데이터 개요
- 신용카드 사기 검출 분류 실습용 데이터
- class 컬럼 : 사기 유무 (0, 1)
- Amount : 거래금액
- class 컬럼의 불균형이 심해서 전체 데이터의 약 0.172%가 1(사기)을 가짐
- 금융 데이터이므로 기업 보안상 대다수의 특성 이름은 삭제
데이터를 읽어보자
import pandas as pd
raw_data = pd.read_csv('./creditcard.csv')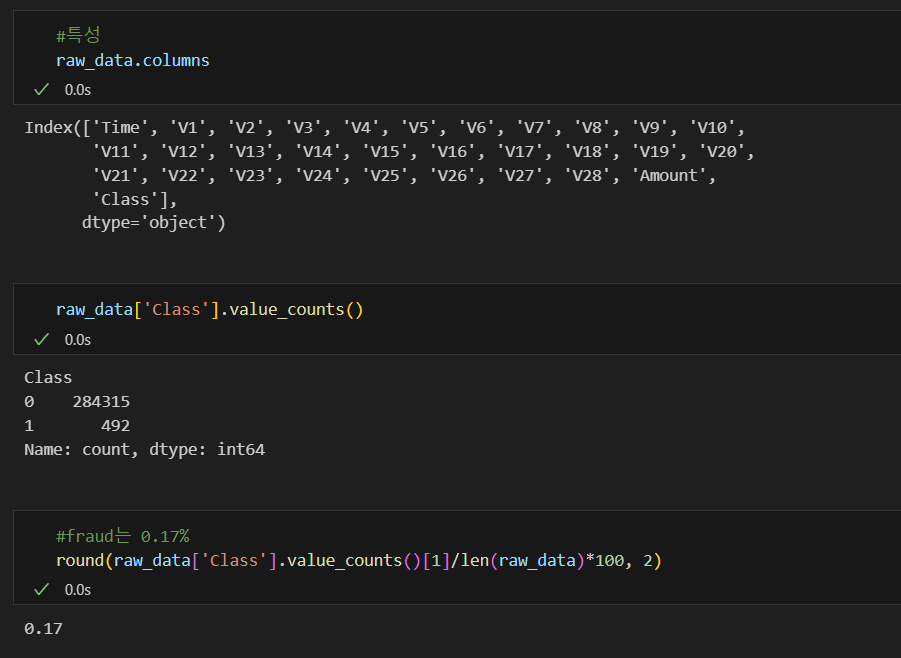
class 컬럼을 그래프로 그려보면
import seaborn as sns
import matplotlib.pyplot as plt
sns.countplot(x='Class', data=raw_data)
plt.title('Class Distrbutions \n (0: No Fraud || 1: Fraud)', fontsize=14)
plt.show()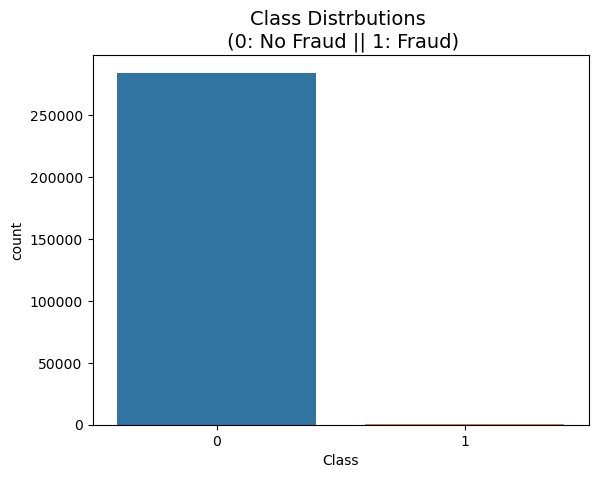
일단 X,y 데이터를 선정하여 데이터를 나누어서 불균형 정도를 보면,
#X, y 선정
X = raw_data.iloc[:, 1:-1] #첫번째 time 컬럼은 안써서 제외시키고 마지막 컬럼인 class는 라벨로 쓰니까 제외
y = raw_data.iloc[:,-1]
#데이터 나누기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=13, stratify=y) #불균형성이 너무 심해서 stratify 꼭 넣기
#나눈 데이터의 불균형 정도가 어떤지 알아보자
import numpy as np
np.unique(y_train, return_counts=True)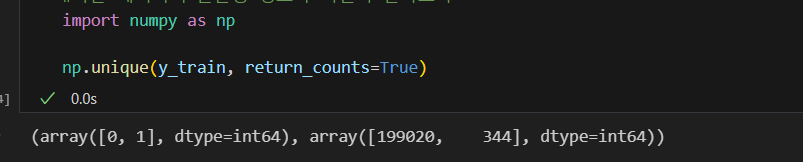

첫번째 시도
일단 무작정 돌려보자
#분류기 성능을 return하는 함수
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score
def get_clf_eval(y_test, pred):
acc = accuracy_score(y_test, pred)
pre = precision_score(y_test, pred)
re = recall_score(y_test, pred)
f1 = f1_score(y_test, pred)
roc = roc_auc_score(y_test, pred)
return acc, pre, re, f1, roc#성능 출력 함수
from sklearn.metrics import confusion_matrix
def print_clf_eval(y_test, pred):
confusion = confusion_matrix(y_test, pred)
acc, pre, re, f1, auc = get_clf_eval(y_test, pred)
print('=> confusion matrix')
print(confusion)
print('===========')
print('Accuracy: {0:.4f}, Precision: {1:.4f}'.format(acc, pre))
print('Recall: {0:.4f}, F1: {1:.4f}, AUC:{2:.4f}'.format(re, f1, auc))#logistic regression
#148개 praud 데이터 중에서 88개 맞춤
#acc가 높아도 recall이 낮음
from sklearn.linear_model import LogisticRegression
lr_clf = LogisticRegression(random_state=13, solver='liblinear')
lr_clf.fit(X_train, y_train)
lr_pred = lr_clf.predict(X_test)
print_clf_eval(y_test, lr_pred)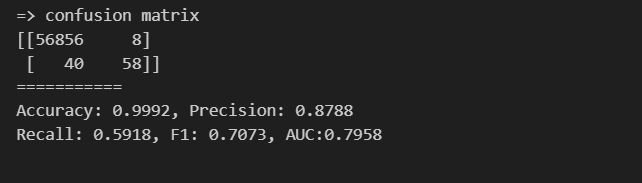
#decision tree
from sklearn.tree import DecisionTreeClassifier
dt_clf = DecisionTreeClassifier(random_state=13, max_depth=4)
dt_clf.fit(X_train, y_train)
dt_pred = dt_clf.predict(X_test)
print_clf_eval(y_test, dt_pred)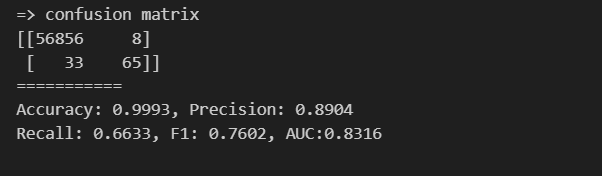
#randomforest
from sklearn.ensemble import RandomForestClassifier
rf_clf = RandomForestClassifier(random_state=13, n_jobs=-1, n_estimators=100)
rf_clf.fit(X_train, y_train)
rf_pred = rf_clf.predict(X_test)
print_clf_eval(y_test, rf_pred)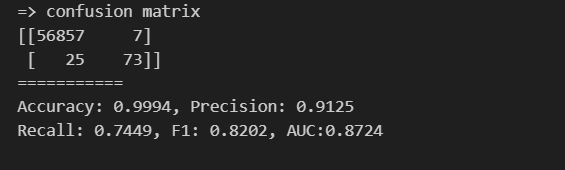
from lightgbm import LGBMClassifier
lgbm_clf = LGBMClassifier(random_state=13, n_jobs=-1, n_estimators=1000, num_leaves=64, boost_from_average=False)
lgbm_clf.fit(X_train, y_train)
lgbm_pred = lgbm_clf.predict(X_test)
print_clf_eval(y_test, lgbm_pred)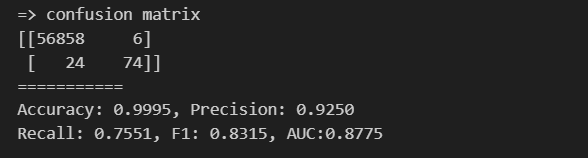
#모델과 데이터를 주면 성능을 출력하는 함수
def get_result(model, X_train, y_tain, X_test, y_test):
model.fit(X_train, y_train)
pred = model.predict(X_test)
return get_clf_eval(y_test, pred)#다수의 모델 성능을 정리해서 DataFrame으로 반환하는 함수
def get_result_pd(models, model_names, X_train, y_train, X_test, y_test):
col_names = ['accuracy', 'precision', 'recall', 'f1', 'roc_auc']
tmp = []
for model in models:
tmp.append(get_result(model, X_train, y_train, X_test, y_test))
return pd.DataFrame(tmp, columns=col_names, index=model_names)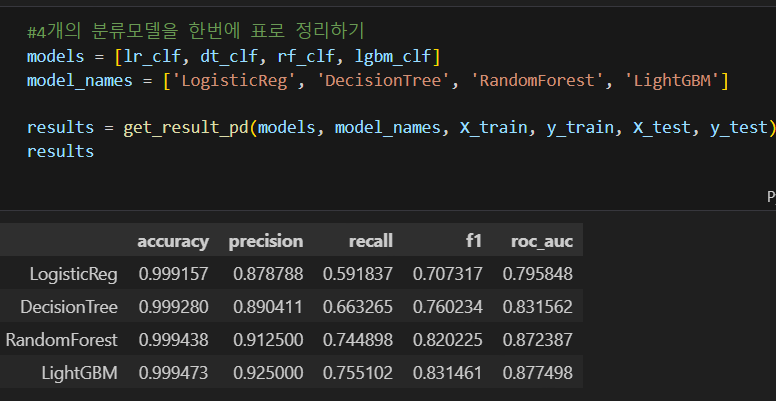
accuracy는 모두 높지만, 앙상블 계열의 성능이 가장 우수하다
두 번째 시도
데이터를 정리해서 다시 도전
#raw_data의 amount 컬럼 확인
plt.figure(figsize=(10,5))
sns.distplot(raw_data['Amount'], color='r')
plt.show()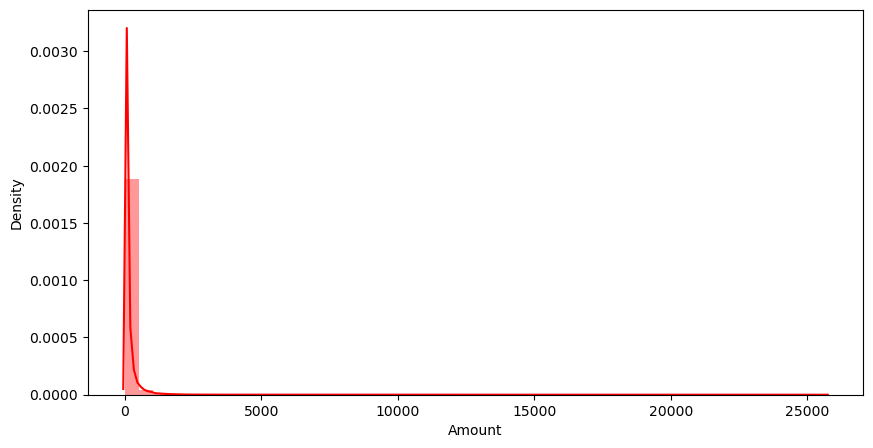
컬럼의 분포가 특정 대역이 아주 많다.
특정 대역에 몰려있는 것은 좀 문제가 있다.
#amount 컬럼에 standardscaler 적용
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
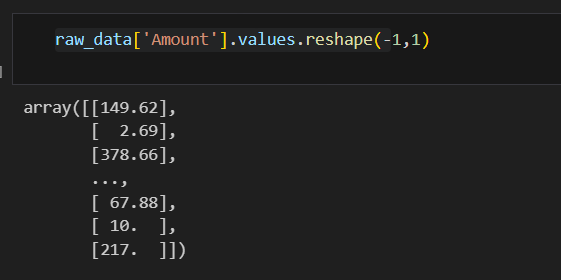
amount_n = scaler.fit_transform(raw_data['Amount'].values.reshape(-1,1))
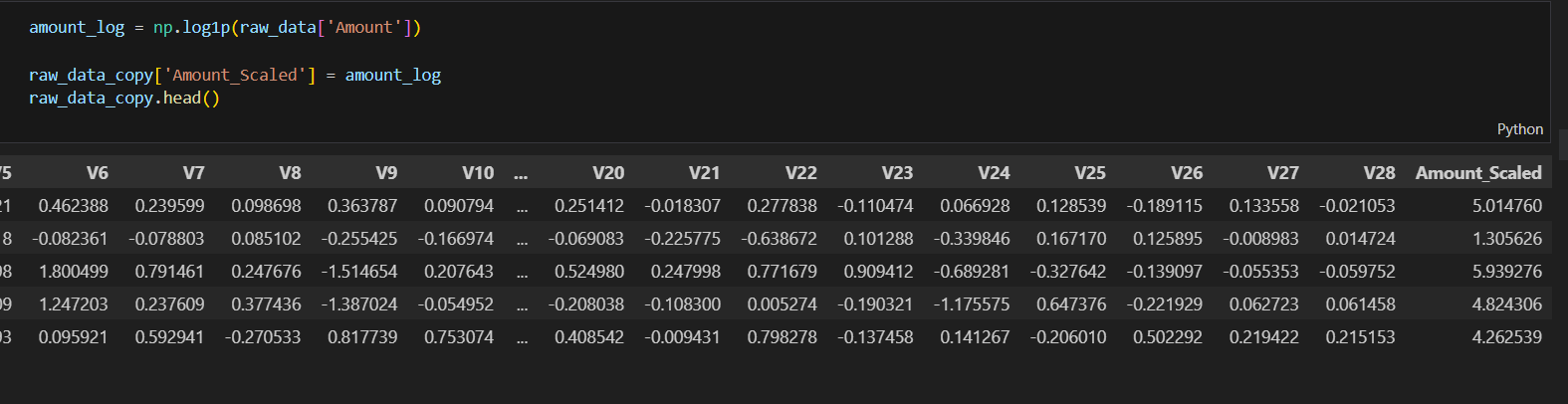
raw_data_copy = raw_data.iloc[:, 1:-2]
raw_data_copy['Amount_Scaled'] = amount_n
raw_data_copy.head()
#다시 데이터를 나누고
X_train, X_test, y_train, y_test = train_test_split(raw_data_copy, y, test_size=0.2, random_state=13, stratify=y)
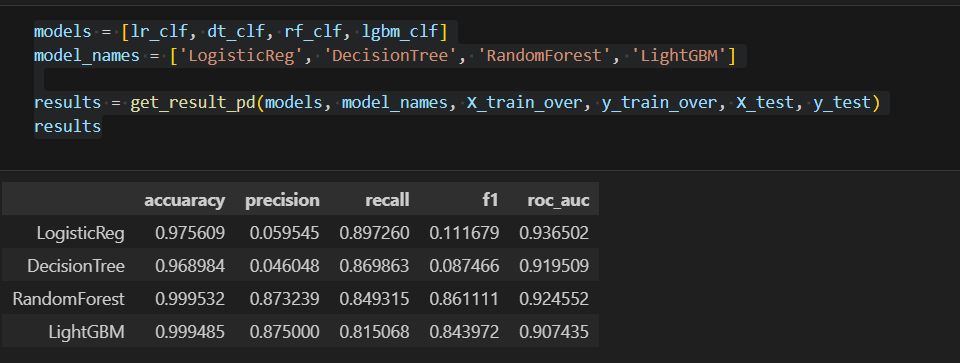
models = [lr_clf, dt_clf, rf_clf, lgbm_clf]
model_names = ['LogisticReg', 'DecisionTree', 'RandomForest', 'LightGBM']
results = get_result_pd(models, model_names, X_train, y_train, X_test, y_test)
results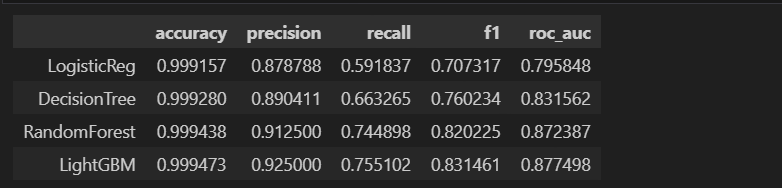
별 차이가 없다
#모델별 ROC 커브
from sklearn.metrics import roc_curve
def draw_roc_curve(models, model_name, X_test, y_test):
plt.figure(figsize=(10,10))
for model in range(len(models)):
pred = models[model].predict_proba(X_test)[:, 1]
fpr, tpr, thresholds = roc_curve(y_test, pred)
plt.plot(fpr, tpr, label=model_names[model])
plt.plot([0,1], [0,1], 'k--', label='random quess')
plt.title('ROC')
plt.legend()
plt.grid()
plt.show()
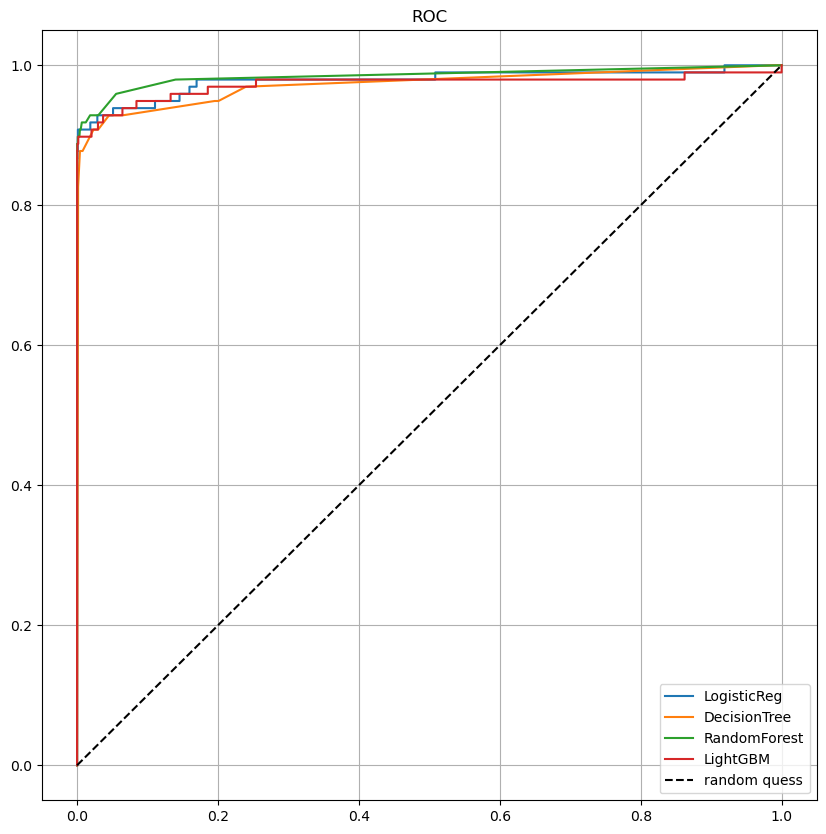
draw_roc_curve(models, model_names, X_test, y_test)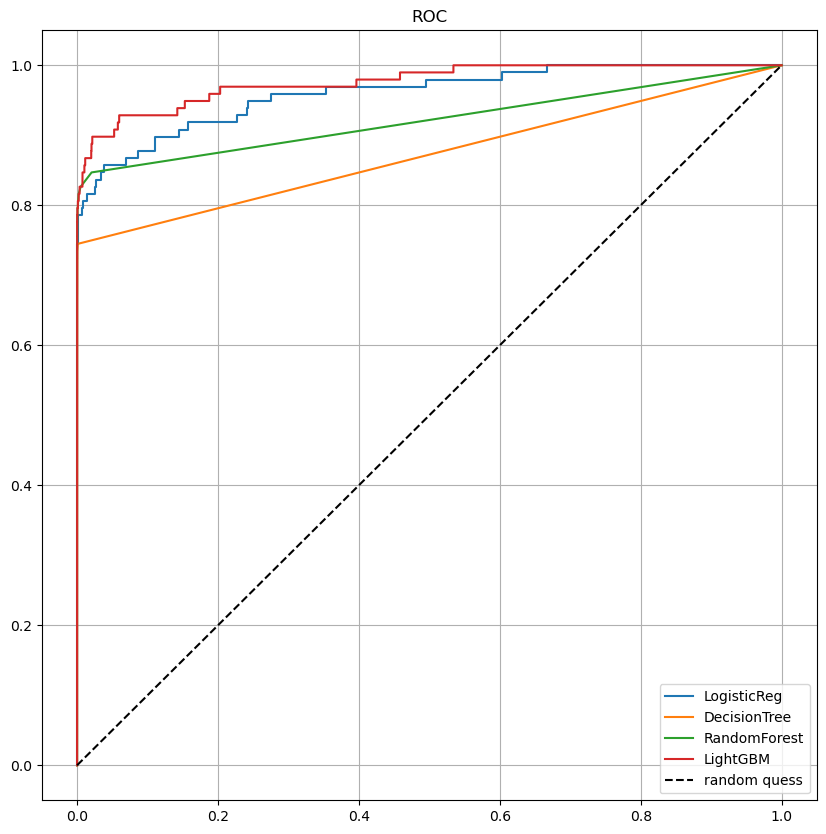
함수를 통해 살펴본 roc 커브도 같이 보았는데 큰 성능 향상은 없어보인다.
또 다른 시도 log scale
plt.figure(figsize=(10,5))
sns.distplot(raw_data_copy['Amount_Scaled'], color='r')
plt.show()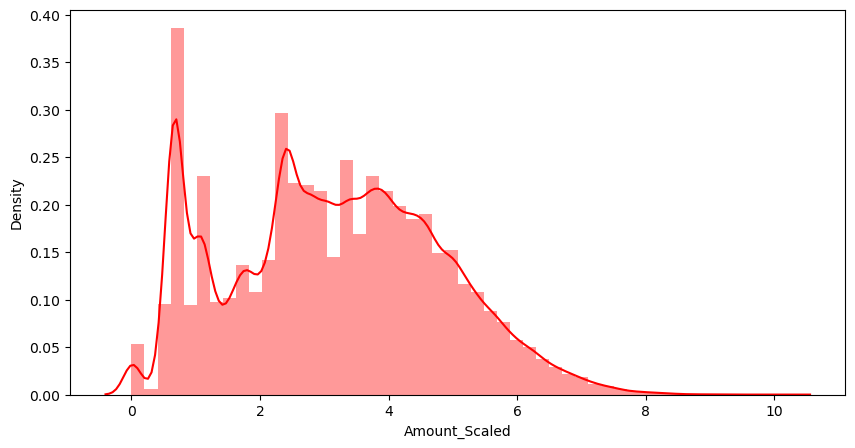
X_train, X_test, y_train, y_test = train_test_split(raw_data_copy, y, test_size=0.3, random_state=13, stratify=y)
models = [lr_clf, dt_clf, rf_clf, lgbm_clf]
model_names = ['LogisticReg', 'DecisionTree', 'RandomForest', 'LightGBM']
results = get_result_pd(models, model_names, X_train, y_train, X_test, y_test)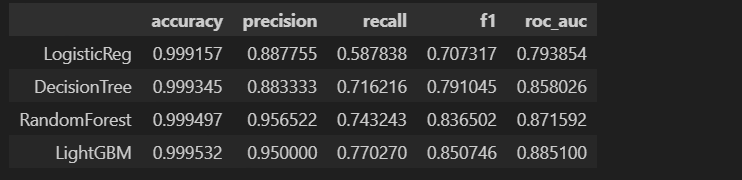
미세한 변화가 보이지만 확실한 변화는 관찰되지 않는다
from sklearn.metrics import roc_curve
def draw_roc_curve(models, model_name, X_test, y_test):
plt.figure(figsize=(10,10))
for model in range(len(models)):
pred = models[model].predict_proba(X_test)[:, 1]
fpr, tpr, thresholds = roc_curve(y_test, pred)
plt.plot(fpr, tpr, label=model_names[model])
plt.plot([0,1], [0,1], 'k--', label='random quess')
plt.title('ROC')
plt.legend()
plt.grid()
plt.show()
draw_roc_curve(models, model_names, X_test, y_test)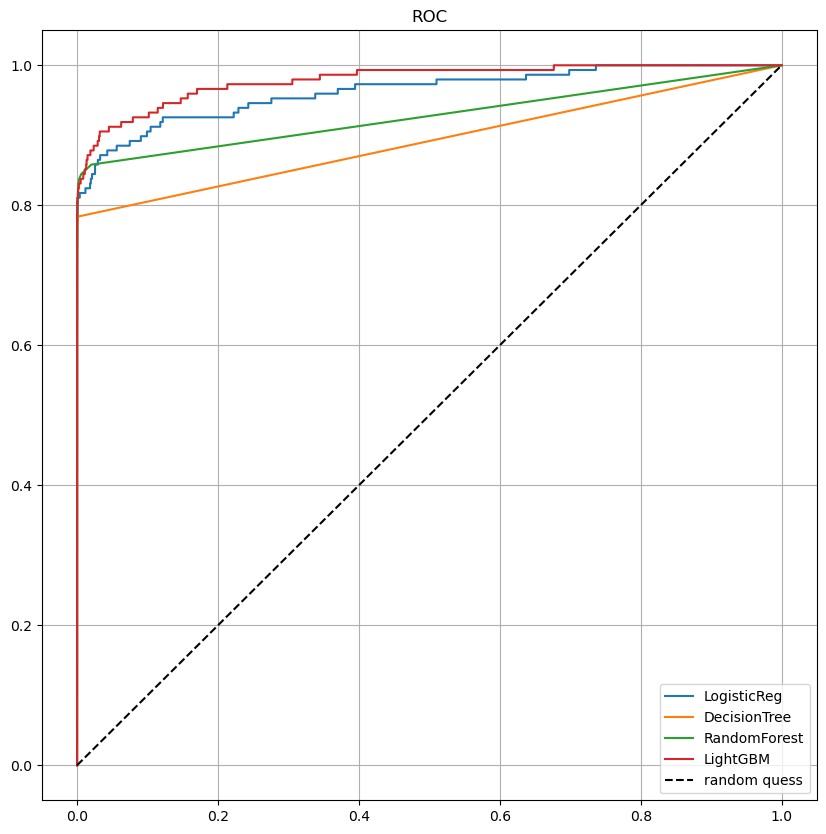
세번째 시도
#특이 데이터 관찰
import seaborn as sns
plt.figure(figsize=(10,7))
sns.boxplot(data=raw_data[['V13', 'V14', 'V15']])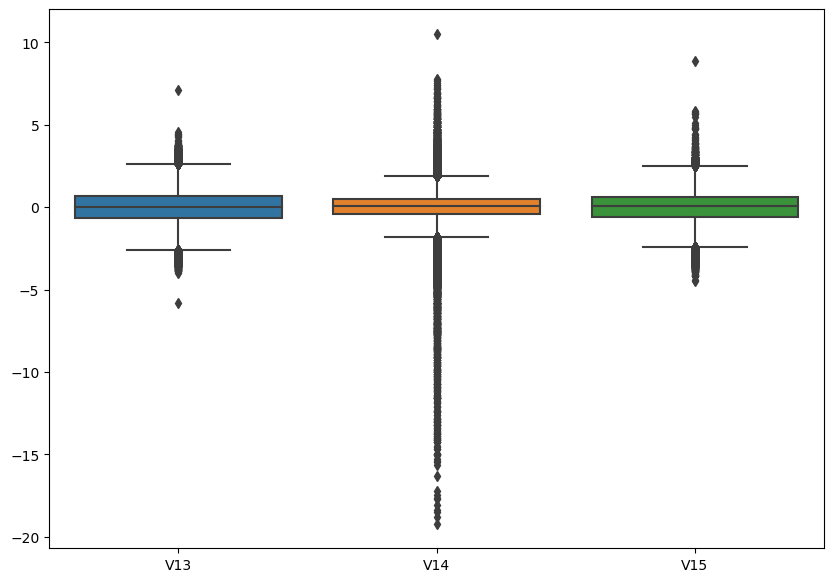
#outlier를 정리하기 위해 outlier의 인덱스를 파악하는 코드
def get_outlier(df=None, column=None, weight=1.5):
fraud = df[df['Class']==1][column]
quantile_25 = np.percentile(fraud.values, 25)
quantile_75 = np.percentile(fraud.values, 75)
iqr = quantile_75 - quantile_25
iqr_weight = iqr * weight
lowest_val = quantile_25 - iqr_weight
highest_val = quantile_75 + iqr_weight
outlier_index = fraud[(fraud < lowest_val) | (fraud > highest_val)].index
return outlier_index#outlier 찾기
get_outlier(df=raw_data, column='V14', weight = 1.5)
#outlier 제거
raw_data_copy.shape
outlier_index = get_outlier(df=raw_data, column='V14', weight=1.5)
raw_data_copy.drop(outlier_index, axis=0, inplace=True)
raw_data_copy.shape
#outlier 제거 후, 데이터 나누기
X = raw_data_copy
raw_data.drop(outlier_index, axis=0, inplace=True)
y = raw_data.iloc[:, -1]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=13, stratify=y)
models = [lr_clf, dt_clf, rf_clf, lgbm_clf]
model_names = ['LogisticReg', 'DecisionTree', 'RandomForest', 'LightGBM']
results = get_result_pd(models, model_names, X_train, y_train, X_test, y_test)
results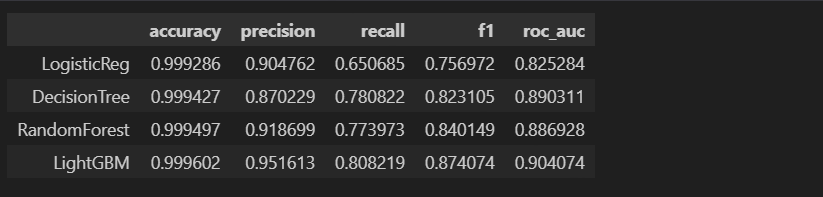
from sklearn.metrics import roc_curve
def draw_roc_curve(models, model_name, X_test, y_test):
plt.figure(figsize=(10,10))
for model in range(len(models)):
pred = models[model].predict_proba(X_test)[:, 1]
fpr, tpr, thresholds = roc_curve(y_test, pred)
plt.plot(fpr, tpr, label=model_names[model])
plt.plot([0,1], [0,1], 'k--', label='random quess')
plt.title('ROC')
plt.legend()
plt.grid()
plt.show()
draw_roc_curve(models, model_names, X_test, y_test)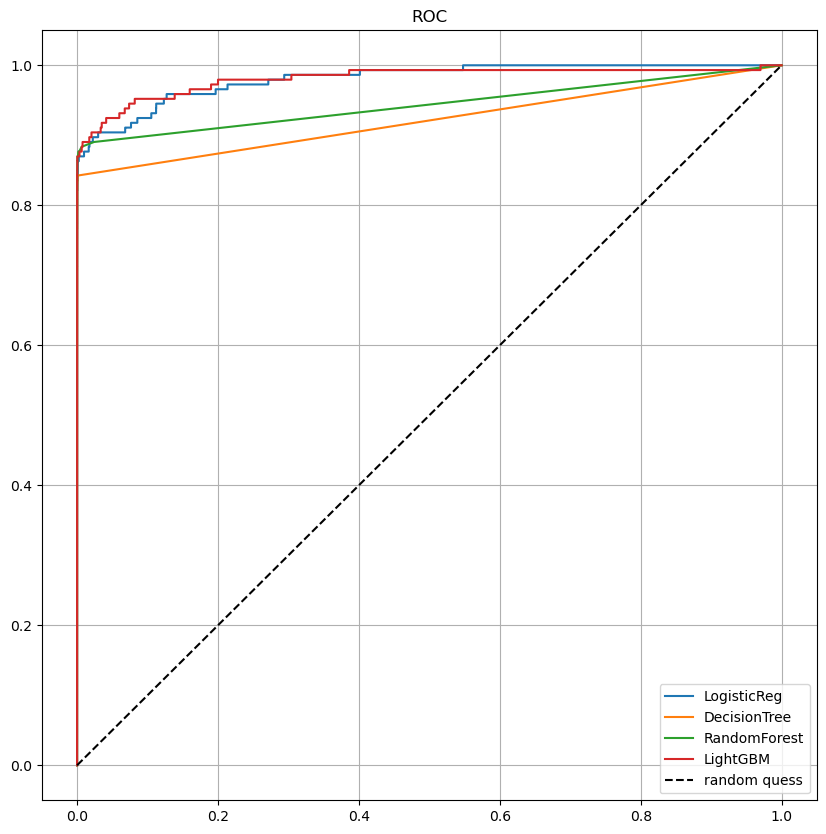
확실히 좋아진 것 같다!
네번째 시도 - oversampling
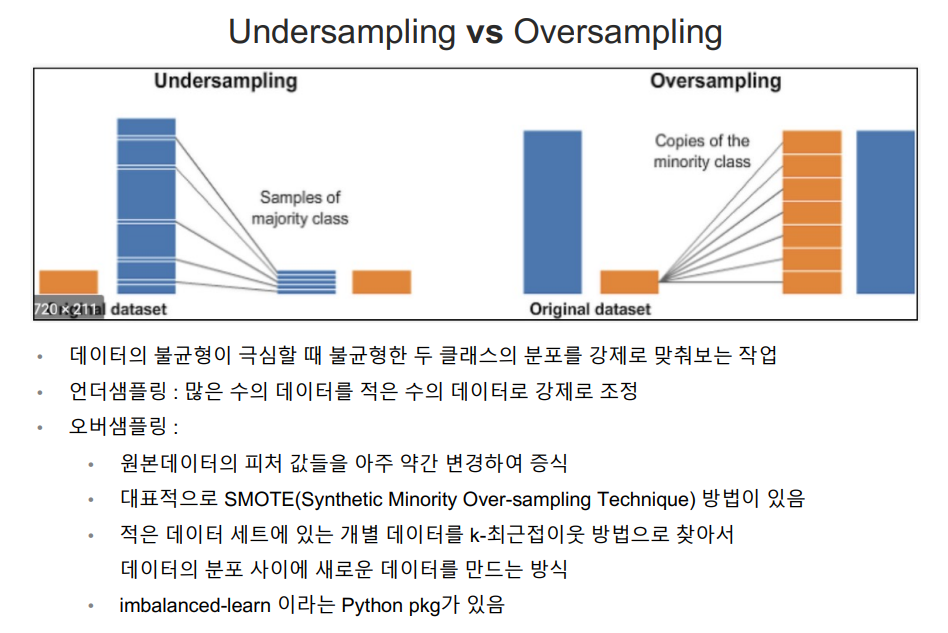
설치 !pip install imbalanced-learn
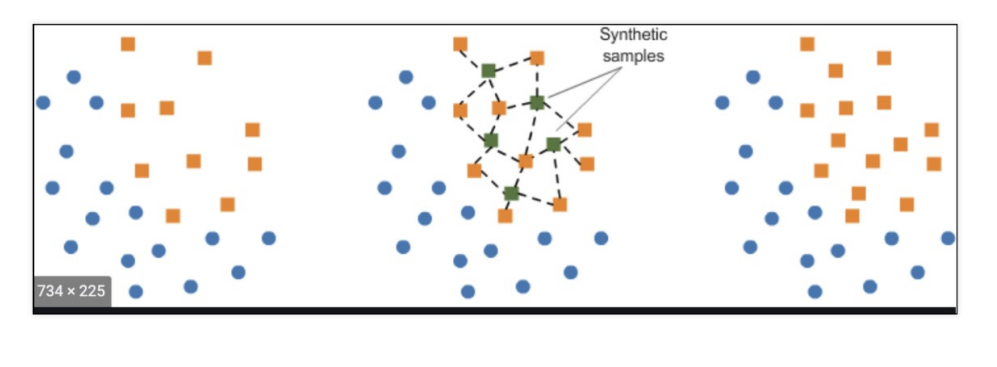
#smote 적용
from imblearn.over_sampling import SMOTE
smote = SMOTE(random_state=13)
X_train_over, y_train_over = smote.fit_resample(X_train, y_train)
#train 데이터에 대해서만 불려야함, test 데이터도 같이하면 오염됨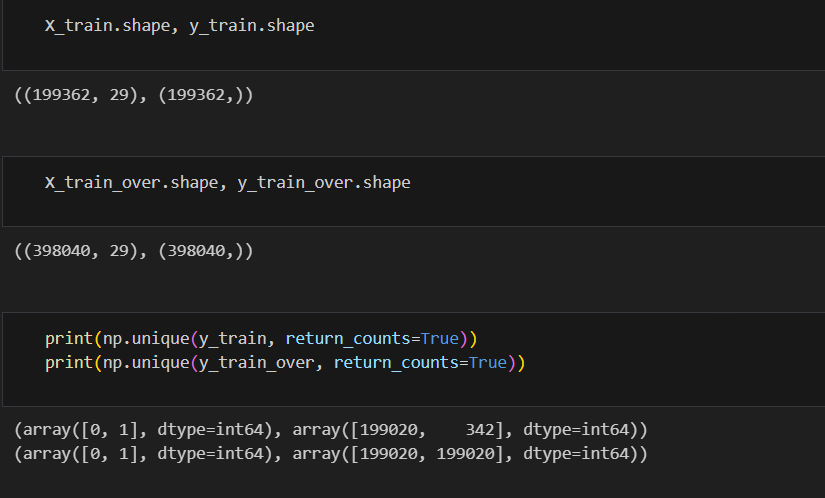
draw_roc_curve(models, model_names, X_test, y_test)