
무언가 검색을 하기 위해서는 키워드가 필요하다.
하지만 그 키워드를 찾기 위해서는 모든 것을 찾아서 해당 결과를 도출하다보니 속도가 느려질 수 밖에 없다.
그래서 조금 더 빠르게 하기 위하여 해당하는 값에 추가적인 요소를 넣은 것을 인덱스 라고 한다.
Index
배열에서 사용하는 인덱스도 결국은 특정한 무언가를 지목하기 위해서 사용을 하는데,
DB에서 또한 같은 의미로 사용된다.

즉 특정한 값에 그것을 가리키는 값을 추가적으로 넣어서, 색인하는 속도(검색하는 속도)를 비약적으로 빠르게 만들 수 있다.
기본적으로 인덱스는 PK,FK,Unique한 값에 기본적으로 달려있고, 추가를 하는 것도 가능하다.
하지만 위에 언급한 것처럼 값에 가리키는 고유의 값을 넣는 형식으로 되어있기 때문에
검색 속도는 상승할 수 있겠지만, 속도가 느려지는 경우도 발생할 수 있다는 단점이 있다.
그럼 인덱스가 있다는 것이 얼마나 큰 차이를 주는지 한번 확인해보자.
일단 모든 DB에는 DB Optimizer라는 개념이 존재한다.
무슨 말이냐면, 최적의 방식으로 검색을 할 것이다 라는 알고리즘이 적용이 되어있다고 볼 수 있다.
DB는 데이터를 저장하고, 읽어내기 위해 존재하기에 정말 정말 핵심인 기술이라고 볼 수 있다.
그리고 사용자는 그 검색하는 계획을 눈으로 직접 볼 수 있는데, 그것이 바로 Explain 명령어다.
이 명령어를 사용하는 방식은 매우 간단하다.
자신이 사용할 쿼리문 + explain을 맨 위에 덧붙여서 사용을 할 경우 어떤식으로 검색을 할 것인지 계획을 알려주는데
아래와 같은 사진처럼 보여준다.
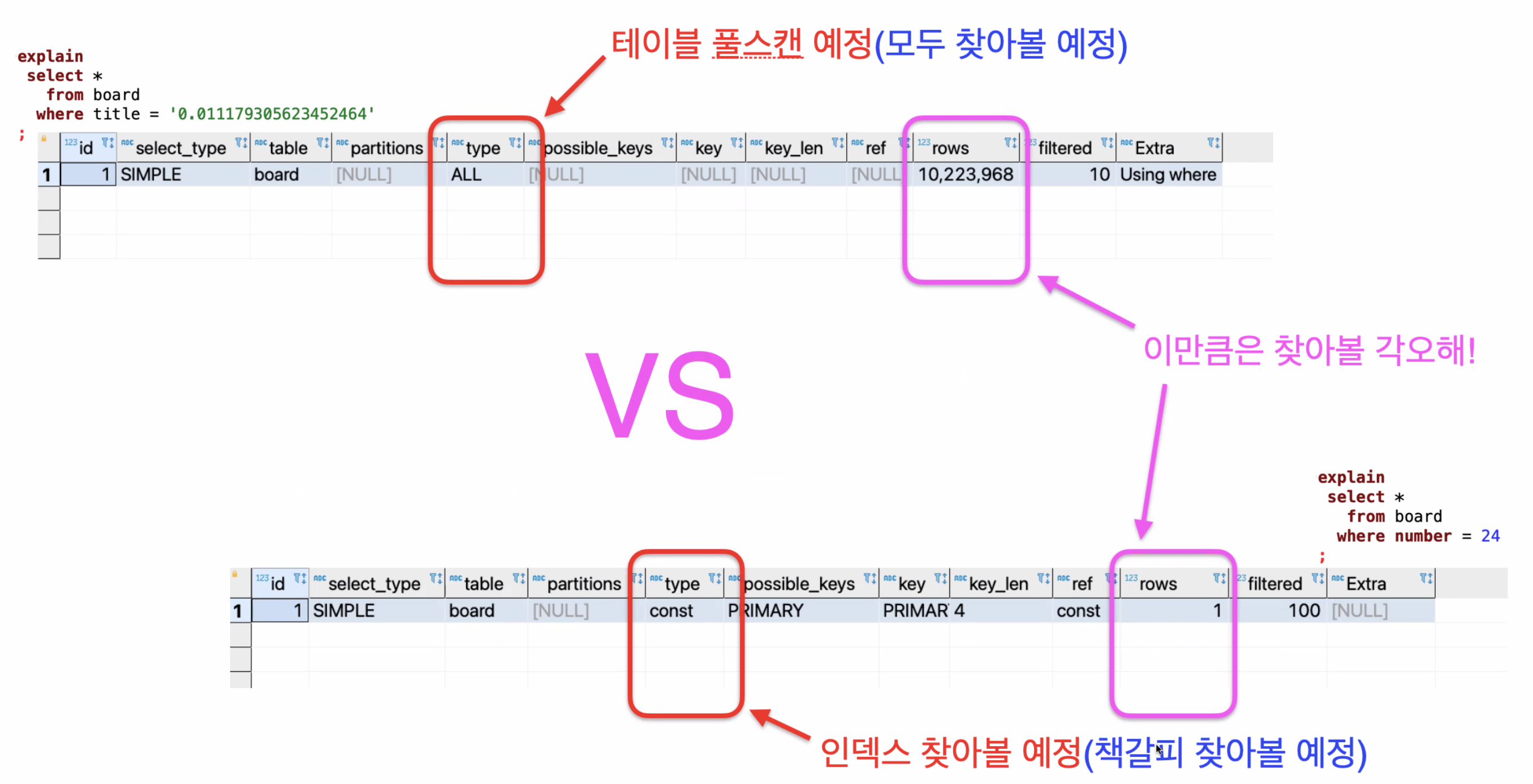
이 사진은 어떤 내용이 들어가있냐면
현재 데이터베이스의 값은 천만개가량이 들어가있는 상태고
위의 사진은 title이라는 일반 컬럼 중 한개의 값을 찾으려고 하는 것
아래 사진은 PK인 number의 한개의 값을 찾으려고 하는 상태이다.
사진에 설명이 워낙 잘되어있어서 추가로 덧붙일 내용이 많이 없는데,
일반 컬럼은 존재하는 모든 데이터를 다 뒤져봐야한다고 계획을 알려주고 있고
PK 컬럼은 딱 한개를 바로 보면 된다고 계획을 알려주고 있다.
이것은 관계형 데이터 베이스가 모두 가지고 있는 옵션이고, 이제 역색인을 사용하는 비관계형 데이터베이스
그리고 그것보다 더 나아간 램 기반 데이터베이스에 대해서 적어보려고 한다.
-> 끗
