[Development] Mitigating Thundering Herd with Redis Pub/Sub (feat. Debounce and Distributed Lock)
Development
0. 서론 및 개요
굉장히 오랜만에 블로그 글을 작성해보는 것 같다. 1달은 넘었었는데 그 동안 여러가지 일이 있어 글을 쓸 시간이 없었다. 그 동안 간간히 프로젝트 몇개를 진행했었는데, 그 중 하나가 CTF 플랫폼 개발이다.
학교 또는 전공 동아리 차원에서 CTF 대회 운영을 도왔던 경험이 있었는데, 여러가지 부실한 플랫폼에 있어 불만이 많았었고 이 경험을 바탕으로 더욱 더 개선된 플랫폼을 만들기 위해 프로젝트를 시작했다.
이 블로그는 이에 대한 내용은 아니니 자세한 내용은 아래의 Github 레포지토리나 Docs를 참조하면 좋을 듯 하다.
- https://github.com/nullforu/smctf
- https://github.com/nullforu/container-provisioner-k8s
- https://github.com/nullforu/smctfe
- https://github.com/nullforu/smctf-infra
- (Docs) https://ctf.null4u.cloud [Repo]
아무튼 플랫폼에선 스코어보드라는 것을 제공한다. 여기엔 타임라인과 리더보드로 구성되어 있고, 전자는 시간대 별로 참여자가 어떤 문제를 해결하여 어느 점수를 받았는지를 그래프로 나타내고 후자는 순위를 매김과 동시에 어떤 문제를 풀었는지, 또 First Blood 인지 등을 확인할 수 있도록 한다.
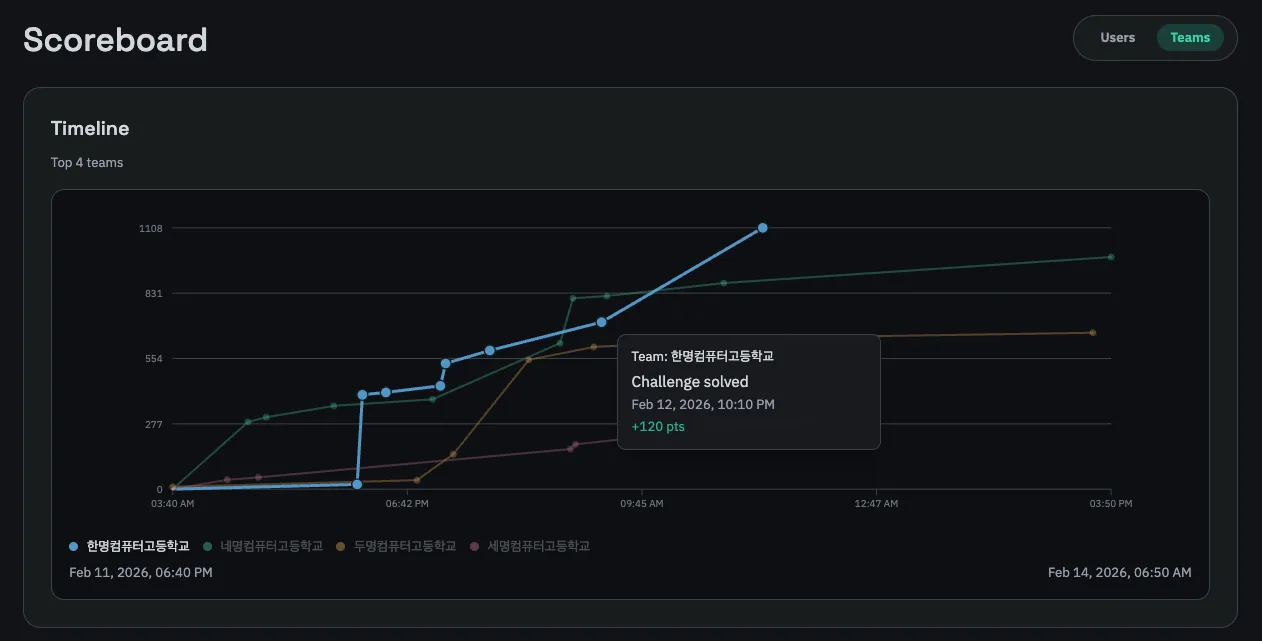
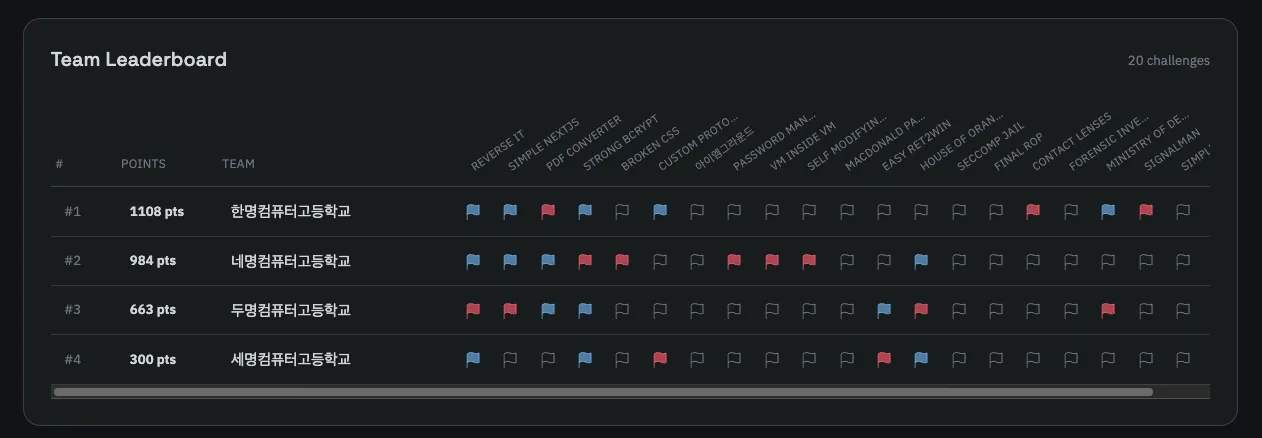
개인적으로 이 UI가 CTF 플랫폼에 있어 가장 중요한 UI이지 않을까 싶고, 이에 따라 신경도 많이 쓴 편이다. 그런 와중에 하나의 의견을 받았는데, "실시간 업데이트" 기능을 구현하자는 의견이였다.
필자도 이에 대해 공감하였고 단방향 통신이면 충분하기에 SSE(Server Sent Events)를 도입하기로 하였다.
스코어보드가 변화되는 API 호출(올바른 플래그 제출, 문제 업데이트 등)이 발생하면 클라이언트에게 스코어보드가 업데이트되었다고 알림을 보내고 클라이언트는 새롭게 스코어보드 관련 API를 호출하는 것이 베이스다.
그런데 해당 SSE 핸들러를 도입하였을 경우 스코어보드를 계산(집계)하는 로직이 효율적이지 못하다고 판단하였다.
1. Redis Pub/Sub 도입하기
해당 기능에 대한 비즈니스 로직(서비스)는 다음과 같았다. 코드의 길이로 인해 포스팅엔 일부만 작성하여 문맥이 어색할 수 있는 점 양해 부탁한다.
func (h *Handler) Leaderboard(ctx *gin.Context) {
cacheKey := "leaderboard:users"
if h.respondFromCache(ctx, cacheKey) {
return
}
rows, err := h.score.Leaderboard(ctx.Request.Context())
if err != nil {
writeError(ctx, err)
return
}
h.storeCache(ctx, cacheKey, rows, h.cfg.Cache.LeaderboardTTL)
ctx.JSON(http.StatusOK, rows)
}이 포스팅에 어느정도 관심이 있어 방문하였다면 유추가 가능하겠지만, 리더보드와 타임라인을 비롯한 GET /api/leaderboard 등의 API는 내부적으로 아래와 같이 처리된다.
- Redis 캐싱이 되어있다면 Cache Hit 및 바로 응답
- Cache Miss 라면 Leaderboard 계산 및 캐싱 후 응답
여기서 스코어보드 캐싱은 앞서 언급한 스코어보드에 변화를 주는 API 호출에서 자동으로 무효화된다.
func (h *Handler) SubmitFlag(ctx *gin.Context) {
// ... (중략)
if correct {
h.invalidateTimelineCache()
h.invalidateLeaderboardCache()
// ... (중략)
}
// ... (중략)
}만약 이 상태에서 SSE를 도입한다면 무효화와 동시에 클라이언트에게 이벤트를 보내야 하므로 분산된 환경에선 일관성있게 Redis Pub/Sub과 같은 Broadcast(1:N) 성격의 메시징 시스템을 사용해야 한다.
기존에 Redis를 캐싱 용도로 사용하고 있으므로 어렵지 않게 도입할 수 있다.
func (h *Handler) SubmitFlag(ctx *gin.Context) {
// ... (중략)
if correct {
h.invalidateTimelineCache()
h.invalidateLeaderboardCache()
h.publishScoreboardEvent() // 예시
// ... (중략)
}
// ... (중략)
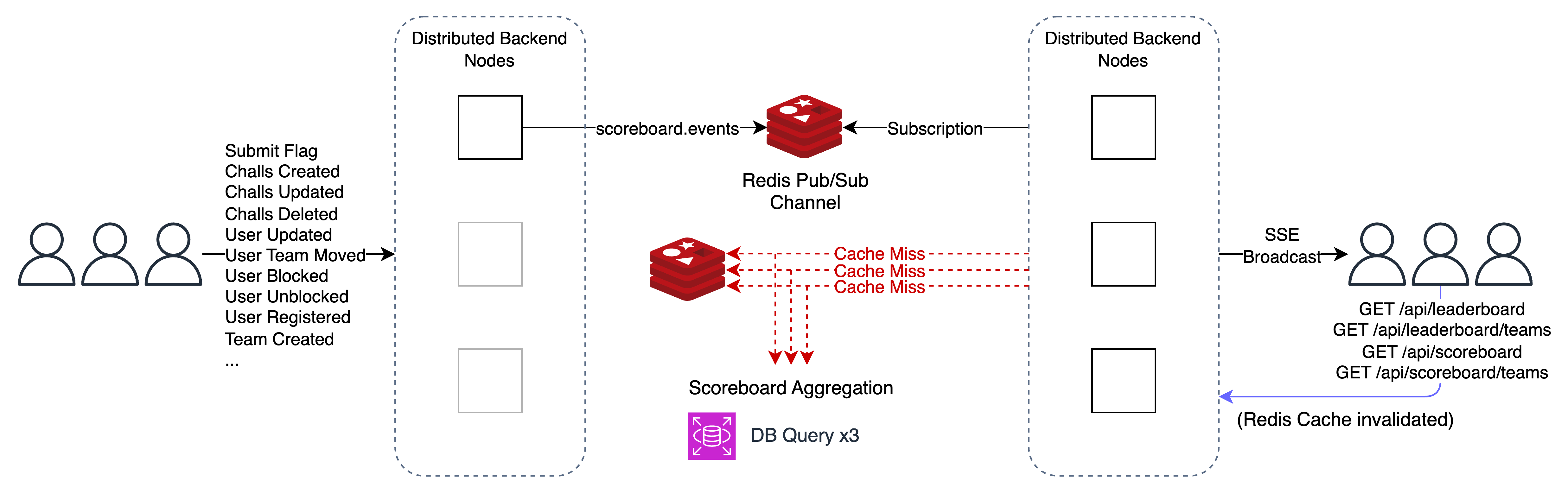
}하지만 앞서 클라이언트는 스코어보드 업데이트 이벤트를 받으면 새롭게 스코어보드 API를 호출한다고 하였고, 이는 곧 거의 같은 시간에 여러 요청이 Burst로 들어오고 다수의 Cache Miss가 발생하여 Thundering Herd 문제가 발생할 수 있다.
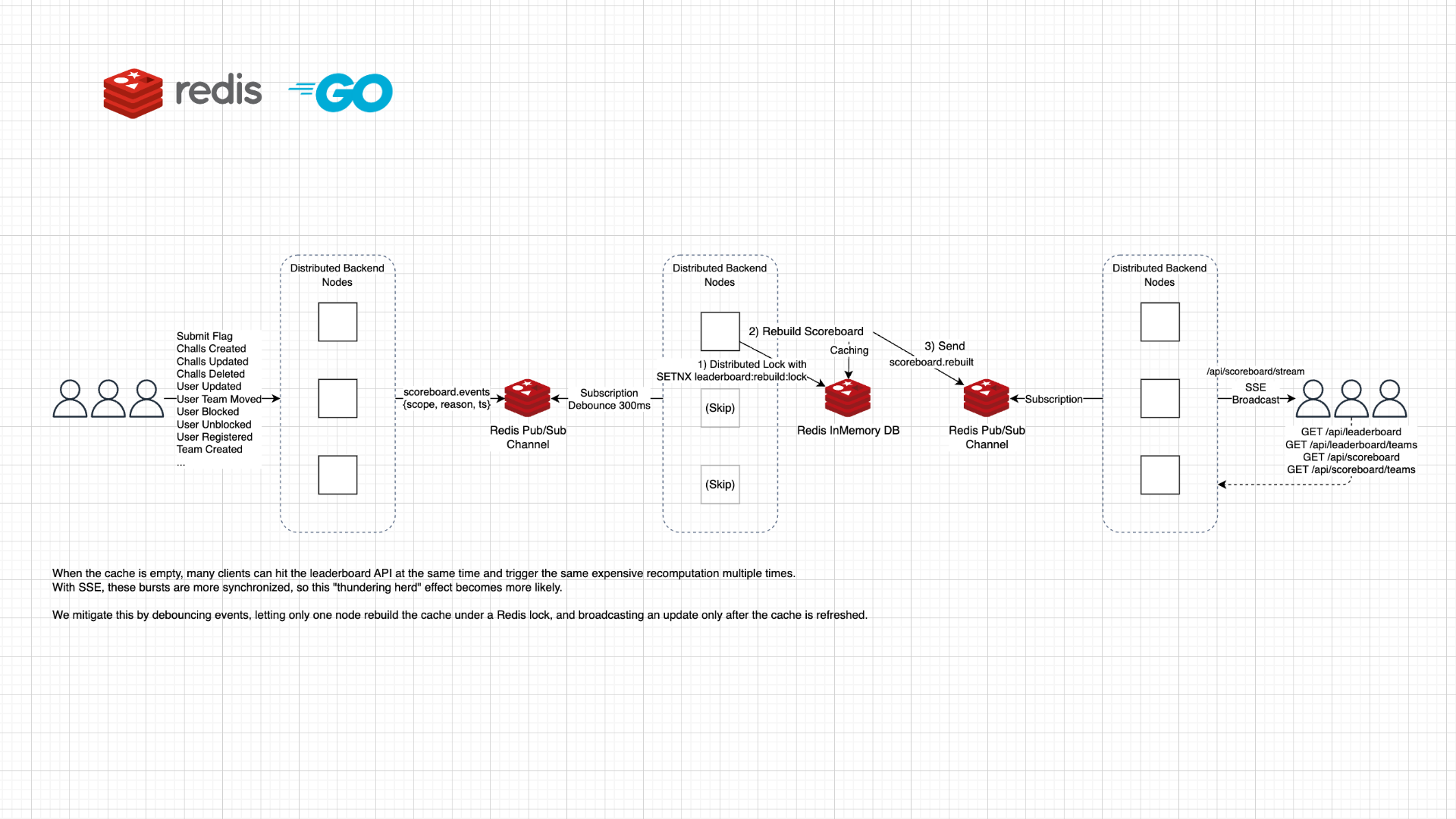
아키텍처에서 Distributed Backend Nodes와 Redis 모양이 여러개지만, 이는 이해를 돕기 위함으로 착각하지 말자.
이는 캐싱이 무효화된 상태에서 한번에 다수의 캐시 접근이 있을 경우 (이론적으로) 모두 Cache Miss가 발생하여 비즈니스 로직을 여러번 실행하는 전형적인 Thundering Herd의 사례이다.
특히나 프로젝트에서 스코어보드의 집계는 많은 DB 엑세스 및 쿼리를 사용하므로 이러한 문제가 더욱 더 부각되며, 여기에 앞서 언급한 SSE를 통한 실시간 스코어보드 아키테처로 인해 더더욱 심해진다.
프로젝트에선 동적 스코어라고 해서 CTFd 플랫폼의 Dynamic Value 기능을 구현해뒀는데, 이 때문에 더 많은 DB 쿼리가 필요하다.
2. Thundering Herd 문제 해결하기
이를 해결하기 위해 처음으로 고안한 대책은 아래와 같다.
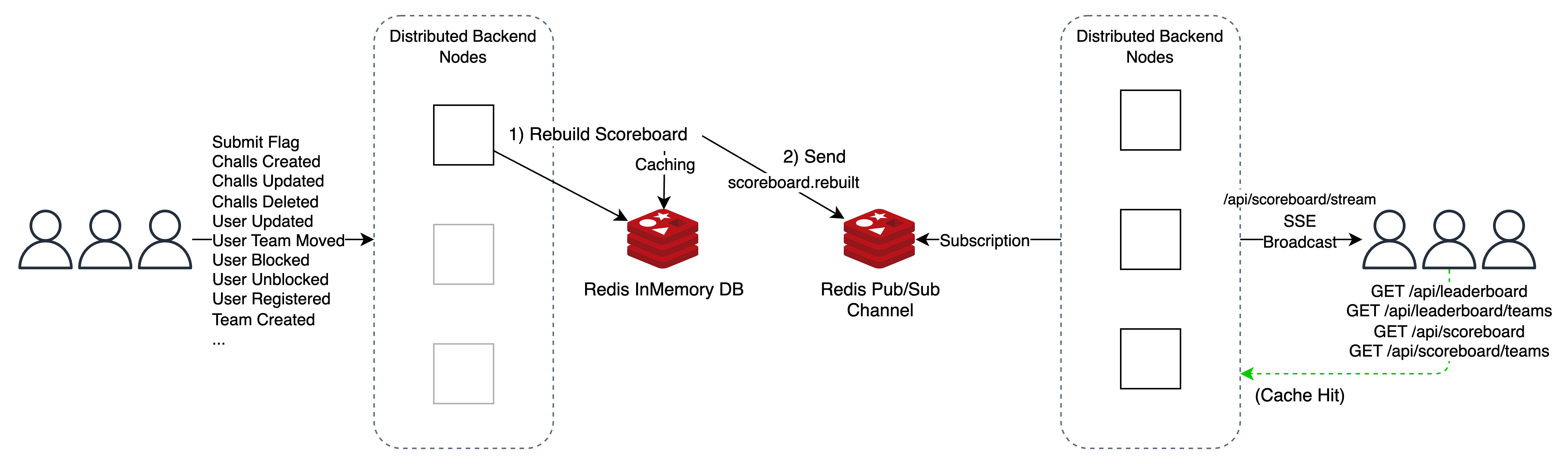
가독성을 위해 Redis Cache Miss 시 내부 흐름은 포함하지 않았다.
사용자가 스코어보드에 영향을 미치는 API를 호출한다면 분산된 환경 중 해당 백엔드 노드에서 스코어보드를 집계하고 계산한다. 이때 기존 캐싱을 무효화하는 것은 마찬가지이다.
이 작업이 완료된다면 결과를 캐싱하고 scoreboard.rebuilt와 같은 Pub/Sub 메시징 채널에서 알림(이벤트)를 보낸다. 그러면 분산된 모든 노드에서 해당 이벤트를 Subscribe 하니 SSE 스트림에 이벤트를 전송한다.
이후 클라이언트는 스코어보드 관련 API를 호출하며 스코어보드 UI를 업데이트한다.
3. 급한 불은 껐지만...
하지만 몇가지 문제가 있었다. 사실 앞으로 진행될, 그리고 이 플랫폼을 사용하여 운영할 CTF의 규모가 크진 않아 문제는 없지만 프로젝트의 규모를 무제한으로 수용할 수 있도록 메인테인하고 있기 때문에 짚고 넘어가야 한다.
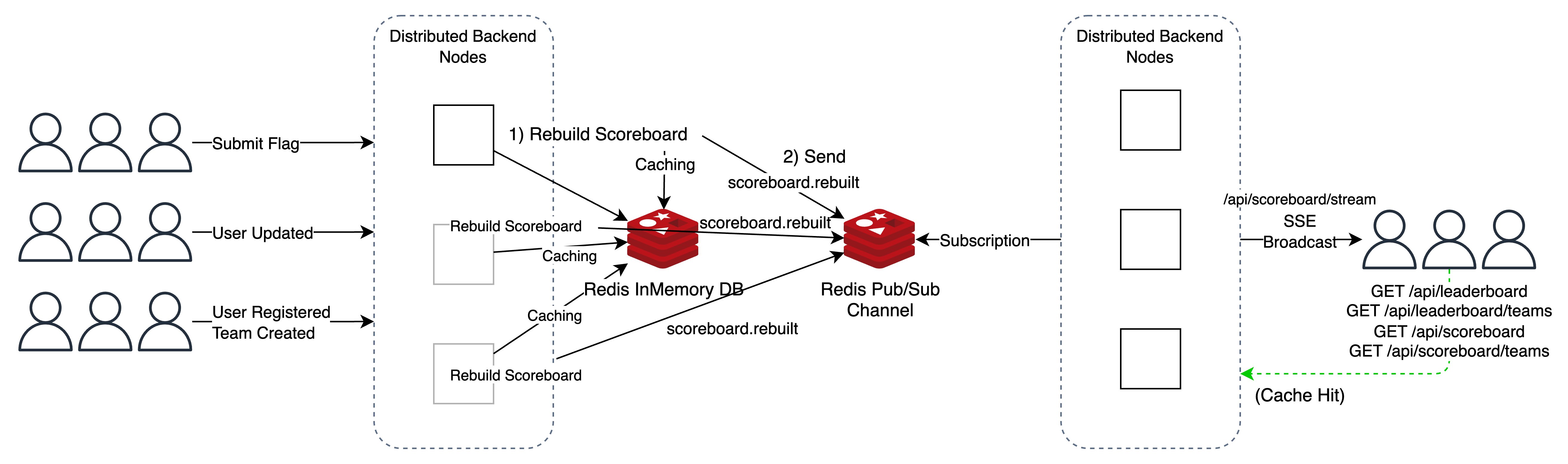
필자의 미적 감각 부재로 가독성이 떨어진 점 양해 부탁한다.
위 다이어그램에서 유추가 가능할 수 있겠지만, 스코어보드에 변동을 주는 API가 짧은 시간 내에 다수가 요청된다면 내부적으로 스코어보드가 여러번 계산되고 캐싱된다.
이에 따라 SSE 스트림에서도 많은 요청이 발생하게 되고, 스코어보드 관련 API도 더 많이 호출될 것이다.
CTF 플랫폼 특성상 장기적으로 봤을때 이런 경우는 많지 않을 수 있지만 대회가 시작된 직후 유저 생성, 팀 생성과 같이 많은 요청이 발생하면서도 스코어보드에 영향을 주는 경우가 있기 때문에 충분히 개선할 여지가 있다.
굳이 그런 이유가 아니여도 핸들러의 역할을 명확하게 분리하고 API 요청 시간을 줄일 수도 있다는 점이 장점이다. (앞서 언급했지만 스코어보드 처리는 많은 DB 요청과 비교적 많은 시간이 발생한다.)
3. Burst 요청 처리하기
이러한 문제를 백엔드 차원에서 해결하기 위해선 가장 효율적인 방법이 메시지 큐나 브로커를 사용하는 것이지 않을까 생각한다.
그 중 앞서 사용해왔던 Redis Pub/Sub이 1:N Broadcasting 모델로 가정 적합하며, 클라이언트가 스코어보드에 변동을 주는 API 호출 시 스코어보드 계산을 해당 API 핸들러에서 처리하는 대신 scoreboard.events와 같은 채널에 이벤트를 보낸다.
그 다음으로 해당 채널을 Subscribe 하는 모든 노드들 중 단 하나의 노드만 선정하여 해당 노드에서 처리 후 scoreboard.rebuilt 채널에 이벤트를 보내면 되는 것이다. (이 부분은 2번째 차례와 동일하다.)
여기서 scoreboard.events를 Subscribe 할 때 디바운스(Debounce) 전략을 사용하면 이 문제를 가장 적절히 해결할 수 있다. 쉽게 말하지면 특정 짧은 시간 내에 발생하는 모든 이벤트를 무시하고 시간 내에 마지막 이벤트만 보면서 처리하는 최적화 기법인데, 현재의 아키텍처에 매우 적합하다.
또한 여기서 핵심은 불특정한 하나의 노드에서만 스코어보드 계산이 처리된다는 점으로 비즈니스 로직 실행(DB 접근 포함)을 최소화할 수 있다.
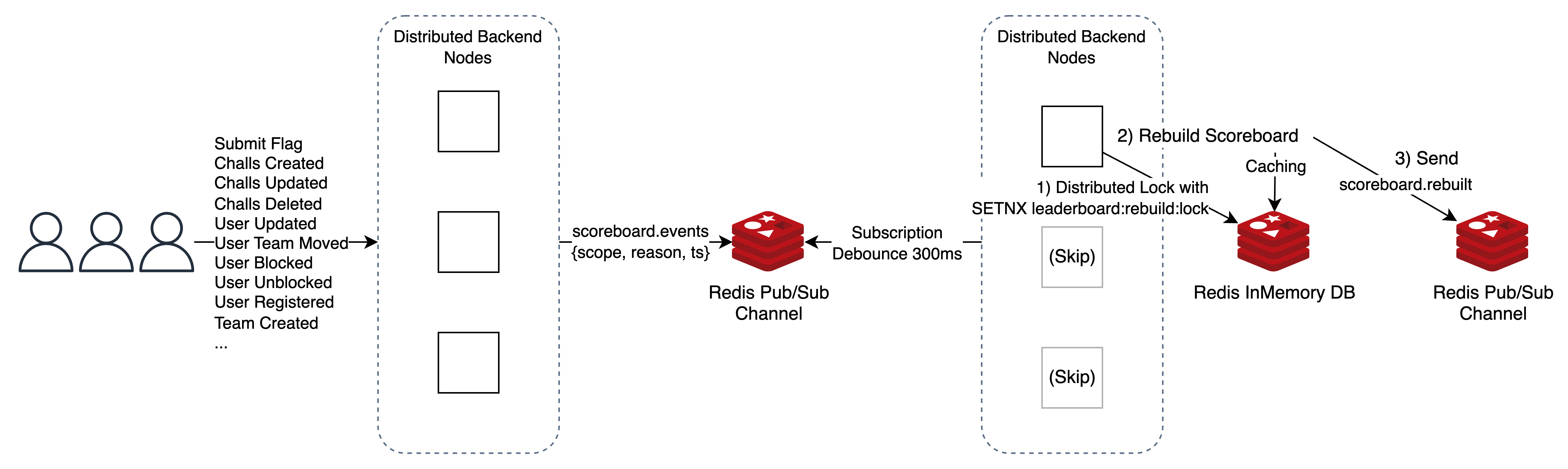
이미지 사이즈가 길어서 scoreboard.rebuilt에 대한 Subscribe 이후 다이어그램은 생략하였다. 기존과 동일하니 참고하자. 디바운스 기간은 300ms이다.
하나의 노드가 선정되면 그 외의 다른 노드는 더이상 작업을 처리하지 않는다. 대신 선정된 노드가 처리를 끝내면 scoreboard.rebuilt에 이벤트를 전송하고 이를 구독하는 여러 노드들이 SSE 스트림에 이벤트를 보내는 것이다.
이때 하나의 노드를 선정하는 방법은 여러가지가 있을 수 있으나 필자는 분산 락(Distributed Lock) 기법을 사용하였다. 이는 여러 노드(서버, 프로세스 등)가 공유된 자원에 동시에 접근하려고 할때 오직 하나의 노드만이 자원에 접근할 수 있도록 하는 동기화 메커니즘이다.
이는 Redis의 SETNX 명령어를 통해 어렵지 않게 구현할 수 있으며, 락이 걸려있는 상태라면 디바운스 기간이 초과되었더라도 노드에서 처리되지 못한다. 이전 처리가 끝나 락이 반환되었을 경우 다시 처리되기 시작하는 것이다.
다만 디바운스 전략과 분산 락을 도입하여 Burst 요청을 "완화"한다는 표현을 사용해야 한다.
이전과 같은 경우 300ms 주기로 스코어보드가 계산되는게 맞지만, 아래와 같은 시나리오를 생각해보자.
- A 노드: 마지막 이벤트 수신 시간
t=0ms, 디바운스 만료t=300ms- B 노드: 마지막 이벤트 수신 시간
t=100ms, 디바운스 만료t=400ms이때 A 노드가 락을 잡은지 10ms만에 처리가 끝났다면, B가 자신의 디바운스 만료 시간은 400ms에 도달하였을 때 락이 풀려있을 수 있고 결론적으로 400ms 내에 2번의 스코어보드 처리가 발생할 수 있다는 의미다.
이론적(이상적)으로 보면 괜찮을 수 있지만(항상 300ms 동기화), 실제 운영 환경에선 네트워크 레이턴시나 프로세스의 처리 한계 등의 요소로 충분히 발생할 수 있는 문제이다.
이 문제 또한 완화하려면 처리 직후 쿨다운 등을 도입하거나 마지막 계산 시각을
last_rebuilt키 등으로 저장하고 처리하는 방법 등이 있을 수 있지만, 거기까진 너무 복잡하다고 판단하였고 이 정도로 만족하기로 타협을 봤다.더 괜찮은 방법이 있다면 언제든지 피드백을 환영한다.
분산 락을 잡을 때 값으로 임의의 랜덤한 토큰을 지정하는데, 이는 특정한 노드가 자신의 락임을 지정하는 용도이다.
TTL(기본 10초)로 인해 락이 해제되어 다른 노드의 락이 생기는 경우, 즉 락 소유권이 바뀐 경우 늦어진 노드가 처리를 끝낸 후 락을 삭제하려고 시도한다.
이때 노드에서 특정한 토큰 값이 없다면 다른 노드의 락이 삭제될 수 있다. 때문에 마지막에 자신의 락만 삭제하기 위해 락을 생성할 때 임의의 토큰을 함께 생성하도록 하는 것이다.
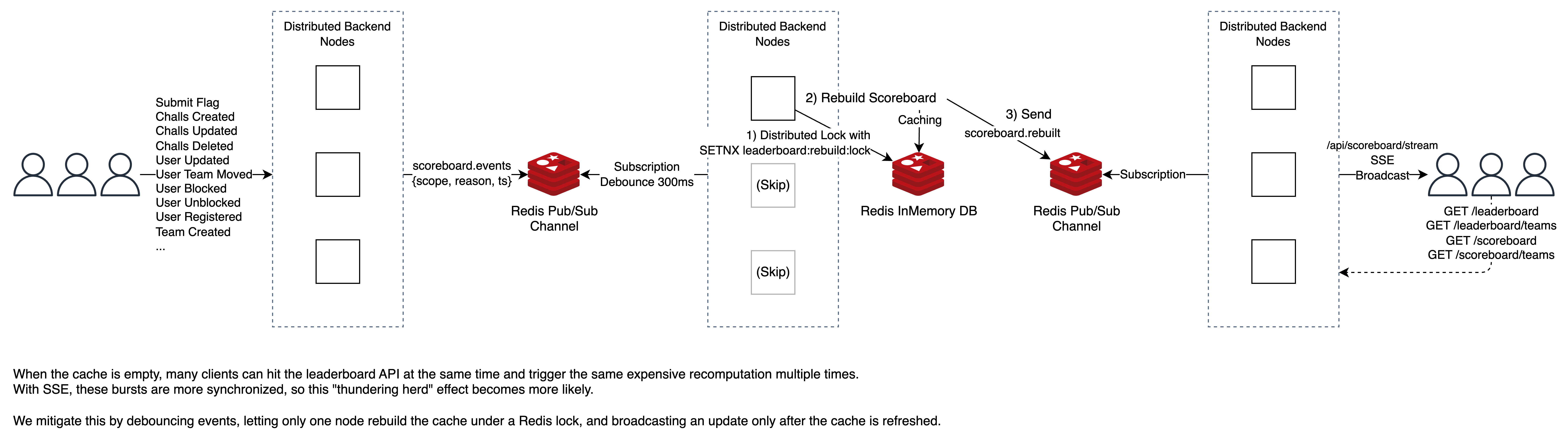
최종적으로 PR에 사용된 다이어그램은 아래와 같다. 궁금하다면 아래의 PR을 참조하자.
4. 구현하기 in Go
프로젝트는 Go 언어와 Gin 프레임워크와 Bun ORM을 사용한다. 원래는 NestJS를 주로 사용하였지만, 너무 무거워서 프로젝트에서 사용하기엔 적합하지 않았다.
사실상 Gin 프레임워크를 도입한 첫 프로젝트인데, 만족도가 굉장히 높다. Go 언어 자체에 대한 만족도가 높은 것도 한 몫 한다.
모든 비즈니스 로직에 대해 설명하기엔 분량 상 어려움이 있고 몇가지 주요 로직만 서술하려고 한다. 자세한 내용은 위쪽에 첨부된 PR이나 레포지토리를 방문해보도록 하자.
먼저 스코어보드에 변동을 주는 API는 아래와 같다. 일부 API는 일반적인 스코어링 시스템이라면 영향을 주지 않지만 이 플랫폼에선 Dynamic Scoring을 적용하기 때문에 적절한 핸들링이 필요하다.
- 정답 플래그 제출
- 유저 차단/해제
- 유저 정보(닉네임) 변경
- 유저 팀 이동
- 문제 생성/수정/삭제
- 회원가입
- 팀 생성
이 API 핸들러들에 대해 아래와 같은 공통된 헬퍼 함수를 만들어서 캐시 무효화 및 scoreboard.events 채널에 이벤트를 보내도록 한다.
// internal/http/handlers/handler.go
func (h *Handler) notifyScoreboardChanged(ctx context.Context, reason string) {
h.invalidateLeaderboardCache()
h.invalidateTimelineCache()
h.publishScoreboardEvent(ctx, reason)
}func (h *Handler) publishScoreboardEvent(ctx context.Context, reason string) {
event := realtime.ScoreboardEvent{
Scope: "all",
Reason: reason,
TS: time.Now().UTC(),
}
payload, err := json.Marshal(event)
if err != nil {
return
}
_ = h.redis.Publish(ctx, "scoreboard.events", payload).Err()
}이때 페이로드 없이 이벤트를 보내도 되지만, 추후 확장과 디버깅을 위해 몇가지 정보를 포함하도록 작성하였다.
이 로직이 맨 앞단의 무효화 후 scoreboard.events Pub/Sub 채널에 이벤트를 보내는 로직으로 이제 이 채널을 Subscribe 하고 디바운스 및 분산 락을 적용하는 로직을 작성해야 한다.
이는 별도의 마이크로서비스로 분산할 수 있었지만 유지보수 포인트가 늘어날 것 같아 같은 백엔드 서비스 내에 포함하도록 하고, 이때 Goroutine을 사용한다.
// internal/realtime/scoreboard_bus.go
type ScoreboardBus struct {
redis *redis.Client
cfg config.Config
score ScoreboardReader
logger *logging.Logger
hub *SSEHub
debounce time.Duration
lockTTL time.Duration
trigger chan string
}
func (b *ScoreboardBus) Start(ctx context.Context) {
pubsub := b.redis.Subscribe(ctx, scoreboardEventsChannel)
rebuilt := b.redis.Subscribe(ctx, scoreboardRebuiltChannel)
go b.run(ctx, pubsub, rebuilt)
}
func (b *ScoreboardBus) run(ctx context.Context, pubsub *redis.PubSub, rebuilt *redis.PubSub) {
defer func() {
if err := pubsub.Close(); err != nil {
b.logger.Warn("leaderboard pubsub close", slog.Any("error", err))
}
if err := rebuilt.Close(); err != nil {
b.logger.Warn("leaderboard rebuilt close", slog.Any("error", err))
}
}()
// ... (중략)
}scoreboard.events Subscribe
scoreboard.events는 스코어보드에 변동이 생길 경우 무효화와 함께 이벤트가 Publish 되는 채널로, Redis Pub/Sub 채널 내 메시지가 있을 경우 가져와서 적절하게 처리하면 된다.
이때 해당 채널을 Subscribe 하는 Goroutine 내에서 모든 처리를 하게 되면 스코어보드 처리가 늦어지면 해당 Goroutine에서 병목이 발생할 수 있다.
그렇다고 메시지마다 Goroutine을 만드는 방법은 메모리/GC에 상당한 부하를 발생시킬 수 있으므로 필자는 별도의 Trigger 채널을 만드는 방법을 사용하였다.
(위에서 ScoreboardBus 구조체 내의 trigger가 그 역할이다.)
go func() {
ch := pubsub.Channel()
for {
select {
case <-ctx.Done():
return
case msg, ok := <-ch:
if !ok {
return
}
select {
case b.trigger <- msg.Payload:
default:
}
}
}
}()이제 디바운스 로직을 작성해보는데, 이 경우 Time과 Trigger 채널을 기반으로 하는 State Machine 형태라 비동기 처리를 할 필요가 없다.
디바운스 구현을 위해 time.Timer를 사용하며 timer.C는 타이머가 만료되었음을 알려주는 수신 전용 채널이므로 적절하게 사용할 수 있다.
var (
timer *time.Timer
lastPayload string
)
for {
select {
case <-ctx.Done():
if timer != nil {
timer.Stop()
}
return
case payload := <-b.trigger:
lastPayload = payload
if timer == nil {
timer = time.NewTimer(b.debounce)
continue
}
if !timer.Stop() {
select {
case <-timer.C:
default:
}
}
timer.Reset(b.debounce)
case <-func() <-chan time.Time {
if timer == nil {
return nil
}
return timer.C
}():
if timer != nil {
timer.Stop()
timer = nil
}
b.handleEvent(ctx, lastPayload)
}
}Go의 채널 select에선 준비된 case와 default 까지 없다면 Blocking 한다.
ctx.Done()은 생략하고, select로 처리하는 아래의 두가지 경우를 각각 살펴보겠다.
case payload := <-b.trigger:
lastPayload = payload
if timer == nil {
timer = time.NewTimer(b.debounce)
continue
}
if !timer.Stop() {
select {
case <-timer.C:
default:
}
}
timer.Reset(b.debounce)위 로직은 Trigger 채널에 이벤트가 수신될 경우 실행되는데, 마지막 이벤트 페이로드만 저장하고 타이머를 디바운스 만큼 초기화한다.
이 경우 이벤트가 절대 멈추지 않고 계속 들어온다면 영원히 이벤트 핸들링이 되지 않겠지만 플랫폼 특성상 + 300ms의 짧은 디바운스 간격으로 그럴 경우는 없으니 문제가 되지 않는다.
만약 300ms동안 이벤트가 들어오지 않는다면 타이머가 만료된다면 분산 락을 잡은 하나의 노드가 스코어보드를 처리할 수 있다.
case <-func() <-chan time.Time {
if timer == nil {
return nil
}
return timer.C
}():
if timer != nil {
timer.Stop()
timer = nil
}
b.handleEvent(ctx, lastPayload)
}중간에 익명 함수는 타이머가 nil일 경우 timer.C를 사용하면 Panic이 발생하므로 이에 대한 처리이다. nil case는 실행되지 않는다.
즉 아래와 같이 동작한다. 이때 락을 잡을 때 TTL이 필요한데 너무 짧다면 중복으로 실행될 가능성이, 너무 길거나 아예 없다면 장애 발생 시 처리가 장시간 정지될 수 있다.
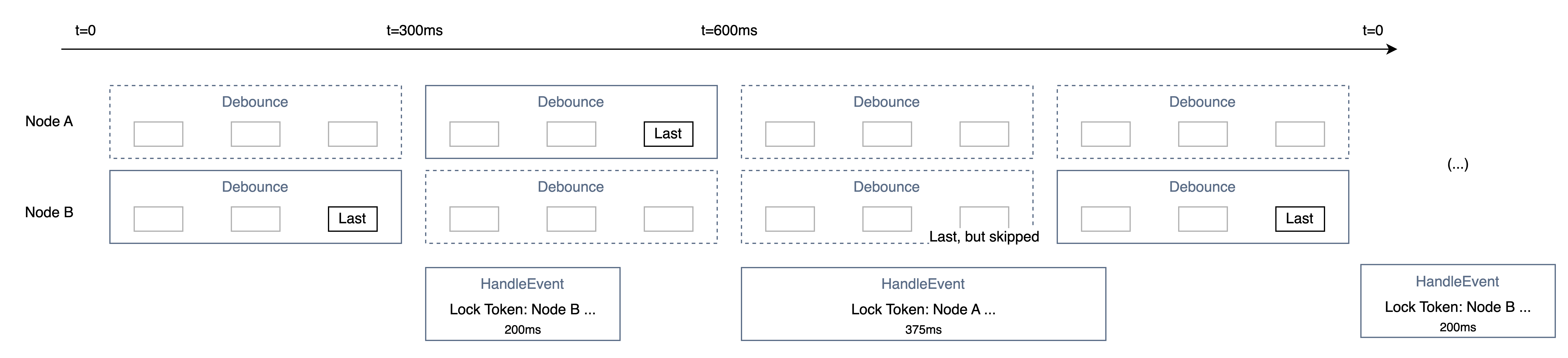
물론 이 다이어그램의 전제 조건은 네트워크 레이턴시를 비롯한 걸림이 전혀 없다는 가정하에 락 TTL ≥ 최대 처리 시간이 성립할 때 유효하다. 이에 대해선 아래에서 다시 설명하겠다.
handleEvent
이 함수는 본격적으로 스코어보드를 처리하는 함수로, 디바운스 이후 단 하나의 노드만이 처리 후 캐싱하고 scoreboard.rebuilt Pub/Sub 채널에 이벤트를 송신한다.
분산 락이 핵심적인 함수이며, 아까 언급하였듯이 TTL 만료 이후 다른 노드의 토큰을 삭제하지 않도록 임의의 토큰을 사용하도록 한다.
락의 TTL은 적절한 타협이 필요하다. 너무 짧으면 중복으로 실행될 가능성과 너무 길다면 장애 시 처리 시간이 길어진다는 트레이드 오프가 있다.
여기서 Lock TTL은 10초로 설정하였고, 보통 아래의 공식대로 설정한다면 적절할 것이다.
TTL ≥ (handleEvent 최대 실행 시간 + 네트워크 지연 + clock skew)- (간단하게)
handleEvent최대 실행 시간의 2~3배 정도
만약 TTL 만료에 대해 토큰과 같은 전략을 사용하지 않는다면 아래은 상황이 발생할 수 있다.
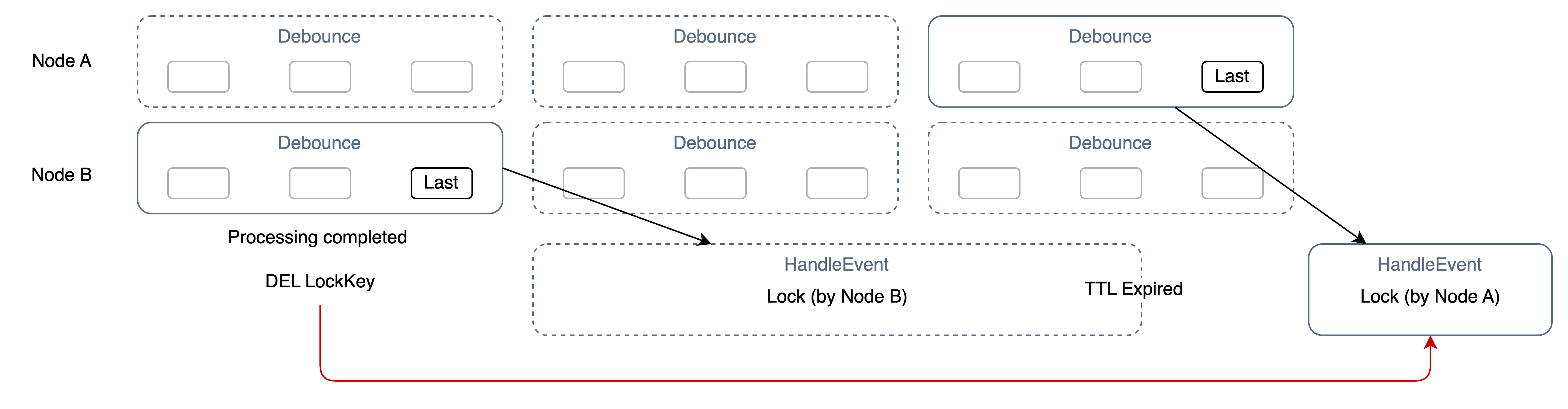
노드 B가 락을 먼저 잡고 처리를 하지만 너무 오래 걸려 TTL을 초과하여 해당 락이 삭제된다. 이후 디바운드 기간이 지나 새로운 노드 A의 락이 걸리는데 노드 B의 처리가 이제서야 끝나 락을 삭제하게 된다.
이때 B 입장에선 자신의 락이라고 착각했기 때문에 새로운 A 노드의 락이 삭제되게 되고 이는 짧은 시간 내에 중복된 계산이 될 수 있다.
(물론 처리 시간이 락 TTL을 넘길 경우는 거의 없지만, 만약의 경우를 대비하도록 한다.)
이를 해결하기 위해 락 키에 대한 임의의 토큰 전략을 사용하고, 락킹 시 같이 생성되는 토큰 값과 동일해야 락을 회수(삭제)할 수 있도록 한다.
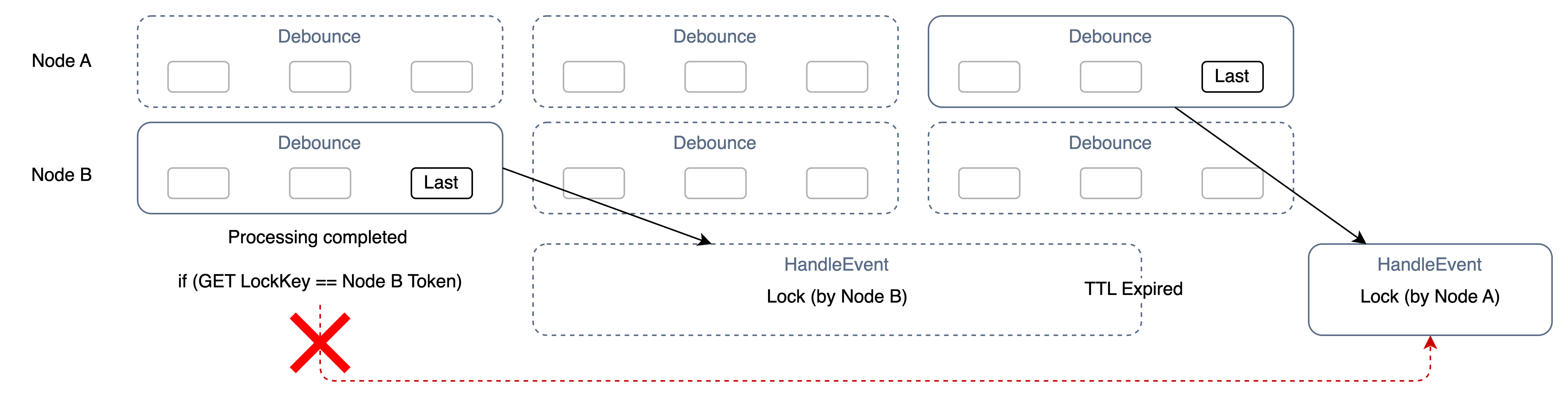
이론 설명은 여기까지만 하고, 본격적으로 handleEvent 코드를 살펴보겠다.
func (b *ScoreboardBus) handleEvent(ctx context.Context, payload string) {
locked, token := b.acquireLock(ctx)
if !locked {
return
}
ctx, cancel := context.WithTimeout(ctx, 10*time.Second)
defer cancel()
if err := b.rebuildCaches(ctx); err != nil {
b.logger.Warn("leaderboard rebuild failed", slog.Any("error", err))
b.releaseLock(ctx, token)
return
}
b.releaseLock(ctx, token)
_ = b.redis.Publish(ctx, scoreboardRebuiltChannel, payload).Err()
}Refs 1. rebuildCaches(Context) 함수는 따로 살펴보지 않겠다. 스코어보드 처리 후 캐싱하는 로직이 포함됐다고 생각하면 된다.
Refs 2. Context 타임아웃이 락을 회수하기 전 아웃될 수 있지만 이러한 상황을 위해 락 TTL을 걸어뒀기 때문에 큰 문제는 없다.
Refs 3. 더욱 더 안정성있게 하려면 lock TTL ≥ ctx timeout + 여유 등으로 살짝의 여유를 주는 것이 좋을 수 있다.
여기서 중요한건 acquireLock과 releaseLock 함수이다. 이름에서 유추할 수 있겠지만 락을 잡고 회수하는 로직이다.
func (b *ScoreboardBus) acquireLock(ctx context.Context) (bool, string) {
token := randomToken()
ok, err := b.redis.SetNX(ctx, scoreboardLockKey, token, b.lockTTL).Result()
if err != nil {
b.logger.Warn("leaderboard lock error", slog.Any("error", err))
return false, ""
}
return ok, token
}
func (b *ScoreboardBus) releaseLock(ctx context.Context, token string) {
if token == "" {
return
}
const script = `if redis.call("get", KEYS[1]) == ARGV[1] then return redis.call("del", KEYS[1]) else return 0 end`
_, _ = b.redis.Eval(ctx, script, []string{scoreboardLockKey}, token).Result()
}이 로직을 간단하게 의사 코드로 표현한다면 아래와 같다.
Acquire
SetNX(key, token, TTL)Release
if get(key) == token then
del(key)
end락을 잡는 로직은 단일 명령어로 가능하니 문제가 없지만, 락을 회수(릴리즈)하는 로직은
- 키 값 확인 후 같은 토큰인지 여부
- 해당 토큰이 같을 경우 락 삭제(회수)
두 단계와 두가지의 명령어를 사용하기 때문에 일반적인 명령어를 통해 조합하여 사용한다면 정합성(일관성)에 문제가 발생할 수 있다.
예를 들어 발생할 수 있는 시니라오는 아래와 같다.
- Node A가 락 획득 (Token=A)
- 릭 TTL 만료, 이와 동시에 Release도 실행될때 GET 결과가 Node A 락일 가능성이 있음
- Node B가 락 획득 (Token=B)
- Node A가 늦게 Release 실행, GET 시점에선 Node A의 토큰이 확인되었으므로 A가 DEL 실행
이 또한 거의 발생하지 않는 경우이지만 개발자는 최악의 시나리오를 항상 생각해야 한다.
이러한 문제를 해결하기 위해선 릴리즈 시 두 과정을 하나의 트랜잭션, 즉 원자적으로 만들면 되고 Redis에선 Lua Script를 통해 원자(Atomic) 단위로 처리할 수 있는 기능을 지원한다.
위 소스코드의 Release 함수에서 사용된 스크립트 또한 그 이유에서다.
if redis.call("get", KEYS[1]) == ARGV[1] then
return redis.call("del", KEYS[1])
else
return 0
end이는 원자적(Atomic)으로 실행된다. (Redis 내부에서 스크립트 평가 시 스레드를 Blocking 함)
최종적으로 Acquire과 Release를 조합하여 handleEvent를 구현할 수 있다. 마지막으로 Rebuilt Redis Pub/Sub 채널에 이벤트를 보내 SSE 스트림에 이벤트를 작성하라고 모든 노드에 Broadcasting 할 수 있다.
_ = b.redis.Publish(ctx, scoreboardRebuiltChannel, payload).Err()scoreboard.rebuilt Subscribe
handleEvent가 처리를 완료하였다면 scoreboard.rebuilt 채널에 이벤트를 송신한다고 했었다.
이는 모든 노드에서 자신의 SSE 스트림에 이벤트를 일관적으로 작성(송신)하도록 해야 하므로 분산 락과 같은 전략은 필요하지 않다. 단순하게 다시 run 함수로 돌아가 Goroutine을 하나 더 만들고 해당 채널을 Subscribe 하면 된다.
go func() {
ch := rebuilt.Channel()
for {
select {
case <-ctx.Done():
return
case msg, ok := <-ch:
if !ok {
return
}
b.hub.Broadcast(msg.Payload)
}
}
}()Broadcast는 SSE Connections에 대해 같은 메시지를 Fan out으로 뿌리는 역할을 한다. 이에 대해선 internal/realtime/sse.go 소스코드를 참조하도록 하고, 이 로직에 대해 설명하는 포스팅은 아니기 때문에 넘어가겠다.
// internal/realtime/sse.go
package realtime
import "sync"
type SSEHub struct {
mu sync.Mutex
subscribers map[chan string]struct{}
}
func NewSSEHub() *SSEHub {
return &SSEHub{subscribers: make(map[chan string]struct{})}
}
func (h *SSEHub) Subscribe(buffer int) (chan string, func()) {
if buffer <= 0 {
buffer = 1
}
ch := make(chan string, buffer)
h.mu.Lock()
h.subscribers[ch] = struct{}{}
h.mu.Unlock()
unsubscribe := func() {
h.mu.Lock()
if _, ok := h.subscribers[ch]; ok {
delete(h.subscribers, ch)
close(ch)
}
h.mu.Unlock()
}
return ch, unsubscribe
}
func (h *SSEHub) Broadcast(payload string) {
h.mu.Lock()
for ch := range h.subscribers {
select {
case ch <- payload:
default:
}
}
h.mu.Unlock()
}
이로써 실시간 스코어보드 대해 Thundering Herd 완화를 위한 아키텍처 고안, 그리고 디바운스(Debounce)를 전략과 이후의 분산 락(Distributed Lock) 등을 도입해보고 Redis Pub/Sub를 활용해보는 시간을 가져보았다.
MSA가 표준이 된 인프라와 백엔드에선 분산 처리나 메시징(이벤트) 처리가 핵심적인 구성 요소라고 생각하고, 이에 따른 복잡한 시나리오를 예상하고 적절하게 해결하거나 완화하는 것이 진정한 실력이지 않나 생각한다.
앞서 설명하였던 모든 소스코드와 관련된 내용은 아래의 레포지토리에서 확인해볼 수 있다.
Thank you for taking the time to read this.
