
해당 게시글은 세명컴퓨터고등학교 보안과 동아리 세미나 발표 내용을 블로그 형식으로 정리한 글로, 본 글의 저작권은 yulmwu (김준영)에게 있습니다. 개인적인 용도로만 사용 가능하며, 상업적 목적의 무단 복제, 배포, 또는 변형을 금지합니다.
이미지의 출처가 있는 경우 별도로 명시하며, 출처가 없는 경우 직접 제작한 이미지입니다.
글에 오류가 댓글로 남겨주시거나 피드백해주시면 감사드리겠습니다.
포스팅에서 사용한 소스코드는 깃허브에 올려두었습니다. 아래의 링크에 방문하여 확인하실 수 있습니다.
https://github.com/eocndp/aws-lambda-example
발표에 사용된 프레젠테이션(PPT)는 완성되는 대로 해당 포스팅에 첨부하겠습니다.
https://drive.google.com/file/d/1KhsmWHPzbNs-tEzAapYcLQmlH2dt0gzt/view?usp=sharing
0. Overview
서버리스(Serverless)라 하는 아키텍쳐를 들어본적이 있다면, 흥미로운 주제가 아닐 수 없을 것이다.
가령 서버리스가 당장 무슨 말인지 몰라도 이 포스팅을 통해 어느정도 이해가 되었으면 하는 바람이다.
이에 따라 MSA(Micro Service Architecture)와 AWS 람다(Lambda)에 대해 알아보고, 실제로 AWS 람다를 이용한 서버리스 API 구축을 다뤄보면서 추가적으로 Cognito를 사용한 인증(Authentication) 구현에 대해 다뤄볼까 한다.
(때문에 해당 포스트에서 설명하는 서버리스는 AWS 람다와의 연관성이 큼을 미리 알린다.)
그 외에도 DynamoDB, S3, CloudFront, CloudFormation(with Serverless Framework) 등의 여러 AWS 서비스와, 마지막으로 Github Actions를 활용한 CI/CD 자동화까지 가볍게 다뤄볼 예정이다.
또한 글에 등장하는 용어들에 대해선 웬만하면 잠깐이라도 설명을 하고 넘어가려고 하였으나, 독자 여러분의 배경 지식이 어느정도 있다고 가정하기 때문에 설명하지 않는 용어가 있을 수 있다.
처음엔 이론 중심의 내용을 다루며, 6번째 파트(Let's build the Infra) 부터 실제 인프라를 구축하고 배포해볼 것이며, 그 이야기의 시작으로 AWS가 뭔지부터 간단하게 설명하고 넘어가려 한다.
1. What is AWS(Amazon Web Service)?
1-1. Cloud
사실 클라우드와 AWS가 뭔지 정도는 설명이 가능해도, 그 자세한 내용과 다양한 서비스를 설명하기엔 분량 상 어려움이 있다.
애초에 이 글을 읽는 독자 여러분은 AWS에 대한 기초적인 지식이 있다고 가정하지만, 이 포스팅에선 AWS에 대한 설명을 간단히 하고 넘어가려 한다.
람다(Lambda), API Gateway, DynamoDB 등의 서비스에 대해선 이후 따로 설명할 예정이다.
" 인터넷을 통해 접근 가능하고, 가상화된 서버나 서비스, 자원 등을 제공해주는 서비스. "
이렇게만 말하면 이해가 안될 수 있겠다만, 쉽게 생각을 해보자.
우리가 전통적으로 서버를 구축하고 서비스하려면 어떻게 해야할까?
만약 그러한 상황에 처했다면 필자는 아마 컴퓨터(=서버), 즉 장비부터 구매하였을 것이다.
문제가 벌써 발생했다. 앞으로 서비스할 서비스의 규모가 어느정도로 커질지,
또는 줄어들지 예측도 어려우니, 초기 인프라 구축 비용도 크게 발생한다.
또한 이미 비싼 장비를 구매해뒀기 때문에 이를 변경하려면 추가적인 비용과 시간이 들며, 상당히 어려운 작업이 되는데, 그렇다고 그러한 장비의 유지보수에 대해 쉬운것도 아니다.
확장성도 거의 없다시피 하고, 많은 인력과 실력자들이 있지 않는 이상 이상적인 보안 솔루션도 만들기 어렵다. 애초에 펌웨어 및 운영체제 부터 시작하여 모든걸 관리해야되기 때문이다.
이렇게 서버 컴퓨터 부터 하나하나 관리하고 유지보수하는 것을 온 프레미스(On Premise) 환경이라 칭한다.
서론을 너무 길게 말한 듯 싶다. 이러한 인프라의 단점을 보완한 것이 있으니, 바로 앞서 말했듯이 클라우드이다.
1-2. AWS
AWS(Amazon Web Service)는 그러한 클라우드 서비스/업체 중 단연 1위를 달리고 있는 업체이다.
사실상 백엔드 서버를 구축할 때 필요한 모든 기술 및 서비스가 갖춰져있고, 비용적인 측면만 제외한다면 안쓸 이유가 없다. (물론 초기 러닝 커브 등은 생각하지 않는다.)
AWS에서 서버를 배포할 땐 주로 EC2(Elastic Cloud Computer)라는 가상 컴퓨팅 서비스를 주로 사용한다.
이는 IaaS(Infrastructure as a Service) 아키텍쳐인데, 컴퓨터 가상화만 제공하고 그 위의 OS부터 애플리케이션 까지 개발자(= AWS 이용자)가 구현하고 관리해야한다.
하지만 그럼에도 여전히 OS나 런타임 등의 환경은 개발자가 관리해야 되고,
여기서 한발짝 더 나아가 아예 OS와 런타임 플랫폼(예: NodeJS, Python 등)을 AWS에 맏겨두고, 필요 시 실행시키는 아키텍쳐가 바로 이 포스팅의 주제인 서버리스(Serverless)이다.
2. What is Serverless?
앞서 말했듯이 전통적으로 OS부터 관리하는 것이 IaaS(Infrastructure as a Service)라면 서버리스는 FaaS(Function as a Service) 아키텍쳐에 가깝다. (함수에 대해선 곧 설명할 예정이다.)
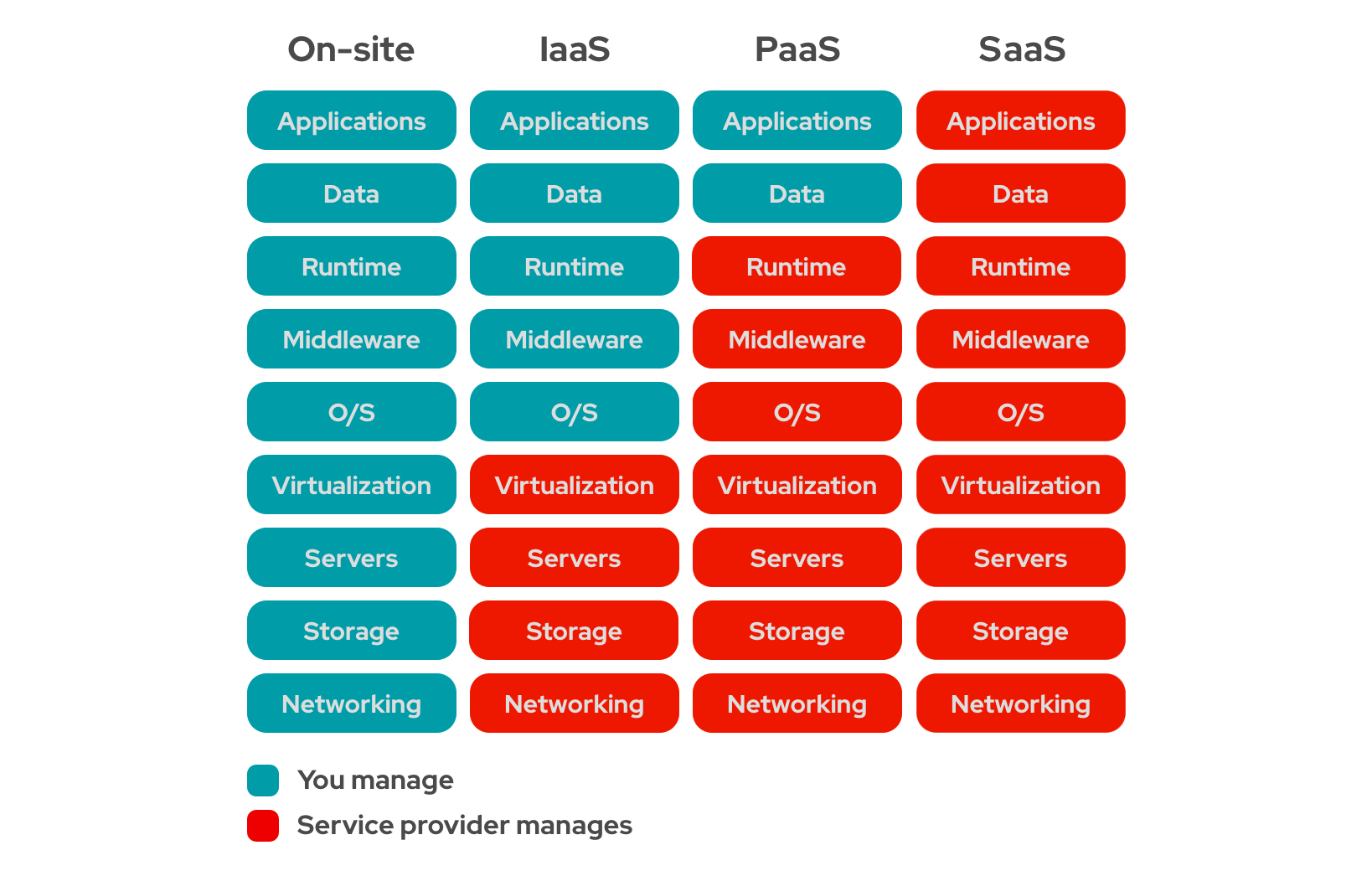
출처: https://www.redhat.com/en/topics/cloud-computing/iaas-vs-paas-vs-saas
PaaS(Platform as a Service)와 FaaS(Function as a Service)는 얼핏 보기엔 비슷해보일 순 있으나, PaaS는 플랫폼(NodeJS, Python 등)을 제공해주고, 그 위에 배포할 수 있도록 한다. (대표적으로 AWS ECS, EKS Fargate)
이렇게 배포를 하면 EC2 등의 IaaS를 사용했을 때 처럼 지속적으로 서버 애플리케이션을 유지시킬 수 있다.
얼핏 보면 플랫폼을 제공해준 다는 것에 대해 PaaS도 서버리스의 특징을 가져 범주에 포함될 순 있지만, 해당 포스트에선 PaaS를 서버리스라고 부르진 않겠다.
그에 비해 FaaS는 더 세분화된 함수라는 단위로 코드를 작성하고, 이벤트가 발생했을 때 순간적으로 실행한다. (대표적으로 AWS Lambda)
즉 사용하지 않았을 땐 실행되는 상태가 아니라는 것이다.
이는 런타임 플랫폼을 클라우드 업체에서 제공하는 것인데, 정말 쉽게 말해서 코드만 올려서 작동시키는 것이다. "서버가 없는 것"이 절대 아니라, 서버를 직접 관리하지 않는다는 점을 강조하고 싶다.
즉 백엔드 개발자 입장에서 서버와 OS를 따로 관리하지 않는 다는 점이 서버리스의 핵심 포인트이다.
(물론 실제로 전혀 직접 관리하지 않는 것은 아니다. 기본적인 최대 메모리/CPU 구성, 동시성 등의 설정은 세팅할 수 있다.)
또한 서버리스는 (대부분) 이벤트 기반으로 작동한다. 즉 어떠한 조건이 되었을 때 실행된다. (이 조건에는 HTTP 요청 등의 작업도 포함된다.)
2-1. AWS Lambda
앞서 말했 듯 서버리스는 대부분 FaaS의 형태, 즉 함수(Function) 형태로 작동하며 지속적으로 실행되는게 아닌 해당 로직만 처리하고 끝난다.
이러한 함수는 대부분 이벤트 기반으로 작동하는데, AWS의 대표적인 서버리스 서비스인 람다(Lambda)의 경우도 이벤트 기반 트리거를 사용한다.
즉 어떠한 서비스가 특정한 조건이 되었을 때(예: S3 파일 업로드) 람다를 실행시킬 수 있고, 특히 API Gateway라는 서비스에서 HTTP 요청이 들어왔을 때 람다를 실행시킬 수 있기 때문에 이를 사용한 서버리스 API를 구축할 수 있다.
람다에 대한 자세한 사용 방법과 내용은 추후 AWS 아키텍쳐 파트에서 더욱 자세히 설명하겠다.
만약 누군가 람다가 무엇인지 묻는다면 이렇게 답한다면 좋은 답변이 될 것 이다.
" 서버를 직접 프로비저닝하지 않고 이벤트에 따라 함수(코드)를 실행할 수 있는 FaaS 기반 서버리스 서비스 "
Lambda's Price
람다의 요금과 IaaS(EC2 등)의 요금에 대해 잠깐 이야기하려고 한다.
흔히들 EC2의 대표적인 요금제인 온디맨드, 즉 사용량 만큼 비용을 지불한다는 요금제가 존재한다.
이는 EC2를 켜두는 시간만큼 요금이 지불되는데, 잘 생각해보자.
365일 24시간 돌아가야 하는 서버인데, 즉 맨날 켜둬야하는 서비스인데 그럼 결국엔 사용한 만큼 지불한다는 온디맨드라 하기엔 좀 그렇지 않은가?
(다만 전통적인 관점에서 볼땐 서버를 구매하는게 아닌, 특정 시간동안 임대하여 사용하는 것이니 맞는 표현이긴 하다.)
하지만 AWS의 FaaS 기반 서버리스인 람다는 해당 람다의 사용량만큼만 계산하는데, 여기서 사용량은 람다 함수의 수 + 함수의 실행 시간으로 계산된다.
때문에 트루(True) 온디맨스라는 비공식적인 용어로 불리기도 한다. 진짜로 요금을 사용한만큼 지불한다는 것.
요금에 대한 자세한 이야기는 나중에 설명하겠다.
이렇듯 람다는 특정한 이벤트를 통해 호출되는 함수(Function)를 바탕으로 작동하는 서버리스이자 FaaS(Function as a Service)이다.
2-2. Why use Serverless?
일단 장점부터 말하겠다. 대표적인 장점으로는 쉽게 확장이 가능하다는 점, 앞서 말했 듯 비용 효율적이라는 것, 안전성/보안성이 높으며 애플리케이션 개발자는 코드 작성에 집중할 수 있다는 점이 있을 것이다.
첫번째 "확장성" 부터 생각해보자.
기존의 EC2를 사용하여 배포한다면, 확장성을 위하여 로드벨런서(Load Balancer)와 오토 스케일링(Auto Scailing) 등의 솔루션을 고려해봐야 한다.
하지만 이에 따른 복잡한 인프라 구성과 비용, 그럼에도 즉각적으로 대응할 수 없다는 점 등의 단점이 존재한다.
하지만 람다를 사용하여 서버리스 환경을 구축하면 이러한 문제 없이 AWS에서 자동으로 처리해주며, 성능을 자동으로 쉽게 확장시킬 수 있다.
두번째 "비용 효율적"은 여러번 말하지만 사용량을 바탕으로 요금이 부과되기 때문에 비교적 저렴하다는 점이 있다.
다만 규모가 커지만 EC2를 사용한 Serverful한 방법이 더욱 비용 효율적일 수 도 있다.
마지막으로 보안성과 안전성이 AWS단에서 보장이 되며, 이로써 개발자는 서버 개발 및 코드 작성에 집중할 수 있다는 점이 일반적인 서버리스의 장점이다.
다만 FaaS에 대한 이야기이자 람다의 크나큰 단점이 있는데, 가장 중요한 단점은 추후 람다의 Life Cycle 이야기를 할 때 다뤄보기로 하자.
그 외엔 (함수를 개별적으로 실행함으로) 전체적인 디버깅의 어려움, 의존성 관리의 어려움 등이 있다.
참고로 전통적인 방식으로, 하나의 애플리케이션으로 작성되어 있는 것을 모놀리식(Monolithic) 아키텍쳐라 부른다.
2-3. MSA(MicroService Architecture)
서버리스와 람다에 대해 다룰 때 빠질 수 없는 아키텍쳐 구조가 있다.
먼저 전통적인 서버의 아키텍쳐인 모놀리식 아키텍쳐를 살펴보자.
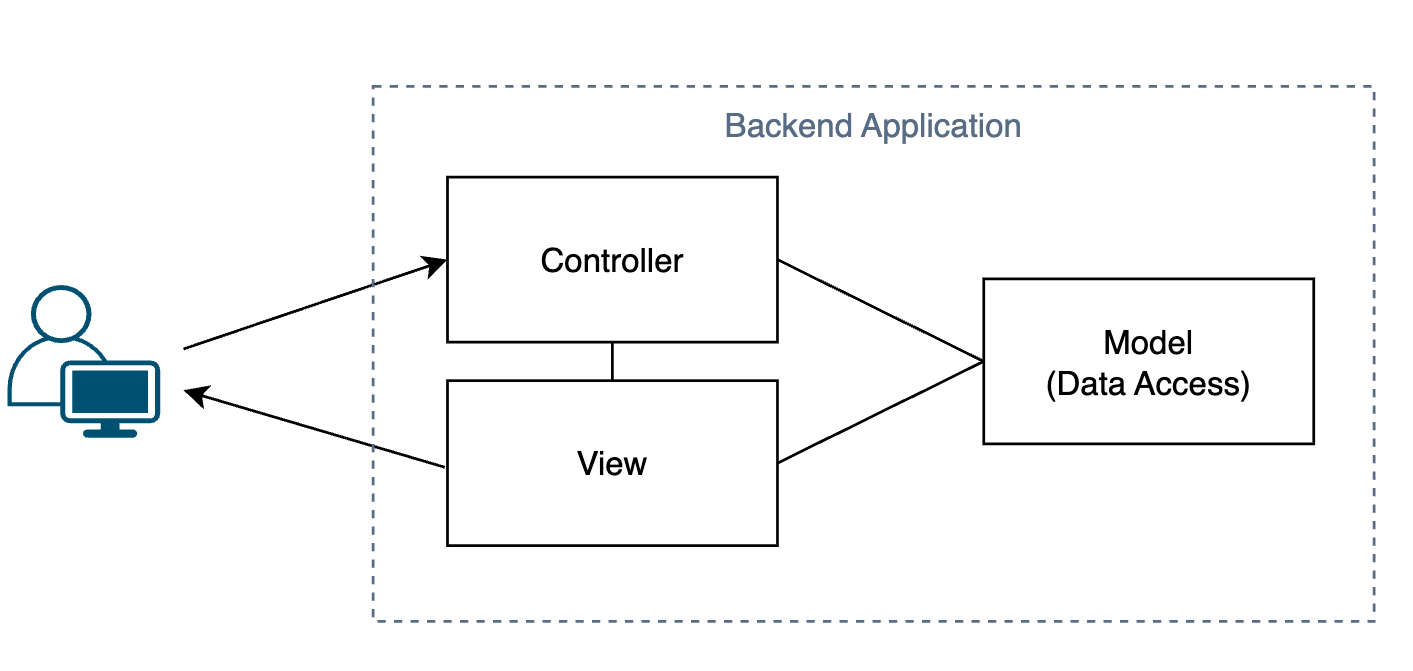
실제 모놀리식 아키텍쳐가 이렇다는건 아니다. 이는 MVC(Model-View-Controller 패턴인데, 모놀리식 아키텍쳐에서 주로 사용되는 백엔드 어플리케이션 패턴이다.
위와 같은 구조를 잘 살펴보자. 만약 우리가 결제와 관련 로직을 수정한다고 해보자.
결제와 관련된 로직을 수정했으면, 수정된 내용을 배포해야 하는데 이는 하나의 큰 덩어리의 백엔드 애플리케이션 안에 모여있다.
즉 이를 다시 배포하기 위해선 애플리케이션 전체를 다시 배포해야 한다는 것이다.
서버의 경우 잠깐이라도 끊긴다면 문제가 커지는데, 이렇게 배포 과정에서 일어나는 손실이 존재한다.
그럼 마이크로서비스 아키텍쳐 방식을 보도록 하자.
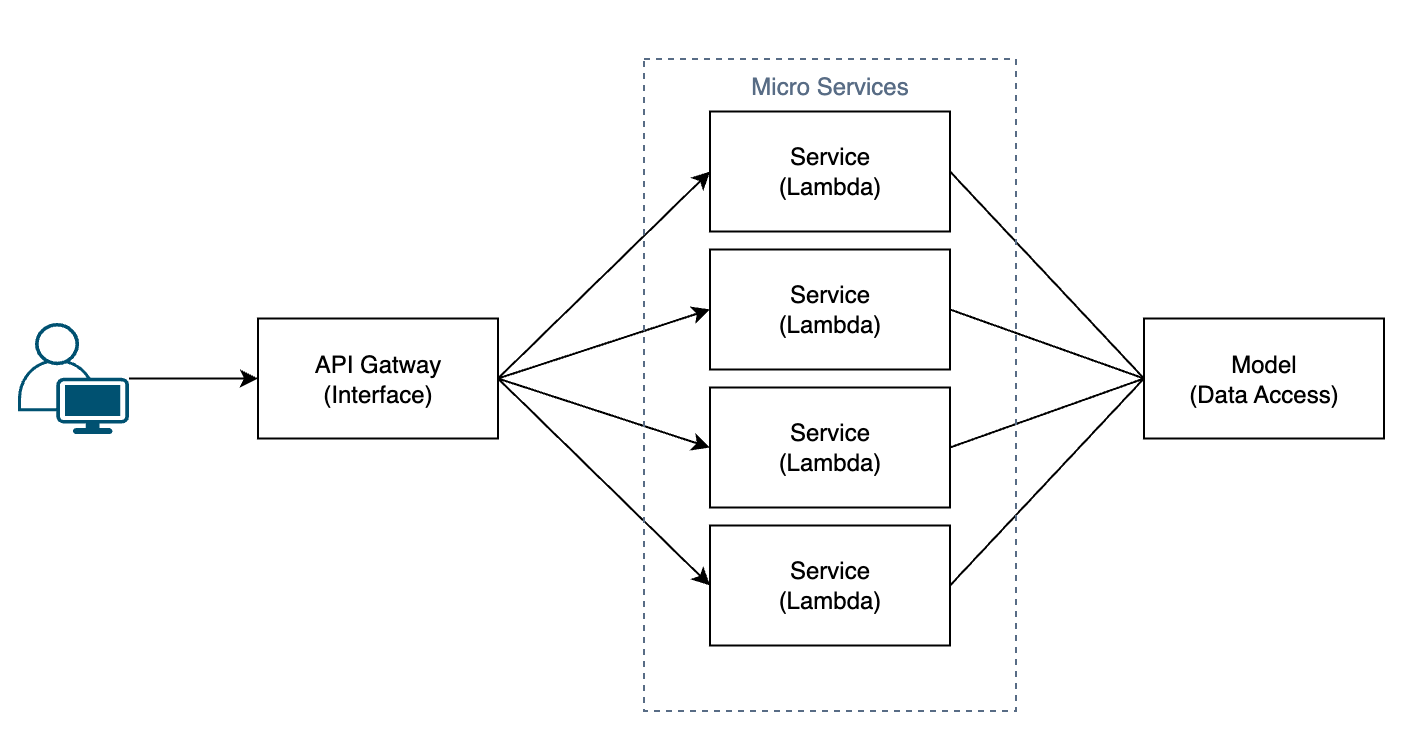
백엔드 맨 앞단에 API들을 통합해주는 API Gateway가 존재하고, 그 뒤에 하나하나가 서비스인 람다 함수들이 자잘하게 모여있다.
만약 각 람다 함수가 담당하는 서비스가 각각 결제, 로그인, 회원 관리 등의 서비스라면, 위와 같은 아키텍쳐에선 결제를 담당하는 람다 함수 하나만을 수정하고 다시 배포하면 되기 때문에, 다른 서비스들에게 미치는 영향이 (일반적으론)없다.
AWS 람다로 예를 들면 각 함수별로 서비스가 구분된다는 것(FaaS)과 MSA의 개별적인 마이크로 서비스의 궁합이 잘 맞고, 앞서 설명했던 장점들을 극대화 하여 서버리스 환경과 MSA 아키텍쳐 조합을 자주 사용한다.
물론 착각하면 안되는게, "서버리스 환경에선 무조건 MSA"와 같은 오해는 금물이다.
서버리스 환경에서도 모놀리식 아키텍쳐를 사용하는 프로젝트도 많고, 반대로 Serverful한 환경에서 MSA 아키텍쳐를 사용하는 프로젝트도 많다.
2-4. Stateless
대부분의 서버리스 특징이자, 곧 람다의 특징인 무상태(Stateless)에 대한 설명을 빠트릴 순 없다.
특히 람다, 즉 FaaS(Function as a Service)에선 빠질 수 없는 내용인데, 먼저 전통적인 모놀리식 아키텍쳐의 관점에서 살펴보자.
예를 들어, 어떤 코드를 실행하면 백엔드 애플리케이션 전체의 전역 변수 하나가 바뀐다고 가정해보자. 이렇게 현재 상태를 애플리케이션 내부적으로 저장하게 되는데, 이를 Stateful하다고 한다.
하지만 람다의 경우 이벤트에 대해 트리거 되며 개별적인 함수가 실행되고, 이러한 함수는 호출될 때 마다 새로운 환경으로 부터 가상화되어 실행되기 때문에 (기본적으론) 상태를 저장할 수 가 없다.
다만 이 문장엔 에러가 존재한다. 이후 람다의 Life Cycle에 대해 다룰 때 알아볼 내용이지만, 미리 스포하자면 람다는 효율성을 위해 특정 시간 동안 환경을 유지한다. (이를 Warm Start라 한다.)
예를 들어 람다에 전역 변수를 선언해두고, 곧바로 똑같은 요청을 보내게 되면 해당 전역 변수가 보통은 유지된다는 것이다. (똑같은 환경이 유지되니)
때문에 람다를 사용할 땐 비동기 처리 등에서 정확한 처리가 필요하며, 이를 주의하고 코드를 작성해야 한다.
이렇게 내부적으로 저장할 수 없는 것을(않는 것을) 무상태(Stateless)라고 한다.
다만 Stateless냐 Stateful이냐를 논할 때 DynamoDB와 같이 외부의 리소스를 사용하여 데이터를 저장하는 것은 생각하지 않으며, Stateless는 이벤트를 처리할 때 내부적인 상태를 저장하지 않기 때문에 독립된 환경에서 처리할 수 있게 된다.
만약 인증 등의 상태 저장이 필요할 경우, 외부의 DB를 따로 사용하거나 JWT 방식의 인증을 사용한다. (대부분 후자)
이 포스팅에선 AWS Cognito를 사용한 인증에 대해 알아본다.
2-5. When to use Serverless?
람다는 아래와 같은 상황에서 유용하게 사용할 수 있고, 더욱 더 효율적으로 활용될 수 있다.
- 인프라 구축 및 관리(DevOps)에 대한 부담을 줄이거나 그러한 관리를 하기 어려운 경우
- 스타트업 등 초기 비용을 줄이고, 빠르게 프로토타입을 만들며 확장성 및 유연성을 갖추고 싶은 경우 (Serverless + MSA)
- 특정한 이벤트(예: S3 파일 업로드, HTTP 요청 등)에 대해 트리거 되는 이벤트 기반 애플리케이션을 만들고 싶은 경우
3. Project Concept
서버리스와 AWS 람다에 대해 설명하느라 서론이 너무 길어진 듯 싶다.
이제 무슨 프로젝트를 어떻게 할지를 정해야한다. 필자는 적절하다고 생각되는 항목을 정해두었고, 이 항목에 맞춘 프로젝트를 고안해내었다.
- 서버리스 환경에 적절하게 뭍어나야 될 것
- REST API로 CRUD(Create, Read, Update, Delete)를 잘 따를 것
- 인증 시스템을 사용하는 API일 것 (JWT)
- 복잡한 구조를 가지지 않을 것
이렇게 고안해냈다는게 좀 뻔하지만 한번 쯤은 시도해볼만한 게시판 프로젝트였다.
REST API를 통해 적절한 CRUD를 구현하고, 인증 시스템까지 있으며 그리 복잡한 구조도 아니고, 람다 함수를 통해 MSA를 따르며 서버리스 환경에 적절히 뭍어난다고 생각하였기 때문이다.
3-1. API Endpoint
자세한 API 별 소개는 이곳에서 확인할 수 있다.
여기선 단순히 추후 인프라를 구성할 때 참고할 정도의 API 구조를 설명한다.
| 엔드포인트 | 설명 | 요청 데이터 | 응답 데이터 | JWT 인증 여부 |
|---|---|---|---|---|
POST /auth/login | 로그인 | username, password | accessToken, idToken(Set-Cookie) refreshToken | |
POST /auth/confirmEmail | 이메일 인증 | username, code | ||
POST /auth/resendEmail | 이메일 인증 재전송 | username | ||
POST /auth/logout | 로그아웃 (리프레시 토큰 무효화) | O | ||
POST /auth/refresh | 엑세스 토큰 재발급 | accessToken, idToken | ||
GET /posts | 모든 글 조회 | (생략) | ||
GET /posts/{postId} | 특정 글 조회 | (생략) | ||
POST /posts | 글 작성 | title, content | (생략) | O |
PUT /posts/{postId} | 글 수정 | title, content | (생략) | O |
DELETE /posts/{postId} | 글 삭제 | O | ||
GET /myinfo | 로그인된 유저 정보 확인 | (생략) | O |
이제 프로젝트 구상이 끝났으니 실제로 AWS 아키텍쳐를 그려보고, 인프라를 구축하며 자동화까지 해보도록 하자.
4. AWS Architecture
이 프로젝트에서 사용할 AWS 아키텍쳐는 아래와 같다.
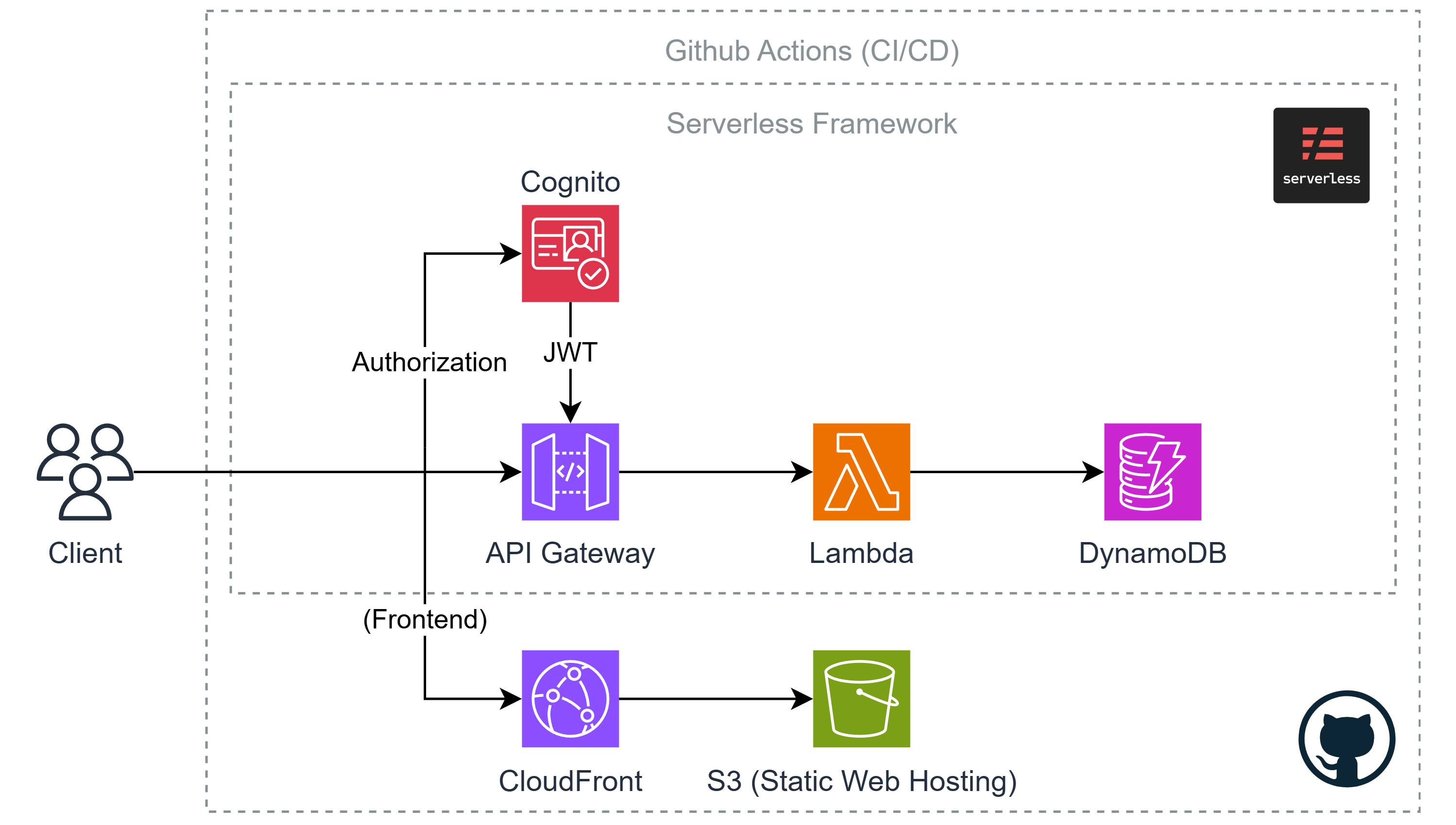
이제 위 아키텍쳐를 참고하여 개별적으로 어떤 역할을 하고, 또 어떻게 동작하는지 등에 대해 알아보도록 하자.
실습과는 별개로, 먼저 개념 위주로 살펴본 뒤 다음의 6번째 파트(Let's build the Infra)에서 실제 프로젝트의 실습을 진행하고 Serverless Framework를 사용할 예정이다.
4-1. Lambda
우선 람다는 앞서 설명했었는데, AWS의 FaaS 기반 서버리스 서비스이다.
람다의 개념은 이전에 설명을 하였고, 이 파트에선 람다가 어떻게 동작하는지에 알아보는 것을 목표로 한다.
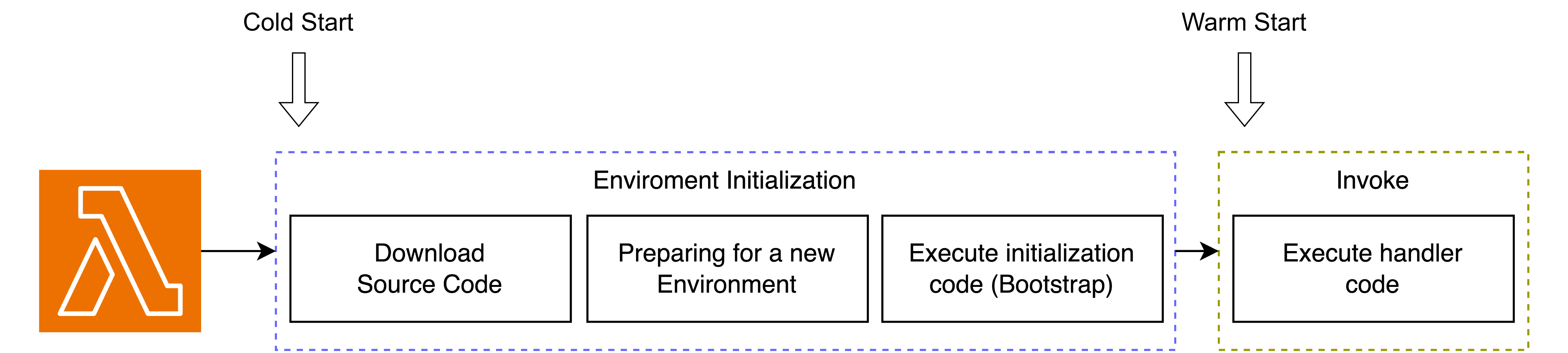
How Lambda works (Life Cycle)
먼저 람다에 이벤트, 즉 요청이 들어오면 람다는 실행되며 종료되기 까지 아래와 같은 3단계를 거친다.

각 단계를 살펴보도록 하자.
(1) Environment Initialization
흔히 Cold start라고 불리는 부분인데, 나중에 따로 설명하도록 하겠다.
여기선 람다 함수를 실행하기 위한 런타임(NodeJS, Python 등)등의 환경(또는 컨테이너) 구축하고 초기화시키는 단계이다.
우리가 람다 함수를 실행할 때 설정해뒀던 런타임, 메모리 사이즈, 환경 변수 등이 이때 사용되어 세팅된다.
또한 사용자의 소스 코드를 다운로드 하고 초기화 코드를 실행하는데, 실행에 필요한 라이브러리 등을 세팅하여 실행(Invoke)될 준비를 하게 된다.
런타임을 구축하는 시간은 요금을 계산할 때 람다의 실행 시간에 포함되지 않는다. 다만 초기화 코드(부트스트랩)를 실행하는 시간은 람다의 실행 시간에 포함된다.
2025년 8월 1일부터 람다의 라이프 사이클 중 INIT 단계 또한 요금에 포함된다. 람다 사용에 참고하도록 하자.
https://aws.amazon.com/ko/blogs/compute/aws-lambda-standardizes-billing-for-init-phase
(2) Invoke
실제로 람다 함수 핸들러, 즉 소스코드의 handler() 함수를 실행하는 단계로, 흔히 이 구간에서 부터 실행되는 것을 Warm Start라 부른다. (곧 설명)
하나의 요청이 끝나면 다음 이벤트를 처리하기 위해 Shutdown 단계로 넘어간다.
다음은 타입스크립트로 작성된 람다 함수 코드의 예시이다.
import { DynamoDBClient } from '@aws-sdk/client-dynamodb'
import { DynamoDBDocumentClient, ScanCommand } from '@aws-sdk/lib-dynamodb'
import { APIGatewayProxyResultV2 } from 'aws-lambda'
import { error, internalServerError } from '../../utils/httpError'
const dynamoDB = DynamoDBDocumentClient.from(new DynamoDBClient({}))
export const handler = async (): Promise<APIGatewayProxyResultV2> => {
try {
const command = new ScanCommand({ TableName: 'Posts' })
const result = await dynamoDB.send(command)
return {
statusCode: 200,
body: JSON.stringify(result.Items),
}
} catch (err) {
return error(internalServerError((err as Error).message), 'ERR_GET_POSTS_INTERNAL_SERVER_ERROR')
}
}여기서 handler() 함수가 Invoke 단계에서 처리하는 것으로, 그 위의 라이브러리를 가져오고 dynamoDB 변수를 정의하는 것은 초기화 코드(부트 스트랩) 단계에 속한다.
(3) Shutdown
람다 런타임과 플랫폼 환경을 종료하는 단계이다.
곧 설명하겠지만, 람다는 특정 시간동안 같은 요청이 없다면 런타임과 환경을 종료하고, 처음부터 다시 환경을 초기화해야 다시 이벤트를 처리할 수 있게 된다.
Cold Start
람다의 실행 단계를 다시 한번 복습해보자.
- Download Source Code
- Preparing for a new Environment
- Execute initialization code
- Execute Handler
여기서 1, 2, 3번 단계에 해당되는 과정을 바로 Cold Start라고 한다.
즉 처음부터 환경을 다시 만들고 세팅을 한다는 의미인데, 문제는 이 과정이 꽤나 시간이 소요된다는 점이다.
이 Cold Start가 FaaS 기반 서버리스의 큰 단점 중 하나이다. 서비스의 속도는 곧 사용자의 경험(UX)와 직결되는 문제이기 때문이다.
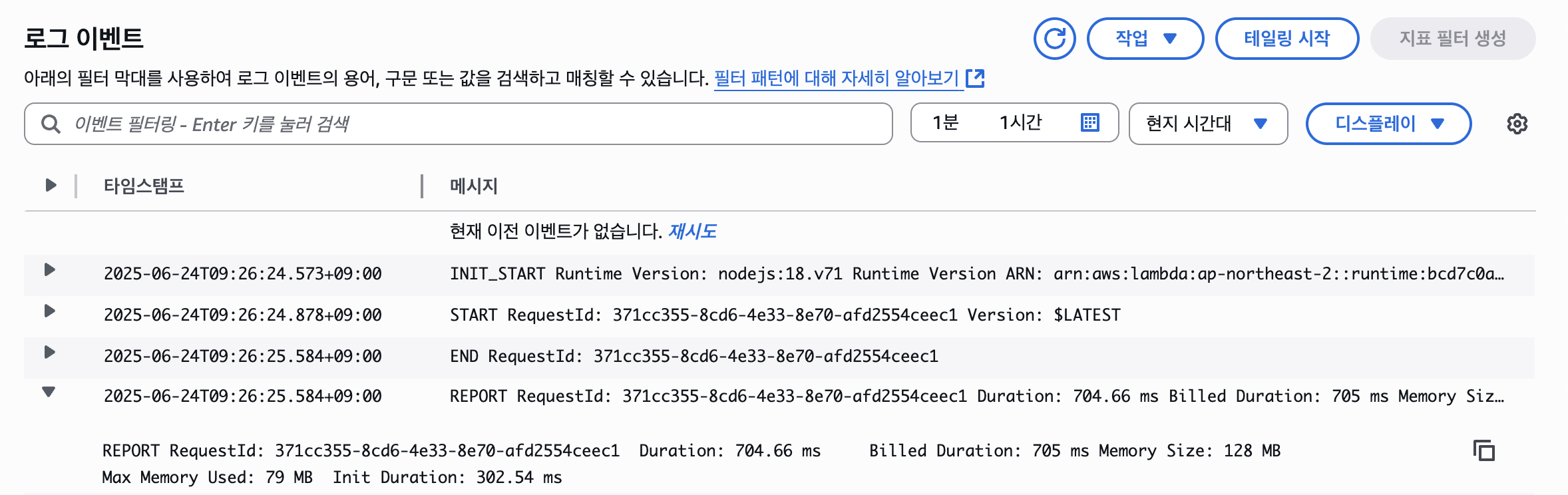
위 사진은 람다의 실행했을 때의 로그이다. INIT_START가 환경을 생성하고 초기화 하는 단계인데, 사진과 같이 약 300ms의 시간이 소요된다.
이해를 돕기 위해 예를 들어 아래의 코드를 보자.
const db = connectToDatabase()
const config = loadConfig()
export const handler = async (event) => {
return await db.query("SELECT * FROM users")
}여기서 데이터베이스 연결과 설정 관리 등의 로직은 handler() 함수 밖에 있는데, 바로 이게 초기화 코드(부트스트랩)이다.
이 초기화 코드의 실행 시간이 INIT_START, 즉 300ms라는 것이고, 총 시간(Duration)은 약 700ms이므로 handler() 함수의 실행(Invoke) 시간은 약 400ms임을 알 수 있다.
Warm Start
그런데 저러면 Environment Init 단계의 시간이 너무 아깝다.
그래서 람다에서는 한번 만들어두고 초기화 코드까지 실행해둔 환경을 일정 시간동안 유지시키는데, 이를 바로 Warm Start라고 한다.
때문에 람다에선 같은 요청(이벤트)에 대해 handler() 코드만 실행하면 굳이 처음부터 다시 환경을 만들 필요가 없어지므로 불필요한 오버헤드가 줄어들게 된다.
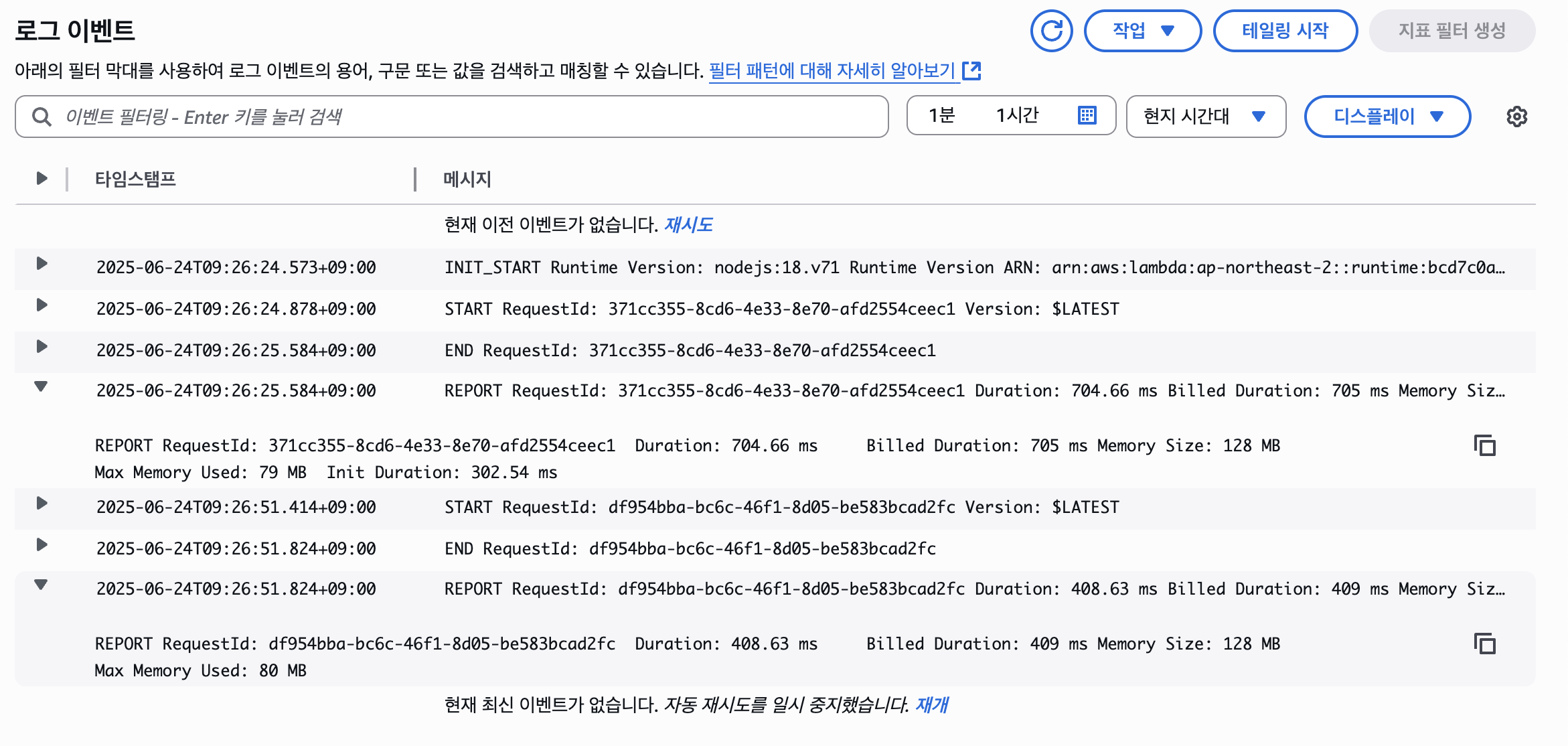
위 사진은 실제 Warm Start로 작동하였던 예시이다.
두번째 START에 대해선 보고에서 Init Duration이 없는 것을 볼 수 있는데, 즉 초기화를 진행하지 않고 handler() 함수만 실행했다는 의미로 해석된다.
그래서 이로 인해 문제가 발생할 수 도 있는데, 예를 들어 아래와 같은 코드를 예시로 볼 수 있다.
let a = 0
export const handler = async (event) => {
a += 1
const response = {
statusCode: 200,
body: JSON.stringify({ a }),
}
return response
}이 코드는 얼핏 보기엔 람다에서 실행하면 항상 1이 반환될 것으로 볼 수 있다. 하지만 실제로 단시간에 2번을 실행해보면 아래와 같은 결과를 얻을 수 있다.
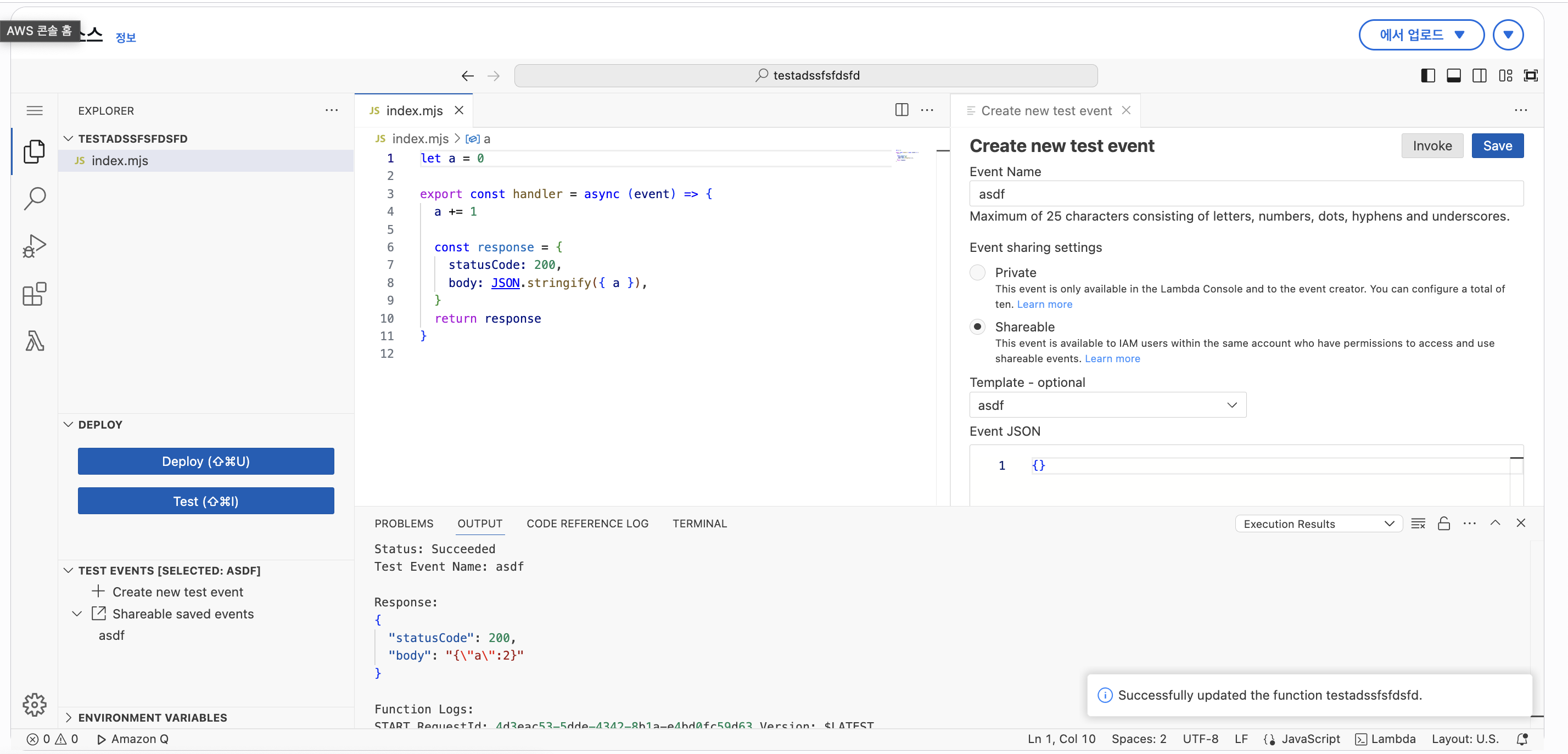
위와 같이 Warm Start 현상이 발생하여 a 변수에 대해 상태 유지가 되고, 때문에 2로 증가한 것을 확인할 수 있다.
만약 새롭게 Deploy하여 환경을 다시 만든다면 어떨까?
(람다에선 Deploy 시 처음부터 초기화하도록 함)
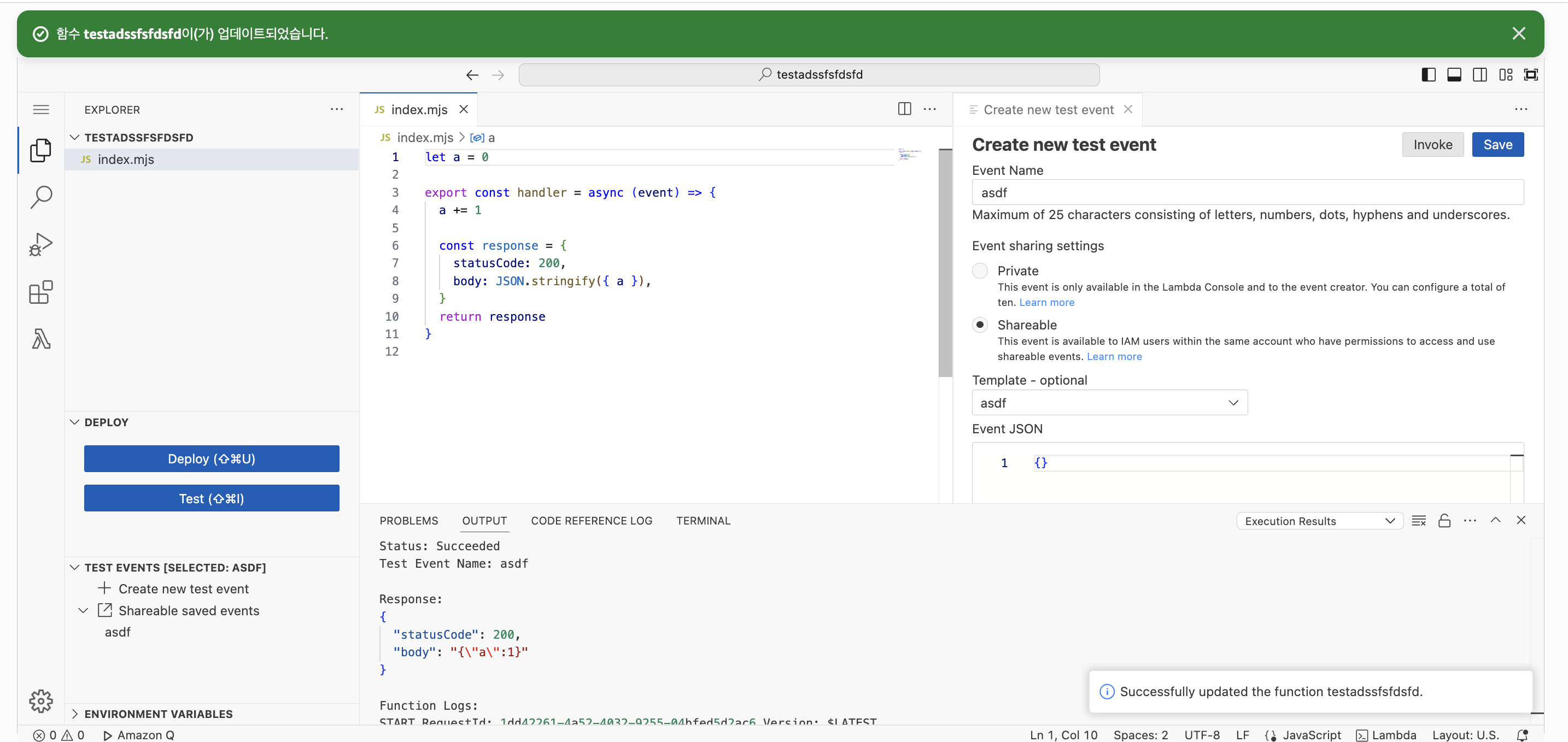
위와 같이 a 변수가 초기화 되어 다시 1로 출력되는 것을 확인할 수 있다.
이처럼 람다 함수에선 Warm Start로 인한 문제가 발생할 수 있으므로, Stateless한 코드 작성을 중요시한다.
다만 이러한 Warm Start를 활용할 수 도 있는데, 후술할 프로비저닝된 동시성을 사용하거나 Cold Start를 대응할 수 있다면 작업이 오래걸리는 데이터베이스 연결 등의 코드를 초기화 코드로 빼두는 방법이다.
Warm Start로 실행된다면 빠르게 실행이 가능하니, 람다의 성능을 개선시켜보고 싶다면 이와 같은 방법도 괜찮은 방법이다.
다만 stateful한 코드 작성은 금물이다.
Lambda Concurrently
람다가 이벤트를 처리하고 있으면 해당 람다의 환경은 추가적인 이벤트를 받을 수 없는 상태가 된다.
이후 처리가 끝나 해당 람다가 Idle 상태가 된다면 새로운 이벤트를 받을 수 있다.
이 기간에서 실행되면 Warm Start로 실행될 수 있다.

하지만 이렇게 람다 하나만을 기다리며 동시성을 처리하는 것은 매우 비효율적인데, 그래서 람다는 위와 같이 직렬적인 방식(Sequential)이 아닌 병렬적인 방식(Concurrent)을 사용할 수 있다.
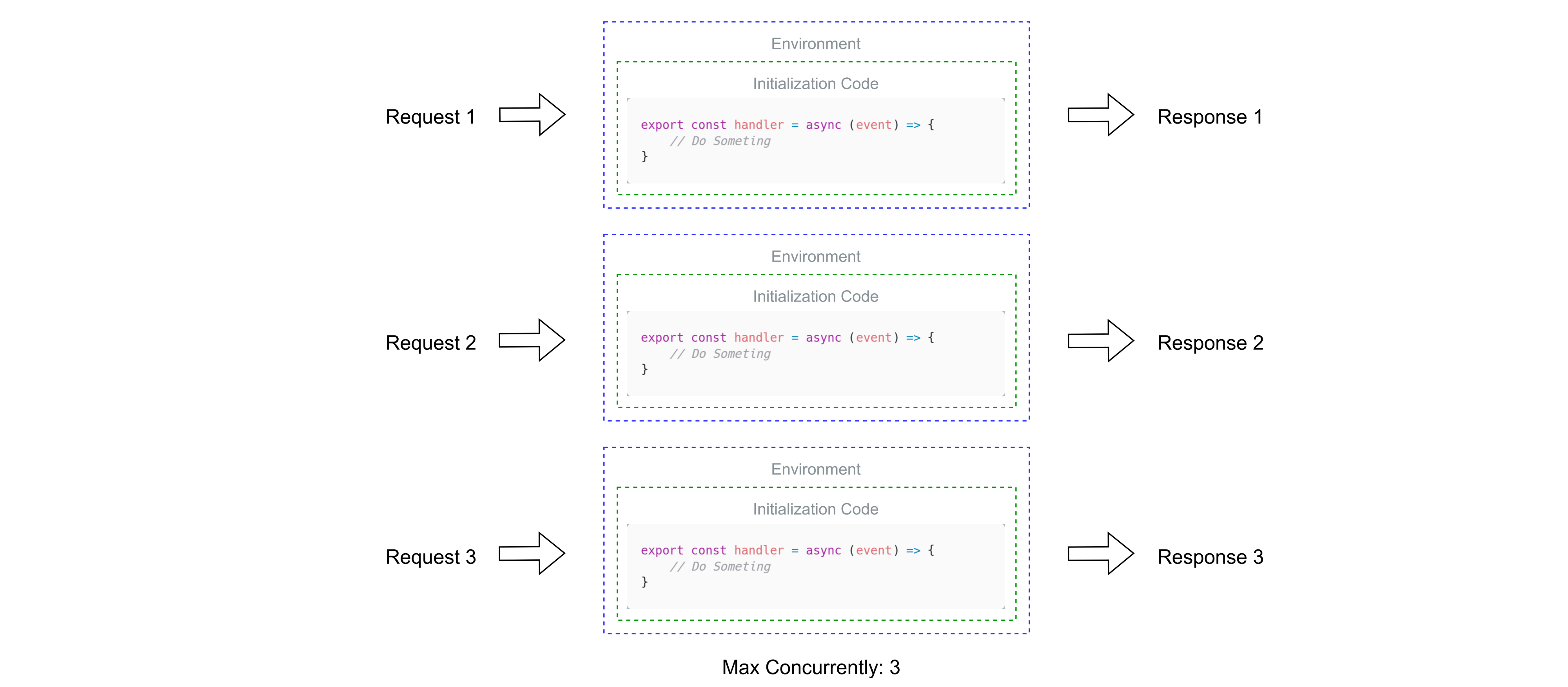
동시성(Concurrent)이 설정된 람다에선, 만약 이벤트를 처리중이라 다른 이벤트를 받을 수 없다면 새로운 환경을 새로 생성한다.
이에 대해선 람다에서 동시성 제한을 둘 수 있다.

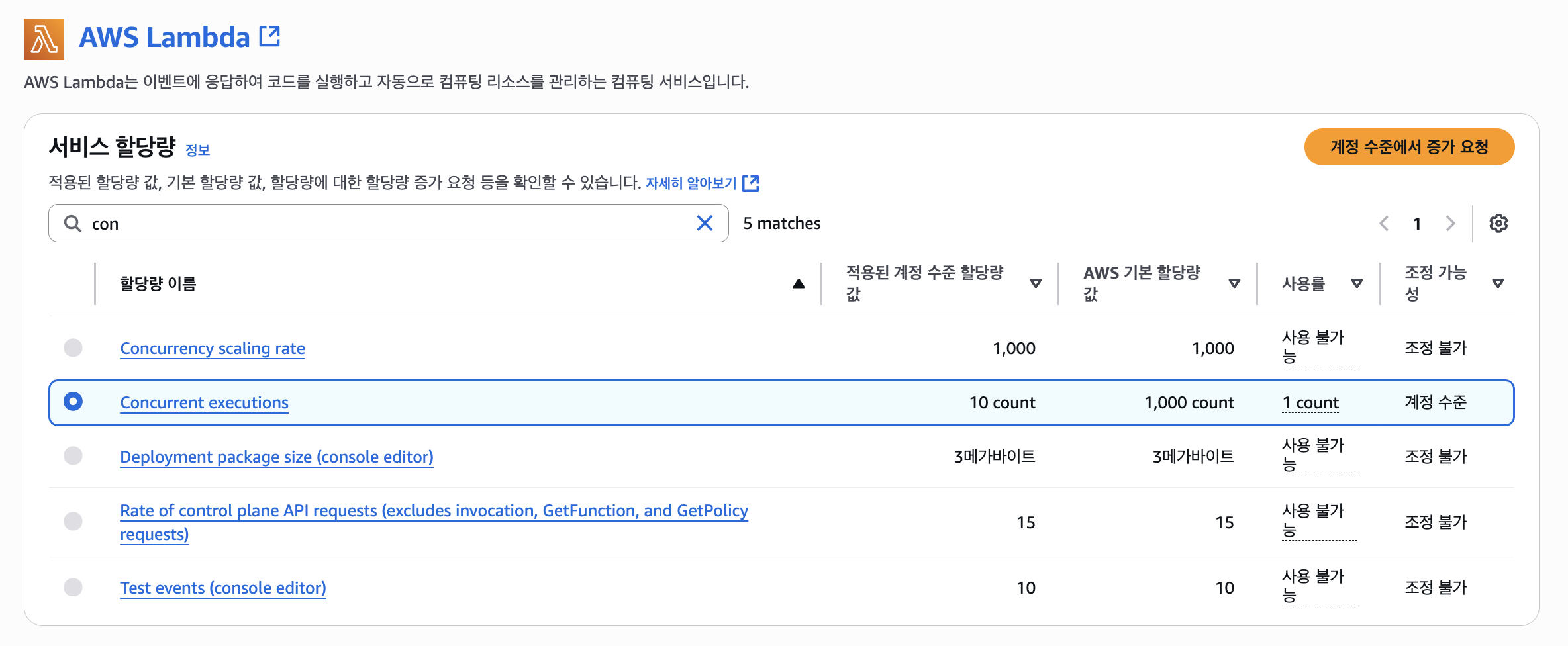
위 사진에선 "예약되지 않은 계정 동시성"이라는 문장을 볼 수 있는데, AWS에선 계정의 리전 별로 동시성의 최대 한도를 1000으로 제한하고 있다.
기본적으로 이 함수에 대해선 10개의 동시성을 기본으로 사용하고, 10개의 동시성을 넘는다면 쓰로틀(Throttled)되어 이벤트를 받을 수 없게 된다.
그렇게 10개의 제한을 꽉 채운다면 남은 계정의 동시성 제한은 990개가 된다.
이러한 동시성은 아래의 옵션인 "동시성 예약"을 통해 최대 동시성의 제한을 둘 수 있다.
그런데 계정 별로 최대 한도를 1000으로 제한하고 있는데, 왜 예약되지 않은 계정 동시성은 10으로 뜰까?
필자도 그 이유가 궁금하여 Service Quotas에서 확인한 결과, 기본적으로 10으로 설정되어 있음을 확인했다.
이 계정만 그런건지, 아니면 모든 계정이 기본적으로 10으로 설정된 것인지는 모르겠지만 이는 AWS에 요청을 통해 증가시킬 수 있다.
Lambda Cold Start Prevention
방금 설명했던 내용은 여러 요청이 발생했을 때 동시성에 대한 이야기였고, 그럼 계속 Warm Start가 가능한 상태를 유지할 순 없을까?
Warm Start가 발생되는 매커니즘을 생각해본다면 한가지 아이디어가 떠오를 수 있다.
람다는 어떠한 함수를 실행하면 일정 기간 동안은 해당 람다 함수의 환경이 유지된다.
그리고 그 유지되는 기간 + Idle 상태까지 된 상태에서 이벤트가 발생하면 Warm Start 현상이 발생한다는 것이다.
즉 해당 람다 함수에 주기적으로 요청을 보내면 그 람다 함수를 Warm Start로 실행할 수 있게 할 수 있다.
(1) EventBridge Scheduler
AWS엔 EventBridge라는 서비스가 있는데, 이 서비스는 어떠한 다른 서비스의 이벤트를 감지하거나 스케줄러(Scheduler) 등의 기능을 사용할 수 있다.
이 중 스케줄러를 사용하여 주기적으로 Ping 등의 요청을 보내는 것을 통해 람다의 Warm Start로 실행될 수 있는 환경을 유지한다.
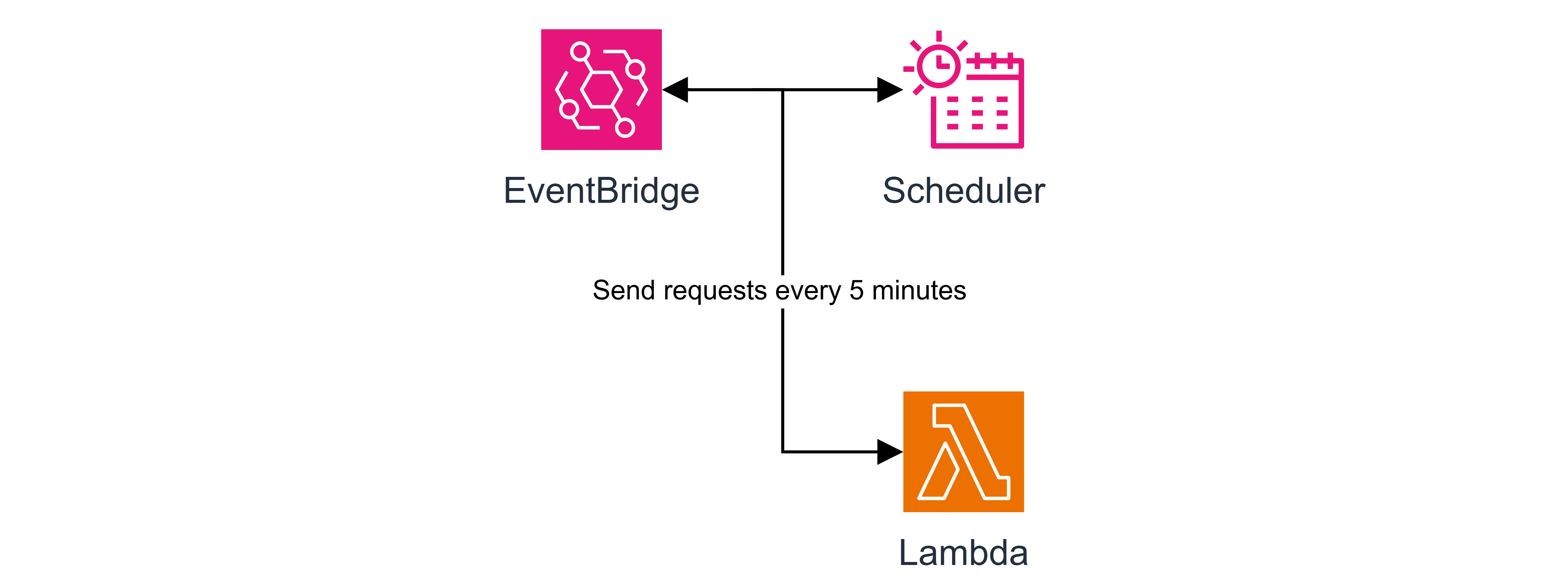
물론 약간의 비용이 발생할 순 있으나 그 비용은 미미하고, 또 성능 상 크게 문제가 될만하진 않기 때문에 꽤나 자주 이용하는 편이다.
다만 이 방식을 100% 신뢰하면 안되는게, Warm Start가 가능한 상태의 유지 시간을 AWS에서 공식적으로 말하지 않았기 때문이다.
일부 개발자들에 의하면 보통은 5분 내외, 또는 10분 정도로 보고 있다고 하지만,
이 또한 람다의 성능에 따라 달라질 수 있다고 하니 여러 테스트를 통해 몇 분의 주기로 설정할진 직접 정해야할 듯 싶다.
(2) Provisioned Concurrency
앞서 설명한 EventBridge 스케줄러를 사용한 방식은 Cold Start 방지에 대해 100% 보장을 하지 않는다.
쉽게 말해 Cold Start 현상이 발생할 수 있다는 것이다.
람다에선 Provisioned Concurrency(프로비저닝된 동시성)이라는 기능을 지원하는데, 이를 사용하면 "확실하게" Warm Start를 보장할 수 있다.
원리는 간단한데, 그냥 람다의 환경을 주기적으로 띄워주는 것이다.
프로비저닝된 동시성 설정에서 몇개의 환경을 띄워줄지를 정하고, 이에 따라 추가적인 요금이 발생한다.
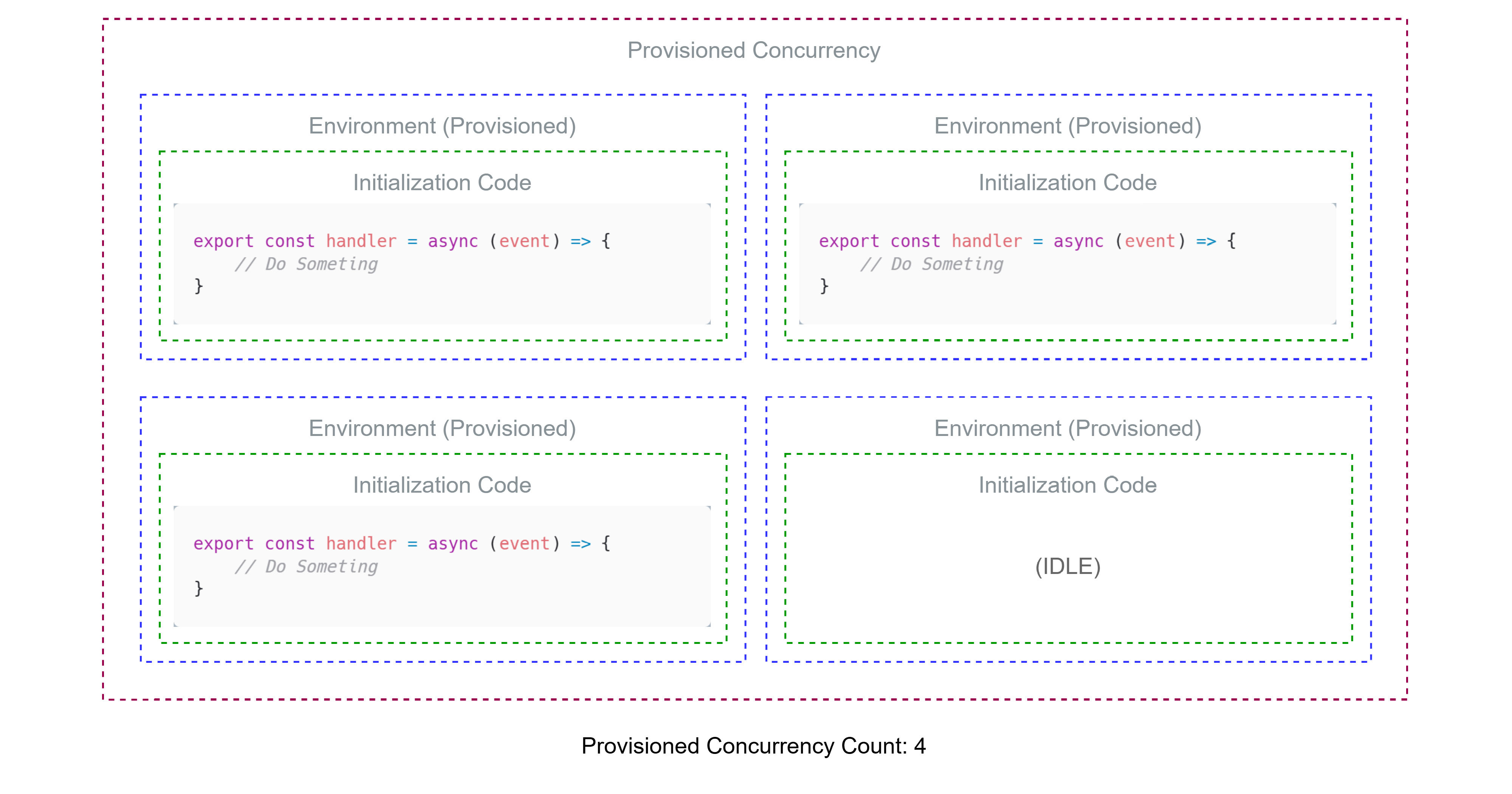
Provisioned Concurrency의 요금이 더 비싼데, 굳이 왜 이걸 사용하려는 것일까 의문이 들 수 있다.
이는 SLA(Service Level Agreement)에 따른 요금의 발생인데, 쉽게 말해 돈을 좀 더 주면 AWS에서 가용성, 안정성 등을 보장하고 제공한다는 의미이다.
즉 Provisioned Concurrency은 실시간 응답이나 속도 등이 중요한 서비스에 활용할 수 있으며, EventBridge Scheduler를 사용한 방법이 별로라는 것은 아니다.
물론 Provisioned Concurrency은 SLA에 따라 Cold Start 현상을 방지하는 것을 보장한다.
추가적으로 프로비저닝된 동시성에도 오토스케일링을 지정할 수 있는데, 자세한 내용은 다른 포스팅이나 공식 문서를 참조하도록 하고, 이 포스팅에선 다루지 않는다.
(3) Increase Memory
람다에서 메모리를 증가시킨다는 것은 곧 CPU 성능도 같이 향상된다.
즉 가장 단순하지만 금전적 여유만 된다면 가장 확실한 방법으로, 비용 계산을 효율적으로 하여 메모리를 늘리는 방법도 Cold Start를 대응하는 방법 중 하나이다.
Lambda Limit
람다에선 실행에 대한 제한과 배포에 대한 제한이 존재하는데, 아래와 같은 제한이 존재한다.
더욱 자세한 내용은 아래의 공식 문서를 참조하길 바란다.
https://docs.aws.amazon.com/lambda/latest/dg/gettingstarted-limits.html
Execution Limit
먼저 람다가 실행되는 환경에 대한 제한은 아래와 같다.
| 항목 | 제한 | 기타 |
|---|---|---|
| 메모리 | 128MB ~ 10GB | 메모리에 따라 CPU 성능이 같이 증가함, 1MB 단위로 조절 가능 |
| 실행 시간 | 최대 15분(900초) | 기본 값은 3초 |
/tmp 용량 | 512MB | 임시 파일을 저장하는 용도로 람다에서 /tmp 디렉토리를 사용할 수 있음. |
| 동시성 | 최대 1000개 | 리전 단위 당 최대 1000개 제한 |
Deployment Limit
또한 람다 함수를 업로드하거나 배포할 때 코드의 크기 제한이 있는데, 아래와 같이 제한된다.
| 방식 | 제한 | 기타 |
|---|---|---|
| ZIP 파일 직접 업로드 | 최대 50MB | |
| ZIP 파일 S3 업로드 및 연동 | 최대 250MB | |
| ZIP 압축 해제 이후 코드 | 최대 250MB | AWS 내부에서 언팩된 코드의 사이즈 |
| 도커 컨테이너 이미지 | 최대 10GB | ECR 업로드 후 람다에서 컨테이너 이미지 사용 가능 |
| 레이어 결합 | 최대 5개 | |
| 개별 레이어 | 압축 후 최대 50MB | 레이어 총합 압축 해제 후 최대 250MB 이내 |
그래서 이 포스팅에선 용량을 초과하지 않아 추후 Serverless Framework를 사용하여 ZIP + S3 배포를 하기 때문에 최대 250MB로 제한된다.
하지만 코드가 그 만큼 크지 않으므로 그냥 사용하지만, 사이즈가 250MB를 초과할 경우 도커로 컨테이너 이미지를 만든 후 ECR(Elastic Container Registry)에 업로드하여 람다에서 사용하는 것이 일반적이다.
그리고 람다 파트에서 설명하지 않은 내용 중 레이어(Layer)라는 개념도 존재하는데, 쉽게 말해 함수 코드 외에 의존성 등을 레이어에 업로드해두면 여러 함수에서 돌려쓸 수 있는 기능이다.
하지만 이 포스팅에선 다루지 않으며, 따로 설명하지도 않겠다.
4-2. API Gateway
람다의 이야기를 끝냈으니, 다음으로 람다를 사용한 AWS 서버리스 구축에서 빠질 수 없는 API Gateway에 대해 이야기 하려고 한다.
만약 여러 기능들을 구현하여 MSA 아키텍쳐를 유지하고, 여러 람다 함수들이 있다고 가정해보자.
각 람다 함수엔 호출가능한 HTTP 요청이 가능한 함수 URL를 제공하는데, 그럼 아래의 아키텍쳐를 보자.
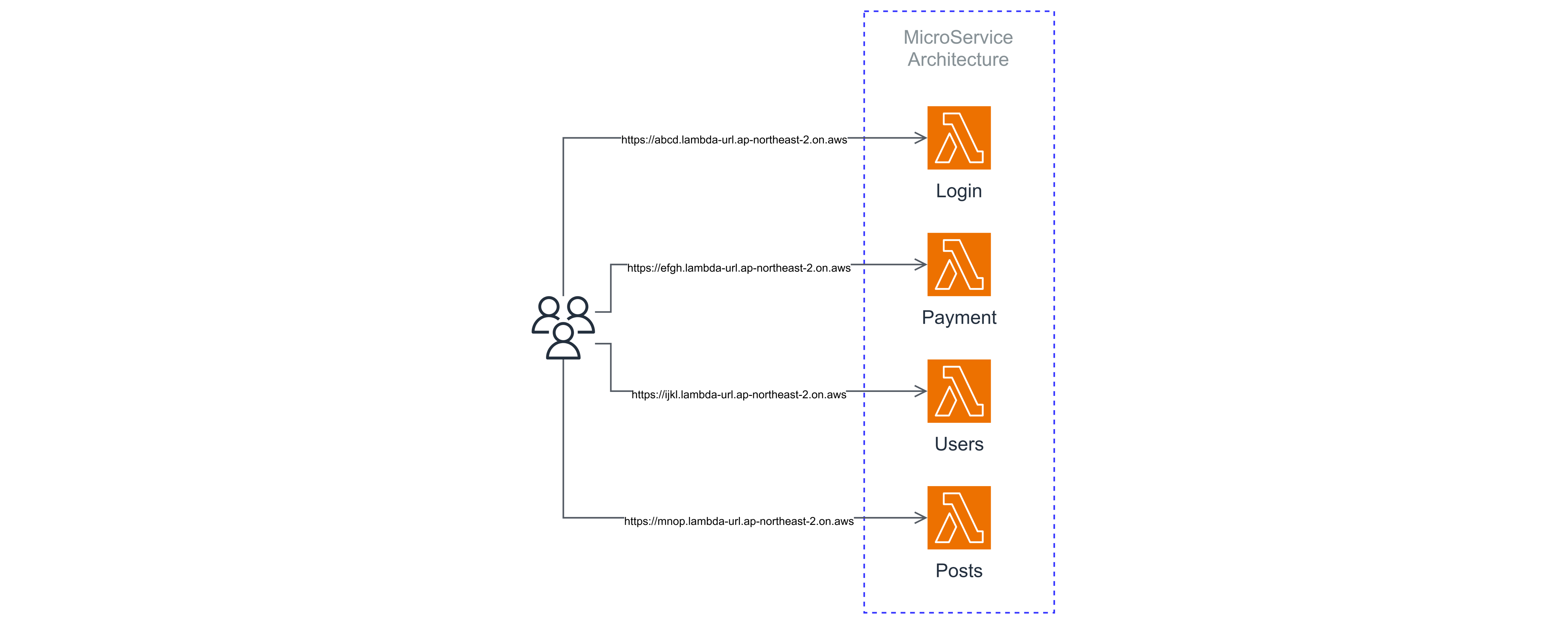
위 아키텍쳐에선 람다 함수마다 함수 URL을 가지고 있고, 클라이언트 입장에선 각 람다 함수(서비스 또는 기능) 별로 요청을 보낼 URL을 알고있어야 하니, 이러한 구조는 매우 비효율적이다.
또한 이러한 MSA 아키텍쳐에선 각 서비스(람다 함수)는 독립적이고 유연하며 특정 기능만을 담당하는게 좋은데, 예를 들어 JWT 인증 등의 경우 위와 같은 아키텍쳐에선 모든 람다에 하나하나 인증과 관련된 로직을 추가해야된다.

위와 같은 불편한 점으로 인해, MSA 아키텍쳐에선 여러 마이크로 서비스를 통합하는 인터페이스(또는 User Interface=UI)를 맨 앞단에 두게 되는데(일종의 프록시임), AWS에선 API Gateway를 사용하여 람다들을 통합하고 하나의 리소스(URL)로 제공한다.
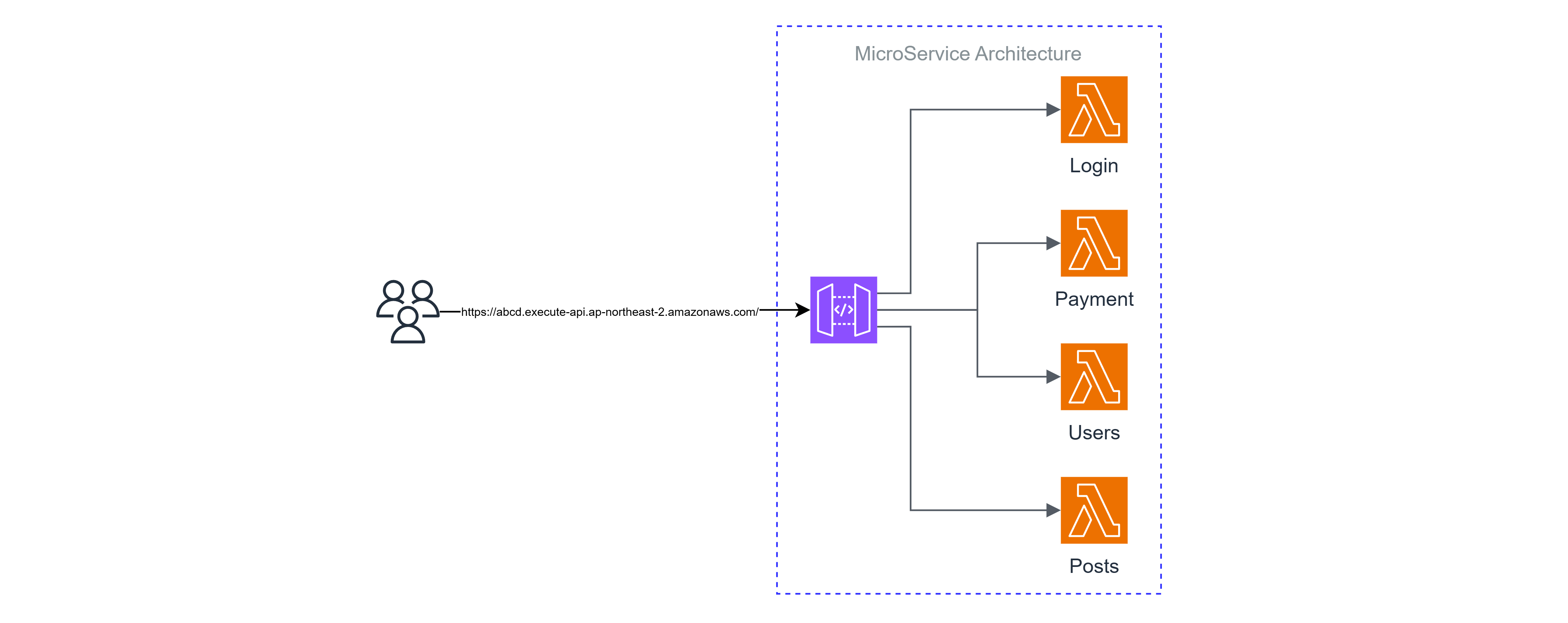
더 자세히 말하자면, 클라이언트와 람다 사이의 프록시 역할은 한다는 표현이 더욱 정확하다.
여러 람다들을 하나의 리소스(URL)로 통합하고, 거기에 클라이언트의 요청을 적절하게 람다로 라우팅해주며 API 관리, 통계 및 이번 주제의 핵심 중 하나인 인증 기능까지 가지고 있는 서비스이다.
그 중 인증, 특히 JWT 인증의 경우 AWS의 Cognito라는 IDaaS(Identity as a Service) 서비스와 연동하면 더욱 더 큰 힘을 발휘할 수 있다. (이에 대한 아키텍쳐는 4번째 파트의 맨 처음에서 확인할 수 있다.)
더욱 더 자세한 이야기는 인프라를 직접 구축해보면서 알아보도록 하고, 다음으론 바로 DynomoDB와 Cognito에 대한 소개로 넘어가려 하였으나, CORS(Cross Origin Resource Sharing)에 대한 이야기를 빠트릴 순 없어서 따로 준비하였다.
CORS(Cross Origin Resource Sharing)
적어도 이 프로젝트를 진행하면서 계속 나올 개념이라 한번쯤 소개하고 넘어가려 한다.
먼저 CORS(Cross Origin Resource Sharing)에 대해 이해하기 위해선 SOP(Same Origin Policy)에 대해 잠깐 알아보자.
SOP는 풀네임에서 알 수 있듯이, 같은 오리진에서만 리소스를 공유하게 하는 보안 상의 정책이다.
여기서 오리진(Origin)은 프로토콜, 호스트 또는 도메인, 포트를 묶어서 부르는 용어로, 리소스의 출처라고 표현하기도 한다.

아무래도 같은 오리진(출처) 내에서의 리소스 공유가 가장 안전하고, 외부의 리소스를 가져오는 것은 보안 상 문제가 될 수 있기 때문이다.
하지만 웹 개발을 하다보면 어쩔 수 없게 외부의 리소스를 가져와야 할 때가 있는데, 이때 CORS(Cross Origin Resource Sharing) 정책을 지킨 리소스라면 이 요청을 허용하게 된다.
여기서 Cross Origin은 직역하면 교차 출처라고 해석되지만, 쉽게 "다른 출처"라고 설명하겠다.
How it Works?
CORS의 기본적인 동작 과정은 아래와 같다.
만약 웹 페이지가 현재 오리진과 다른 오리진의 리소스를 요청하게 되면, 일단은 그 응답을 받아오게 된다.
하지만 서버에서 보내온 응답에 웹 페이지의 오리진을 명시적으로 허용하지 않으면 브라우저는 이 요청을 파기하게 된다.
아래의 두 가지 예시를 보자.

첫번째 예시는 서버에 접근하는데, 클라이언트의 오리진은 https://example-bar.com이다. 일단 서버에 요청을 보내는데, 그 응답으로 Access-Control-Allow-Origin: https://example-bar.com 헤더가 포함된 응답을 받게 된다.
이 헤더는 해당 크로스 오리진은 CORS 정책에 따라 허용한다고 명시하고, 브라우저도 이에 따라 요청을 허용한다.
하지만 만약 아래와 같이 Access-Control-Allow-Origin 헤더에 적힌 오리진이 클라이언트의 오리진이 아니라면 어떨까?

요청을 하는 클라이언트의 오리진은 https://example-bar.com인데, 서버는 응답으로 Access-Control-Allow-Origin: https://example-foo.com 헤더를 포함하여 보내왔다.
때문에 브라우저는 이 응답을 보고 해당 요청은 CORS 정책에 따라 허락하지 않는다.
또한 Access-Control-Allow-Origin 헤더엔 와일드카드에서 모든 것을 허락한다는 *를 사용할 수 있는데, 인증이 필요하지 않은 공개 API를 제외하면 보안 상 사용해선 안된다.
특히 인증 정보가 포함되어 있는, 즉 JWT 토큰 등이 포함된 Authentication 헤더나 쿠키가 포함된 요청을 보낼 땐 더욱 까다롭다.

위와 같이 먼저 클라이언트 입장에선 예를 들어 axios HTTP 통신 라이브러리를 사용한다고 치면 withCredentials: true 옵션을 활성화해야 Authentication 헤더나 쿠키가 전송된다.
또한 서버에선 Access-Control-Allow-Credentials 헤더를 true로 설정해둬야 브라우저에서 이 요청은 안전하다고 판단한다.
만약 클라이언트에서 인증 정보를 포함하여 요청하였는데, Access-Control-Allow-Credentials: true가 아니라면 해당 요청은 보안 상 인증 정보를 보내기에 안전하지 못하다고 판단한다.
때문에 Access-Control-Allow-Origin 헤더에 와일드카드 *를 사용할 수 없는 것이고, 오리진을 명시적으로 표기해야된다.
이 포스팅에선 Preflight Request와 같은 좀 더 깊은 내용의 CORS에 대해선 따로 다루지 않는다.
이에 따라
Access-Control-Allow-Methods등의 Preflight Request와 관련된 내용도 다루지 않는다.
4-3. DynamoDB
DynamoDB는 AWS에서 제공하는 서버리스 기반의 NoSQL 및 Key-Value 구조의 데이터베이스이다.
생소할 수 있는 용어들이 등장하는데, 하나하나 설명하자면 아래와 같다.
Serverless Database
서버리스가 꼭 람다 FaaS처럼 존재하는건 아니다. 서버리스의 뜻 풀이 그대로 서버 관리가 필요가 없다는 뜻임으로, 그러한 서버리스 기반의 데이터베이스도 존재한다.
AWS에세 제공하는 서버리스 기반의 데이터베이스엔 크게 2가지가 있는데, 하나난 RDS(관계형 데이터베이스)인 Aurora Serverless와 이 포스팅에서 소개할 NoSQL인 DynamoDB가 있다.
때문에 다른 서버리스 FaaS인 람다와의 궁합이 좋다.
NoSQL, Key-Value Database
먼저 전통적인 데이터베이스(MySQL 등)는 데이터를 테이블로 구조화하고, 그 테이블들 끼리 관계를 유지하며 상호 작용한다.
또한 SQL이라는 언어를 사용하여 관계형으로 데이터를 관리하는데, NoSQL은 곧 비관계형 데이터베이스를 의미한다.
다만 DynamoDB에선 파티션 키(Partition Key)를 필수로 지정하고, 정렬 키(Sort Key)를 옵션으로 지정할 수 있다.
간단하게 말해서 파티션 키는 기본 키이고, 정렬 키는 복합 키(Composite Key)이다.
이렇듯 기본 키가 존재하고, 그에 대해 값이 존재함으로 Key-Value 데이터베이스로 분류된다. (값들은 속성이라 불린다.)
또한 기본 키를 제외하면 테이블의 속성을 미리 정의 해둘 필요가 없으므로, RDBMS와 달리 유연하게 데이터를 처리할 수 있다.
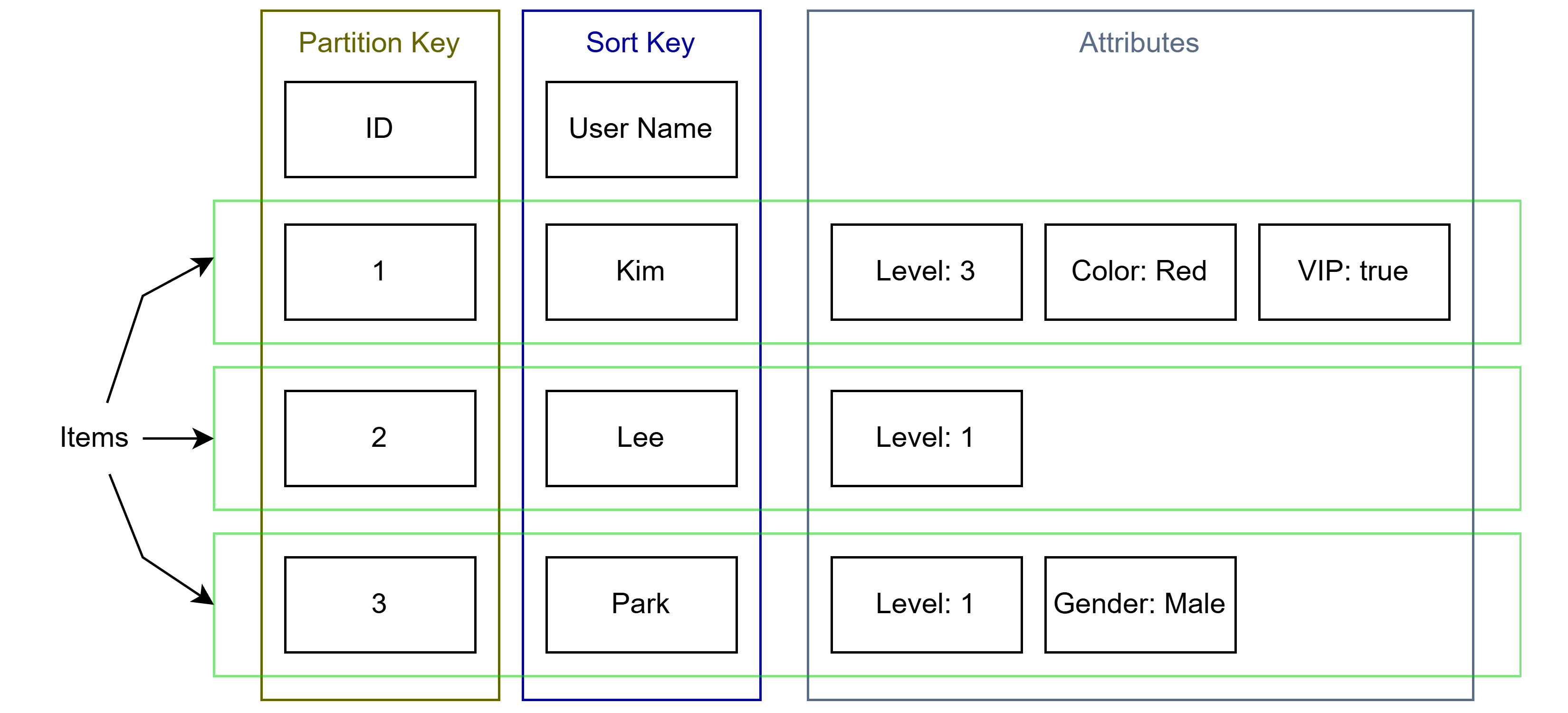
위 사진처럼 각 아이템별로 속성에 대한 스키마를 정의할 필요 없이 유연하게 데이터를 저장하고 관리할 수 있다.
With HTTP Request (Connectionless)
마지막으로 DynamoDB는 HTTP API를 사용하여 통신한다.
전통적인 데이터베이스의 경우 TCP Connection을 통해 데이터베이스와 연결하고 통신하는데, DynamoDB는 Connectionless하게 HTTP API 호출을 통해 데이터를 처리함으로 유연하며 간단하게 코드를 작성할 수 있다.
다만 HTTP API 통신이므로 네트워크적 오버헤드나 레이턴시 등의 문제가 발생할 순 있다.
위와 같은 이유로 해당 포스팅에서 구현하려는 프로젝트에 DynamoDB를 채택하였다.
서버리스 람다 사용 시 무조건 DynamoDB와 같은 오해는 하지 않기를 바라며, DynamoDB의 간단함과 유연함이 간단한 Toy 프로젝트를 구현하는데 적합하다고 생각하였기 때문이라는 것만 알고있다면 좋을 것 같다.
4-4. Cognito
원래 로그인, 회원가입 같은 인증(Authorization)과 권한 확인 등에서 필요한 인가(Authentication) 기능을 직접 구현하였다.
모놀리식 아키텍쳐에선 그러한 구현이 가능하였으나, 서버리스 MSA 아키텍쳐에선 각 서비스별로 독립되어 있고, 인증과 인가 기능을 구현하기 위해선 각 서비스마다 구현을 다시 해주어야 했다.
하지만 그렇게 되면 마이크로 서비스에 대해 코드도 복잡해지고 관리하기에도 어려움이 생겼다.
그래서 각 마이크로 서비스 내에서 직접 구현하지 않고, 인증과 인가 자체를 다른 클라우드 환경으로 분리시켜 관리하니, 그것이 바로 IDaaS(Identity as a Service)이다
IDaaS(Identity as a Service)
클라우드 시대가 오면서 여러 서비스의 형태가 생겨나기 시작했는데, 그 중 IDaaS(Identity as a Service)라는 서비스의 형태가 있다.
이름 그대로 클라우드 형태로 인증과 인가를 제공하는 SaaS(Software as a Service)의 일종이다.
즉 인증과 인가에 관련하여 직접 구현할 필요 없이 클라우드에서 제공하는 인증과 인가를 사용할 수 있다는 것인데, 이것이 서버리스 MSA 아키텍쳐의 핵심이다.
그 중 외부 인증 서비스(예: 구글 계정 등)와 연동 할 수 있는 OAuth와 OIDC 등의 개념과 한번의 로그인으로 여러 서비스를 이용할 수 있게 하는 SSO(Single Sign On) 등의 요소도 있으나, 해당 포스트에선 이러한 개념까지 다루지는 않는다.
IDaaS on AWS
그래서 서버리스 MSA 아키텍쳐에선 IDaaS 형태로 동작하는 인증, 인가 서비스를 사용하는 것이 좋은 선택인데, AWS에서도 대표적인 IDaaS 서비스를 제공한다.
그것이 바로 현재 주제인 AWS Cognito인데, 주로 인증과 인가(권한 부여 등)에 대한 서비스를 제공하고, 구글이나 페이스북 같은 타사의 인증(OAuth)을 통해 로그인할 수 있는 기능을 제공한다.
IDaaS 클라우드엔 Okta라는 기업의 서비스가 유명한데, 필자는 써본적도 없고 AWS를 사용한다면 Cognito를 사용하는 것이 연동(특히 후술할 자격 증명 풀 등의 인가 시스템)하기에 더욱 더 뛰어나다.
User Pools
Cognito에선 유저 풀(User Pools)이라는 풀로 사용자를 관리한다.
쉽게 말해 유저들의 정보를 저장하고 관리하는 일종의 데이터베이스가 포함되고, 거기에 OAuth나 JWT, MFA 인증, 에미일 인증 그리고 내장 UI 등의 여러 부가적인 기능이 제공된다.
Cognito의 유저 풀에 회원가입을 진행하면 해당 유저에 대해 데이터가 저장되고, 로그인 시 JWT 엑세스 토큰과 리프레시 토큰, 그리고 ID 토큰(엑세스 토큰보다 더욱 더 구체적인 정보 제공)이 제공된다.
각 유저 풀엔 유저 풀 클라이언트가 존재하는데, 이는 유저 풀에 접근하기 위한 클라이언트를 의미한다.
Cognito를 포함한 AWS의 대부분의 기능과 서비스는 AWS SDK(Software Development Kit)를 통해 제공되는데, 이를 사용하여 /login, /signup, /refresh(엑세스 토큰 리프레시) 등의 API 엔드포인트를 아주 쉽게 구현할 수 있다.
다음은 Cognito SDK를 사용하여 유저 풀에서 회원 정보를 가져와 JWT 토큰을 반환하는 POST /login API 엔드포인트를 타입스크립트로 구현한 코드다.
https://github.com/eocndp/aws-lambda-example/blob/main/backend/functions/auth/login.ts
(코드가 길어 포스팅의 가독성을 떨어트려 위 링크로 대신한다.)
후술하겠지만 JWT 토큰에서 엑세스 토큰 및 ID 토큰은 body에 저장하여 클라이언트에서 메모리(변수) 등에 저장하고, 리프레시 토큰은 HTTPOnly Cookie에 저장하도록 한다.
Identity Pools
아까 Cognito에선 인증과 인가 기능 모두를 제공한다고 하였는데, 유저 풀이 인증을 담당한다면 인가 기능은 자격 증명 풀(Identity Pools)로 제공한다.
인증된 사용자에 대해서 AWS의 서비스 권한을 부여할 수 있는 기능이다.
예를 들어, 어느 사용자에 대해 특정 S3 접근을 허용하도록 하려면 자격 증명 풀을 사용하면 된다.
본 포스팅에선 자격 증명 풀에 대해선 다루지 않고, 유저 풀을 사용한 회원가입/로그인/JWT 인증에 대해 다루며, API Gateway와 통합하여 자동으로 JWT 검증까지 하는 구조로 나아가볼 것이다.
JWT(JSON Web Token)
앞서 JWT 토큰에 대해서 언급을 했었는데, JWT(JSON Web Token)이 무엇인지, 그리고 기존의 세션 방식과의 차이는 무엇인지 알고 넘어가도록 하자.
vs Session
JWT이나 세션(Session) 방식 모두 로그인 후, 그 로그인 상태를 유지하기 위해 사용된다.
어느 서비스에 로그인하였고, 이로써 인증과 관련된 정보를 서버에서 받아와 클라이언트에 저장하고 추후에 인증이 필요한 API를 요청할 때 해당 정보를 넘김으로써 인증하는 것이 일반적인 인증의 방식이다.
하지만 이때 서버에서 어떠한 값을 받아오고 어떠한 값으로 인증을 하기 위해 넘기는지에 따라 크게 세션 방식과 JWT 방식으로 나뉘게 되는 것이다.
세션(Session) 방식은 서버에서 암호화된 세션 아이디를 받아오는데, 서버는 클라이언트가 로그인을 하면 이 세션 아이디를 만들고, 클라이언트에 전달함과 동시에 서버의 데이터베이스에 이 세션 아이디와 사용자의 정보를 저장한다.
즉 사용자의 정보 등을 가져오기 위해 세션 아이디와 대응되는 별도의 저장소(데이터베이스, Redis 등의 인메모리 DB 등)를 마련해야 한다.
즉 세션 방식의 흐름은 아래와 같다.
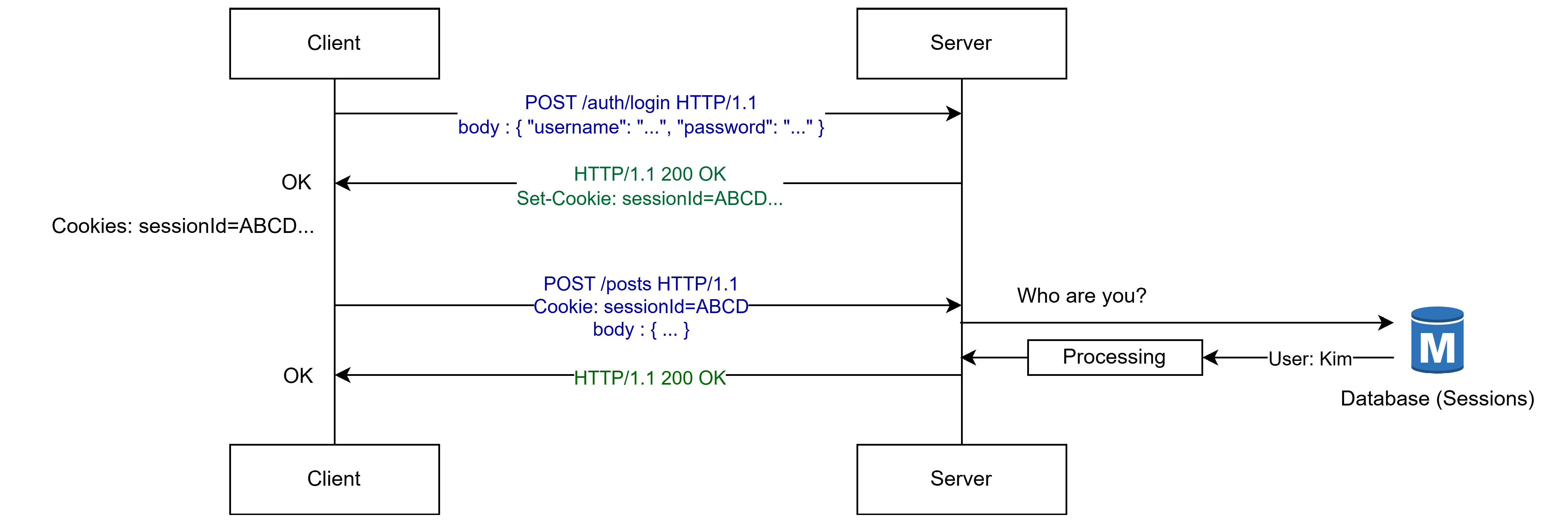
위 사진 자료에서도 볼 수 있듯이 POST /posts 엔드포인트를 요청하여 글을 작성하려 하는데, 클라이언트는 세션 아이디를 쿠키에 담아 요청한다.
이때 서버는 요청을 받았으나, 해당 요청의 쿠키에 포함된 세션 아이디가 누구의 세션 아이디인지 모르니, 세션 아이디를 저장하는 별도의 데이터베이스에 접근하여 유저 정보를 가져오고, 그 이후 API를 처리한다.
즉 인증을 위해선 세션 아이디 데이터베이스에 접근하는 오버헤드가 발생하게 되고, 서비스의 규모가 커질수록 이러한 문제는 더욱 극대화된다.
What is JWT?
JWT은 JSON Web Token의 약자이다. 즉 JSON 객체에 인증에 필요한 데이터(페이로드)를 담은 후, 그 페이로드를 비밀키로 암호화하여 서명하고 검증한다.
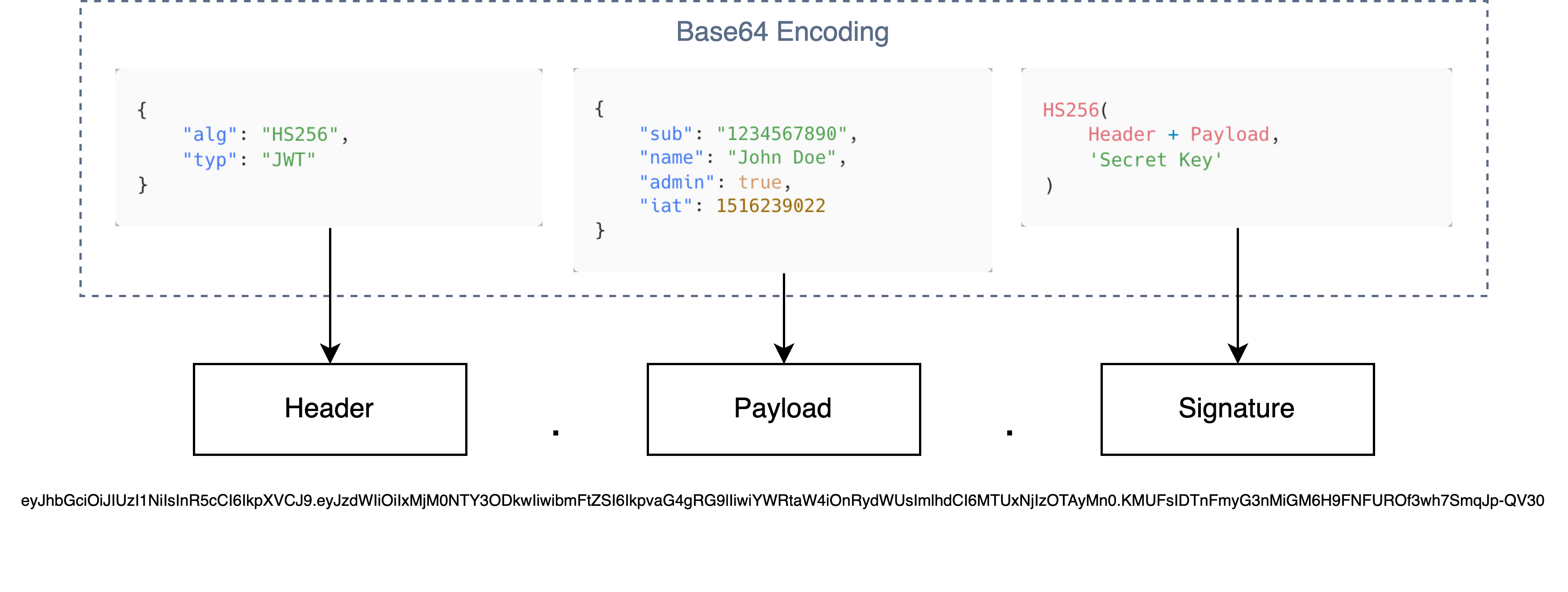
위와 같이 헤더(Header)엔 서명에 사용할 암호화 알고리즘(대부분의 경우 HS256)과 "type": "JWT" 고정 필드가 있다.
그리고 페이로드(Payload)엔 사용자의 이름이나 메일 등의 정보와 토큰의 생성 시간(iat), 그리고 경우에 따라 exp (만료 시간) 등의 다양한 값이 존재한다.
이 페이로드에 포함된 Key-Value 형태의 값을 클레임(Claim)이라 한다.
마지막 서명(Signature)엔 헤더와 페이로드의 값을 비밀 키를 가지고 서명이라는 검증을 위한 문자열을 생성한다.
이 서명을 통해 이 JWT 토큰이 변조되었는지 등을 검증한다.
이렇게 인증을 위한 문자열(토큰) 안에 기본적인 유저의 정보가 포함되어 있으니, 세션 방식과는 다르게 유저 정보를 세션 아이디 데이터베이스에서 가져오는 오버헤드가 발생하지 않는다.
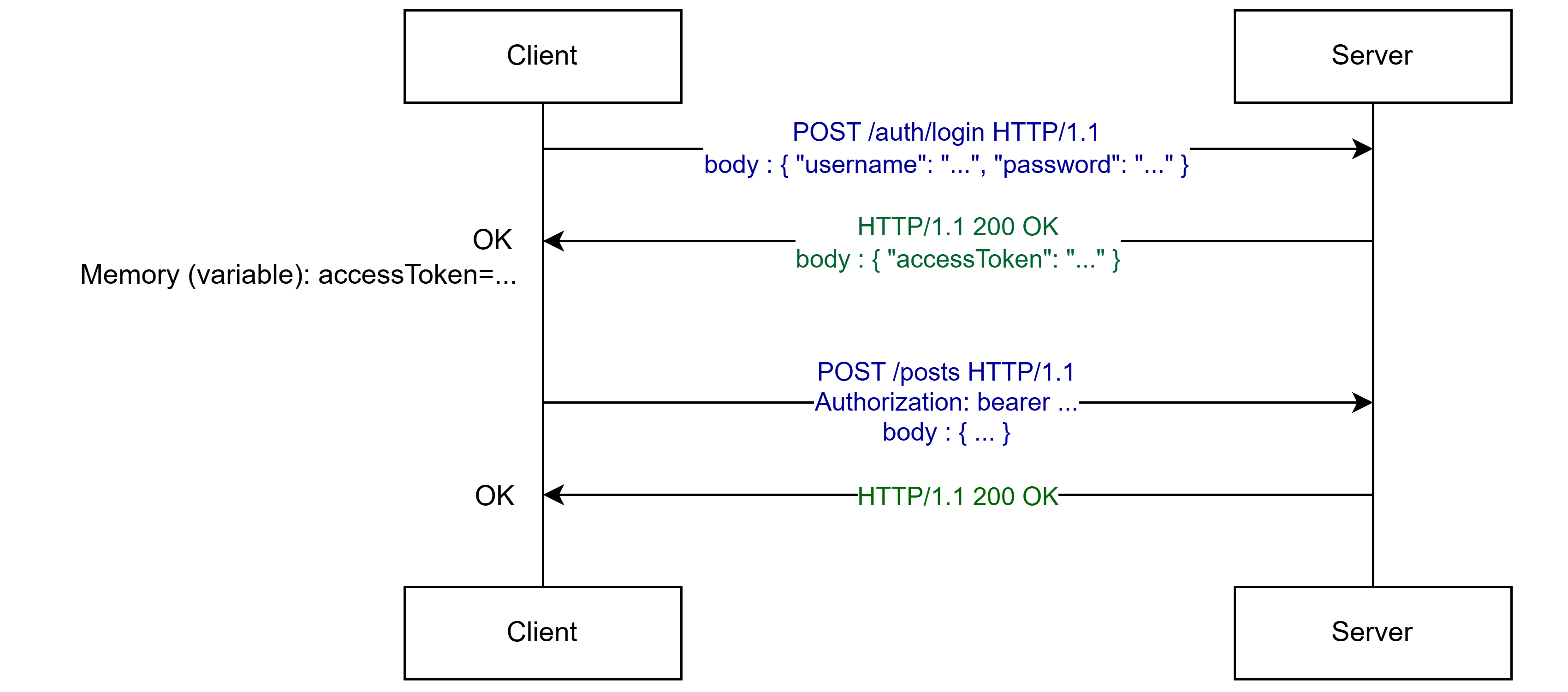
위와 같이 로그인을 하면 JWT 토큰을 반환하는데, 클라이언트는 이 토큰을 적당한 곳에 저장한다. SPA(Single Page Application)의 경우 대부분 변수에 저장하여 클라이언트도 해당 사용자에 대해 간략히 알 수 있게 하고, 페이지가 새로고침 되면 변수가 초기화되니 보안 상으로도 비교적 안전하게 지킬 수 있다.
무엇보다 서버에선 JWT 토큰 내에 어느정도의 정보가 담겨서 오니 세션 방식과는 다르게 추가적인 오버헤드가 발생하지 않고, 효율적이면서 빠른 처리가 가능하다.
다만 더욱 자세한 내용을 알기 위해선 사용자 정보가 있는 데이터베이스에 한번 더 접근해야하긴 하겠지만, 기본적인 정보는 JWT 토큰 내에 포함되어 있기 때문에 큰 문제가 되진 않는다.
요청 시 JWT 토큰을 포함시키려면 Authorization 헤더에 JWT 토큰을 포함시킨다.
JWT 토큰은 대부분 Bearer로 시작하는데, 이건 해당 토큰이 소유자의 토큰이라고 표시하며 JWT 또는 OAuth 방식에 대한 토큰을 사용한다는 의미이다.
Basic(아이디와 비밀번호를 Base64로 인코딩 후 사용) 등의 다른 타입도 존재하나, 여기선 다루지 않는다.
JWT도 만능은 아니다. 그 예시 중 하나는 강제 로그아웃과 같은 문제인데, 세션 방식에선 세션 아이디를 저장하는 데이터베이스에서 원하는 세션 아이디를 삭제시키면 클라이언트에선 자동으로 로그아웃된다.
하지만 JWT 방식의 경우 그렇지 못하는데, Stateful한 세션 방식과는 다르게 Stateless하게 작동하여 의도적으로 직접 만료시킬 수 가 없다.
그래서 JWT 토큰의 페이로드엔 생성일이나 만료일을 설정하는데, 이 만료일을 짧게 설정하여 보안을 유지한다.
JWT 토큰이 만료되면 로그아웃되지 않냐 하겠지만, 곧 알아볼 리프레시 토큰(Refresh Token)을 사용하여 그러한 문제를 해결할 수 있다.
아까 설명에서 JWT 토큰을 변수에 담는다고 하였는데, 이는 쿠키나 로컬 스토리지 등은 XSS 등의 보안 상 문제가 될만한 곳이다.
그렇다고 후술할 HTTPOnly 쿠키에 담는 경우 아예 접근할 수 없는 경우가 되기 때문에 JWT 토큰을 변수에 담는 것이 좋은 방법이다.
하지만 "좋은 방법이다"라고 말한 이유가, 어떻게 저장하는지에 대한 방법은 없기 때문이다. JWT 토큰을 로컬 스토리지나 세션 등에 저장하는 경우도 있고, 그러한 방식은 아키텍쳐나 구조에 따라 달라질 수 있기 때문이다.
Refresh Token
여기까지 제대로 읽었다면 이러한 질문이 들 수 있을 것이다.
" JWT 토큰이 만료되면 다시 로그인을 해야하나? "
위 설명대로라면 그렇겠지만, 실제론 그렇지 않다. 아직 설명하지 않은 개념이 있는데, 바로 리프레시 토큰(Refresh Token)이다.
JWT엔 일반적으로 2가지의 토큰이 존재하는데, 여태 설명했던 인증을 위한 토큰, 엑세스 토큰(Access Token)과 해당 엑세스 토큰을 다시 생성할 수 있게끔 하는 리프레시 토큰(Refresh Token)이 존재한다.
아래의 자료를 참고하며 설명하겠다.
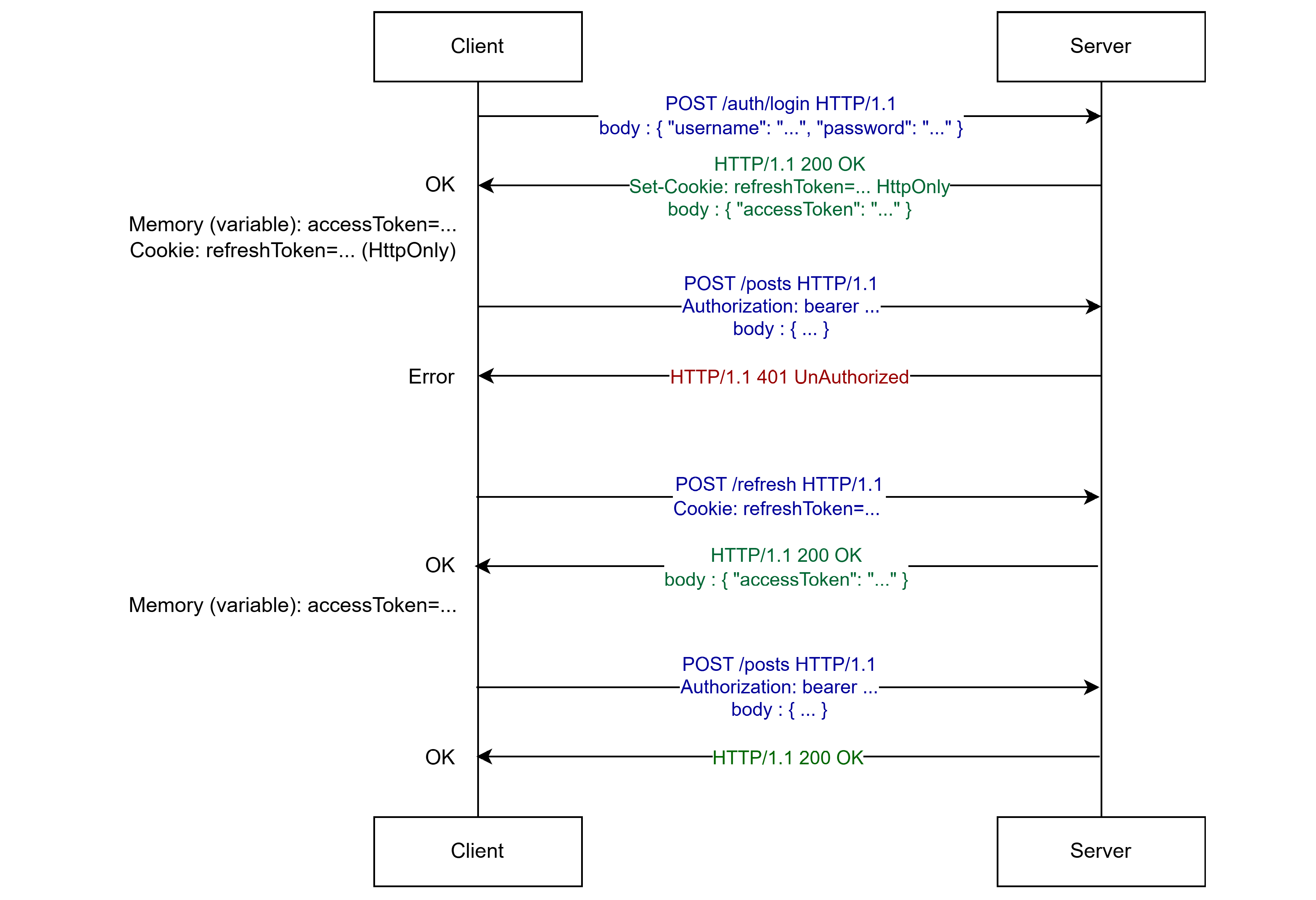
위 자료와 같이 클라이언트에서 요청을 보냈는데 권한이 없다면서 실패하는 경우(또는 토큰이 만료됐다거나), 또는 JWT 엑세스 토큰에 명시되어있는 만료 시간(exp)을 초과하였을 경우 클라이언트는 HTTPOnly 쿠키에 저장된 리프레시 토큰을 가지고 POST /refresh 엔드포인트에 요청을 하여 새로운 엑세스 토큰을 받아온다.
리프레시 토큰은 클라이언트가 로그인을 하면 자동으로 서버엔 리프레시 토큰을 위한 데이터베이스에 해당 리프레시 토큰과 사용자 정보를 저장한다.
그 리프레시 토큰은 클라이언트는 (일반적으로) HTTPOnly 쿠키에 저장한다.
일반적으로 쿠키는 서버의 응답에
Set-Cookie헤더를 통해 클라이언트(=브라우저 등)에 자동으로 저장한다.다른 리소스로 요청(Request) 시 해당 쿠키를 자동으로 포함하여 보내지는(물론 HTTP 클라이언트에
withCredentials: true등의 옵션이 있어야 함),
HTTPOnly 쿠키는 자바스크립트로 접근할 수 없어 XSS 공격 등을 방어할 수 있다.즉 HTTP 통신 시에만 자동으로 포함하는 쿠키로, 자바스크립트로 접근 할 수 없기 때문에 리프레시 토큰을 저장할 때 대부분 HTTPOnly 쿠키에 저장한다.
HTTPOnly 쿠키를 보내기 위해선
HttpOnly옵션을 붙여야 하는데, 같이 붙는 여러 옵션들을 아래에 간략히 정리해두었다.
HttpOnly: HTTPOnly를 적용시키기 위해 필요한 옵션이다.Path: 주로Path=/로 설정되며, 모든 경로에 대해 쿠키를 전송할 수 있도록 한다.Max-Age: 쿠키의 만료 시간으로, 쿠키가 생성된 시점으로 부터 몇 초 동안 유지할건지를 나타낸다. 이는 상대적인 시간이지만,Expires옵션은 절대적인 시간으로 나타내며, 둘 다 설정하지 않는다면 그 쿠키는 브라우저가 종료될 때 없어진다.SameSite: 크로스 사이트(또는 써드파티) 요청에도 이 쿠키를 허용할 것인가를 나타낸다. 예를 들어, 사이트 A에서 사이트 B의 API를 호출할 때SameSite=Strict옵션이 들어가있으면 쿠키를 설정하지 않는다.SameSite=Lax(기본값) 옵션은 GET이나 리다이렉션 등의 비교적 안전한 요청에만 쿠키를 보내며, 마지막으로SameSite=None은 모든 요청에 대해 쿠키를 전송한다. (이 경우엔Secure옵션이 있어야함)Secure: 요청의 오리진이 HTTPS일때만 쿠키를 전송한다. 즉 HTTP 요청엔 쿠키를 보내지 않는데,SameSite=None상태에선 무조건 활성화가 되어야한다.
만약 사용자가 로그아웃을 요청하게 되면, 일단 클라이언트의 저장된 엑세스 토큰을 제거한다.
그리고 서버에 POST /logout 등의 요청을 보내는데, 그러면 서버는 내부의 리프레시 토큰을 저장하는 데이터베이스에서 해당 리프레시 토큰을 삭제한다.
그러면 결국엔 다시 로그인을 해야 리프레시 토큰이 생기는 것이니, 로그아웃 구현이 가능하다.
다만 엑세스 토큰이 만료되지 않았다면 로그아웃 이후에도 해당 엑세스 토큰을 여전히 사용할 수 있는 것이고, 리프레시 토큰이 없기 때문에 이후의 엑세스 토큰 리프레시는 불가능하다.
4-4. S3 + CloudFront (Frontend)
사실 해당 포스팅(발표)에서 프론트엔드는 분량 상 다루지 않으려고 하였으나, 그래도 완성된 무언가가 시각적으로 보여져야 더욱 완벽하다고 생각하여 해당 파트를 추가하였다.
이 포스팅에서 사용할 프론트엔드 아키텍쳐는 간단한데, 바로 S3(Simple Storage Service)와 CloudFront를 사용한 CDN(Content Delivery Network) 사용까지를 목표로 하고있다.
S3(Simple Storage Service)
S3(Simple Storage Service)는 이름 답게 AWS에서 제공하는 클라우드 스토리지 서비스입니다. 말 그대로 파일 등의 데이터를 저장할 수 있는데, 특징은 버킷(Bucket)이라는 일종의 컨테이너를 사용하고, 디렉토리 구조 대신 객체(Object)라는 형태로 데이터를 저장한다.
S3에 저장되는 데이터는 모두 객체인데, 객체는 실제 데이터와 메타데이터(파일의 이름, 생성날짜, 권한 등의 속성)로 이루어져있다.
그리고 S3엔 실제 디렉토리 구조가 없고, 객체의 이름을 /path/file.txt 형태로 저장하며 평면적으로 저장된다.
S3에 대해선 여기까지만 알아보고, 중요한건 S3엔 정적 웹 호스팅을 지원한다는 것이다.
즉 이걸 가지고 프론트엔드를 띄울 수 있다는 얘기인데, 사실 이건 Github Pages 등으로 "무료로" 사용 가능하기도 하다.
하지만 굳이 AWS S3를 선택한 이유는 그 앞에 CDN 서비스인 CloudFront를 쉽게 사용하기 위해, 그리고 S3에 호스팅한다 해도 엄청나게 큰 비용이 발생하는 것은 아니기 때문에 S3 + CloudFront를 선택하였다.
CloudFront
CDN(Content Delivery Network)
앞서 설명한대로 CDN(Content Delivery Network) 서비스인데, CDN은 물리적으로 멀리 떨어진 사용자에게 더욱 더 빠르게 데이터를 전송할 수 있게 하기 위해 여러 곳에 복제된 캐시 서버를 두어 빠른 전송을 가능케 하는 기술이다.
아래 자료를 보도록 하자.
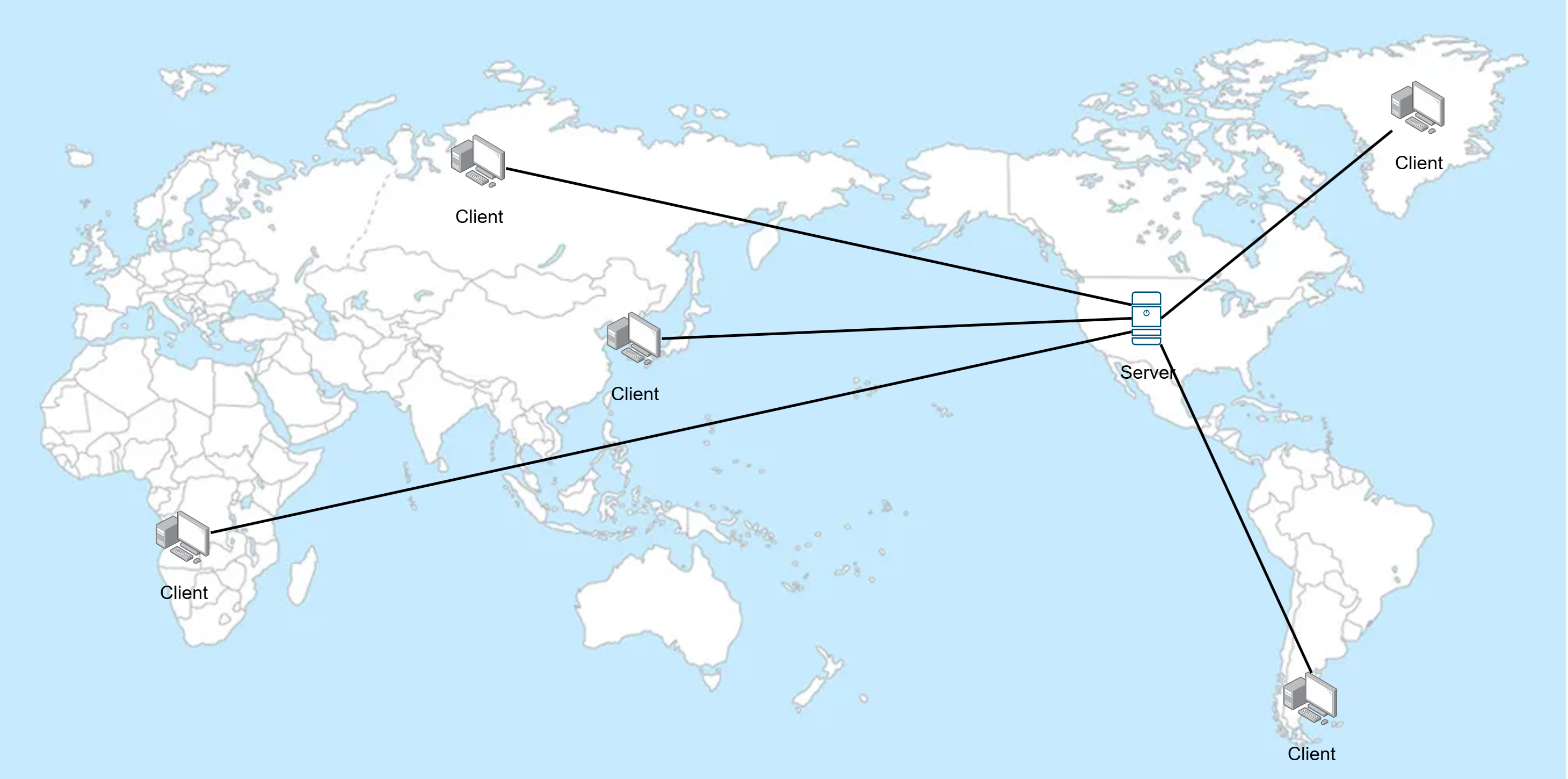
서버는 미국에 하나 밖에 없는데, 클라이언트의 위치는 세계 곳곳에서 접근한다.
그러면 물리적으로 떨어져 있을수록 전송의 속도가 느려질 수 밖에 없는데, 그것을 보완하기 위함이 CDN 서비스이다.
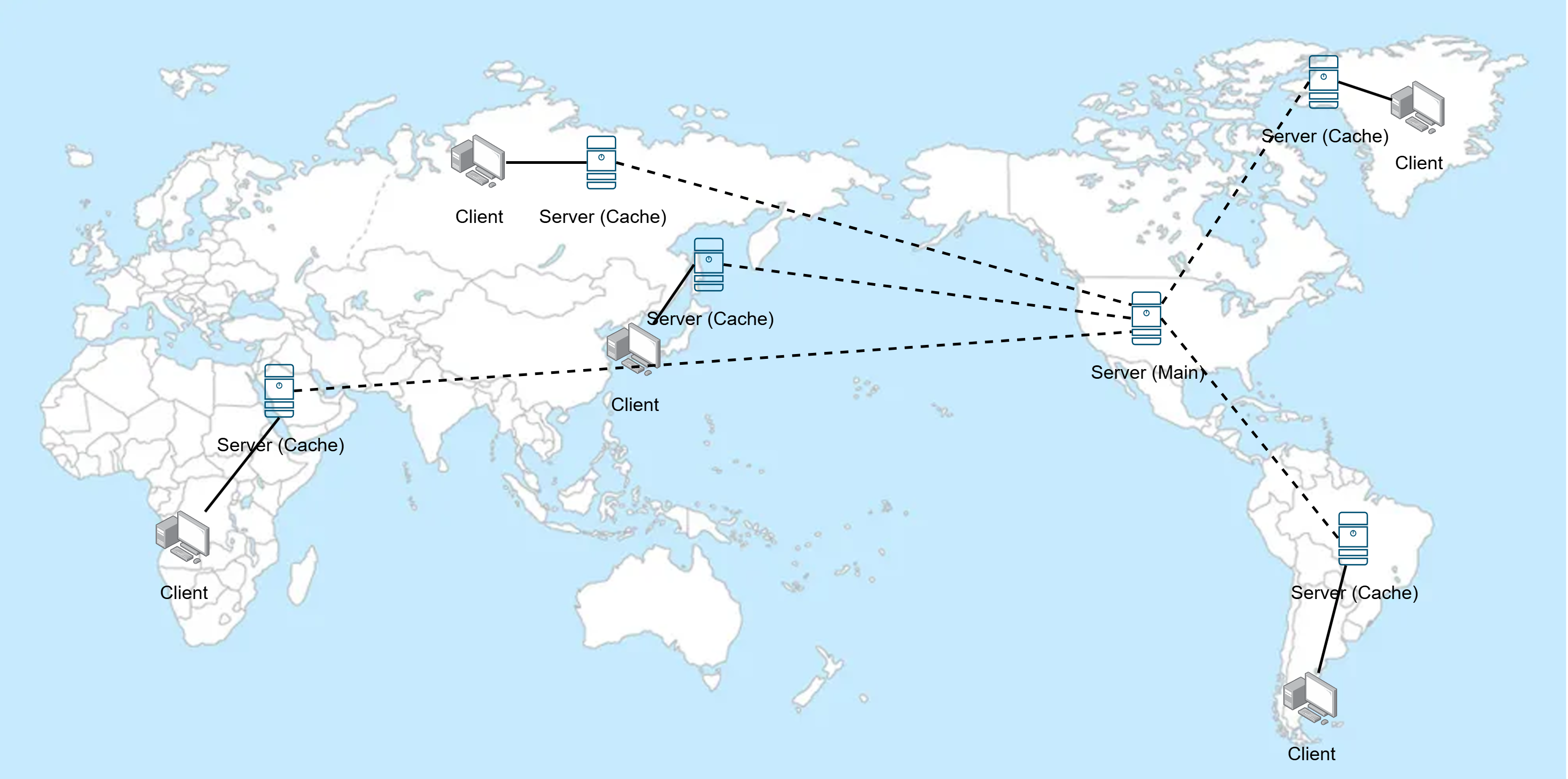
위와 같이 사전에 미리 메인 서버에 대해 캐싱을 해두고, 다른 캐시 서버에 분산해둠으로써 빠르게 데이터를 전송할 수 있다.
또한 메인 서버의 부하를 낮춰주기도 하는 등, 이 또한 금전적인 이유가 아니라면 유용하지 않을 수 가 없다.
CloudFront
CloudFront에선 캐시 서버를 엣지 로케이션(Edge Location)이라 부르는데, 클라이언트가 접속 시 자동으로 최적의 엣지 로케이션을 찾아준다.
새롭게 배포 할땐 캐시를 없애줘야 하는데, 이를 캐시 무효화라고 한다.
또한 CDN을 목적으로 하는 것이 아닌, 오리진을 하나로 통합하는 것으로도 사용이 가능하다. (여러 오리진을 사용하는 것이 가능함)
추가적으로, 람다와 연계하여 CloudFront에 람다 함수를 배포하여 CDN 처럼 사용할 수 있는데, 이를 Lambda@Edge라 부른다. 쉽게 설명하자면 그냥 CloudFront의 엣지 로케이션에서 돌아가는 람다이다.
해당 포스팅에선 Lambda@Edge에 대해선 다루지 않는다.
4-5. Serverless Framework
일단 Serverless Framework를 다루기 전에, 기반이 되는 AWS Cloudformation에 대해 먼저 알아보도록 하자.
IaC(Infrastructure as Code)
서버리스 인프라를 구성하다보면 문득 이런 생각이 들 수 있다.
" 서버 관리가 불필요한데, 이렇게 복잡한 인프라를 직접 수정하다니 이게 맞나 .. "
실제로도 그렇다. 클라우드 환경에선 서비스를 운영하다보면 서버나 데이터베이스, IAM, S3 등의 여러 서비스들을 반복적으로 설정하고 수정하는 등 복잡한데, 이건 서버리스에서도 마찬가지다.
만약 전체적으로 람다 코드를 실행하였고, API Gateway의 엔드포인트가 일부 변경되었다면 어떻게 수정을 해야할까?
만약 AWS Console에서 직접 클릭한다면 아래와 같이 진행될 것이다.
- 수정된 람다 함수들을 하나하나 직접 수정 후 Deploy 버튼 클릭
- API Gateway에서 변경된 엔드포인트를 하나하나 직접 변경
하지만 이러면 실수하기도 쉽고, 협업하기도 어려우며 버전 관리도 안되는 점, 무엇보다 귀찮은 점 등 불편한 점이 한두가지가 아닐것이다.
만약 aws CLI를 사용해 자동화 코드를 만든다해도, 위와 같은 불편한 점은 그대로 일 것이다.
그래서 등장한 개념이 있는데, IaC(Infrastructure as Code), 즉 인프라를 코드로 작성한다는 것이다.
JSON, YAML, HCL(테라폼) 등의 포맷으로 인프라를 구성하고, 해당 인프라에 대해 세부적인 설정을 코드로 작성한다는 것이다.
이렇게 구성된 IaC는 선언형 코드로 정의하고, 배포 시 자동으로 버전 관리 및 로깅 등의 기능을 지원한다.
명령형 코드의 경우, 주로 절차를 정의하는데, 예를 들어 아래와 같다.
람다 HelloLambda를 생성하고 "index.js" 코드를 올린 후, API Gateway의 "/hello" 엔드포인트에 그 람다를 연결해라반면 선언형 코드는 그 결과를 직접 입력하는 것인데, 위 코드를 선언형 코드로 변경하면 아래와 같아진다.
HelloLambda: SourceCode="index.js" API Gateway: "/hello"="HelloLambda"대부분의 경우 IaC는 선언형으로 작성된다.
또한 이 포스팅에서 잠깐 다룰 Github Actions 등의 CI/CD(지속적 통합, 지속적 배포) 자동화와 조합하여 더욱 더 강력하게 만들 수 있다.
CloudFormation
CloudFormation은 AWS에서 제공하는 IaC 서비스이다.
YAML이나 JSON 형태로 코드를 작성할 수 있는데, 이 포스팅에선 YAML을 사용한다. 주석을 지원하며, JSON보다 코드의 가독성이 더 괜찮다고 판단하였기 때문이다.
그러한 선언적 코드를 템플릿(Template)이라 부른다.
템플릿의 요소로는 아래와 같은 대표적인 요소가 있다.
AWSTemplateFormatVersion: 템플릿 버전, 현재까진2010-09-09가 유일하다.Description: 템플릿 설명Parameters: 외부(CLI 등에서 실행 시 주입 가능)에서 값을 받아 사용 할 수 있다.Resources: 실제로 생성할 AWS 리소스들의 목록이다. (필수임)Outputs: 생성된 스택의 결과를 노출하기 위해 사용한다.
그리고 스택(Stack)이라는 개념이 있는데, 위 템플릿을 바탕으로 실제로 생성된 AWS 리소스를 말한다.
즉 생성된 리소스들의 집합을 말하는데, 만약 이렇게 생성된 인프라가 필요하지 않을 경우 스택을 삭제하면 AWS 리소스들도 같이 삭제된다.
실습을 해보자, 아래와 같은 AWS CloudFormation 템플릿 YAML 코드를 사용하면 S3 버킷을 코드를 사용하여 생성할 수 있다.
AWSTemplateFormatVersion: '2010-09-09' # 템플릿 버전 (현재까진 2010-09-09가 유일함)
Description: 'Example Cloudformation Template' # 설명
Resources: # 리소스 목록
TestBucket: # 논리적인 리소스 이름: TestBucket
Type: AWS::S3::Bucket # 서비스 이름: S3
Properties: # 속성
BucketName: test1234 # 버킷 이름 지정: test1234
AccessControl: Private # 프라이빗으로
VersioningConfiguration:
Status: Enabled # 버전 관리 사용이런식으로 작성하면 되며, 실제로 테스트해보자. AWS > CloudFormation으로 들어가 "스택 생성"을 클릭한다.
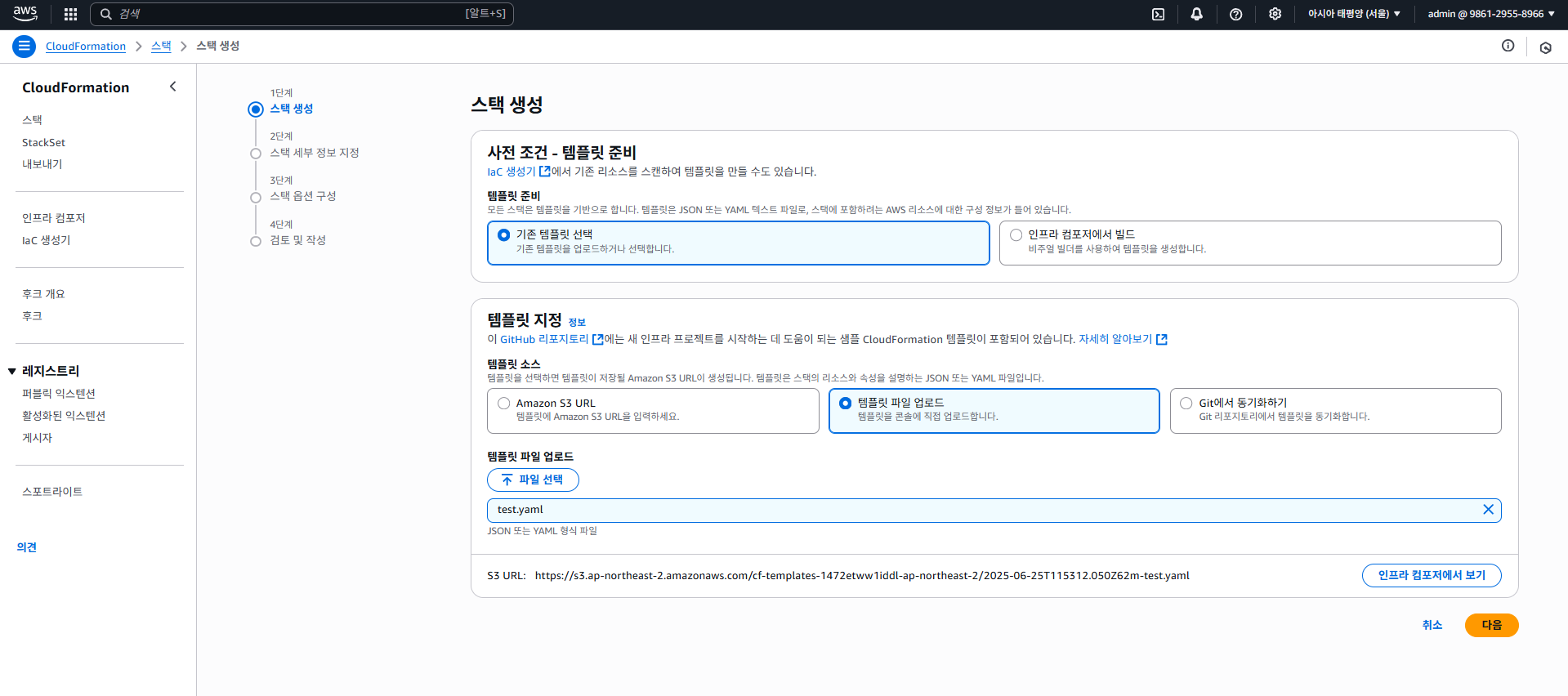
우리는 간단히 템플릿 코드로 테스트만 해볼 예정임으로, "템플릿 파일 업로드"를 클릭하고, 위 템플릿 코드를 YAML로 작성하여 업로드해보자.
(인프라 컴포즈를 통해 시각적으로 편집할 수 도 있고, 이미 만들어둔 인프라를 IaC 생성기를 통해 템플릿 코드로 만들 수 도 있다.)
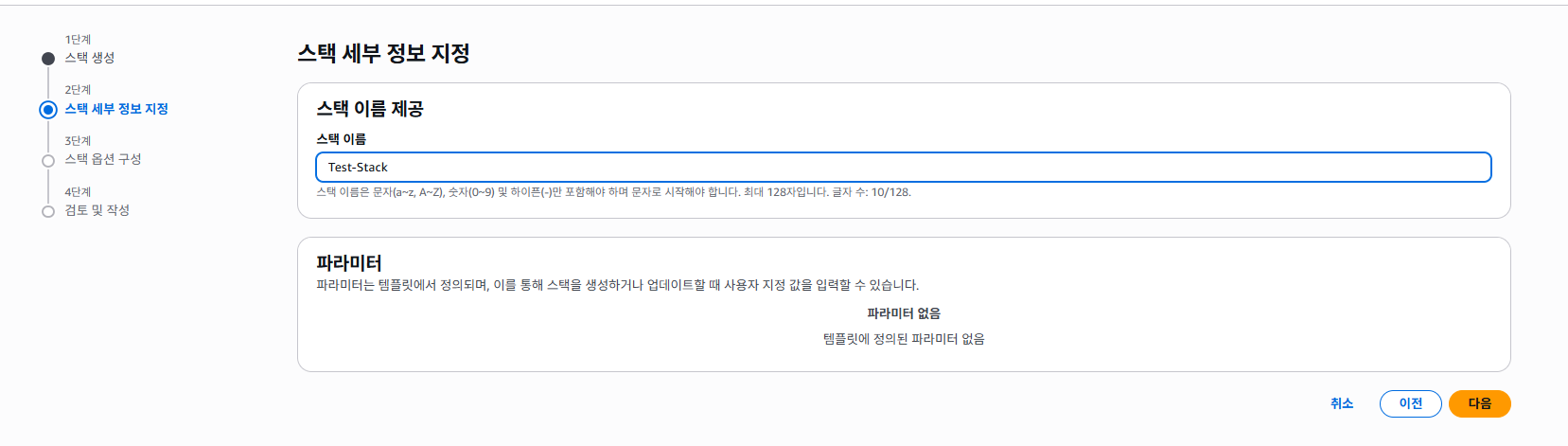
다음으로 스택 이름을 지정하고, 스택 옵션 구성도 그대로 냅둔다.
(인프라를 만드는 도중 에러가 발생했을 때 어떻게 롤백할지 등을 정할 수 있는데, 대부분 기본값으로 냅두면 된다.)
다음을 클릭하여 완료하면, 아래와 같이 CREATE_IN_PROGRESS로 뜨면서 생성이 되기 시작한다.
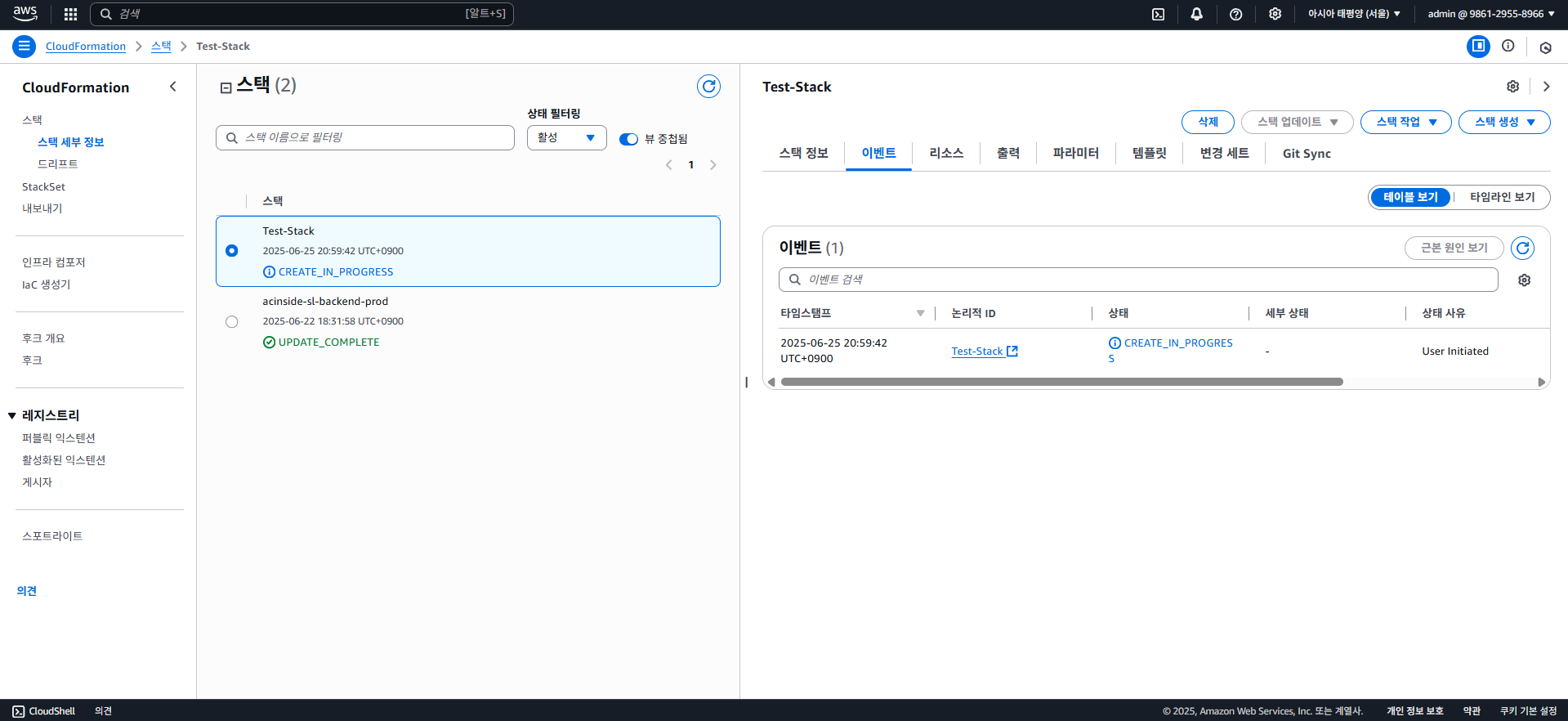
이후 약간의 시간이 흐르고 새로고침 해보면, 위 코드를 그대로 사용했을 시 당연히 에러가 떠야한다.
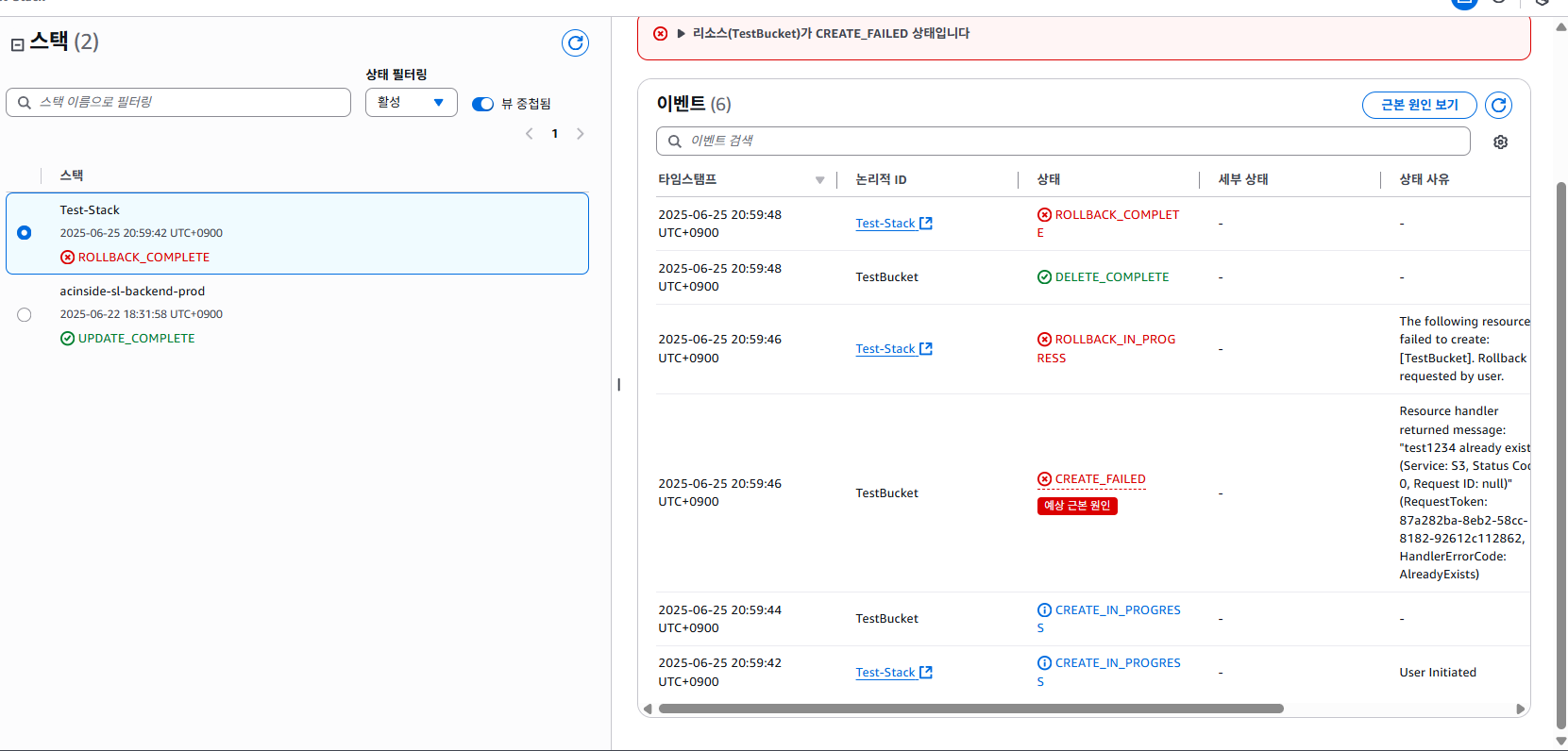
버킷의 이름은 유일해야 하는데, test1234과 같이 흔한 이름을 사용하였기 때문이다. 중복되지 않은 고유한 버킷 이름을 지정하고, AWS Console에선 템플릿을 직접 수정하는 기능은 제공하지 않으니 일단 삭제 후 다시 만들어보자.
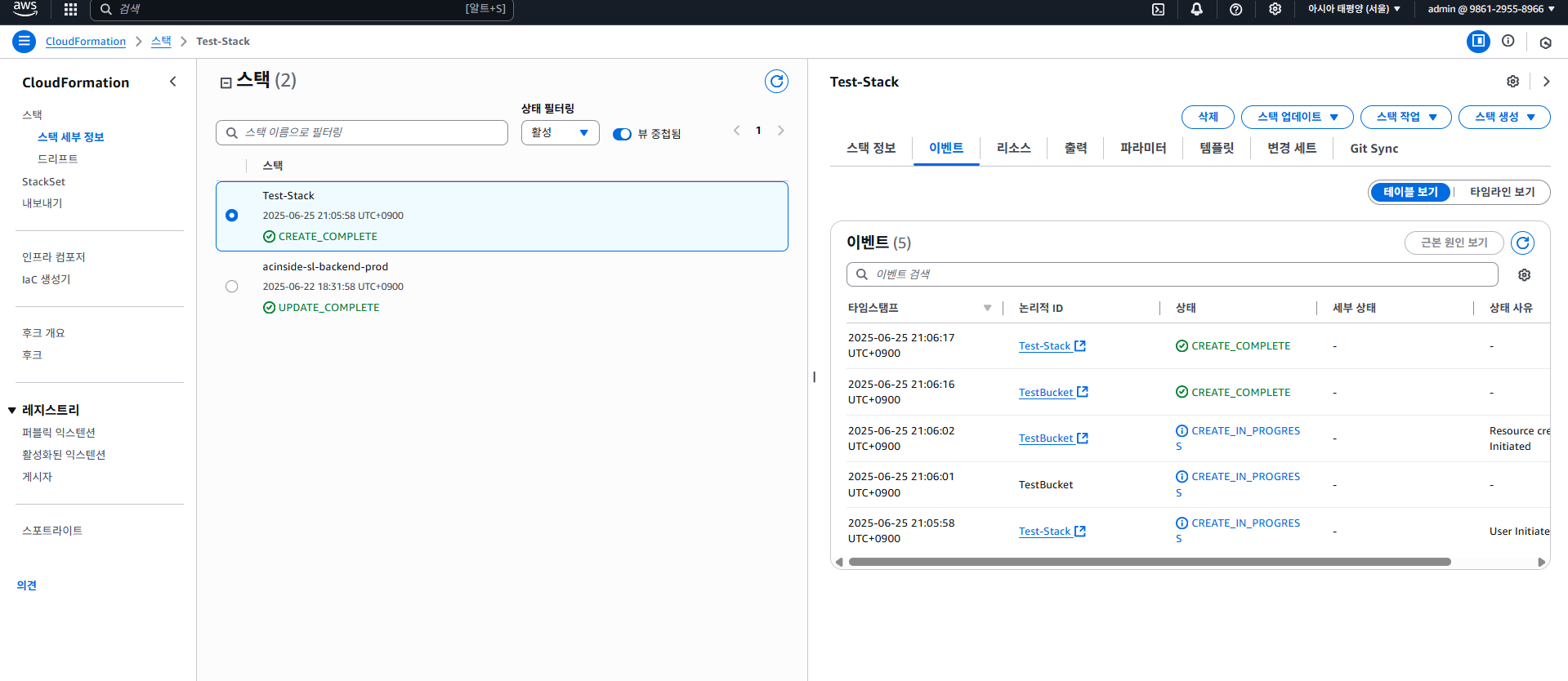
이렇게 고유한 이름을 넣어주게 되면 성공적으로 생성이 된다. S3 버킷이 잘 생성되었는지 실제로 확인해보자.
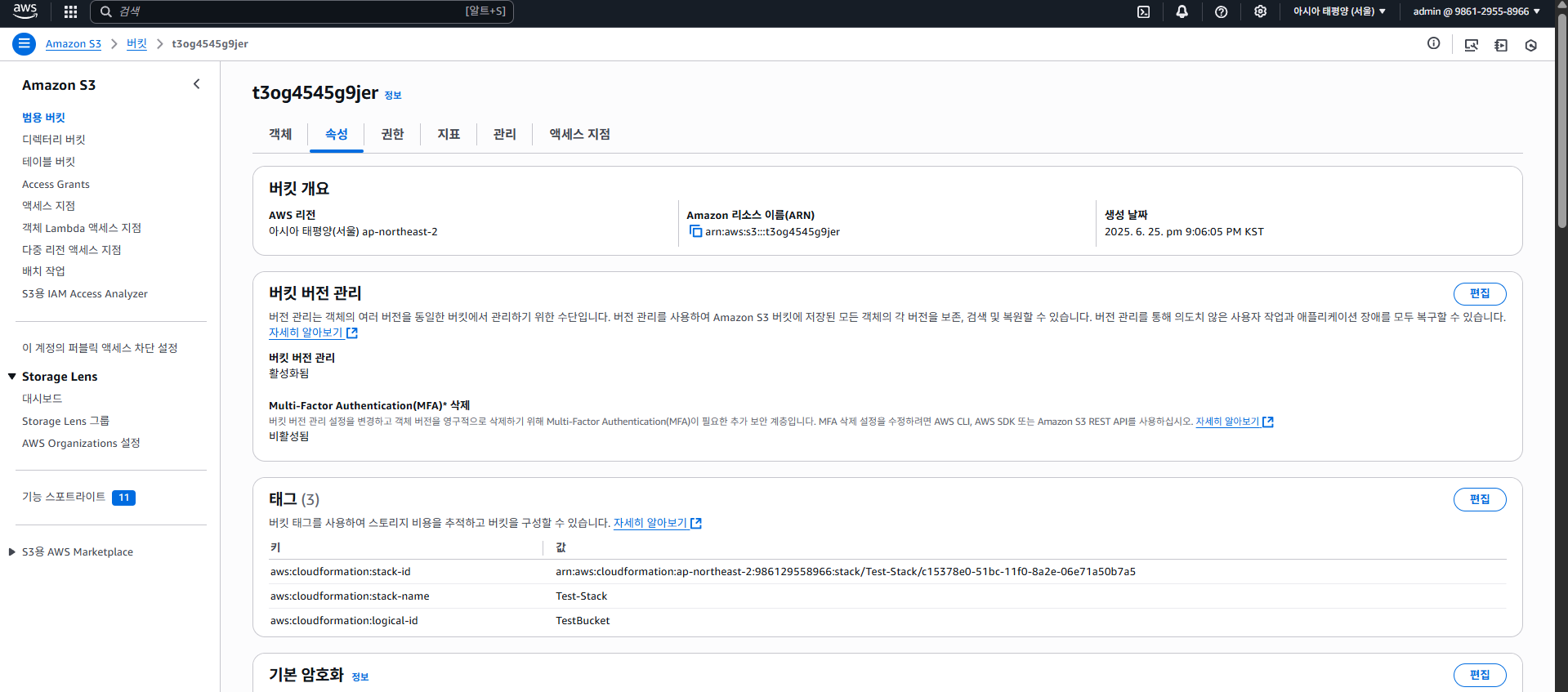
잘 생성되었다. 추가적으로 CloudFormation를 통해 생성되었지만, 특정 리소스가 직접 수정됐을 경우 스택 드리프트(Stack Drift)라 하여 탐지가 가능하다. 자세한건 다루지 않는다.
아래는 인프라 컴포즈 화면인데, 잘 쓰이지는 않는 듯 하고, 여기서도 직접 코드를 작성해보는 식으로 진행할 것이다.
SAM(Serverless Application Model)
앞서 CloudFormation에 대해 알아보았는데, SAM(Serverless Application Model)은 AWS에서 공식적으로 지원하는 CloudFormation을 기반으로 만들어진 서버리스에 특화된 IaC 프레임워크다.
만약 아래와 같이 작성했을 경우:
Resources:
HelloWorldFunction:
Type: AWS::Serverless::Function
Properties:
Handler: index.handler
Runtime: nodejs20.x
Events:
HelloWorld:
Type: Api
Properties:
Path: /hello
Method: getSAM을 통해 배포하면 람다 함수 생성은 물론, 자동으로 index.js 등의 코드를 압축 후 S3 등에 업로드한 후, 람다를 생성하고 해당 코드를 적용시킨다.
또한 Events의 Type: Api는 API Gateway를 의미하는데, GET /hello 엔드 포인트를 자동으로 연동시켜준다.
이후 sam build 및 sam deploy CLI 명령어를 통해 배포할 수 있으며, sam local invoke 등의 명령어를 통해 로컬에서 람다 함수를 테스트 해볼 수 있다.
AWS에서 공식적으로 지원하고, 서버리스에 특화되어 있다는 점 등이 있지만, 너무 간단하여 플러그인 등을 지원하지 않는 점 때문에 SAM 보단 Serverless Framework 선호율이 더 높고, 커뮤니티도 더욱 더 활성화되어 있는 듯 하다.
Serverless Framework
이것도 서버리스 배포에 특화된 프레임워크인데, 얘도 결국엔 CloudFormation을 사용하기 때문에 구조 자체는 비슷하다.
AWS에 최적화되어 있으며, 특히 플러그인 등이 활발하게 지원되고 있어 더욱 더 많이 사용되는 듯 하며, SAM보다 더욱 더 간결한 코드를 작성할 수 있다.
다음은 위의 SAM 코드 예시를 Serverless Framework(serverless.yaml)로 작성한 코드이다.
service: HelloWorld
provider:
name: aws
runtime: nodejs20.x
functions:
hello:
handler: handler.hello
events:
- http:
path: hello
method: getprovider를 사용하여 기본값을 정해주고, 서버리스에 특화된 프레임워크이기 때문에 람다 함수에 대한 functions라는 요소를 따로 지원한다.
또한 플러그인을 지원하는 점이 장점인데, 예를 들어 자바스크립트 번들링 등을 원한다면 아래와 같이 플러그인을 설치하고 사용할 수 있다.
> npm install -g serverless-esbuildplugins:
- serverless-esbuild # 플러그인 추가
custom:
esbuild:
bundle: true # 번들링
minify: true # 코드 간소화
target: 'node20' # NodeJS 20버전 사용 (람다에서 지원하는 최신 버전)
platform: 'node'
treeShaking: true # 사용하지 않는 코드 삭제
packager: npm # npm 패키지 메니저 사용
format: 'cjs' # CommonJS 사용단점이라 하면 요즘 들어와서 어느정도 유료화가 됐다는 점, AWS 외의 리소스를 다루기엔 어렵다는 점 등이 있으나 AWS만 쓴다면 큰 단점이 되진 못한다.
만약 멀티 클라우드 등의 더욱 더 복잡한 환경을 원한다면, 테라폼(Terraform) 등을 사용해야 한다.
(더 나아가 Ansible 등의 소프트웨어도 있으나, 이 포스팅에선 테라폼 개념만 살짝 다룬다.)
이 포스팅에선 Serverless Framework를 사용하는데, CloudFormation이나 SAM에 비해 더욱 다양한 기능(플러그인 등)을 지원하고, 서버리스에 특화되어 이 포스팅에 적합하다고 판단하였다.
추후 다시 설명하겠지만, 이 포스팅에서 사용된 예제의 Serverless Framework 파일(serverless.yaml)은 아래에서 확인할 수 있다.
https://github.com/eocndp/aws-lambda-example/blob/main/backend/serverless.yaml
테라폼(Terraform)
테라폼도 IaC 도구인데, AWS만 지원하는 것이 아닌, GCP, Azure, 쿠버네티스, Cloudflare 등의 다양한 서비스를 지원한다.
또한 자체적인 언어(DSL)인 HCL(HashiCorp Configuration Language)를 사용하는데, 예를 들어 아래와 같이 사용할 수 있다.
resource "aws_s3_bucket" "my_bucket" {
bucket = "my-app-bucket"
acl = "private"
}멀티 클라우드인 만큼 커뮤니티가 크고, 다양한 클라우드와 서비스를 지원하지만 러닝 커브가 높다는 등의 단점이 있다.
이 포스팅에선 자세한 내용을 다루진 않겠으나, 이런게 있구나 정도만 알면 좋을 듯 하다.
4-6. CI/CD
CI/CD는 Continuous Integration/Continuous Deployment의 약자로, 직역하면 지속적 통합과 지속적 배포가 된다.
이게 무슨말이냐면, 예를 들어 아래와 같은 시나리오를 생각해보자.
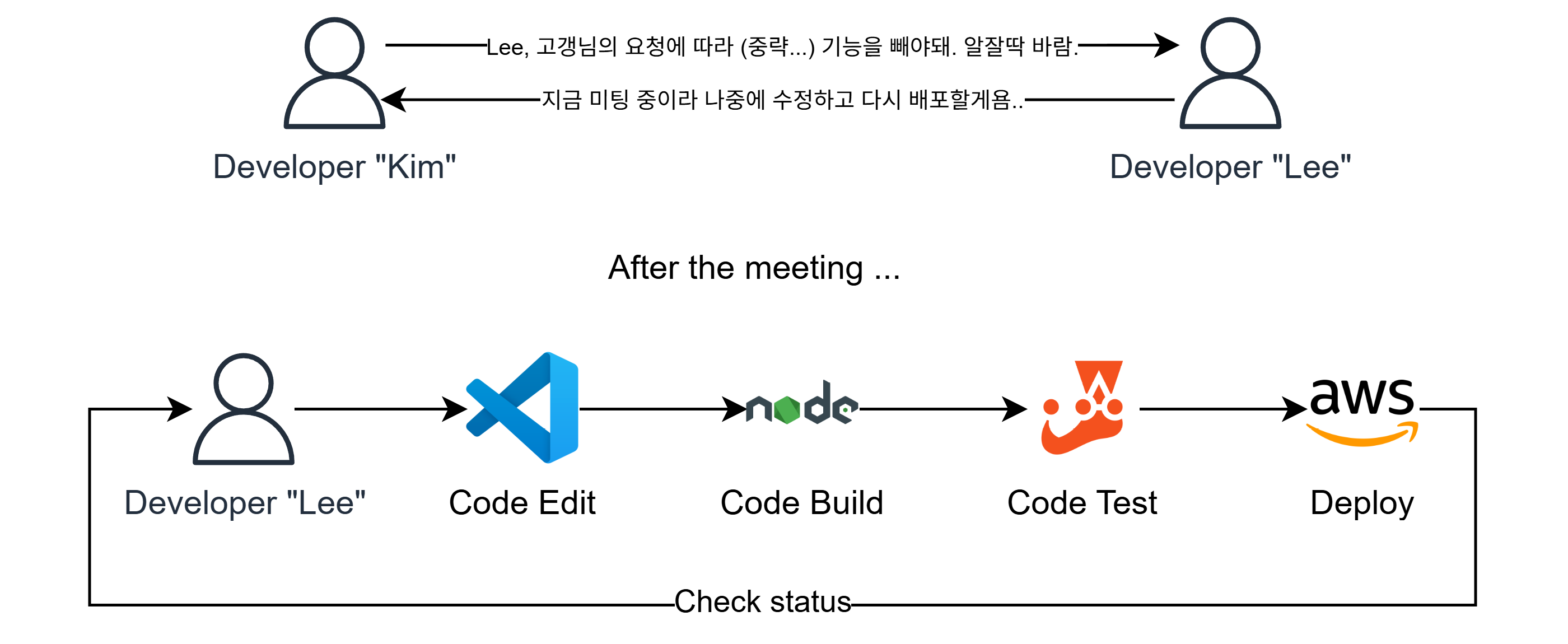
만약 어느 코드를 수정했으면, 그 코드를 빌드하고, 배포하며 테스팅까지 한 뒤 문제가 없다면 배포하는 형태인데, 이정도도 많이 생략된 것이고 실제 실무에선 버전 관리, 코드 리뷰, 모니터링 등의 더욱 복잡한 과정(파이프라인)을 거친다.
그러한 복잡한 작업을 자동화 시킨것이 바로 CI/CD이다.
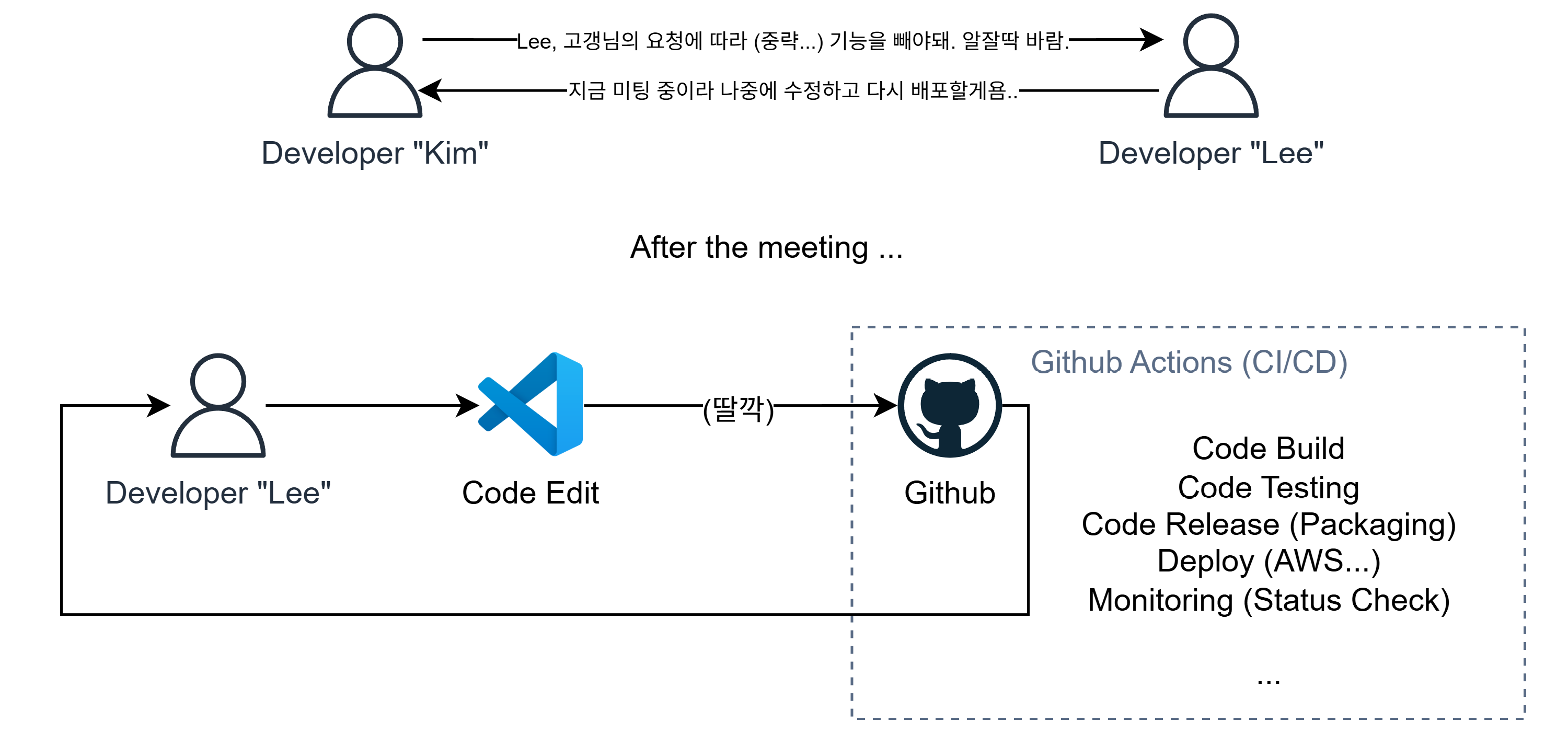
CI/CD에서 CI, 즉 지속적 통합은 코드를 빌드하고 테스팅해보면서 문제를 발견하는 과정이고, CI을 통과하면 통합된 코드를 자동으로 배포한다. (CD)
그리고 그 과정을 파이프라인(Pipeline)이라 하는데, CI부터 CD까지 일련의 과정을 한번에 자동화하는 것이 CI/CD의 목표이다.
이렇듯 배포와 지속적인 관리에 중점을 둔 DevOps에선 핵심적인 내용인데, CI/CD에 대한 이야기는 여기까지만 하고, 다음으로 CI/CD 플랫폼에 관해 이야기를 해볼것이다.
CI/CD 플랫폼엔 대표적으로 오픈소스인 Jenkins나 Travis CI 등이 있으나, 이 포스팅에서 사용할 CI/CD 플랫폼은 Github Actions이다.
Github Actions
이 포스팅을 읽는 독자 중에서 깃(Git)과 깃허브(Github)에 대해 모르는 독자는 거의 없을 것이라 생각하지만, 간단히 설명하자면 깃(Git)은 소스코드 등의 변경 사항을 추적하고 관리하는 버전 관리 시스템이다.
특히 협업을 위해선 깃이 필수인데, 그러한 깃들을 저장하는 서비스엔 크게 깃허브(Github)나 깃랩(Gitlab)이 존재한다.
그 중 깃허브가 가장 대중적으로 많이 사용되는데, 그 깃허브에선 Github Actions라는 CI/CD 도구를 지원한다.
원격 저장소(깃허브)에서 특정한 이벤트가 발생했을 경우 어떠한 작업들을 실행시킬 수 가 있는데, 이것이 Github Actions의 작동 방식이다.
그러한 작업들을 작성해둔 것이 워크플로우(Workflow)라고 하며, .github/workflows/ 경로에 YAML 형식으로 작성할 수 있다.
그 안에서 이루어지는 작업들을 잡(Job)라고 부르며, 그 Job 안에서 진행되는 명령어나 작업들을 스텝(Step)이라 칭한다.
또한 이러한 Workflow를 실행하는 환경을 러너(Runner)라고 하며, Github Actions에서 제공하는 기본 Runner를 사용할 수 도 있고, 특정 컴퓨터에서 실행되게 할 수 있는 Self Hosting Runner를 사용할 수 도 있다.
Github Actions는 특정한 이벤트(Event)를 트리거 했을 때 실행되는데, 그 이벤트에는 소스코드를 깃허브(원격 저장소)에 push 하였을때, 이슈(issue)나 풀 리퀘스트(Pull Request)가 등록되었을 때나 또는 스케줄러를 사용한 특정 시간 등 다양한 이벤트를 사용할 수 있다.
예를 들어 아래와 같이 YAML로 Github Actions를 작성할 수 있다.
name: Github Pages Deploy
on:
push:
branches:
- main
permissions:
contents: write
jobs:
publish:
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v4
- name: Install dependencies
run: npm install
- name: Build
run: npm run build
- name: Deploy on Github Pages
uses: JamesIves/github-pages-deploy-action@v4
with:
folder: build먼저 Github Actions는 특정 이벤트를 트리거하여 실행되는데, 이는 Workflow의 on을 기준으로 트리거된다.
위 코드에선 main 브랜치에 push 하였을 때 실행된다느 뜻이다.
만약 main 브랜치에 push가 되면 Workflow를 실행하고, 각 Job을 실행하 그 Job 안의 Step들을 절차적으로 실행한다.
만약 에러 등으로 인해 실패하게 된다면 Workflow는 멈추게 된다.
모든 스텝들이 실행되면 그 결과를 보고하는데, Github Actions에서 확인할 수 도 있고, Slack이나 Discord 등에 웹훅을 연동하여 결과를 보고할 수 도 있다.
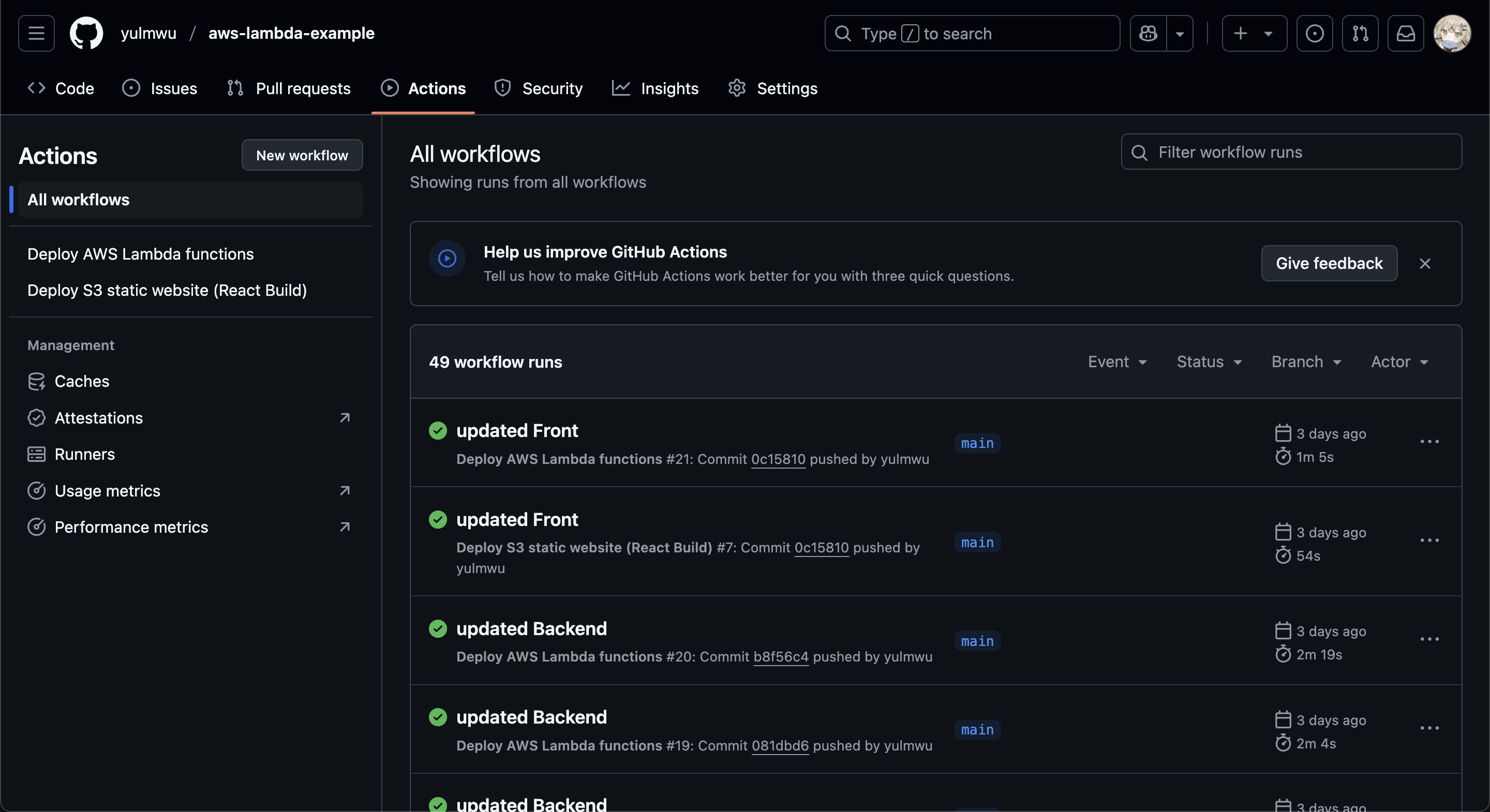
또한 위 예제에서 볼 수 있듯이 Step은 uses를 통해 다른 개발자가 만들어둔 워크플로우를 사용할 수 도 있는데, 이는 마켓플레이스에서 확인해볼 수 있다.
추가적으로 Github Actions는 첫 스텝으로 actions/checkout@v3(또는 v4)를 사용하여 레포지토리의 소스코드를 다운받는다.
예를 들어, 아래와 같은 워크플로우를 .github/workflows/test.yaml에 작성하고 push해보자.
name: Test Workflow
on: push
jobs:
checkout:
runs-on: ubuntu-latest
steps:
- name: First Check
run: |
ls -al
- name: Checkout
uses: actions/checkout@v4
- name: Second Check
run: |
ls -al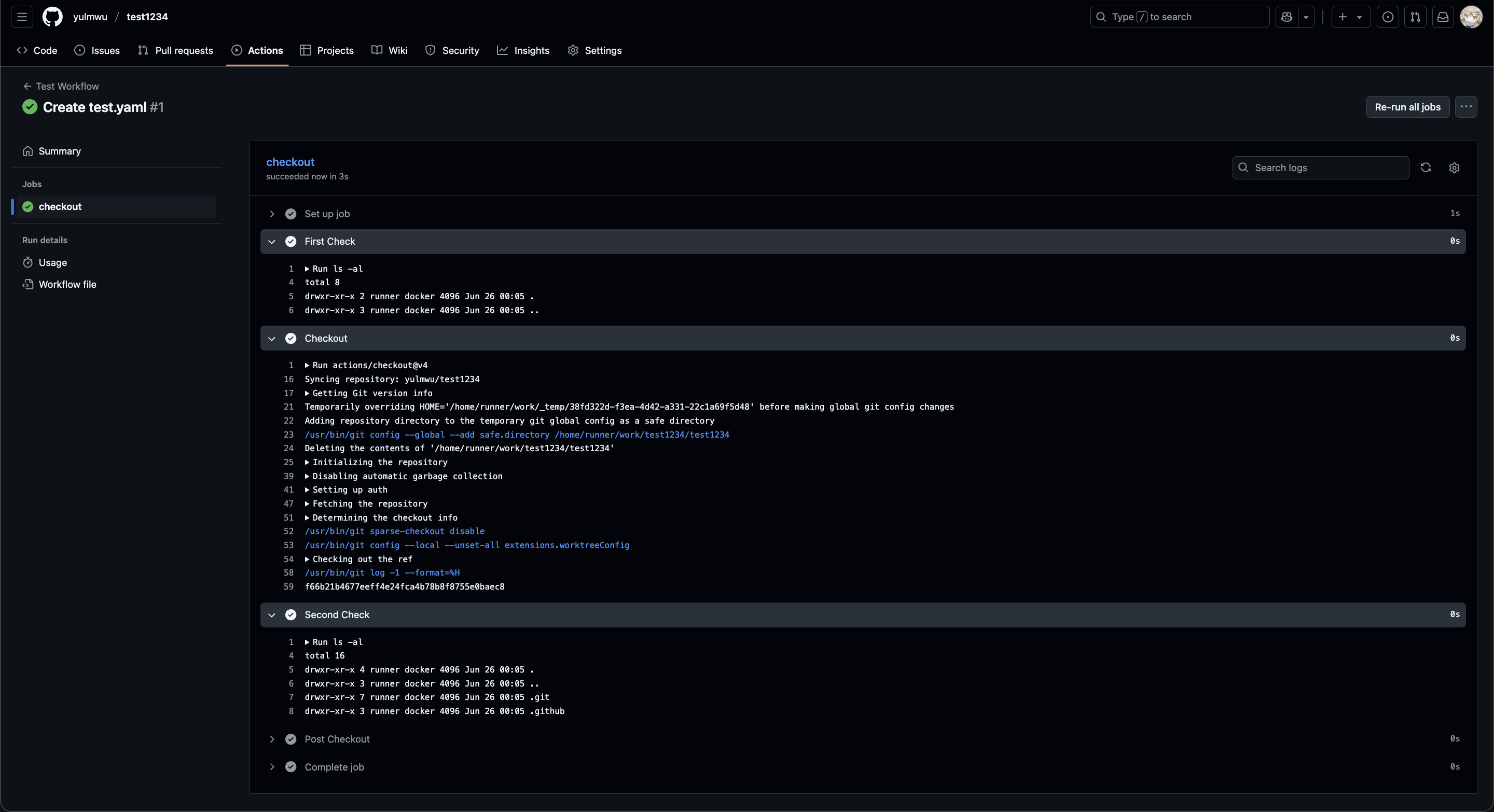
그럼 이렇게 성공적으로 실행되는데, Checkout 이후 레포지토리의 소스 코드가 다운된다.
자세한 내용은 이후 실습을 통해 다시 한번 더 알아보도록 하자.
5. Let's write the Code
사실 인프라 구축을 어느 정도 해두고 람다 함수 코드를 작성하려고 하였으나, 그렇게 되면 포스팅이 너무 난잡해질 것 같아 코드를 먼저 작성한 뒤 배포하는 방식으로 설명한다.
우리가 작성할 함수는 카테고리로 나눠보면 인증과 관련된 부분(/auth), 포스트 CRUD와 관련된 부분(/posts), 그리고 마지막으로 현재 유저 정보를 가져오는 /myinfo 정도가 있다.
실제 서비스를 개발한다면 여기서 더욱 더 추가되겠지만, 공부를 위한 예제 가까움으로 깊게 파고들진 않는다.
또한 이 파트에서 모든 코드를 설명하기엔 무리가 있는데, 그래서 이 파트에선 중요한 개념들이 등장하는 코드만 일부 소개할 예정으로, 아래와 같은 람다 함수 코드를 설명할 것이다.
/auth/login.ts/auth/signup.ts/post/createPost.ts/post/getPost.ts/user/myinfo.ts
프로젝트의 코드 자체는 모든 코드가 비슷한 구조를 가졌고, 함수의 AWS SDK 사용 등의 차이이니 일부만 설명해도 큰 문제가 없다고 판단하였다.
프로젝트에 사용된 소스코드는 아래에서 확인할 수 있다.
https://github.com/eocndp/aws-lambda-example
프로젝트의 파일 구조는 아래와 같다. 프론트엔드 코드와 백엔드 코드가 한 프로젝트에 같이 있으니 이를 참고하길 바란다.
.
├── backend
│ ├── functions
│ │ ├── auth
│ │ │ ├── confirmEmail.ts
│ │ │ ├── login.ts (설명)
│ │ │ ├── logout.ts
│ │ │ ├── refresh.ts
│ │ │ ├── resendEmail.ts
│ │ │ └── signup.ts (설명)
│ │ ├── post
│ │ │ ├── createPost.ts (설명)
│ │ │ ├── deletePost.ts
│ │ │ ├── getPost.ts (설명)
│ │ │ ├── getPosts.ts
│ │ │ └── updatePost.ts
│ │ └── user
│ │ └── myInfo.ts (설명)
│ ├── package.json
│ ├── serverless.yaml
│ ├── tsconfig.json
│ └── utils
│ └── httpError.ts
└── frontend
├── index.html
├── package.json
├── README.md
├── src
│ ├── App.css
│ ├── App.tsx
│ ├── index.css
│ ├── main.tsx
│ └── vite-env.d.ts
├── tsconfig.app.json
├── tsconfig.json
├── tsconfig.node.json
└── vite.config.ts백엔드의 람다 함수는 backend/functions에 위치하고, 프론트엔드는 /frontend에 위치한다.
(프론트엔드 코드는 따로 설명하지 않는다.)
AWS SDK는 기본적으로 람다 실행 환경에 내장되어 있다.
즉 굳이node_modules까지 업로드 할 필요는 없으나, 그 외의 라이브러리를 사용한다면 업로드 하도록 하자.
5-1. Tech Stacks
코드를 설명하기 앞서, 이 프로젝트에서 사용한 기술(Tech)을 설명하고 넘어가겠다.
먼저 전체적으론 TypeScript를 사용하였는데, 백엔드에 사용된 tsconfig는 여기서 확인할 수 있다.
전체적으로 NodeJS 버전은 v20 (람다에서 지원하는 NodeJS 최신버전), TypeScript 버전은 5.8이다.
Serverless Framework는 3.4를 사용하였는데, 4.x 부턴 로그인을 필수로 하는 등 더 복잡해졌기 때문에 아직은 3.x를 사용해도 큰 문제는 없다.
AWS SDK(Software Development Kit)
코드 설명에 앞서, 가장 중요한 AWS SDK를 설명하고 가려 한다. SDK는 개발에 필요한 도구(툴)의 모음으로, 흔히 라이브러리 등이 포함된다.
(NodeJS를 통해 개발하니 AWS SDK도 NodeJS 용 SDK를 사용한다.)
AWS SDK는 AWS 서비스와 관련된 API를 쉽게 호출할 수 있도록 하는 SDK인데, 크게 v2 버전과 v3 버전이 존재한다.
흔히 인터넷을 돌아다녀보면 v2 버전의 AWS SDK를 사용한 코드를 볼 수 있는데, v3와 구조가 꽤나 다를 뿐더러 지원이 곧 종료되기 때문에 v3를 사용하는것이 바람직하다.
v2와 v3의 가장 큰 차이점이라 하면 기존엔 aws-sdk 라이브러리 안에 모든 서비스가 포함되어 있었는데, 그래서 번들링이나 Tree Shaking 등에서 불리하였다.
예를 들어, DynamoDB 연결을 위한 Client를 생성하기 위해선 아래와 같은 AWS SDK v2를 사용해야 했다. (ESModule 기준)
import AWS from 'aws-sdk'
const dynamoDB = new AWS.DynamoDB()
dynamoDB.getItem({
TableName: 'Users',
Key: {
userId: { S: '123' },
},
}, (err, data) => {
// Do Someting
})하지만 v3의 경우 서비스별로 따로 모듈화되어 있는데, 때문에 필요한 기능만 임포트하여 사용할 수 있다. 위 v2 SDK를 v3로 변경하면 아래와 같다.
import { DynamoDBClient } from '@aws-sdk/client-dynamodb'
import { DynamoDBDocumentClient, GetCommand } from '@aws-sdk/lib-dynamodb'
const dynamoDB = DynamoDBDocumentClient.from(new DynamoDBClient({}))
const command = new GetCommand({
TableName: 'Users',
Key: { '123' },
})
const result = await dynamoDB.send(command)
// Do Someting또한 v3에선 작업을 명령어 형식으로 정의하고, 각 서비스를 API 클라이언트라 하며 명령어를 보내는(.send()) 방식이다.
이처럼 서비스별로 모듈화 되어있어 가독성도 좋아지고 추후 번들링과 Tree Shaking 등의 용량 감소에 도움을 줄 수 있다.
SDK의 서비스별 사용 방법은 아래에서 차근차근 설명하도록 하겠다.
5-2. login.ts
포스팅의 가독성을 위하여 실제 배포에 사용되었던 코드를 변형하여 주요 로직만 포함되어있다.
때문에 예외 처리 및 유틸리티 함수 등이 존재하지 않으며, 자세한 코드는 깃허브 소스코드를 참고하길 바란다.
login.ts는 로그인 기능을 담당하는 람다 함수로, Body로 username과 password를 받는다.
그 응답으로 엑세스 토큰과 ID 토큰, 그리고 Set-Cookie를 통해 HTTPOnly 쿠키로 리프레시 토큰을 응답한다.
import { CognitoIdentityProviderClient, InitiateAuthCommand } from '@aws-sdk/client-cognito-identity-provider'
import { APIGatewayProxyEventV2, APIGatewayProxyResultV2 } from 'aws-lambda'
const cognitoClient = new CognitoIdentityProviderClient({})
export const handler = async (event: APIGatewayProxyEventV2): Promise<APIGatewayProxyResultV2> => {
try {
const { username, password } = JSON.parse(event.body ?? '{}')
if (!username || !password)
return {
statusCode: 400,
body: JSON.stringify({
error: 'Bad Request',
message: 'Username and password are required',
}),
}
const command = new InitiateAuthCommand({
AuthFlow: 'USER_PASSWORD_AUTH',
ClientId: process.env.COGNITO_CLIENT_ID!,
AuthParameters: {
USERNAME: username,
PASSWORD: password,
},
})
const result = await cognitoClient.send(command)
const accessToken = result.AuthenticationResult?.AccessToken
const idToken = result.AuthenticationResult?.IdToken
const refreshToken = result.AuthenticationResult?.RefreshToken
const maxAge = 30 * 24 * 60 * 60 // 30 days
return {
statusCode: 200,
headers: {
'Set-Cookie': `refreshToken=${refreshToken}; HttpOnly; Path=/; Max-Age=${maxAge}; SameSite=None; Secure`,
},
body: JSON.stringify({
accessToken,
idToken,
}),
}
} catch (err) {
return {
statusCode: 500,
body: JSON.stringify({
error: 'Internal Server Error',
message: (err as Error).message,
}),
}
}
}먼저 aws-lambda라는 추가적인 라이브러리를 사용하는데, 이는 AWS SDK와는 별개로 람다 함수에 대한 기능과 타입스크립트 타입을 제공한다. (@types/aws-lambda)
이 프로젝트에선 타입스크립트를 사용하기 때문에 해당 라이브러리를 사용하였으며, 실제로 의존성 목록에도 devDependencies에만 포함시켰다.
"dependencies": {
"@aws-sdk/client-cognito-identity-provider": "^3.830.0",
"@aws-sdk/client-dynamodb": "^3.830.0",
"@aws-sdk/lib-dynamodb": "^3.830.0"
},
"devDependencies": {
"@types/aws-lambda": "^8.10.150",
"@types/node": "^24.0.3"
}먼저 아래의 코드로 Cognito에 대한 클라이언트를 생성한다. 이 클라이언트를 바탕으로 username과 password를 제공하여 유저의 정보를 가져오게 된다.
클라이언트 선언 시 일반적으론 리전 등의 값을 파라미터에 옵션으로 넣어줘야 하나, 만약 넣지 않았을 경우 AWS_REGION 환경 변수를 자동으로 확인한다.
AWS 람다의 경우 자동으로 AWS_REGION 환경 변수를 설정해줌으로 굳이 따로 리전을 설정하진 않았다.
const cognitoClient = new CognitoIdentityProviderClient({})이것이 람다 함수에서 초기화 코드이고, Invoke 단계에서 실행되는 handler() 함수를 살펴보자.
export const handler = async (event: APIGatewayProxyEventV2): Promise<APIGatewayProxyResultV2> => {
// ...
}람다 핸들러는 비동기 함수로 작성되며, handler()의 event 파라미터는 APIGatewayProxyEventV2라는 타입을 가지고 있다.
람다 함수에서 handler()의 event 파라미터는 람다를 실행했을 때 람다에게 제공되는 데이터를 의미하는데, API Gateway와 연동하여 사용하기 때문에 API Gateway에서부터 제공되는 데이터(페이로드)를 받아야한다.
그것을 API Gateway Proxy라 하는데, 레거시한 APIGatewayProxyEvent가 아닌 V2 버전(APIGatewayProxyEventV2)을 사용한다. V2에 대한 내용은 이곳을 참고하자.
이후 해당 요청의 Body에 username과 password 항목이 있는지 검사한다.
const { username, password } = JSON.parse(event.body ?? '{}')
if (!username || !password)
return {
statusCode: 400,
body: JSON.stringify({
error: 'Bad Request',
message: 'Username and password are required',
}),
}만약 둘 중 하나라도 제공되지 않을 경우 400 Bad Request를 반환한다.
다음으로 아래 코드는 받아온 username과 password를 바탕으로 Cognito에 인증 정보를 가져온다.
const command = new InitiateAuthCommand({
AuthFlow: 'USER_PASSWORD_AUTH',
ClientId: process.env.COGNITO_CLIENT_ID!,
AuthParameters: {
USERNAME: username,
PASSWORD: password,
},
})
const result = await cognitoClient.send(command)
const accessToken = result.AuthenticationResult?.AccessToken
const idToken = result.AuthenticationResult?.IdToken
const refreshToken = result.AuthenticationResult?.RefreshToken이제부터 AWS SDK를 사용하는 로직이 등장하는데, 먼저 InitiateAuthCommand를 통해 Cognito 클라이언트에 보낼 명령어를 선언한다.
인증 방식으론 패스워드를 사용하겠다는 USER_PASSWORD_AUTH, Cognito 클라이언트 ID는 환경 변수로 받아오며(Cognito Client ID는 추후 인프라를 구축하면서 설명하겠다.) 인증에 필요한 데이터를 AuthParameters에 넣는다.
그리고 Cognito 클라이언트에 선언해둔 명령어를 보내는데(.send()), 이는 비동기 함수이기 때문에 await을 사용하여 동기화한다.
마지막으로 그 결과값에서 엑세스 토큰과 ID 토큰, 리프레시 토큰을 받아온다.
const maxAge = 30 * 24 * 60 * 60 // 30 days
return {
statusCode: 200,
headers: {
'Set-Cookie': `refreshToken=${refreshToken}; HttpOnly; Path=/; Max-Age=${maxAge}; SameSite=None; Secure`,
},
body: JSON.stringify({
accessToken,
idToken,
}),
}위에서 Cognito 클라이언트에 InitiateAuthCommand 명령어를 통해 인증 정보를 받아왔다면 (API를 호출한)클라이언트에게 인증 정보를 반환한다.
그 중 리프레시 토큰은 HTTPOnly 쿠키로 보낼 것인데, 이에 대해선 앞서 설명했었다.
그리고 나머지 엑세스 토큰과 ID 토큰은 Body에 넣어서 반환하고, 로그인 함수는 이로써 끝이 난다.
2025-08-30 업데이트
무슨 이유인지는 모르겠으나, Cognito에서 "기존 웹 애플리케이션" 선택 시 자동으로 Client Secret 옵션이 켜지면서 Client Secret Hash 값을 요구하는 것 같다.
아래와 같이 코드 추가하고 수정해주자.
import { createHmac } from 'crypto' const clientSecretHashGenerator = (username, clientId, clientSecretKey) => { // Base64 ( HMAC_SHA256 ( "Client Secret Key", "Username" + "Client Id" ) ) const hmac = createHmac('sha256', clientSecretKey) hmac.update(username + clientId) return hmac.digest('base64') }AuthParameters: { USERNAME: '...', PASSWORD: '...', SECRET_HASH: clientSecretHashGenerator('...', CLIENT_ID, CLIENT_SECRET_KEY), },
5-3. signup.ts
앞서 Body의 페이로드가 있는지 확인하는 로직,
handler()함수의event파라미터 등은 이미 설명하였으니 생략하고, AWS SDK 중심으로 다룬다.
import { CognitoIdentityProviderClient, SignUpCommand } from '@aws-sdk/client-cognito-identity-provider'
import { APIGatewayProxyEventV2, APIGatewayProxyResultV2 } from 'aws-lambda'
const cognitoClient = new CognitoIdentityProviderClient({})
export const handler = async (event: APIGatewayProxyEventV2): Promise<APIGatewayProxyResultV2> => {
try {
const { username, password, email } = JSON.parse(event.body ?? '{}')
if (!username || !password || !email)
return {
statusCode: 400,
body: JSON.stringify({
error: 'Bad Request',
message: 'Username, password, and email are required',
}),
}
const command = new SignUpCommand({
ClientId: process.env.COGNITO_CLIENT_ID!,
Username: username,
Password: password,
UserAttributes: [{ Name: 'email', Value: email }],
})
await cognitoClient.send(command)
return {
statusCode: 200,
body: JSON.stringify({ message: 'Signup successful, please check your email for confirmation.' }),
}
} catch (err) {
return {
statusCode: 500,
body: JSON.stringify({
error: 'Internal Server Error',
message: (err as Error).message,
}),
}
}
}앞서 설명한대로 Cognito 클라이언트를 선언하고, 회원가입 시 필요한 값인 username, password, email이 Body에 포함되어있는지 확인한다.
그리고 Cognito 클라이언트에 회원 가입 명령어를 보내는데, 그 코드는 아래와 같다.
const command = new SignUpCommand({
ClientId: process.env.COGNITO_CLIENT_ID!,
Username: username,
Password: password,
UserAttributes: [{ Name: 'email', Value: email }],
})
await cognitoClient.send(command)추후 설명하겠지만 Cognito엔 유저 이름, 비밀번호는 기본적으로 제공해야 하지만 이메일은 제공하지 않아도 되게 할 수 있다. (다만 회원가입과 동시에 계정 인증을 처리하는 식으로 로직을 작성해야함.)
그래서 이메일의 경우 속성으로 값을 넘기는데, 그 사용은 위 코드와 같다.
위와 같은 명령어를 통해 Cognito 클라이언트에 전달하면 회원가입이 완료되고, 인증 코드가 포함된 이메일이 회원가입 시 기입되었던 이메일로 전송된다.
회원가입 API의 반환은 특별한 값을 반환하지 않으므로 반환에 대한 코드 설명은 생략한다.
5-4. createPost.ts
import { DynamoDBClient } from '@aws-sdk/client-dynamodb'
import { DynamoDBDocumentClient, UpdateCommand, PutCommand } from '@aws-sdk/lib-dynamodb'
import { APIGatewayProxyEventV2WithJWTAuthorizer, APIGatewayProxyResultV2 } from 'aws-lambda'
const dynamoDB = DynamoDBDocumentClient.from(new DynamoDBClient({}))
const getNextId = async (): Promise<number> => {
const command = new UpdateCommand({
TableName: 'Counter',
Key: { name: 'post' },
UpdateExpression: 'SET #v = if_not_exists(#v, :init) + :inc',
ExpressionAttributeNames: { '#v': 'value' },
ExpressionAttributeValues: {
':inc': 1,
':init': 0,
},
ReturnValues: 'UPDATED_NEW',
})
const result = await dynamoDB.send(command)
return result.Attributes?.value
}
export const handler = async (event: APIGatewayProxyEventV2WithJWTAuthorizer): Promise<APIGatewayProxyResultV2> => {
try {
const { title, content } = JSON.parse(event.body ?? '{}')
if (!title || !content)
return {
statusCode: 400,
body: JSON.stringify({
error: 'Bad Request',
message: 'Title and content are required',
}),
}
const user = event.requestContext.authorizer?.jwt?.claims
if (!user || !user.sub || !user.username)
return {
statusCode: 401,
body: JSON.stringify({
error: 'Unauthorized',
message: 'User is not authenticated',
}),
}
const item = {
id: String(await getNextId()),
title,
content,
userId: user.sub,
userName: user.username,
createdAt: new Date().toISOString(),
}
const command = new PutCommand({
TableName: 'Posts',
Item: item,
})
await dynamoDB.send(command)
return {
statusCode: 201,
body: JSON.stringify(item),
}
} catch (err) {
return {
statusCode: 500,
body: JSON.stringify({
error: 'Internal Server Error',
message: (err as Error).message,
}),
}
}
}
event파라미터의 타입이APIGatewayProxyEventV2이 아닌APIGatewayProxyEventV2WithJWTAuthorizer인 이유는 JWT 토큰의 값을 가져오기 위해서다.
기본적으로APIGatewayProxyEventV2엔 JWT 클레임 등의 정보가 포함되지 않는데, 확장된APIGatewayProxyEventV2WithJWTAuthorizer엔 JWT를 사용할 수 있다.
본격적으로 DynamoDB를 사용하는 코드이다. DynamoDB 또한 Cognito 클라이언트와 마찬가지로 클라이언트로 선언해주고, 그 클라이언트에 명령어를 보내는 형식이다.
const dynamoDB = DynamoDBDocumentClient.from(new DynamoDBClient({}))DynamoDBClient는 쉽게 말해 AWS 내부에서 사용되는 형식을 사용하는데, 그러한 방식이 불편하여 SDK에선 DynamoDBDocumentClient라는 Wrapper를 지원한다.
잘 이해가 안된다면 아차피 SDK에선 대부분 DynamoDBDocumentClient를 사용하니 이걸 사용하면 될 듯 하다.
이제 본격적으로 게시글을 작성하는 로직을 살펴보자.
const getNextId = async (): Promise<number> => {
const command = new UpdateCommand({
TableName: 'Counter',
Key: { name: 'post' },
UpdateExpression: 'SET #v = if_not_exists(#v, :init) + :inc',
ExpressionAttributeNames: { '#v': 'value' },
ExpressionAttributeValues: {
':inc': 1,
':init': 0,
},
ReturnValues: 'UPDATED_NEW',
})
const result = await dynamoDB.send(command)
return result.Attributes?.value
}사실 위 코드는 꼭 필요한게 아닌데, 위는 게시글의 ID 번호를 순차적으로 카운팅하기 위해 사용된다.
예를 들어 어느 사용자가 게시한 게시글의 ID가 10번이라면, 그 다음 게시글은 11번, 그 다음은 12번 이런식으로 게시글의 ID가 증가하는 것이다.
사실 SQL을 지원하는 RDBMS에선 테이블을 만들 때 AUTO_INCREMENT라는 속성을 사용하여 이러한 기능을 쉽게 사용할 수 있다.
하지만 DynamoDB와 같은 NoSQL에선 AUTO_INCREMENT과 같은 기능이 없다. 그래서 사용한 방법이 Counter라는 테이블을 하나 만들고, post와 같이 포스트 ID의 값을 카운팅하는 값을 하나 만드는 것이다.
위 코드를 보면 Counter 테이블의 post 키를 가진 값에 대해 아래와 같은 partiQL이라는 쿼리 언어로 로직을 처리하게 한다.
SET #v = if_not_exists(#v, :init) + :inc여기서 #v는 ExpressionAttributeNames에서 정의된 값인 value이다. 이렇게 따로 속성 등을 빼두는 이유는 식의 키워드(예약어)와 충돌이 날 수 있기 때문이다.
:inc는 1로 설정하였고, 초기화 값 :init은 0으로 설정해두었다.
즉 만약 post 키에 대해 value 속성(값)이 없다면 0으로 초기화해두고, 아니라면 기존의 값이 1로 초기화를 하라는 의미이다.
그리고 ReturnValues: 'UPDATED_NEW'는 바뀐 값만 응답으로 받는다는 것으로, ALL_NEW 등의 다른 타입도 지원한다.
최종적으로 getNextId() 함수는 새로운 게시글 ID를 반환하여 해당 ID를 새롭게 만들 게시글에 사용한다.
const item = {
id: String(await getNextId()),
title,
content,
userId: user.sub,
userName: user.username,
createdAt: new Date().toISOString(),
}
const command = new PutCommand({
TableName: 'Posts',
Item: item,
})그리고 위와 같은 코드를 사용하여 Posts 테이블에 getNextId()를 통해 만들어진 ID를 키로 하여 새로운 게시글을 만든다. (PutCommand 명령어)
그 내용으론 title, content, userId(user.sub은 JWT 토큰의 제목, 즉 식별을 위한 값임), username(JWT 토큰의 클레임 중 하나) 그리고 마지막으로 생성 시간을 포함하여 데이터베이스에 생성한다.
그리고 그 내용을 API를 호출한 클라이언트에 반환하면 이 함수는 끝이 난다.
5-5. getPost.ts
import { DynamoDBClient } from '@aws-sdk/client-dynamodb'
import { DynamoDBDocumentClient, GetCommand } from '@aws-sdk/lib-dynamodb'
import { APIGatewayProxyEventV2, APIGatewayProxyResultV2 } from 'aws-lambda'
const dynamoDB = DynamoDBDocumentClient.from(new DynamoDBClient({}))
export const handler = async (event: APIGatewayProxyEventV2): Promise<APIGatewayProxyResultV2> => {
try {
const id = event.pathParameters?.id
if (!id)
return {
statusCode: 400,
body: JSON.stringify({ message: 'Missing id parameter' }),
}
const command = new GetCommand({
TableName: 'Posts',
Key: { id },
})
const result = await dynamoDB.send(command)
if (!result.Item)
return {
statusCode: 404,
body: JSON.stringify({ message: 'Not found post' }),
}
return {
statusCode: 200,
body: JSON.stringify(result.Item),
}
} catch (err) {
return {
statusCode: 500,
body: JSON.stringify({ message: (err as Error).message }),
}
}
}전반적으론 createPost와 비슷한데, 애초에 CRUD의 구현 코드는 대부분 간단한 편이다.
(CRUD에서 Read를 제외하면 인증만 하고, 데이터베이스만 조작하는거니 어렵지 않음)
먼저 getPost는 특정 게시글의 ID를 URL 파라미터로 요구한다. 즉 API 호출에서 경로가 GET /posts/3라면, API Gateway에서 GET /posts/{id}로 지정하고 코드에선 event.pathParameters?.id로 접근할 수 있다.
const command = new GetCommand({
TableName: 'Posts',
Key: { id },
})
const result = await dynamoDB.send(command)
if (!result.Item)
return {
statusCode: 404,
body: JSON.stringify({ message: 'Not found post' }),
}그리고 GetCommand 명령어를 통해 특정 키(게시글의 ID)를 바탕으로 그 아이템을 가져올 수 있다.
이 아이템을 API를 호출한 클라이언트에게 반환하면 게시글을 불러오는 함수도 끝이 난다.
GetCommand가 아닌QueryCommand를 사용할 수 도 있는데,GetCommand는 파티션 키와 정렬 키를 바탕으로 하나의 요소만 가져온다면QueryCommand는 SQL문 처럼 여러개의 요소를 가져올 수 있다.또는
getPosts코드에선ScanCommand를 사용하였는데, DynamoDB에서 모든 테이블을 가져오는Scan은 상당한 리소스를 잡아먹는 명령어인데, 실전에는Scan명령어 사용을 지양한다.그 대신
Query를 사용하여 조건 형태로 가져오거나, 파티션 키를 "POST" 등으로 고정해두고Query를 사용하여 페이지네이션, 또는 GSI(Global Secondary Index)를 사용한 뒤 페이지네이션하는 등의 솔루션이 필요하다.하지만 자세한건 여기서 다루지 않고, 테스트로 확인만을 위해
Scan을 사용한다는 점 참고 바란다.
5-6. myInfo.ts
/user/myInfo(/myInfo 엔드포인트)는 현재 유저의 자세한 정보(이메일, 이메일 인증 여부 등의 속성 포함)를 반환하는데, 그 기준으로 Authorization 헤더에 JWT 엑세스 토큰을 전달한다.
import { CognitoIdentityProviderClient, GetUserCommand } from '@aws-sdk/client-cognito-identity-provider'
import { APIGatewayProxyEventV2, APIGatewayProxyResultV2 } from 'aws-lambda'
const cognitoClient = new CognitoIdentityProviderClient({})
export const handler = async (event: APIGatewayProxyEventV2): Promise<APIGatewayProxyResultV2> => {
try {
const authHeader = event.headers?.Authorization ?? event.headers?.authorization
if (!authHeader || !authHeader.startsWith('Bearer '))
return {
statusCode: 401,
body: JSON.stringify({
error: 'Unauthorized',
message: 'No valid authorization header provided',
}),
}
const accessToken = authHeader.substring('Bearer '.length)
const getUserCommand = new GetUserCommand({ AccessToken: accessToken })
const result = await cognitoClient.send(getUserCommand)
const userAttributes = Object.fromEntries(
(result.UserAttributes ?? []).map((attr) => [attr.Name, attr.Value])
)
return {
statusCode: 200,
body: JSON.stringify({
username: result.Username,
...userAttributes,
}),
}
} catch (err) {
return {
statusCode: 500,
body: JSON.stringify({
error: 'Internal Server Error',
message: (err as Error).message,
}),
}
}
}먼저 헤더에서 JWT 토큰을 추출한다.
const authHeader = event.headers?.Authorization ?? event.headers?.authorization
if (!authHeader || !authHeader.startsWith('Bearer '))
return {
statusCode: 401,
body: JSON.stringify({
error: 'Unauthorized',
message: 'No valid authorization header provided',
}),
}
const accessToken = authHeader.substring('Bearer '.length)그런 후, Cognito 클라이언트에 GetUserCommand 명령어를 보내는데, 이 명령어는 엑세스 토큰을 바탕으로 해당 유저의 자세한 정보(속성)을 가져올 수 있는 명령어이다.
const getUserCommand = new GetUserCommand({ AccessToken: accessToken })
const result = await cognitoClient.send(getUserCommand)
const userAttributes = Object.fromEntries(
(result.UserAttributes ?? []).map((attr) => [attr.Name, attr.Value])
)해당 명령어를 실행하려면 JWT 엑세스 토큰이
aws.cognito.signin.user.admin의 범위 안에 있어야 하는데, 이는 자기 자신의 계정을 관리할 수 있는 권한이다.Cognito에서 발급해주는 엑세스 토큰을 base64로 디코딩해보면 알 수 있다.

그리고 이 속성을 API를 호출한 클라이언트에게 반환하면 함수가 마무리된다.
6. Let's build the Infra
이제 개념과 코드 설명이 끝났다. 이제 AWS 인프라를 직접 구축해보면서 여태 배웠던 개념들을 적용하고, 코드를 배포해볼 것이다.
먼저 AWS Console을 사용하여 인프라를 구축해볼 것인데, 이후엔 Serverless Framework를 사용한 방식으로 일부 변경해볼 것이다.
인프라를 만들 순서는 아래와 같다.
(SF) 표시가 있는 것은 추후 Serverless Framework를 사용하여 생성해볼 인프라로, 포스팅의 설명에선 하나하나 직접 실제 프로젝트를 배포해보는 것이 아닌 그 서비스의 사용법 정도만 간단한 예제로 익힌 후, 나중에 Serverless Framework를 사용하여 실제 배포해볼 것이다.
- Lambda 코드 배포하기 (SF)
- API Gateway 연동하기 (SF)
- Cognito 설정하기 (SF)
- DynamoDB 생성하기 (SF)
- Serverless Framework로 배포 방식 바꾸기
- Github Actions를 사용하여 Serverless Framework 자동화 및 프론트엔드 자동 배포 작성하기
- CloudFront + S3로 프론트엔드 배포하기
이 파트에선 각 서비스 별 개념과 용어에 대해 자세히 설명하지 않는다. 만약 해당 서비스의 개념이나 용어를 모르겠다면 위 포스팅을 다시 읽어보는 것을 추천한다.
6-1. Deploy Lambda Function
먼저 람다 함수를 배포해보자. 아직 Cognito나 DynamoDB의 인프라 사용 방법을 익히지 않았기 때문에, 먼저 예시 코드만 배포해보는 방식으로 진행해볼 것이다.
먼저 AWS Console에 들어가자. 그리고 검색 > Lambda을 찾아서 들어가고, "함수 생성" 버튼을 클릭하자.
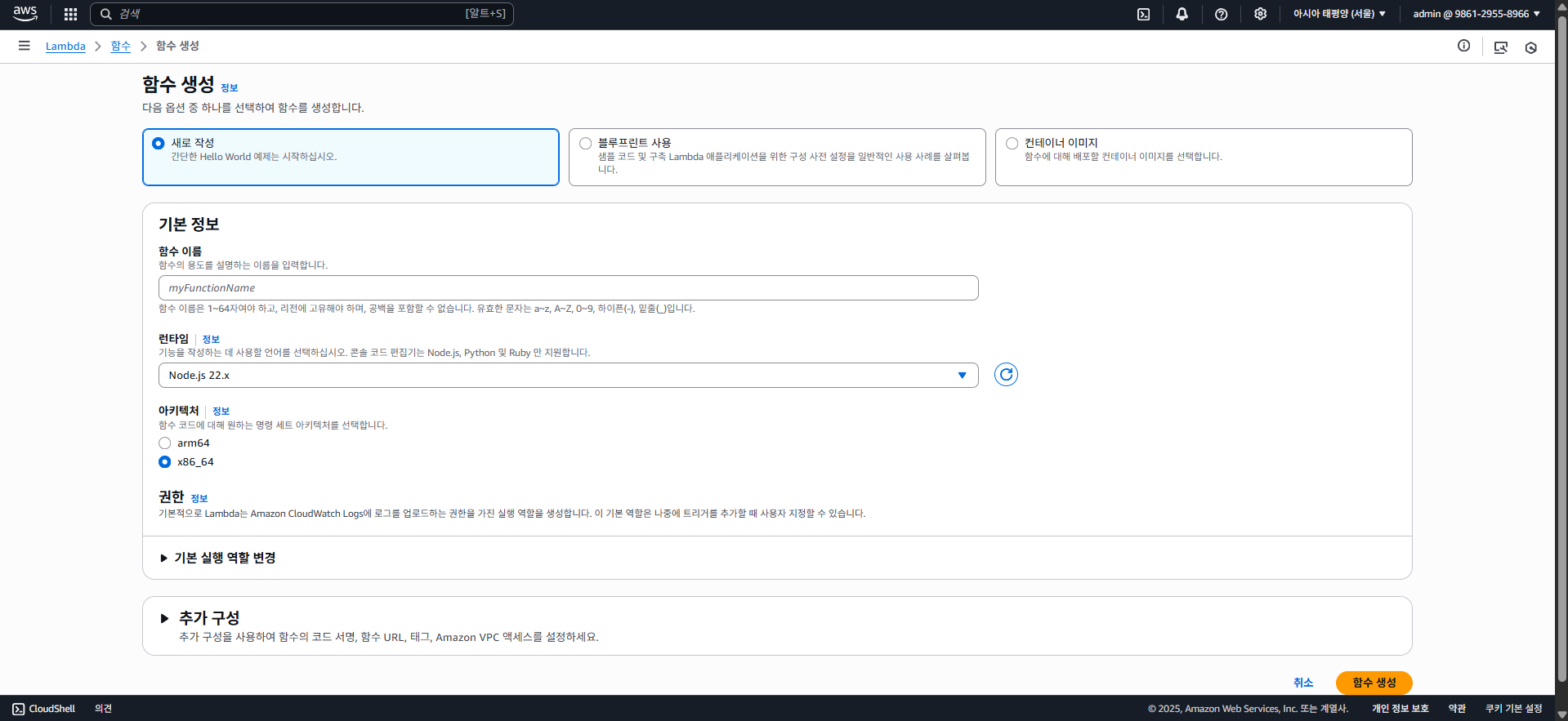
그럼 위와 같이 람다 함수를 생성할 수 있는 화면이 나타난다. 여기에 중복되지 않은 적당한 이름을 입력하고 런타임을 선택하자.
필자는 람다 함수의 이름을 myTestFunction이라 정했으며, 런타임 플랫폼은 NodeJS 20.x로 선택하였다.
그 아래에 권한을 부여할 수 있는데, 람다 함수는 CloudFront라는 모니터링 서비스에 로깅을 함으로 기본적으로 CloudFront에 대한 권한이 있다.
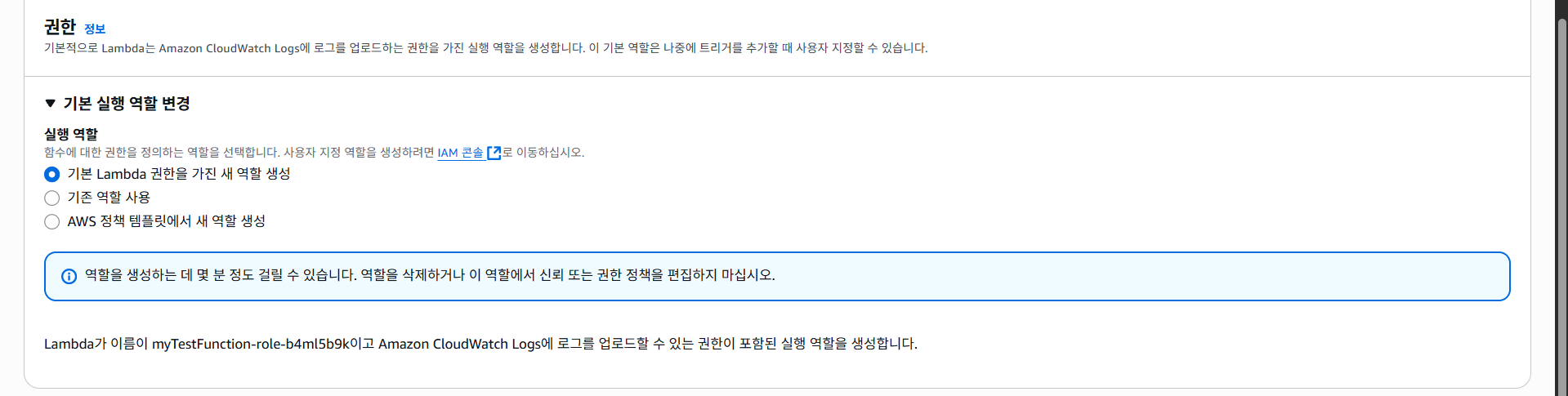
권한은 추후 DynamoDB를 사용할 때 다시 다뤄보기로 하고, "함수 생성" 버튼을 클릭한다.
그럼 잠시 후 람다 함수가 만들어지는데, 아래와 같은 화면이 나타날 것이다.
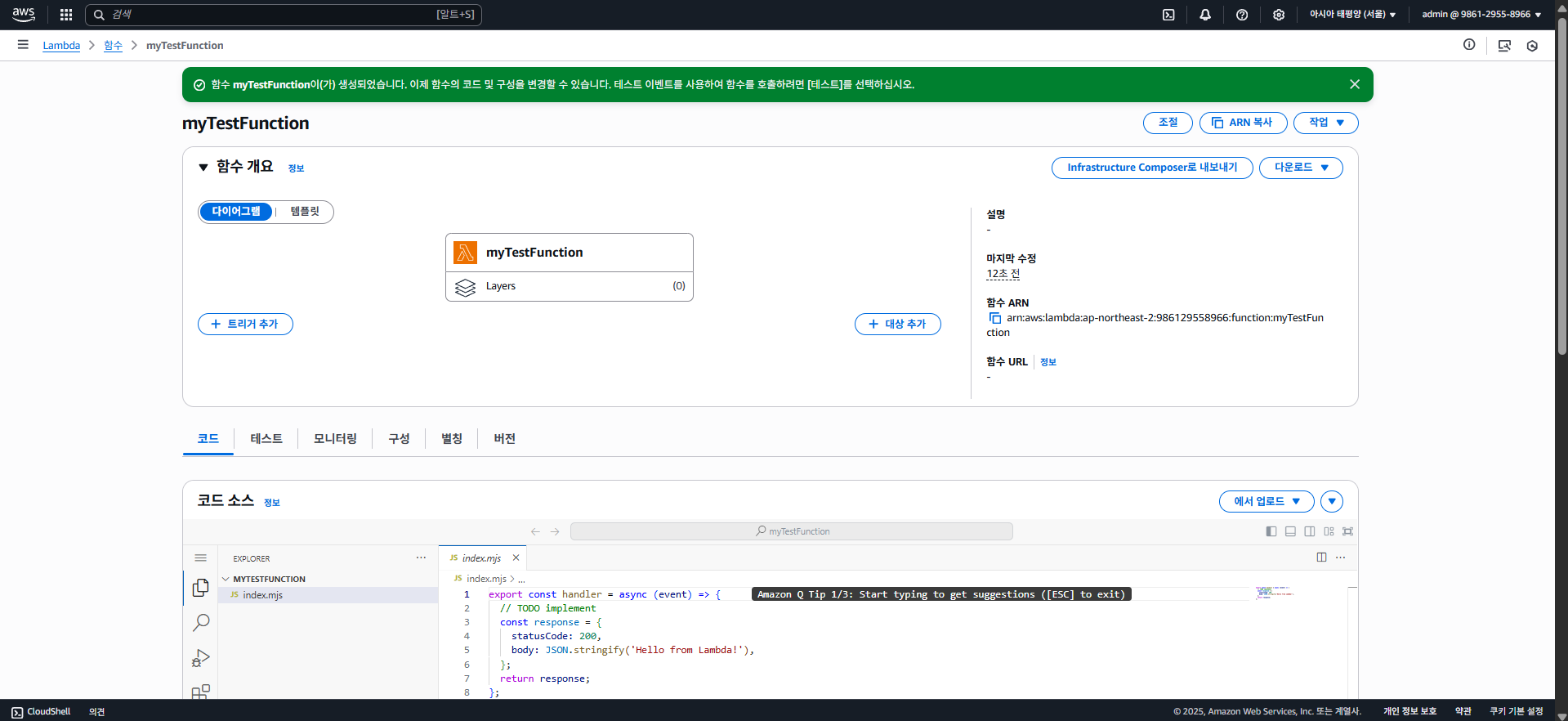
여기서 이벤트 트리거를 선택할 수 도 있고, 코드를 직접 편집하거나 모니터링, 또는 람다 함수에 대한 권한 등을 설정할 수 있다.
일단은 "코드" 탭의 "코드 소스"에서 아래와 같은 소스코드를 복사하고 붙여넣어보자.
(프로젝트는 타입스크립트를 사용하나, 일단은 편의 상 자바스크립트를 사용한다.)
// index.mjs
export const handler = async (event) => {
try {
const body = JSON.parse(event.body ?? '{}')
const num1 = Number(body.num1)
const num2 = Number(body.num2)
if (isNaN(num1) || isNaN(num2))
return {
statusCode: 400,
body: JSON.stringify({ error: 'Both num1 and num2 must be numbers' }),
}
const sum = num1 + num2
console.log(`${num1} + ${num2} = ${sum}`)
return {
statusCode: 200,
body: JSON.stringify({ result: sum }),
}
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({ error: 'Internal server error', details: error.message }),
}
}
}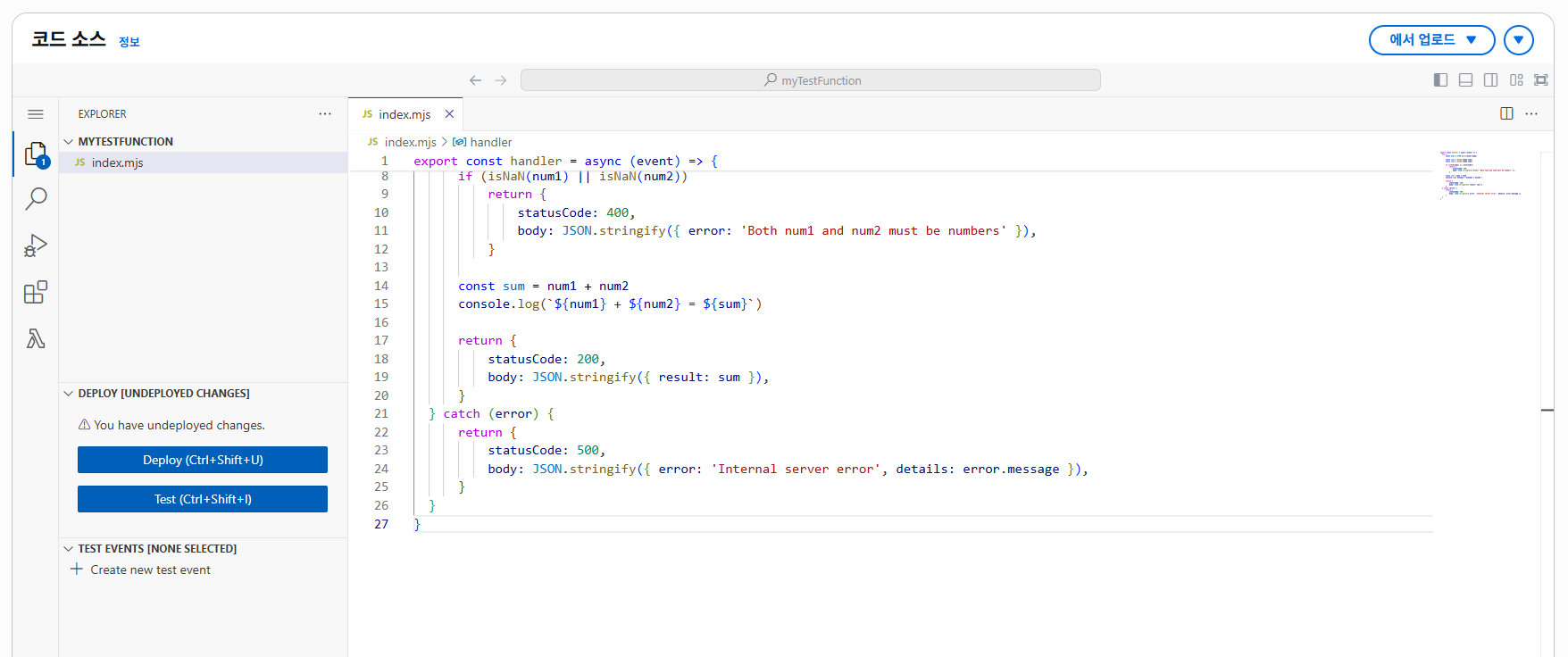
그런 다음 Deploy 버튼을 클릭하여 코드를 배포한다.

이제 람다 함수가 잘 작동하는지 테스트를 해보자. Deploy 버튼 아래의 Test 버튼을 클릭하면 테스트를 할 수 있다.
Test 버튼 클릭 > Create New Test Event 클릭 후 Event JSON에 아래의 데이터를 복사하고 붙여넣자.
{
"body": "{\"num1\": 10, \"num2\": 20}"
}그리고 Invoke 버튼을 클릭하면 테스트가 진행된다.
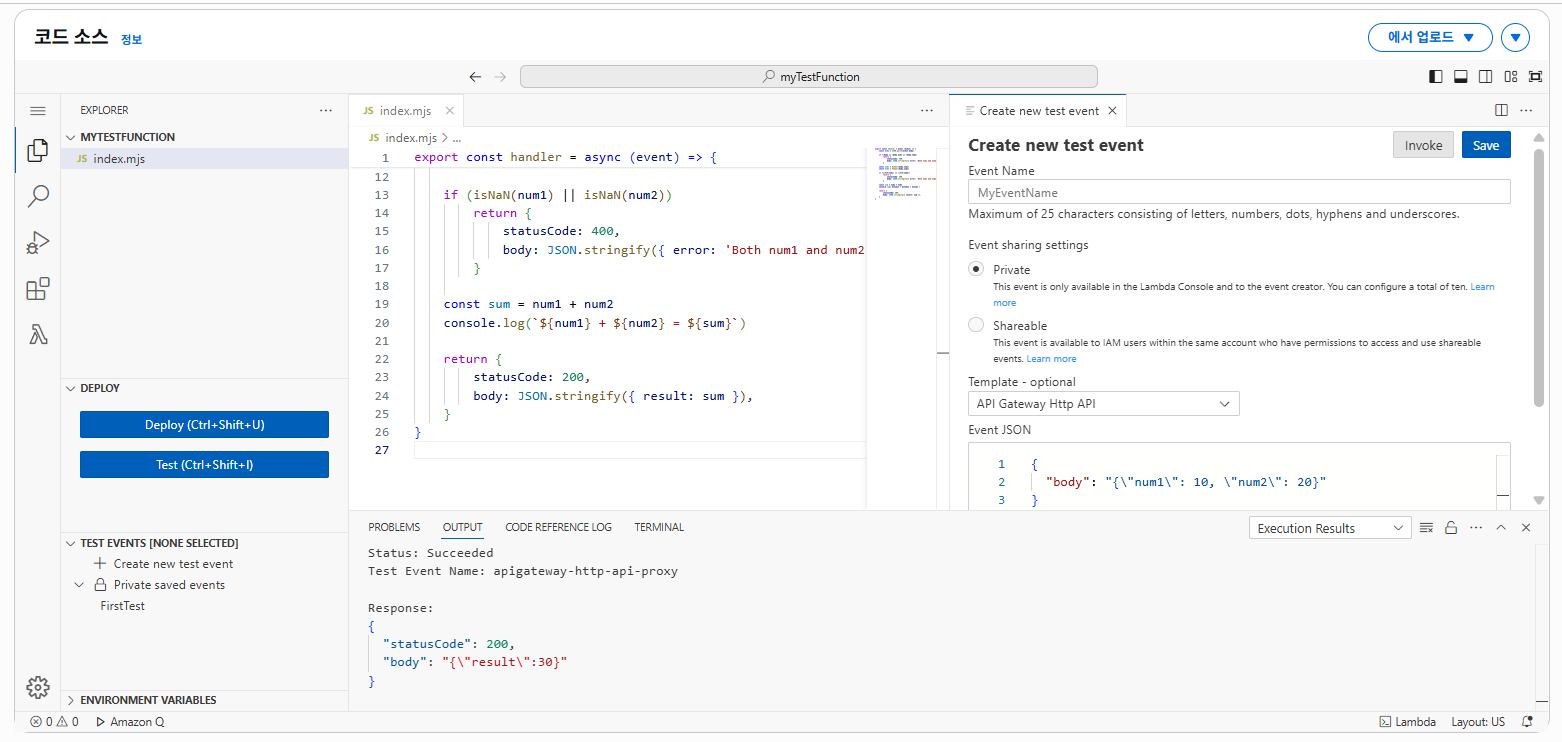

위와 같이 두 값을 더한 결과가 상태 코드 200과 함께 반환되며, console.log를 통한 로깅도 INFO로 날 나타난다.
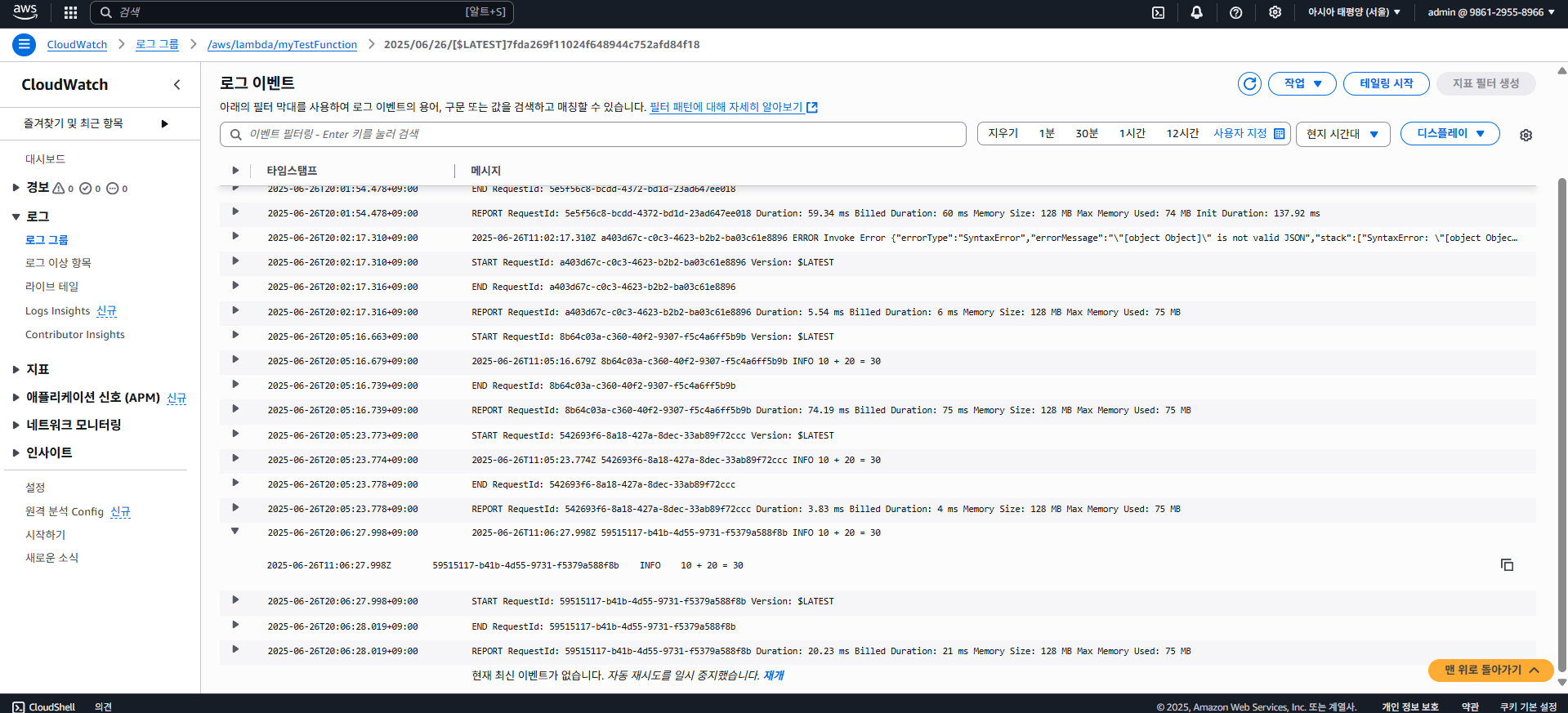
이러한 로그는 CloudWatch에서도 확인할 수 있다. CloudWatch > 로그 그룹 > /aws/lambda/람다함수이름을 클릭하고, 최신 로그 스트림을 클릭하면 아래와 같이 로그를 확인할 수 있다.
6-2. With API Gateway
앞서 람다 함수를 만들었는데, 여러 이벤트를 트리거할 수 있으나 우리의 목표는 API를 구축하는 것이다.
물론 람다 함수에서 함수 URL 기능을 통해 다이렉트로 API를 만들 수 도 있으나, 이는 매우 제한적이고 여러 기능을 사용하려면 API Gateway를 도입해야 한다.
API Gateway에 들어가 "API 생성" 버튼을 클릭하자.
들어가보면 HTTP API 구축이 있는데, 클릭하여 아래의 페이지로 넘어가자.
이 화면에서 직접 통합을 하여 람다와 연동할 수 있는데, 아직은 생략하고 이름만 적은 후 다음 버튼을 클릭하자.
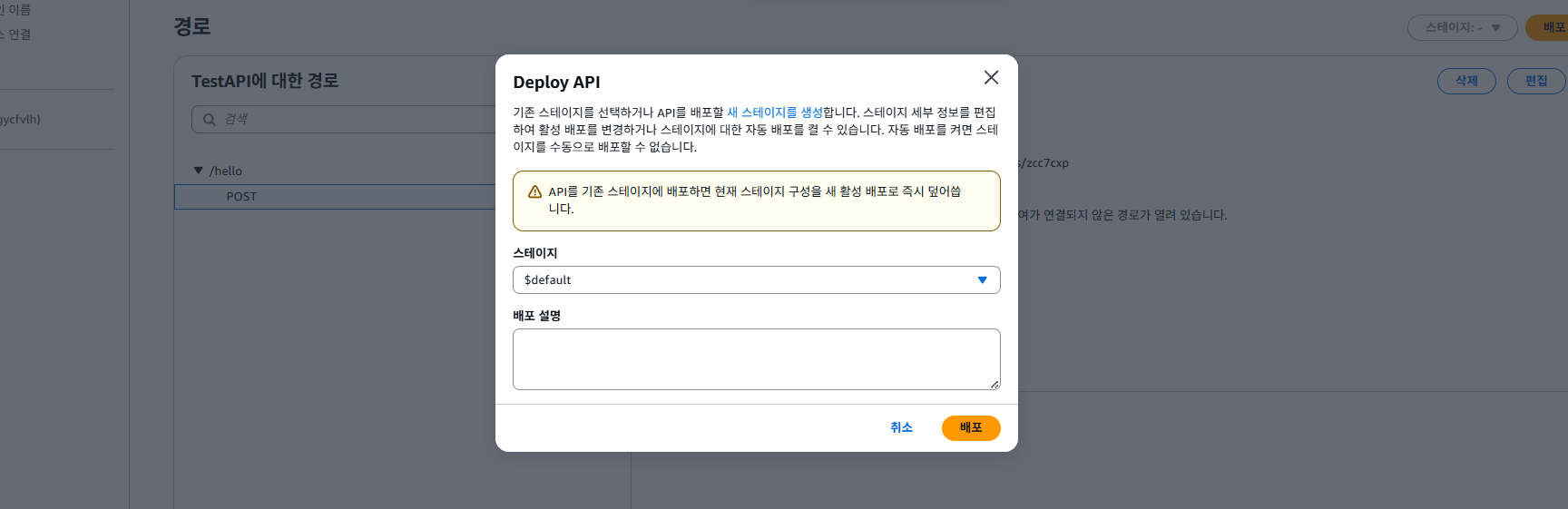
경로 설정도 무시하고 다음으로, 그럼 스테이지 배포 설정에서 자동 배포를 할 수 있는데, 이를 꺼놓고 나중에 한번에 배포할 수 있도록 하자.
스테이지는 배포 시 다양한 버전이나 환경 등을 구분하여 배포할 수 있도록 하는데, 예를 들어 v2라는 스테이지에 배포하면 API 엔드포인트는 /v2/...로 호출할 수 있다.
default 스테이지는 기본 루트(/) 경로에 배포하는 것으로, 아직은 스테이지 설정을 하지 않아도 된다.
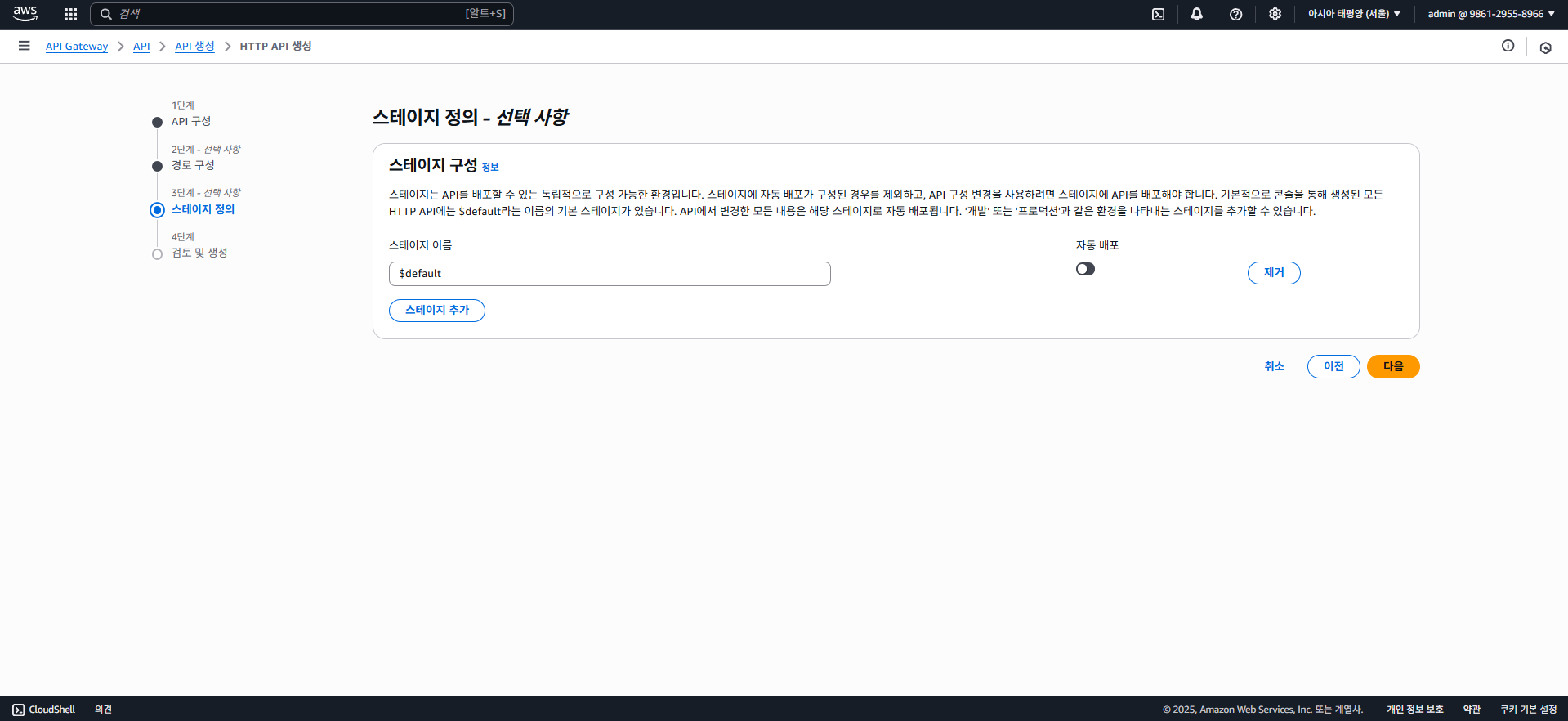
다음 버튼 클릭 후, 생성 버튼을 클릭하면 API Gateway가 생성된다.
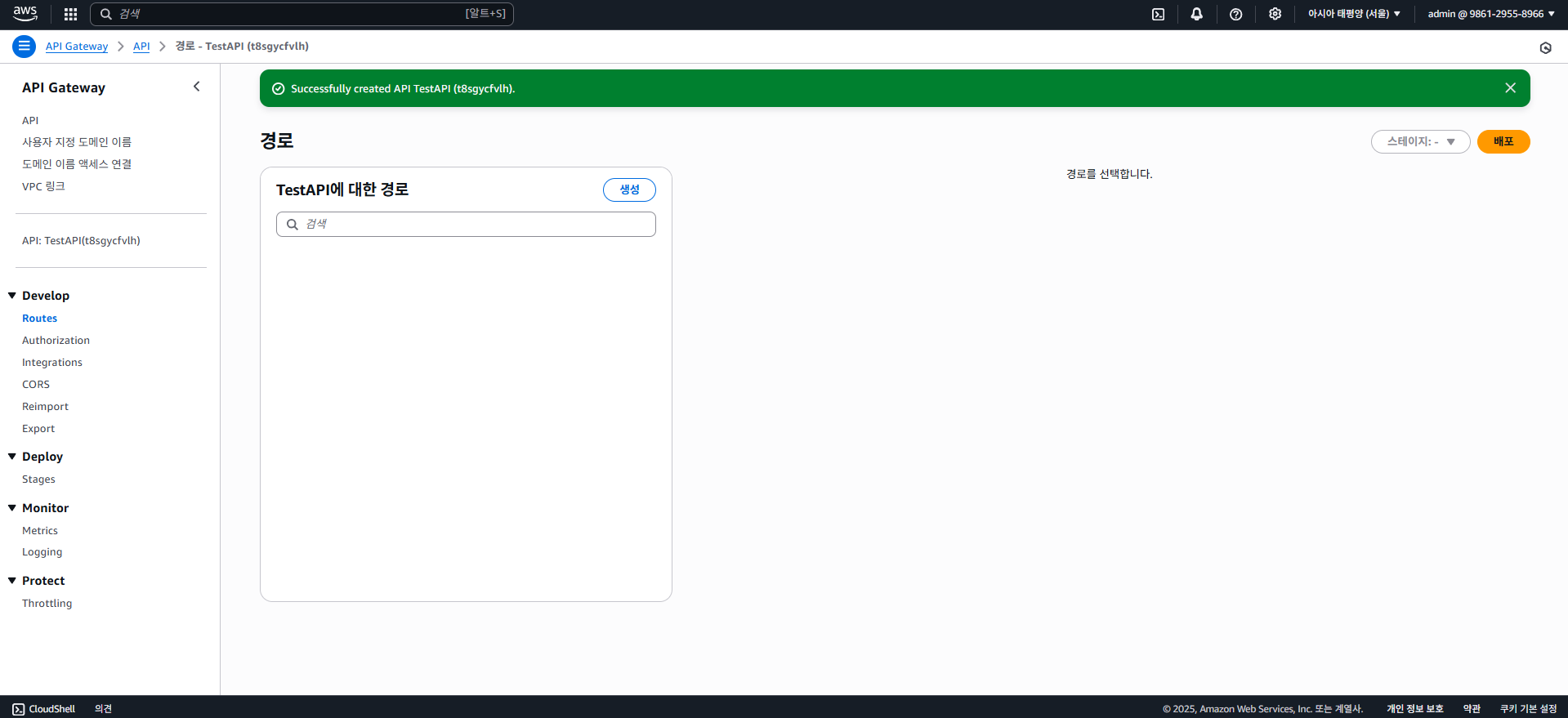
이제 라우팅, 즉 경로 설정을 해줘야 하는데 Develop 메뉴의 Routes에 들어가 "생성"을 클릭해보자.
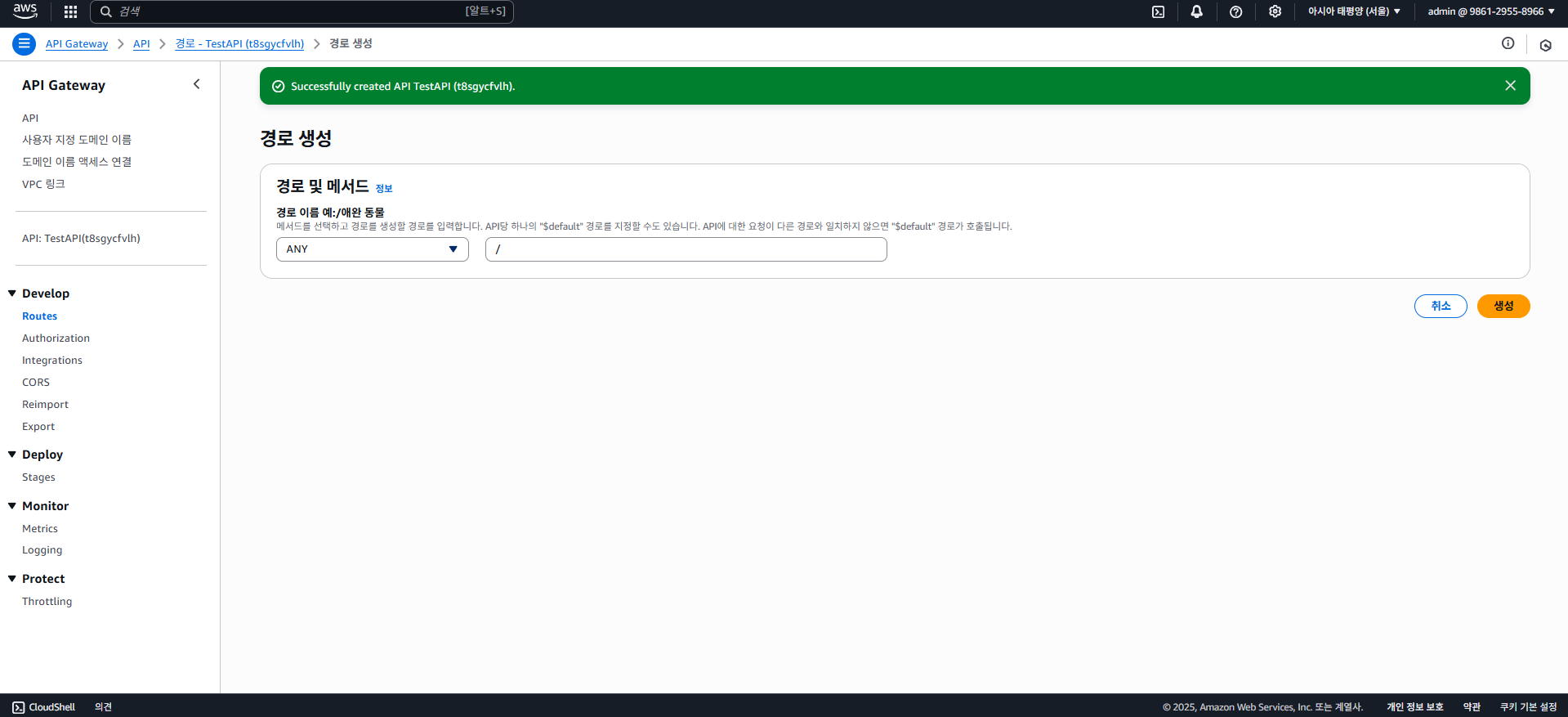
그럼 메서드와 경로(엔드포인트)를 선택하고 작성할 수 있는 화면이 나타나는데, 아까 만들어둔 두 값을 더하는 함수는 Body에 값을 제공하기 때문에 적절하게 POST 메서드를 선택하고, 경로(엔드포인트)는 /hello로 설정해두었다.
경로엔 * 등의 와일드카드나 /{id} 등의 동적 파라미터를 지정할 수 도 있다. (그 값은 람다 함수의 event 파라미터에서 확인할 수 있음.)

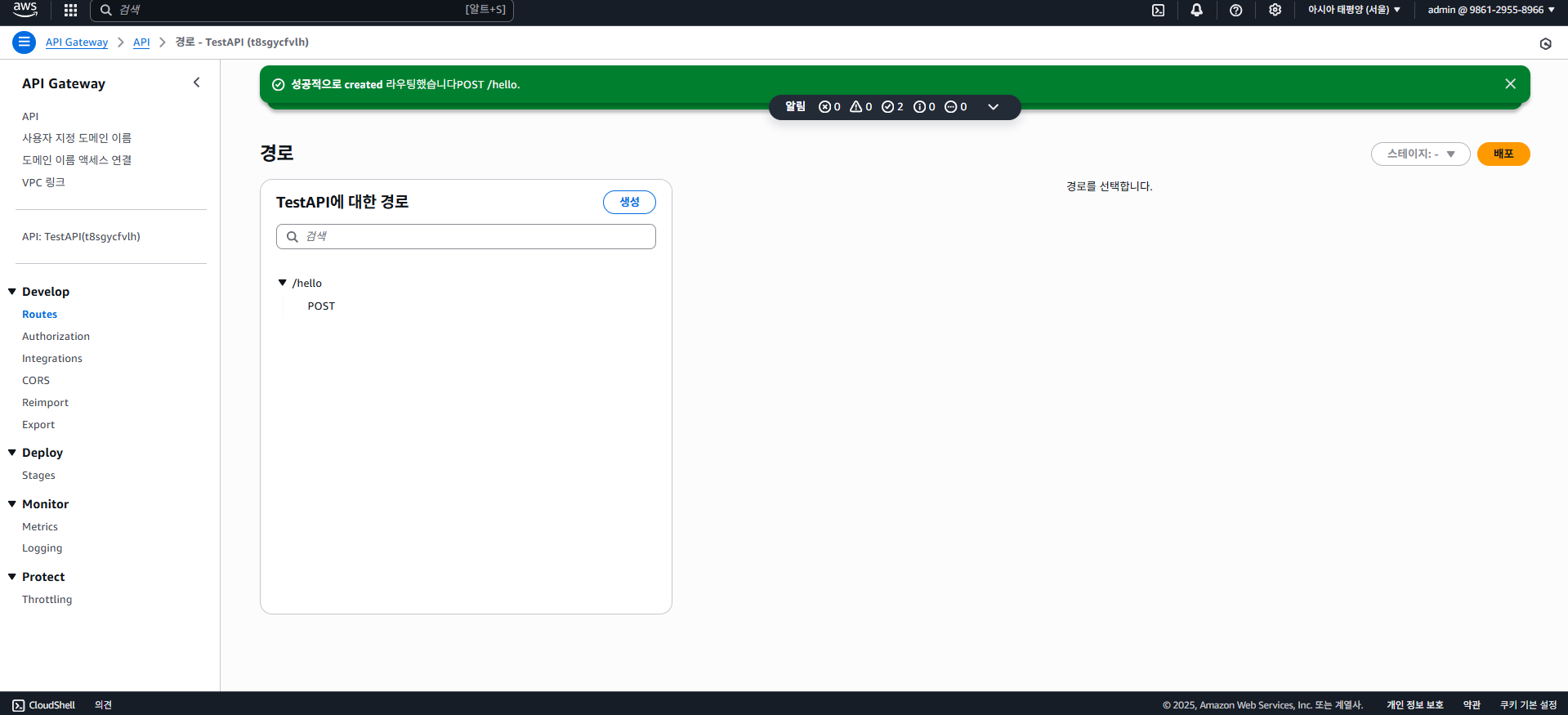
생성해보면 경로가 생기는데, 이제 여기에 람다 함수를 붙여줘야 한다.
AWS API Gateway에서 경로에 람다를 붙여주는걸 통합(Integrations)이라 한다.
Develop > Integrations 탭으로 가서 POST /hello를 선택하고 "통합 생성 및 연결"을 클릭하자.
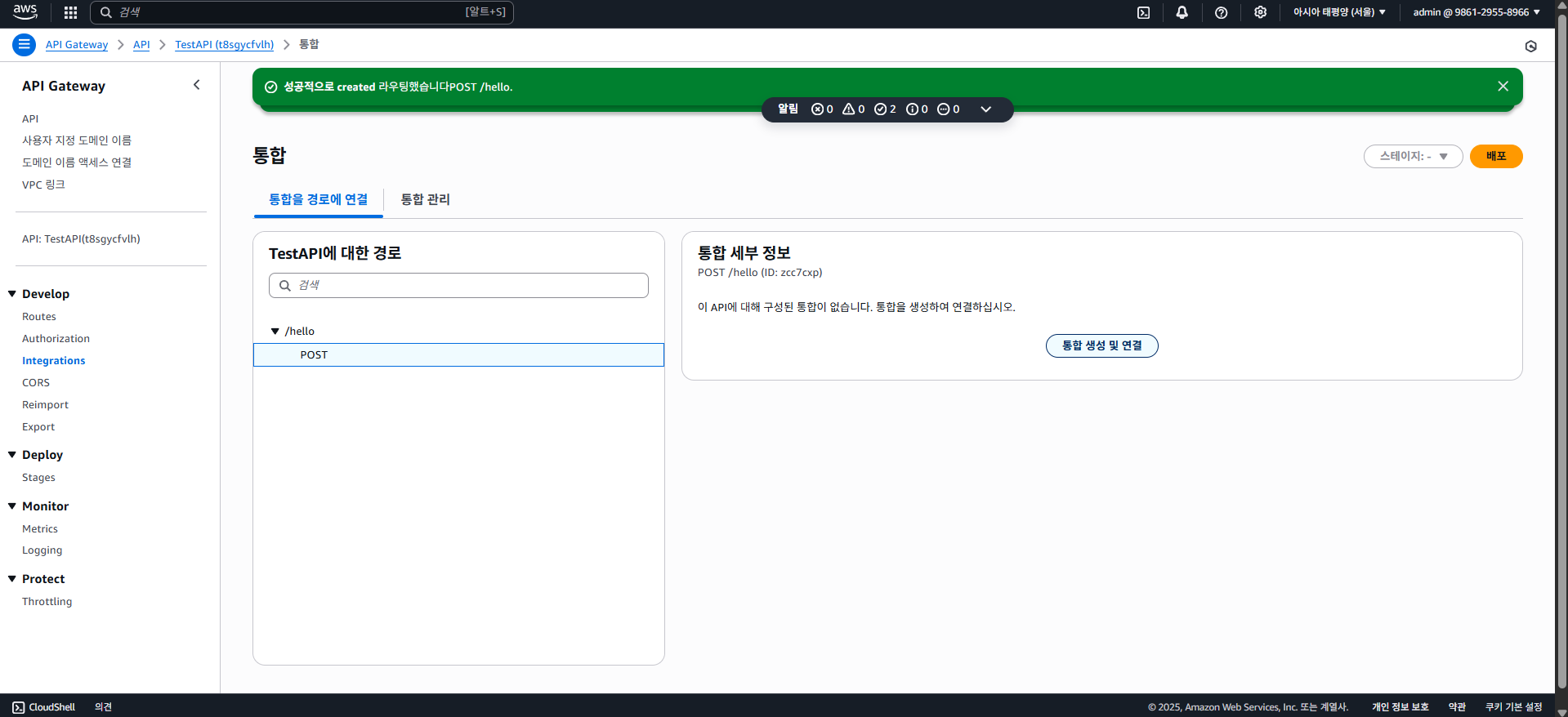
그럼 "통합 대상"을 정할 수 있는데, 람다를 클릭하고 통합 세부 정보에 람다 함수를 넣자. (ARN 입력 가능)
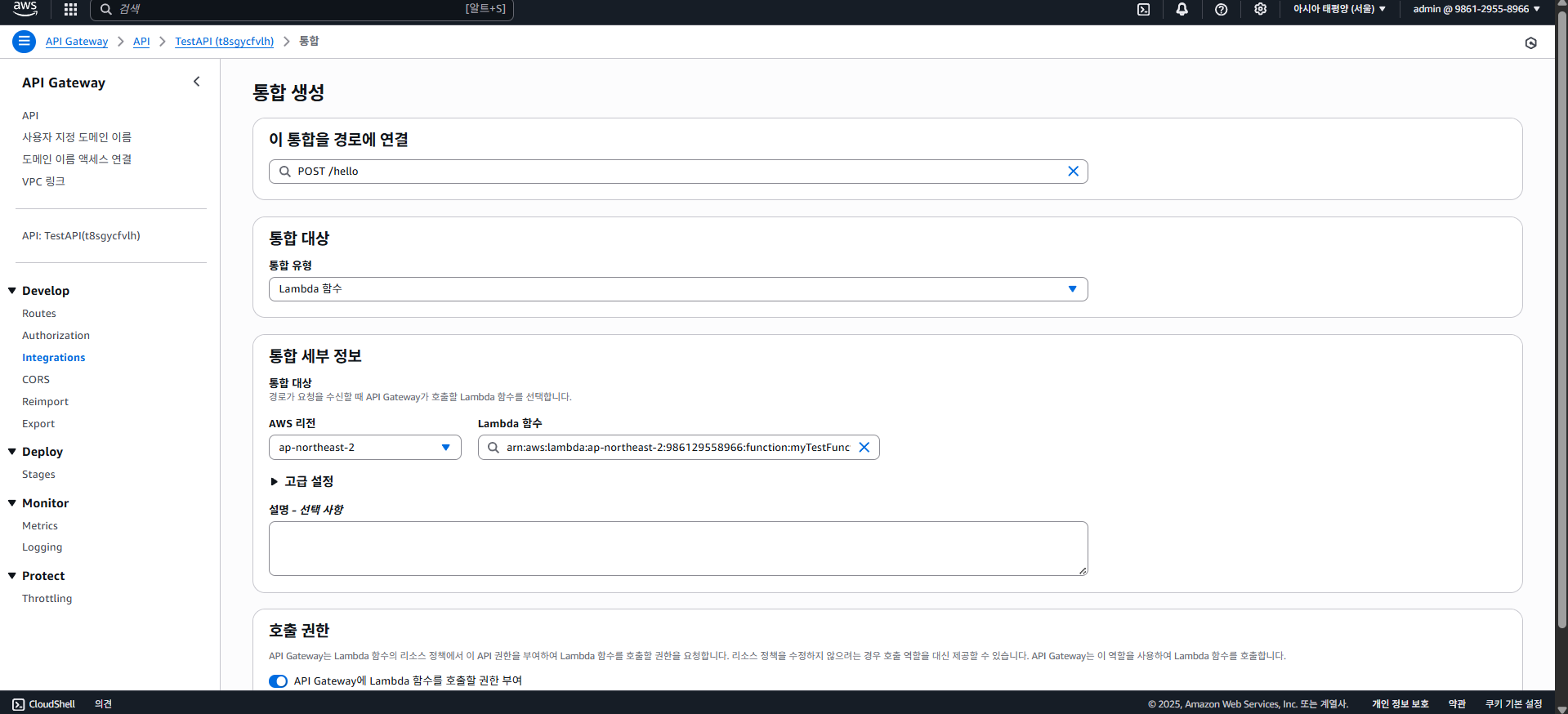
그리고 생성하기 버튼을 클릭하면 생성이 되는걸 확인할 수 있다.
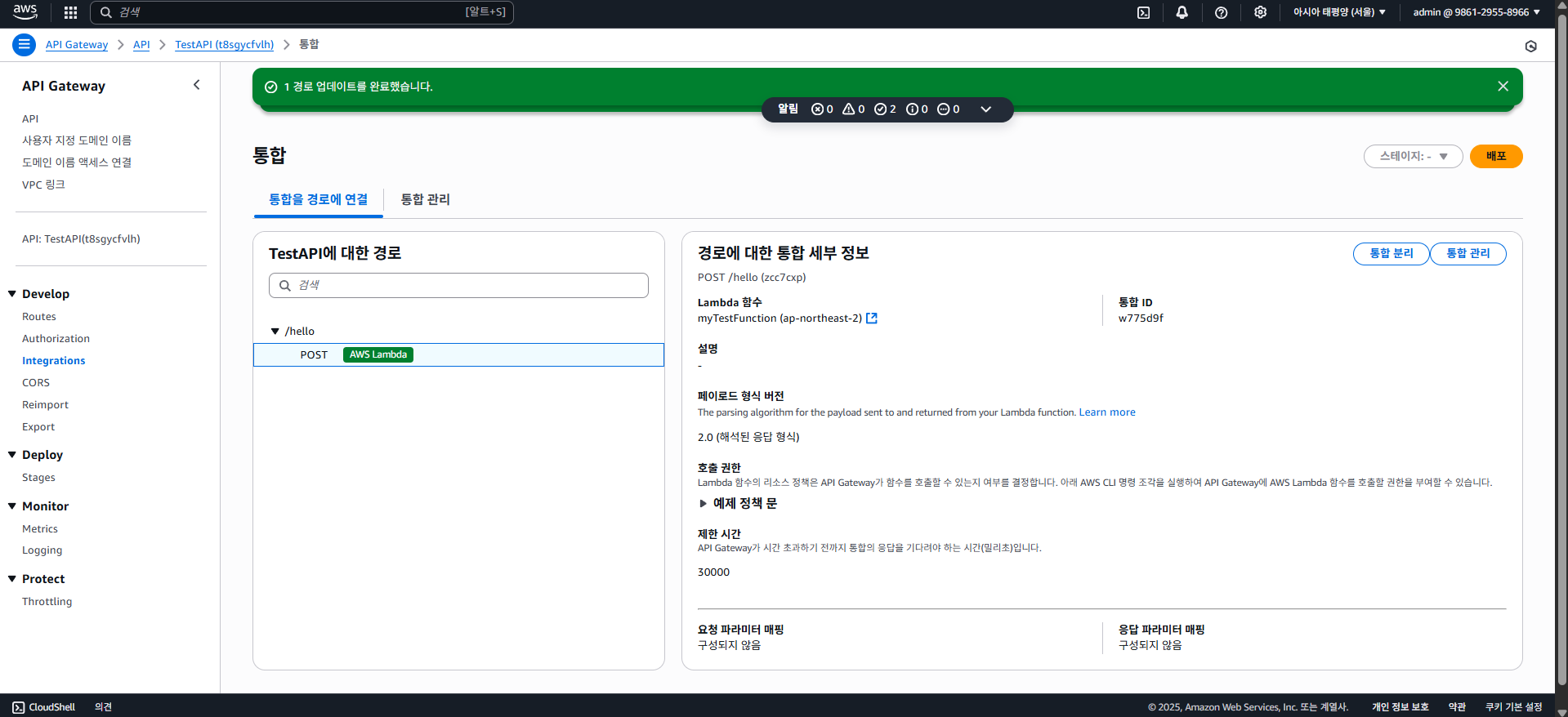
마지막으로 스테이지 배포까지 하고 나면 POST /hello에 대한 API가 구축되는 것이다.
Testing with Postman
이제 람다와 API Gateway를 사용하여 구축했던 API를 테스트해보자.
GET 메서드를 사용했을 경우 간단히 브라우저에서 테스트해볼 수 있겠지만 POST 메서드를 사용했으므로 편의 상 API 개발 및 테스트 플랫폼인 Postman을 사용해볼 예정이다.
VSCode의 Thunder Client나 REST Client 등의 HTTP 클라이언트를 사용해도 좋다.
먼저 Postman에 접속하고 Collections에서 새로운 Collection을 만들자.
그리고 New Request를 클릭하여 API 요청을 보낼 화면을 띄우고, 요청 방식을 GET에서 POST로 변경하고 API Gateway의 대시보드에서 "기본 엔드포인트" 또는 "스테이지 URL 호출"에서 URL을 찾아 Postman에 입력하자.
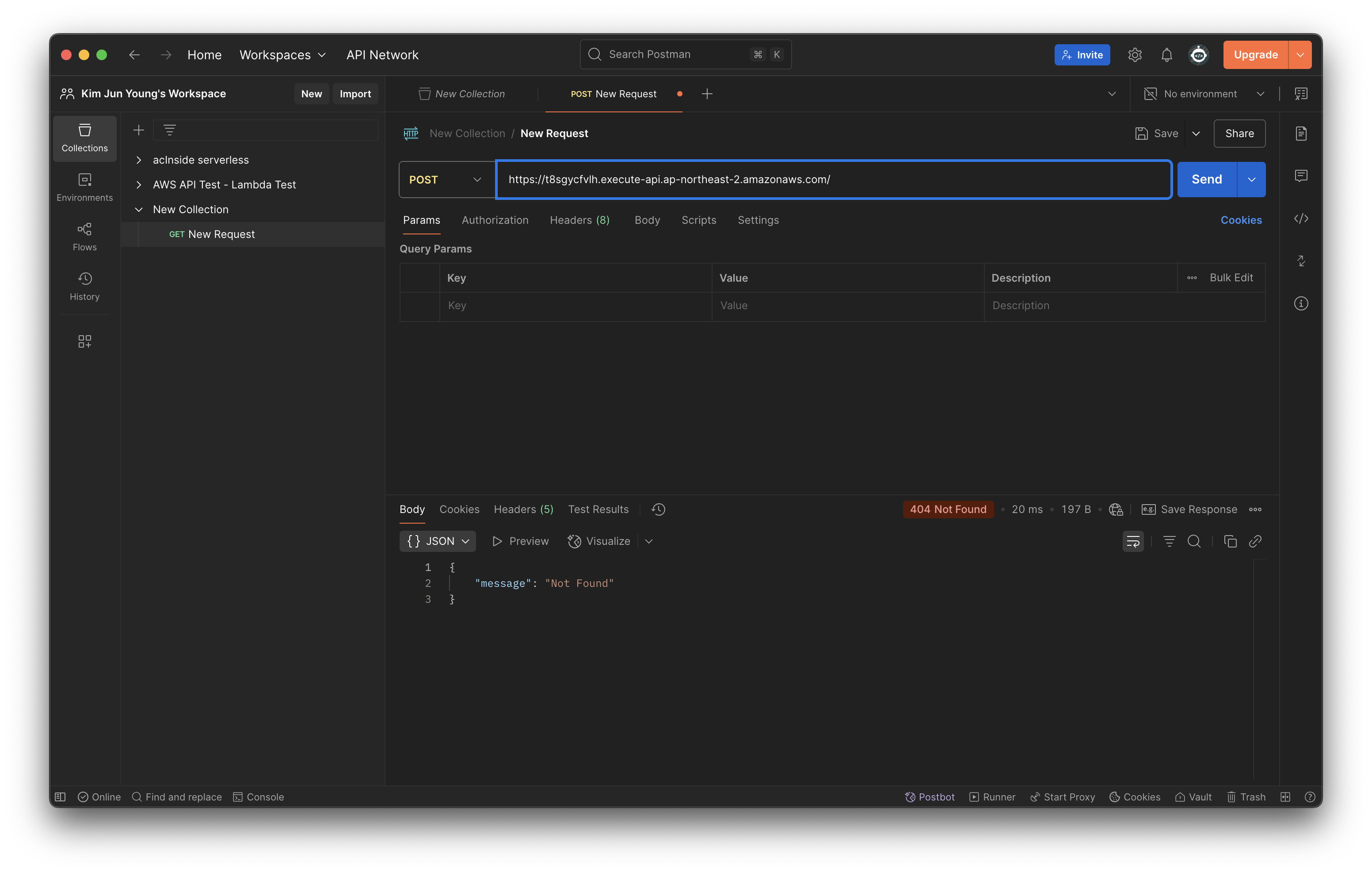
그리고 Send 버튼을 누르면 404 Not Found가 뜰텐데, 우리가 /에 대한 경로를 지정하지 않았기 때문이다.
우리가 지정했던 /hello 엔드포인트를 URL에 추가하고 실행해보자.
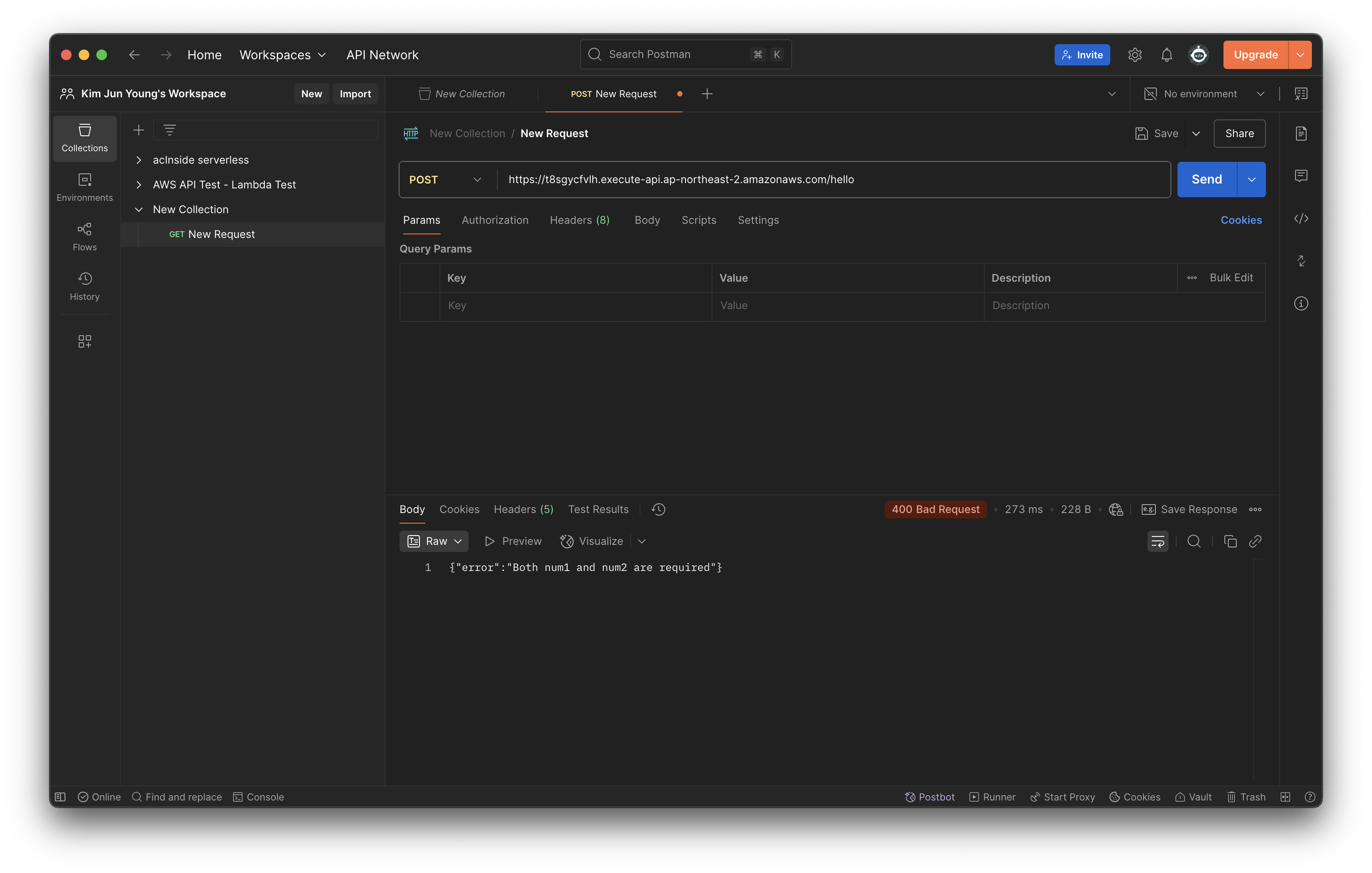
역시 에러가 뜨는데, 우리가 함수에 핸들링했던 에러가 나타난다. Body에 값이 없다는 뜻이니 Body 탭에 데이터를 입력하고 보내보자. (형식은 Raw > JSON을 선택한다.)
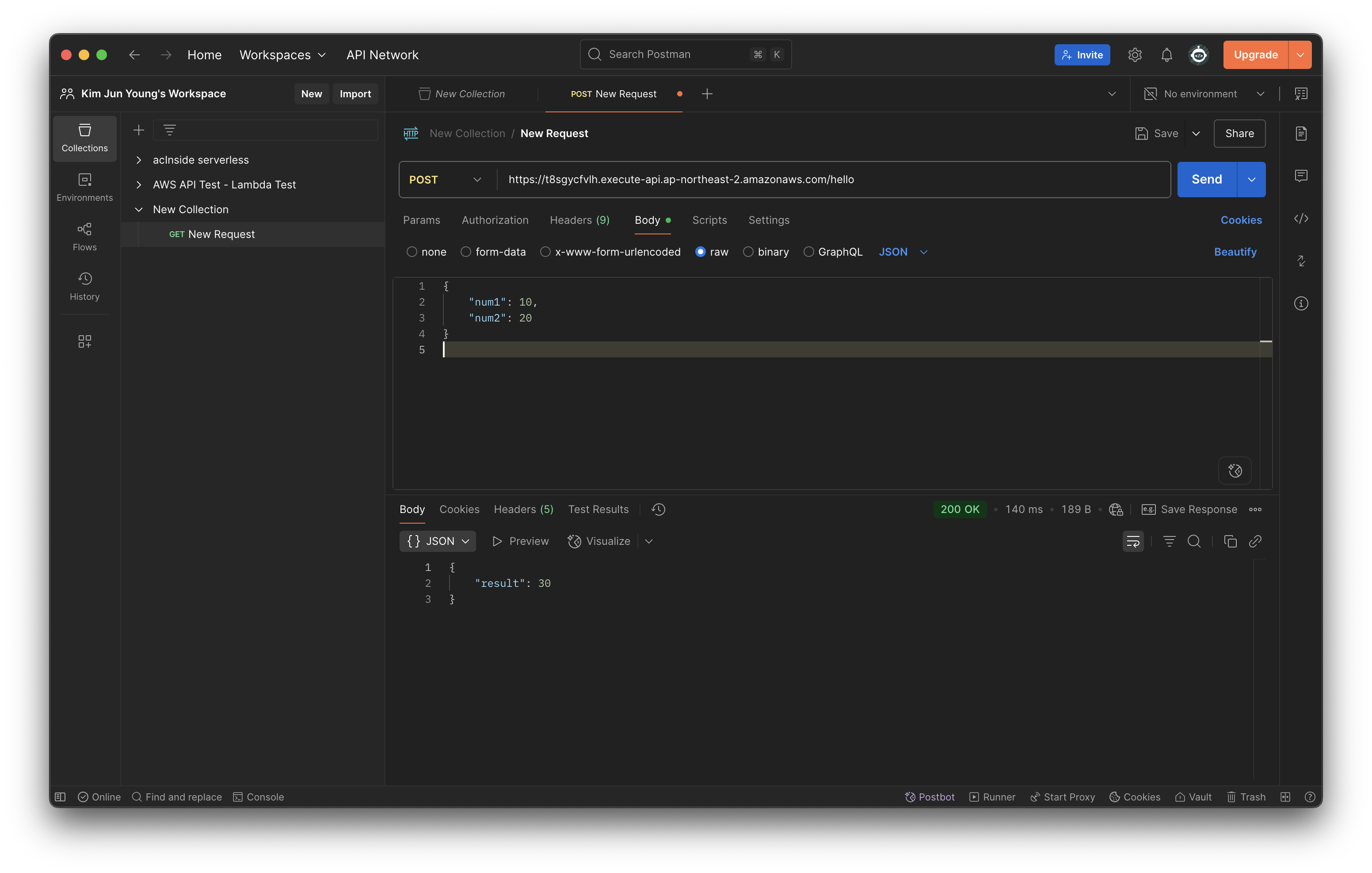
그럼 위와 같이 성공적으로 결과 값이 나타난다.
이후 Cognito를 설정하고, Cognito를 연동해볼 때 다시 한번 살펴보도록 하자.
나중엔 람다와 API Gateway는 Serverless Framework를 사용하여 자동화할 것 이다.
6-3. Cognitto Authorization
AWS Cognito에 들어가보자.
다음으로 사용자 풀(유저 풀) > 사용자 풀 생성을 클릭하여 유저 풀을 만들어보자.
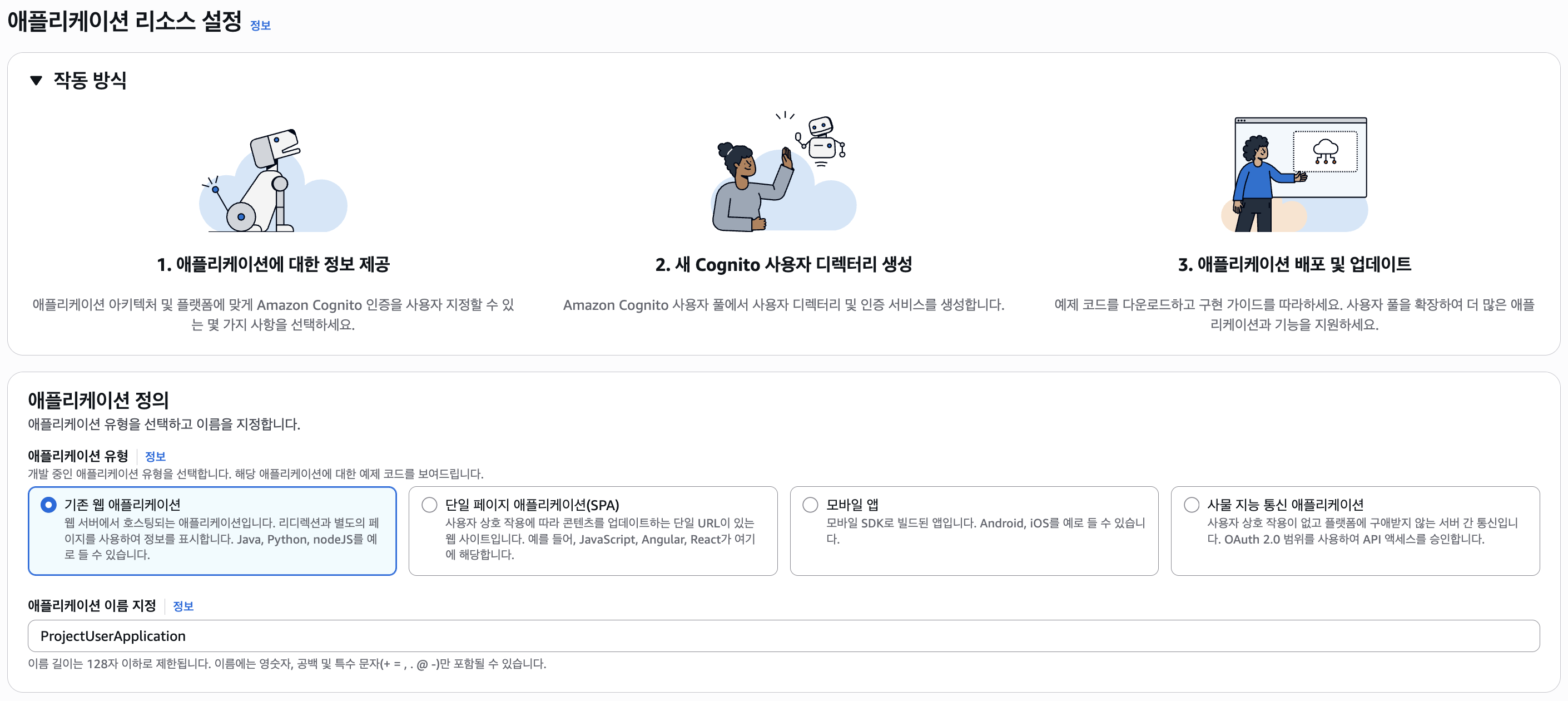
먼저 애플리케이션 리소스 설정에선 크게 "기존 웹 애플리케이션"과 "단일 페이지 애플리케이션(SPA)"을 선택할 수 있는데, 후자는 백엔드 없이 클라이언트에서 Cognito에 접근할 때 사용되므로 "기존 웹 애플리케이션"을 선택하자.
다음으로 애플리케이션의 이름을 정하고 로그인 옵션을 설정한다.
(애플리케이션은 백엔드나 프론트엔드에서 Cognito 클라이언트에 접근하기 위한 것으로, 유저 풀은 별도로 존재한다.)
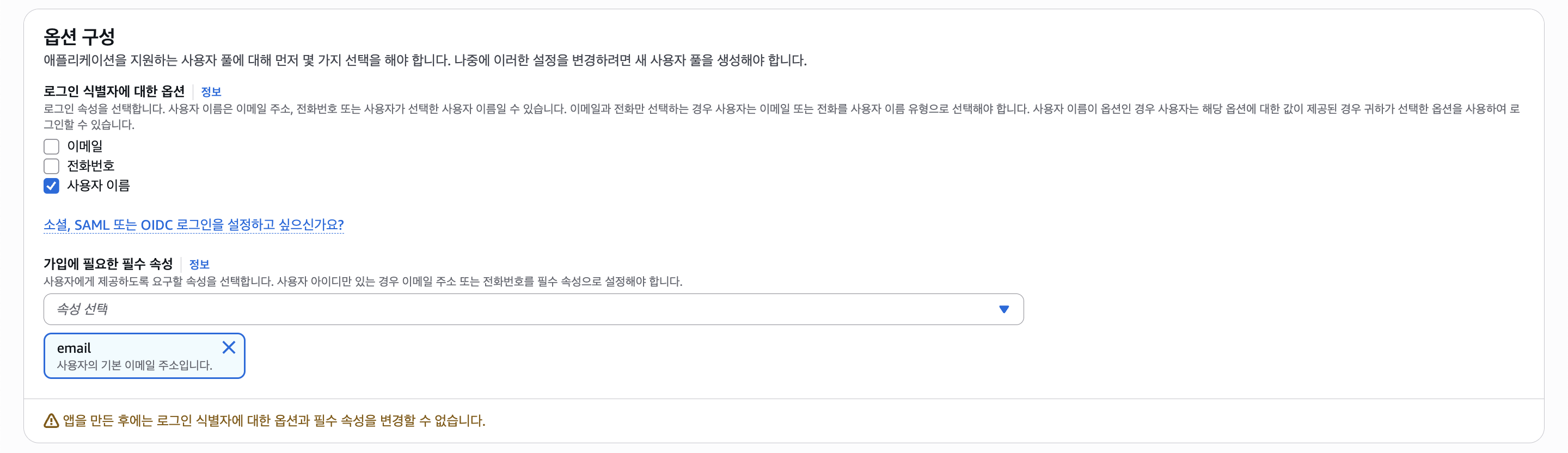
어떠한 방식으로 유저를 식별할 지 선택할 수 있는데, 여기선 사용자 이름을 선택한다.
그러려면 회원가입 시 이메일을 제공해야되는데 그래서 "가입에 필요한 필수 속성"에서 이메일을 선택하자.
그러면 유저 풀에 클라이언트가 사용할 애플리케이션이 만들어진다.
위 화면에서 "로그인 페이지 보기"를 선택하면 AWS에서 기본적으로 제공하는 로그인/회원가입 페이지가 나타나는데, 이는 설정을 통해 비활성화 할 수 있다.
즉 로그인과 회원가입에 대해선 백엔드 람다 함수를 통해서만 생성하게 하는 것이다.
코드를 배포하여 API를 구현하기 전, 유저가 잘 생성될지 테스트를 위해 AWS에서 제공하는 회원가입 페이지에서 회원가입을 해보자.
그러면 이메일 인증을 하라고 하는데, 아까 가입에 필요한 필수 속성에서 이메일을 선택하였기 때문이다. (아까 설정에서 전화번호를 선택할 수 도 있다.)
다만 이에 대해선 요금이 부과될 수 있다.
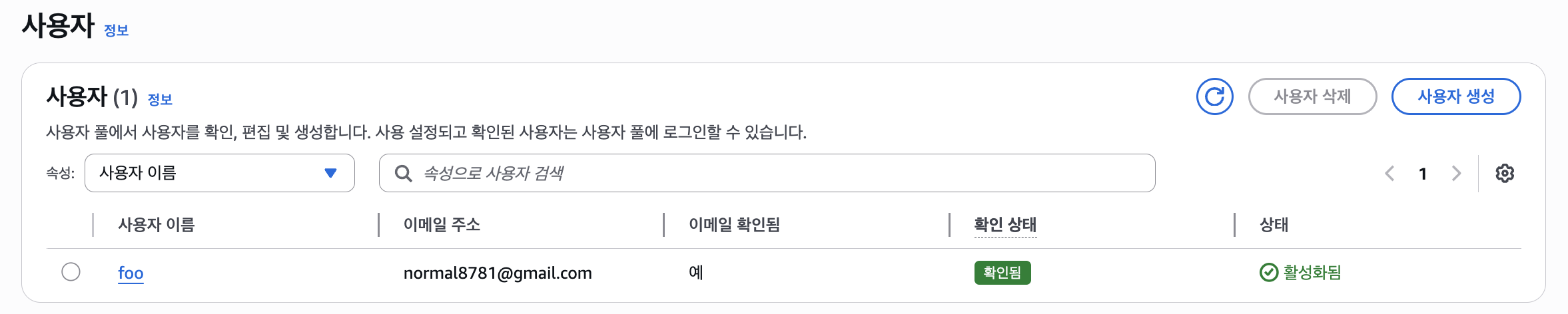
이메일 인증 후 확인해보면 위와 같이 가입이 됐다고 나오며, AWS 유저 풀로 들어가보면 방금 생성했던 유저가 나타나는 것을 볼 수 있다.
하지만 이렇게만 생성하면 엑세스 토큰과 리프레시 토큰이 나타나지 않는데, 이는 아까 설명했던 코드처럼 AWS SDK를 사용하여 가져올 수 있다.
그리고 Cognito엔 플랜이 있는데, 기본적으로 에센셜(Essentials) 플랜으로 제공된다.
Cognito 플랜엔 크게 Lite, Essentials, Plus가 존재하는데 이 포스팅에서 사용하는 Cognito 기능은 Lite에서도 모두 사용할 수 있다.
하지만 요금은 Lite와 Essentials 사이에 거의 3배 가까이 차이가 나는데, 때문에 Lite로 전환하는걸 추천한다. (설정에서 가능)
Serverless Framework(CloudFormation)에서도
UserPoolTier: LITE속성으로 설정할 수 있다.
Cognito + API Gateway
이제 Cognito와 API Gateway를 연동해보자.
어떤식으로 연동이 되냐면 사용자는 람다에 요청을 보낼 때 Authorization 헤더를 포함하고 요청하여 인증을 한다.
API Gateway에서 Cognito와 연동을 하게 되면 이 인증을 자동으로 검증해주고 디코딩하여 event.requestContext.authorizer?.jwt?.claims 등의 코드를 사용하여 이에 대해 접근할 수 있다. (위 코드는 JWT 토큰의 클레임을 확인함.)
API Gateway에서 Authorization 항목에서 Cognito와 연동할 수 있다.
"권한 부여자 생성 및 연결"을 클릭해보자.
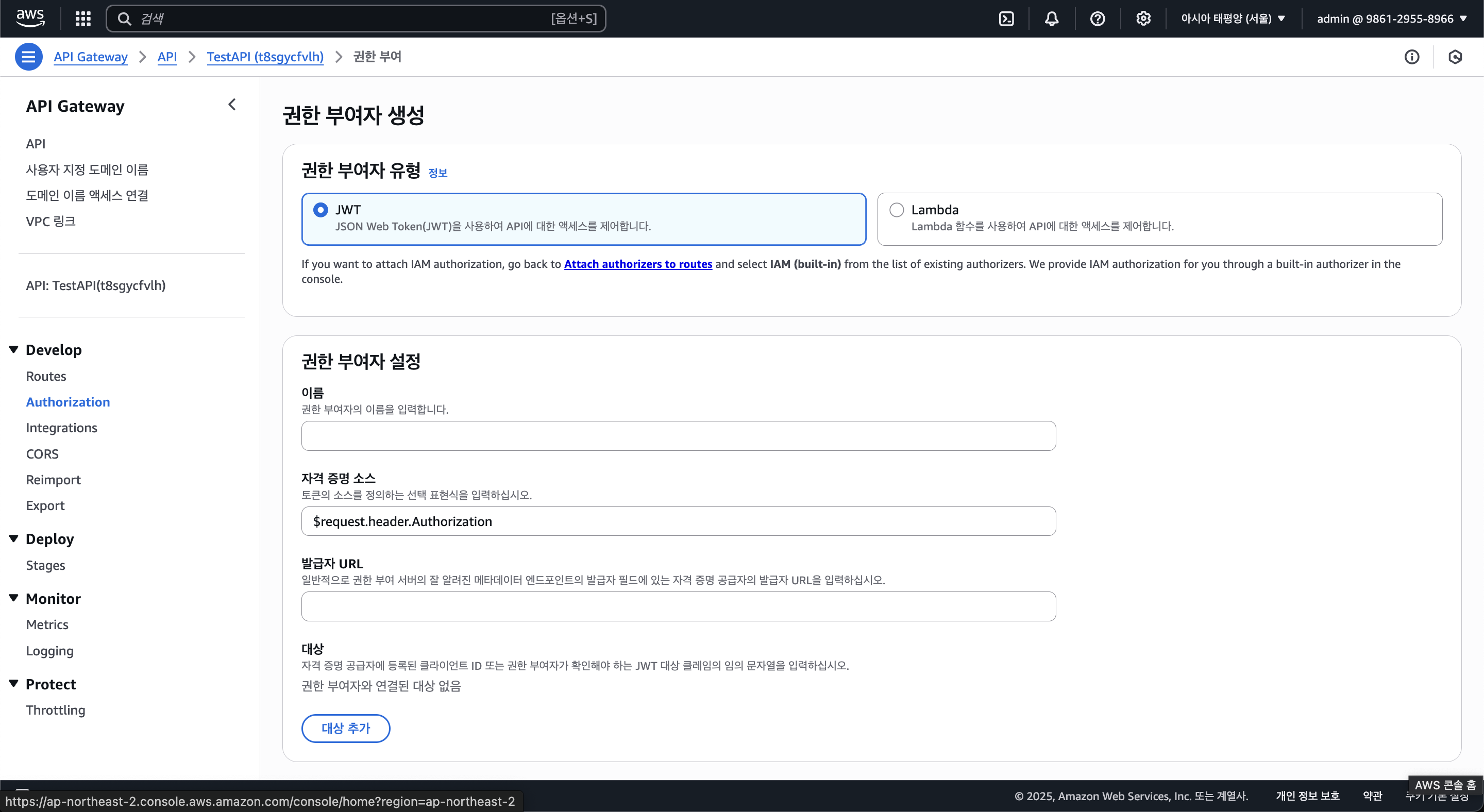
람다로 직접 인증 로직을 작성할 수 도 있으나, Cognito를 사용하여 JWT 인증이 필요하니 JWT를 선택해둔다.
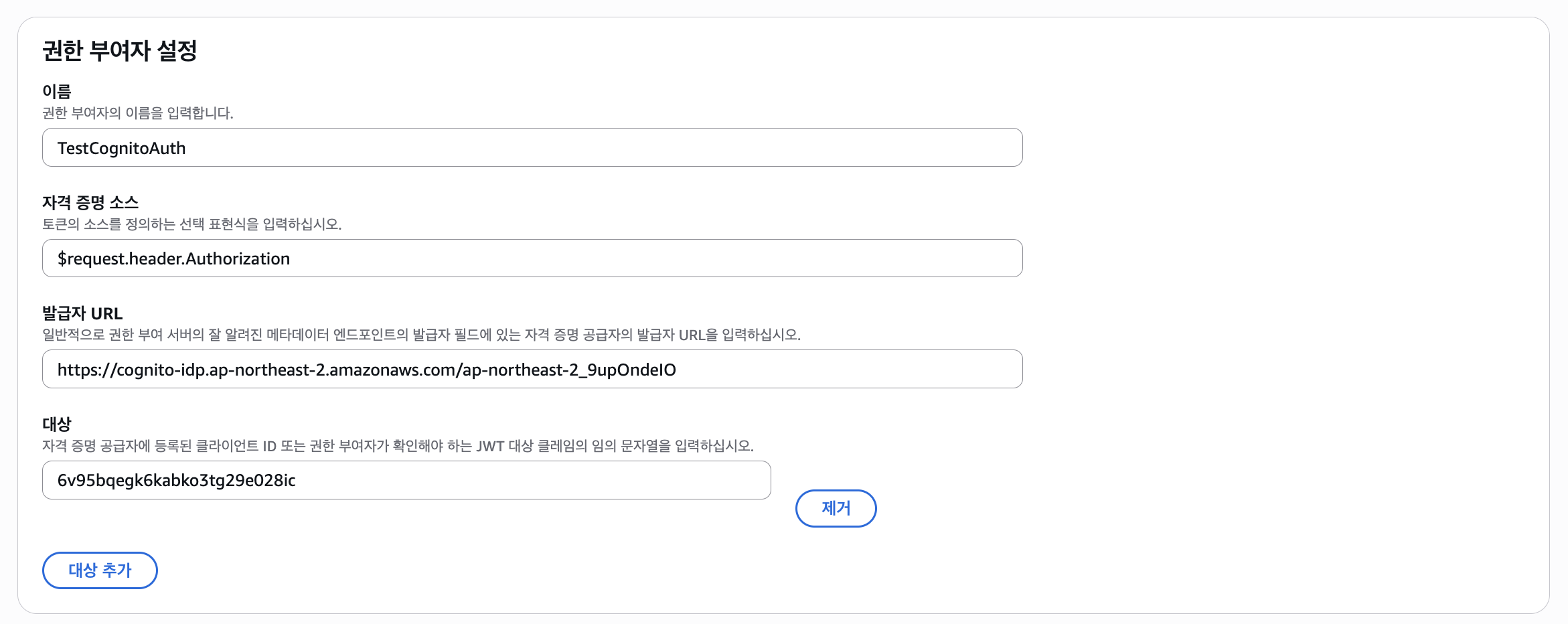
아래의 "권한 부여자 설정"에선 권한 부여자의 이름과 자격 증명(=JWT) 소스(=Authorization 헤더)를 설정할 수 있고, 발급자 URL과 대상을 입력해야된다.
발급자 URL은 Cognito 유저 풀의 IDP(유저 풀을 제공하는 서비스) URL을 기입해야 되는데, 그 형식은 아래와 같다.
https://cognito-idp.[Region].amazonaws.com/[User_Pool_ID]그리고 대상엔 Cognito 앱 클라이언트의 ID를 입력한다.
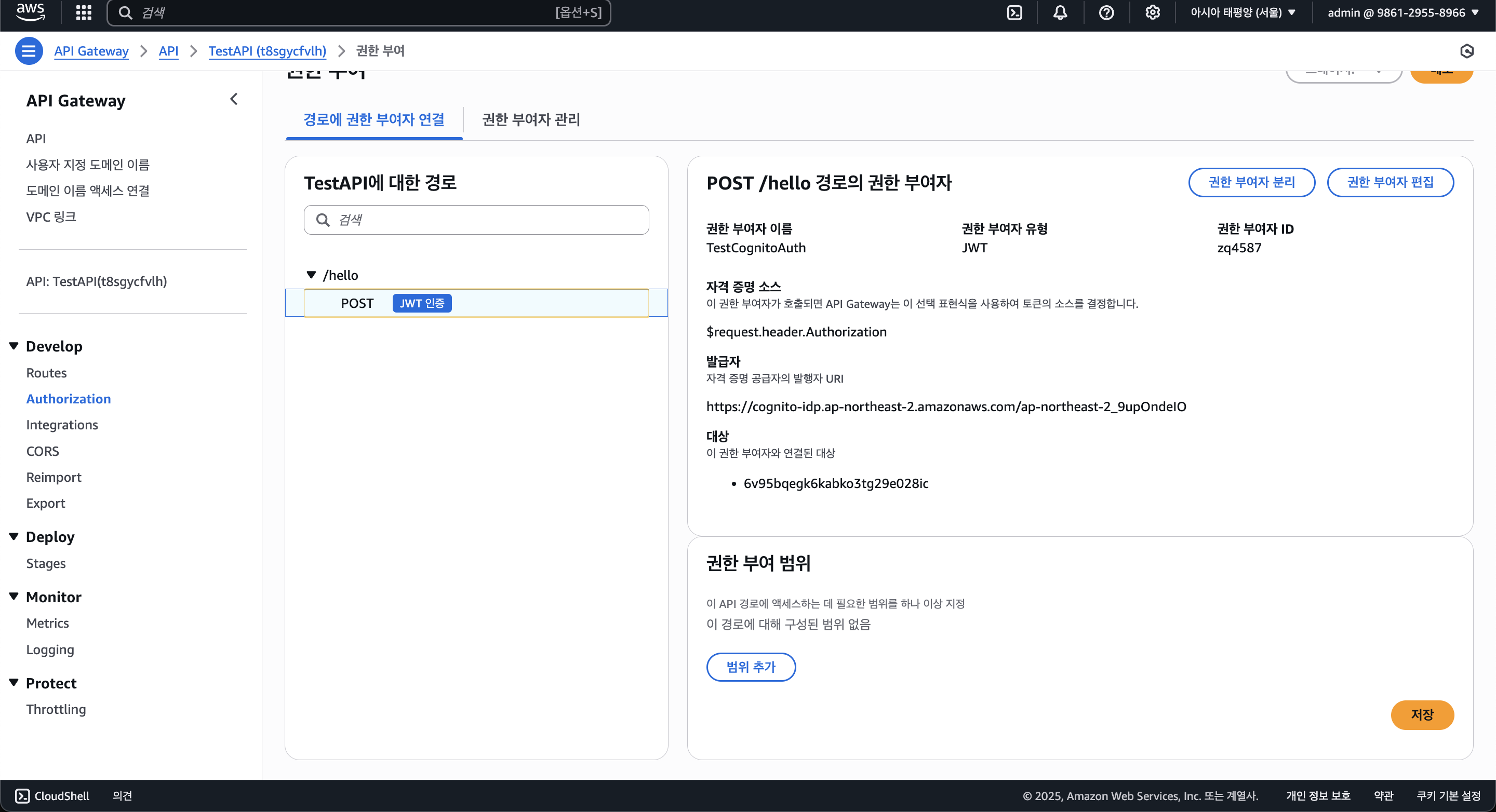
그럼 Cognito 권한 부여자가 생겼고, 나중에 이를 돌려쓸 수 있게 된다.
이 작업은 이후 Serverless Framework에서 다시 IaC로 작성해볼 예정이다.
6-4. CRUD with DynamoDB
다음으로 포스팅을 저장하기 위한 Posts 테이블과 Counter 테이블을 만들어보자.
다만 추후에 Serverless Framework 사용 시 기존의 인프라에 같은 이름의 리소스가 존재하면 안되는데, 이렇게 되면
Posts와Counter리소스가 이미 존재하게 된다.필자는 이 파트에서 만들고 삭제할 예정이지만, 다른 리소스 이름(
Posts_Test등)을 사용해도 괜찮다.
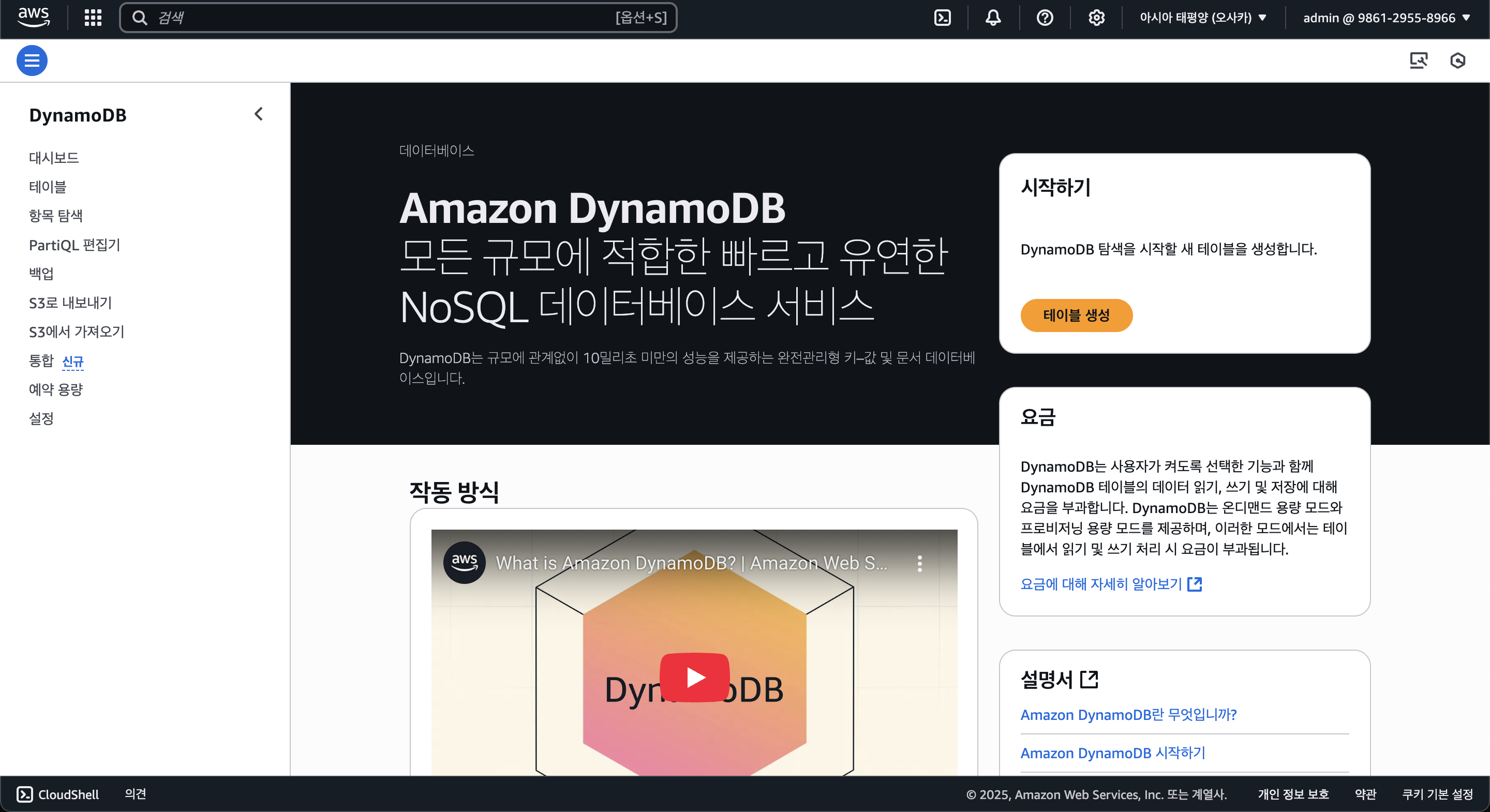
AWS Console에서 DynamoDB에 접속한 후 Posts 테이블을 만들자. Posts 테이블의 파티션 키(기본 키)는 id이며, String 타입이다. (정렬 키는 이 포스팅에선 설명하지 않는다.)
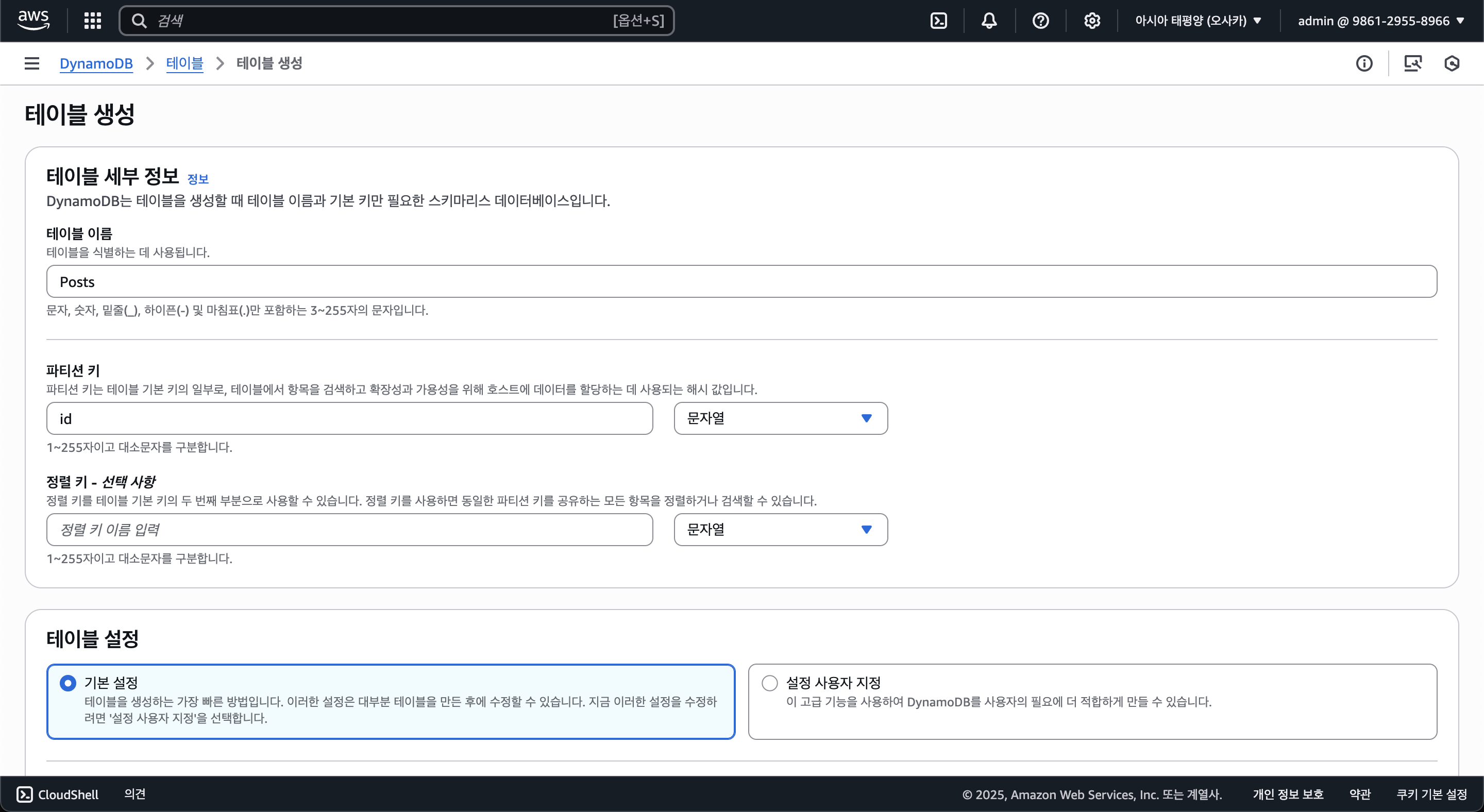
그 뒤 DynamoDB의 용량이나 성능 등의 세부 정보를 설정할 수 있으나, 일단 기본값으로 냅두고 만들겠다.
같은 방식으로 Counter 테이블을 만든다. 다만 Counter 테이블의 파티션 키는 name이며, String 타입이다.
const getNextId = async (): Promise<number> => {
const command = new UpdateCommand({
TableName: 'Counter',
Key: { name: 'post' },
UpdateExpression: 'SET #v = if_not_exists(#v, :init) + :inc',
ExpressionAttributeNames: { '#v': 'value' },
ExpressionAttributeValues: {
':inc': 1,
':init': 0,
},
ReturnValues: 'UPDATED_NEW',
})
const result = await dynamoDB.send(command)
return result.Attributes?.value
}위 코드를 보면 알 수 있듯이 Counter 테이블의 post라는 키를 가진 아이템을 생성해주자.
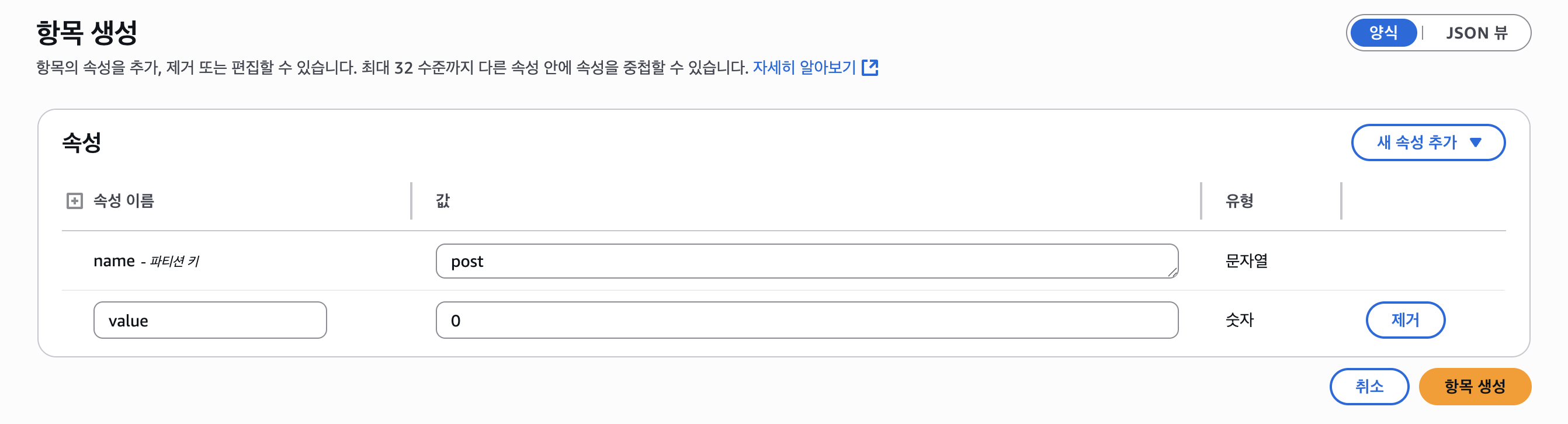
value 속성이 없어도 알아서 만들어주지만 예시를 위해 설정을 해두자.
Lambda IAM
이제 DynamoDB를 만들었다면 람다에서 DynamoDB에 접근할 IAM 권한이 필요하다.
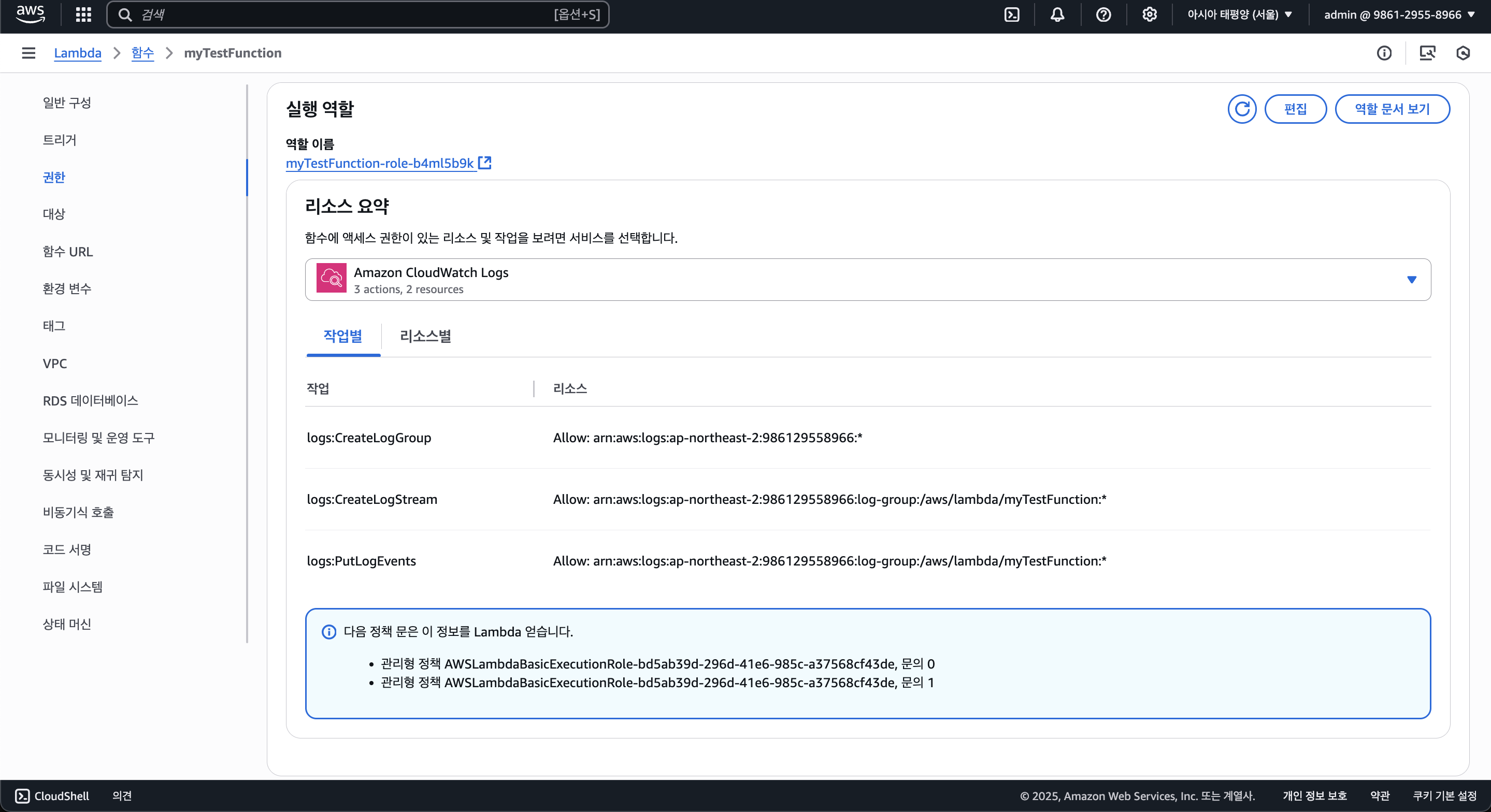
람다 함수를 보면 기본적으로 CloudWatch에 대한 권한만 존재한다. (Allow: logs:CreateLogStream, Allow: logs:PutLogEvents, 로그 그룹 생성은 모든 리소스(서비스)에서 생성할 수 있음)
람다 함수 별로 IAM 역할을 각자 만들거나 하나의 IAM 역할을 돌려쓸 수 있는데, 이 포스팅에선 각 람다 별 IAM 역할을 만드는게 아닌 하나의 IAM 역할을 돌려 쓸 예정이다.
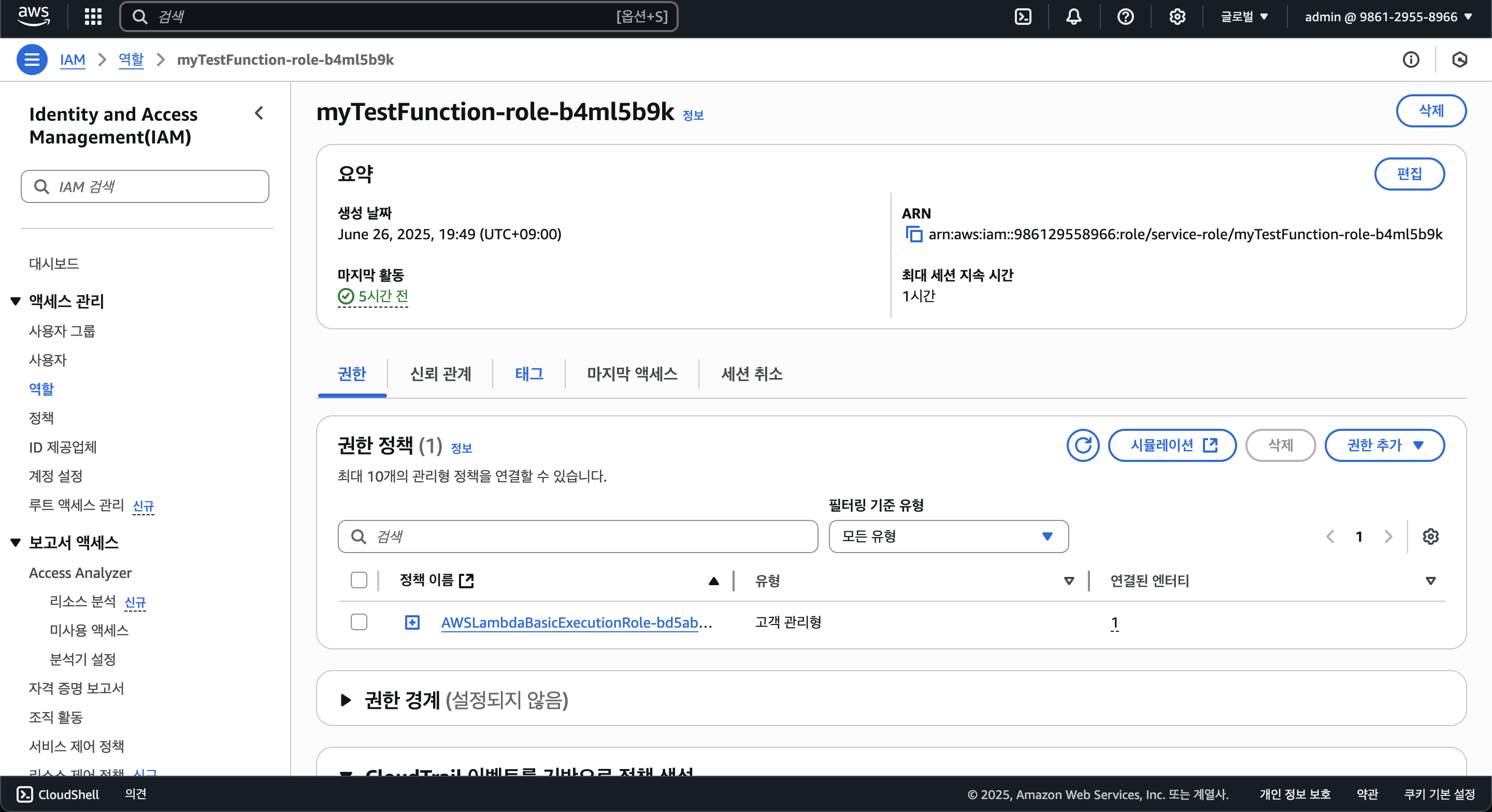
IAM 역할로 들어가 설정을 해보자. 권한 정책에 있는 정책을 클릭해보면 아래와 같은 화면이 나타난다.
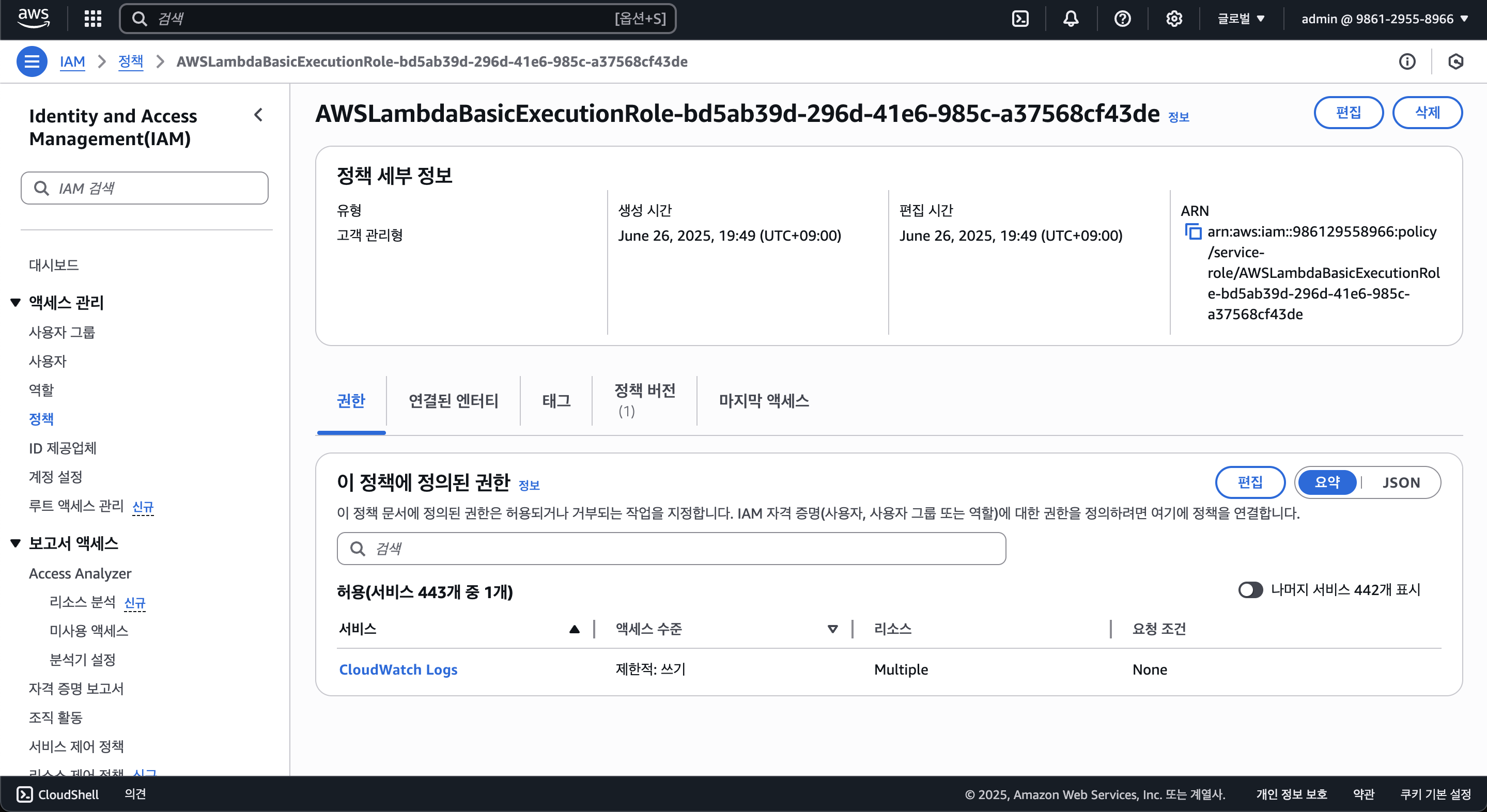
여기서 "이 정책에 정의된 권한"에서 편집을 클릭하자.
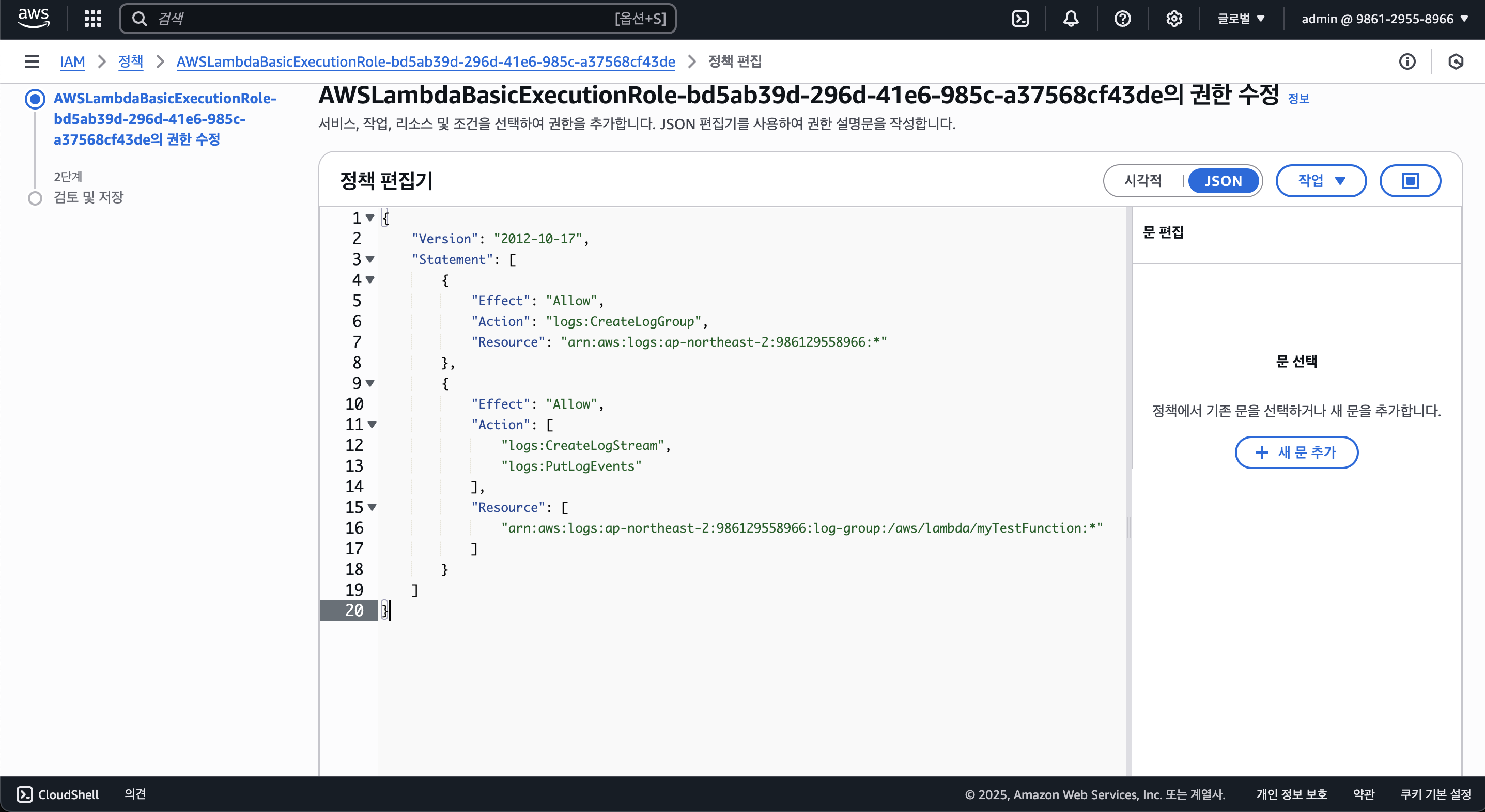
그럼 위와 같이 JSON 형태의 IAM 정책이 나타나는데, 어떤 리소스에 대해 어떠한 정책 Allow할지 선택할 수 있으며, 일단 아래와 같은 정책을 허용하도록 설정해보자.
dynamodb:PutItem: 아이템 생성 권한 (Create)dynamodb:GetItem: 아이템 읽기 권한 (Read)dynamodb:Scan: 아이템 모두 읽기 권한 (Read)dynamodb:Query: 아이템 쿼리 읽기 권한 (Read)dynamodb:UpdateItem: 아이템 수정 권한 (Update)dynamodb:DeleteItem: 아이템 삭제 권한 (Delete)
이 밖의 DynamoDB에 대한 다양한 IAM 정책을 확인하려면 AWS 공식 문서를 참고하길 바란다.
dynamodb:*를 사용하여 DynamoDB에 대한 모든 권한 정책을 부여할 수 있으나, 보안상의 안전을 위해 꼭 필요한 기능만 활성화하는 것을 추천한다.
그리고 위 IAM 권한은 아까 만들어둔 Posts와 Counter 테이블이라는 리소스에 대해 부여할 예정이다.
위 IAM 권한 정책을 바탕으로 아래와 같은 JSON을 작성하여 설정할 수 있다.
{
"Action": [
"dynamodb:PutItem",
"dynamodb:GetItem",
"dynamodb:Scan",
"dynamodb:Query",
"dynamodb:UpdateItem",
"dynamodb:DeleteItem"
],
"Resource": [
"[Posts_Tabble_ARN]",
"[Counter_Table_ARN]"
],
"Effect": "Allow"
}각 DynamoDB 테이블의 ARN(Amazon Resource Name)은 아래와 같은 형식이다.
arn:aws:dynamodb:[Region]:[Account_ID]:table/[Table_Name]알맞은 ARN을 기입하고 아래와 같이 JSON의 Statement 필드 안에 입력하고 "다음" 버튼을 누르자.
에러가 없는지 확인하고, 아래와 같이 나온다면 성공한 것이다.
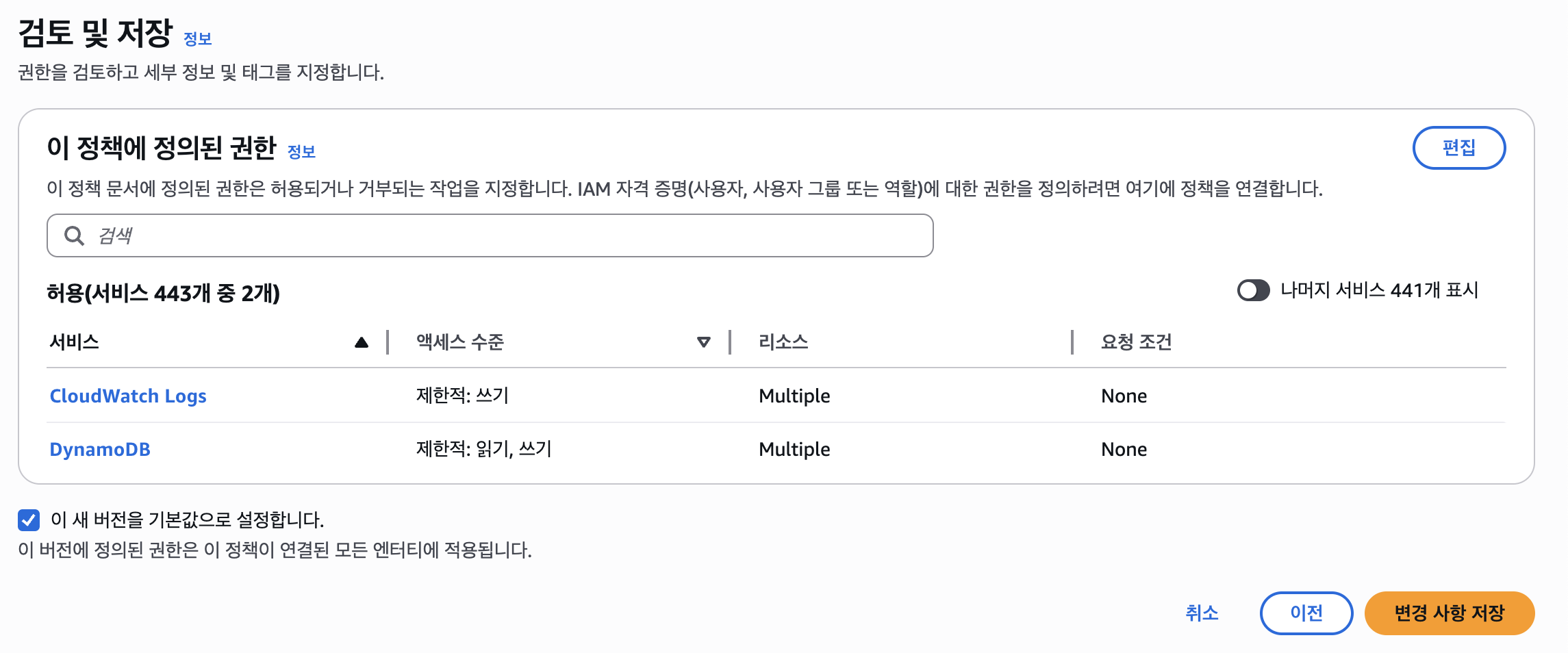
변경 사항 저장을 클릭하여 권한을 저장하자. 그리고 DynamoDB에 대한 읽기/쓰기 권한을 테스트하기 위해 아래의 람다 함수 코드를 람다에 넣고 수정한 뒤 테스트해보자.
import { DynamoDBClient } from '@aws-sdk/client-dynamodb'
import { DynamoDBDocumentClient, PutCommand, GetCommand } from '@aws-sdk/lib-dynamodb'
const dynamoDB = DynamoDBDocumentClient.from(new DynamoDBClient())
export const handler = async () => {
const item = {
id: '1',
title: 'Hello World',
content: 'This is a test post.',
createdAt: new Date().toISOString(),
userId: 'TestUserID',
userName: 'Foo',
}
await dynamoDB.send(
new PutCommand({
TableName: 'Posts',
Item: item,
})
)
const result = await dynamoDB.send(
new GetCommand({
TableName: 'Posts',
Key: {
id: item.id,
},
})
)
return {
statusCode: 200,
body: JSON.stringify({
message: 'Post created successfully',
post: result.Item,
}),
}
}아까 생성해두었던 POST /hello에 연결된 람다에 수정해두었고, Postman을 이용하여 테스트를 해보았다.
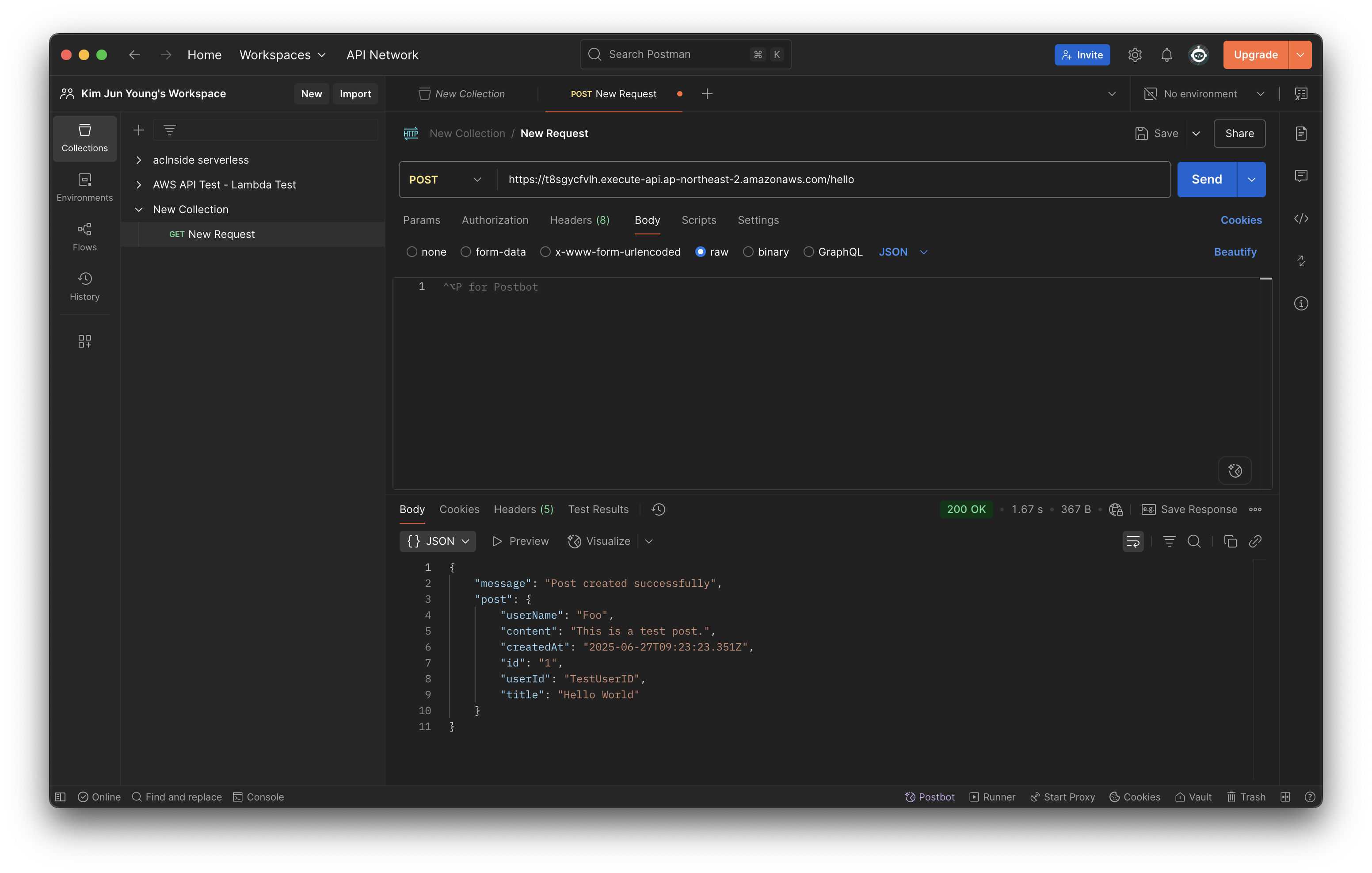

위와 같이 실행 결과도 잘 출력되며, DynamoDB에서 확인해보아도 성공적으로 생성되고 가져오는 것 까지 되는 모습을 볼 수 있다.
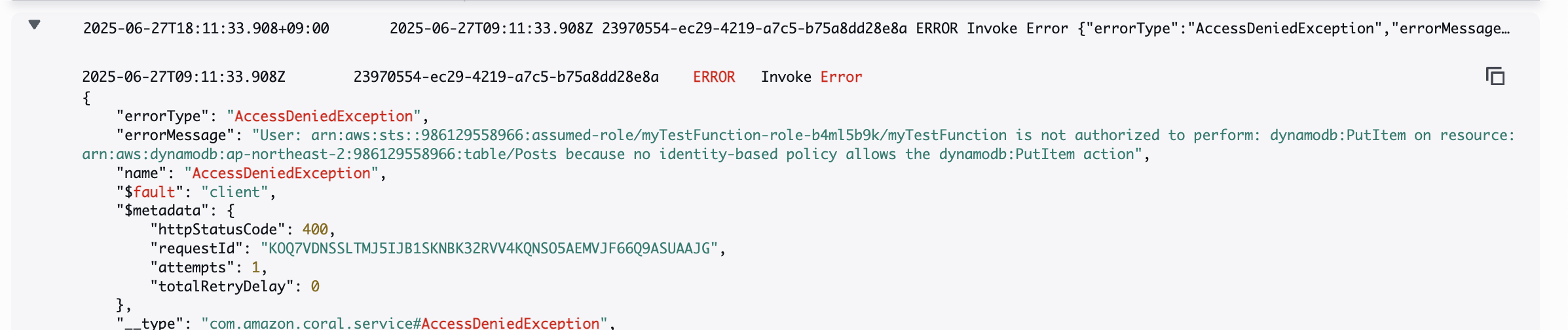
만약 ARN을 잘못 설정하였거나 권한 문제가 있다면 CloudWatch에 아래와 같은 에러가 찍힐 것이다.
이러한 권한 설정도 아래에서 설명할 Serverless Framework를 사용하여 쉽게 설정할 수 있다.
어차피 개발자만 람다 함수를 다루고 작성한 코드대로 작성하는데 굳이 왜 IAM 정책을 부여하며 권한을 사용하는지 의문이 들 수 있다.
하지만 이렇게 해두지 않으면 혹시 모를 개발자의 실수로 발생하는 보안 사고 등을 방지함으로 없는 것 보단 훨씬 좋다.
6-5. Serverless Framework
아까도 말했 듯 직접 하나하나 인프라를 구축하고 배포하면 굉장히 비효율적이다. 그래서 CloudFormation을 사용하여 스택을 만들어 쉽게 인프라를 구축할 수 있는데, 이 파트에선 Serverless Framework를 사용한 인프라 구축에 대해서 다뤄볼 예정이다.
Serverless Framework의 설치 방법은 생략한다.
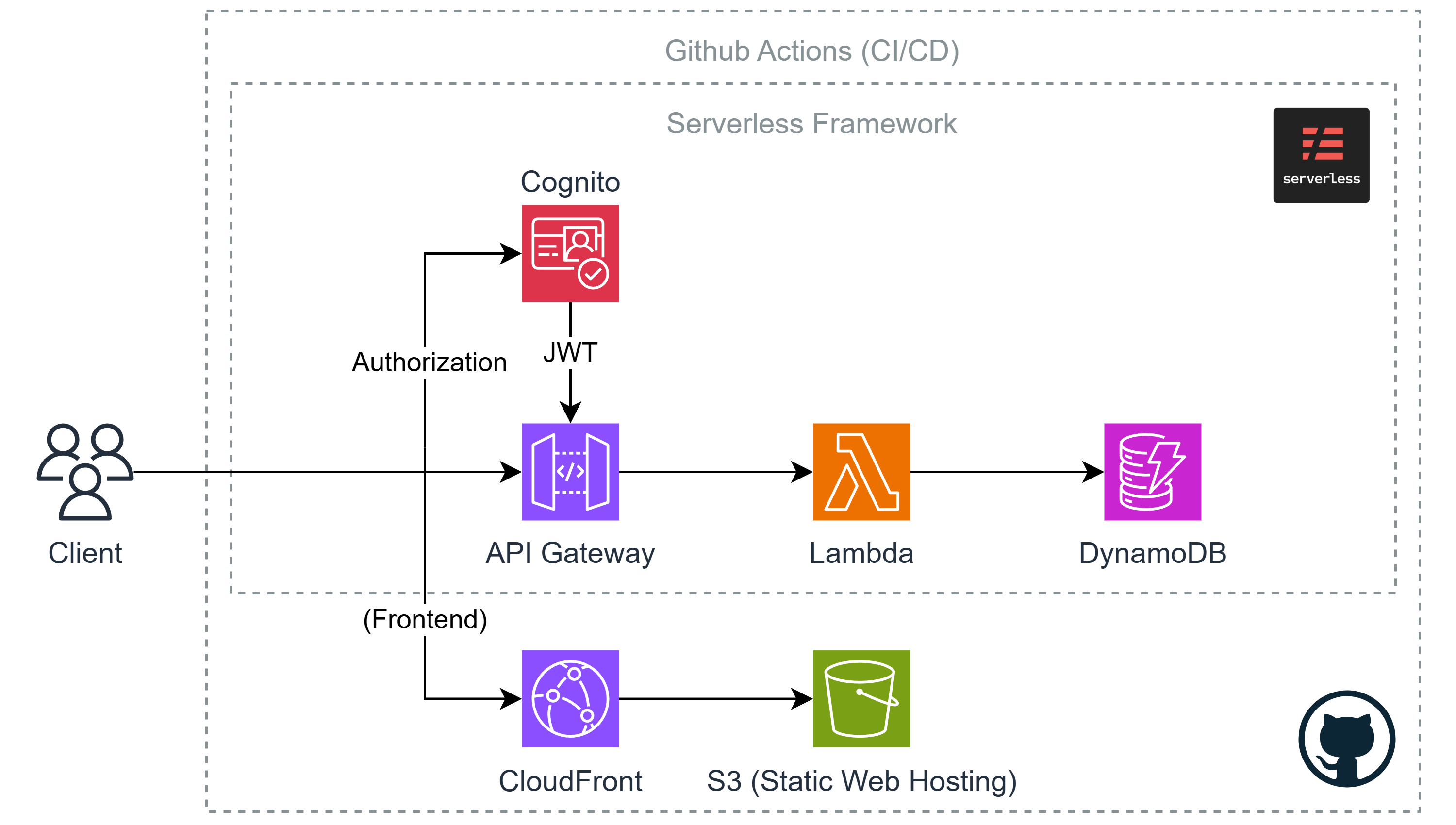
AWS 아키텍쳐를 소개할 때 사용했었던 자료인데, 위 자료에서 "Serverless Framework"로 그룹되어 있는 서비스가 우리가 Serverless Framework로 인프라를 구축하고 배포 할 서비스다.
즉 Lambda 코드 배포, API Gateway 설정, DynamoDB 설정, Cognito 설정까지 모두 Serverless Framework 안에서 처리할 것이다.
그러기 위해선 우선 람다 소스코드가 필요한데, 포스팅의 예제는 아래의 깃허브 레포지토리에서 확인할 수 있다.
https://github.com/eocndp/aws-lambda-example/tree/main/backend
serverless.yaml이 이미 존재하는데, 직접 실습을 통해 따라해도 좋고 어떠한 기능을 하는지만 확인해도 좋다.
우선 Serverless Framework는 일반적으로 serverless.yaml 이라는 파일 명을 사용하며, serverless deploy 등의 명령어 사용 시 자동으로 해당 파일을 사용한다.
(--config 또는 -c 옵션으로 다른 파일을 사용할 수 도 있다.)
/functions, /utils 등의 디렉토리와 package.json 파일 등이 있는 위치에 serverless.yaml을 만들자.

Provider Property
각 파트마다 코드를 일부분씩 설명하도록 하겠다. 맨 처음 아래와 같은 코드를 작성한다.
service: acinside-sl-backend
provider:
name: aws
runtime: nodejs20.x
region: ap-northeast-2
memorySize: 128
timeout: 10
stage: prod
environment:
COGNITO_CLIENT_ID: !Ref CognitoClient
COGNITO_USER_POOL_ID: !Ref CognitoUserPool
AWS_ACCOUNT_ID: ${env:AWS_ACCOUNT_ID}먼저 맨 처음 service 속성은 곧 프로젝트의 이름을 의미한다. CloudFormation에 배포될 때 스택 이름에서 사용된다.
다음으로 provider 속성은 AWS와 AWS의 서비스나 리소스에 대해 기본 값을 설정해주는데, 즉 API Gateway 등의 공통적인 서비스나 리소스를 정의한다. 단, 예외적으로 람다의 경우 provider와 같은 루트 레벨에서 functions라는 속성으로 선언한다.
위 코드에서 provider의 각 속성은 다음을 의미한다.
name: 프로바이더의 이름, 사실상 AWS로 고정된다. 애초에 Serverless Framework 자체가 AWS의 서버리스 구축을 쉽게 도와주는 도구이기 때문이다.runtime: 람다의 기본 런타임을 설정한다. (따로 설정 가능)region: 사용할 리전을 설정한다.memorySize: 람다의 최대 메모리 사이즈를 설정한다.timeout: 람다 함수가 실행 될 때, 특정 시간이 지나면 자동으로 종료되는데 그 시간을 설정한다. 기본값은 3초이지만, 람다 특성 상 데이터베이스의 작업 등으로 인해 오래 걸릴 수 있으므로 10초로 설정해주었다.stage: Serverless Framework의 스테이지를 의미하는데, 기본값은dev이다. 왜인지는 모르겠으나 API Gateway의 스테이지 이름이 아니며, Serverless Framework에서 구분하기 위해 사용된다.environment: 람다 함수 등에서 사용할 환경 변수를 설정한다.
environment 속서에서 보면 !Ref CognitoClient 라는 구문이 있는데, Ref는 CloudFormation에서 지원하는 내장 함수이다. !는 Serverless Framework에서 사용 가능한 단축형이고, CloudFormation에선 Fn::Ref 등으로 사용한다.
Ref 함수는 해당 리소스의 기본 속성 값을 가져온다. 예를 들어 S3의 경우 버킷 이름, DynamoDB의 경우 테이블 이름을 가져오는데, Cognito 유저 풀 클라이언트 리소스의 경우 클라이언트 ID를 반환한다.
아래의 유저 풀도 유저 풀 ID를 반환하게 된다. Ref와 비슷한 GetAtt 함수도 있는데, ARN 등을 가져올 땐 GetAtt 함수를 사용한다.
${env:AWS_ACCOUNT_ID}는 Serverless Framework를 실행하는 호스트에서 환경 변수를 가져오는 것인데, AWS 계정 ID는 환경 변수로 따로 받는다.
Provider: API Gateway
# provider:
# (생략)
httpApi:
name: acinside-sl-api
cors:
allowedOrigins:
- https://XXX.cloudfront.net
allowedHeaders:
- Content-Type
- Authorization
- X-Requested-With
- X-Csrf-Token
- Set-Cookie
allowedMethods:
- GET
- POST
- PUT
- DELETE
- PATCH
- HEAD
- OPTIONS
maxAge: 86400 # 1 day
allowCredentials: true다음으로 provider 내에서 선언한 httpApi, 즉 API Gateway를 설정한다.
API Gateway 이름(name)의 경우 acinside-sl-api라고 지정했으며, CORS의 기본값을 설정해주었다.
allowedOrigins 속성은 Access-Control-Allow-Origin 헤더를 의미하고, 나중에 S3 + CloudFront로 프론트엔드를 배포하였을 때 해당 오리진을 허용하기 위해 작성되어있다.
allowedHeaders와 allowedMethods도 마찬가지로 각각 Access-Control-Allow-Headers, Access-Control-Allow-Methods를 의미하고, maxAge는 프리플라이트 요칭 시 캐싱할 기간을 나타낸다. (Access-Control-Max-Age)
Access-Control-Allow-Credentials를 허용하기 위해 allowCredentials: true로 설정해두었다.
CORS에 대한 내용은 위에서 설명하였으며, API Gateway의 라우팅 등은 추후 람다에서 따로 설정한다.
# provider:
# (생략)
# httpApi:
# (생략)
authorizers:
cognitoAuthorizer:
type: jwt
identitySource: '$request.header.Authorization'
issuerUrl: !Sub "https://cognito-idp.${AWS::Region}.amazonaws.com/${CognitoUserPool}"
audience: !Ref CognitoClient또 API Gateway에서 권한 부여자, 즉 Cognito를 연결하는 코드를 작성할 수 있다.
위 코드처럼 작성해두면 추후 람다를 선언할 때 authorizer: cognitoAuthorizer라고만 해줘도 자동으로 권한 부여자로 Cognito와 연동된다.
권한 부여자의 이름은 cognitoAuthorizer이며, 타입은 JWT, 인증 방법은 Authorization 헤더, 발급자(issuer) URL은 Cognito IDP(JWT 제공자) URL, 대상은 Cognito Client ID를 설정한다.
issuerUrl: !Sub "https://cognito-idp.${AWS::Region}.amazonaws.com/${CognitoUserPool}"위 코드에서 Sub 함수는 문자열을 치환하는 함수이다.
Sub 함수 없이 문자열을 저렇게 동적으로 처리하려고 하면 문자열 내용이 그대로 들어가 작동하지 않는데, Sub 함수를 통해 동적으로 변환된다.
프로그래밍에서 포맷 스트링과 같은 기능을 수행한다고 보면 된다.
그리고
Sub함수는 Serverless Framework 레벨에서 처리하지 않고 CloudFormation 레벨에서 처리한다.하지만
provider에 설정된 리전은 Serverless Framework에서 배포 시 어느 리전에 배포할지를 식별하는 것이라Sub함수에서 사용할 수 없다.그래서 CloudFormation에서 제공하는 내장 파라미터
AWS::Region을 사용한다.
그러면 API Gateway 권한 부여자 설정은 끝났다.
다음으로 람다에 부여할 IAM을 기본으로 설정할 수 있다. 우리가 람다와 DynamoDB를 직접 만들었을 때 처럼 권한을 줘야 람다가 DynamoDB에 접근할 수 있다. (CloudWatch에 대한 권한은 이미 있으므로 DynamoDB에 대한 권한만 설정해주었다.)
Provider: Lambda IAM
# provider:
# (생략)
iam:
role:
statements:
- Effect: Allow
Action:
- dynamodb:PutItem # Create
- dynamodb:GetItem # Read
- dynamodb:Scan # Read(all)
- dynamodb:Query # Read
- dynamodb:UpdateItem # Update
- dynamodb:DeleteItem # Delete
Resource:
- !GetAtt PostsTable.Arn
- !GetAtt CounterTable.Arn위 처럼 IAM 권한 정책을 설정했을때와 비슷하게 작성할 수 있다.
Allow할 권한(Action)에 DynamoDB에 대한 CRUD 권한을 주었고, 그 DynamoDB 대상 리소스(테이블)는 게시글을 저장할 Posts 테이블과 게시글의 ID를 카운팅할 Counter 테이블을 설정하였다.
테이블은 GetAtt 함수를 통해 ARN을 가져와 설정한다.
Lambda Functions
provider를 통해 기본 설정을 마쳤으면 다음으로 람다 함수들을 생성해보자.
서버리스에 특화된 프레임워크 답게 람다 함수는 functions 속성을 따로 지원하는데, 아래와 같이 사용할 수 있다.
functions:
acinsideSL_CreatePost:
handler: dist/functions/post/createPost.handler
events:
- httpApi:
path: /posts
method: post
authorizer: cognitoAuthorizer람다 함수의 이름은 acinsideSL_CreatePost로 설정해주었고, 타입스크립트 빌드 후 dist에 빌드된 자바스크립트 파일이 위치하여 dist/functions/post 경로의 createPost.js 함수의 핸들러(handler())를 handler 속성을 통해 설정해주었다.
이렇게 설정하면 Serverless Framwork (CloudFormation)이 자동으로 S3에 코드를 올려두고 람다에 사용한다.
또한 event 속성을 통해 트리거할 이벤트를 정해주는데, 우리는 API Gateway를 이벤트 트리거로 사용함으로 httpApi를 사용하였다.
httpApi 속성에서 라우팅 설정과 권한 부여자를 설정하는데, 위 코드에선 CreatePost의 라우팅을 POST /posts로 설정해두었으며, 만약 URL 경로를 동적으로 처리해야 된다면 path: /posts/{id} 등으로 설정할 수 있다.
또한 권한 부여자는 아까 provider에서 설정해주었으니 authorizer: cognitoAuthorizer를 사용하여 권한 부여자를 붙여줄 수 있다.
API 엔드포인트 구조를 참조하여 나머지 람다 함수에 대한 설정을 해주자. 이 글에선 생략하고, 전체적인 코드는 깃허브에서 확인할 수 있다.
Resources
다음으로 Cognito에 대한 리소스인 유저 풀과 유저 풀 클라이언트를 선언해주자.
다만 Serverless Framework에선 provider 내부에서 사용하는 리소스와 람다(functions) 외의 리소스를 자체적으로 선언하는 속성이 없는데, 그 대신 resources 속성을 제공하여 CloudFormation 템플릿 코드를 사용할 수 있도록 한다.
이 포스팅 또한 이곳에서 Cognito와 DynamoDB에 대한 리소스를 정의해볼 것이다.
Resources: Cognito
먼저 Cognito를 설정하는 코드는 아래와 같다.
resources:
Resources:
CognitoUserPool:
Type: AWS::Cognito::UserPool
DeletionPolicy: Retain
UpdateReplacePolicy: Retain
Properties:
UserPoolName: acinside-cognito-user-pool
AutoVerifiedAttributes:
- email
Schema:
- Name: email
Required: true
UserPoolTier: LITE위 코드에서 먼저 Cognito 유저 풀은 CognitoUserPool이라는 이름을 가지도록 하는데, 이는 실제로 AWS 리소스에 적용될 이름이 아닌 CloudFormation 템플릿에서 사용할 논리적 이름이다.
그 타입(Type)은 AWS::Cognito::UserPool로 설정하였고, Properties 속성을 통해 해당 리소스의 속성을 설정할 수 있다. (유저 풀 이름, 인증 수단, 이메일 필수 제공 여부 등)
Cognito의 플랜(요금제)는 Lite로 사용한다. (UserPoolTier: LITE)
그리고 코드에서 아래와 같은 속성을 볼 수 있다.
DeletionPolicy: Retain
UpdateReplacePolicy: Retain이는 CloudFormation에서 스택 삭제 시 리소스가 삭제되는 것을 방지한다. (DeletionPolicy)
UpdateReplacePolicy는 리소스가 교체될 때, 예를 들어 리소스의 이름이 변경될 때 기존의 리소스를 삭제하고 새로운 이름의 리소스를 생성하는데, 이를 유지(Retain)하는 것이다.
Cognito와 DynamoDB는 자료를 유지시키는 것이 좋으므로 해당 옵션을 켜두었다.
다만 AWS Console에서 설정 가능한 삭제 방지 기능과는 다른데, 위 옵션은 CloudFormation 스택과 관련된 내용이고 삭제 방지 기능은 AWS Console과 관련된 기능이다.
# resources:
# Resources:
# (생략)
CognitoClient:
Type: AWS::Cognito::UserPoolClient
Properties:
ClientName: acinside-cognito-client
UserPoolId: !Ref CognitoUserPool
ExplicitAuthFlows:
- USER_PASSWORD_AUTH그리고 Cognito 유저 풀 클라이언트(AWS::Cognito::UserPoolClient)에 대한 설정도 해주었다. 클라이언트의 이름은 acinside-cognito-client, 유저 풀 ID는 이전에 만들어둔 유저 풀을 참조한다.
인증 방식은 USER_PASSWORD_AUTH, 즉 username과 password를 사용하도록 한다.
Resources: DynamoDB Table
다음으로 DynamoDB 테이블을 작성해주자. 형식은 이전과 동일하자.
# resources:
# Resources:
# (생략)
PostsTable:
Type: AWS::DynamoDB::Table
DeletionPolicy: Retain
UpdateReplacePolicy: Retain
Properties:
TableName: Posts
AttributeDefinitions:
- AttributeName: id
AttributeType: S
KeySchema:
- AttributeName: id
KeyType: HASH
BillingMode: PAY_PER_REQUEST타입은 Type: AWS::DynamoDB::Table, 스택 삭제 및 교체 시 유지 기능을 활성화 해뒀으며, 테이블은 이름은 Posts, 기본 속성은 id: String(S)이며 키는 id로 해시화하여 저장한다.
키 스키마에서 HASH일 경우 파티션 키, RANGE일 경우 정렬키가 된다. DynamoDB에서 파티션 키를 해시화 하는 이유는 내부의 처리 과정(파티셔닝)에 있지만, 이 포스팅에선 설명하지 않는다.
BillingMode는 PAY_PER_REQUEST, 즉 온디맨드로 사용한다. 또는 PROVISIONED을 사용하여 미리 사용량을 정해둘 수 있다.
마찬가지로 Counter 테이블(다만 파티션 키는 name)을 선언하면 리소스 선언은 끝이 난다.
Plugins
AWS에서 공식적으로 지원하는 SAM 대신 Serverless Framework를 사용하는 이유 중 가장 큰 이유가 플러그인 사용이 아닐까 싶다.
Serverless Framework에선 플러그인 사용이 가능한데, 플러그인은 serverless plugin install을 사용하여 설치하거나 npm을 사용하여 설치할 수 도 있다.
플러그인은 아래와 같이 사용한다는 것을 명시할 수 있다.
plugins:
- serverless-esbuild
- serverless-prune-plugin이 포스팅에서 사용할 플러그인은 위 두가지다.
serverless-esbuild
NodeJS를 사용하다보면 필연적으로 서드파티 npm 모듈을 사용할 수 밖에 없는데, 그러다보면 node_modules의 크기가 커질 수 밖에 없다.
그래서 여러 소스코드를 하나로 묶는 번들링(Bundling)이나 사용하지 않는 코드를 제거하는 트리 쉐이킹(Tree Shaking), 코드의 공백이나 긴 변수 명 등을 줄여 용량을 줄이는 경량화(Minify) 작업 등이 필요하게 된다.
또한 환경에 맞게 최신 버전의 기능을 레거시하게 변경해주기도 한다.
esbuild는 그러한 작업들을 처리해주는데, 이를 Serverless Framework에서 플러그인을 통해 쉽게 사용할 수 있다. custom 속성을 통해 플러그인을 설정할 수 있다.
custom:
esbuild:
bundle: true
minify: true
sourcemap: false
target: 'node20'
platform: 'node'
concurrency: 10
treeShaking: true
packager: npm
format: 'cjs'번들링을 위한 bundle: true, 경량화를 위한 minify: true, 트리 쉐이킹을 위한 treeShaking: true 옵션 등을 사용할 수 있으며, 그 외에 병렬 처리나 타켓 NodeJS 버전 등을 설정할 수 있다. (CommonJS 사용)
그리고 Serverless Framework 자체에서 람다별로 사용하는 핸들러 코드들을 독립적으로 따로 배포하는 것도 지원하는데, Serverless Framework에선 기본적으로 node_modules는 포함시키므로 그냥 쓴다면 큰 역할을 하진 못한다.
하지만 esbuild 플러그인을 사용했을 시 번들링을 해주기 때문에 매우 큰 효과를 볼 수 있다.
아래와 같이 작성할 수 있다.
package:
individually: true만약 위 기능을 사용하지 않았다면 아래와 같이 모든 람다 함수들이 한번에 같이 올라갔을 것이다.
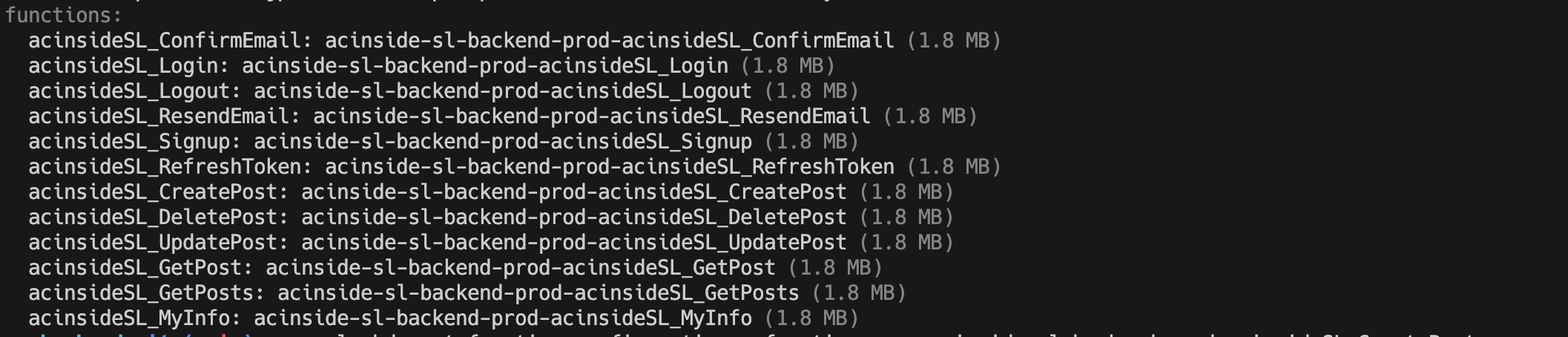

보다시피 각 함수 별 용량도 크고 불필요한 다른 람다 함수의 코드까지 올라가게 된다.
하지만 individually: true로 활성화하면 아래와 같이 줄어든 용량과 불필요한 파일이 올라가지 않았음을 확인할 수 있다.
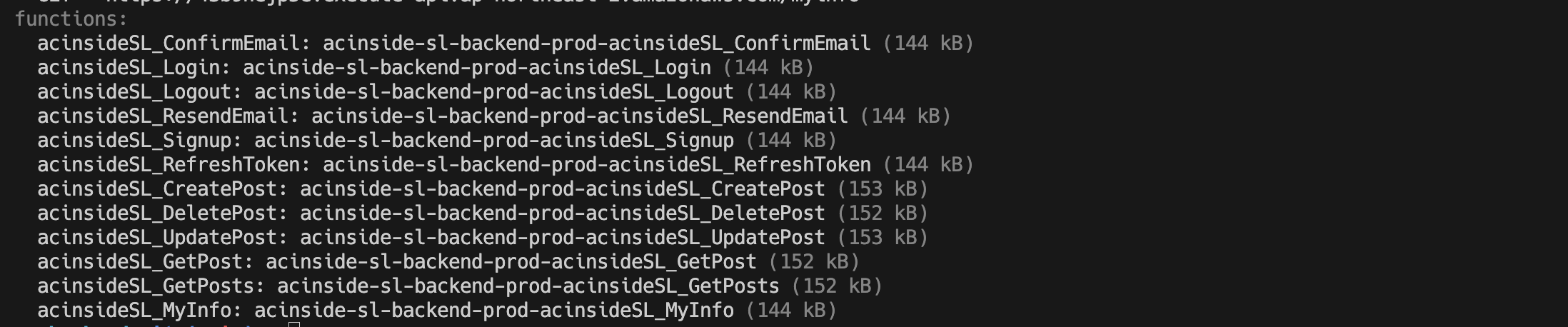

코드 사이즈가 1769349바이트(약 1.8MB) -> 152586바이트(약 153KB)로 10배 이상 줄어든걸 확인할 수 있다.
(람다 함수의 파일 개수에 비례함)
serverless-prune-plugin
Serverless Framework를 사용하면 람다 함수 생성 또는 코드 수정 시 람다 함수의 버전이 생긴다.
이 버전은 추후에 롤백이나 버전 관리 등을 위해 생성해두는데, 비용은 따로 나가지 않지만 75GB의 용량 제한이 있다.
그래서 node_modules 등이 포함된 큰 용량의 소스코드가 쌓이다보면 금방 채워지는데, 이 버전들은 딱히 필요가 없고, 버전 관리는 깃으로 관리하면 그만이므로 사용하지 않을 것이다.
하지만 이전 버전을 제거하는건 직접적으로 지원하는 기능은 아니라 플러그인을 사용해야 하는데, serverless-prune-plugin 플러그인을 사용하면 된다.
# custom:
# (생략)
prune:
automatic: true
number: 1위와 같이 작성해두면 마지막 버전 1개만 냅두고 나머지는 전부 지워준다.

이제 Serverless Framework에 대한 내용은 끝이 났다. 이대로 serverless deploy를 통해 수동으로 배포할 수 도 있으나, Github Actions를 통해 깃허브에 push 할 시 자동으로 실행되어 배포할 수 있게 해보겠다.
6-6. CI/CD With Github Actions
Github Actions의 사용법과 워크플로우 작성 방법은 위에서 어느정도 설명하였으니 자세한 설명은 생략하겠다.
.github/workflows/aws-deploy-be.yaml 파일을 만들어 Serverless Framework를 자동화해보자.
먼저 워크플로우의 이름을 정하고, 워크플로우가 실행될 조건을 작성하자.
name: Deploy AWS Backend (Serverless Framework)
on:
push:
branches:
- main
paths:
- 'backend/**'
- '.github/workflows/aws-deploy-be.yaml'이벤트에서 main 브랜치에 push될때, 거기에 추가로 프론트엔드와 백엔드를 디렉토리로 구분해뒀으니 backend 디렉토리에서 수정이 발생했을 때 워크플로우가 실행되도록 하였다.
이제 Job과 스텝(Step)을 작성해주자. 먼저 actions/checkout@v4 워크플로우를 사용하여 소스코드를 실행 환경(runner)로 가져오는 스텝이 필요하다. (실행 환경은 Github에서 제공하는 우분투를 사용한다.)
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v4(1) Configure AWS credentials
그 다음으로 AWS IAM 자격 증명을 해줘야하는데, Serverless Framework가 AWS CLI를 직접적으로 의존하진 않으니 AWS 자격 증명은 필요로 하기 때문에 아래와 같은 스텝을 추가해준다.
- name: Configure AWS credentials
uses: aws-actions/configure-aws-credentials@v2
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: ap-northeast-2이때 환경 변수가 사용되는데, 환경 변수는 깃허브 레포지토리 설정에서 설정해줄 수 있다.
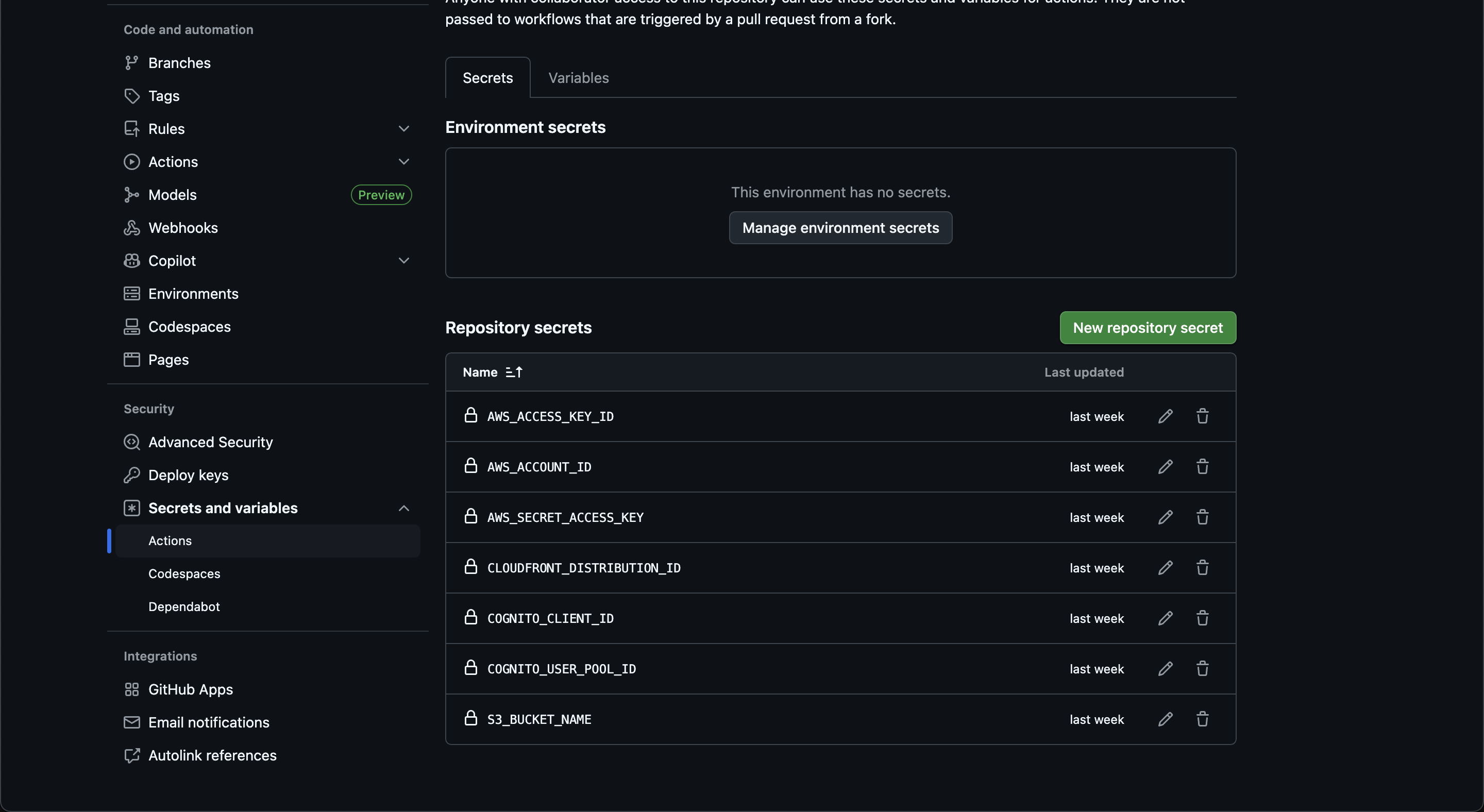
설정에서 Security > Secrets and variables 탭에 들어가 설정할 수 있다.
Environment secrets와 Repository secrets이 있는데, 전자는 특정한 환경 단위로 작동하여 Actions에서 environment 등의 속성을 사용하여 등록해둔 환경을 가져와 환경 변수를 사용한다.
그에 반해 Repository secrets는 레포지토리 단위로 모든 Actions에서 접근할 수 있는데, 이 포스팅에선 Repository secrets를 사용하였다.
New repository secrets 버튼을 클릭하여 환경 변수를 만들 수 있는데, 위 코드에선 IAM 퍼블릭 엑세스 키인 AWS_ACCESS_KEY_ID와 IAM 프라이빗 엑세스 키인 AWS_SECRET_ACCESS_KEY를 필요로 한다.
IAM 엑세스 키 생성에 대해선 다루지 않는다.
(2) Setup NodeJS and Install Dependencies
다음으로 NodeJS를 설치하고, 필요한 의존성을 설치해주자.
- name: Setup NodeJS
uses: actions/setup-node@v4
with:
node-version: '22'
- name: Install Serverless Framework v3
run: npm install -g serverless@3.40.0
- name: Install Serverless plugin dependencies
run: npm install -g serverless-esbuild serverless-prune-plugin
- name: Install TypeScript
run: |
cd backend
npm install typescript ts-node @types/node --save-dev
- name: Install project dependencies
run: |
cd backend
npm install(3) Deploy with Serverless Framework
마지막으로 타입스크립트를 빌드하고, Serverless Framework를 사용하여 배포할 수 있다.
- name: Build TypeScript files
run: |
cd backend
tsc
- name: Deploy with Serverless Framework
run: |
cd backend
npx serverless deploy --verbose
env:
AWS_ACCOUNT_ID: ${{ secrets.AWS_ACCOUNT_ID }}여기서 AWS 계정 ID가 AWS_ACCOUNT_ID 환경 변수로 필요로 하니 환경 변수 등록을 해주도록 하자.
그럼 Github Actions 작성이 끝났고, Github에 push 하면 자동으로 배포가 될 것 이다.
약 2분 10초 정도가 소요되는 것을 확인할 수 있다. 이 파트에서 사용했던 Github Actions 워크플로우 파일 역시 깃허브 레포지토리에서 확인할 수 있다.
https://github.com/eocndp/aws-lambda-example/blob/main/backend/serverless.yaml
6-7. Frontend with S3 + CloudFront
마지막으로 프론트엔드 코드를 S3에 업로드 하고 CloudFront CDN 서비스를 구성해볼 것이다.
이 파트에선 간단하게 CSR(Client Side Rendering)을 사용한 프론트엔드를 배포해볼 것인데, 실제 서비스 시 SSR(Server Side Rendering)를 사용하는 것이 검색 엔진 최적화(SEO), (클라이언트 입장에서) 빠른 로딩 속도 등의 면에서 더욱 좋다.
하지만 CSR과 비교적 서버리스에서 SSR을 구현하기엔 다소 복잡하다.
특히 JWT 토큰을 사용하여 더욱 더 복잡해지는데, 다음과 같은 기본적인 아키텍쳐를 사용해볼 수 있다.
일단 React를 사용한다고 가정하였을 때, NextJS 프레임워크를 사용하여 라우팅 및 SSR을 구현하고 이를 SST로 인프라를 구축하고 배포한다.
원래 Serverless Framework에 NextJS를 올릴 수 있는
serverless-next.js플러그인이 있었으나, 현재는 지원 중단으로 NextJS 13 이후 지원하지 않는다.그래서 SST라는 툴을 사용하여 NextJS를 배포할 수 있다.
이 이상의 SSR 구조에 대해선 다루지 않으며, 이 포스팅에선 간단하게 CSR 구조의 프론트엔드만 호스팅해보는 형태로 진행해볼 것이다.
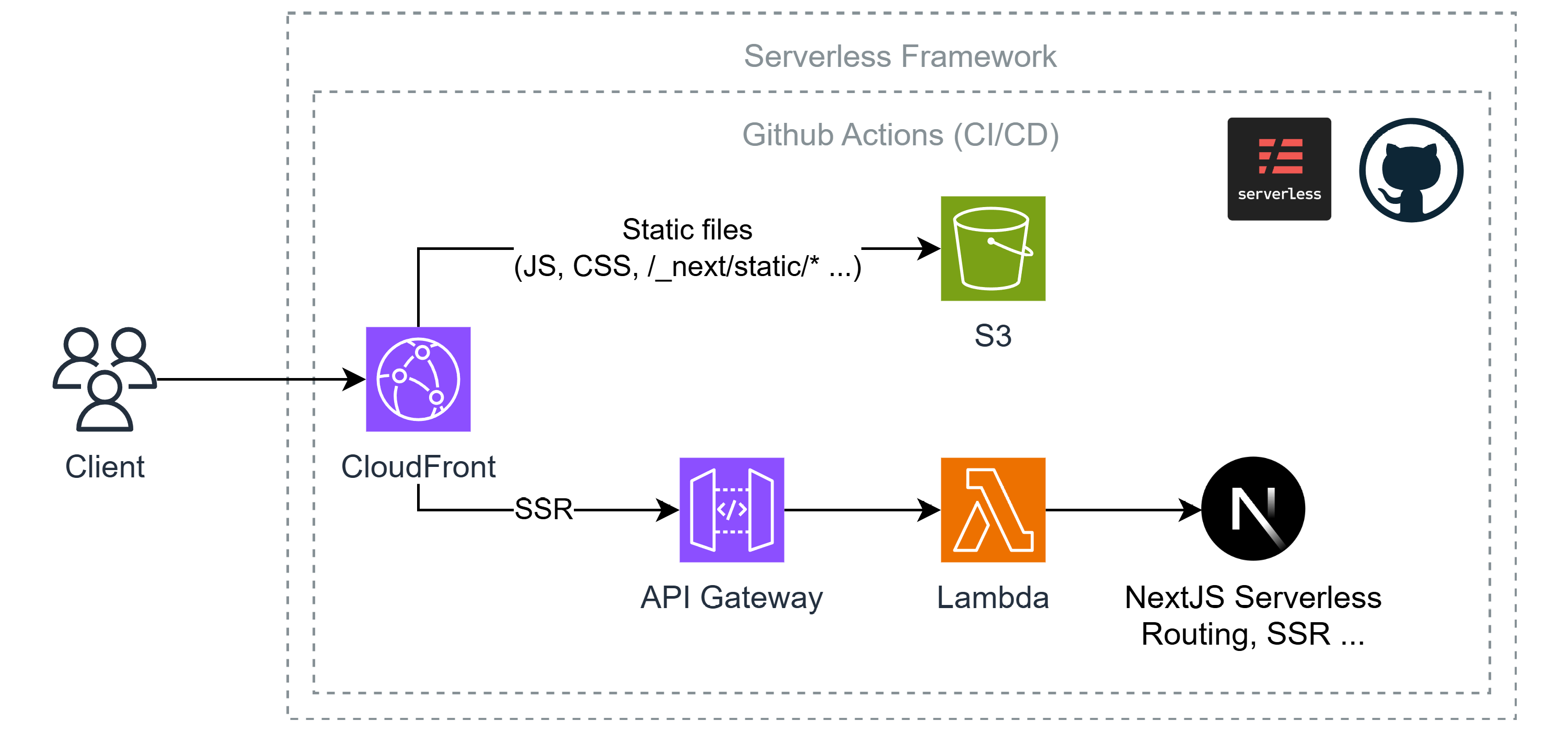
또한 이 파트에선 포스팅에서 직접 소스코드를 설명하지 않는다. 프론트엔드에 대한 코드는 아래에서 확인할 수 있으며, 직접 소스코드를 다운받아
/frontend디렉토리에서 프론트엔드를 확인할 수 있다.https://github.com/eocndp/aws-lambda-example/tree/main/frontend
Tech Stacks
사용된 기술은 간단한 예시를 위해 Vite에서 제공하는 React + TypeScript 템플릿을 사용하였으며, 별다른 컴포넌트 없이 App.tsx에서 모든 요소를 확인해볼 수 있다.
포스팅 작성일(2025/06/27) 기준 로그인, 게시글 확인, 게시글 생성/수정/삭제 기능만 상태이며, 라우팅은 간단하게 react-router-dom을 사용하였다. NextJS 등의 프레임워크는 사용하지 않은 상태이다.
소스코드는 다운받은 후 아래와 같은 명령어로 실행하고 빌드할 수 있으며, 직접 소스코드를 수정하며 기능을 추가해보는 것도 나쁘지 않은 선택이다.
> git clone https://github.com/eocndp/aws-lambda-example.git
> cd frontend
> npm run dev # 개발 모드 (Hot Reloading)
> npm run build # 빌드또한 백엔드 API처럼 Serverless Framework를 사용하지 않고 Github Actions만 사용하였는데, 간단한 예제라 CloudFront와 S3 인프라를 만들고 Github Actions에서 AWS CLI로 S3에 배포만 하는게 더 괜찮다고 생각하였기 때문이다.
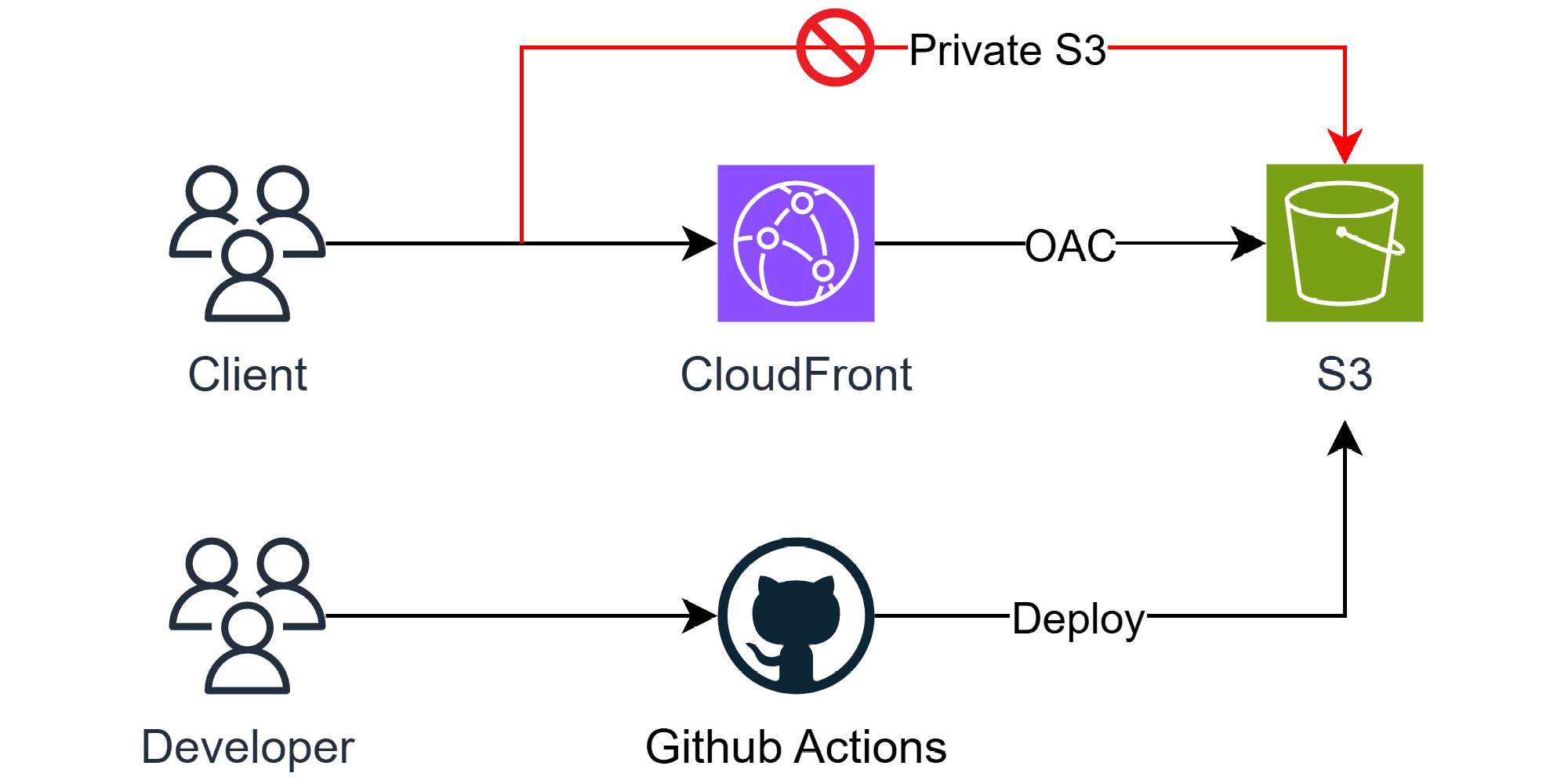
그래서 Github 레포지토리에 가보면 두개의 Actions가 작동 중이며, 각 Actions는 /backend와 /frontend에서 변동 사항이 있을 때 작동한다.
또한 프론트엔드 코드에서 API_URL에 필자의 API Gateway 주소를 입력해뒀는데, 실제로 시도해보려면 이 주소를 본인의 주소로 바꿔서 사용하길 바란다.
S3
시작하기 앞서, S3에 파일을 배포할 때 AWS CLI를 사용하지 않고 AWS Console을 사용할 예정이니 빌드된 코드가 모여있는
/dist디렉토리를 따로 빌드해두고 배포할땐/dist안의 파일들을 업로드하자. (index.html이 최상위 루트 경로에 있어야함)
먼저 S3 버킷을 만들어보자. 만드는건 매우 간단한데, AWS Console에서 S3 접속 후 "버킷 만들기"를 클릭하자.
버킷 이름은 고유해야 되니 직접 시도해본다면 다른 이름을 선택하도록 하자.
버킷 이름에서
actions는 필자의 오타이다. 원래는acinside를 사용하려 하였다...
다음으로 ACL(Access Control List)을 설정할 수 있는데, 우리는 나중에 CloudFront를 통해서만 접근할 예정이니 ACL은 사용하지 않는다.

다음으로 퍼블릭 엑세스는 차단한다. 나중에 CloudFront를 사용하여 S3에 접근할 것이기 때문에 차단해도 괜찮다.
나머지 옵션은 그대로 냅두고, 버킷이 만들어지면 빌드된 /dist 디렉토리의 파일들을 업로드하자. AWS CLI를 사용해도 되지만, 간단하게 AWS Console을 통해 업로드할 수 있다.
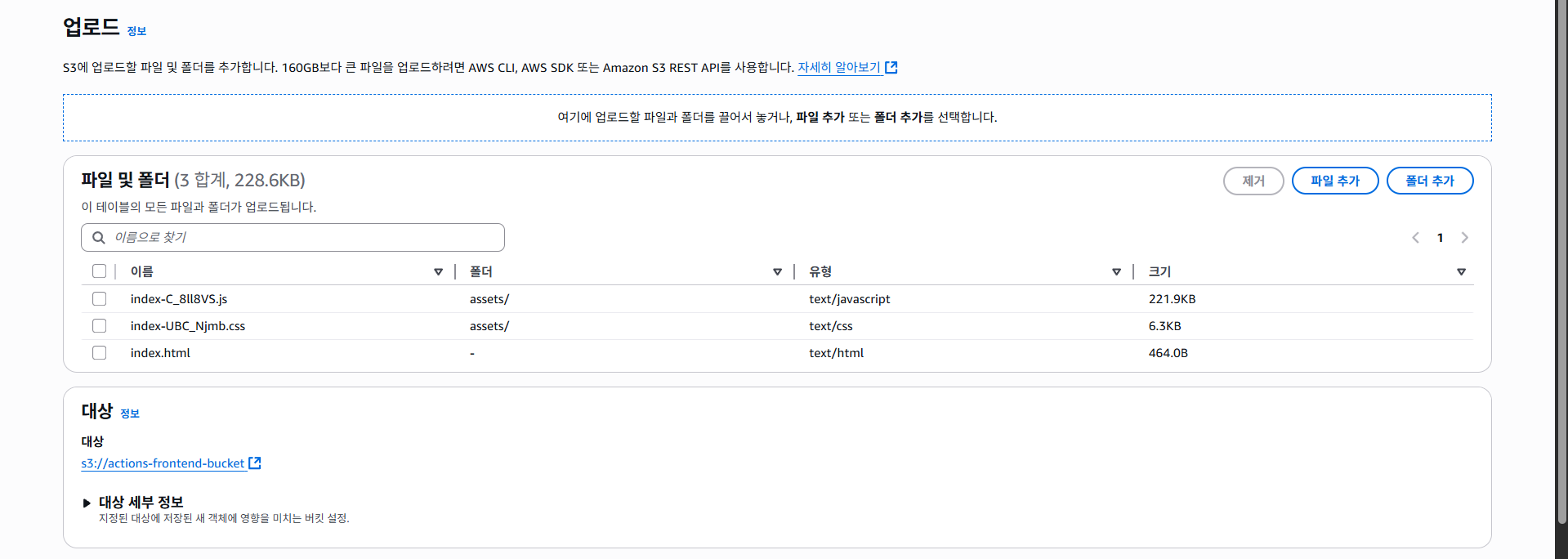
그리고 버킷 설정에서 정적 웹 호스팅 옵션을 켜둬야한다.
그래야 웹으로 해당 버킷에 업로드해둔 사이트에 접속할 수 있다.
버킷 속성 > 맨 아래의 정적 웹 호스팅 항목에서 설정할 수 있다.
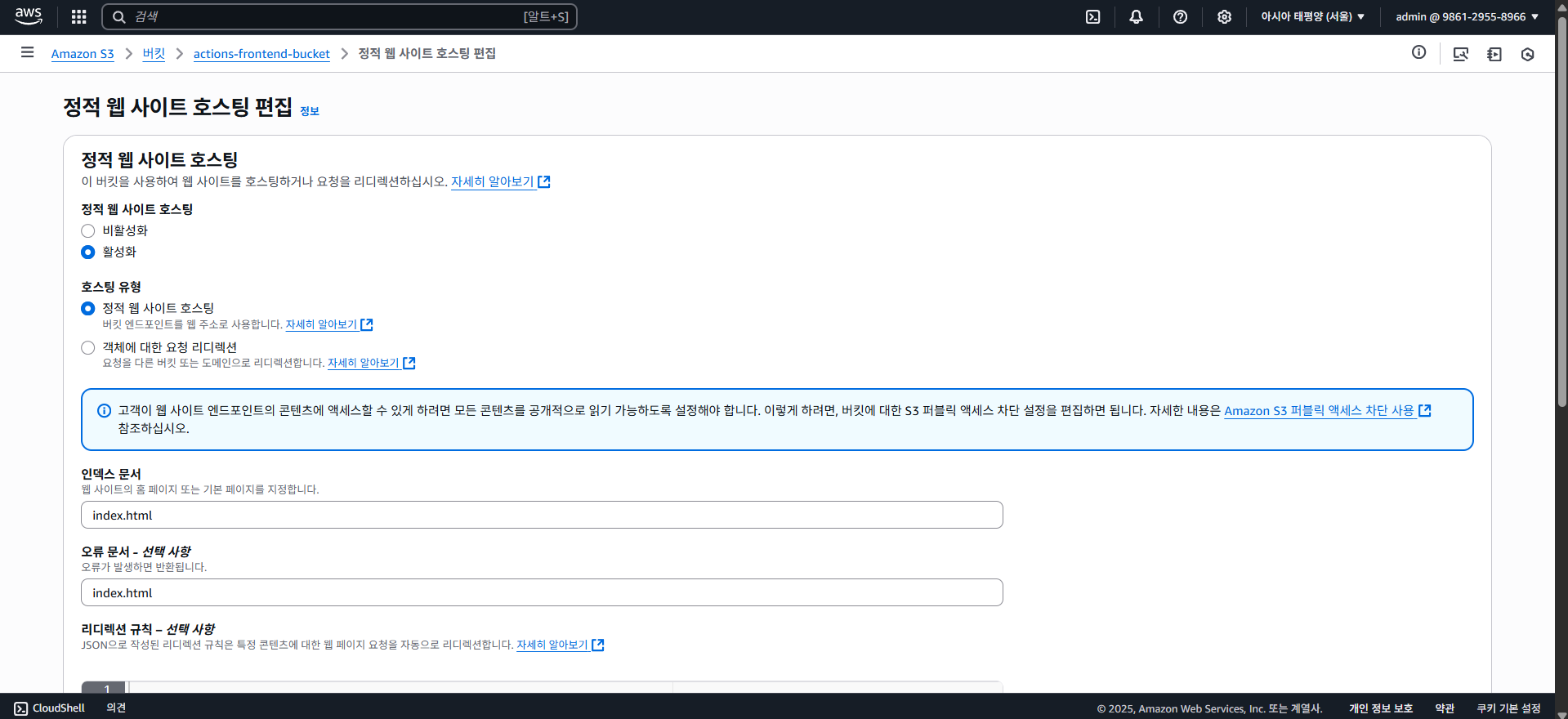
그럼 위와 같이 인덱스 문서와 오류 문서를 입력하라고 나오는데, 우리는 리액트에서 react-router-dom을 사용하여 클라이언트 측에서 라우팅하게 작성하였으니 둘 다 index.html을 입력한다.
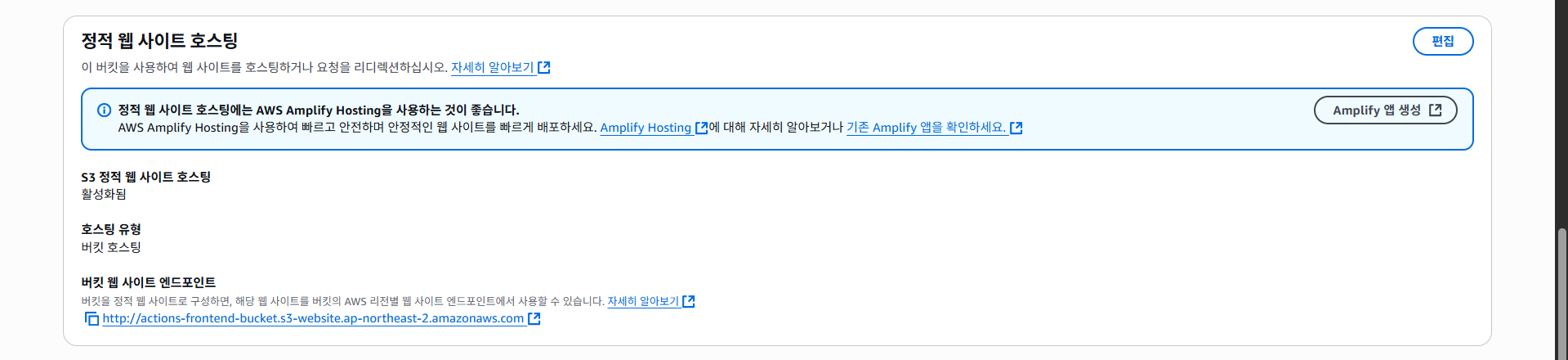
그럼 S3가 해당 파일들로 웹 호스팅을 해주고 URL을 제공해주는데, 퍼블릭 엑세스를 차단해뒀기 때문에 에러가 떠야한다.

우리의 목적은 CloudFront를 사용한 CDN 서비스까지 적용할 예정이기 때문에 CloudFront 배포(Distribution) 설정으로 넘어가자.
CloudFront
먼저 CloudFront의 CDN 단위인 배포(Distribution)를 만들어야한다.
오리진을 설정하는데, 오리진 타입은 S3를 사용한다. 만약 S3에서 퍼블릭 엑세스를 차단하지 않고 URL에 접근할 수 있었다면 기타(Other)를 선택하여 URL만 입력해줘도 자동으로 가능하나, 그러한 상황이 아니기 때문에 오리진 타입은 S3를 선택한다.
오리진은 아까 만들어둔 S3 버킷으로 설정한다.
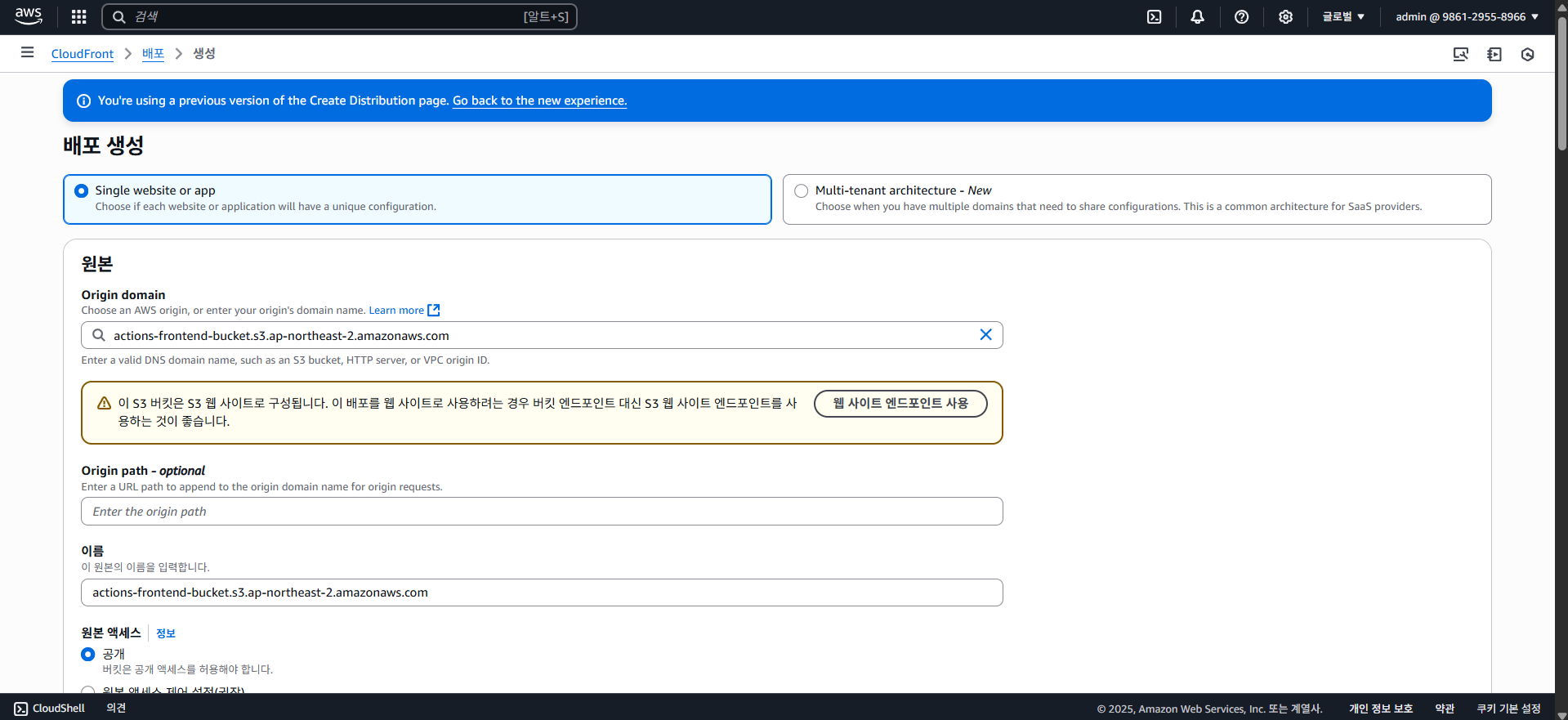
그리고 "원본 엑세스" 항목엔 "원본 엑세스 제어 설정(권장)"을 선택한다.

그럼 OAC(Origin Access Control)를 설정할 수 있는데 OAC를 사용하여 IAM 설정을 통해 CloudFront만이 S3에 접근할 수 있도록 할 수 있다.
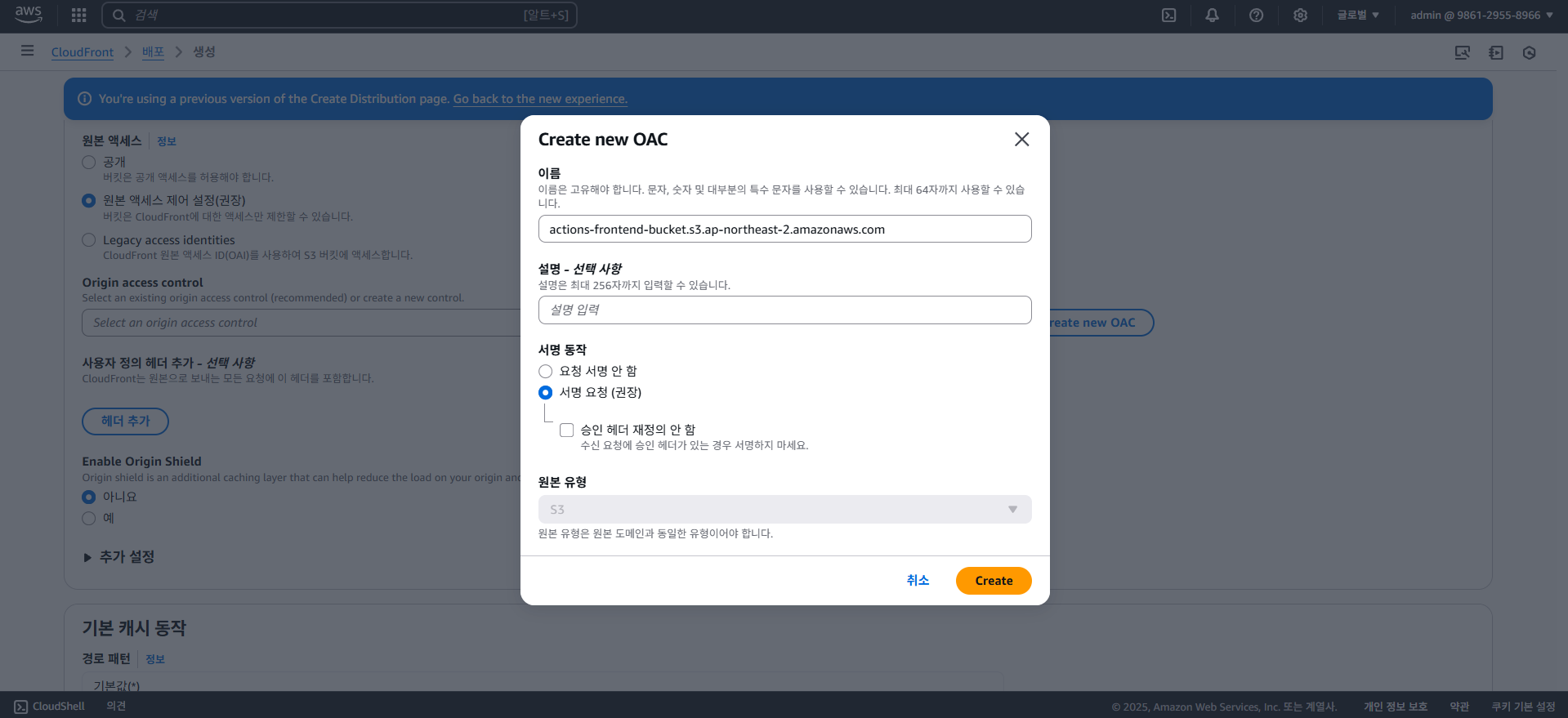
OAC를 만드는데 기본 설정을 유지하자.

그럼 버킷 정책을 업데이트해야 된다고 하는데, CloudFront 설정이 끝나면 버킷 정책을 수정해주도록 하자.
다음으로 뷰어 프로토콜 설정은 Redirect HTTP to HTTPS를 선택해주자. 그럼 CloudFront가 http를 사용한 URL을 https로 넘겨준다.
그 외에 DDoS, XSS, SQL 인젝션 등의 공격을 방어할 수 있는 AWS 서비스인 WAF(Web Application Firewall) 등을 설정할 수 있으나, 요금이 부과되는 옵션이기 때문에 이 포스팅에선 설정하지 않는다.

나머지는 그대로 두고, 기본값 루트 객체에서 index.html을 입력해주자.

그러면 루트(/)에 접속했을 때 자동으로 index.html을 띄워준다.
이제 생성 버튼을 눌러 CloudFront 배포를 만들어주자. 그러면 아래와 같은 메세지가 나올 것이다.

"정책 복사"를 누르면 아래와 같은 IAM 설정이 복사된다.
{
"Version": "2008-10-17",
"Id": "PolicyForCloudFrontPrivateContent",
"Statement": [
{
"Sid": "AllowCloudFrontServicePrincipal",
"Effect": "Allow",
"Principal": {
"Service": "cloudfront.amazonaws.com"
},
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::actions-frontend-bucket/*",
"Condition": {
"StringEquals": {
"AWS:SourceArn": "[CloudFront_Distribution_ARN]"
}
}
}
]
}아까 S3로 돌아가 "권한" 탭의 버킷 정책 항목에서 편집 버튼을 눌러보자.
그리고 복사했던 정책을 붙여넣기 하고 변경 사항 저장을 클릭하자.

마지막으로 CloudFront의 배포 도메인 이름의 URL을 복사하고 들어가면 성공적으로 배포된 것을 볼 수 있다.
배포엔 성공하였으나, 아래와 같이 에러가 뜰것이다.
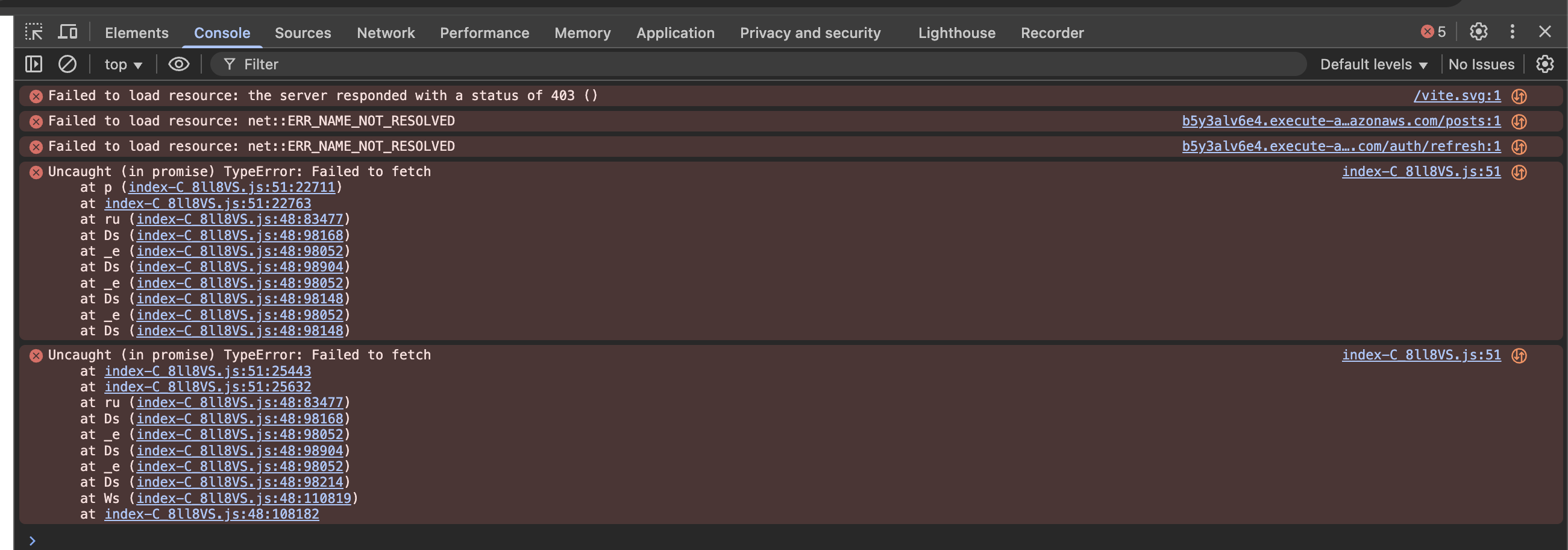
두가지 이유가 있는데,
- 프론트엔드 코드에서 API Gateway Base URL을 바꿔주지 않아서
- API Gateway CORS 설정에서 배포된 사이트의 오리진을 설정해주지 않아서
가 있다. 첫번째의 경우는 프론트엔드 코드를 아래와 같이 자신의 API Gateway Base URL을 수정하여 다시 배포하면 해결된다.
수정은 새로 업로드하거나 CLI 등을 사용하여 수정하자.
S3에 다시 배포하였다면 CloudFront에서 캐시 무효화를 해줘야할 수 있다.

그럼 다음으로 2번째 경우인 CORS 에러가 발생한다. API Gateway CORS 설정에서 방금 만들었던 CloudFront 오리진을 허용하지 않아서인데, 우리는 Serverless Framework와 Github Actions를 사용하여 설정 자동화를 해뒀기 때문에 아래와 같이 serverless.yaml의 allowedOrigins 속성만 바꿔주면 된다.
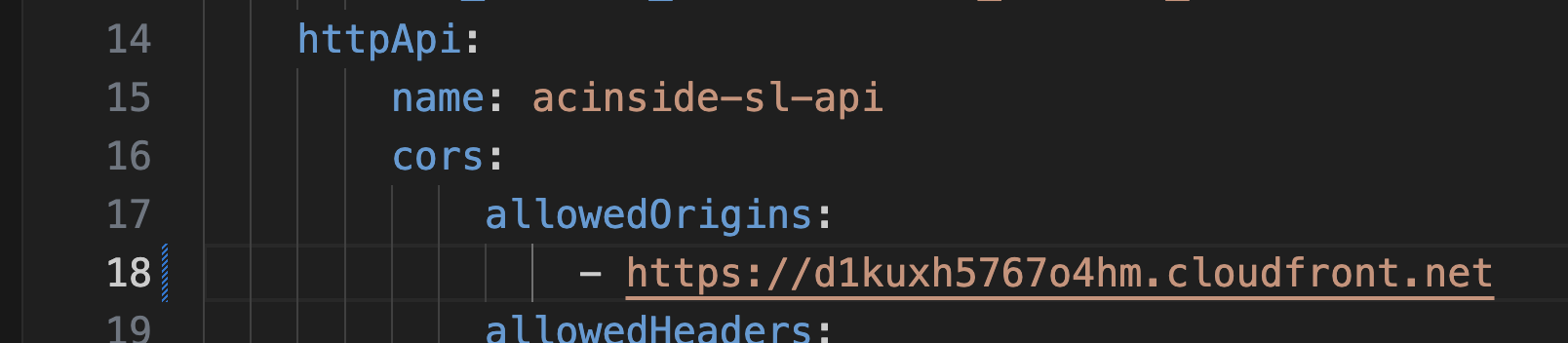
그리고 push하고 배포가 완료되기 까지 기다리면 된다.

그리고 다시 들어가보면 정상적으로 작동하는 것을 볼 수 있다.
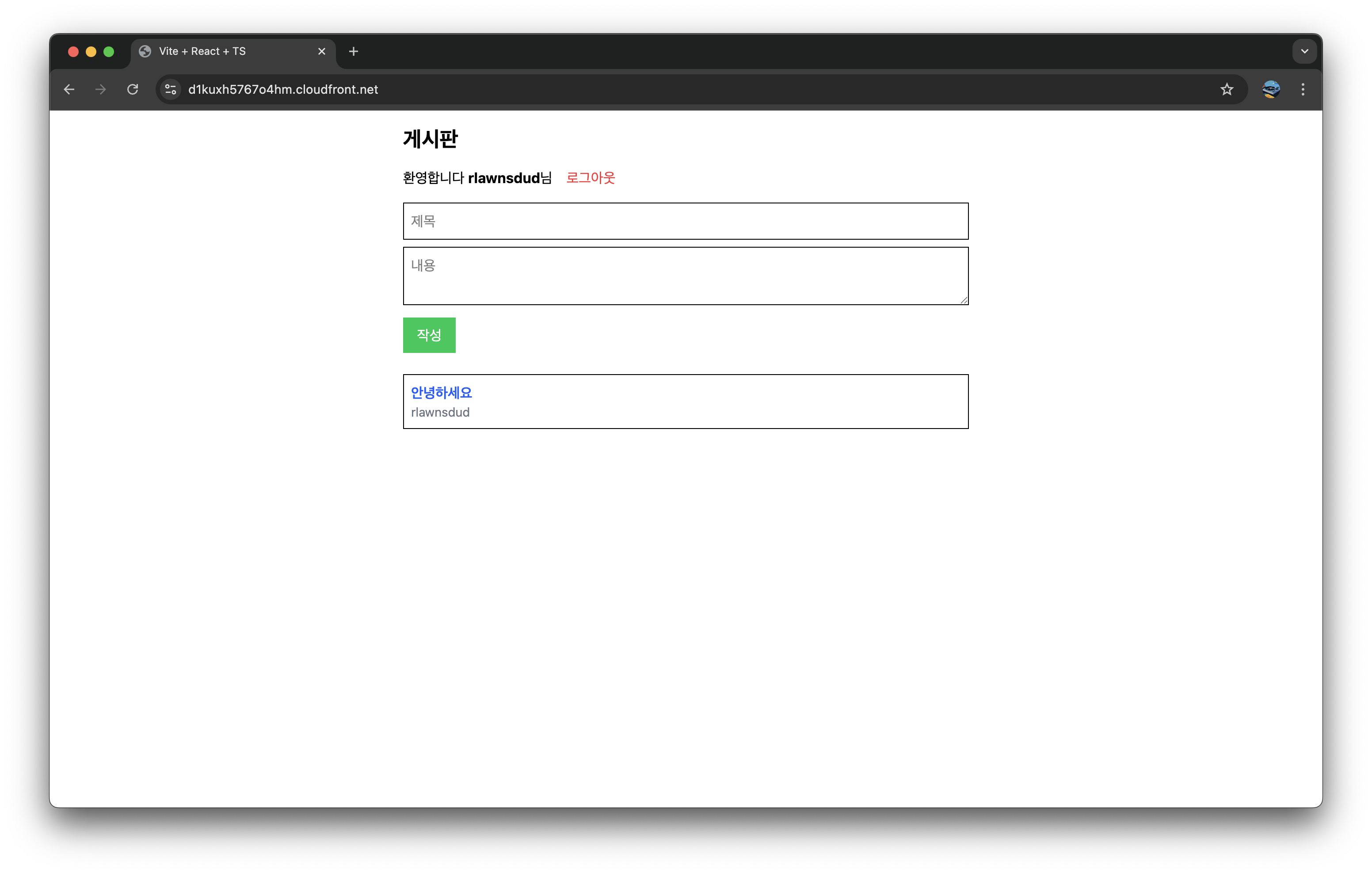
글 작성일(2025-06-29) 기준 프론트엔드에 회원가입 기능을 만들지 않았는데,
POST /auth/signup엔드포인트로 직접 요청을 해보거나 AWS Console로 Cognito 계정을 만들 수 있다.
With Github Actions CI/CD
다음으로 S3와 CloudFront를 설정해뒀으니 Github Actions를 사용하여 자동으로 배포해주는 워크플로우를 작성해보겠다.
여기에선 Serverless Framework를 사용하지 않았는데, CloudFront 설정의 복잡함(OAC 설정 등)과 간단히 인프라 2개만 사용하기 때문에 오히려 Serverless Framework를 사용하면 복잡도만 증가할 것이라 판단하였다.
그래서 간단하 AWS CLI를 사용한 S3 배포만 다룰 예정이다.
먼저 .github/workflows/aws-deploy-fe.yaml 파일을 만들어주고 아래와 같이 이벤트 트리거 조건을 작성해주자.
name: Deploy S3 static website (React Build)
on:
push:
branches:
- main
paths:
- 'frontend/**'
- '.github/workflows/aws-deploy-fe.yaml'그리고 Jobs를 작성하고 스텝들을 작성할건데, 먼저 코드 Checkout과 AWS 자격 증명을 설정해주고 NodeJS를 설치해주자. 여기까진 백엔드 워크플로우와 동일하다.
jobs:
build-and-deploy:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v4
- name: Configure AWS credentials
uses: aws-actions/configure-aws-credentials@v2
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: ap-northeast-2
- name: Setup NodeJS
uses: actions/setup-node@v4
with:
node-version: '22'시크릿 키 또한 백엔드 워크플로우를 작성할 때 설정해뒀으니 따로 설정하지 않아도 된다.
다음으로 리액트 빌드를 위한 의존성을 설치해주고, package.json에 작성해둔 스크립트를 사용하여 vite 빌드를 진행한다.
- name: Install dependencies
run: |
cd frontend
npm install
- name: Build React app
run: |
cd frontend
npm run build다음으로 AWS CLI를 사용하여 S3에 빌드된 소스코드(/dist)를 배포한다.
AWS CLI는 Github Actions Runner에 자동으로 설치되어 있다.
- name: Upload to S3
run: |
cd frontend
aws s3 sync dist/ s3://${{ secrets.S3_BUCKET_NAME }} --deleteAWS CLI 옵션 중 sync는 로컬 파일과 비교하여 변경된 부분만 수정하여 동기화 한다. cp는 기존의 파일을 복사하고 덮어쓰는데, sync는 변경된 부분만 수정한다는 차이점이 있다.
그리고 --delete 옵션은 S3엔 파일이 있지만 로컬엔 해당 파일이 없을 때, S3에서 해당 파일을 삭제하는 역할을 한다.
즉 불필요한 파일은 자동으로 삭제해주는 옵션이다.
그리고 시크릿 키로 S3_BUCKET_NAME를 받는데, Github 레포지토리에서 버킷 이름을 가진 시크릿 키(S3_BUCKET_NAME)를 등록해주자.
다음으로 CloudFront에서 캐싱 무효화 작업을 해줘야 하는데, 그래야 곧바로 변경 사항이 적용된 서비스를 이용할 수 있다.
- name: Invalidate CloudFront cache
run: |
aws cloudfront create-invalidation \
--distribution-id ${{ secrets.CLOUDFRONT_DISTRIBUTION_ID }} \
--paths "/*"마찬가지로 CloudFront 배포 ID를 시크릿 키로 설정해주고 해당 배포에 대해 모든 경로의 캐싱을 무효화를 진행하라고 명령한다.
이로써 프론트엔드에 대한 Github Actions 워크플로우 작성도 마쳤다.
그럼 두개의 워크플로우가 성공적으로 실행되는 것을 확인할 수 있다.
CloudFront 캐싱 무효화까지 잘 되는 모습이다.
7. API Testing with Postman
배포하였던 프론트엔드 사이트를 사용하여 간단한 로그인과 게시글 CRUD를 테스트 해볼 수 있었지만 제대로 API 테스트를 위해 Postman을 사용하여 테스트해보겠다.
Postman을 실행하여 새로운 컬렉션을 만들고, 우클릭 후 New Request로 요청을 생성한다.
편의를 위해 Base URL을 환경 변수로 만들고 사용하겠다.
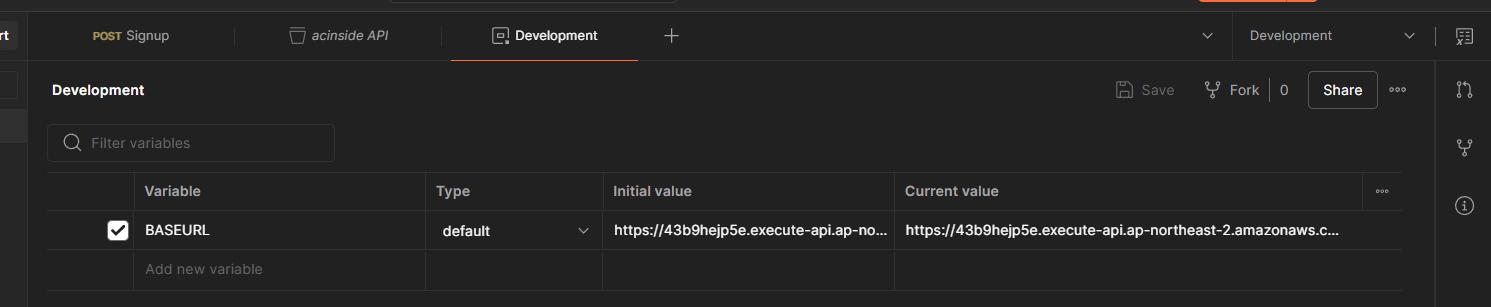
엔드포인트 설명에 대해선 아래의 링크에서 자세히 볼 수 있다.
https://github.com/eocndp/aws-lambda-example/blob/main/backend/README.md
Authorization API
POST /auth/signup
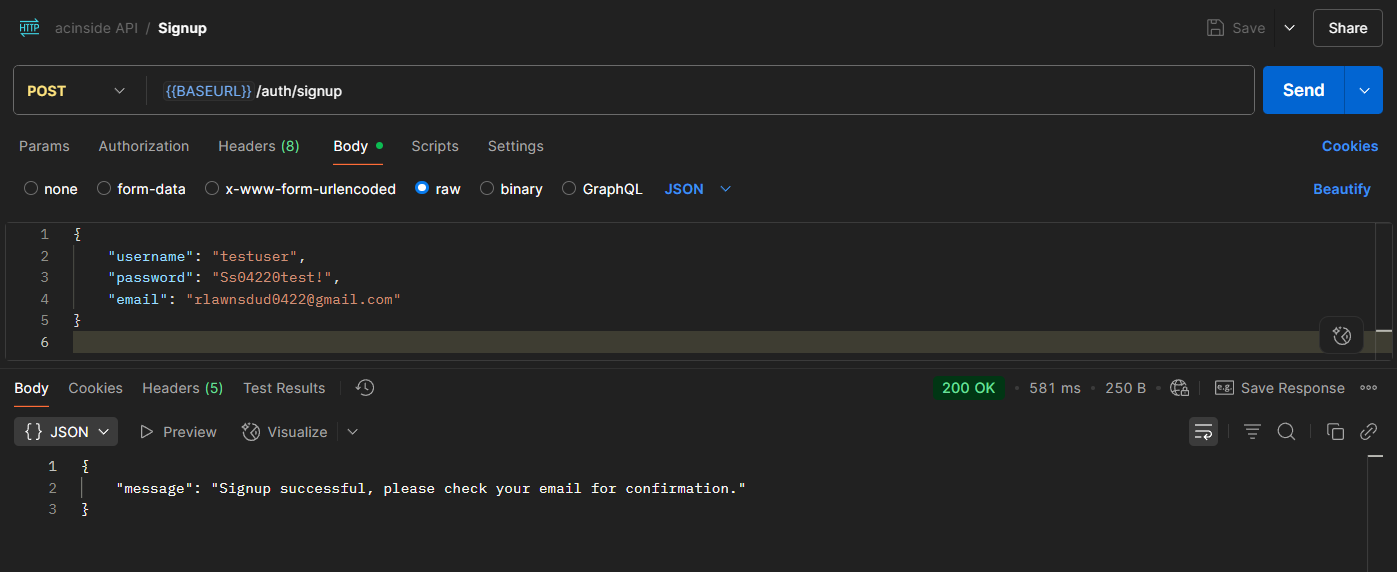

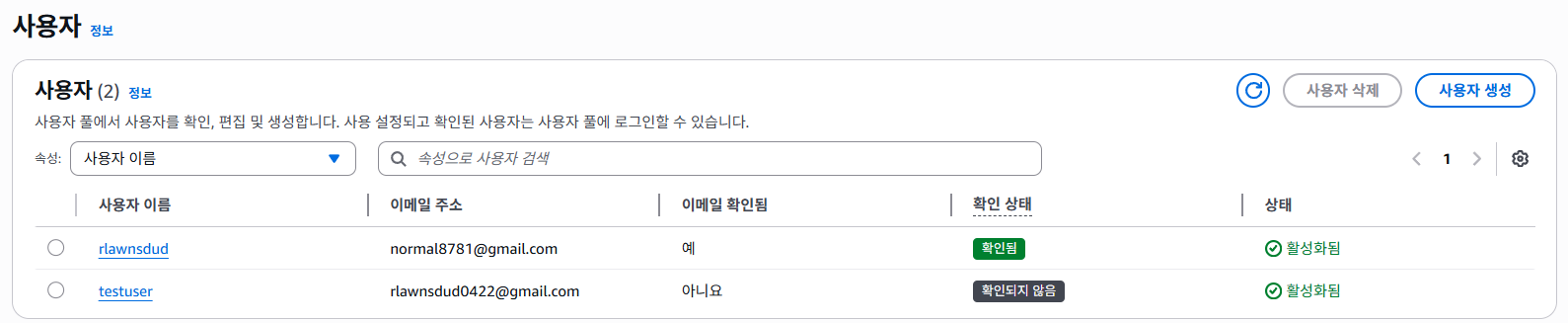
POST /auth/confirmEmail
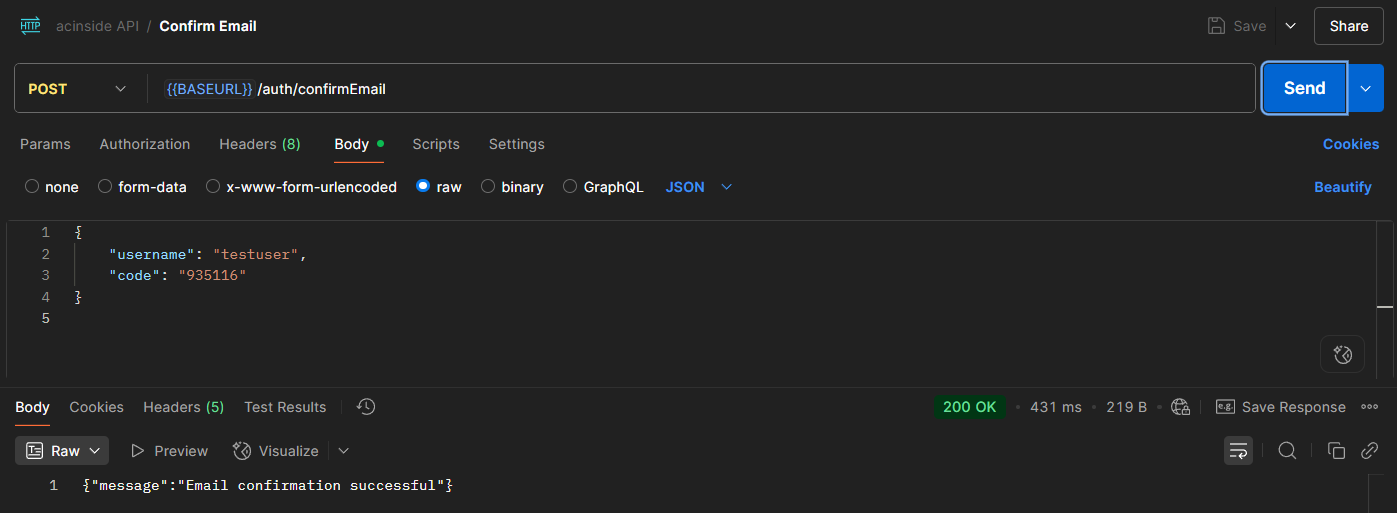

POST /auth/resendEmail
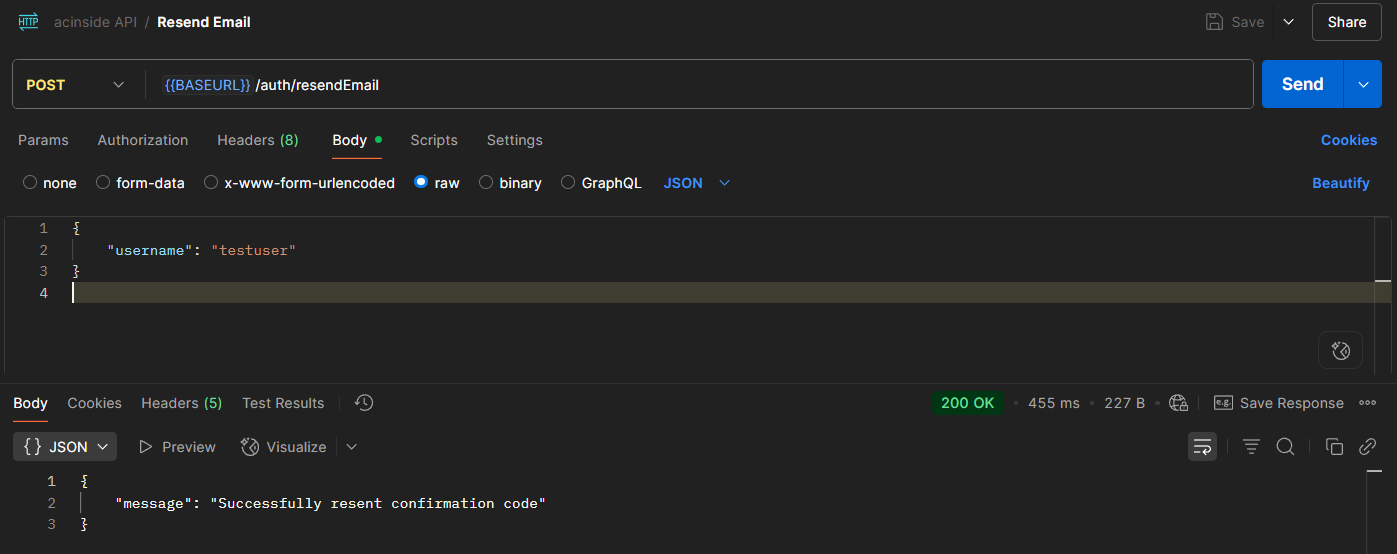

POST /auth/login
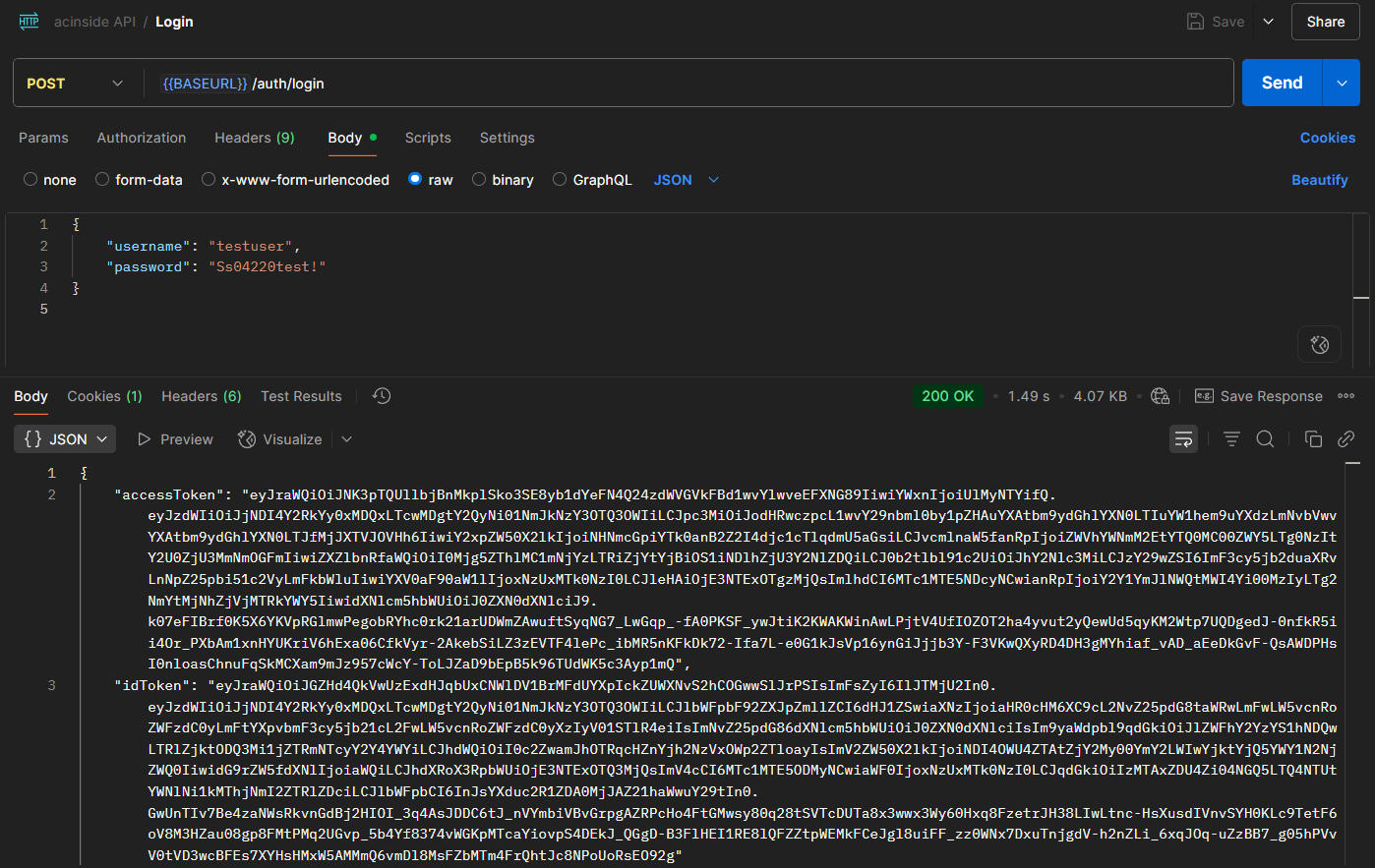
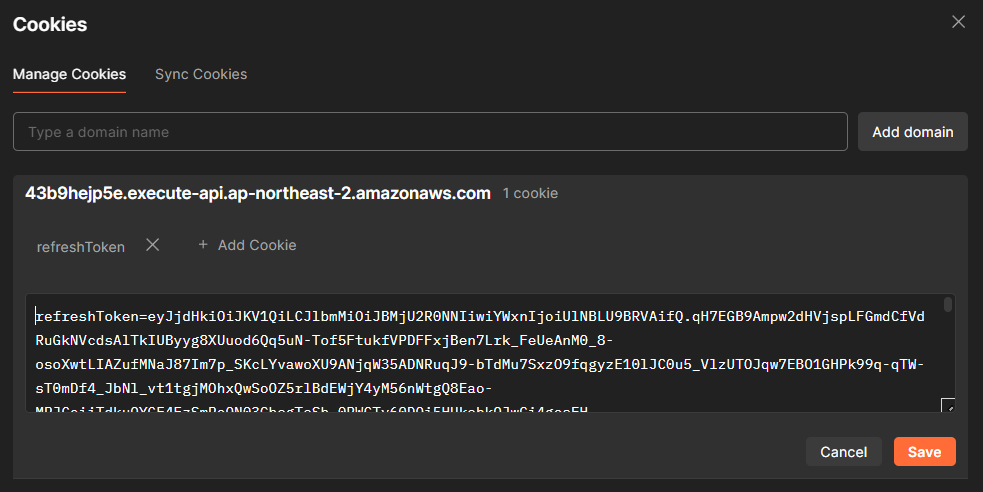
POST /auth/refresh
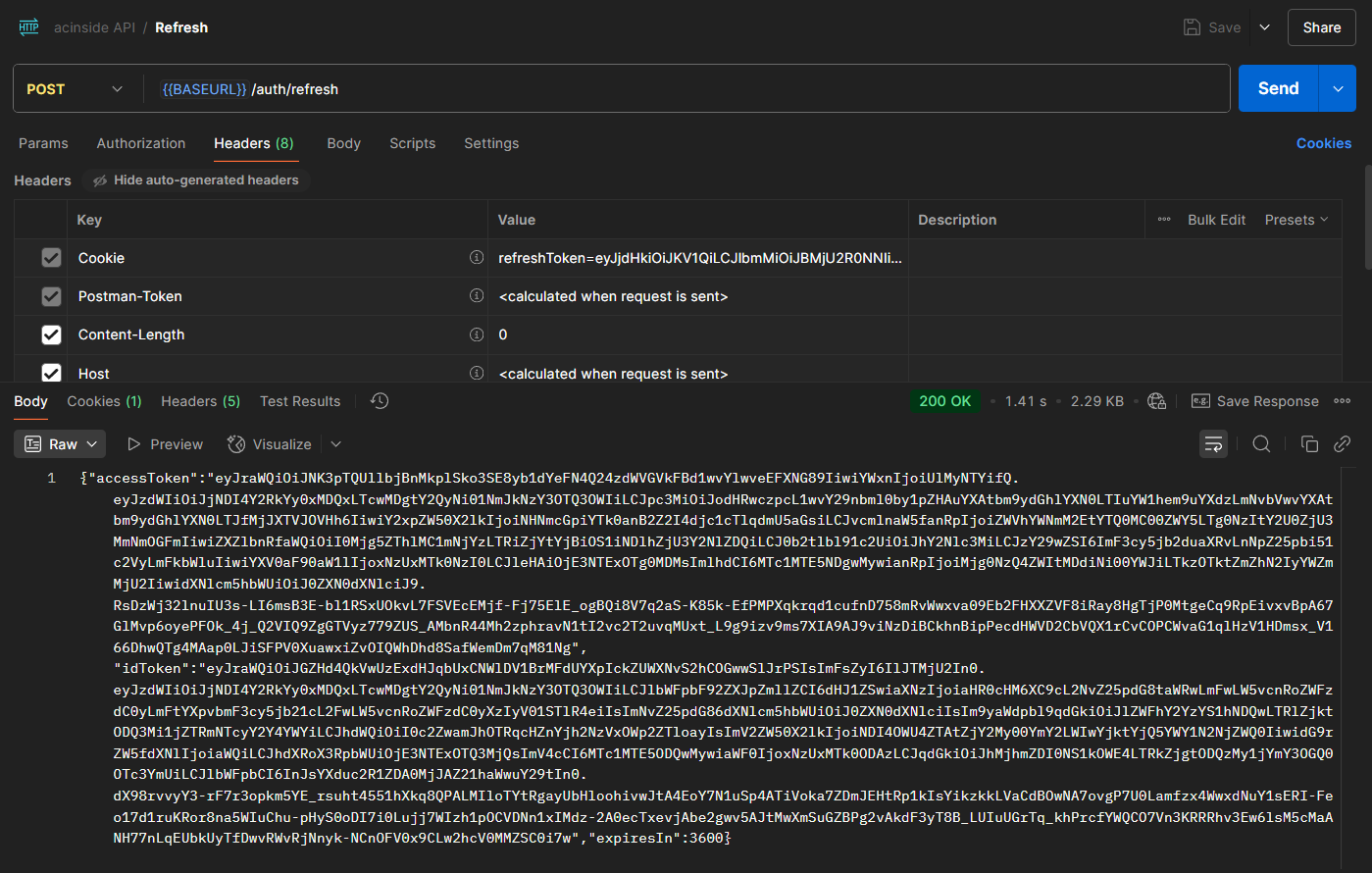
POST /auth/logout
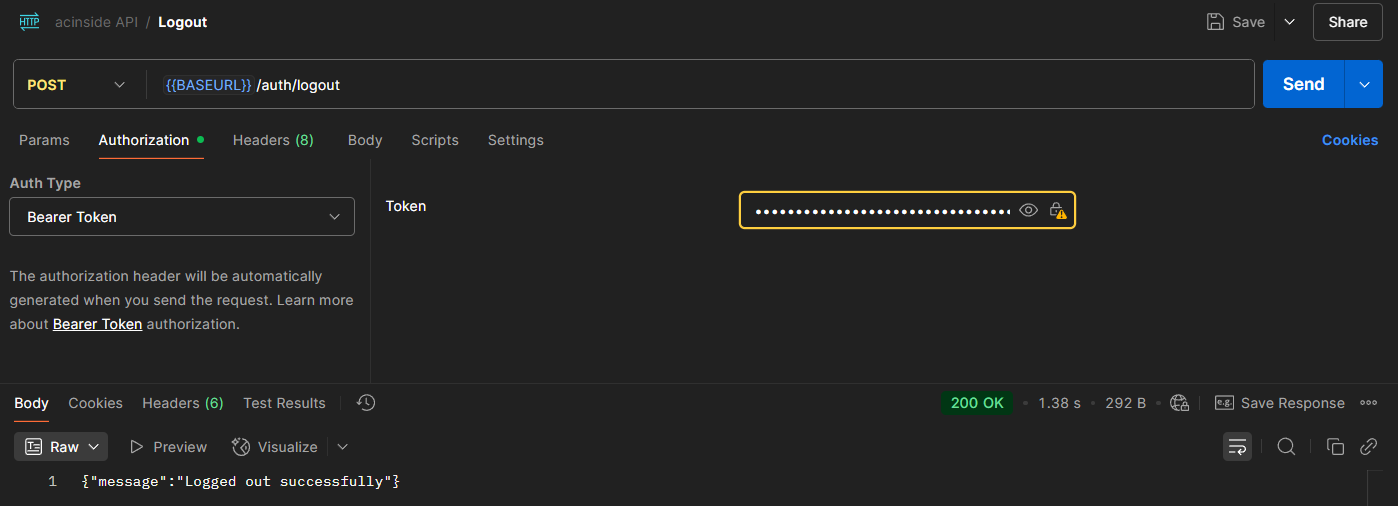
Post CRUD API
GET /posts (Get All Posts)
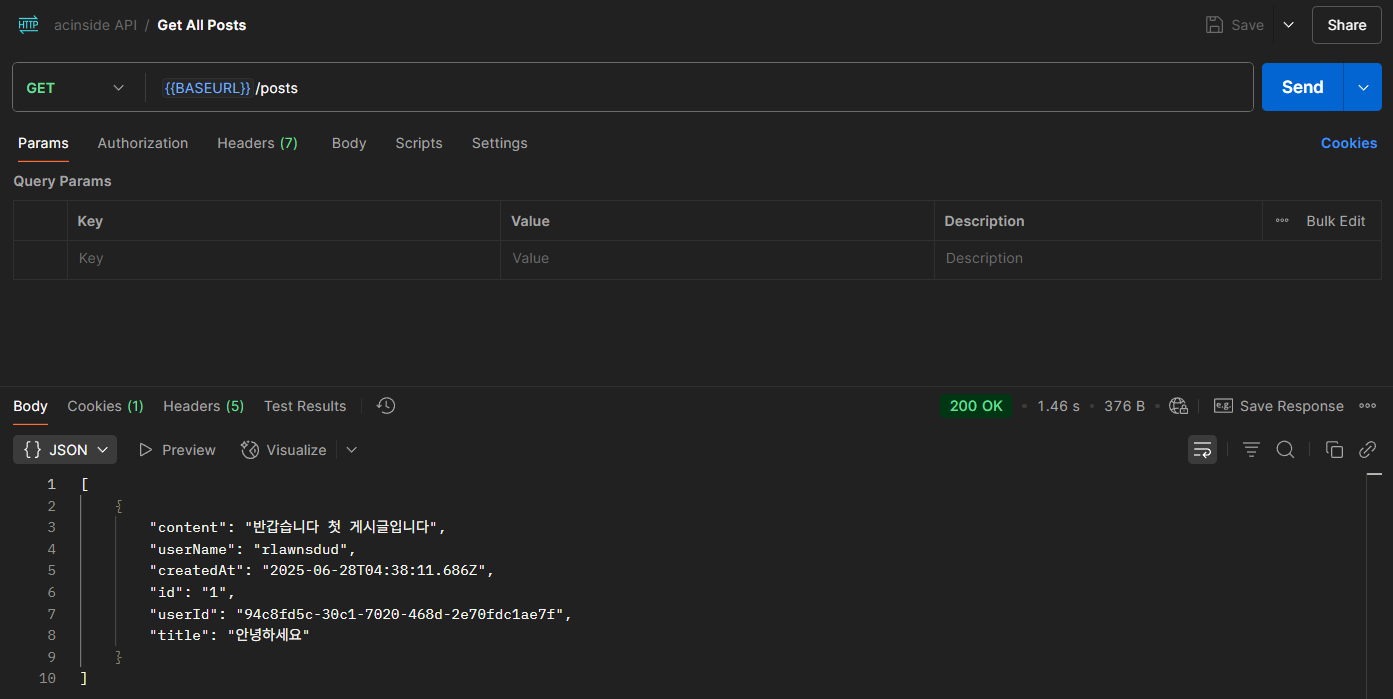
GET /posts/{id} (Get Specific Post)
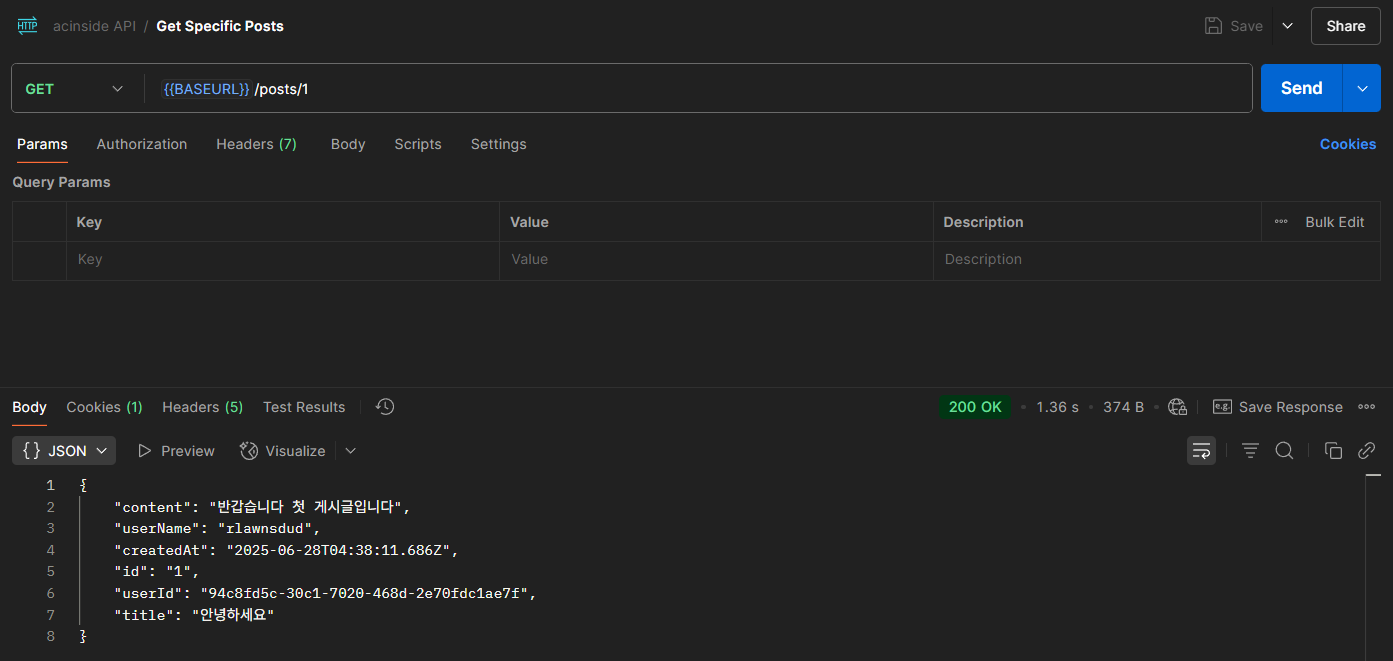
POST /posts (Create Post)
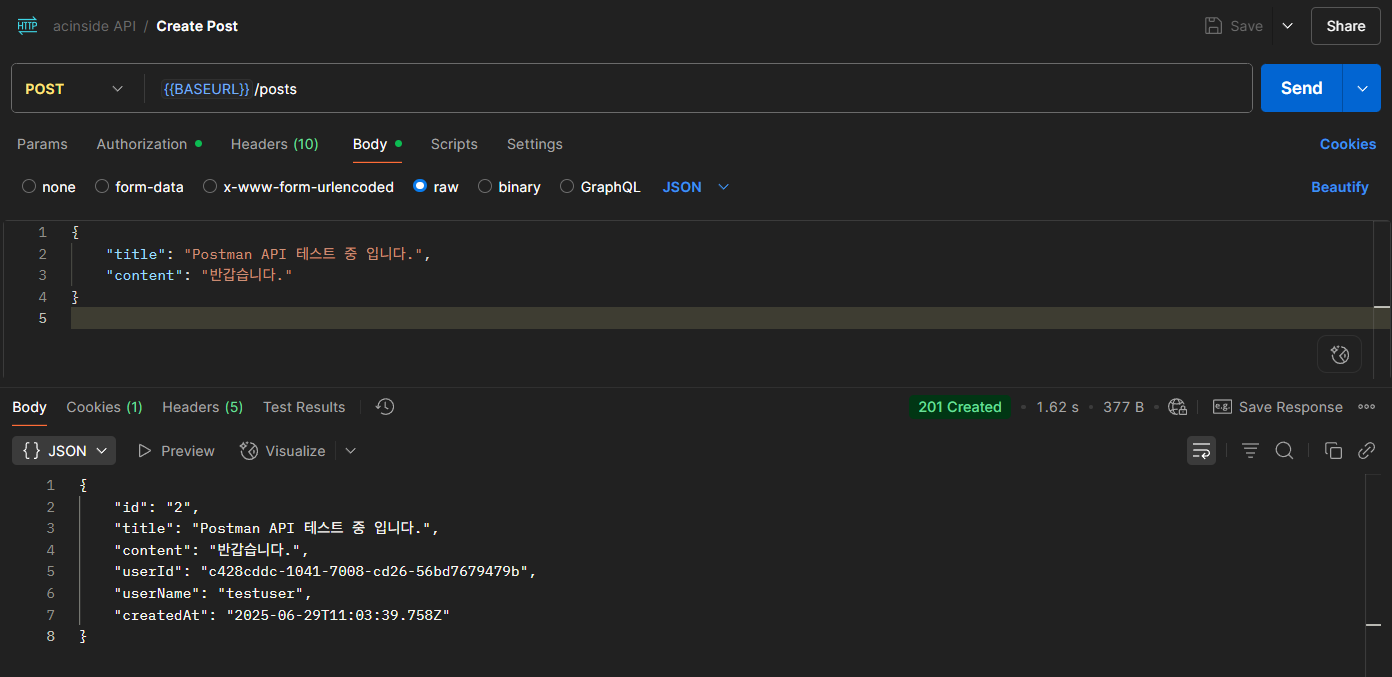
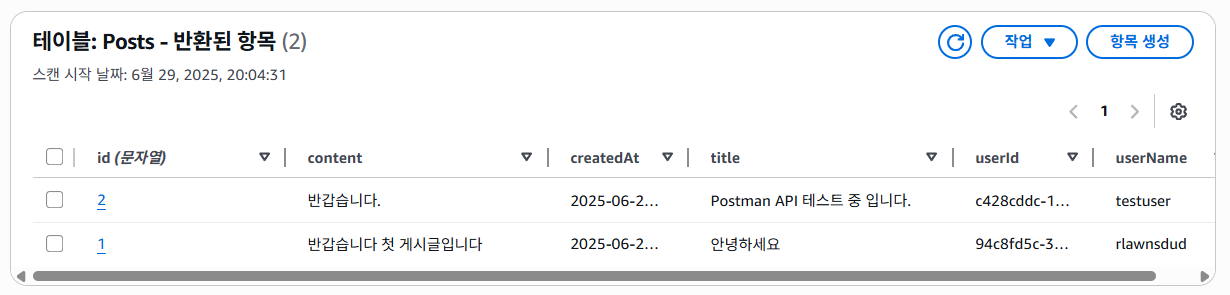
PUT /posts/{id} (Update Specific Post)
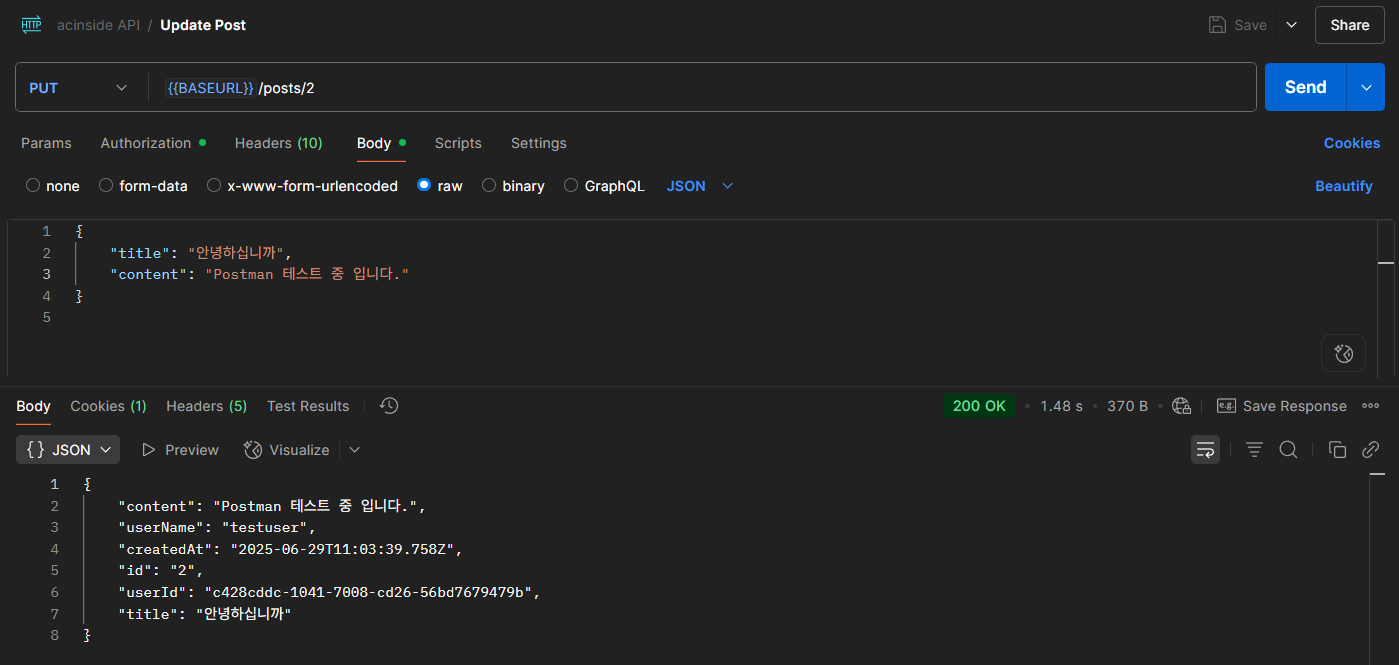
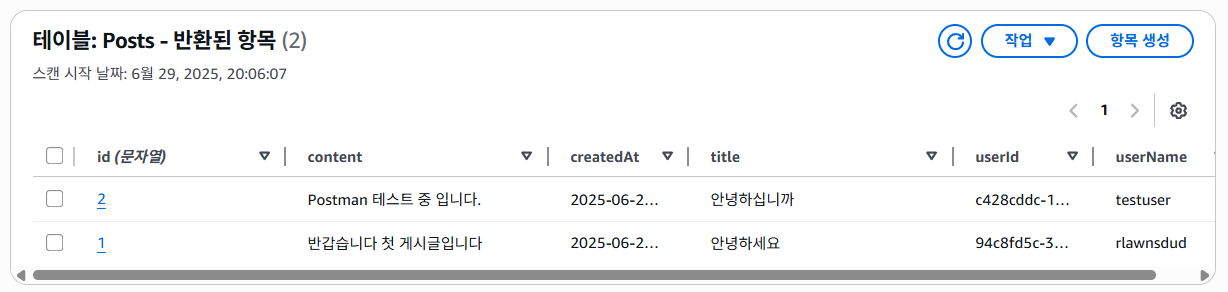
DELETE /posts/{id} (Delete Specific Post)
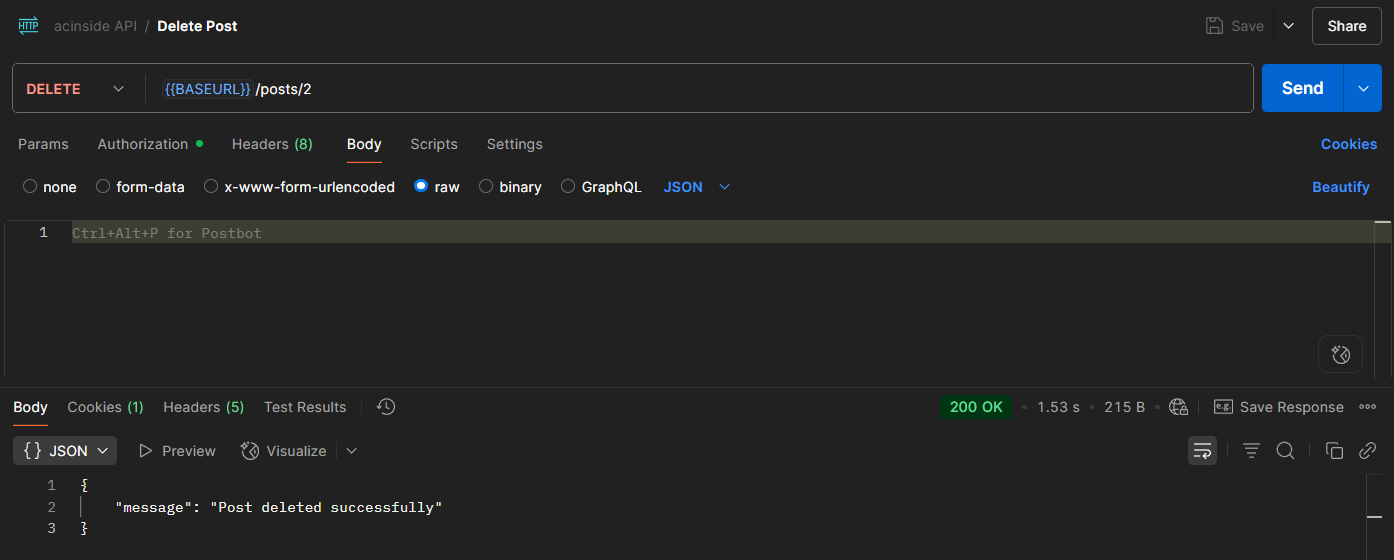
Users API
GET /myinfo
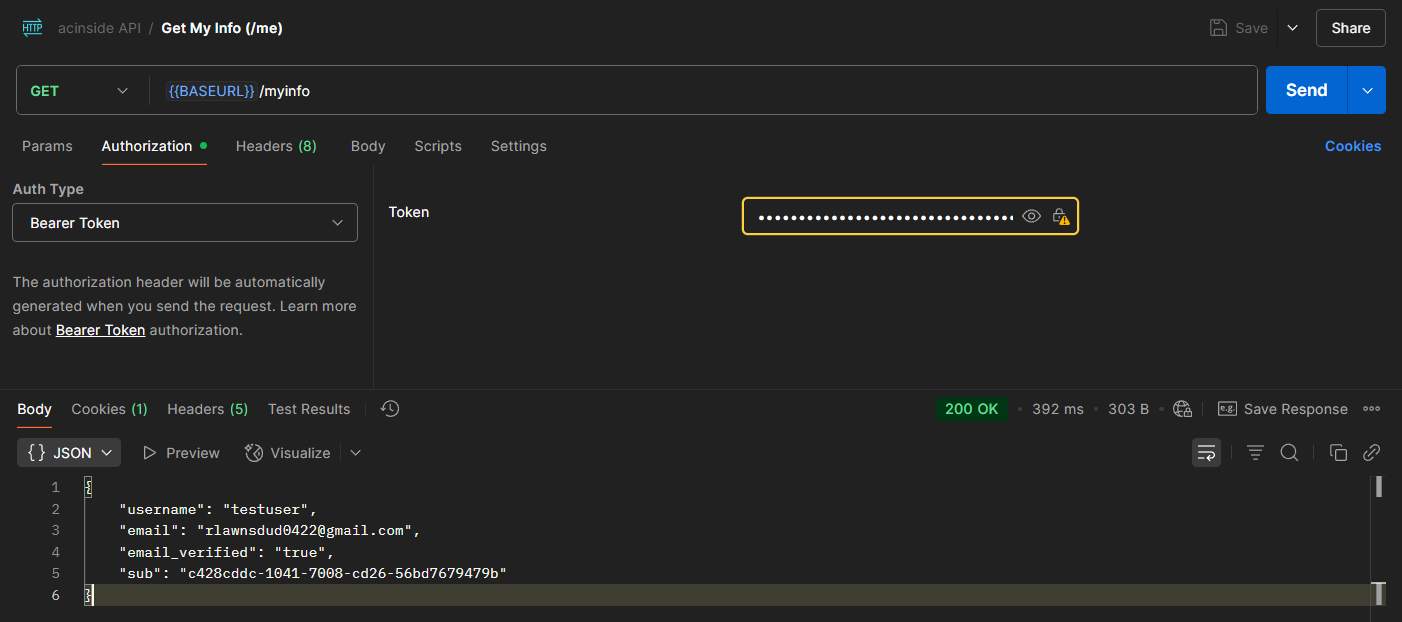
8. Calculate Price
비용을 계산하기 앞서, 일단 어느정도의 트래픽이 발생하는지, MAU(월간 활성 유저 수) 등은 얼마 정도 되는지를 가정해야 편리하다.
또한 이 포스팅에서 작성했던 API는 매우 간단한 로그인 기능과 포스트 CRUD 기능 밖에 없기 때문에 그 양이 더 적겠지만, 시나리오 가정에선 실사용이 가능할 정도의 서비스로 생각한다.
특히 서버리스를 베이스로 한 아키텍쳐이기 때문에 그 가정은 아래와 같이 정하며, 한달을 기준으로 한다.
그리고 지금까지 만들어온 아키텍쳐는 아래와 같다.
이를 바탕으로 AWS Pricing Calculator를 사용하여 요금을 계산해보겠다.
100% 정확한 것은 아니며, 애초에 시나리오를 가정하였기 때문에 정확하다곤 할 수 없다.
또한 필자의 오류로 인해 잘못된 계산이 있을 수 있다. 혹시라도 발견했다면 지적해주길 바란다.
Lambda
먼저 람다에 대한 설정은 아래와 같다.
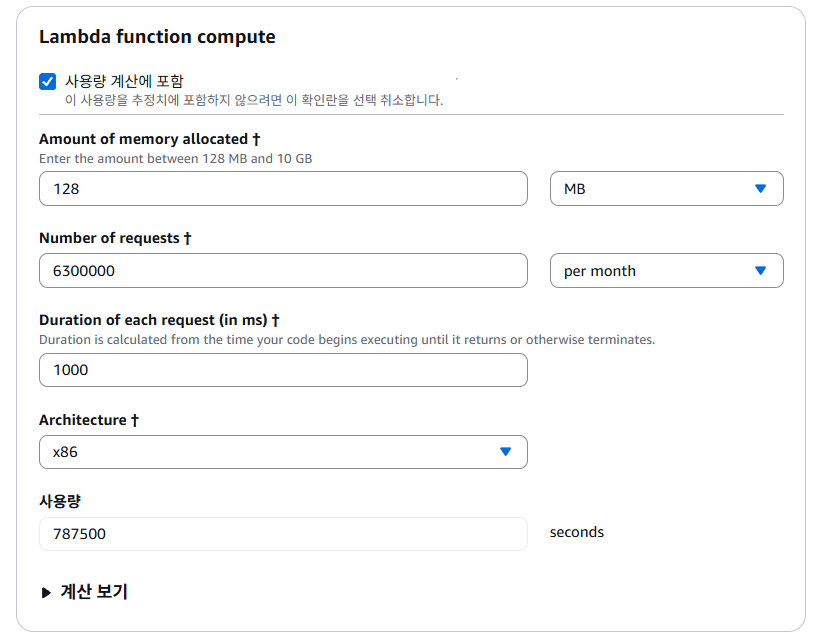
총 요청 수를 6,300,000건으로 생각하였고, 요청 당 실행 시간은 1000ms(1초)로 생각하였다.
메모리는 128MB에 x86 아키텍쳐 기준으로 아래와 같은 요금이 부과된다고 한다.

글 작성일 기준 환율로 생각하면 한화 2만원 정도이다.
API Gateway
API Gateway도 사용량을 기준으로 한다. 요청 수와 요청의 크기로 계산되는데, 6,300,000건의 요청과 요청 당 약 크기는 약 20KB라고 생각하였다.

7.75달러, 한화 약 만원 정도의 요금이 발생하였다.
Cognito
Cognito에선 MAU를 바탕으로 요금을 계산한다.
Number of monthly active users (MAU) who sign in through SAML or OIDC federation는 OAuth, OIDC와 관련된 내용인데 이건 사용하지 않으므로 0으로 설정한다.
다만 MAU는 처음에 가정해뒀던 시나리오를 바탕으로 작성하였다.
MAU는 회원가입, 로그인, 토큰 리프레시 등의 작업이 한번이라도 발생하면 1 MAU로 가정한다.

Cognito는 첫 10,000 MAU는 무료로 제공해주는데, 때문에 Lite 기준으로 10,000 MAU만 계산되어 55달러, 한화 약 7만 4천원 정도가 나온다.
다소 비싸보일 수 있어도, 직접 구현할 시 데이터베이스 사용 + 이메일 인증 + 보안 처리 등의 인프라 비용과 시간이 소요되므로 엄청나게 비싼건 아니다.
다만 Lite 다음 플랜인 에센셜과 비용이 3배 정도 차이가 나기 때문에 복잡한 기능을 사용할 게 아니라면 Lite 사용을 추천한다.
DynamoDB
DynamoDB는 크게 읽기/쓰기 작업과 스토리지 용량에 따라 요금을 계산한다.
읽기/쓰기의 비중은 총 6,000,000건의 요청 중 읽기는 90% = 5,400,000, 쓰기는 10% = 600,000건으로 계산한다.
읽기에 대해선 아래와 같이 설정하였다.
여기서 Eventually consistent reads와 Strongly consistent reads 개념이 등장하는데, 전자는 데이터베이스에 데이터가 쓰여질 시 바로 그 결과값이 보여지지 않을 수 있다.
DynamoDB는 내부적으로 여러 곳에 분산하고 복제하기 때문이다. 반면 후자는 바로 그 값이 적용되어 읽을 수 있는 것으로, 게시글 작성 후 바로 작성된 글 보기 등에서 사용될 수 있다.
하지만 대부분은 전자를 사용하니 그 비중을 95%로 설정하였다. Transactional read는 복수의 데이터를 하나의 트랜잭션(작업)으로 읽을 때 사용하는데 여기선 사용하지 않는다고 가정하였다. (가장 비싸다.)
그리고 평균 아이템 사이즈는 1KB로 설정하였다. 게시글 API에선 큰 용량의 데이터가 사용되진 않기 때문이다.
다음으로 Write에 대한 비용은 아래와 같다.
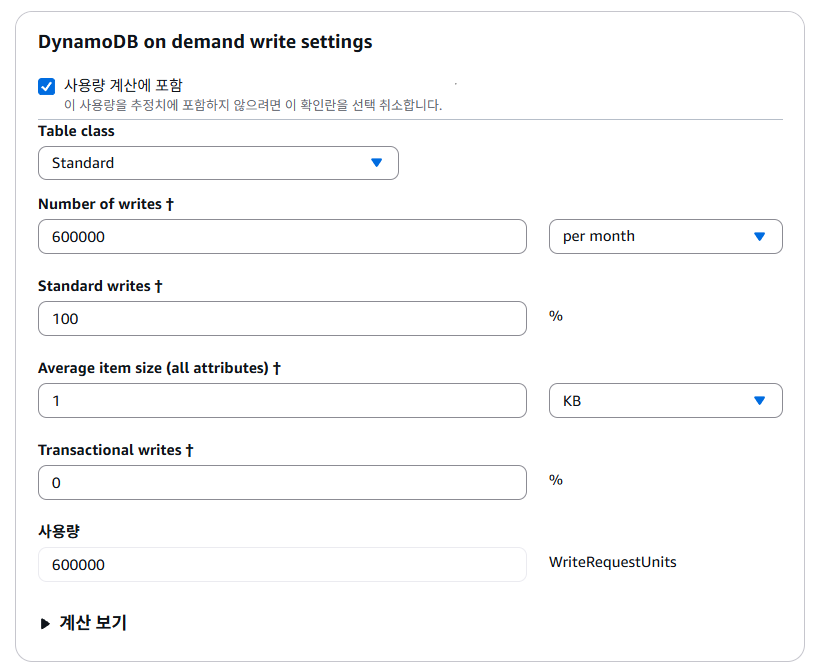
쓰기량은 전체의 10%, 트랜잭션 비율도 0%로 설정해뒀으며 평균 아이템 사이즈도 마찬가지로 1KB로 설정하였다.
마지막으로 스토리지 용량의 경우 DynamoDB의 총 용량을 의미하는데, 게시글이 10만개, 댓글이 50만개라고 가정하면 (100,000 + 500,000) x 1KB = 약 600MB, 여유잡아 1GB라고 설정하였다.
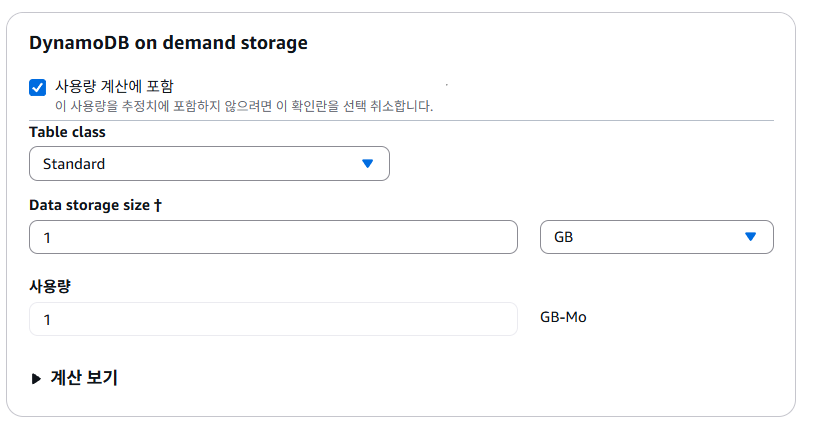
테이블 클래스는 전부 스탠다드로 하였는데, 자주 접근하지 않는 아이템은 스탠다드 IA에 저장하는 것이 스토리지 면에서 효율적이다.

그럼 DynamoDB에 대해선 0.79달러, 한화 약 1100원 정도로 매우 저렴한 것을 볼 수 있다.
S3
다음으로 프론트엔드 배포인 S3와 CloudFront를 보도록 하자.
먼저 S3는 리소스 저장 비용과 요청 비용으로 비용을 계산한다. (S3 스탠다드 기준)
월간 페이지 뷰는 2,000,000회로 설정하였으나, CloudFront를 앞에 붙였기 때문에 캐시 미스가 났을때만 직접 S3에 접근하도록 한다.
만약 CloudFront가 없었다면 2,000,000건의 요청에 정적 파일이 10개라고 가정하면 20,000,000건의 요청이 있어야 했으나, CloudFront가 있으므로 캐시 미스일때만 계산하겠다.
캐시 해트율이 90%라면 미스는 10%, 즉 2,000,000건의 요청으로 적어주겠다.
그리고 리소스 저장 비용은 단순히 웹 페이지 소스코드만 저장하기 때문에 더욱 적은 용량이겠지만, 1GB로 잡아주었다.

이렇게 했을 때 요금은 0.73달러, 한화 약 천원 정도로 매우 저렴하다.
참고로 S3 -> CloudFront로 전송하는 트래픽 요금은 없다.
CloudFront
CloudFront는 데이터 전송 용량과 HTTPS 요청 수를 기준으로 비용을 계산한다.
각 리전(국가), 즉 엣지 로케이션을 기준으로 따로따로 설정할 수 있는데, 아래와 같이 계산하였다.
월간 페이지 뷰(2,000,000회) x 소스코드 용량(1MB) = 약 2TB
그리고 국가는 간단하게 대한민국, 일본으로 나눠서 계산하였다.
(참고로 그러한 국가별 요금은 AWS 공식 문서에서 확인할 수 있다.)
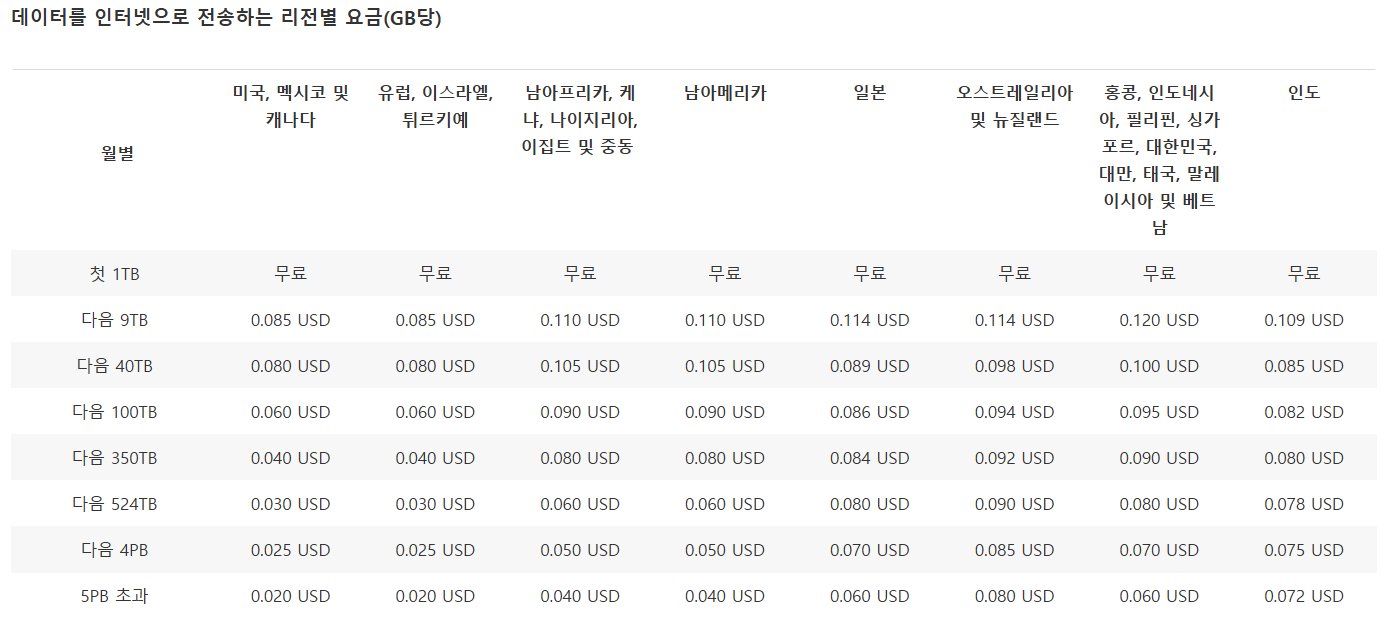
- 서울(대한민국)
=> Data transfer out to internet: 90% = 1.8TB, Number of requests = 18,000,000 - 일본
=> Data transfer out to internet: 10% = 0.2TB, Number of requests = 2,000,000

그럼 대략 268.53달러, 한화 36만 5천원 정도가 나온것을 볼 수 있다.
원래 CDN 서비스가 비용이 꽤나 나가는 서비스이기도 하고 CloudFront는 요금이 복잡하기 때문에 실제론 더 나가거나 덜 나갈 수 도 있다.
가격이 다소 비싸보일 순 있으나 S3만 사용한다고 해도 S3 -> 인터넷으로 나가는 데이터 전송 비용도 꽤나 크고, CloudFront 사용 시 CDN 서비스에 부하 분산 및 WAF 서비스를 연동하여 여러 보안 기능까지 사용할 수 있다.
더군다나 위 요금 표에서 볼 수 있드시 데이터 전송량이 많아지면 많아질 수 록 요금이 더 저렴해지기 때문에 오히려 이득이라 볼 수 있다.
(처음과 비교하여 5PB를 초과하면 요금이 2배 이상 떨어진다.)
아래는 S3만 사용했을 때 인터넷으로 나가는 데이터 전송 요금이다.

Total Cost of Ownership
그래서 TOC(Total Cost of Ownership), 총 비용은 우리가 가정했던 시나리오를 기준으로 아래와 같다.
총 347.18달러, 한화 약 47만 2,506원이 지불된다는 것을 예측할 수 있다.
(비중의 대부분을 CloudFront가 차지했다.)
물론 Serverful하게 아키텍쳐를 작성해도 비슷하지 않냐 생각할 수 도 있지만, Serverful하게 인프라를 만들어도 기본적인 EC2와 RDS 등의 비용까지 생각을 해야된다.
또한 서버리스의 장점인 사용된 만큼(총 실행 시간)만 비용으로 나간다와 인프라를 한번 구축 해두면 이후엔 서버 관리가 비교적 불필요하다는 점에서 장점으로 다가온다.
만약 API 백엔드 요금만 계산한다면 77.93달러, 약 10만 5천원 정도가 과금된다.
물론 기능을 자세히 구현하지 않고 Cognito와 간단한 CRUD API 구현만 해뒀기 때문에 이정도로 저렴하지만, 실제 서비스에서도 요청된 수 + 실행 시간 만큼 과금되기 때문에 스타트업이나 확장성 등이 중요한 서비스에선 서버리스가 유리하게 작용된다는 것이 핵심이다.
9. Cleaning AWS Services
마지막으로 그동한 사용했던 AWS 서비스는 아래와 같이 정리할 수 있다.
- Serverless Framework 정리 (Lambda, API Gateway, IAM, CloudWatch, S3) = CloudFormation 스택 삭제
DeletionPolicy가 적용된 리소스 정리 (Cognito, DynamoDB)- 프론트엔드 정리 (S3, CloudFront)
- (옵션) 깃허브 레포지토리 삭제
10. Conclusion & Insights
프레젠테이션(PPT)에만 포함될 내용으로, 블로그 글에선 생략합니다.
