들어가며
이 글은 Kubernetes의 내부 로직, 특히 클러스터와 Control Plane이 어떤 역할로 동작하는지를 정리하기 위해 작성했습니다.
🔗 https://kubernetes.io/docs/concepts/architecture/
Kubernetes 클러스터
Kubernetes 클러스터는 크게 두 영역으로 구성됩니다.
- Control Plane: 클러스터 전체의 상태를 관리하고 전반적인 동작을 결정하는 영역
- Worker Node: 실제 애플리케이션 워크로드(Pod)가 스케줄링되고 실행되는 영역
✏️ Pod를 실행하려면 최소 1개의 Worker Node가 반드시 필요합니다.
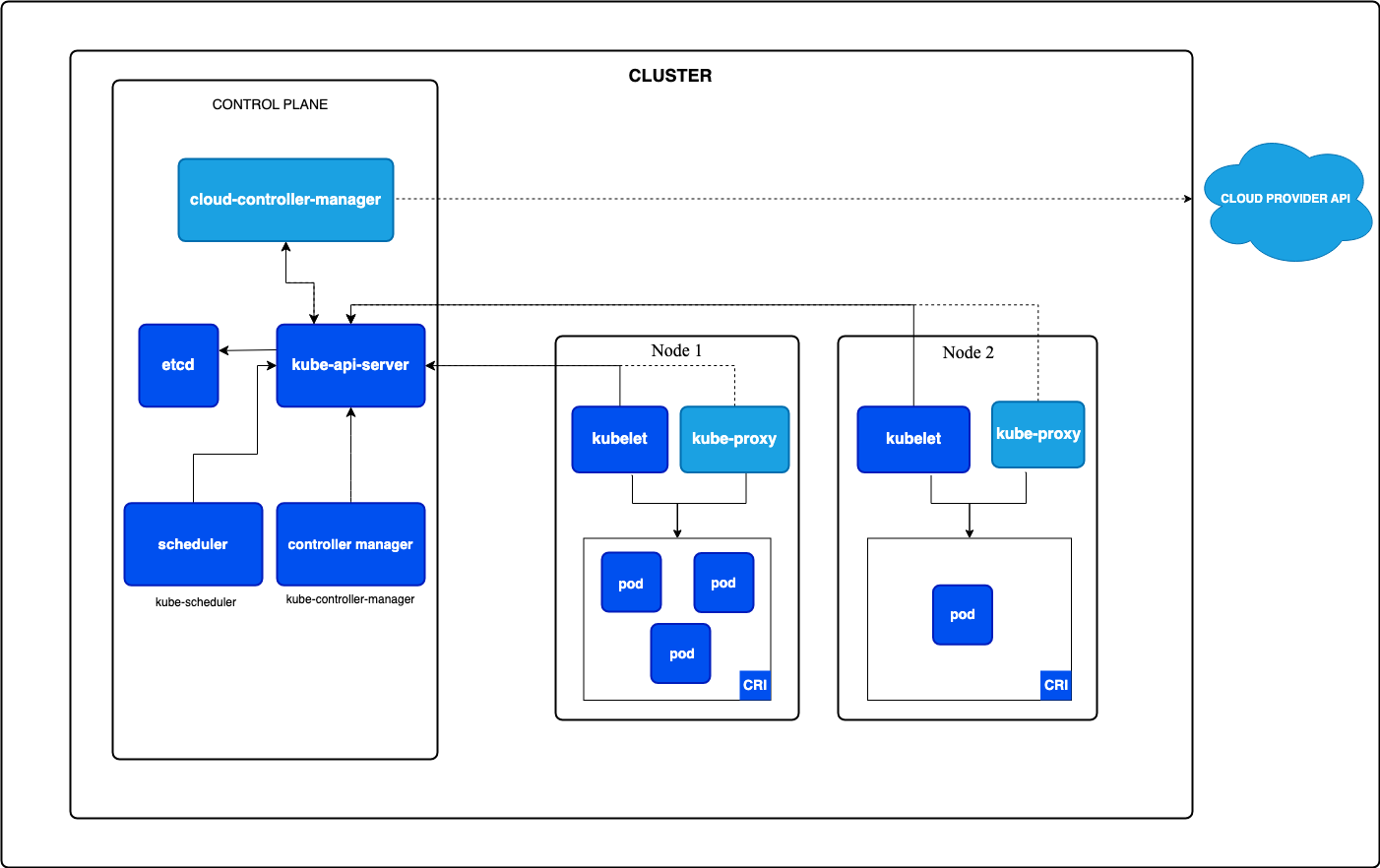
Control Plane
Control Plane은 클러스터의 Desired State를 관리하는 영역입니다. 여러 컨트롤러는 현재 클러스터 상태를 지속적으로 감시하고, 사용자가 선언한 상태와 차이가 발생하면 이를 맞추도록 조정합니다.
주요 구성요소
-
kube-apiserver: Kubernetes API를 외부와 내부에 노출하는 컴포넌트입니다. kubectl을 비롯한 모든 클라이언트와 다른 Control Plane/Node 컴포넌트는 kube-apiserver를 통해 상호작용합니다.
-
etcd: 클러스터의 모든 상태 데이터를 저장하는 일관성 있는 고가용성 키-값 저장소입니다. Control Plane 컴포넌트는 etcd에 저장된 데이터를 기준으로 클러스터 상태를 판단하고 조정합니다.
-
kube-scheduler: 아직 노드가 할당되지 않은 새로운 Pod를 감시하고, 리소스 요구사항, 제약 조건, affinity/anti-affinity 등을 고려해 적절한 노드를 선택합니다.
-
kube-controller-manager: 여러 종류의 컨트롤러를 하나의 프로세스로 실행하는 컴포넌트입니다. 예를 들어 Node 컨트롤러, Job 컨트롤러 등이 있으며, 각각 특정 리소스의 현재 상태가 Desired State를 만족하도록 지속적으로 조정합니다.
1) 노드 간 Pod 트래픽 흐름
쿠버네티스는 IP-per-Pod 모델을 사용합니다. 각 Pod는 고유한 IP 주소를 할당받으며, CNI 플러그인이 노드 간 라우팅을 구성해 NAT 없이 Pod 간 직접 통신이 가능하도록 합니다.
Service는 이 Pod들 앞에 고정된 주소를 하나 제공하고, 해당 주소로 들어온 요청을 여러 Pod 중 하나로 연결해 줍니다.
1. Service 이름으로 요청
애플리케이션은 Service 이름을 통해 통신합니다. 어떤 Pod가 선택되고 트래픽이 어떻게 전달되는지는 쿠버네티스가 내부적으로 처리합니다.
2. DNS 조회로 ClusterIP 확인
클러스터 DNS는 Service 이름에 대응하는 ClusterIP를 반환합니다. 이 ClusterIP는 노드의 네트워크 인터페이스나 라우팅 테이블에 실제로 존재하지 않는, Service를 위해 정의된 논리적인 가상 IP입니다.
3. Pod에서 노드 네트워크로 전달
DNS 해석 이후, Pod는 목적지 주소를 ClusterIP로 설정한 패킷을 생성합니다. 이 패킷은 Pod의 veth 인터페이스를 통해 노드 브리지로 전달됩니다.
4. Service IP -> Pod IP 변환
각 노드에서 동작하는 kube-proxy는 Service 및 Endpoint 변경을 감지해 이에 대응하는 iptables 규칙을 사전에 구성해 둡니다.
패킷이 노드 커널의 netfilter 체인을 통과하는 과정에서 Service의 ClusterIP에 매칭되는 규칙이 적용되고, 목적지 주소는 실제 Pod의 IP와 포트로 DNAT 됩니다.
5. CNI를 통한 노드 간 라우팅
DNAT가 완료된 패킷은 커널 라우팅 테이블을 기준으로 전달됩니다. 목적 Pod가 다른 노드에 위치한 경우, 패킷은 CNI 플러그인이 구성한 Pod CIDR 경로를 따라 해당 노드로 전달됩니다.
6. 대상 Pod로 최종 전달
패킷은 대상 노드의 네트워크 인터페이스로 유입된 뒤, 브리지와 veth 인터페이스를 거쳐 최종적으로 목적 Pod에 전달됩니다.
📍 kube-proxy의 역할
kube-proxy는 패킷을 직접 전달하거나 중계하지 않습니다. iptables 모드에서는 Service 및 Endpoint 변화에 따라 iptables 규칙을 사전에 구성하며, 실제 패킷 처리는 리눅스 커널이 수행합니다.
Service를 통한 노드 간 Pod 트래픽 흐름 예시
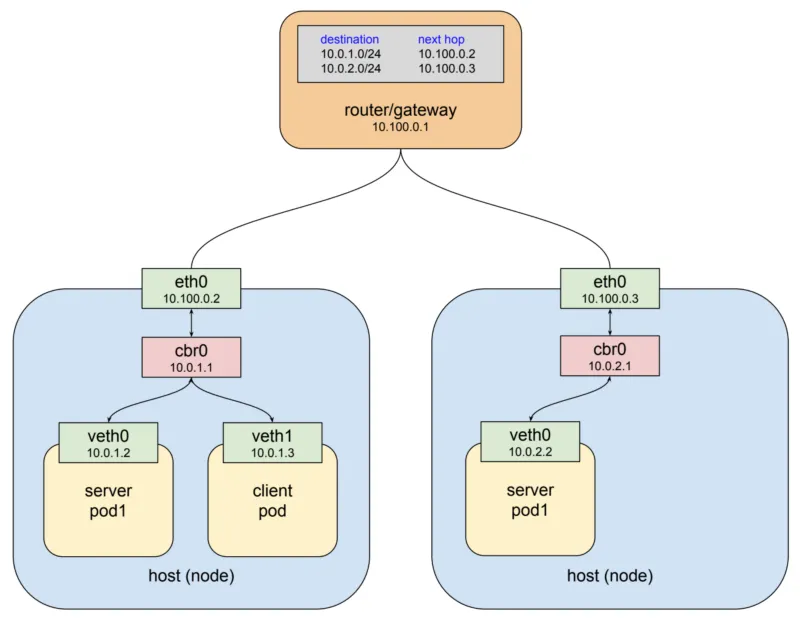
시나리오 설정
- client pod IP: 10.0.1.3
- server pod IP: 10.0.2.2
- Service 이름: example.default.svc.cluster.local
- ClusterIP: 10.96.123.45
1. Service 이름으로 요청
client pod 내부 애플리케이션은 실제 server pod의 IP를 알 필요 없이 Service 이름으로 요청을 보냅니다.
목적지: example.default.svc.cluster.local2. DNS 조회로 ClusterIP 확인
클러스터 DNS(CoreDNS)는 Service 이름에 대응하는 ClusterIP(Virtual IP)를 반환합니다. 이 ClusterIP는 실제 노드의 네트워크 인터페이스나 라우팅 테이블에 존재하지 않는 논리적인 가상 주소입니다.
example.default.svc.cluster.local -> 10.96.123.453. Pod에서 노드 네트워크로 전달
DNS 해석 이후, client pod는 다음과 같은 패킷을 생성합니다.
출발지 IP: 10.0.1.3
목적지 IP: 10.96.123.45패킷은 Pod의 veth 인터페이스를 통해 노드1의 브리지(cbr0)로 전달됩니다. 이 단계에서도 패킷의 목적지는 여전히 Service의 ClusterIP입니다.
client pod → veth → cbr04. Service IP -> Pod IP 변환
노드1에서 동작 중인 kube-proxy는 Service 및 Endpoint 변경을 감지해 이에 대응하는 iptables 규칙을 사전에 구성해 둡니다.
패킷이 노드 커널의 netfilter 체인을 통과하면서 Service의 ClusterIP에 매칭되는 규칙이 적용되고, 목적지 주소는 실제 server pod의 IP와 포트로 변환됩니다.
여러 Endpoint가 존재하는 경우, 이 단계에서 로드밸런싱이 함께 수행됩니다.
DNAT 전: 10.96.123.45:80
DNAT 후: 10.0.2.2:80805. CNI를 통한 노드 간 라우팅
DNAT가 완료된 패킷의 목적지는 이제 10.0.2.2입니다.
노드1의 라우팅 테이블에는 CNI 플러그인이 구성한 Pod CIDR 경로 정보가 존재합니다.
10.0.2.0/24 -> 노드2이에 따라 패킷은 노드1의 eth0을 통해 외부 네트워크로 전달됩니다. 이 구간에서는 일반 IP 라우팅이 적용되며, Pod IP는 변경되지 않습니다.
노드1 eth0 -> 라우터 -> 노드2 eth06. 대상 Pod로 최종 전달
노드2는 목적지 IP 10.0.2.2가 자신의 Pod CIDR에 속함을 확인하고, 패킷을 브리지(cbr0)로 전달합니다. server pod는 요청을 수신하고, 응답 패킷을 동일한 경로로 반환합니다.
eth0 -> cbr0 -> veth -> server pod2) Deployment 생성 후 Pod가 뜨기까지의 내부 로직
쿠버네티스는 선언적 API와 컨트롤 루프 기반으로 동작합니다. 사용자가 kubectl apply로 원하는 상태를 정의하면, 여러 컨트롤러가 이를 지속적으로 감시하며 실제 클러스터 상태를 맞춰 나갑니다.
1. Deployment 생성
사용자가 kubectl apply로 Deployment를 생성하면, 해당 리소스는 kube-apiserver를 통해 인증/인가 및 유효성 검증을 거친 뒤 etcd에 저장됩니다.
2. ReplicaSet 생성 및 조정
Deployment Controller는 새로 생성되거나 변경된 Deployment를 감지하고, spec.replicas와 Pod 템플릿을 기준으로 ReplicaSet을 생성하거나 기존 ReplicaSet의 크기를 조정합니다.
이 과정에서 생성/수정된 ReplicaSet 역시 API 서버를 통해 etcd에 반영됩니다.
3. Pod 리소스 생성
ReplicaSet Controller는 ReplicaSet을 지속적으로 감시하며 현재 Pod 수가 원하는 개수와 일치하는지 확인합니다.
Pod 수가 부족한 경우 새로운 Pod 리소스를 생성하며, 이때 Pod는 아직 실행되지 않은 상태로 노드가 할당되지 않은 Pending 상태에 머무릅니다.
4. 노드 선택 및 바인딩
kube-scheduler는 노드가 지정되지 않은 Pod를 감지하고, 리소스 요청, taint/toleration, affinity/anti-affinity 등의 조건을 종합적으로 고려해 실행할 노드를 선택합니다.
선택된 노드는 Pod의 spec.nodeName 필드에 기록됩니다.
5. 컨테이너 실행 및 상태 보고
각 노드의 kubelet은 자신에게 할당된 Pod를 감지하고, Pod 정의에 따라 컨테이너 이미지를 Pull한 뒤 컨테이너를 생성합니다.
컨테이너가 정상적으로 실행되면, kubelet은 Pod 상태를 Running으로 API 서버에 보고하며 클러스터 상태가 최종적으로 동기화됩니다.
