
이 시리즈에서 정리하는 Spring Boot 스터디 내용은
UMC 10기 활동을 기반으로 진행된 학습과 과제를 바탕으로 작성되었습니다

이전에 SWU UMC 7기에서는 Plan 파트로 참여했으며,
졸업 전 Spring Boot를 한 번 더 정리해보고자 UMC Spring Boot로 다시 참여하게 되었습니다.

개념 정리
0주차 개념 요약
0주차에서는 데이터베이스를 어떻게 설계해야 하는지를 중심으로 학습했다.
백엔드에서 DB 설계는 단순히 테이블을 만드는 작업이 아니라, 요구사항을 데이터 구조로 바꾸는 과정이라는 점이 핵심이다.
먼저 DB와 DBMS, 그리고 RDB와 NoSQL의 차이를 짚었다.
RDB는 테이블 간 관계를 기반으로 데이터를 관리하며, 중복을 줄이고 데이터 일관성과 정확성을 유지하는 데 강점이 있다. 반면 NoSQL은 대량 데이터 처리와 빠른 성능이 중요한 상황에서 주로 사용된다. 상황에 따라 SQL과 NoSQL을 함께 사용할 수도 있는데, 예를 들어 읽기 성능이 중요한 경우 Redis 같은 캐시를 추가로 도입할 수 있다.
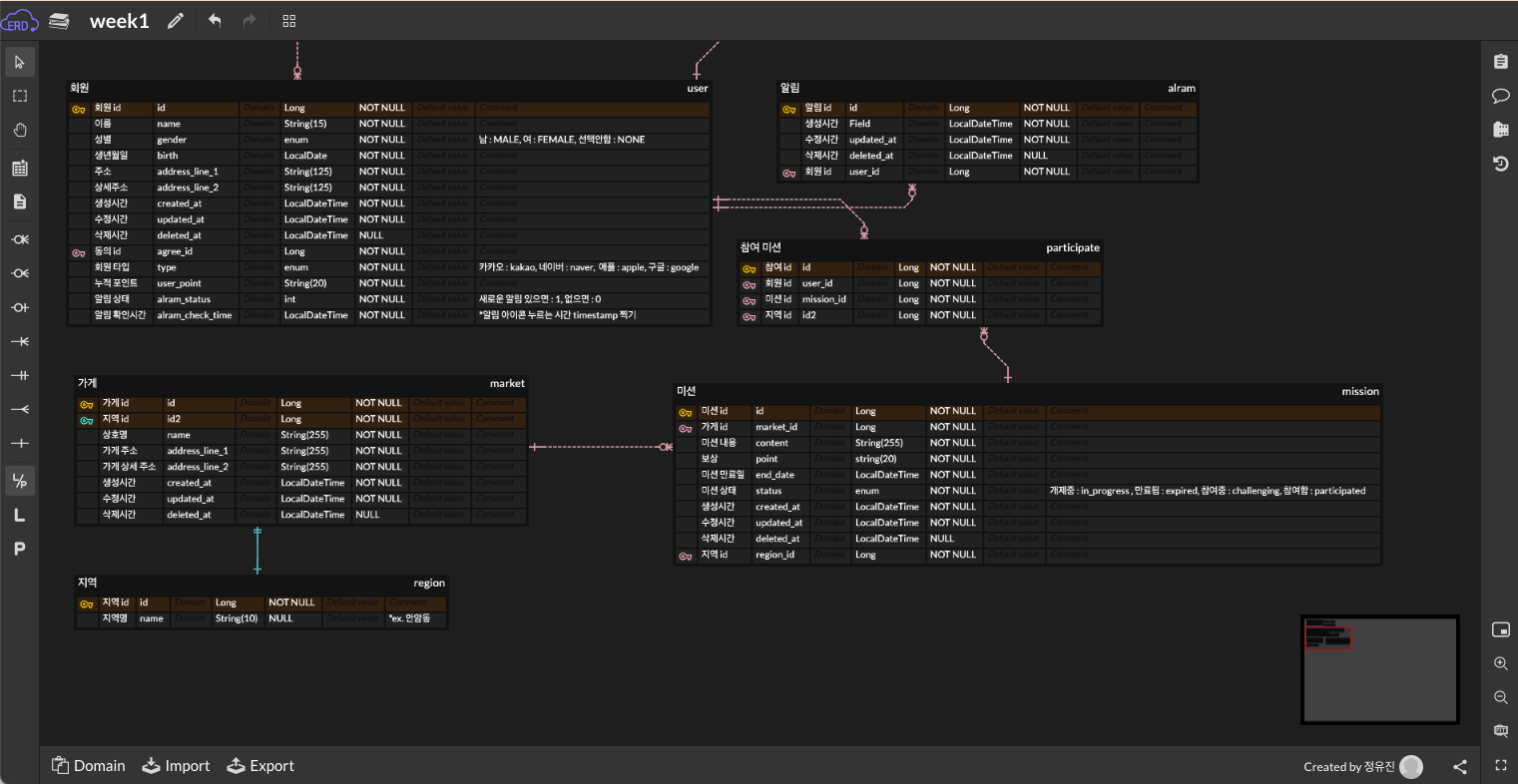
이후 본격적으로 ERD 설계를 다루었다.
ERD는 테이블, 속성, 관계, 제약조건을 시각적으로 정리한 것으로, 프로젝트 초기에 와이어프레임이나 요구사항이 나오면 이를 바탕으로 설계를 시작하게 된다. 결국 DB를 설계한다는 것은 ERD를 작성한다는 것과 거의 같은 의미로 볼 수 있다.
ERD를 작성할 때는 먼저 요구사항을 보고 어떤 데이터를 저장해야 할지 판단해야 한다.
이 과정에서 테이블명과 속성명 스타일을 통일하고, PK 이름 규칙도 일관되게 가져가는 것이 중요하다. 또 속성별로 NULL 허용 여부, 길이 제한, enum 사용 여부 같은 제약조건을 설정해야 한다. 이때 제약조건은 임의로 정하기보다 PM과 충분히 협의하며 결정하는 것이 중요하다.
추가로 Soft Delete 개념도 중요하게 다뤄졌다.
회원 탈퇴처럼 데이터를 바로 지우기보다 deleted_at 같은 값을 두어 삭제 여부만 표시하면, 복구 기능이나 탈퇴 후에도 남아야 하는 데이터 처리가 쉬워진다. 실제 서비스에서는 이런 방식이 자주 사용된다.
관계 설정에서는 특히 다대다(N:N) 관계를 어떻게 설계할지가 핵심이었다.
예를 들어 사용자-책 대여, 책-해시태그, 사용자-책 좋아요 관계는 모두 다대다 관계이므로, 이를 그대로 한 테이블에 담지 않고 중간 테이블(매핑 테이블) 을 두어 설계해야 한다. 이렇게 해야 데이터 중복을 줄이고 정규화된 구조를 유지할 수 있다.
마지막으로, ERD는 처음부터 완벽해야 하는 것이 아니라 구현 가능한 수준으로 빠르게 설계하고, 개발하면서 계속 수정해 나가는 것이 중요하다는 점도 강조되었다. 결국 좋은 설계란 이론적으로만 완벽한 설계가 아니라, 현재 요구사항을 잘 반영하면서도 이후 변경에 대응할 수 있는 설계라고 정리할 수 있다.
ERD를 작성 (예시 실습)

각 테이블 작성
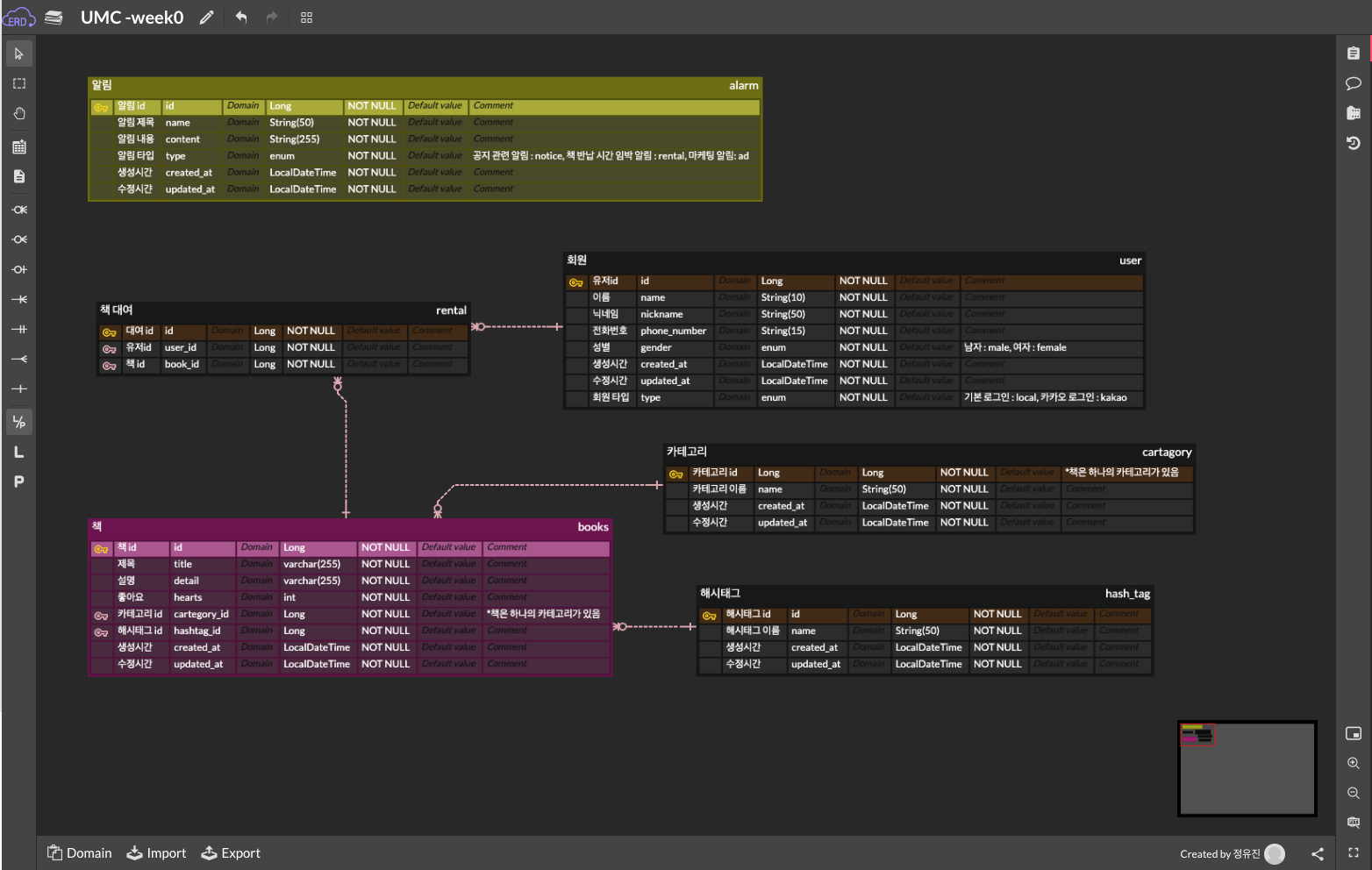
설계 과정에서 고민한 부분
- 소셜 로그인 시 카카오 uid를 어떻게 저장할 것인가
- 책 좋아요 기능을 별도 테이블로 분리할 필요성
- 알림은 단순 내용보다 type 기반 설계가 필요함
- 삭제 데이터를 관리하기 위한 Soft Delete 적용
👉 특히 Soft Delete는 실제 서비스에서 매우 중요하며,
삭제 여부를 deleted_at으로 관리하는 방식이 일반적으로 사용된다.
모법 답안
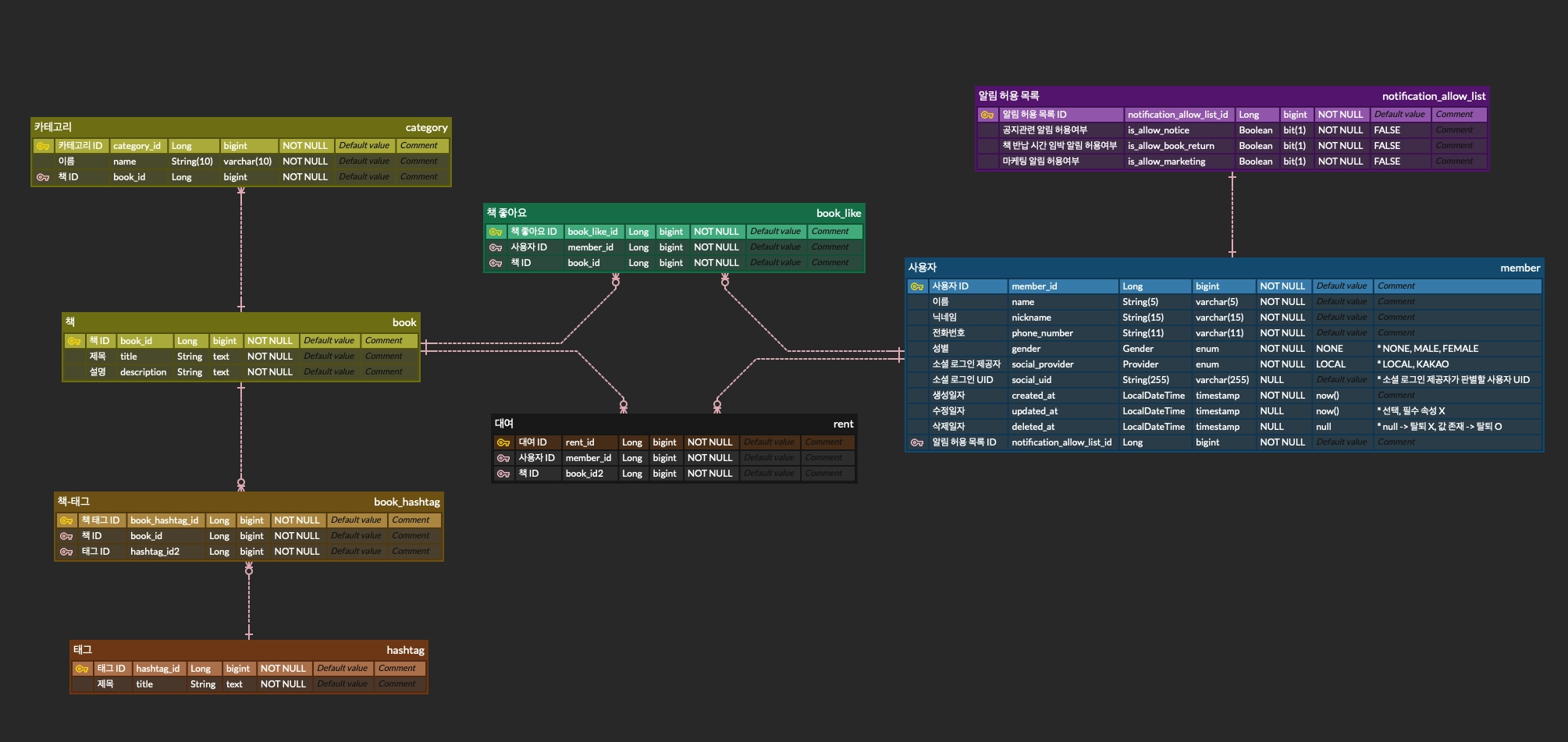
핵심 키워드 정리
미션 과제 말고 직접 조사하는 과제가 있는데
주요 내용들에 대해 조사해보고, 자신만의 생각을 통해 정리해보세요! 레퍼런스를 참고하여 정의, 속성, 장단점 등을 적어주셔도 됩니다. 조사는 공식 홈페이지 Best, 블로그(최신 날짜) Not Bad라는 멘트를 보고, 공식 문서를 보고 최대한 찾고 싶었다
#1. PK, FK 란


#2. ERD란?

#3. 연관관계란? 그리고 연간관계를 설정하는 방법은?

연관관계(Association)란 두 개 이상의 엔티티가 데이터베이스의 조인(join) 개념을 바탕으로 서로 연결되는 관계를 의미한다. 관계형 데이터베이스에서는 보통 외래 키(Foreign Key)를 통해 테이블 간 관계를 맺고, JPA에서는 이를 엔티티 간 관계로 매핑한다. 연관관계의 종류에는
@ManyToOne,@OneToMany,@OneToOne,@ManyToMany가 있다.

연관관계는 JPA에서 어노테이션을 사용해 설정할 수 있다. 예를 들어
@ManyToOne은 여러 자식 엔티티가 하나의 부모 엔티티를 참조하는 관계를 나타내며,@JoinColumn을 사용해 외래 키 컬럼을 지정할 수 있다. 또한 연관관계는 한쪽만 참조하는 단방향 관계와 양쪽이 서로 참조하는 양방향 관계로 나뉜다. 양방향 관계에서는 외래 키를 실제로 관리하는 연관관계의 주인(owning side) 이 하나만 존재하며, 보통 자식 엔티티 쪽이 주인이 된다.
#4. 정규화란?

위 처럼 공식 문서엔 나와있었고,
한마디로 정규화란? 데이터 정합성(데이터의 정확성과 일관성을 유지하고 보장)을 위해
엔터티를 작은 단위로 분리하는 과정을 말한다.
정규화를 할 경우 데이터 조회 성능은 처리조건에 따라 향상되는 경우도 있고 저하되는 경우도 있지만 입력, 수정, 삭제 성능은 일반적으로 향상된다고 볼 수 있다.
하지만 그렇다고 모든 엔터티를 무작정 분리하면 안 되기 때문에
정규화를 하기 위한 일정한 룰이 존재함 !
정규화 종류 (대표단계)
- 제1정규형 - 모든 속성은 반드시 하나의 값만 가져야 한다
- 제2정규형 - 엔티티의 모든 일반 속성은 반드시 모든 주식별자에 종속되어야 한다.
- 제3정규형 - 주식별자가 아닌 모든 속성 간에는 서로 종속될 수 없다.
출처 : 2024 유선배 SQL개발자 과외노트
#5. 반 정규화란?

위 처럼 공식 문서엔 나와있었고,
한마디로 반정규화란? 데이터의 조회 성능을 위해
데이터의 중복을 허용하거나 데이터를 그룹핑하는 과정을 말한다.
여기서 주의해야 할 점은 조회 성능은 향상될 수 있으나 입력, 수정, 삭제 성능은 저하될 수 있으며 데이터 정합성 이슈가 발생할 수 있다는 점이다.
반정규화의 과정은 정규화가 끝난 후 거치게 되며 정규화와 마찬가지로 일정한 룰이 존재한다
반정규화 종류
- 테이블 반정규화 - 테이블 변합, 분할, 추가
- 컬럼 반정규화 - 중복 칼럼 추가, 파생 칼럼 추가, 이력 테이블 컬럼 추가
- 관계 반정규화(중복 관계 추가) - 업무 프로세스상 JOIN이 필요한 경우가 맣아 중복 관계를 추가하는 것이 성능 측면에서 유리할 여우 고려
출처 : 2024 유선배 SQL개발자 과외노트
#6. DB에서의 상속관계 표현은 어떻게 하는가?

#7. 인덱스란?

위 처럼 공식 문서엔 나와있었고,
주요 특징으로는
- 인덱스를 통하여 레코드를 빠르게 접근할 수 있다.
- 데이터 베이스의 물리적 구조와 밀접한 관계가 있다.
- 레코드의 삽입/삭제가 자주 발생 시 인덱스의 개수를 최소화하는 것이 효율적이다.
- 하지만 인덱스가 많아질수록 INSERT, UPDATE, DELETE 성능은 저하될 수 있다.
- B 트리
- m차 B 트리는 근노드와 단말 노드를 제외한 모든 노드가 최소 m/2개, 최대 m개의 서브 트리를 가지는 구조이다.
- 한 노드에 있는 키 값은 오름차순을 유지한다.
- 근노드로부터 탐색 , 추가, 삭제가 이뤄진다.
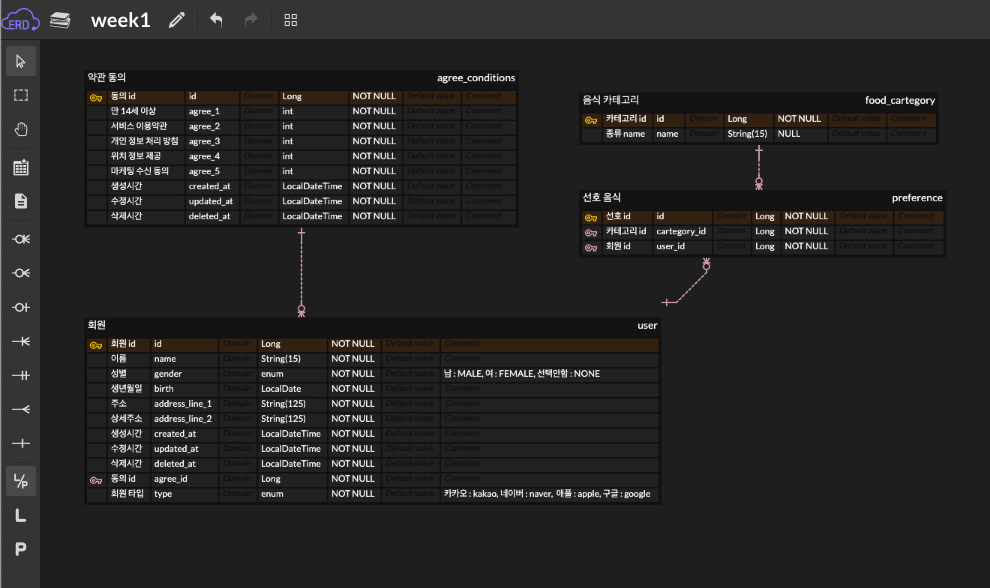
week0 주차 워크북 미션
주어진 IA(기획 플로우)와 와이어 프레임(디자인 프로토타입)을 보고 직접 데이터베이스를 설계하기
데이터베이스 설계 조건은 ?!

#1. 로그인/회원가입 파트
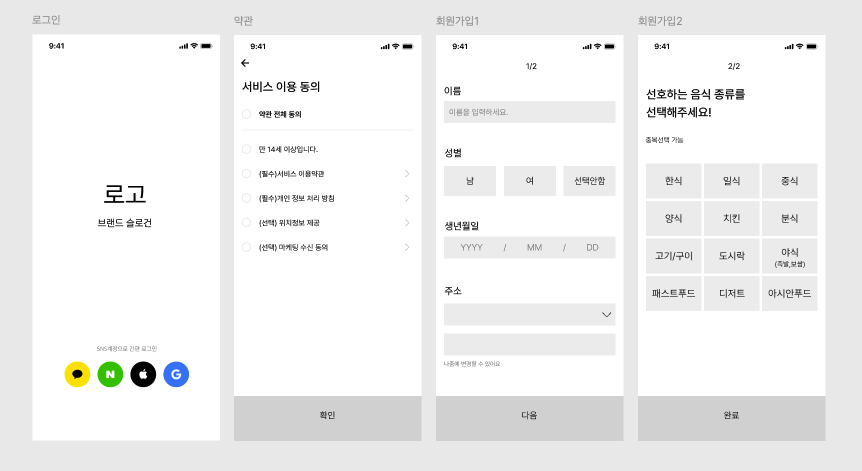
보이는 조건들을 정리해보면
1. 로그인은 4가지 방법으로 가능함
2. 이용 약관은 5개 - 필수도 있고 선택도 있음
3. 개인정보는 이름, 성별, 생년월일, 주소1, 주소2를 받고
4. 음식 종류를 선택가능 - 16개가 주어지고 선택은 다중선택 가능
CREATE TABLE `user` (
`id` Long NOT NULL,
`name` String(15) NOT NULL,
`gender` enum NOT NULL COMMENT '남 : MALE, 여 : FEMALE, 선택안함 : NONE',
`birth` LocalDate NOT NULL,
`address_line_1` String(125) NOT NULL,
`address_line_2` String(125) NOT NULL,
`created_at` LocalDateTime NOT NULL,
`updated_at` LocalDateTime NOT NULL,
`deleted_at` LocalDateTime NOT NULL,
`agree_id` Long NOT NULL,
`type` enum NOT NULL COMMENT '카카오 : kakao, 네이버 : naver, 애플 : apple, 구글 : google'
);
CREATE TABLE `agree_conditions` (
`id` Long NOT NULL,
`agree_1` int NOT NULL,
`agree_2` int NOT NULL,
`agree_3` int NOT NULL,
`agree_4` int NOT NULL,
`agree_5` int NOT NULL,
`created_at` LocalDateTime NOT NULL,
`updated_at` LocalDateTime NOT NULL,
`deleted_at` LocalDateTime NOT NULL
);
CREATE TABLE `food_cartegory` (
`id` Long NOT NULL,
`name` String(15) NULL
);
CREATE TABLE `preference` (
`id` Long NOT NULL,
`cartegory_id` Long NOT NULL,
`user_id` Long NOT NULL
);
#2. 홈 파트
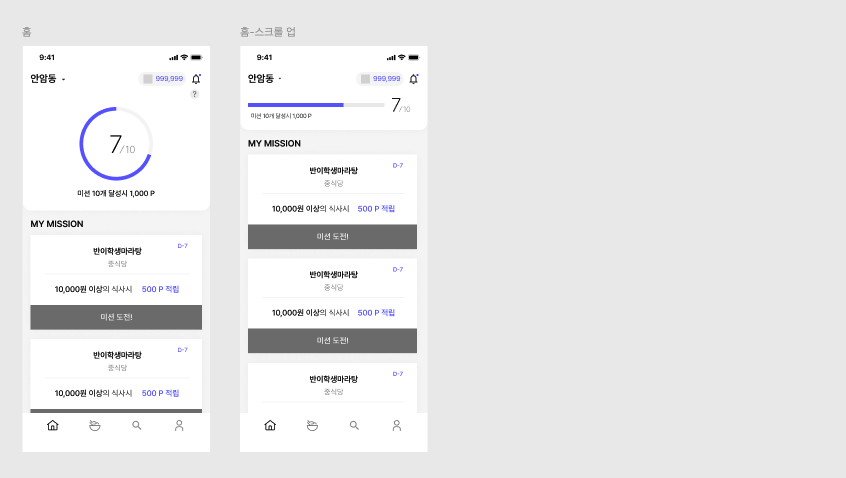
우선, 미션 관련 테이블을 만들기 전에
상단에 보이는 포인트 내역, 알림여부에 대한 data 구조를 기존 table에서 추가했습니다.
CREATE TABLE `user` (
`id` Long NOT NULL,
... 생략
`user_point` String(20) NOT NULL,
`alram_status` int NOT NULL COMMENT '새로운 알림 있으면 : 1, 없으면 : 0'
);CREATE TABLE `alram` (
`id` Long NOT NULL,
`Field` LocalDateTime NOT NULL,
`updated_at` LocalDateTime NOT NULL,
`deleted_at` LocalDateTime NULL,
`user_id` Long NOT NULL
);그런 다음 미션카드 데이터를 저장하기 위해 가게정보, 미션정보 그리고 기타 지역 정보 table, 참여 미션 테이블 등을 추가 했습니다.
#3. 미션 파트
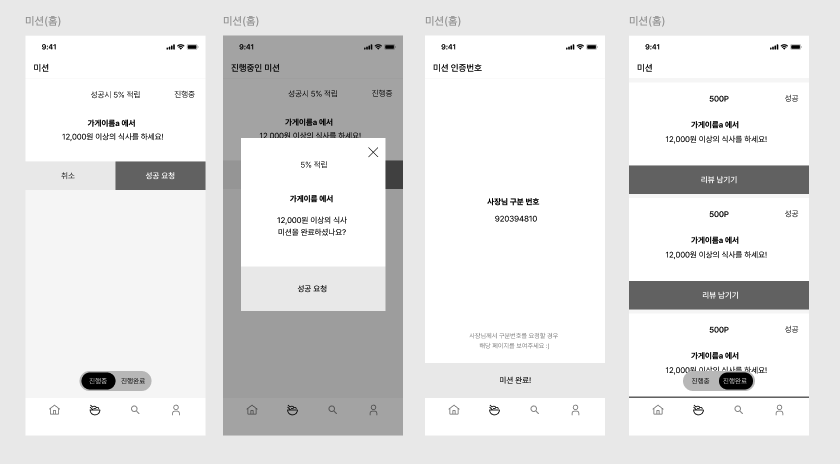
다른 추가적인 데이터 입출력보다는, 3번째 page에 사장님 구분 번호 9자리에 대한걸 어떻게 처리할지 고민 해봤었다.
방법1. 미션이 생성될 때 자동 증가되며 생성되는 미션 고유 id인 값을 보여주기
방법2. 미션 고유 id를 그럼 자동증가가 아닌, 9자리 랜덤생성으로 할지
방법3. 미션 성공요청시에 생성되는 인증번호를 따로 만들지
일단 이에 대한 과제 제한 사항은 없었기 때문에,
현재는 구현 단순성을 위해 1번 방식을 선택했지만,향후에는 인증번호 기반 구조(3번)도 고려할 수 있다.
#4. 기타
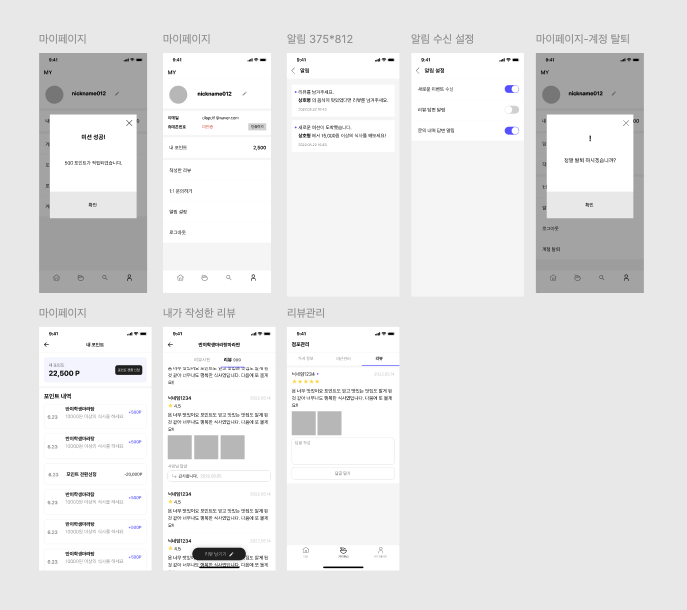
남은 페이지들을 확인해보니
기존 회원 table, 알림 table, 약관 동의 table, 참여 미션 table 에 조금씩 수정한다면, 다 보여줄 수 있는 데이터들 이였다
01. 회원 table
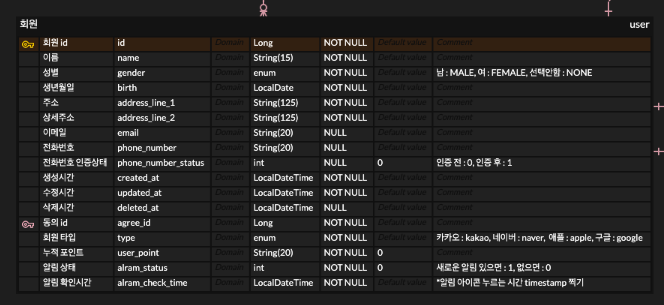
CREATE TABLE `user` (
...
// 추가 항목
`email` String(20) NULL,
`phone_number` String(20) NULL,
`phone_number_status` int NULL DEFAULT 0 COMMENT '인증 전 : 0, 인증 후 : 1',
...
);02. 알림 table
이전 화면에서는 알림이 어떻게 표시되는지 알 수 없어서 추가하지 않았었던, 알림 table을 완성시켜봐야할거같아요
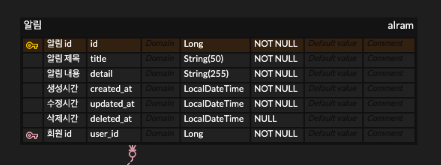
CREATE TABLE `alram` (
`id` Long NOT NULL,
`title` String(50) NOT NULL,
`detail` String(255) NOT NULL,
`created_at` LocalDateTime NOT NULL,
`updated_at` LocalDateTime NOT NULL,
`deleted_at` LocalDateTime NULL,
`user_id` Long NOT NULL
);
03. 약관 동의 table
새로운 이벤트 수신, 리뷰 답변 알림, 문의 내역 답변 알림 3개에 대한 알림 수신 설정을 할 수 있음
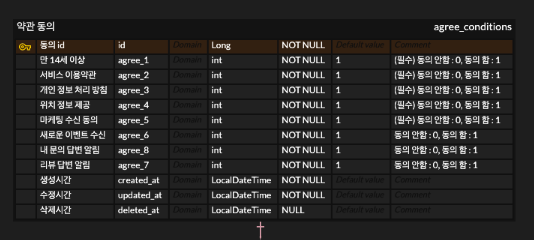
04. 참여 미션 table
참여 미션 또한 생성시간이 있어야하고, ui에서도 참여 완료 시간이 찍혀야하기 때문에 꼭 필요한 것을 알 수 있음
CREATE TABLE `participate` (
...
// 추가 항목
`created_at` LocalDateTime NOT NULL,
`updated_at` LocalDateTime NOT NULL,
`deleted_at` LocalDateTime NULL,
...
);미션 최종 ERD

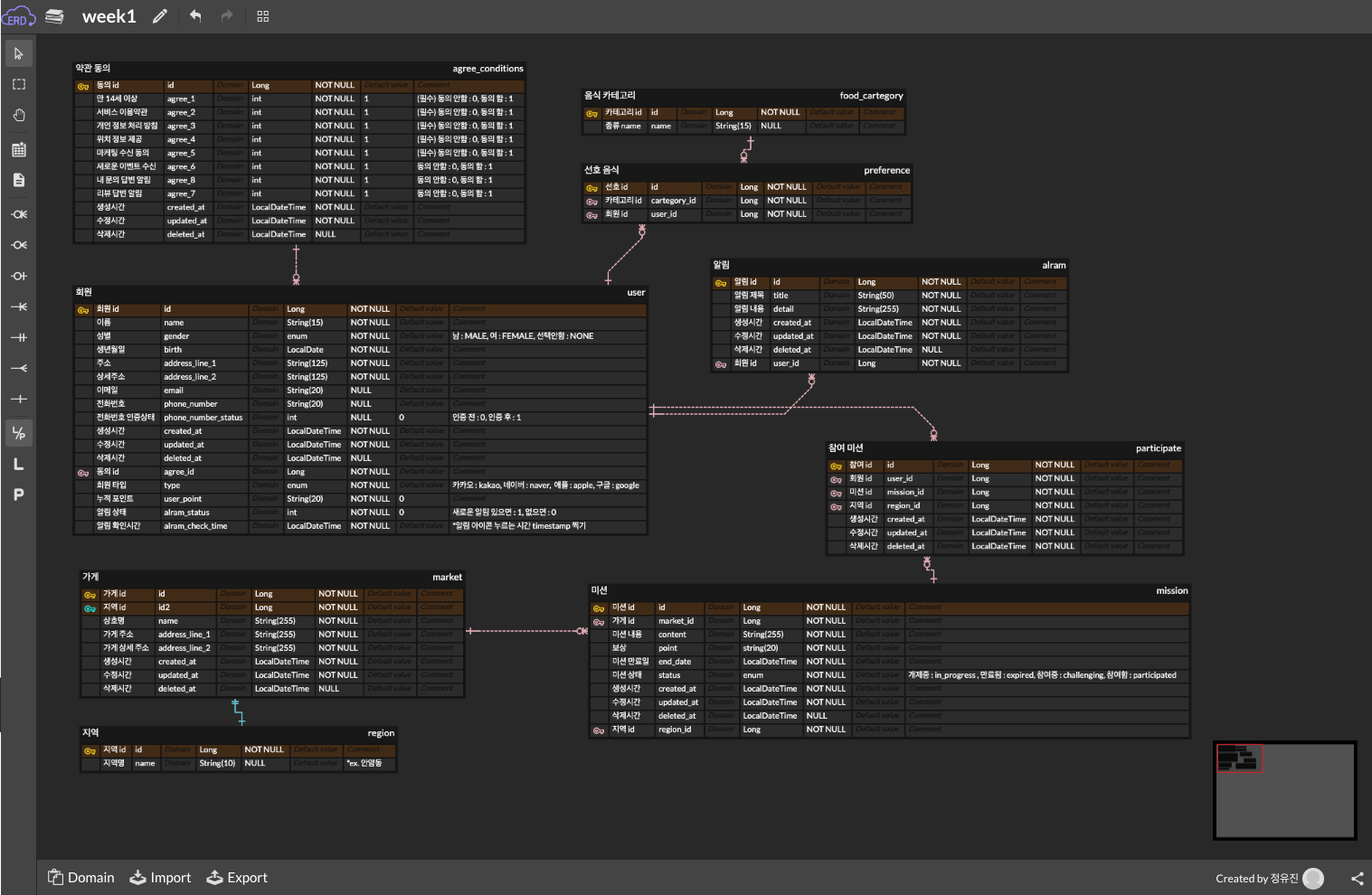
📌 마무리
0주차에서는 단순한 DB 구조 설계가 아니라,
요구사항을 기반으로 데이터를 어떻게 구조화할 것인지에 대해 고민하는 과정이었습니다.
특히,
- N:N 관계를 중간 테이블로 분리하는 것
- Soft Delete를 고려한 설계
- 확장성을 고려한 컬럼 설계
이 세 가지가 핵심 포인트였다.
다음 주차에서는 이렇게 설계한 ERD를 기반으로
실제 데이터를 조회하는 쿼리를 작성해보며,
DB 설계가 어떻게 실제 기능으로 이어지는지 학습할 예정입니다.
