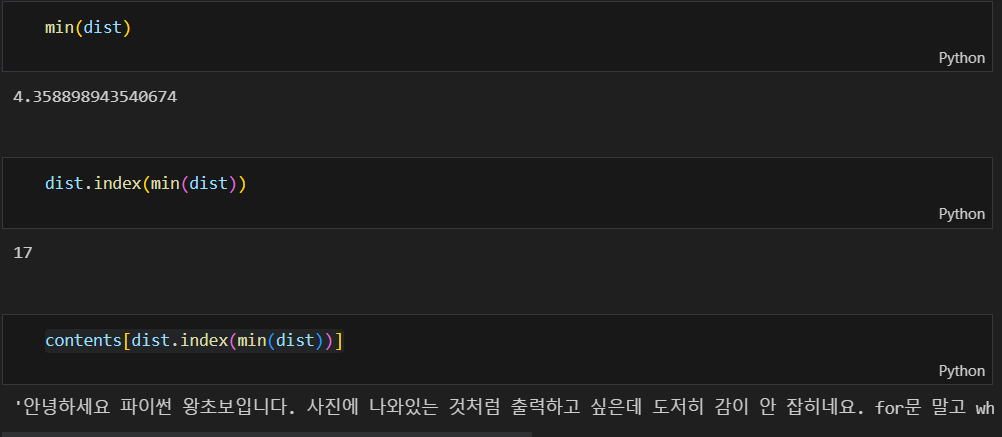
한글은 형태소 분석이 필요하다
from konlpy.tag import Kkma
kkma = Kkma()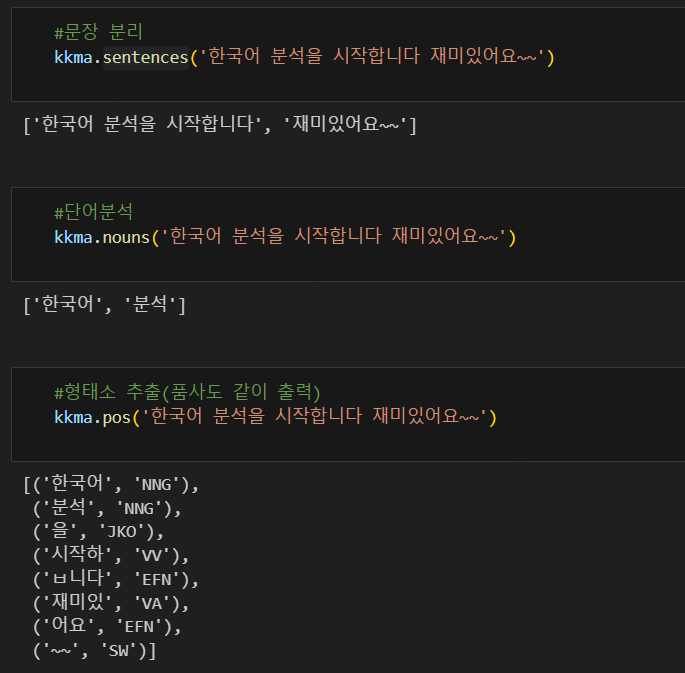
from konlpy.tag import Hannanum
hannanum = Hannanum()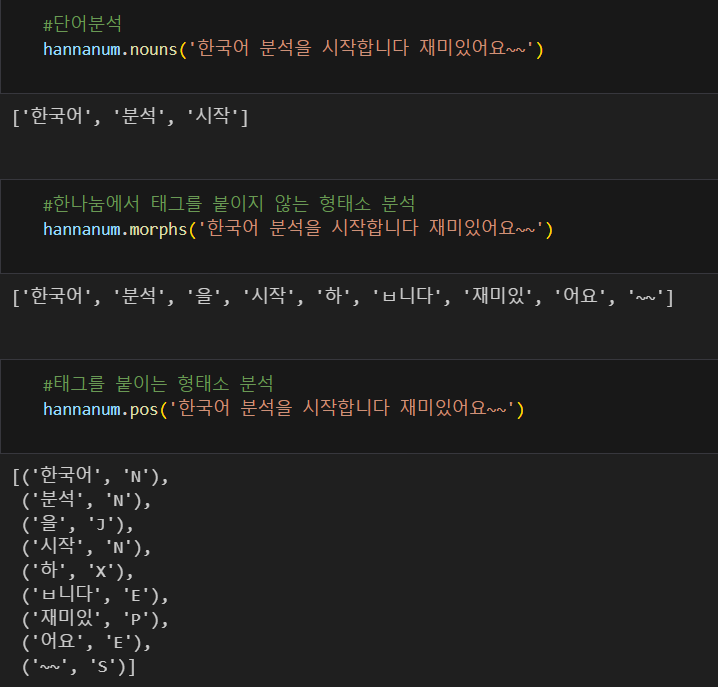
#트위터 엔진
from konlpy.tag import Okt
t = Okt()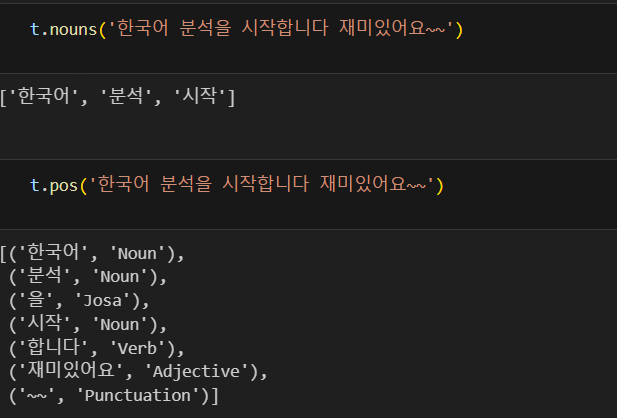
엘리스 데이터로 실습
#워드클라우드
from wordcloud import WordCloud, STOPWORDS
import numpy as np
from PIL import Image
text = open('./06_alice.txt').read()
alice_mask = np.array(Image.open('./06_alice_mask.png'))
stopwords = set(STOPWORDS)
stopwords.add("said")
#한글대응
import matplotlib.pyplot as plt
from matplotlib import rc
rc('font', family='Malgun Gothic')
plt.figure(figsize=(8,8))
plt.imshow(alice_mask, cmap=plt.cm.gray) #imshow : 이미지 파일
wc = WordCloud(
background_color = 'white', max_words = 2000, mask = alice_mask, stopwords = stopwords
)
wc = wc.generate(text)
#발생빈도
wc.words_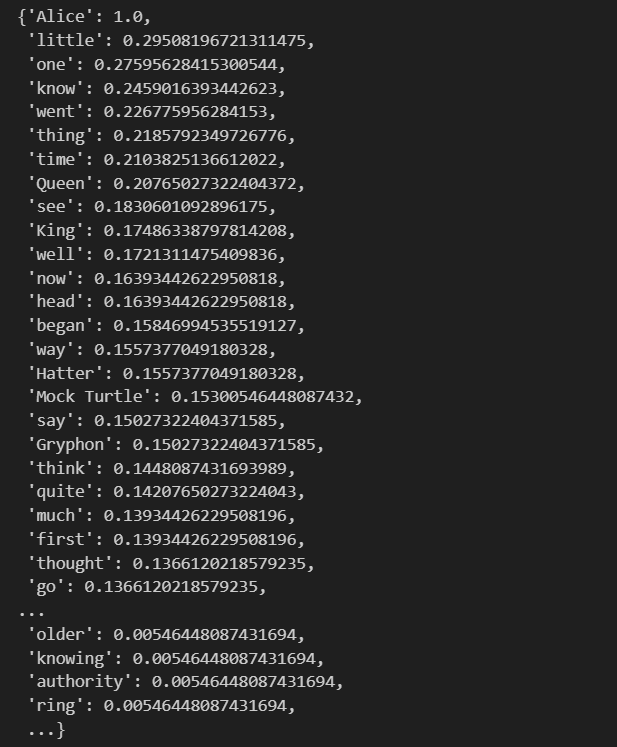
plt.figure(figsize=(12,12))
plt.imshow(wc, interpolation='bilinear')
plt.axis('off')
plt.show()
Star Wars 데이터
text = open('./06_a_new_hope.txt').read()
text = text.replace('HAN', 'Han')
text = text.replace("LUKE'S", "Luke")
mask = np.array(Image.open('./06_stormtrooper_mask.png'))
stopwords.add('int')
stopwords.add('ext')
#WordCloud 지정
wc = WordCloud(
max_words=1000, mask=mask, stopwords=stopwords, margin=10
).generate(text)
default_colors = wc.to_array()
#그레이톤으로 그리기 위한 색상함수 지정
import random
def grey_color_func(word, font_size, position, orientation, random_state=None, **kwargs):
return 'hsl(0, 0%%, %d%%)' % random.randint(60, 100)
#그리기
plt.figure(figsize=(12,12))
plt.imshow(wc.recolor(color_func=grey_color_func, random_state=3), interpolation="bilinear")
plt.axis("off")
plt.show()
실제 문서(육아휴직관련 법안 대한민국 국회 제 1809890호 의안)로 실습
import nltk
#KoNLPy는 대한민국법령을 갖고 있다
from konlpy.corpus import kobill
files_ko = kobill.fileids()
doc_ko = kobill.open("1809890.txt").read()
#Okt 엔진(구 twitter엔진)으로 명사분석
from konlpy.tag import Okt
t = Okt()
tokens_ko = t.nouns(doc_ko)
#nltk를 사용해서 토큰(빈도수 포함) 분석
#단어들의 집합을 text처리하면 유용한 기능들 사용가능
ko = nltk.Text(tokens_ko, name="육아휴직법")
len(ko.tokens) #tokens_ko의 길이
len(set(ko.tokens)) #중복을 제외한 단어로 구성된 tokens_ko의 길이
ko.vocab() #단어 반복 횟수
#그래프 그려보기
plt.figure(figsize=(16,6))
ko.plot(50) #자주 나오는 50개 단어만 그려라
plt.show()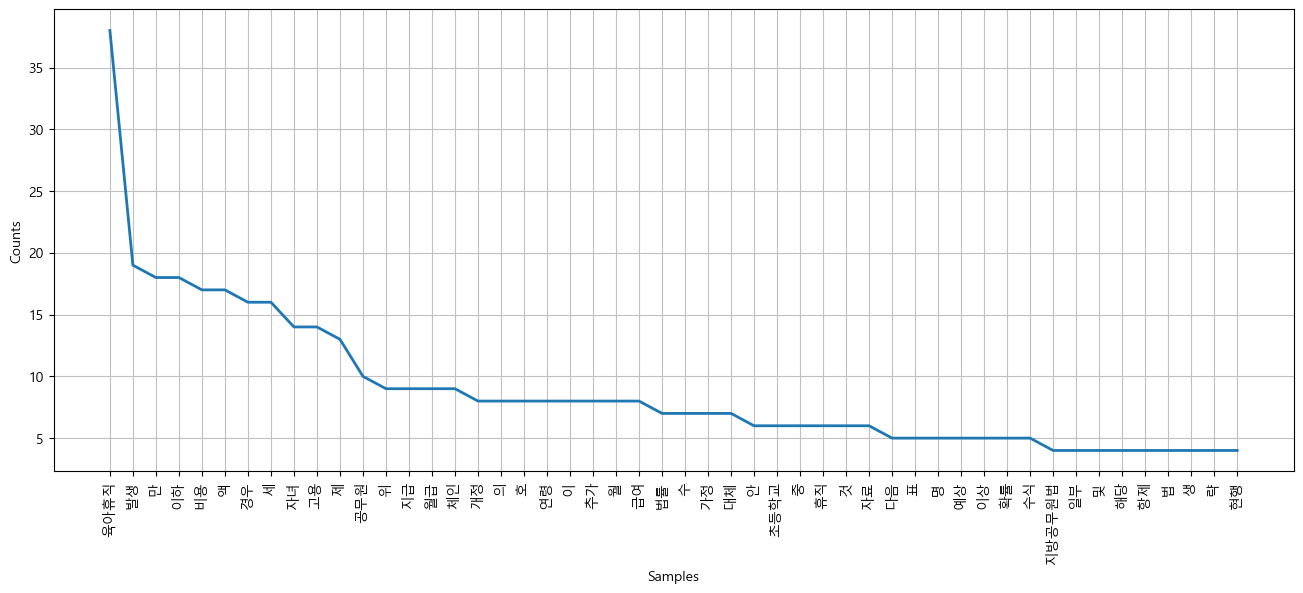
#의, 호,이,수 등등 의미없는 단어를 제거하기 위해 stop_words 만들기
#한글 stopword는 복잡해서 일일이 잡는다.
stop_words = [
".",
"(",
")",
",",
"%",
"-",
"X",
"x",
"의",
"자",
"에",
"안",
"번",
"호",
"을",
"이",
"다",
"만",
"로",
"가",
"를"
]
ko = [each_word for each_word in ko if each_word not in stop_words]
#불용어 제외한 것들로만 그려보기
ko = nltk.Text(ko, name="육아휴직법")
plt.figure(figsize=(16,6))
ko.plot(50)
plt.show()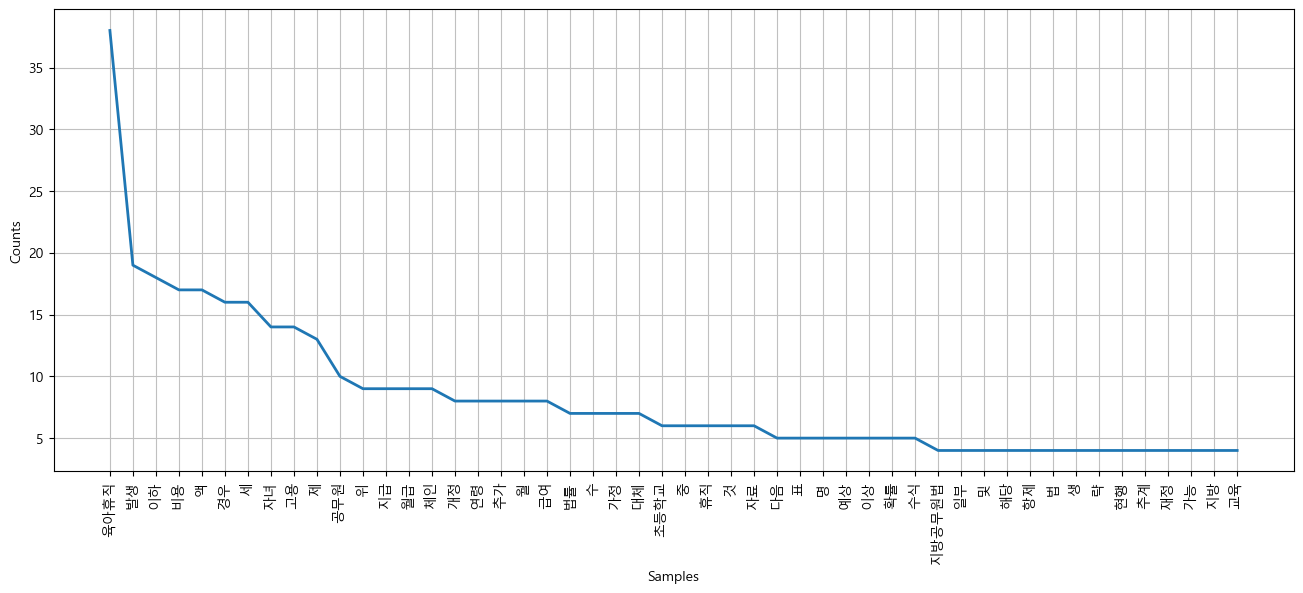
ko.count("초등학교") #특정 단어 반복횟수
plt.figure(figsize=(18,6))
ko.dispersion_plot(['육아휴직', '초등학교', '공무원']) #전체 길이에서 특정 단어의 위치를 보여줌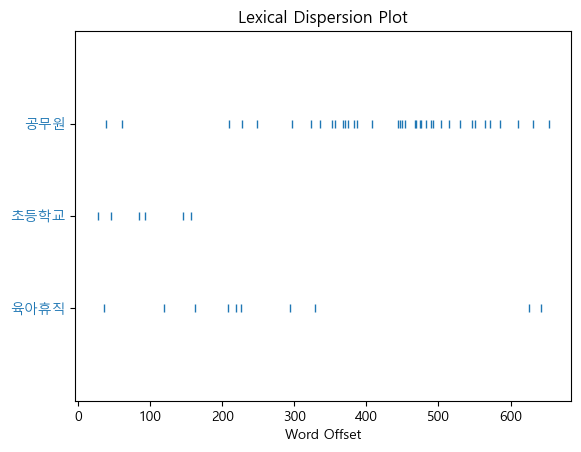


#워드클라우드
data = ko.vocab().most_common(150)
wordcloud = WordCloud(
font_path='C:/Windows/Fonts/malgun.ttf',
relative_scaling=0.2, #단어 사이 간격
background_color='white'
).generate_from_frequencies(dict(data))
plt.figure(figsize=(12,8))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
Naive Bayes Classifier(나이브 베이즈 분류)
from nltk.tokenize import word_tokenize #word_tokenize : 띄워쓰기로 분리시켜주는 기능
import nltknaive bayes 분류기는 지도학습이라서 정답을 알려줘야 한다.
train = [
("i like you", "pos"),
("i hate you", "neg"),
("you like me", "neg"),
("i like her", "pos")
]전체 말 뭉치를 만든다
-> 말뭉치를 이용하면 전체 문장을 만들 수 있다
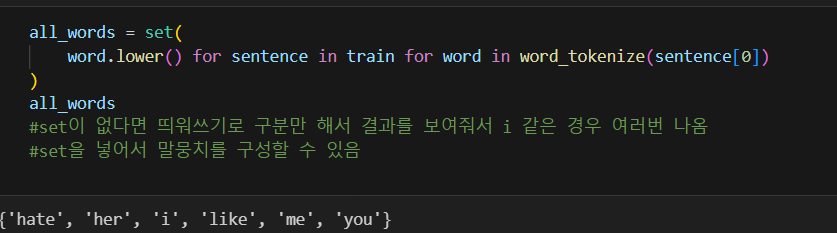
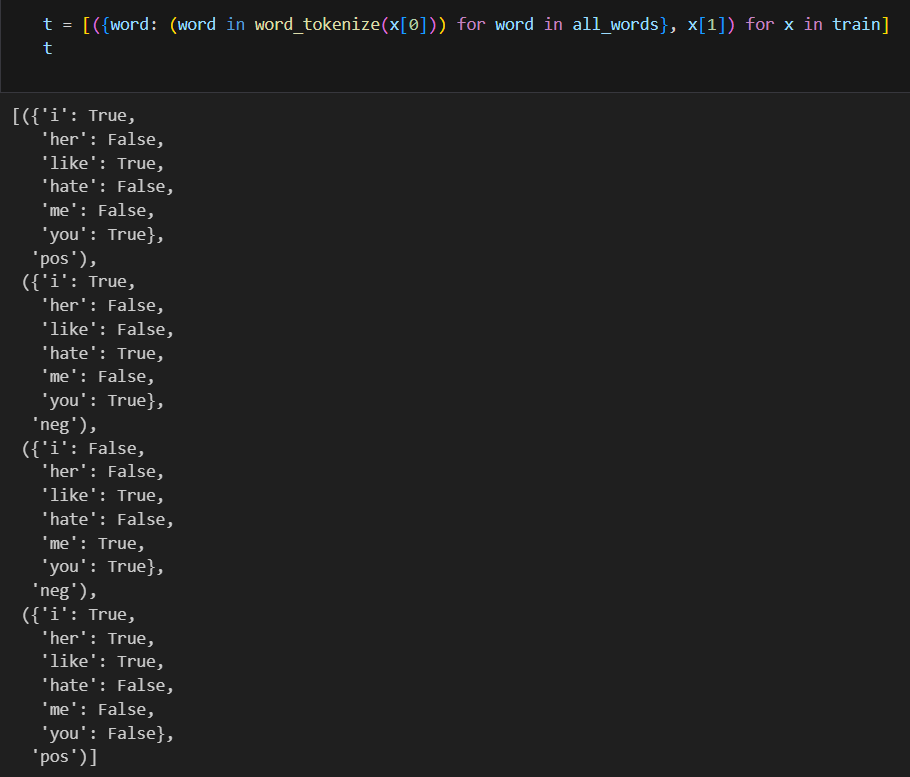 말 뭉치에 대비해서 단어의 유무를 표기
말 뭉치에 대비해서 단어의 유무를 표기
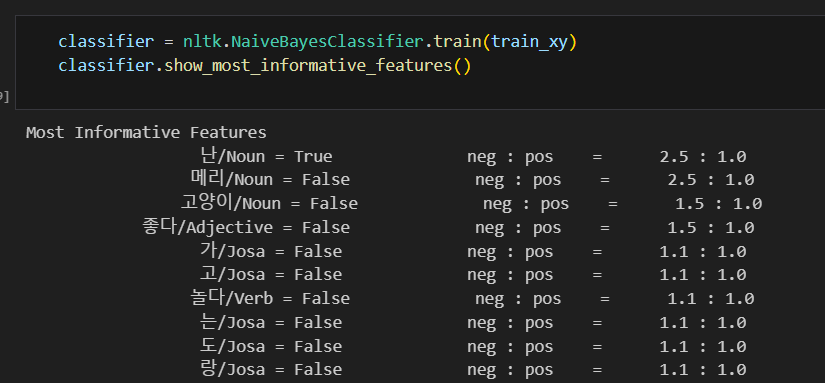
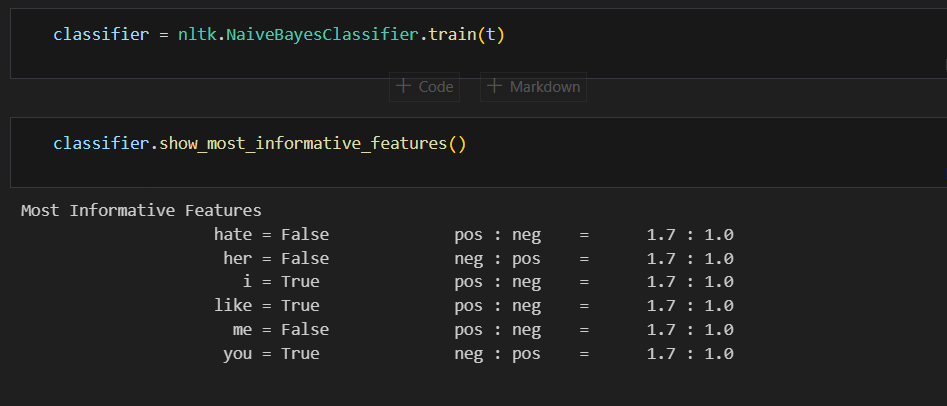 like가 있을 때, positive할 확률이 1.7:1.0이란 뜼
like가 있을 때, positive할 확률이 1.7:1.0이란 뜼
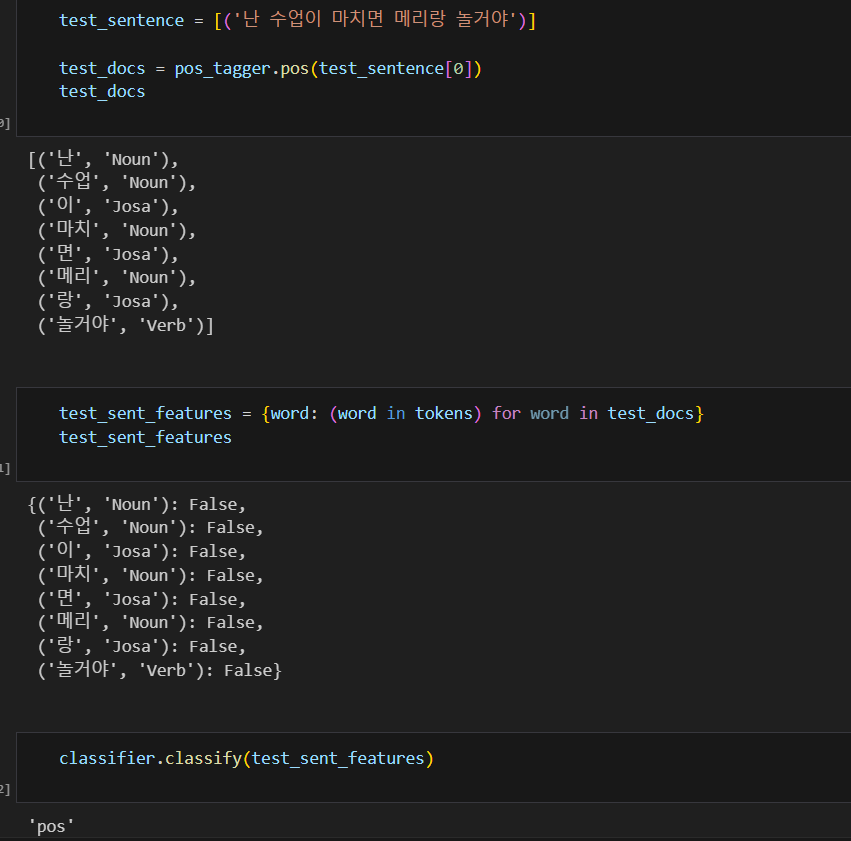
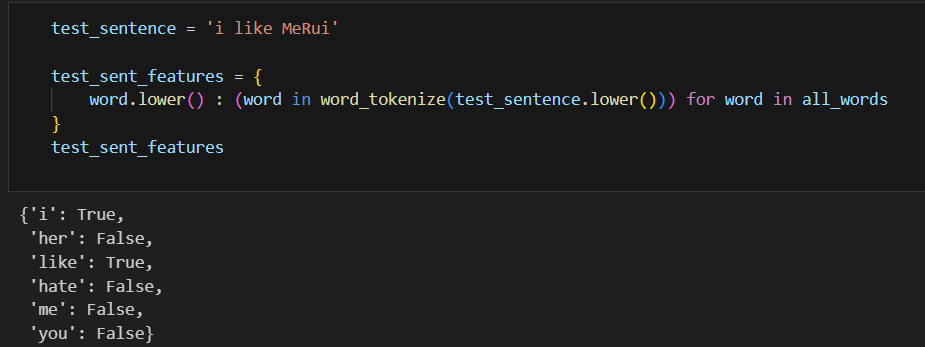 학습 결과를 가지고 테스트 해보자
학습 결과를 가지고 테스트 해보자

한글은 형태소 분석을 해야함
왜 필요한지 보기 위해서 일단 형태소 분석 없이 그냥 해본다
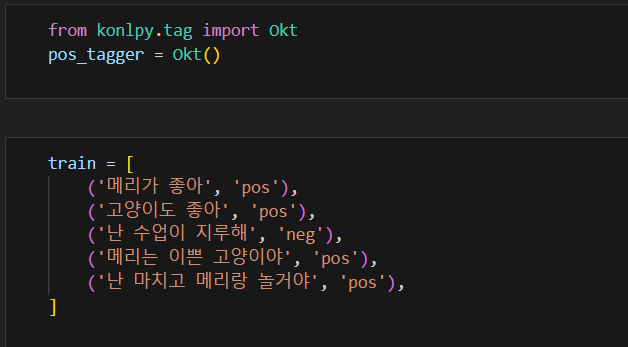 정답을 알고 있는 문장으로 훈련용 데이터를 준다
정답을 알고 있는 문장으로 훈련용 데이터를 준다
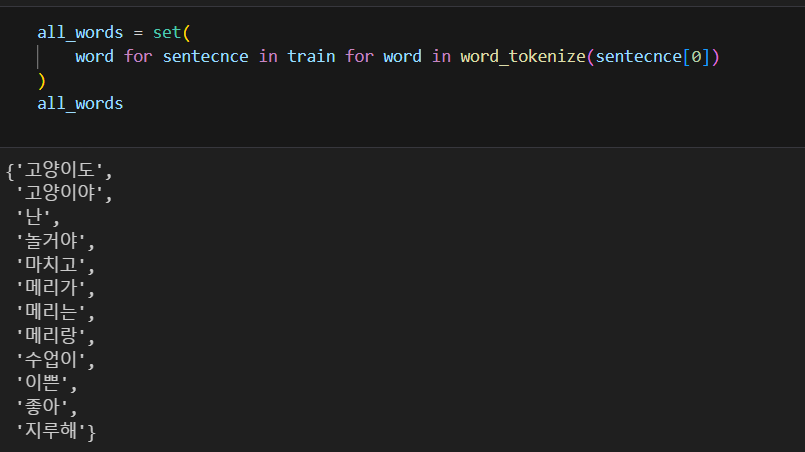 말뭉치를 만드는데, 메리가 메리는 메리랑을 모두 다른 단어로 인식하는데 이는 형태소 분석을 안했기 때문이다.
말뭉치를 만드는데, 메리가 메리는 메리랑을 모두 다른 단어로 인식하는데 이는 형태소 분석을 안했기 때문이다.
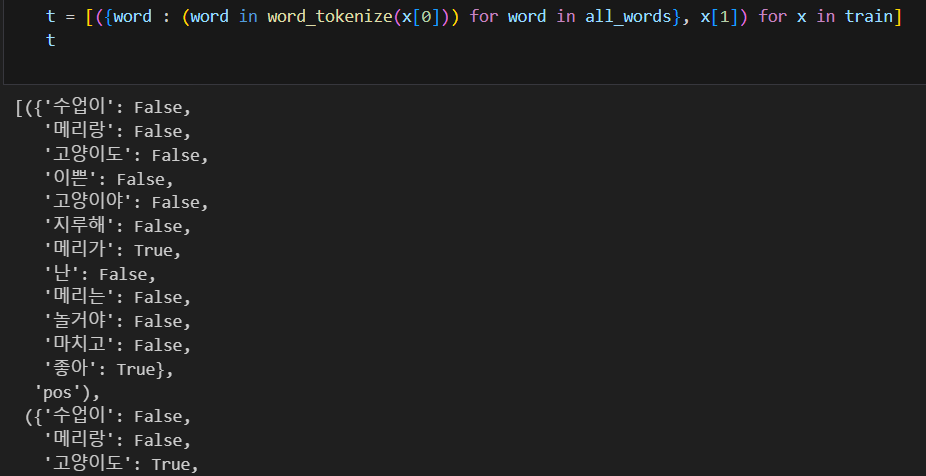
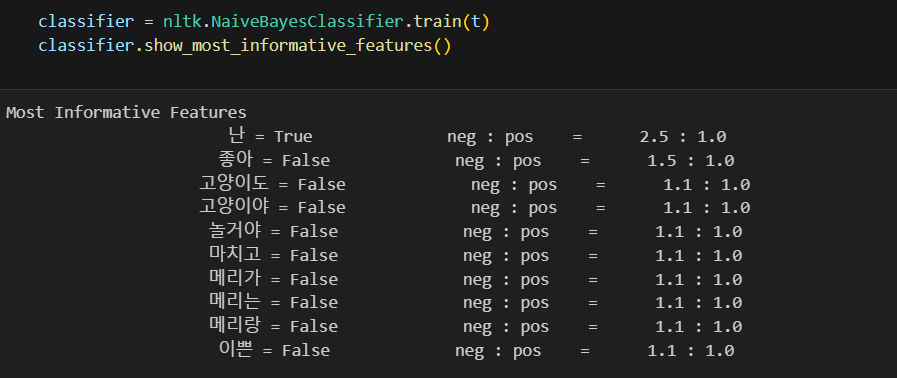
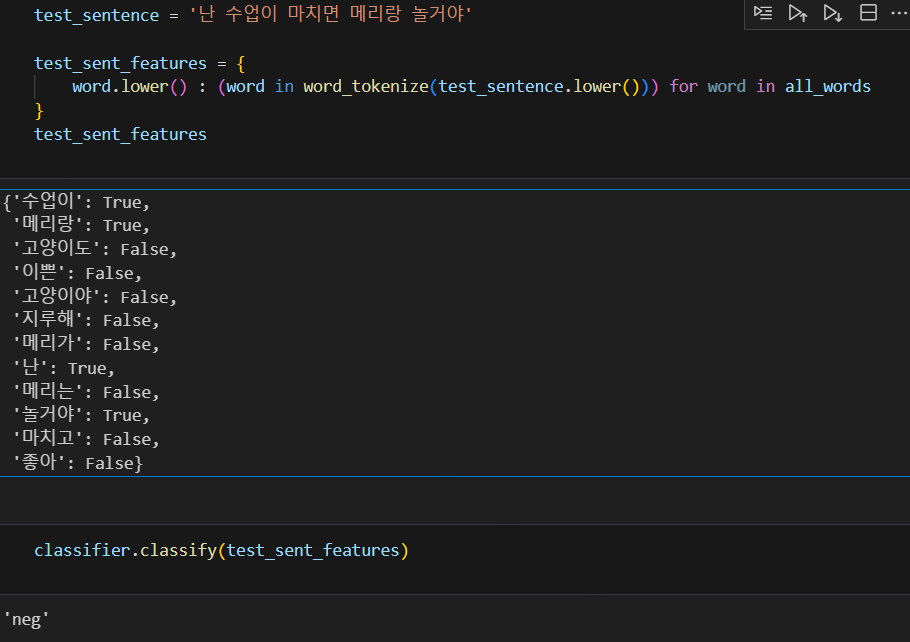 맞지 않는 결과가 나왔다
맞지 않는 결과가 나왔다
그래서 한글은 형태소 분석이 필수!!
#태그를 달아주는 함수
def tokenize(doc):
return['/'.join(t) for t in pos_tagger.pos(doc, norm=True, stem=True)]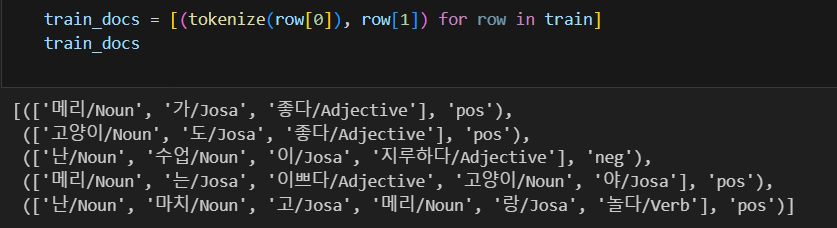
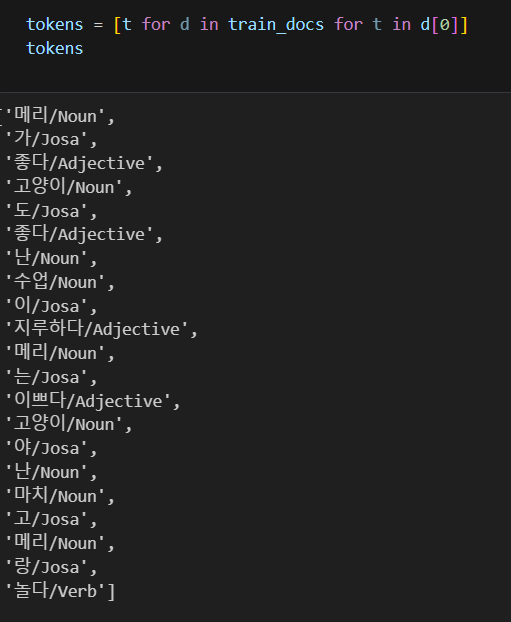
def term_exists(doc):
return {word: (word in set(doc)) for word in tokens}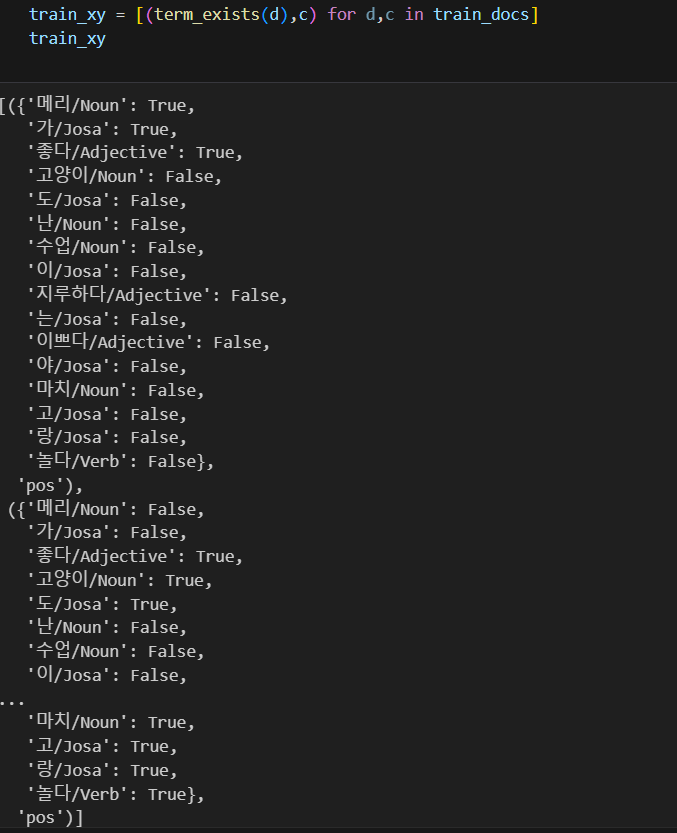
문장의 유사도 측정 - count vectorize
유사도 측정은 지도학습을 하지 않기 때문에 라벨 불필요
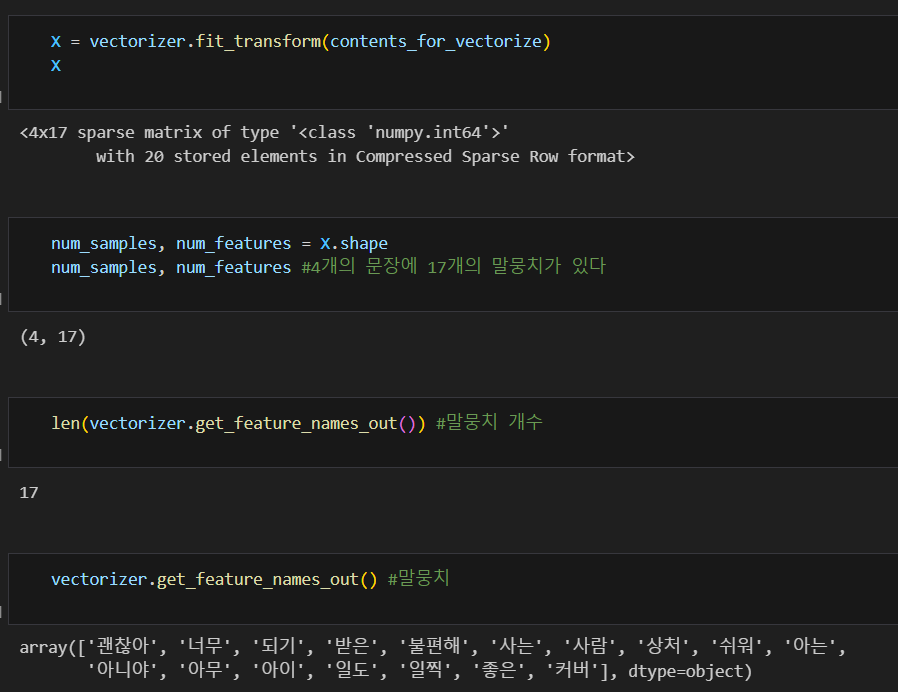
from sklearn.feature_extraction.text import CountVectorizer #CountVectorizer:글자들을 센다
vectorizer = CountVectorizer(min_df=1)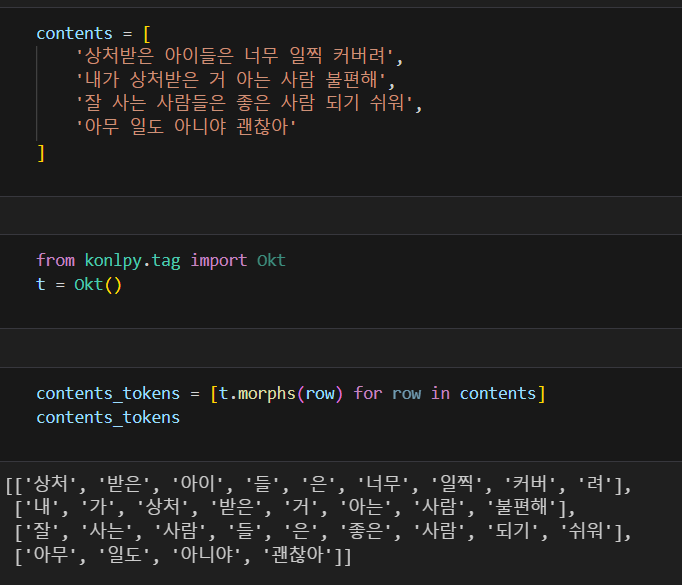
형태소 분석된 결과를 다시 하나의 문장씩으로 합친다
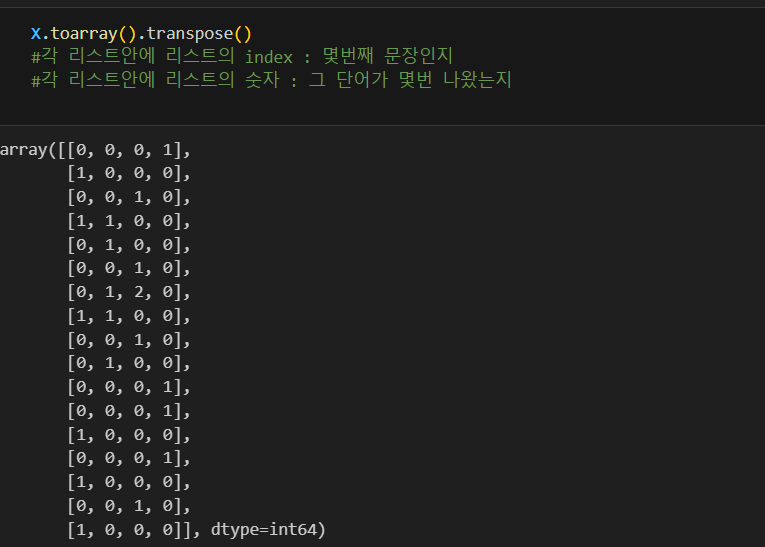
#벡터로 표현
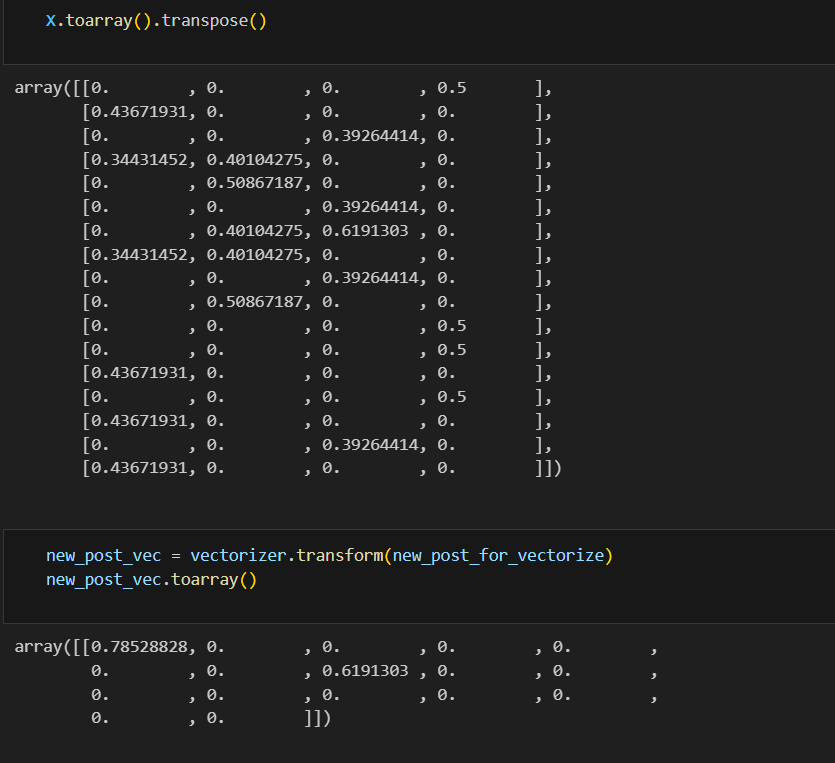
new_post_vec = vectorizer.transform(new_post_for_vectorize)
new_post_vec.toarray() #말뭉치에 없는 단어는 벡터로 못 만듦
#거리 계산
import scipy as sp
def dist_raw(v1,v2):
delta = v1-v2
return np.linalg.norm(delta.toarray())
dist = [dist_raw(each, new_post_vec) for each in X]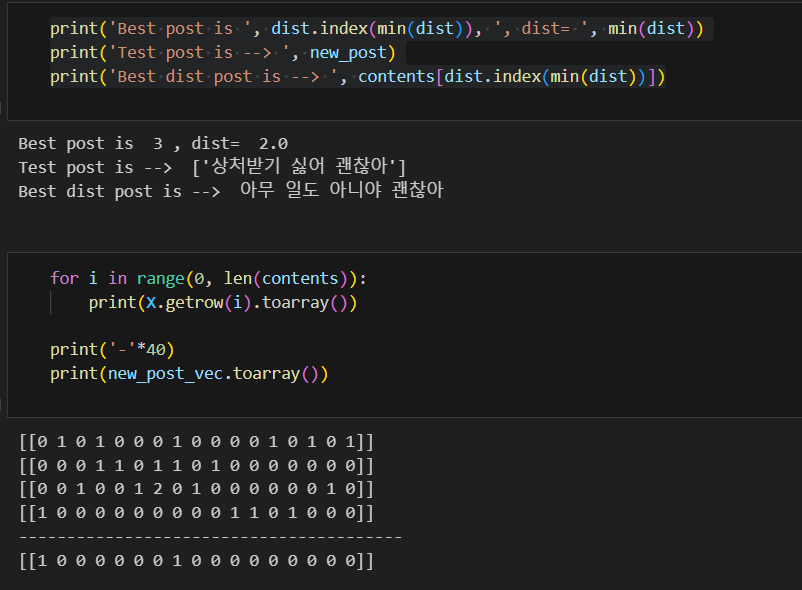
결국 가장 중요한 것은 벡터를 잘 만드는 것, 만들어진 벡터 사이의 거리를 잘 계산하는 것이다.
말뭉치는 벡터의 크기를 같은 크기로 만들어주는 중요한 역할을 한다
tfidf vectorize
한 문서에서 많이 등장한 단어는 중요하다고 보고, 전체 문서에서 많이 나타나는 단어는 중요하지 않다고 볼 때, 나타나는 개념
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(min_df=1, decode_error='ignore')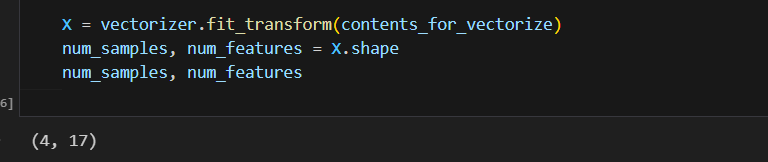
#두 벡터의 크기를 1로 변경하여 거리 측정
#한쪽 특성만 두드러져 보이는 것을 막을 수 있음
def dist_norm(v1,v2):
v1_normalized = v1 / sp.linalg.norm(v1.toarray())
v2_normalized = v2 / sp.linalg.norm(v2.toarray())
delta = v1_normalized - v2_normalized
return sp.linalg.norm(delta.toarray())
가장 유사한 문장이 count vectorize에서와 동일하게 '아무 일도 아니야 괜찮아'로 나왔다.
그러나 유사도는 다르다
네이버 API를 통한 유사질문 찾기
import urllib.request
import json
import datetime
def gen_search_url(api_node, search_text, start_num, disp_num):
base = "https://openapi.naver.com/v1/search"
node = "/" + api_node + ".json"
param_query = "?query=" + urllib.parse.quote(search_text)
param_start = "&start=" + str(start_num)
param_disp = "&display=" + str(disp_num)
return base + node + param_query + param_start + param_disp
def get_result_onpage(url):
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
print("[%s] Url Request Success" % datetime.datetime.now()) #[현재시간] 이 찍힘
return json.loads(response.read().decode("utf-8"))
client_id = 'm19f_M7BacBlDgpT6SMu'
client_secret = 'cQjt07FwM3'
url = gen_search_url('kin', '파이썬', 1, 100) #지식인에 파이썬을 검색
one_result = get_result_onpage(url)
def delete_tag(input_str):
input_str = input_str.replace('<b>', '')
input_str = input_str.replace('</b>', '')
return input_str
def get_description(pages):
contents = []
for sentences in pages['items']:
contents.append(delete_tag(sentences['description']))
return contents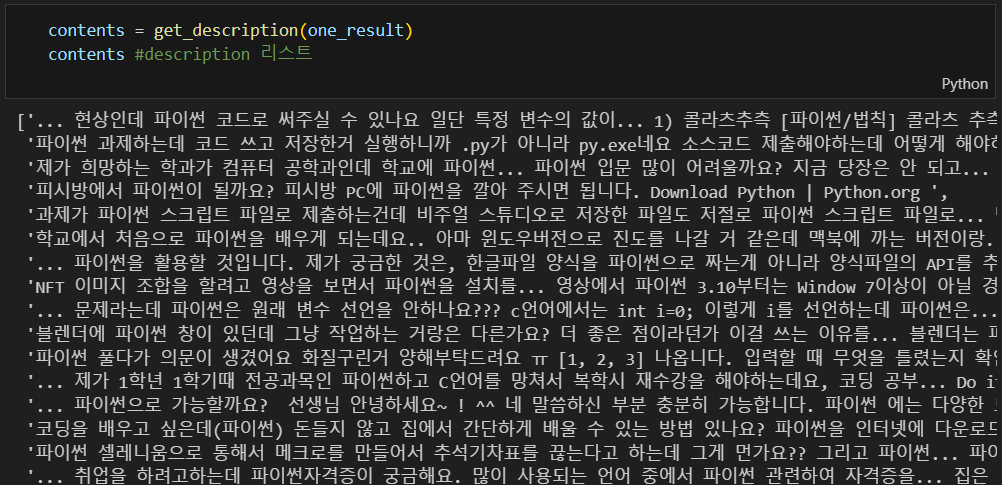
from sklearn.feature_extraction.text import CountVectorizer
from konlpy.tag import Okt
t = Okt()
vectorizer = CountVectorizer(min_df=1)
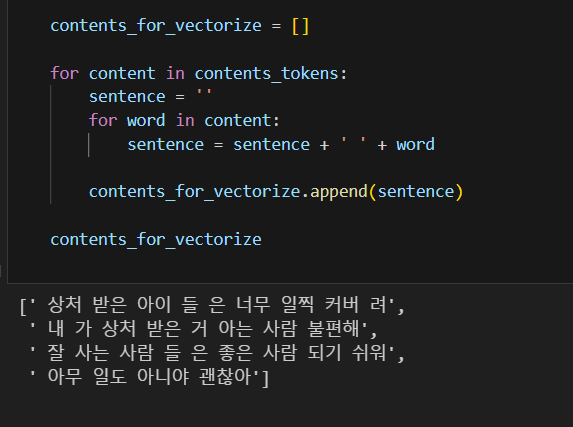
contents_tokens = [t.morphs(row) for row in contents]
contents_for_vectorize = []
for content in contents_tokens:
sentence = ''
for word in content:
sentence = sentence + ' '+ word
contents_for_vectorize.append(sentence)
X = vectorizer.fit_transform(contents_for_vectorize)
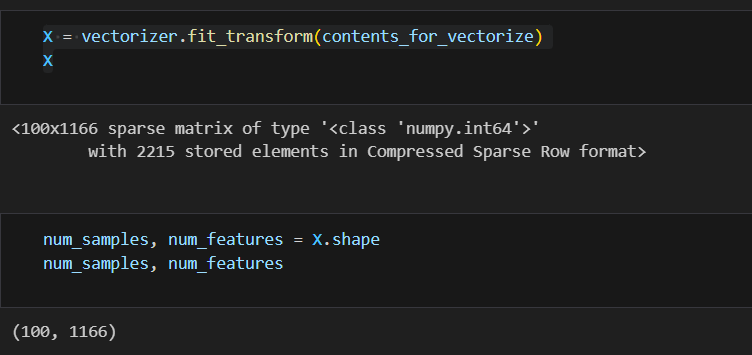
import scipy as sp
def dist_raw(v1, v2):
delta = v1 - v2
return sp.linalg.norm(delta.toarray())
dist = [dist_raw(each, new_post_vec) for each in X]