Boosting
- 여러개의 (약한)분류기가 순차적으로 학습을 하면서 앞에서 학습한 분류기가 예측이 틀린 데이터에 대해 다음 분류기가 가중치를 인가해서 학습을 이어 진행하는 방식
- 예측 성능이 뛰어나서 앙상블 학습을 주도한다
- 그래디언트부스트, XGBoost(eXtra Gradient Boost), LightGBM(Light Gradient Boost) 등
배깅과 부스팅 차이
배깅은 데이터가 동시에 분류기에 들어가고 동시에 학습을 해서 결과를 투표
텍스트부스팅은 데이터를 학습하고, 결과를 보고 가중치가 필요한 것들? 다시 모아서 다시 학습하고 순차적으로 진행되는 과정
Adaboost
순차적으로 가중치를 부여해서 최종 결과를 얻음
DecisionTree 기반의 알고리즘
GBM(Gradient Boosting Machine)
AdaBoost 기법과 비슷하지만 가중치를 업데이트할 때 경사하강법을 사용
XGBoost(eXtra Gradient Boost)
GBM에서 PC의 파워를 효율적으로 사용하기 위한 다양한 기법에 채택되어 빠른 속도와 효율을 가짐
LightGBM
XGBoost보다 빠른 속도를 가짐
Wine 데이터로 실습을 해보자
#standardscaler를 적용
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_sc = sc.fit_transform(X)
#데이터 나누기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_sc, y, test_size=0.2, random_state=13)
모든 컬럼의 히스토그램 조사
import matplotlib.pyplot as plt
wine.hist(bins=10, figsize=(15,10))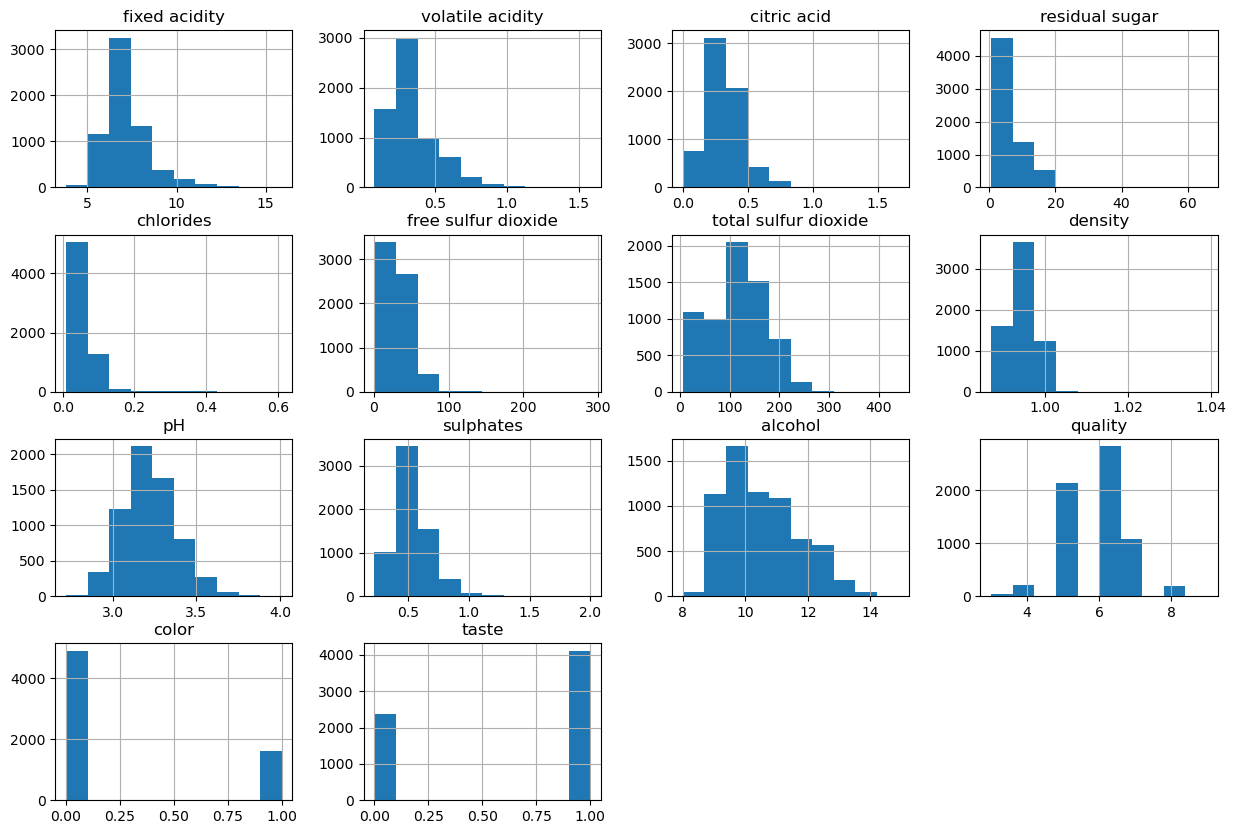 보통 잘 분포되어 있는 컬럼이 좋을 때가 많다.
보통 잘 분포되어 있는 컬럼이 좋을 때가 많다.
quality와 다른 특성이 어떤 관련이 있는지 알아보자
column_names = ['fixed acidity', 'volatile acidity', 'citric acid', 'residual sugar',
'chlorides', 'free sulfur dioxide', 'total sulfur dioxide', 'density',
'pH', 'sulphates', 'alcohol']
df_pivot_table = wine.pivot_table(column_names, ['quality'], aggfunc='median')
print(df_pivot_table)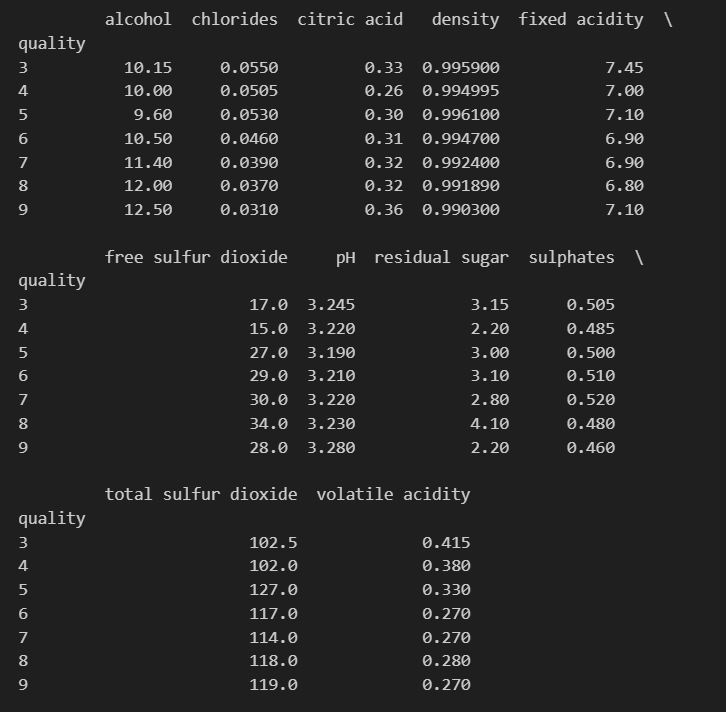
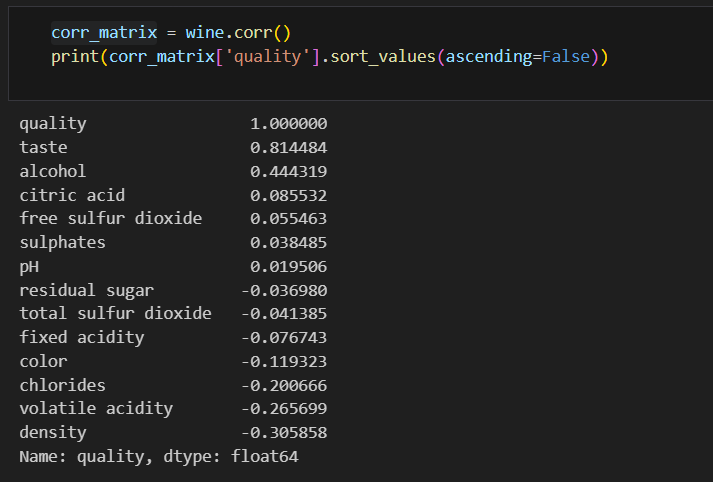
quality에 대한 다른 특성들의 상관관계는? corr로 알아보자(절댓값으로 봐야함)
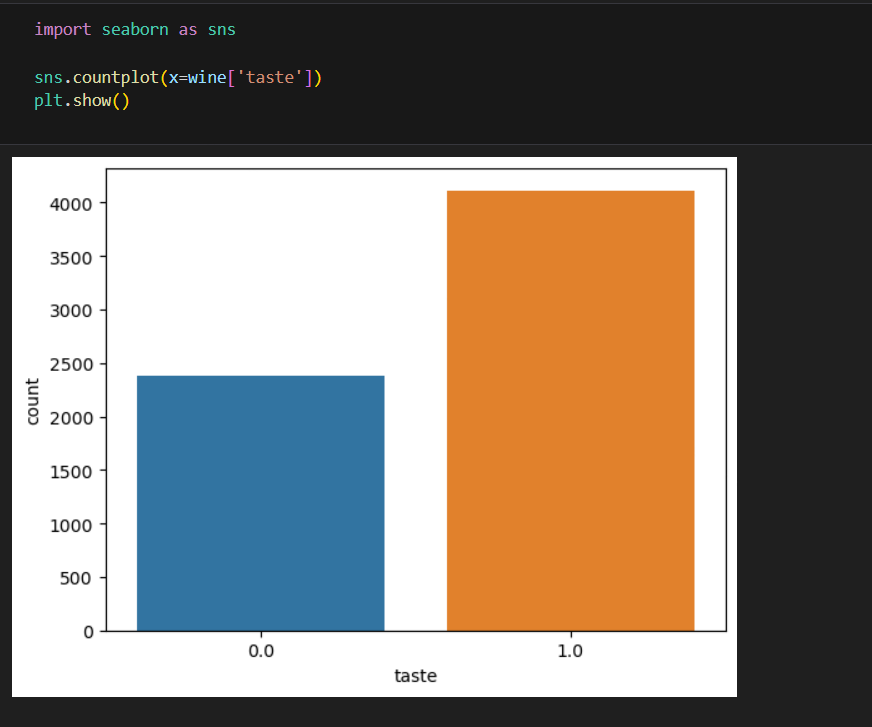
taste 컬럼 분포
다양한 모델을 한번에 테스트해보자
from sklearn.ensemble import AdaBoostClassifier, GradientBoostingClassifier, RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
#함수명, 함수를 tuple 형으로 리스트 안에 넣음
models = []
models.append(('RandomForestClassifier', RandomForestClassifier()))
models.append(('DecisionTreeClassifier', DecisionTreeClassifier()))
models.append(('AdaBoostClassifier', AdaBoostClassifier()))
models.append(('GradientBoostingClassifier',GradientBoostingClassifier()))
models.append(('LogisticRegression',LogisticRegression()))
#결과를 저장하기 위한 작업
from sklearn.model_selection import KFold, cross_val_score
results = []; names = []
for name, model in models:
kfold = KFold(n_splits=5, random_state=13, shuffle=True) #5겹 폴딩, shuffle : 데이터를 나누기 전에 섞는 옵션
cv_results = cross_val_score(model, X_train, y_train, cv=kfold, scoring='accuracy')
results.append(cv_results)
names.append(name)
print(name, cv_results.mean(), cv_results.std())
cross-validation 결과를 확인하기 - boxplot
fig = plt.figure(figsize=(14,8))
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
plt.boxplot(results)
ax.set_xticklabels(names)
plt.show()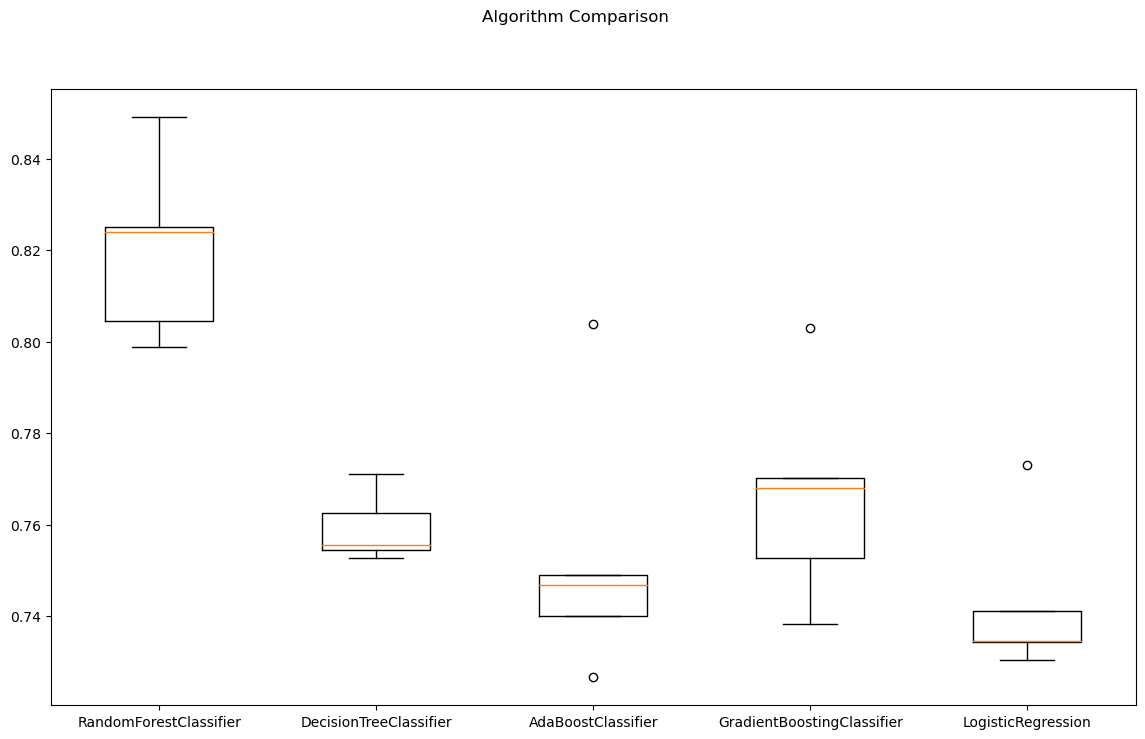 wine 데이터는 랜덤포레스트 성능이 제일 좋다
wine 데이터는 랜덤포레스트 성능이 제일 좋다
데이터마다 어떤 알고리즘의 성능이 좋은 지는 다 다르다.
#테스트 데이터에 대한 평가 결과
from sklearn.metrics import accuracy_score
for name, model in models:
model.fit(X_train, y_train)
pred = model.predict(X_test)
print(name, accuracy_score(y_test, pred))
테스트 데이터도 랜덤포레스트 성능이 제일 좋다
kNN(k Nearest Neighber)
- 새로운 데이터가 있을 때, 기존 데이터의 그룹 중 어떤 그룹에 속하는지를 분류하는 문제
- k는 몇 번째 가까운 데이터까지 볼 것인가를 정하는 수치
- 실시간 예측을 위한 학습이 필요 없어서 속도가 빨라진다.
- 고차원 데이터에는 적합하지 않다.
아이리스 데이터로 실습해보자
from sklearn.datasets import load_iris
iris = load_iris()
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, stratify=iris.target)
#kNN 학습 : 진짜 학습하는게 아니라 그냥 절차상 fit 하는
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)
#accuracy
from sklearn.metrics import accuracy_score
pred = knn.predict(X_test)
print(accuracy_score(y_test, pred))
0.9666666666666667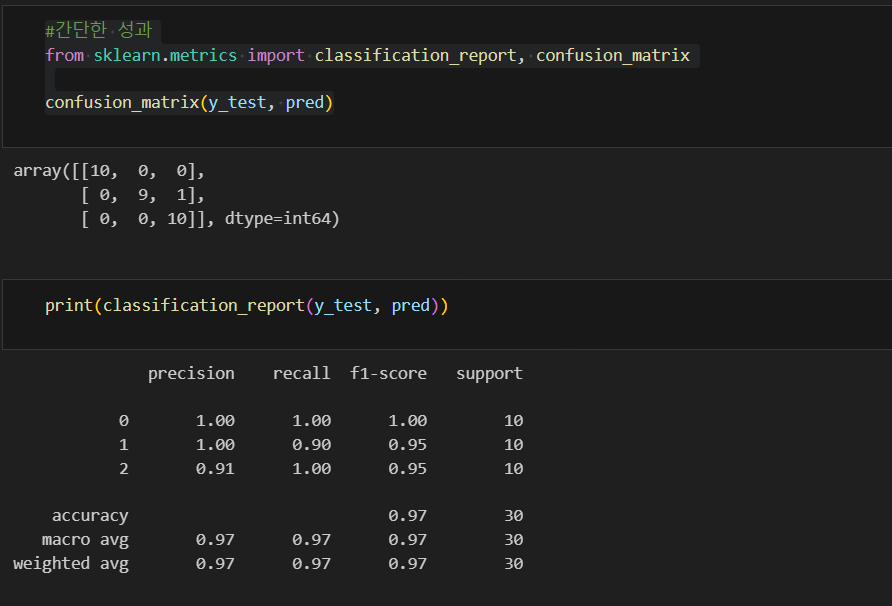
GBM - Gradient Boosting Machine
- 여러 개의 약한 학습기(week learner)를 순차적으로 학습-예측하면서
잘못 예측한 데이터에 가중치를 부여해서 오류를 개선해가는 방식인 부스팅 알고리즘의 방법 중 하나 - GBM은 가중치를 업데이트할 때 경사 하강법(Gradient Descent)을 이용하는 것이 큰 차이
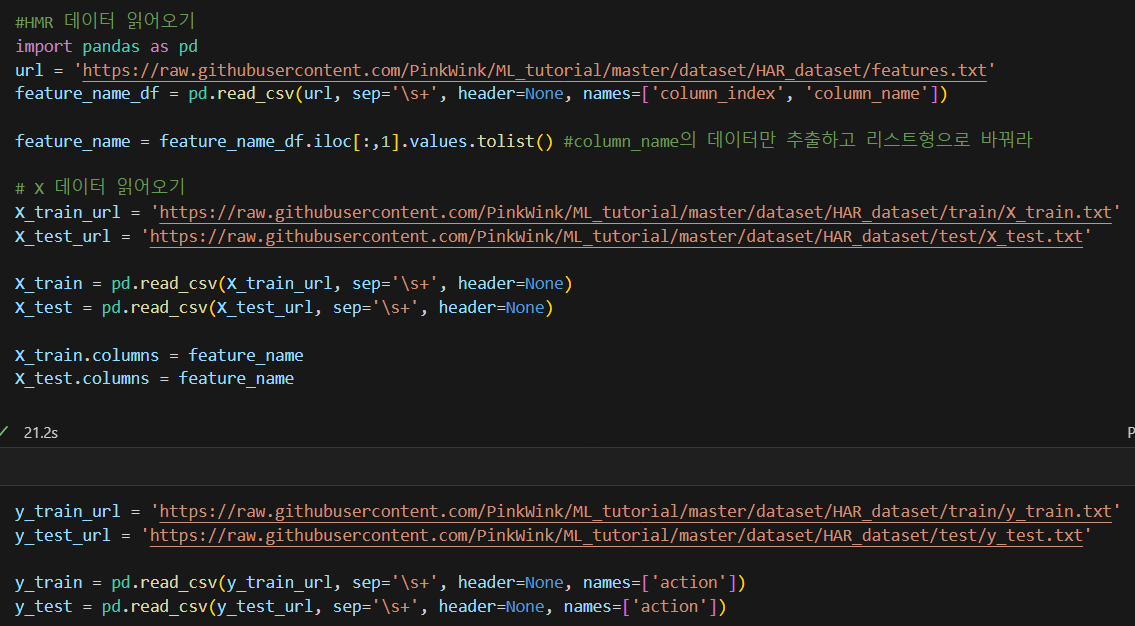
HAR 데이터를 읽어오자
#필요 모듈 import
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import accuracy_score
import time
import warnings
warnings.filterwarnings('ignore')start_time =time.time()
gb_clf = GradientBoostingClassifier(random_state=13)
gb_clf.fit(X_train, y_train)
gb_pred = gb_clf.predict(X_test) #오래걸림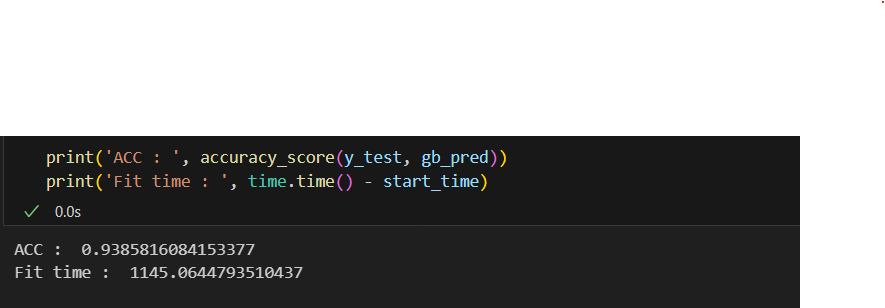 일반적으로 GBM 성능 자체는 랜덤 포레스트보다는 좋다고 알려져있다
일반적으로 GBM 성능 자체는 랜덤 포레스트보다는 좋다고 알려져있다
그러나 속도가 아주 느리다
GridSearch로 조금 더 상세히 찾아보자
from sklearn.model_selection import GridSearchCV
params = {
'n_estimators' : [100, 500],
'learning_rate' : [0.05, 0.1]
}
start_time = time.time()
grid = GridSearchCV(gb_clf, param_grid=params, cv=2, verbose=1, n_jobs=-1)
grid.fit(X_train, y_train)
print('Fit time : ', time.time()-start_time)test 데이터에서의 성능은
accuracy_score(y_test, grid.best_estimator_.predict(X_test))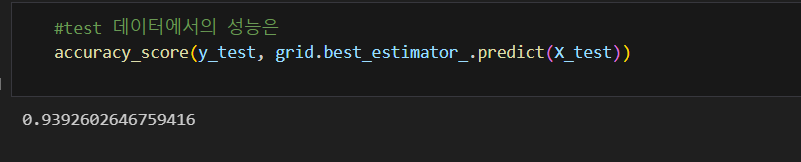
XGBoost
- XGBoost는 트리 기반의 앙상블 학습에서 가장 각광받는 알고리즘 중 하나
- GBM 기반의 알고리즘인데, GBM의 느린 속도를 다양한 규제를 통해 해결
- GBM의 경우 n_estimators에 지정된 횟수만큼 다 학습을 해야하는데, XGBoost는 지정한 부스팅 반복횟수에 도달하지 않더라도 예측 오류가 더 이상 개서노디지 않으면 반복을 끝까지 하지 않고 중지할 수 있음(조기 중단 기능)'
- 교차검증을 통해 최적화되면 반복을 중단하는 조기 중단 기능을 가지고 있음
- 특히 병렬 학습이 가능하도록 설계됨
- XGBoost는 반복 수행 시마다 내부적으로 학습데이터와 검증데이터를 교차검증을 수행
설치
conda install xgboost
!pip install xgboost
주요 파라미터
• nthread : CPU의 실행 스레드 개수를 조정. 디폴트는 CPU의 전체 스레드를 사용하는 것
• eta : GBM 학습률
• n_estimators
• max_depth
조기종료 파라미터
- early_stopping_rounds : 조기 중단할 수 있는 최소 반복 횟수
- eval_set :성능 평가용 데이터 세트
- eval_metric : 평가 세트에 적용할 함수를 정의, 디폴트는 회귀(rmse), 분류(error)이며 검증에 사용되는 함수에는 rmse,mae,logloss,error,merror,mlogloss,auc 등이 있다
XGBoost에서 에러가 발생할 때,
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y_train = le.fit_transform(y_train)
y_test = le.fit_transform(y_test)이 코드를 실행시키고 진행하면 됨
그리고 fit 시킬때, X_train이 아닌 X_train.values를 넣어줘야 함
from xgboost import XGBClassifier
start_time = time.time()
xgb = XGBClassifier(n_estimators=400, learning_rate=0.1, max_depth=3)
xgb.fit(X_train.values, y_train)
print('Fit time : ', time.time() - start_time)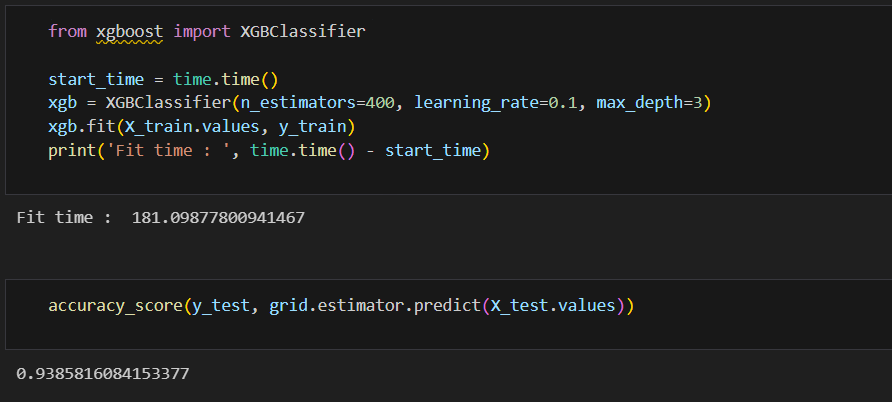 확실히 GBM에 비해 빠르다
확실히 GBM에 비해 빠르다
조기 종료 조건을 넣어보자
evals = [(X_test.values, y_test)]
xgb = XGBClassifier(n_estimators = 400, learning_rate = 0.1, max_depth=3)
xgb.fit(X_train.values, y_train, early_stopping_rounds=10, eval_set=evals)

LightGBM
- LightGBM은 XGBoost와 함께 부스팅 계열에서 가장 각광받는 알고리즘
- LGBM의 큰 장점은 속도
- 적은 수의 데이터에는 어울리지 않음 (일반적으로 10000건 이상의 데이터가 필요)
- GPU 버전도 존재
설치
conda install lightgbm
!pip install lightgbm
from lightgbm import LGBMClassifier
start_time = time.time()
lgbm = LGBMClassifier(n_estimators=400)
lgbm.fit(X_train.values, y_train, early_stopping_rounds=100, eval_set=evals)
print('Fit time : ', time.time() - start_time)
속도가 아주 빠르다
