 0.03(lr), 100 iteration
lr = 0.03
num_iter = 100
w_init = tf.random.normal((X.shape[-1],1), dtype=tf.float64) #X,w dtype을 맞춰줌
w = tf.Variable(w_init)
for i in range(num_iter):
with tf.GradientTape() as tape:
y_hat = tf.matmul(X, w)
loss = tf.reduce_mean((y-y_hat)**2)
dw = tape.gradient(loss, w)
w.assign_sub(lr*dw)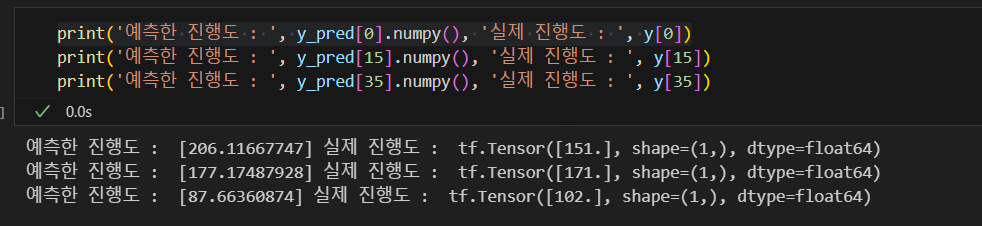
퍼셉트론
Iris 데이터 중 두 종류를 분류하는 퍼셉트론
y값은 1 또는 -1을 사용하고 활성화 함수로는 하이퍼탄젠트(hypertangent)함수를 사용한다.
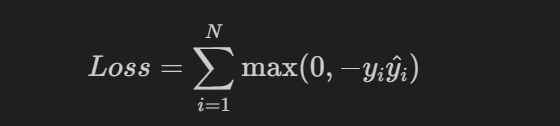
#데이터 준비
from sklearn.datasets import load_iris
iris = load_iris()
idx = np.in1d(iris.target, [0, 2]) #setosa와 virginica 클래스만 사용
X_data = iris.data[idx, 0:2] #feature로 sepal 컬럼만 사용
y_data = (iris.target[idx] - 1.0)[:, np.newaxis]
X_data.shape, y_data.shape #((100, 2), (100, 1))
num_iter = 500
lr = 0.0003퍼셉트론 구현
#변수 생성
w = tf.Variable(tf.random.normal([2,1], dtype=tf.float64))
b = tf.Variable(tf.random.normal([1,1], dtype=tf.float64))
zero = tf.constant(0, dtype=tf.float64)
for epoch in range(num_iter):
for i in range(X_data.shape[0]):
x = X_data[i:i+1] #X_data[i]는 rank가 1이 나와서 차원을 추가해줌
y = y_data[i:i+1] #y_data[i]는 rank가 1이 나와서 차원을 추가해줌
with tf.GradientTape() as tape:
logit = tf.matmul(x,w)+b
y_hat = tf.tanh(logit)
loss = tf.maximum(zero, tf.multiply(-y, y_hat))
grad = tape.gradient(loss, (w,b))
w.assign_sub(lr * grad[0])
b.assign_sub(lr * grad[1])
y_pred = tf.tanh(tf.matmul(X_data, w) + b)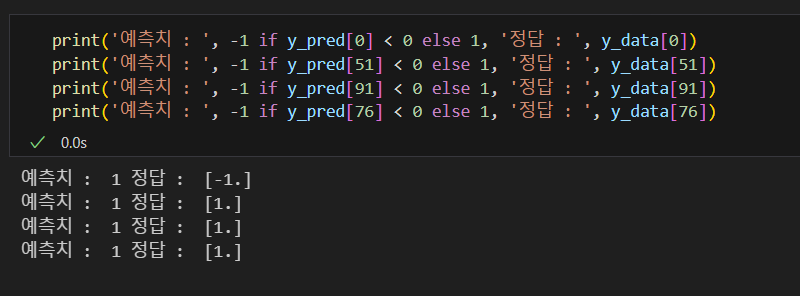
3. 간단한 Model 학습 시키기
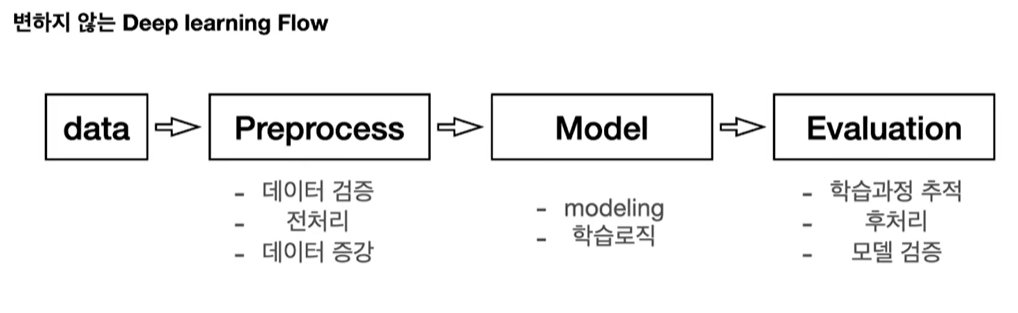
TensorFlow에서 제공하는 MNIST 예제로 실습해보자
1. 데이터 가져오기
(train_x, train_y), (test_x, test_y) = tf.keras.datasets.mnist.load_data()데이터 shape, dtype 확인
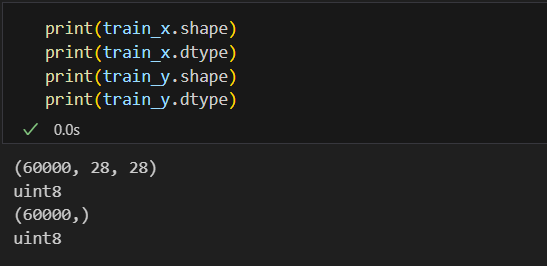
데이터를 받으면 데이터를 이해하기 위해 노력해야한다. 그래서 아래와 같은 작업을 해보았다.
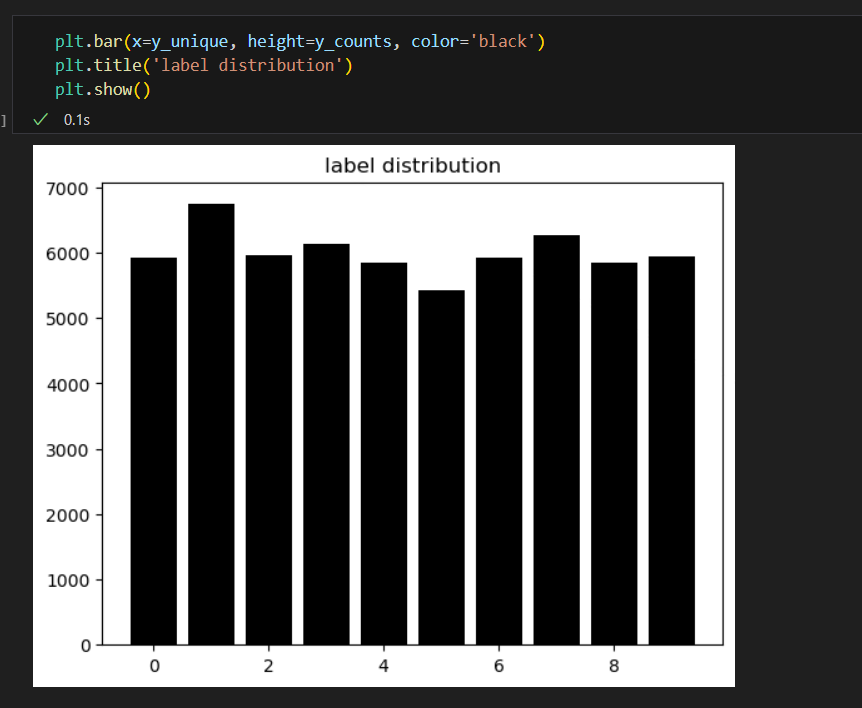
2. Preprocessing
불러온 데이터를 모델의 입력값으로 사용될 수 있도록 변환, 데이터 검증, 데이터 증강
가장 실수가 많이 나오는 부분이므로 체크 !!
데이터 검증
데이터 검증은
- 데이터 중에 학습에 포함 되면 안되는 것이 있는가? ex> 개인정보가 들어있는 데이터, 테스트용 데이터에 들어있는것, 중복되는 데이터
- 학습 의도와 다른 데이터가 있는가? ex> 얼굴을 학습하는데 발 사진이 들어가있진 않은지(가끔은 의도하고 일부러 집어넣는 경우도 있음)
- 라벨이 잘못된 데이터가 있는가? ex> 7인데 1로 라벨링, 고양이 인데 강아지로 라벨링
등으로 할 수 있다.
#데이터 검증 - 이상한 픽셀값 걸러내기
def validate_pixel_scale(x):
return 255 >= x.max() and 0 <= x.min()
validated_train_x = np.array([x for x in train_x if validate_pixel_scale(x)])
validated_train_y = np.array([y for x,y in zip(train_x, train_y) if validate_pixel_scale(x)])
#확인
print(validated_train_x.shape) #(60000, 28, 28)
print(validated_train_y.shape) #(60000,)전처리
- 입력하기 전에 모델링에 적합하게 처리
- 대표적으로 Scaling, Resizing, label encoding
- dtype, shape 항상 체크
#scaling
def scale(x):
return (x / 255.0).astype(np.float32) #(x/255) : 0~1 사이 값 , 그냥 numpy로 놔두면 dtype이 float64라서 변환 필요
sample = scale(validated_train_x[777])
#확인
sample.max(), sample.min()
#시각화로 확인
sns.displot(sample)
#데이터에 적용
scaled_trainx_x = np.array([scale(x) for x in validated_train_x])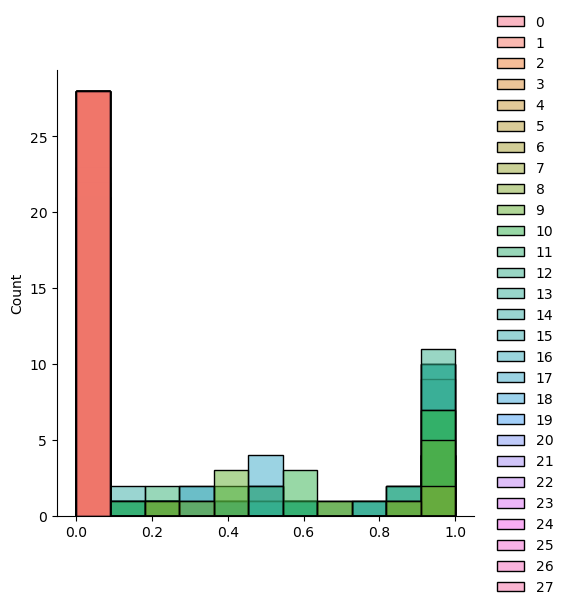
Flattening
모델 중에서 1차원 벡터가 input이 되는 레이어들이 있을 경우 flatten을 해준다.
flattened_train_x = scaled_trainx_x.reshape((60000, -1))
#확인
flattened_train_x.shape #(60000, 784)Label Encoding
타겟 데이터가 범주형인 경우, 이름 같은 것들은 카테고리 데이터로 변환이 필요하다.
- One-Hot encoding : 각 클래스에 해당하면 1, 나머지 클래스에 대해서는 0으로 매겨주는 작업이다.
tf.keras.utils.to_categorical
tf.keras.utils.to_categorical(5, num_classes=10)
#결과: array([0., 0., 0., 0., 0., 1., 0., 0., 0., 0.], dtype=float32)
ohe_train_y = np.array([tf.keras.utils.to_categorical(y, num_classes=10) for y in validated_train_y])
#확인
ohe_train_y.shape #(60000, 10)보통은 큰 작업을 하나의 클래스로 만들어서 관리한다.
class DataLoader():
def __init__(self):
(self.train_x, self.train_y), \
(self.test_x, self.test_y) = tf.keras.datasets.mnist.load_data()
def validate_pixel_scale(self, x):
return 255 >= x.max() and 0 <= x.min()
def scale(self, x):
return (x / 255.0).astype(np.float32)
def preprocess_dataset(self, dataset):
feature, target = dataset
validated_x = np.array([x for x in feature if self.validate_pixel_scale(x)])
validated_y = np.array([y for x, y in zip(feature,target) if self.validate_pixel_scale(x)])
#scale
scaled_x = np.array([self.scale(x) for x in validated_x])
#flatten
flatten_x = scaled_x.reshape((scaled_x.shape[0], -1))
#label encoding
ohe_y = np.array([tf.keras.utils.to_categorical(y, num_classes=10) for y in validated_y])
return flatten_x, ohe_y
def get_train_dataset(self):
return self.preprocess_dataset((self.train_x, self.train_y))
def get_test_dataset(self):
return self.preprocess_dataset((self.test_x, self.test_y))클래스를 생성한 후, 아래와 같이 객체를 생성하여 코드를 실행
#객체 생성
mnist_loader = DataLoader()
#train 데이터에 실행
train_x, train_y = mnist_loader.get_train_dataset()
#test 데이터에 실행
test_x, test_y = mnist_loader.get_test_dataset()
#확인
print(train_x.shape) #(60000, 784)
print(test_x.shape) #(10000, 784)
print(train_y.shape) #(60000, 10)
print(test_y.shape) #(10000, 10)3. Modeling
모델링은 다음이 크게 3 단계이다.
1. 모델 정의
2. 학습 로직 - 비용함수, 학습파라미터 세팅
3. 학습
1) 모델 정의
sequential()로 모델을 정의하고, add 함수를 이용하여 layer 추가 가능
from tensorflow.keras.layers import Dense, Activation
model = tf.keras.Sequential()
#layer 추가
model.add(Dense(15, input_dim=784))
model.add(Activation('sigmoid'))
model.add(Dense(10))
model.add(Activation('softmax'))
#모델 확인
model.summary()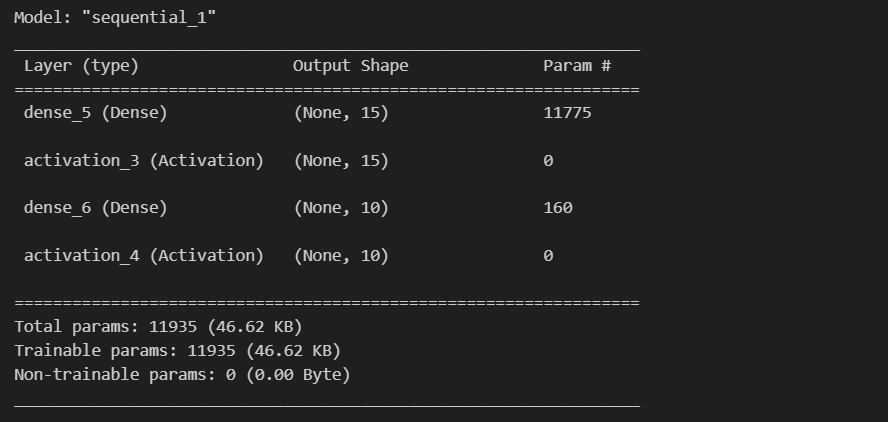
2) 학습 로직
#learning_rate = 0.03
opt = tf.keras.optimizers.SGD(0.03)
loss = tf.keras.losses.categorical_crossentropy
#모델 정의(최적화, loss 함수 선택, 성능 지표 선택)
model.compile(optimizer=opt, loss=loss, metrics=['accuracy'])3) 학습
hist = model.fit(train_x, train_y, epochs=10, batch_size=256) # batch_size= 32 디폴트값4. Evaluation
학습 과정 추적
hist.history
#시각화
plt.figure(figsize=(10,5))
plt.subplot(121)
plt.plot(hist.history['loss'])
plt.title('loss')
plt.subplot(122)
plt.plot(hist.history['accuracy'])
plt.title('acc')
plt.show()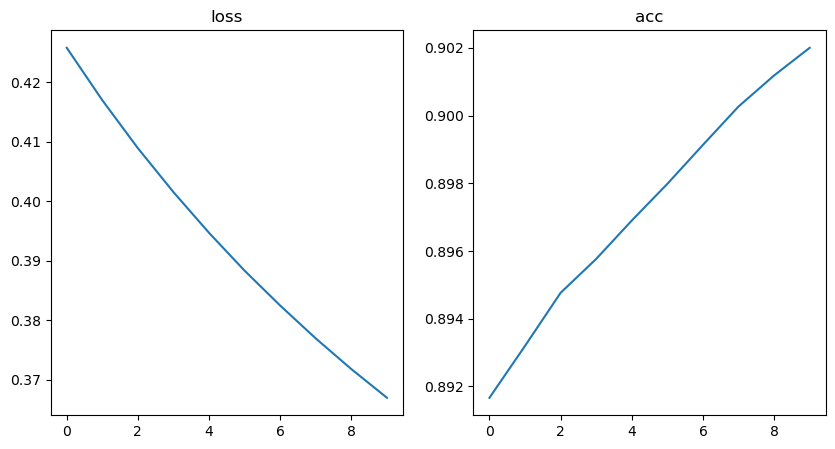 loss의 경우 계속 떨어지다가 유지되는 구간이 없고
loss의 경우 계속 떨어지다가 유지되는 구간이 없고
acc도 올라가다가 유지되는 구간이 없다.
모두 유지가 되는 구간이 없어서 epoch을 늘려서 학습을 더 시켜야함
Test / 모델 검증
model.evaluate()

후처리
Test 데이터에 대해 어떻게 예측을 했는지 확인
.predict를 통해 예측하고,
분류 문제이므로 argmax를 통해 가장 큰 값의 인덱스를 찾아야 한다.
pred = model.predict(test_x[:1])
pred.argmax() # 7
sample_img = test_x[0].reshape((28,28)) * 255
plt.imshow(sample_img)
print(test_y[0]) 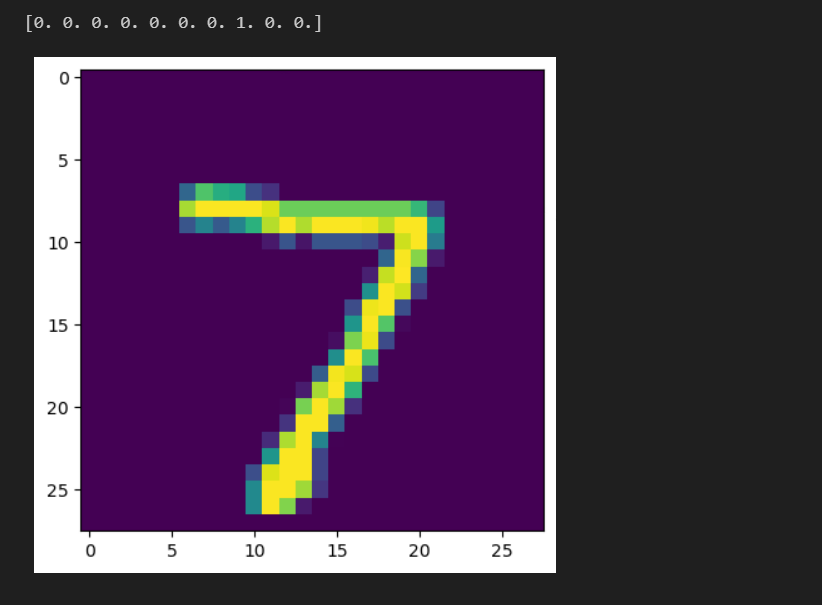
4. Modeling
모델을 정의 하는 방법
- Sequencial (우리가 지금까지 모델을 만들던 방식)
- Functional API model
- Sub class model
1) Sequencial 방식
sequencial으로 CNN(VGGNet)을 구현해보자.
Dataloader
Convolution Layer는 주로 이미지데이터처리를 위해 사용되기 때문에 컬러이미지는 (height, width, 3) 흑백은 (height, width, 1)로 사용한다.
mnist 데이터는 아래와 같이 차원 확장이 필요하다.
ex) (num_data, 28, 28) => (num_data, 28, 28, 1)class DataLoader():
def __init__(self):
(self.train_x, self.train_y), \
(self.test_x, self.test_y) = tf.keras.datasets.mnist.load_data()
def validate_pixel_scale(self, x):
return 255 >= x.max() and 0 <= x.min()
def scale(self, x):
return (x / 255.0).astype(np.float32)
def preprocess_dataset(self, dataset):
feature, target = dataset
validated_x = np.array([x for x in feature if self.validate_pixel_scale(x)])
validated_y = np.array([y for x, y in zip(feature,target) if self.validate_pixel_scale(x)])
#scale
scaled_x = np.array([self.scale(x) for x in validated_x])
#expand
expanded_x = scaled_x[:,:,:,np.newaxis]
#label encoding
ohe_y = np.array([tf.keras.utils.to_categorical(y, num_classes=10) for y in validated_y])
return expanded_x, ohe_y
def get_train_dataset(self):
return self.preprocess_dataset((self.train_x, self.train_y))
def get_test_dataset(self):
return self.preprocess_dataset((self.test_x, self.test_y))
#확인
mnist_loader = DataLoader()
train_x, train_y = mnist_loader.get_train_dataset()
test_x, test_y = mnist_loader.get_test_dataset()
print(train_x.shape) #(60000, 28, 28, 1)
print(test_x.shape) #(10000, 28, 28, 1)
print(train_y.shape) #(60000, 10)
print(test_y.shape) #(10000, 10)layer
사진추가
VGGNet에서 사용되는 Layer들
Conv2D, MaxPool2D, Flatten, Dense
tf.keras.layers.Activationtf.keras.layers.MaxPool2Dtf.keras.layers.Flattentf.keras.layers.Dense
Conv2D
tf.keras.layers.Conv2D(필터개수, 커널사이즈, strides, 패딩옵션, activation func)
tf.keras.layers.Conv2D(64, 3, 1, padding='same', activation='relu')- filters: layer에서 사용할 Filter(weights)의 갯수
- kernel_size: Filter(weights)의 사이즈
- strides: 몇 개의 pixel을 skip 하면서 훑어지나갈 것인지 (출력 피쳐맵의 사이즈에 영향을 줌)
- padding: zero padding을 만들 것인지. VALID는 Padding이 없고, SAME은 Padding이 있음 (출력 피쳐맵의 사이즈에 영향을 줌)
- activation: Activation Function을 지정
MaxPool2D
tf.keras.layers.MaxPool2D(pool_size, strides, 패딩옵션)
- pool_size: Pooling window 크기
- strides: 몇 개의 pixel을 skip 하면서 훑어지나갈 것인지
- padding: zero padding을 만들 것인지
-> pool_size에서 최댓값만 추출하여 결국 차원이 축소가 됨
Dense
-
units : 노드 갯수
-
activation : 활성화 함수
-
use_bias : bias 를 사용 할 것인지
-
kernel_initializer : 최초 가중치를 어떻게 세팅 할 것인지
-
bias_initializer : 최초 bias를 어떻게 세팅 할 것인지
Sequencial 방식으로 Layer들을 이용해 모델 만들기
from tensorflow.keras.layers import Conv2D, MaxPool2D, Flatten, Dense
#Sequential
model = tf.keras.Sequential() #sequential() 방식으로 모델을 만들때, 첫번째 더해지는 layer에 input_shape을 명시해야함. 그 이후에는 안해도 됨
model. add(Conv2D(32, kernel_size=3, padding='same', activation='relu', input_shape=(28,28,1)))
model. add(Conv2D(32, kernel_size=3, padding='same', activation='relu'))
model.add(MaxPool2D()) #defalut (2,2)
model.add(Conv2D(64, kernel_size=3, padding='same', activation='relu'))
model.add(Conv2D(64, kernel_size=3, padding='same', activation='relu'))
model.add(MaxPool2D())
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(64, activation='relu'))
model.add(Dense(10, activation='softmax'))
model.summary()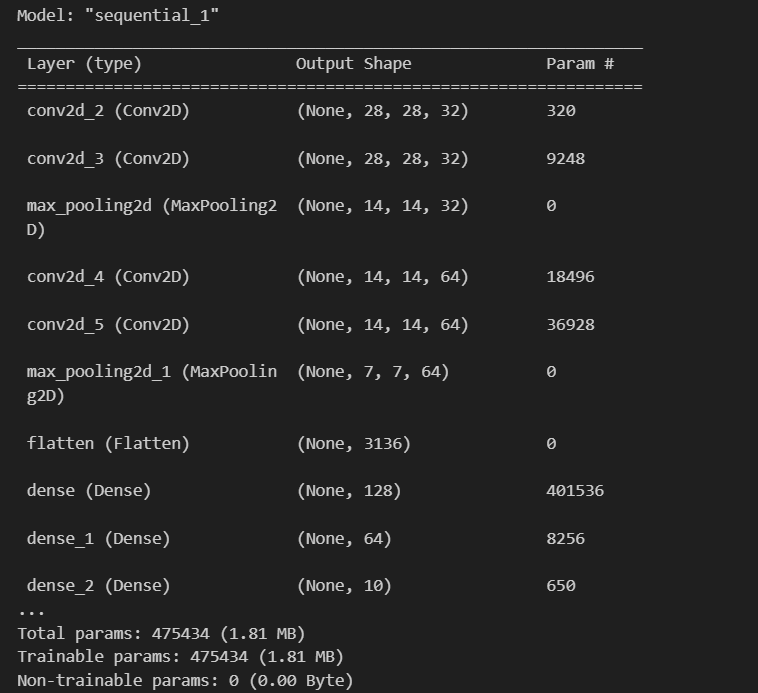
모델을 compile하고 학습하면
#학습 로직
lr = 0.03
opt = tf.keras.optimizers.Adam(lr)
loss = tf.keras.losses.categorical_crossentropy
model.compile(optimizer=opt, loss=loss, metrics=['accuracy'])
#학습
hist = model.fit(train_x, train_y, epochs=2, batch_size=128, validation_data=(test_x, test_y))
#validation_data=(test_x, test_y) : 매 epoch마다 성능을 표시결과 확인
hist.history
#시각화
plt.figure(figsize=(10,5))
plt.subplot(221)
plt.plot(hist.history['loss'])
plt.subplot(222)
plt.plot(hist.history['accuracy'])
plt.subplot(223)
plt.plot(hist.history['val_loss'])
plt.subplot(224)
plt.plot(hist.history['val_accuracy'])
plt.tight_layout()
plt.show()
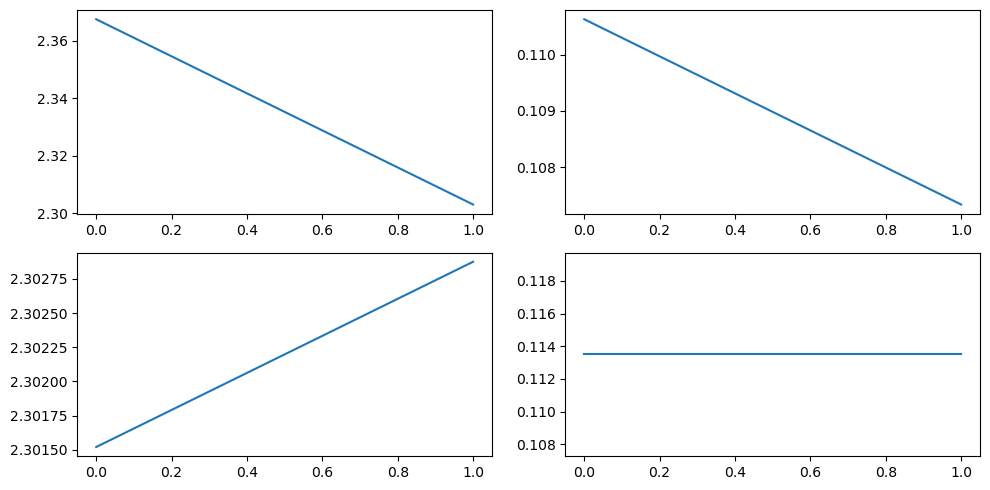
2. Functional API
- functional 함수를 바로 사용하는 것을 functional api
tf.keras.Sequential보다 더 유연하게 모델을 정의할 수 있는 방법.add없이 Input 모듈을 사용하여 바로 입력을 붙여주는 방법
Functional API로 VGGNet를 구현해보자
from tensorflow.keras.layers import Input, Conv2D, MaxPool2D, Flatten, Dense
input_shape = (28, 28, 1)
inputs = Input(input_shape) #Input이라는 함수를 써서 input을 명시해줌
net = Conv2D(32, kernel_size=3, padding='same', activation='relu')(inputs)
net = Conv2D(32, kernel_size=3, padding='same', activation='relu')(net)
net = MaxPool2D()(net)
net = Conv2D(64, kernel_size=3, padding='same', activation='relu')(net)
net = Conv2D(64, kernel_size=3, padding='same', activation='relu')(net)
net = MaxPool2D()(net)
net = Flatten()(net)
net = Dense(128, activation='relu')(net)
net = Dense(64, activation='relu')(net)
net = Dense(10, activation='softmax')(net)
#모델 생성
model = tf.keras.Model(inputs=inputs, outputs=net, name='VGGNet')
model.summary()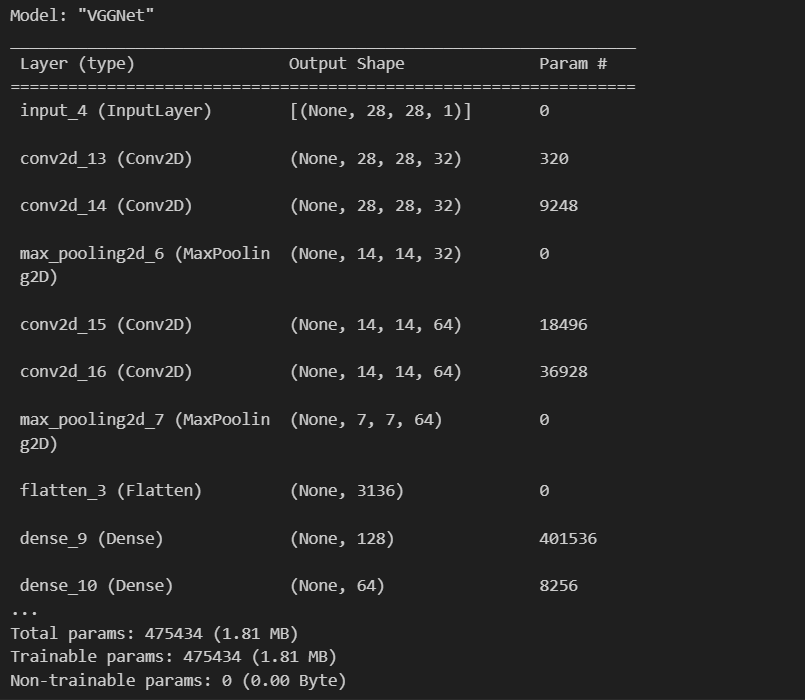
Functional API로 Resnet을 구현해보자
사진추가
Resnet은 위 그림과 같이 초기 입력값을 더해주는 과정이 필요하기 때문에 sequencial로는 구현할 수 없다.
CIfar10 dataset을 이용해 학습을 해보자.
#DataLoader
class DataLoader():
def __init__(self):
(self.train_x, self.train_y), \
(self.test_x, self.test_y) = tf.keras.datasets.cifar10.load_data()
def validate_pixel_scale(self, x):
return 255 >= x.max() and 0 <= x.min()
def scale(self, x):
return (x / 255.0).astype(np.float32)
def preprocess_dataset(self, dataset):
feature, target = dataset
validated_x = np.array([x for x in feature if self.validate_pixel_scale(x)])
validated_y = np.array([y for x, y in zip(feature,target) if self.validate_pixel_scale(x)])
#scale
scaled_x = np.array([self.scale(x) for x in validated_x])
#label encoding
ohe_y = np.array([tf.keras.utils.to_categorical(y, num_classes=10) for y in validated_y])
return scaled_x, np.squeeze(ohe_y,axis=1) #categorical을 거쳐서 rank가 늘어났기 때문에 1차원을 제거
def get_train_dataset(self):
return self.preprocess_dataset((self.train_x, self.train_y))
def get_test_dataset(self):
return self.preprocess_dataset((self.test_x, self.test_y))
loader = DataLoader()
train_x, train_y = loader.get_train_dataset()
test_x, test_y = loader.get_test_dataset()
print(train_x.shape) #(50000, 32, 32, 3)
print(test_x.shape) #(10000, 32, 32, 3)
print(train_y.shape) #(50000, 10)
print(test_y.shape) #(10000, 10)Functional API를 이용하여 ResNet을 구현
from tensorflow.keras.layers import Input, Conv2D, MaxPool2D, Flatten, Dense, Add
#Add : 입력 받은 것을 더해주는 기능
#Functional API
def build_resnet(input_shape):
inputs = Input(input_shape)
net = Conv2D(32, kernel_size=3, strides=2, padding='same', activation='relu')(inputs)
net = MaxPool2D()(net)
net1 = Conv2D(64, kernel_size=1, padding='same', activation='relu')(net)
net2 = Conv2D(64, kernel_size=3, padding='same', activation='relu')(net1)
net3 = Conv2D(64, kernel_size=1, padding='same', activation='relu')(net2)
net1_1 = Conv2D(64, kernel_size=1, padding='same', activation='relu')(net)
net = Add()([net1_1, net3])
net1 = Conv2D(64, kernel_size=1, padding='same', activation='relu')(net)
net2 = Conv2D(64, kernel_size=3, padding='same', activation='relu')(net1)
net3 = Conv2D(64, kernel_size=1, padding='same', activation='relu')(net2)
# net1_1 = Conv2D(64, kernel_size=1, padding='same', activation='relu')(net) #이미 64니까 필요없음
net = Add()([net, net3])
net = MaxPool2D()(net)
net = Flatten()(net)
net = Dense(10, activation='softmax')(net)
model = tf.keras.Model(inputs=inputs, outputs=net)
return model
#모델 정의
lr = 0.03
opt = tf.keras.optimizers.Adam(lr)
loss = tf.keras.losses.categorical_crossentropy
model.compile(optimizer=opt, loss=loss, metrics=['accuracy'])
hist = model.fit(train_x, train_y, epochs=1, batch_size=128, validation_data=(test_x, test_y))epochs를 10으로 하여 돌려봤을 때, 결과
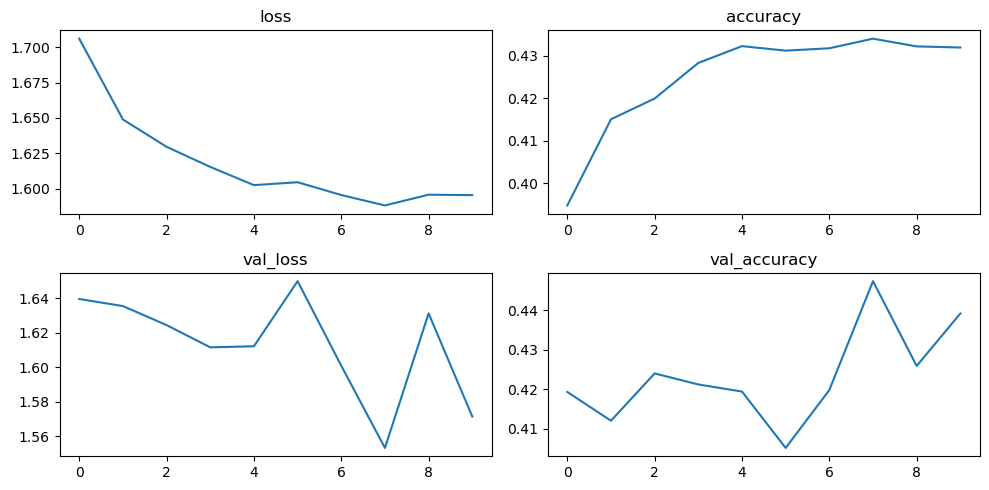
3) Sub class model
모델 이란 것은 Input을 Output으로 만들어주는 수식이다.
해당 기능을 수행하는 두 가지 클래스가 tf.keras.layers.Layer 와 tf.keras.layers.Model 클래스이다.
두가지 모두 연산을 추상화 하는 것으로 동일한 역할을 하지만, tf.keras.layers.Model 클래스의 경우 모델을 저장 하는 기능 과 fit 함수를 사용할 수 있다는 점에서 차이가 있다.
tf.keras.layers.Layer
tf.keras.layers.Model
Linear Regression을 Layer로 만들어 보자.
class LinearRegression(tf.keras.layers.Layer):
def __init__(self, units=1): #1차원 예측을 할거라서
super(LinearRegression, self).__init__()
self.units = units
def build(self, input_shape):
self.w = self.add_weight(
shape=(input_shape[-1], self.units),
initializer='random_normal',
trainable=True
)
self.b = tf.Variable(0.0)
def call(self, inputs):
return tf.matmul(inputs, self.w) + self.b가상 데이터를 적용시켜보면
W_true = np.array([3., 2., 4., 1.]).reshape(4,1)
B_true = np.array([1.])
X = tf.random.normal((500,4))
noise = tf.random.normal((500, 1))
y = X @ W_true + B_true + noise
opt = tf.keras.optimizers.SGD(learning_rate=0.03)
linear_layer = LinearRegression(1) #unit = 1
for epoch in range(100):
with tf.GradientTape() as tape:
y_hat = linear_layer(X)
loss = tf.reduce_mean(tf.square(y - y_hat))
grads = tape.gradient(loss, linear_layer.trainable_weights)
opt.apply_gradients(zip(grads, linear_layer.trainable_weights))
if epoch % 10 == 0:
print('epoch : {}, loss : {}'.format(epoch, loss.numpy()))ResNet을 Sub Class 로 구현 해보자
먼저 Residual Block Layer로 만들고,
ResNet Model을 만든다.
from tensorflow.keras.layers import Input, Conv2D, MaxPool2D, Flatten, Dense, Add
#layer
class ResidualBlock(tf.keras.layers.Layer):
def __init__(self, filters=32, filter_match=False):
super(ResidualBlock, self).__init__()
self.conv1 = Conv2D(filters, kernel_size=1, padding='same', activation='relu')
self.conv2 = Conv2D(filters, kernel_size=3, padding='same', activation='relu')
self.conv3 = Conv2D(filters, kernel_size=1, padding='same', activation='relu')
self.add = Add()
self.filters = filters
self.filter_match = filter_match
if self.filter_match:
self.conv_ext = Conv2D(filters, kernel_size=1, padding='same')
def call(self, inputs):
net1 = self.conv1(inputs)
net2 = self.conv2(net1)
net3 = self.conv3(net2)
if self.filter_match:
res = self.add([self.conv_ext(inputs), net3])
else:
res = self.add([inputs, net3])
return res
#Resnet model
class ResNet(tf.keras.Model):
def __init__(self, num_classes):
super(ResNet, self).__init__()
self.conv1 = Conv2D(32, kernel_size=3, strides=2, padding='same', activation='relu')
self.maxp1 = MaxPool2D()
self.block1 = ResidualBlock(64, True)
self.block2 = ResidualBlock(64)
self.maxp2 = MaxPool2D()
self.flat = Flatten()
self.dense = Dense(num_classes)
def call(self, inputs):
x = self.conv1(inputs)
x = self.maxp1(x)
x = self.block1(x)
x = self.block2(x)
x = self.maxp2(x)
x = self.flat(x)
return self.dense(x)
model = ResNet(10)
#dataloader
class DataLoader():
def __init__(self):
(self.train_x, self.train_y), \
(self.test_x, self.test_y) = tf.keras.datasets.cifar10.load_data()
def validate_pixel_scale(self, x):
return 255 >= x.max() and 0 <= x.min()
def scale(self, x):
return (x / 255.0).astype(np.float32)
def preprocess_dataset(self, dataset):
feature, target = dataset
validated_x = np.array([x for x in feature if self.validate_pixel_scale(x)])
validated_y = np.array([y for x, y in zip(feature,target) if self.validate_pixel_scale(x)])
#scale
scaled_x = np.array([self.scale(x) for x in validated_x])
#label encoding
ohe_y = np.array([tf.keras.utils.to_categorical(y, num_classes=10) for y in validated_y])
return scaled_x, np.squeeze(ohe_y,axis=1) #categorical을 거쳐서 rank가 늘어났기 때문에 1차원을 제거
def get_train_dataset(self):
return self.preprocess_dataset((self.train_x, self.train_y))
def get_test_dataset(self):
return self.preprocess_dataset((self.test_x, self.test_y))
loader = DataLoader()
train_x, train_y = loader.get_train_dataset()
test_x, test_y = loader.get_test_dataset()
print(train_x.shape)
print(test_x.shape)
print(train_y.shape)
print(test_y.shape)모델 정의
lr = 0.03
opt = tf.keras.optimizers.Adam(lr)
loss = tf.keras.losses.categorical_crossentropy
model.compile(optimizer=opt, loss=loss, metrics=['accuracy'])
hist = model.fit(train_x, train_y, epochs=10, batch_size=128, validation_data=(test_x, test_y))평가
hist.history
#시각화
plt.figure(figsize=(10,5))
plt.subplot(221)
plt.plot(hist.history['loss'])
plt.title('loss')
plt.subplot(222)
plt.plot(hist.history['accuracy'])
plt.title('accuracy')
plt.subplot(223)
plt.plot(hist.history['val_loss'])
plt.title('val_loss')
plt.subplot(224)
plt.plot(hist.history['val_accuracy'])
plt.title('val_accuracy')
plt.tight_layout()
plt.show()5. Model 학습
6. Evaluation
7. Data 다루기
각각 레이어 사진, resnet 사진 추가하기!!
