문제 상황
😭 K6 부하 테스트 중 Argo CD UI가 무한 로딩에 빠지고, kubectl 명령어가 모두 응답하지 않는 상황이 발생했습니다.
kubectl get pods -n argocd
^C # 명령어가 멈춤#1. 시스템 리소스 및 프로세스 상태 점검
📍 시스템 리소스 확인
top
free -h
df -h결과
CPU, 메모리(1.9GB/3.8GB), 디스크(19%) 모두 정상
📍 kubelet 상태 확인
systemctl status kubelet
● kubelet.service - kubelet: The Kubernetes Node Agent
Active: active (running)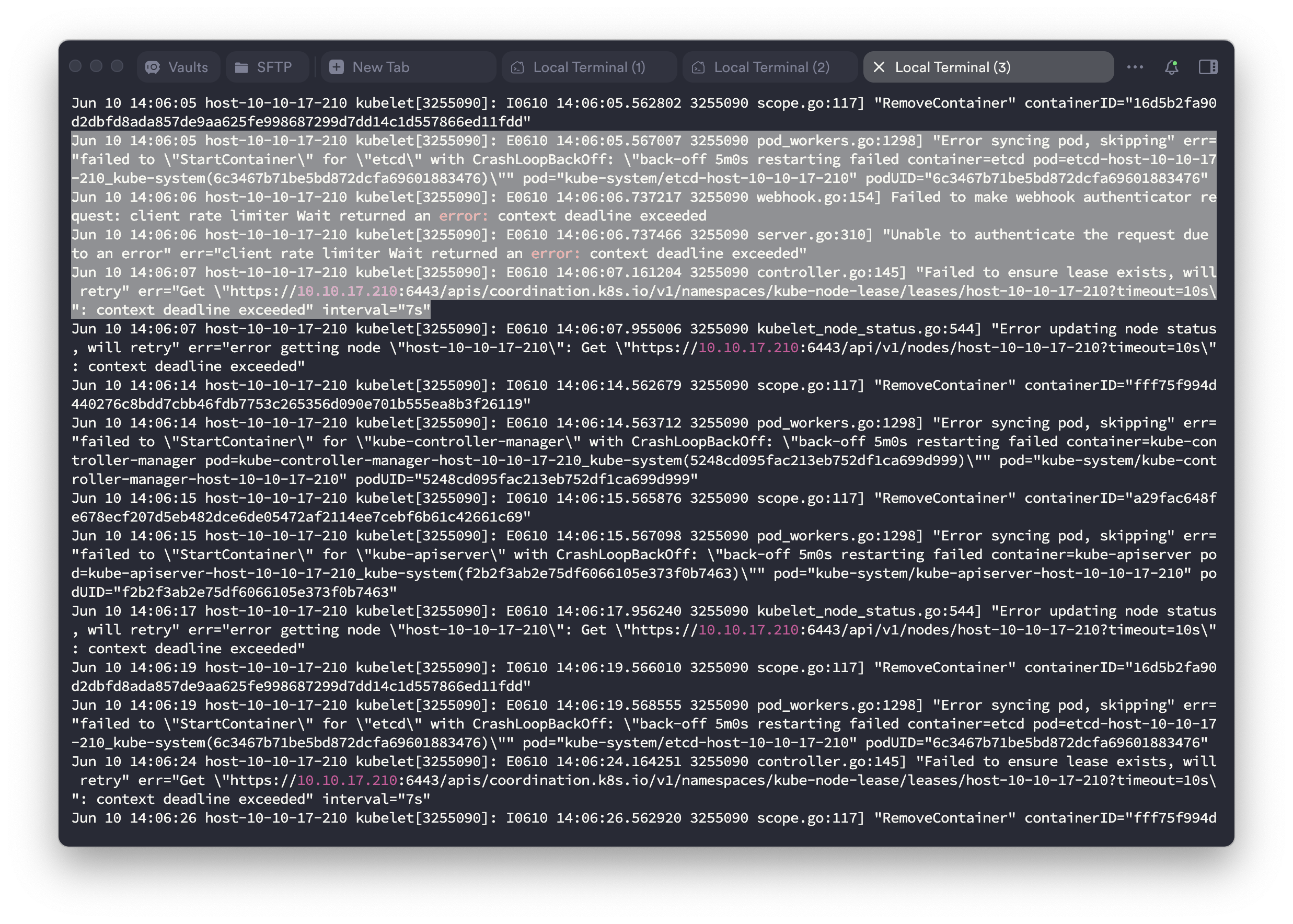
kubelet 서비스는 실행 중이지만, 로그에서 Error syncing pod 오류가 지속적으로 발생함
#2. API 서버 통신 확인
📍 kubelet 로그 메시지 확인
$ journalctl -u kubelet -f --lines=50
E0610 14:06:40.564210 kubelet[3255090]: Error syncing pod, skipping
E0610 14:06:41.167197 kubelet[3255090]: Failed to ensure lease existskubelet이 control plane의 lease를 확보하지 못해 pod 동기화를 건너뜀 → API 서버와의 통신 실패 가능성이 높음
📍 API 서버 포트 확인
$ sudo netstat -tlnp | grep 6443
tcp6 0 0 :::6443 :::* LISTEN 1040497/kube-apiserverAPI 서버는 포트 6443에서 정상적으로 리스닝 중임
📍 API 서버 Health Check
$ curl -k https://localhost:6443/healthz
[+]ping ok
[-]log failed: reason withheld
[-]etcd failed: reason withheld
healthz check failed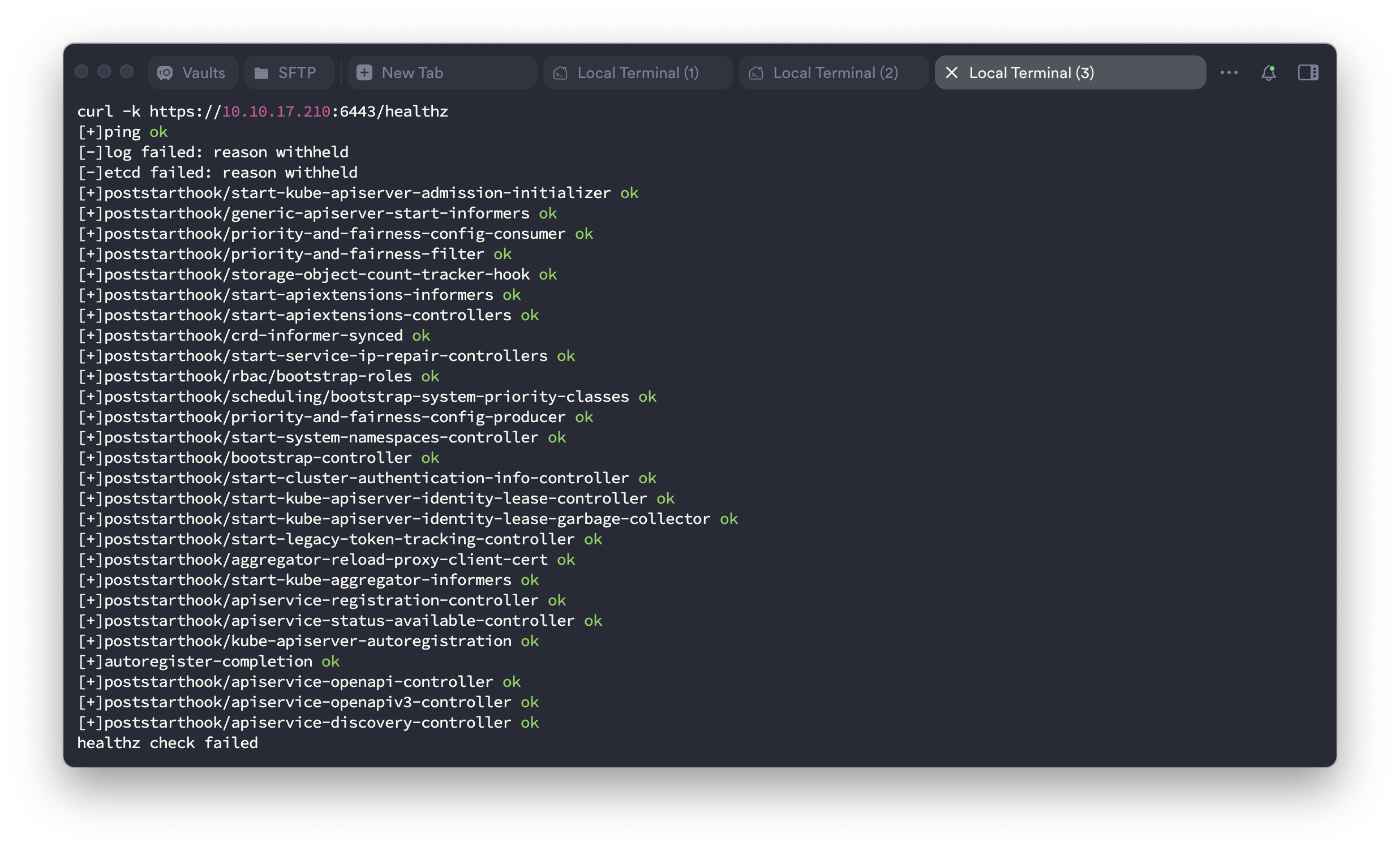
etcd 오류로 /healthz 체크 전체가 실패함 → API 서버는 떠 있지만 etcd와 연결되지 않아 정상 동작이 불가능한 상태
#3. etcd 포트 충돌 확인 및 해결
📍 etcd 로그 확인
$ sudo crictl logs $(sudo crictl ps -a | grep etcd | awk '{print $1}')
{"level":"fatal","ts":"2025-06-10T14:05:22.957668Z","caller":"etcdmain/etcd.go:204","msg":"discovery failed","error":"listen tcp 10.10.17.210:2380: bind: address already in use"}etcd가 바인딩하려는 포트 2380이 이미 사용 중이며, 이로 인해 etcd 프로세스가 시작에 실패함 → 포트 충돌 발생
📍 포트 점유 프로세스 확인 및 종료
$ sudo lsof -i :2380
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
etcd 20728 root 7u IPv4 59959 0t0 TCP host-10-10-17-210:2380 (LISTEN)$ sudo kill -9 20728좀비 상태로 남아 있던 etcd 프로세스를 강제 종료하여 포트 충돌 해결
📍 상태 확인
$ journalctl -u kubelet --since "10 minutes ago" | grep -i etcd
Error syncing pod, skipping err="failed to StartContainer for etcd with CrashLoopBackOff"좀비 프로세스 종료 후에도 etcd는 여전히 정상적으로 실행되지 않으며, CrashLoopBackOff 상태가 지속됨
#4. CrashLoopBackOff 및 볼륨 마운트 문제
📍 static pod 재시작 시도
$ sudo mv /etc/kubernetes/manifests/etcd.yaml /tmp/
$ sleep 30
$ sudo mv /tmp/etcd.yaml /etc/kubernetes/manifests/$ journalctl -u kubelet -f --lines=20
Error syncing pod, skipping err="unmounted volumes=[etcd-certs etcd-data], unattached volumes=[], failed to process volumes=[]: context deadline exceeded"etcd static pod를 잠시 제거했다가 다시 배치하여 재시작을 시도했지만, 여전히 kubelet 로그에 오류 발생
특히 etcd뿐만 아니라 다른 static pod들까지도 etcd-certs, etcd-data 등의 볼륨을 정상적으로 마운트하지 못해 컨테이너가 실행되지 않는 상태 발생
📍 containerd 및 kubelet 재시작
$ sudo systemctl restart containerd
$ sudo systemctl restart kubelet😢 container runtime과 kubelet을 재시작했으나, CrashLoopBackOff 상태는 지속됨
#5: kubelet 캐시 클리어 및 초기화
📍 캐시 삭제 및 매니페스트 임시 이동
$ sudo systemctl stop kubelet
$ sudo mv /etc/kubernetes/manifests/*.yaml /tmp/
$ sudo rm -rf /var/lib/kubelet/pods/*
$ sudo systemctl start kubeletkubelet 캐시를 초기화하고 static pod 매니페스트를 임시로 이동시켜 문제를 일시적으로 제거하려 했으나, /tmp/ 디렉토리에 옮겨둔 YAML 파일들이 없어짐 . . .
📍 캐시 삭제 및 매니페스트 임시 이동
$ ls -la /etc/kubernetes/manifests/
total 8
drwxrwxr-x 2 root root 4096 Jun 10 14:19 .
drwxrwxr-x 4 root root 4096 May 31 05:25 ..
-rw-r--r-- 1 root root 0 Mar 11 18:34 .kubelet-keep
$ ls -la /tmp/*.yaml
ls: cannot access '/tmp/*.yaml': No such file or directorystatic pod 매니페스트가 사라지면서 control plane이 완전히 중단된 상태 발생
#6: kubeadm으로 Control Plane 재생성
📍 Control Plane static pod 재생성
$ sudo kubeadm init phase control-plane apiserver
[control-plane] Creating static Pod manifest for "kube-apiserver"
$ sudo kubeadm init phase control-plane controller-manager
[control-plane] Creating static Pod manifest for "kube-controller-manager"
$ sudo kubeadm init phase control-plane scheduler
[control-plane] Creating static Pod manifest for "kube-scheduler"
$ sudo kubeadm init phase etcd local
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"📍 매니페스트 생성 확인
$ ls -la /etc/kubernetes/manifests/
total 24
-rw------- 1 root root 2416 Jun 10 14:27 etcd.yaml
-rw------- 1 root root 3883 Jun 10 14:26 kube-apiserver.yaml
-rw------- 1 root root 3280 Jun 10 14:26 kube-controller-manager.yaml
-rw------- 1 root root 1464 Jun 10 14:26 kube-scheduler.yaml#7: kubelet 재시작 및 클러스터 복구 확인
$ sudo systemctl restart kubelet
$ sleep 30
$ sudo crictl ps -a
CONTAINER IMAGE STATE NAME
2904a005879f3 a9e7e6b294baf Running etcd
a40780efbde14 f44c6888a2d24 Running kube-apiserver
ec24630fdf71d b0cdcf76ac8e9 Running kube-controller-manager
bb00acb520737 9ea0bd82ed4f6 Running kube-scheduler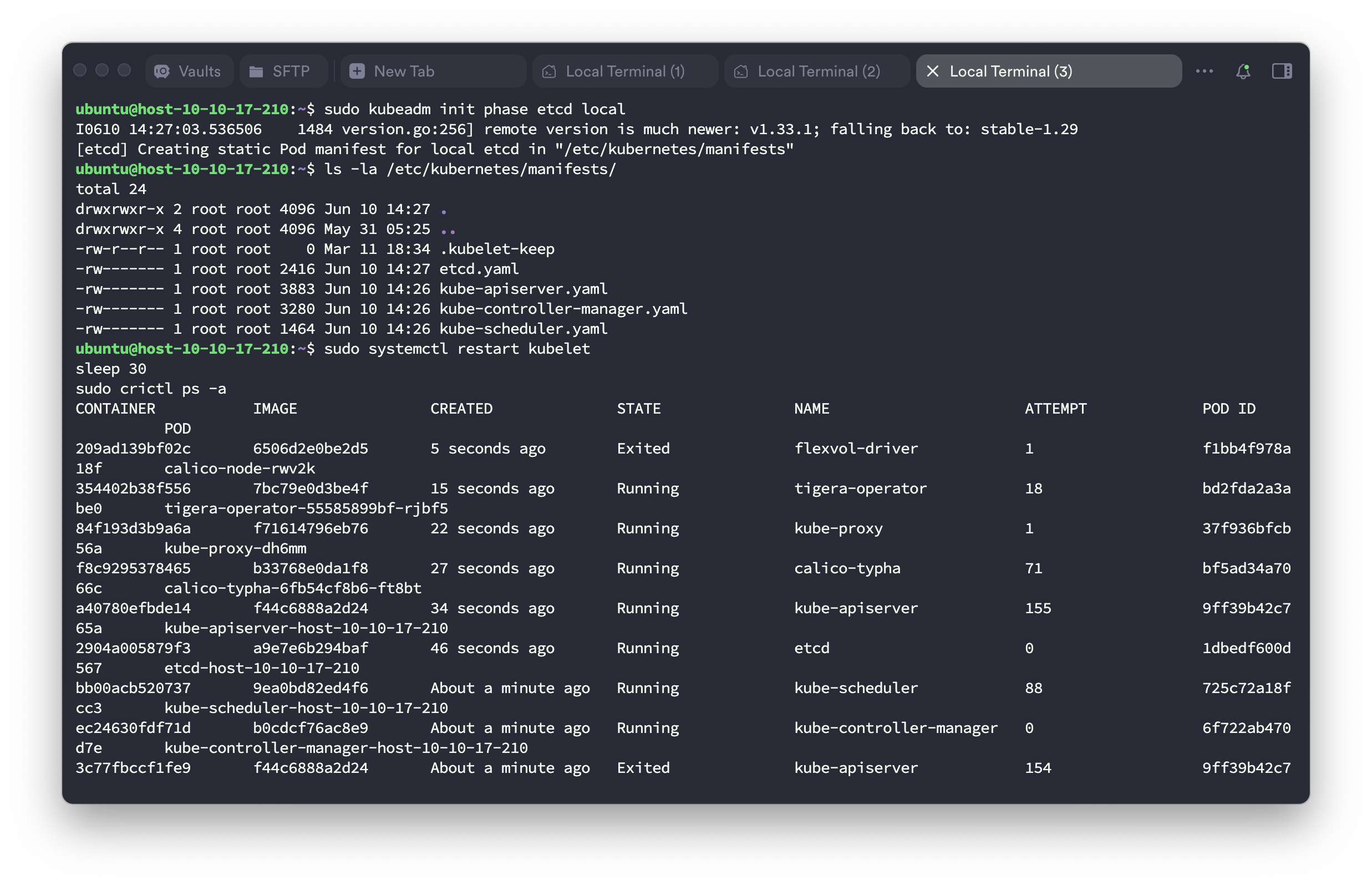
🥳 클러스터 복구 확인
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
host-10-10-16-149 Ready <none> 23h v1.29.15
host-10-10-16-248 Ready <none> 3d3h v1.29.15
host-10-10-17-210 Ready control-plane 10d v1.29.15
host-10-10-17-228 Ready <none> 5d1h v1.29.15
host-10-10-17-253 Ready <none> 10d v1.29.15
host-10-10-19-191 Ready <none> 10d v1.29.15
$ kubectl get pods -n kube-system
NAME READY STATUS RESTARTS
etcd-host-10-10-17-210 1/1 Running 0
kube-apiserver-host-10-10-17-210 1/1 Running 155 (73s ago)
kube-controller-manager-host-10-10-17-210 1/1 Running 0
kube-scheduler-host-10-10-17-210 1/1 Running 88 (7m37s ago)마무리
이번 장애는 단순히 kubectl 명령이 멈춘 문제가 아니라, etcd의 포트 충돌로 시작된 control plane 전체 장애였습니다.
📌 왜 이런 일이 발생했을까?
1) etcd란?
etcd는 Kubernetes의 핵심 데이터 저장소입니다. 클러스터의 모든 상태 정보(노드, 파드, 서비스 등)가 etcd에 저장되며, control plane 구성요소들은 etcd와 실시간으로 통신합니다. etcd가 정상적으로 작동하지 않으면, API 서버를 비롯한 control plane 전체가 제대로 동작하지 않습니다.
2) Static Pod란?
Static Pod는 일반 pod와 달리 kubelet이 직접 실행하고 관리하는 특수한 형태의 pod입니다. etcd, kube-apiserver, controller-manager, scheduler와 같은 control plane 구성요소들이 여기에 해당합니다.
주요 특징
- /etc/kubernetes/manifests/ 디렉토리에 YAML 파일이 존재하면, kubelet이 자동으로 컨테이너 실행
- API 서버를 거치지 않고 로컬에서 직접 관리
- 컨테이너가 중단되면 즉시 재시작 시도
- kubectl delete로는 삭제되지 않으며, YAML 파일을 지워야 중단 가능
3) 포트 충돌의 근본 원인
이번 문제는 다음과 같은 상황이 동시에 겹쳐 발생한 것으로 생각이 됩니다.
- K6 부하 테스트로 control plane에 과부하가 발생
- etcd가 비정상 종료 되었지만, 프로세스가 완전히 정리되지 않음
- containerd 또는 시스템 재시작 과정에서 etcd가 좀비 상태로 남으며 포트 2380을 점유
- kubelet은 etcd 매니페스트(/etc/kubernetes/manifests/etcd.yaml)를 계속 감지하여 재시작 시도
- 포트가 이미 사용 중이라 새 컨테이너가 실행에 실패 → CrashLoopBackOff 상태 발생
