Iris 시각화, 결과값
Iris 시각화:
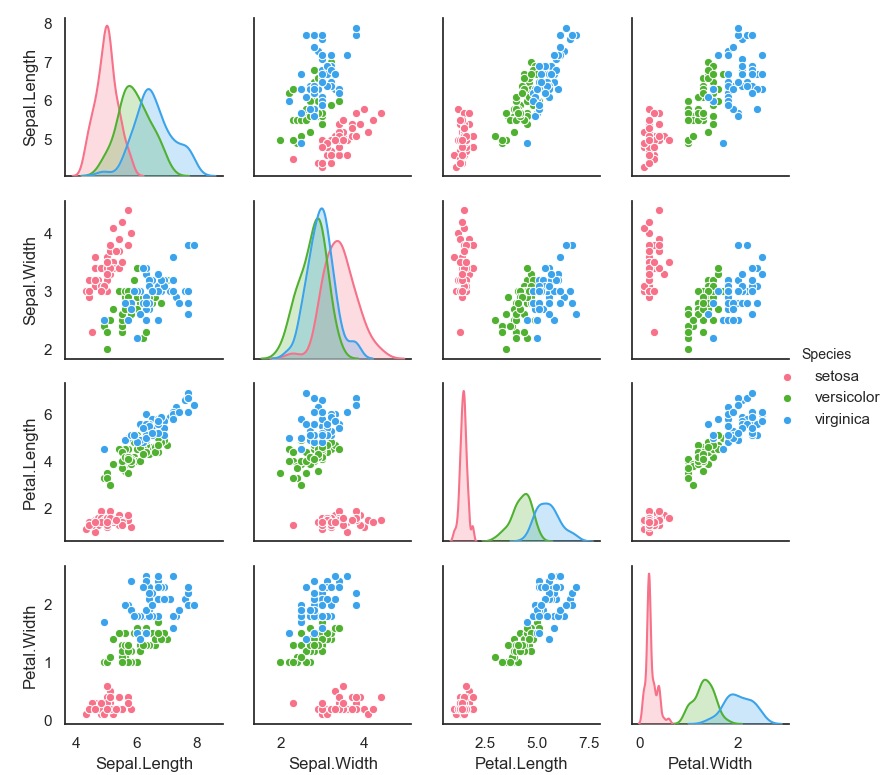
Iris 데이터셋은 머신러닝과 데이터 분석에서 가장 유명한 데이터셋 중 하나입니다. Iris 데이터셋은 꽃받침(Sepal)과 꽃잎(Petal)의 길이와 너비를 측정한 데이터셋입니다. 이 데이터셋을 시각화해보면, 꽃받침과 꽃잎의 길이 및 너비에 따라 꽃의 종류가 어떻게 구분되는지를 확인할 수 있습니다.
one hot encoding:
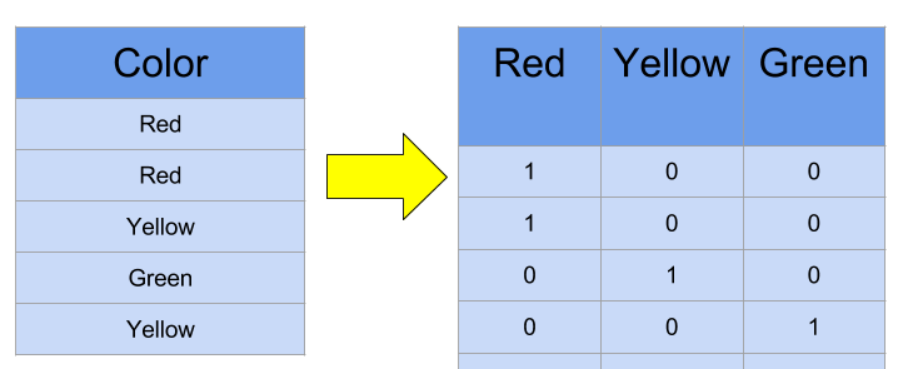
Iris 데이터셋은 세 가지 종류의 꽃을 분류하는 문제입니다. 따라서 이 문제를 해결하기 위해서는 분류 문제를 다루는 머신러닝 알고리즘을 사용해야 합니다. 그리고 머신러닝 알고리즘에 입력값으로 사용되는 데이터는 수치형 데이터여야 합니다. 그러나 Iris 데이터셋은 문자열로 된 종류명으로 이루어져 있으므로, 이를 수치형 데이터로 변환해야 합니다. 이를 위해서 one hot encoding 기법을 사용할 수 있습니다. one hot encoding은 범주형 변수를 수치형 데이터로 변환하는 방법 중 하나로, 각 범주에 대해 새로운 열(column)을 만들고, 해당 범주에 속하는 경우 1로, 속하지 않는 경우 0으로 값을 지정합니다.
___
softmax:
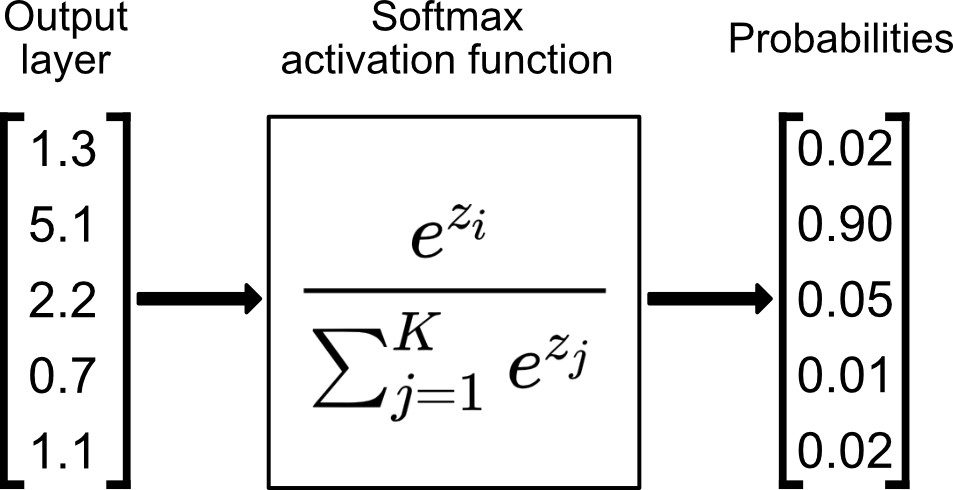
분류 문제를 해결하기 위해서는 softmax 함수를 사용하는 것이 일반적입니다. softmax 함수는 입력값으로 들어온 값을 확률값으로 변환해주는 함수입니다. softmax 함수는 모든 출력값의 합이 1이 되도록 출력값을 조정합니다. 이를 통해 분류 문제에서 각 클래스에 대한 확률값을 얻을 수 있습니다.
Iris 결과값:

Iris 데이터셋에서는 꽃받침과 꽃잎의 길이 및 너비 정보를 바탕으로 세 가지 종류의 꽃을 분류하는 문제를 다루고 있습니다. 이를 해결하기 위해 다양한 머신러닝 알고리즘을 사용할 수 있지만, 대표적으로 로지스틱 회귀 분석, 의사결정나무, SVM 등의 알고리즘이 사용됩니다. 이 중에서도 가장 간단하면서도 성능이 우수한 알고리즘이 로지스틱 회귀 분석입니다. 로지스틱 회귀 분석을 사용하여 Iris 데이터셋을 분류할 경우, 꽃받침과 꽃잎의 길이 및 너비 정보를 입력값으로 사용하고, 세 가지 종류의 꽃을 출력값으로 사용합니다. 이 때 softmax 함수를 사용하여 출력값을 확률값으로 변환해줍니다. 최종적으로 출력된 확률값을 바탕으로 가장 높은 확률값을 가지는 클래스를 선택하여 해당 데이터가 어떤 종류의 꽃인지 분류합니다. 분류 결과는 정확도(accuracy)를 기준으로 평가할 수 있습니다. Iris 데이터셋은 매우 잘 알려진 데이터셋이기 때문에, 이를 바탕으로 다양한 머신러닝 알고리즘을 비교해보고, 최적의 알고리즘을 선택하는 것도 가능합니다.
