무언가 구현을 하다보면 어딘가 있는 정보를 끌어와서 이용을 해야할 때가 있다.
그러한 행위를 스크래핑, 크롤링이라 부르는데
한번만 가져오는 것을 스크래핑
반복해서 가져오는 것을 크롤링이라고 부른다.
작업을 할 때 도움을 주는 라이브러리가 당연히 있고
스크래핑은 cheerio
크롤링은 Puppeteer 가 존재한다.
이게 뭔가? 라는 느낌도 있겠지만 우리는 모르는 사이에 이것을 이용하고 있다.
바로 채팅기능이 포함되어있는 앱(카톡,디코)에서 사이트의 링크를 걸 경우 미리보기가 제공이 되는 것을 볼 수 있는데
그 미리보기는 HTML 문서 중 HEAD태그 속에 있는 mete태그 속 og의 내용을 스크래핑으로 가져온 것이다.
이것은 페이스북에서 시작을 하긴 했지만 클라이언트(사용자)들에게 주는 만족감이 좋기 때문에 모든 사이트에서 활용을 하고 있다.
이제는 링크를 받았을 경우에 미리보기가 없으면 불안한 느낌을 느끼기도 하고, 특정 프로그램에서는 검증되지 않는 사이트라며 필터링을 해주는 곳도 존재한다.

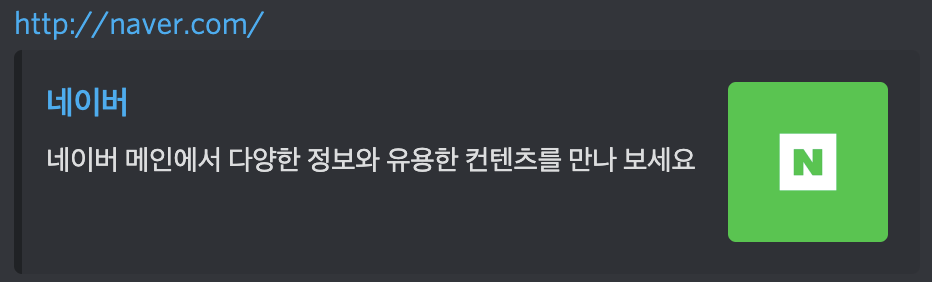
위에서 하는 작업은 프론트쪽에서 하는 것이고, 백엔드에서는 어떤식으로 활용을 하게 되는걸까?
사이트의 메인 홈페이지의 경우에는 프론트쪽에서 작업을 해주겠지만,
메인 홈페이지가 아닌 내용들이 언제나 바뀌는 페이지는 모두 작업을 해줄 수 없기 때문에
api로 자동화를 시켜주는 작업이 필요하다.

이렇게 특정 상품이 링크로 들어왔을 때, 내용의 일부만 가지고 구성을 해줘야할 경우 스크래핑을 활용하여
데이터의 일부로 사진과 링크 등의 정보들을 만들어서 클라이언트(사용자)에게 보낼 수 있다.
그렇다면 크롤링이라는 것은 무엇일까?
크롤링은 주기적으로 스크래핑을 한다고 생각하면 조금은 쉽게 생각할 수 있다.
그리고 특정 사이트의 정보를 주기적으로 가져오는 것이기에 그 사이트의 서버에 과부화를 줄 수 있기에 주의해야한다.
이러한 이유때문에 크롤링을 거부하는 곳도 있는데 주소창에 /robots.txt라고 치면
이 주소는 하지마라, 해도 된다 이런식으로 명시해놓은 파일이 존재한다.
그럼 어떻게 하면 할 수 있는걸까?
미니프로젝트가 거의 다 완성된 상태라서, 미니프로젝트의 코드를 가져와서 리뷰하는 방식으로 진행하려고 한다.
Cheerio를 이용한 스크래핑
import axios from "axios"; import Cheerio from "cheerio"; export async function ogGet(user) { user.includes("http") ? user : (user = "https://" + user); let obj = {}; const page = await axios.get(user); const $ = Cheerio.load(page.data); $("meta").each((_, el) => { if ($(el).attr("property")) { const key = $(el).attr("property").split(":")[1]; const value = String($(el).attr("content")); obj[key] = value; } }); return obj; }
내가 og태그에 들어가있는 내용을 담아오기 위해 작성한 내용이다.
- 스크래핑을 하기 위해서는 통신이 되어야하기 때문에 axios 임포트
- cheerio를 사용하기 위해 임포트
- user에는 주소가 담겨져 있는 상태로 인자를 받아오게 된다.
- https://가 없으면 실행이 안되길래 예외처리한 부분
- 새로 담아놓을 빈 객체를 선언
- axios로 HTML 문서를 통째로 들고온다
- Cherrio.load로 담아온 HTML(page)문서의 data만 뽑아내기
- 뽑아낸 data에서 meta라는 태그가 있는 곳의 값들을 each(반복문)으로 돌고
- 만약에 el의 속성중 property가 있다면
- 그 값을 split(":")으로 나눠서 1번 인덱스 (og:title이면 title만)을 key의 값에 저장
- el의 속성 중 content를 value에 저장 < 중요함 >
- 각각의 값을 키와 벨류 형태로 obj 객체에 저장
- 반환
여기서 크게 어려웠던 것은 별로 없었다. 근데 제일 큰 문제는 바로 주소였다.
그냥 작성을 해서 코드를 돌리면 url은 담아올 수 없다. 문자열의 형태로 바꿔라 라는 에러를 무한반복으로 내뱉는다.
저 에러를 잡는게 진짜 진짜 너무 오래걸렸는데 그냥 그 값에 강제 형변환으로 선언을 해주면 되는 것이더라...^^
아무튼 위와 같은 방식으로 사용했다.
pupperteer를 사용한 크롤링
import puppeteer from "puppeteer"; async function startCrawling() { const browser = await puppeteer.launch({ headless: true }); // 브라우저가 보이게 한다 const page = await browser.newPage(); // 새로운 브라우저 켜기 await page.goto(""); // 페이지 이동 await page.waitForTimeout(1000); for (let i = 1; i <= 10; i++) { // 반복문 돌면서 값 여러개 가져오기 await page.waitForTimeout(500); const img = await page.$eval(,(el) => el.src); const name = await page.$eval(,(el) => el.textContent); } }
- 퍼펫티어로 크롤링을 할거라서 임포트
- 브라우저를 보이게 하는 옵션인데 나는 볼 필요가 없어서 꺼놨다. 만약에 보고싶을 경우 headless : false로 적으면 된다
- 퍼펫티어는 직접 홈페이지에 들어가서 가져오는 형식이라 선언을 무조건 해야한다 // 크롬...뭐? 라는 브라우저를 사용한다
- goto()로 사이트에 접근
- 딜레이없이 계속 접근하면 서버 부하를 크게 줄 수 있어서 시간 조건을 넣어놨다
- 가져오고 싶은 값이 갯수가 10개라서 반복문으로 10번을 돌린다.
- 반복문을 돌면서도 또다시 시간 딜레이
- 가져오고 싶은 값이 이미지라서 el의 src 소스를 가져온다는 코드
- 가져오고 싶은 값이 텍스트라서 el의 textContent라는 코드
이런식으로 구성을 한다.
엄청 자기만의 메소드가 존재하고, js의 메소드들을 사용할 수 있게 하는 함수도 있기 때문에
사용하려고 마음을 먹으면 좀...많이 복잡할 것 같다.
