
오늘은 DB쪽에 연관되어있는 것들이 상당히 많이 나왔는데, 그 부분이 상당히 재밌어서 올려본다.
데이터를 다루는 것이 즐겁다고 느끼고 있는데 데이터 다루는 개발자 되고싶다했더니
형이 대학교 다시 가라고 석사는 따야 써준다고(....)
공부안한게 죄가 맞지.. 그래..
Trigger
트리거는 어제 gcp에서 썸네일을 만들때도 사용했던 용어다.
특정한 작업이 벌어졌을 경우 그것이 방아쇠가 되어서 추가적인 작업을 해주는 것을 이야기한다.
내가 장바구니 API를 짜고 있었을 때
물건을 등록하면 할인률이 적용된 1개의 상품에 대한 정보가 자연스럽게 업데이트가 되었는데
이것 또한 트리거라고 이야기를 할 수도 있다.
하지만 지금 설명하는 트리거는 위에 이야기하는 것보다는 가벼운 정보 를 다룰 때 사용한다.
트리거자체는 typeorm에서 자체적으로 클래스를 지원해주고 있어서, 그것을 사용하면 손쉽게 사용할 수 있다.
하지만, 혼자 개발을 하는 경우라면 로직을 전부 이해를 하고 있기에 문제가 되지 않지만
여러명이 개발을 하는 경우에는 어떤 조건에 트리거가 발생하는지 알 수 없기 때문에
(주석을 달아놓는다고 해도, 졸리면 못볼테니까)
또한 트리거가 만약에, 아주 만약에 고장이 날 경우에는 직접적으로 DB에 넣어줘야하는
중요한 정보를 저장을 하는 것에는 사용하지 않는 것이 좋고
트리거를 활용하는 것은 데이터를 기반으로 BM을 짠다거나,
회사 입장에서 추가적인 수익을 낼 수 있는 상황을 만드는로그를 만들 때 사용하는 것을 추천한다고 하였다.
일단 사용 자체는
@EventSubscriber() export class ProductSubscriber implements EntitySubscriberInterface<Product> { constructor(connection: Connection) { connection.subscribers.push(this); // 디비랑 연결 } // Product 테이블을 읽는다 listenTo() { return Product; } afterInsert( // event: InsertEvent<Product>, ) { // event 속에는 위의 기준으로는 디비에 저장된 값들이 담겨져있다. } }
이런 모영으로 활용을 하게 된다.
EntitySubscriberInterface 이부분이 TypeOrm에서 자체적으로 지원해주는 트리거 클래스다.
클래스를 눌러서 속에 뭐가 있는지 확인을 해보면
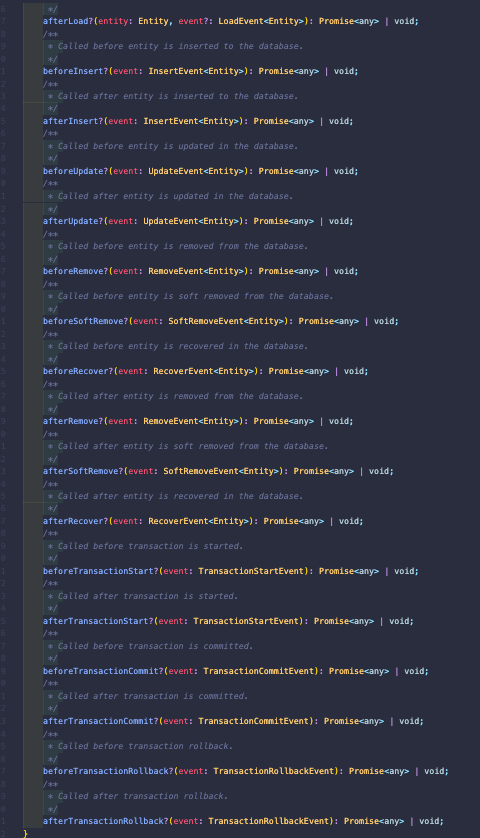
읽고난 후
작성 전
작성 후
업데이트 전
업데이트 후
삭제 전
소프트 삭제 전
삭제 취소 전
트랜지션 시작 전
등등등 우리가 평소에 생각할 법한 것들에 조건들 다 달아놓아서, 필요할 때 활용하면 엄청 편하게 쓸 수 있다고 생각한다.
만약 혼자 짠다고 하면 괜히 클래스에 이것저것 덧붙여야해서 코드가 저세상 길이로 가는 것보다는
이렇게 트리거를 만들어주는 쪽이 더 좋은 것 같다. (내 생각에는)
일단 활용법은 내 딴에는 엄청 편한 것 같은데
일단 이름은 자기 멋대로 지어주고
afterInsert(event: InsertEvent<Product>){}
변수 이름을 짓고서 그것에 원하는 클래스를 불러온 후,
제네릭타입에 해당하는 Entity를 넣은 다음에 활용하는 방식이다.
event 속에는 무엇이 들어있냐면
DB에 저장된 정보가 고스란히 똑같이 들어있다.
그래서 그것을 활용하여 작업을 하면 상당히 편리하게 작업을 할 수 있을 것 같다.
생각해보면 위에 트랜지션 커밋 후 라는 것도 존재하는데
저 속에 이벤트는 정말 다양한 것이 들어가있을 것 같아서 이것저것 선언을 여러번 하지 않고,
한번에 이벤트로 전부 다 땡겨와서 작업을 하면 상당히 편해질 것 같다는 생각이 든다.
Bigquery?
위에 설명한 트리거를 이용하여 하나하나 로그 (매우 중요하진 않지만, 있으면 활용할 수 있는 것)를 쌓을 수 있을 것이다.
하지만 서비스가 길어질수록 혹은 사용자가 엄청 많아질수록 로그는 기하급수적으로 쌓이게 되는데
데이터를 다루는 것은 돈이고 그것을 실제로 서비스를 하고 있는 DB에 담는 경우에는 더 중요한 데이터를 담아야하는데
활용을 해야만 쓸 수 있는 로그가 쌓이는 것은 의미가 없을 것이다.
그래서 빅쿼리 라는 것이 있는데 그런 로그를 담기 좋은 서비스가 존재한다.
구글에서 서비스를 하고 있고, 페타바이트(사실상 어지간한 회사에서는 사용 불가능)의 데이터를 다룰 수 있게 해준다.
자세한 것은 구글의 문서를 링크를 달아놓고, 이 글에서는 nest에서 쓰는 법을 이야기하려고 한다.
https://cloud.google.com/bigquery
일단 이것을 사용하기 위해서는 @google-cloud/bigquery 라이브러리를 깔아야 사용할 수 있다.
https://www.npmjs.com/package/@google-cloud/bigquery
사용법은 구글 스토리지랑 비슷한 형식으로 사용을 할 수 있는데

이렇게 설정을 해놓은 후
생성한 프로젝트에 들어가서 데이터세트 (일반적으로 생각하는 DB)를 생성하고
데이터세트에서 테이블 (말 그대로 테이블)을 생성을 한 후
자신이 저장하고 싶은 내용과, 타입을 담은 스키마를 적어넣어준다.
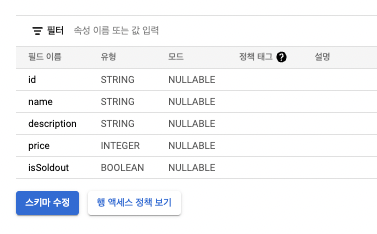
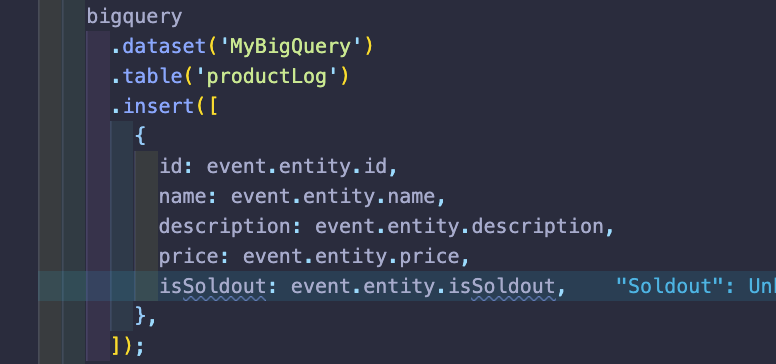
그 후 bigquery.dataset(본인이 생성한 데이터세트이름).table(테이블이름).insert([{자신이 넣고 싶은 값들}])을 넣으면 값이 들어가는 것을 확인할 수 있다.
위의 스크린샷에서는 event라고 적혀있는데 이것은 상단에 설명하고 있는 트리거에서 발생한 이벤트값을 사용한 것이다.
만약 검색, 판매로그같은 것을 확인해서 BM에 적용을 할 때 사용해볼 법 한 시스템인 것 같다.
왜냐하면 검색과 판매는 언제나 시장의 유행을 따라가기 때문에 한번쯤은 다뤄보고 싶다.
