
0주차에서 데이터베이스 구조를 설계했다면,
이번 1주차에서는 해당 ERD를 기반으로 실제 데이터를 조회하는 쿼리를 작성해보는 과정이다.
단순히 SQL 문법을 사용하는 것이 아니라,
요구사항을 어떤 쿼리로 풀어낼 수 있을지 고민하는 데에 초점을 두었다.
1주차 개념 요약
1주차에서는 0주차에 설계한 ERD를 바탕으로,
요구사항을 실제 SQL 쿼리로 어떻게 풀어낼지를 학습했다.
즉, 이번 주차의 핵심은 단순히 테이블 구조를 이해하는 것을 넘어, 필요한 데이터를 효율적으로 조회하는 방법을 익히는 데 있다.
먼저 요구사항을 보고 어떤 쿼리가 필요한지 판단하는 연습을 했다.
단순 조건 조회는 WHERE 절만으로 해결할 수 있지만, 여러 테이블의 정보가 함께 필요할 때는 JOIN 이 필요하다. 예를 들어 특정 지역의 미션을 조회하려면 미션, 가게, 지역 테이블을 연결해서 원하는 조건으로 필터링해야 한다. 이 과정을 통해 하나의 요구사항을 보고 어떤 테이블들이 연결되어야 하는지 생각하는 습관이 중요하다는 점을 배웠다.
또한 JOIN과 서브쿼리(Subquery) 의 차이도 다뤘다.
JOIN은 두 개 이상의 테이블을 결합해서 한 번에 결과를 조회하는 방식이고, 서브쿼리는 쿼리 안에 또 다른 쿼리를 넣어 조건이나 결과를 만드는 방식이다. 일반적으로는 JOIN이 더 효율적인 경우가 많지만, 상황에 따라 서브쿼리가 더 직관적이고 가독성이 좋은 경우도 있다. 따라서 중요한 것은 무조건 한 가지 방식만 고집하는 것이 아니라, 가독성과 성능을 함께 고려하여 선택하는 것이다.
이번 주차에서 특히 중요한 개념은 페이징(Paging) 이다.
목록 조회 시 모든 데이터를 한 번에 가져오면 성능 문제가 발생하기 때문에, 데이터베이스에서 필요한 만큼만 잘라서 조회해야 한다. 이를 위해 LIMIT 과 OFFSET 을 사용하는 Offset 기반 페이징을 먼저 학습했다. 이 방식은 구현이 단순하고 페이지 번호로 이동하기 쉽다는 장점이 있지만, 뒤로 갈수록 성능이 떨어지고 중간에 데이터가 추가되면 중복 조회나 누락이 발생할 수 있다는 단점이 있다.
이러한 문제를 보완하기 위해 Cursor 기반 페이징도 학습했다.
Cursor Paging은 마지막으로 조회한 데이터를 기준으로 다음 데이터를 가져오는 방식이다. 보통 PK처럼 고유한 값을 기준으로 삼으면 안정적으로 다음 페이지를 조회할 수 있다. 다만 별점처럼 중복 가능한 값만 커서로 사용하면 같은 결과가 반복될 수 있기 때문에, 정렬 기준 컬럼과 PK를 함께 사용해 고유한 커서를 만들어야 한다는 점이 중요하다.
정리하면 1주차는 요구사항을 SQL로 해석하는 방법, JOIN과 서브쿼리의 차이, 그리고 Offset / Cursor 기반 페이징의 원리와 차이점을 이해하는 주차였다. 결국 이번 주차를 통해, 좋은 쿼리란 단순히 동작하는 쿼리가 아니라 요구사항을 정확히 반영하면서도 성능과 확장성을 함께 고려한 쿼리라는 점을 배울 수 있었다.
핵심 키워드
#1. DB Join이란?

#2. Join 종류들
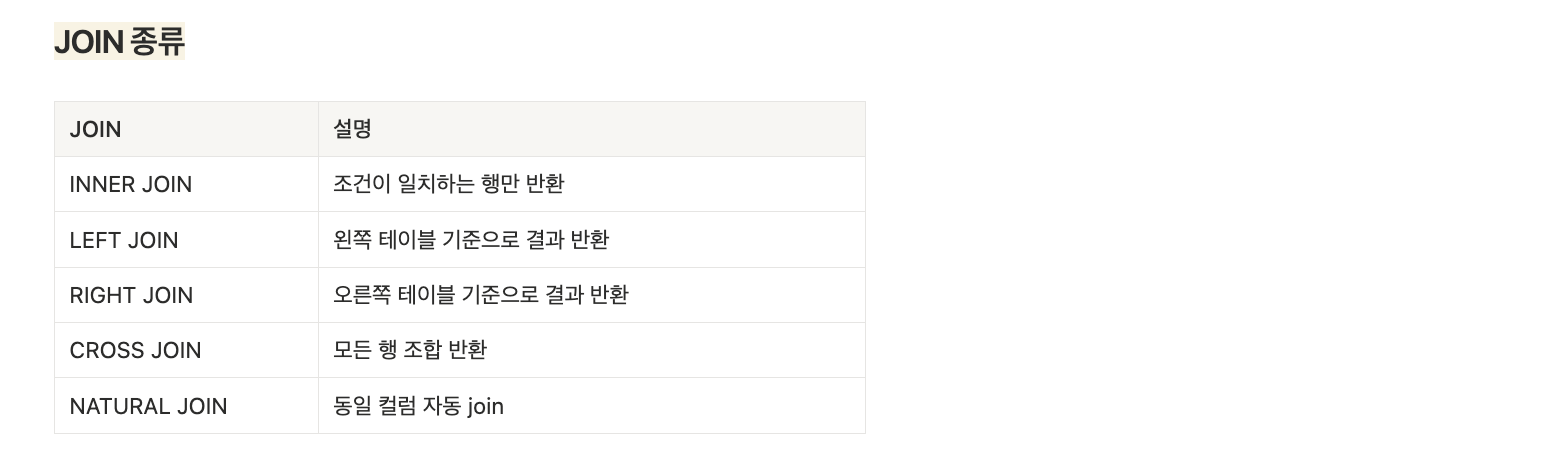
1. INNER JOIN
SELECT *
FROM table1
INNERJOIN table2
ON table1.id= table2.id;- 두 테이블에서 조건이 일치하는 행만 반환
- MySQL에서는 다음이 동일하게 취급된다
JOIN
INNER JOIN
CROSS JOIN2. LEFT JOIN (LEFT OUTER JOIN)
SELECT *
FROM table1
LEFTJOIN table2
ON table1.id= table2.id;- 왼쪽 테이블 기준
- 오른쪽 테이블에 값이 없으면 NULL 반환
문서 예시도 존재
If there is no matching row for the right table in a LEFT JOIN,
a row with all columns set to NULL is used for the right table.3. RIGHT JOIN
SELECT *
FROM table1
RIGHTJOIN table2
ON table1.id= table2.id;- 오른쪽 테이블 기준
- MySQL 문서에서는 LEFT JOIN 사용을 권장
4. CROSS JOIN
SELECT *
FROM table1
CROSSJOIN table2;- Cartesian Product
- 모든 행 조합 생성
문서에서도 설명
INNER JOIN and , produce a Cartesian product if no condition exists5. NATURAL JOIN
SELECT *
FROM t1NATURALJOIN t2;- 같은 이름의 컬럼을 자동으로 join
문서 설명
NATURAL JOIN uses all columns that exist in both tables#3. 트랜잭션이란?

위 처럼 공식 문서엔 나와있었고,
한마디로 트랜잭션이란? 데이터를 조작하기 위한 하나의 논리적인 작업 단위를 말한다.
주요 명령어
- START TRANSACTION : 트랜잭션 시작
- COMMIT : 변경 내용 저장
- ROLLBACK : 작업 취소
출처 : 2024 유선배 SQL개발자 과외노트
#4. Join on 과 where의 차이점

미션 과제
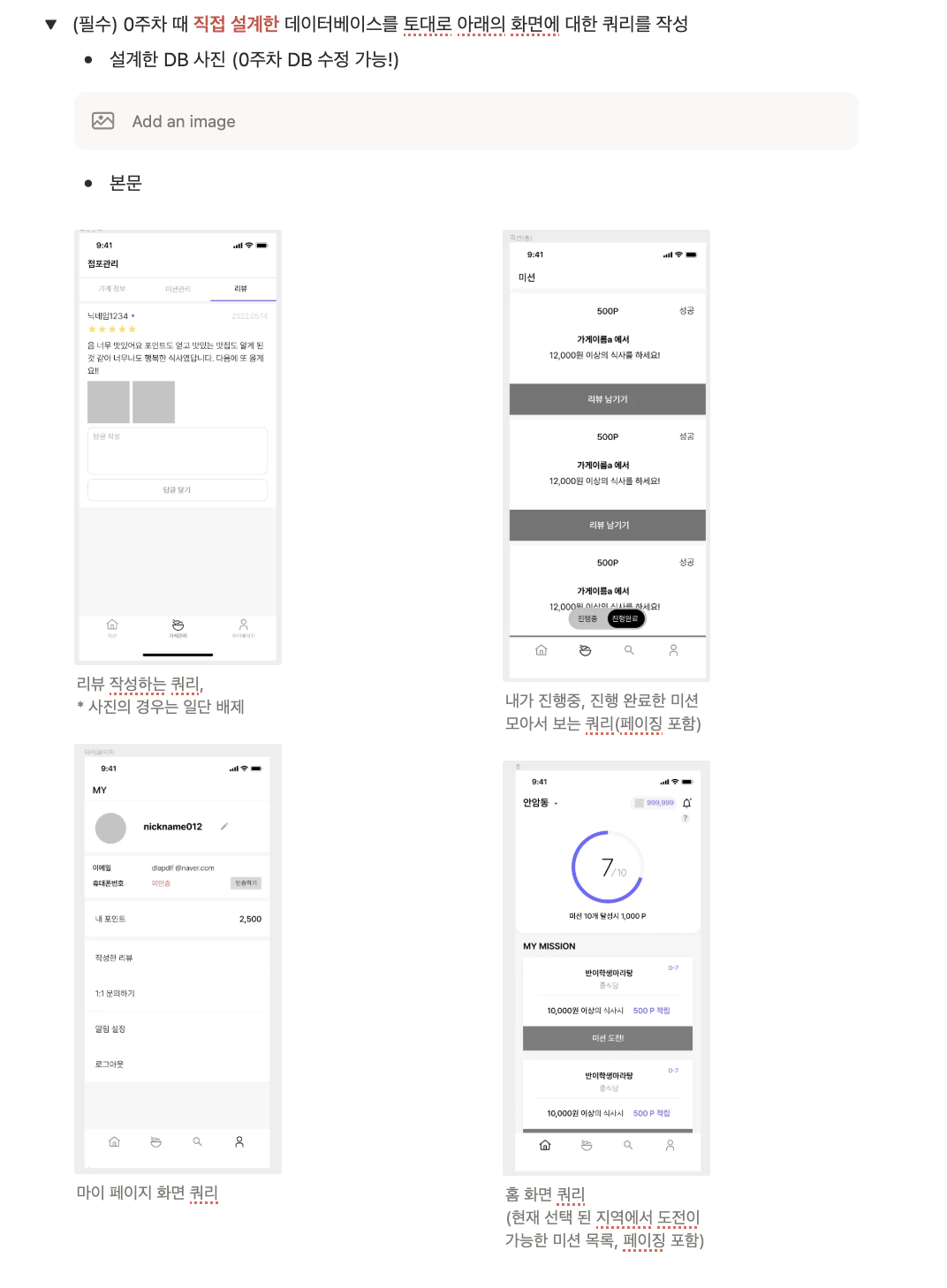
1) 리뷰 작성하는 쿼리
0주차 과제에서 리뷰작성 관련한 table은 만들지 않았어서
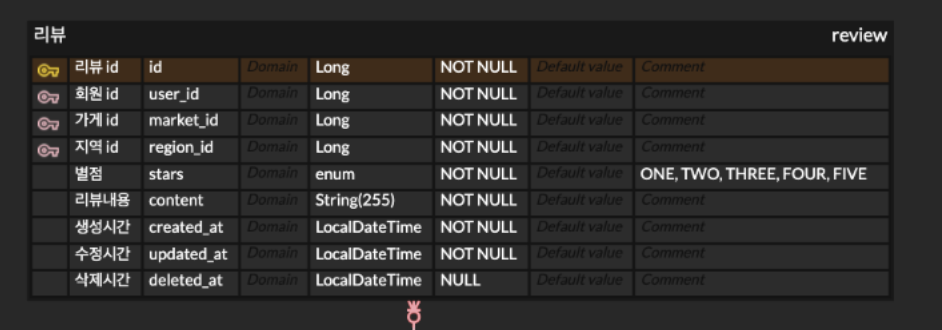
해당 리뷰 작성 화면에서 필요한 data를 기준으로 review table 작성했습니다.
INSERT INTO review (
user_id,
market_id,
stars,
content,
created_at,
updated_at,
deleted_at
)
VALUES (
'닉네임1234',
?,
'FIVE',
'음 너무 맛있었어요 포인트도 얻고 맛있는 맛집도 알게 된것 같아 너무나도 행복한 식사였답니다. 다음에 또 올게요!!',
NOW(),
NOW(),
NULL
);2) 내가 진행중, 진행완료한 미션 모아보는 쿼리 (페이징포함)
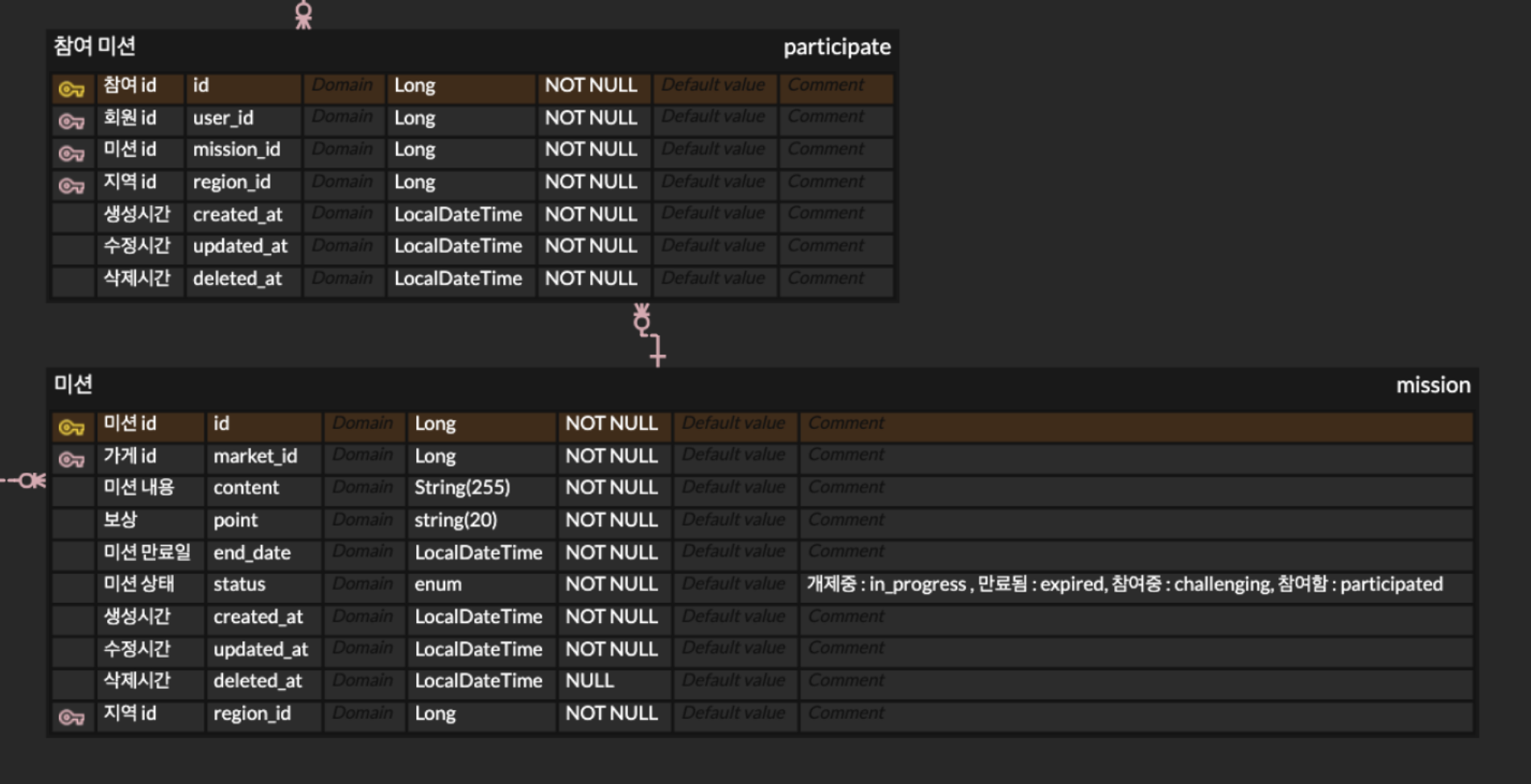
쿼리를 작성하려고 보니까, 테이블 정의상 status 는 mission 테이블에 있다.
mission.status
-- in_progress / expired / challenging / participated그런데 의미를 보면
- in_progress : 미션 자체가 게시중
- expired : 미션 자체가 만료됨
- challenging : 내가 진행중
- participated : 내가 완료함
이 중 뒤의 두 개는 유저별 상태라서
같은 미션이라도 어떤 유저는 아직 참여 안 했고, 어떤 유저는 진행 중이고, 어떤 유저는 완료했을 수 있기 때문에 participate 테이블에 있는 게 더 자연스러울거 같다는 생각이 들어서 수정했다.
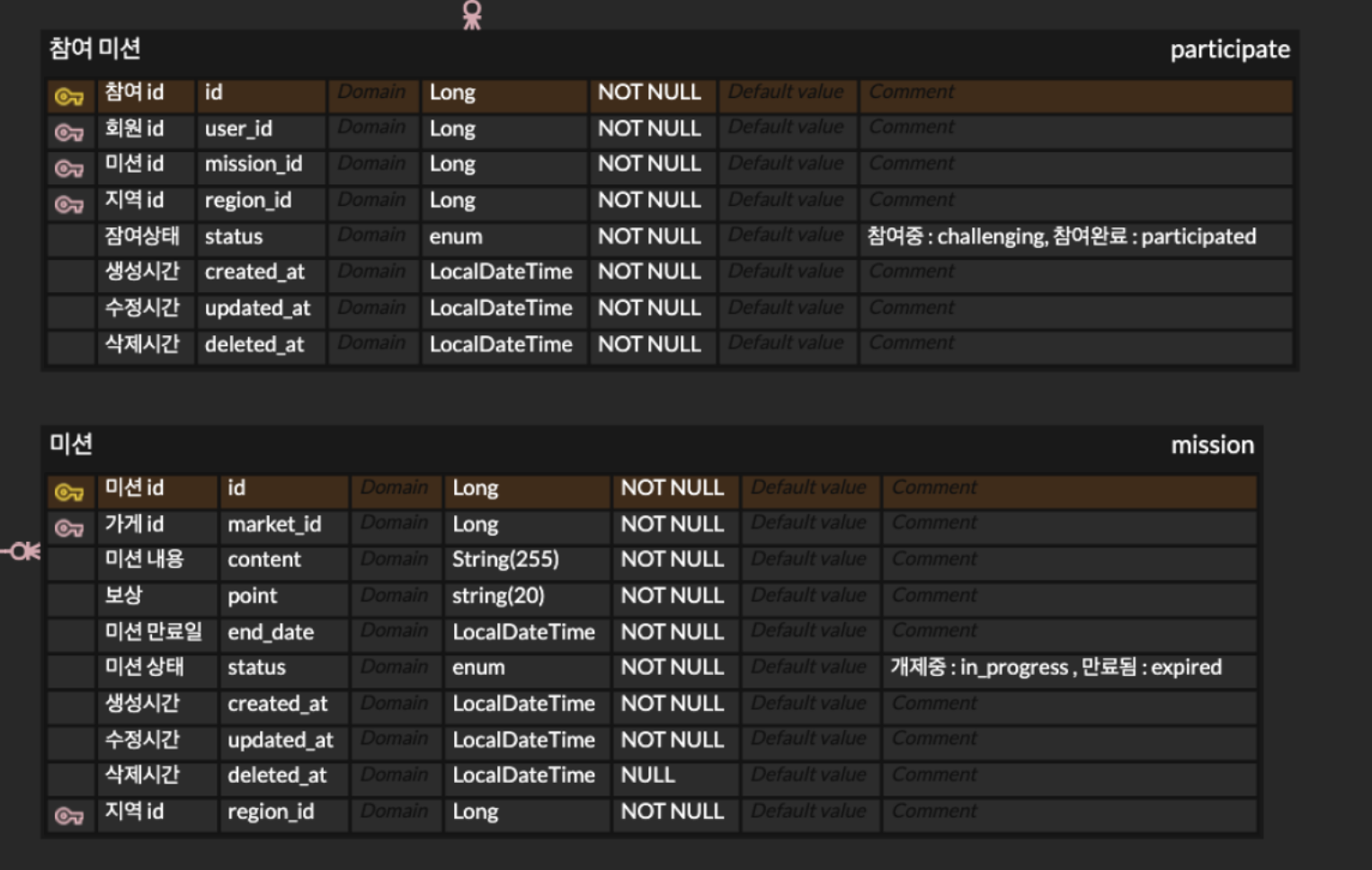
SELECT
m.id AS mission_id,
m.content,
m.point,
m.end_date,
mk.id AS market_id,
mk.name AS market_name,
CASE
WHEN p.status = 'challenging' THEN '진행중'
WHEN p.status = 'participated' THEN '진행완료'
END AS mission_status,
p.created_at AS participate_created_at
FROM participate p
JOIN mission m ON p.mission_id = m.id
JOIN market mk ON m.market_id = mk.id
WHERE p.user_id = ?
AND p.status IN ('challenging', 'participated')
AND p.deleted_at IS NULL
AND m.deleted_at IS NULL
AND mk.deleted_at IS NULL
ORDER BY p.created_at DESC
LIMIT 10 OFFSET 0;3) 마이 페이지 화면 쿼리
SELECT
name AS nickname,
email,
phone_number,
phone_number_status,
user_point
FROM user
WHERE id = 1
AND deleted_at IS NULL;4) 홈 화면 쿼리 (현재 선택된 지역에서 도전이 가능한 미션 목록, 페이징 포함)
SELECT
mk.id AS market_id,
mk.name AS market_name,
m.point,
m.content,
m.end_date
FROM mission m
JOIN market mk
ON m.market_id = mk.id
JOIN region r
ON mk.region_id = r.id
WHERE r.name = ?
AND m.status = 'in_progress'
AND m.deleted_at IS NULL
AND mk.deleted_at IS NULL
ORDER BY m.created_at DESC
LIMIT 10 OFFSET 0;📌 마무리
이번 1주차에서는 ERD를 기반으로 요구사항을 SQL 쿼리로 풀어내는 과정을 경험했다.
특히 JOIN을 활용한 다중 테이블 조회,
서브쿼리와의 차이,
그리고 페이징 처리 방식까지 다루면서
단순 조회를 넘어서 실제 서비스에서 필요한 형태의 쿼리를 구성하는 방법을 이해할 수 있었다.
다음 주차에서는 한 단계 더 나아가,
리소스 중심의 RESTful 설계가 무엇인지 이해하고,
API 명세서를 작성하는 과정을 통해
DB 설계와 쿼리를 실제 API로 연결하는 흐름을 학습할 예정이다.
