
0. 개요
눈, 비가 오더니 날씨가 갑자기 또 추워졌다. 이제 고등학생 신분으로서 보낼 수 있는 마지막 1년인데, 그 어느 때 보다 알차게 보내야하지 않을까 생각한다.
타 전공동아리/학교와 연합하여 CTF 대회를 운영을 위해 필자가 부장으로 활동하는 전공 동아리에서 자체적인 CTF 플랫폼을 개발하고 현재 테스트 중에 있다. (자세한 내용은 아래 포스팅을 참조하도록 하자.)
대회를 운영하면서 가장 중요한 요소는 모니터링, 로깅, 트레이스를 포함한 Observability가 아닐까 생각한다.
특히 이전에 운영해봤던 경험을 바탕으로 본다면 로깅이 필요 이상으로 중요한데, 전엔 이를 방심하여 운영에 차질이 있기도 하였다. (...)
AWS Native로 성능 모니터링 자체는 어렵지 않다. 단순히 AWS Console에서 CloudWatch Metrics를 확인하는 것만으로도 CPU/메모리 사용량, 네트워크/디스크 IO 등의 지표는 어느 정도 파악이 가능하다.
(해당 사진은 CloudWatch Metrics 참고용으로 첨부하였다. 포스팅 내용과는 무관하다.)
참가자들 중 일부는 CTF 서버에 대해 공격을 시도하는 경우가 존재한다. 이 경우 강하게 조치를 취하겠지만, 근본적으로 이러한 공격을 사전에 방어할 수 있도록 조치하는 것도 운영자들의 책임이지 않을까 생각한다.
1. 아이디어 고안
먼저 EKS Control Plane에 대한 CloudWatch 로깅은 자체적으로 기능을 지원한다.
(참고: https://docs.aws.amazon.com/ko_kr/eks/latest/userguide/control-plane-logs.html)
하지만 로깅 대상은 Control Plane이 아닌 백엔드 Pod(그 외의 마이크로서비스 포함)이기 때문에 이를 위한 별도의 솔루션이 필요하다.
Kubernetes에서 Pod/컨테이너 로그 수집은 일반적으로 Node에 배포된 DaemonSet 기반 로그 에이전트를 통해 이루어진다. 하지만 Fargate는 DaemonSet을 지원하지 않기 때문에 EC2 Node를 사용하는 경우와 동일한 방식의 로그 수집 구성을 사용할 수 없다.
만약 EKS Fargate Node를 사용하고 있다면 AWS에서의 자체적인 CloudWatch 로깅을 지원하지만, 필자의 상황에선 EC2 Node를 사용한다.
이때 Pod/컨테이너 로깅을 위한 솔루션은 크게 아래와 같다. 이에 대한 방법/솔루션은 많겠지만 그 무엇이던 정답은 없다.
하지만 이러한 인프라 아키텍처엔 Best Practice는 존재하며, 이에 대한 Best Practice 몇가지는 아래와 같다.
AWS Native 중심
- FluentBit + CloudWatch Logs
- OpenTelemetry Collector + CloudWatch Logs
ELK / OpenSearch / Grafana 중심
- Fluentd/FluentBit + ElasticSearch/OpenSearch, or Loki ...
- LogStash + ElasticSearch + Kibana (ELK)
- ...
물론 이 외에 조합 가능한 Loki, Datadog 등의 부가적인 요소들이 있지만, 운영하려는 서비스가 어떤 목적의 서비스인지, 규모는 어느정도 인지 등등 여러 요소를 고려해야 한다.
필자가 운영하고자 하는 CTF 플랫폼은 길어봤자 하루 정도 운영되는 서비스에, 지원되는 예산이 그리 많지 않기 때문에 강력한 Observability 구성을 갖추기엔 어려움이 있다. 애초에 그정도의 대규모 Observability 솔루션이 필요하지도 않다.
또한 필자는 최대한 AWS Native로 운영하고 싶었고, OTel과 같이 복잡한 구성은 단기간 CTF 운영에 있어 과도한 운영 오버헤드라고 생각하였다. 때문에 필자는 FluentBit + CloudWatch 조합을 도입하기로 하였다.
AWS Native의 Observability에서 자주 언급되는 CloudWatch Agent는 AWS에서 제작한 모니터링 Agent로, 로그 수집도 지원하지만 메트릭 수집에 최적화가 되어있다.
EKS Kubernetes 환경의 Pod/컨테이너 로그 수집에는 컨테이너 환경에 특화된 기능을 제공하는 FluentBit가 일반적으로 사용되며 권장된다. 자세한 내용은 아래에서 다루겠다.
2. Fluentd와 FluentBit
2-1. Unified Logging Layer의 필요성
작은 모놀리식 아키텍처에선 로깅에 대해 큰 문제가 없다. 단일 애플리케이션에서 파일로 로그를 남기고, Log Rotation 등을 애플리케이션에서 구현하거나 별도의 도구로 관리한다면 로그 관리에 큰 어려움이 없었을 것이다.

하지만 인프라가 커지고 MSA와 Stateless한 컨테이너화된 애플리케이션, 분산된 환경에선 파일로 남는 로그는 관리하는 것이 매우 어렵다.
로그 포맷도 제각각이고 로그 수집 경로(Upstream), 로그를 사용할 최종 목적지(Downstream)도 모두 제각각이기 때문에 이를 중간에서 로그 스트림을 통합된 방식으로 받아 가공하고 Downstream으로 내보내는 계층이 필요하게 되었다.
(이를 아래의 Fluentd에선 Unified Logging Layer라고 명칭한다.)
Fluentd는 이러한 문제를 해결하기 위한 도구 중 하나로, 이러한 도구 중엔 그 유명한 ELK 스택의 Logstash가 있기도 하다. (Logstash는 너무 무거운 관계로 도입하지 않았으며, 프로젝트가 그 정도의 규모도 아니다.)
Fluentd는 노드에 설치된 Fluentd Agent에서 Downstream으로 Direct로 보내는 Direct shipping 방식과 Fluentd Aggregator 서버를 두는 방식으로 운영할 수 있다.
이 포스팅에선 Fluentd의 세부적인 사용법을 서술하거나 이론적으로 Deep dive 하지 않는다.
또한 이 파트에선 후술할 FluentBit를 설명하기 앞서 이론적인 내용만 다루겠다.
2-2. Fluentd (Direct shipping)
Fluentd는 Input, Filtering, Output을 포함한 여러 Phase를 유연하고도 다룰 수 있고, 여러 플러그인을 통해 Downstream 백엔드로 필터링/가공된 로그를 Forward 할 수 있도록 설계되었다.
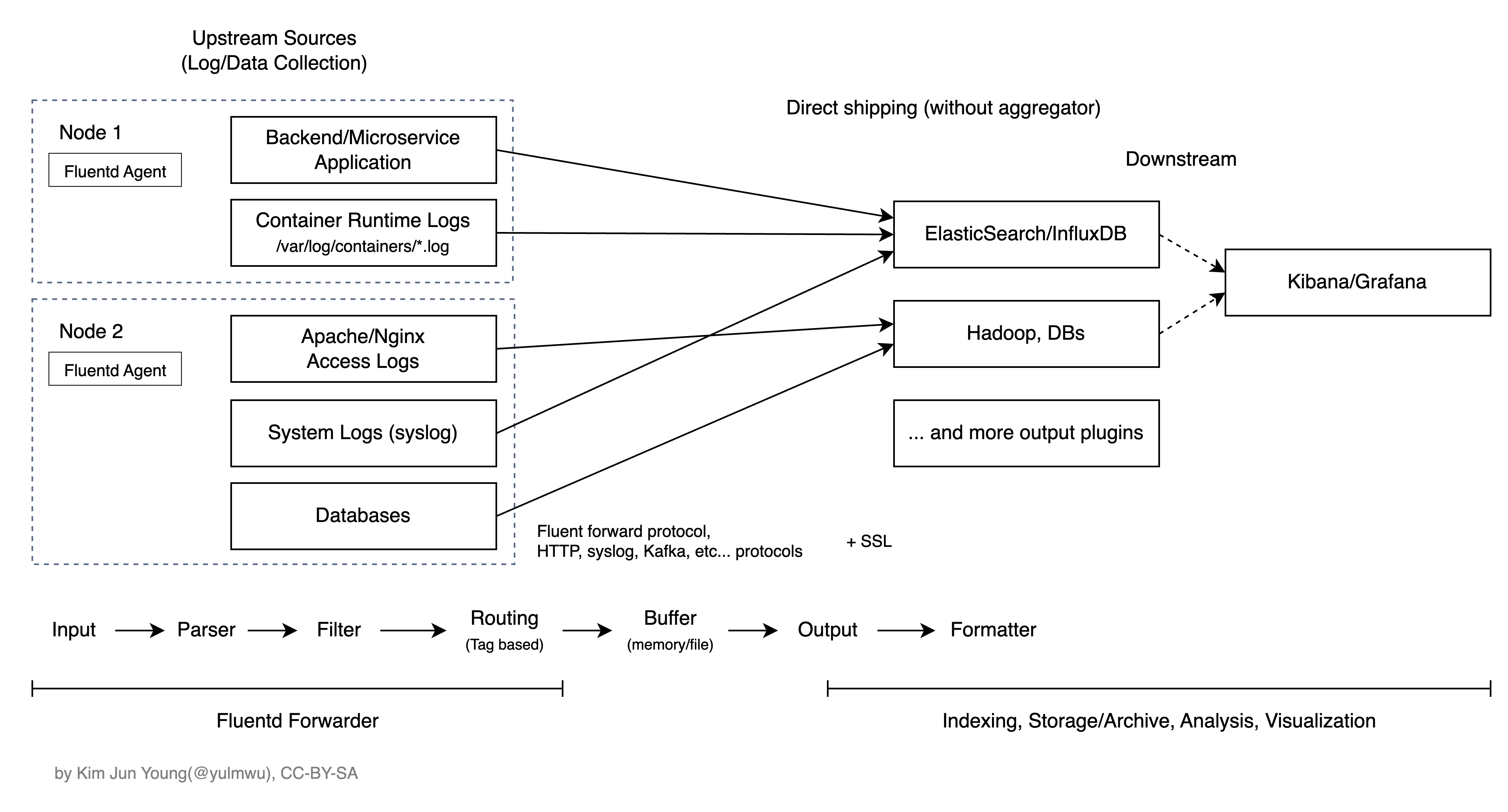
로그를 어느 Source에서 읽을지, 어떻게 필터링하고 어떤 태그를 붙여 어느 백엔드 Downstream으로 내보낼지 등을 세부적으로 지정할 수 있으며, Buffer도 단순한 Queue 수준이 아니라 Chunk 단위로 Flush 조건이나 Retry 정책 등을 세부적으로 다룰 수 있다.
이때의 Downstream 백엔드는 ElasticSearch, InfluxDB, Hadoop이나 AWS S3 아카이빙, AWS CloudWatch Logs와 같은 많은 Downstream 백엔드를 플러그인으로 제공한다.
ELK 스택에서 Logstash 대신 Fluentd 또는 FluentBit를 도입한 EFK(Elasticsearch, Fluentd, Kibana) 스택으로 구성하기도 한다.
Logstash가 비교적 무거운 JVM 위에서 동작하기 때문에 특히 Kubernetes와 같이 컨테이너 환경이나 리소스가 제한된 환경에선 EFK 스택을 이용하는 것도 좋은 방향이다.
Ouput 플러그인 뿐만 아니라 Kafka Topic으로 부터 메시지를 컨슈밍하여 수집하는 fluent-plugin-kafka와 같이 다양한 Input 플러그인이나 Filter 등의 여러 플러그인을 지원한다.
<source>
@type kafka
brokers kafka-broker:9092
topics my-topic
format json
</source>
<filter test.**>
@type grep
<exclude>
key action
pattern ^logout$
</exclude>
</filter>이와 같이 Fluentd는 크게 본다면 Input, Filter/Buffer, Output 순으로 Phase를 거치며 각 Phase엔 그에 맞는 플러그인이 상당수 존재한다.
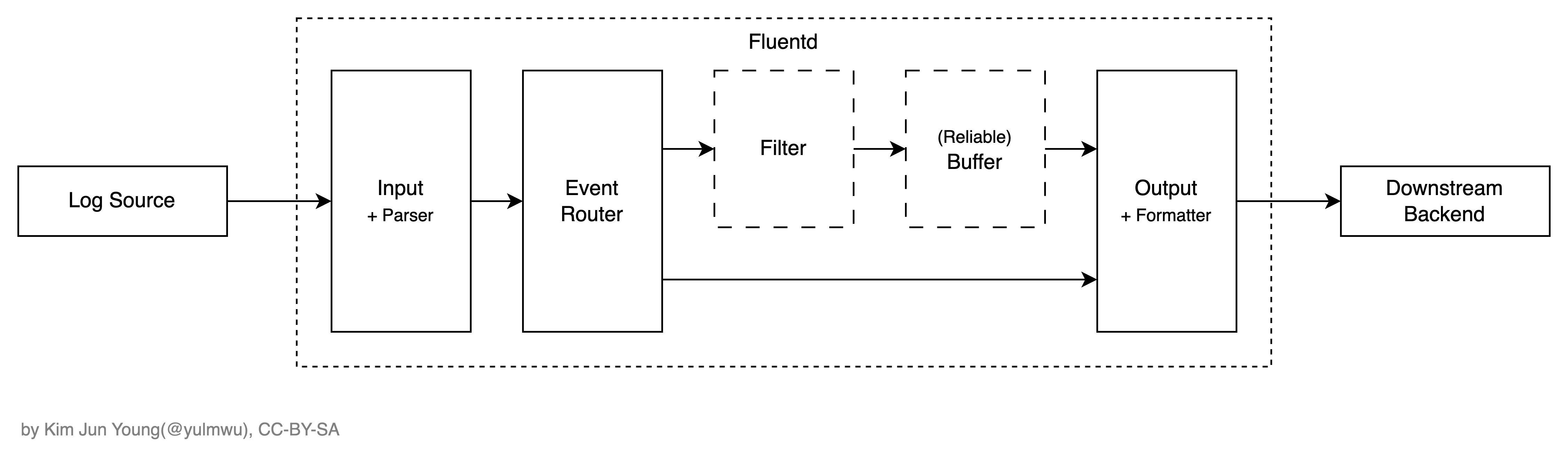
이때 Filter와 Buffer는 필수가 아니며, 필요에 따라 필터링 또는 버퍼링 없이 Output으로 넘길 수 있다.
Fluentd의 이벤트, 즉 로그는 아래와 같이 Time, Tag, Record 구조를 가지며 Tag는 보통 Input Plugin에 의해 만들어진다. (아래의 예시는 Parsing 직후의 Nginx Access Log를 나타낸다. 후술할 Kubernetes 환경의 경우 보통 kubernetes.var.log.containers.nginx 형태로 저장된다.)
{
"tag": "nginx.access",
"time": "2026-03-07T19:30:00+09:00",
"record": {
"remote_addr": "192.168.1.5",
"method": "GET",
"path": "/index.html",
"status": 200,
"size": 1024
}
}또한 Fluentd Core Engine엔 라우팅 기능도 포함되어 있는데, 이는 이 Tag를 기반으로 동작하며 이에 따라 정해진 파이프라인으로 처리된다. 이 포스팅은 Fluentd에 대한 자세한 내용을 다루는 것은 아니니 별도의 문서나 자료를 찾아보길 바란다.
필자가 다이어그램에 Reliable Buffer 라고 명칭하였는데, Fluentd에서 Buffer는 단순한 Queue에 배치로 처리되는 일반적인 Buffer와 달리 Backpressure를 방지하기 위한 Buffer와 자동으로 Retry를 수행하는 메커니즘을 가지고있다. (At-Least-Once Delivery)
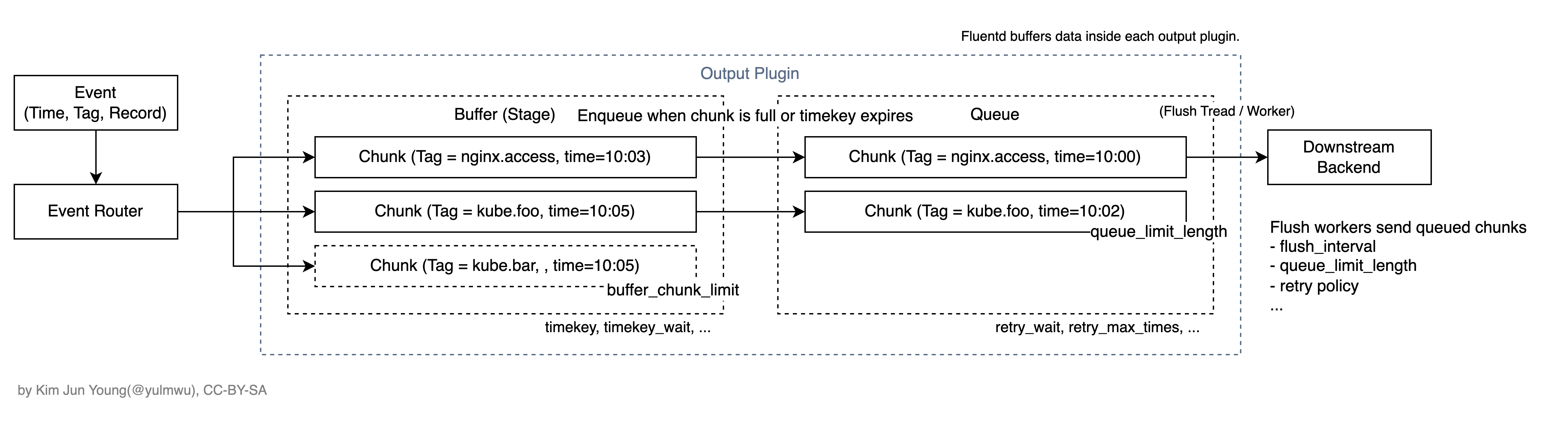
이때 Flush 메커니즘은 Chunk 사이즈(buffer_chunk_limit)에 도달하였거나 Flush Interval(flush_interval)에 도달하였을 경우로, 이는 Kafka Producer의 batch.size나 linger.ms로 비유할 수 있다. (어디까지나 '비유'이고, 두 기능이 같다는 것은 아니다.)
Fluentd의 Buffer는 내부적으로 Tag를 기반으로 Chunk 단위로 쪼개어 관리한다. Buffer는 이 Chunk들을 저장하고 관리한다.
Chunk는 append, queued, flushing, committed 상태를 가지며 각각의 상태는 이벤트를 계속 받을 수 있는 상태, Flush 조건이 만족된 상태, Chunk를 Queue로 전송하는 상태, 그리고 마지막으로 전송이 완료되어 삭제를 기다리는 상태로 나뉜다.
<match kube.**>
@type elasticsearch
host elasticsearch.logging.svc
port 9200
logstash_format true
<buffer>
@type file
path /var/log/fluentd-buffer/es
chunk_limit_size 8m
flush_interval 5s
</buffer>
</match>Buffer는 Output 플러그인 내에 포함되며 적절한 Backpressure 대처와 Retry 정책 등을 백엔드 Downstream 별로 설정할 수 있다.
사실 필자가 이에 대해 장황하게 설명하려고 하였으나, 이 글의 취지와 범위가 맞지 않다고 판단하여 할많하않을 시전하겠다. 잘 작성된 자료를 첨부하겠다.
2-3. Fluentd - Fluentd Aggregator
지금까지 살펴본 아키텍처는 각 노드에서 Fluentd Agent를 통해 Downstream으로 처리되는 구조였다.
하지만 현대의 아키텍처는 애플리케이션의 분산 뿐만 아니라 그 애플리케이션이 실행되는 노드까지 분산하여 스케일링하기 때문에 노드가 추가됨에 따라 Agent를 다시 구성해야 하고, 각 Agent에서 프로세싱 파이프라인을 돌릴 경우 이에 따른 리소스 소모가 발생한다.
이러한 운영 오버헤드 외에도 여러 Upstream 소스와 Downstream 백엔드, 그리고 다양한 Routing 및 파이프라인이 있을 경우 매우 복잡해질 수 있다.
이러한 문제를 개선하기 위해 Fluentd Aggregator 중앙 집중식 서버를 구축할 수 있고, 이 서버에서 Fluentd Agent에서 사용하였던 파이프라인과 플러그인 모두 그대로 지원한
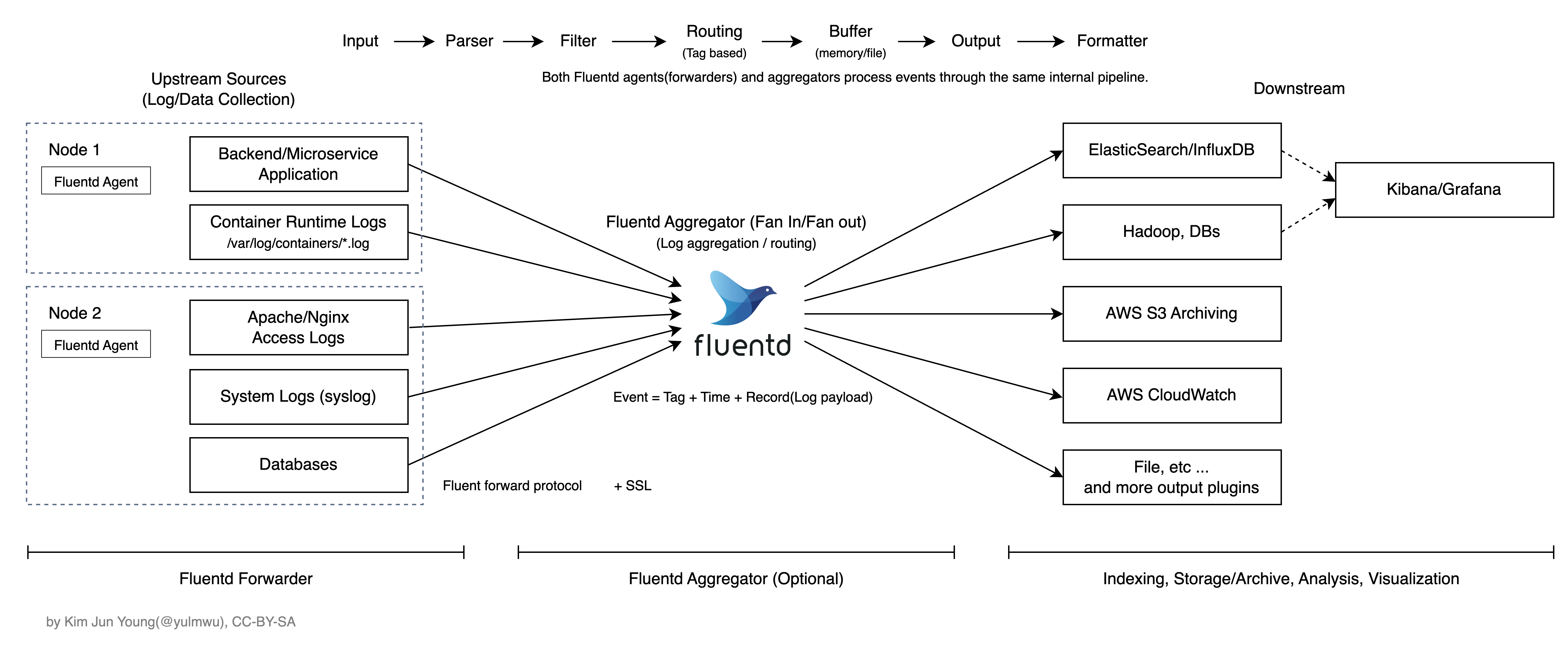
위 다이어그램과 같이 다양한 소스와 백엔드가 있고 복잡한 관계를 가진다면 Fluentd Aggregator 도입은 좋은 선택일 수 있다.
Forwarder Agent는 이 Aggregator 서버로 로그를 전송하고 중앙에 위치한 Aggregator에서 파이프라인 처리 후 Downstream으로 전송하는 것이다. (이때 Agent에서 Aggregator로의 데이터 전송은 Fluent Forward Protocol을 사용한다.)
<source>
@type forward
port 24224
bind 0.0.0.0
</source>사실 Forwarder Agent와 Aggregator는 용도의 차이일뿐, 내부적으로 큰 차이는 없다. Forwarder Agent로 부터 받아온 로그를 Aggregator에서 위와 같이 업스트림 소스로써 사용하면 되기 때문이다.
2-4. Fluentd는 무겁다, 대신 FluentBit.
Fluentd은 매우 강력하고, 많은 플러그인을 지원하지만 그 대가로 리소스 소모가 꽤나 발생한다.
더군다나 Cloud Native와 Kubernetes와 같은 오케스트레이션 도구의 등장으로 노드의 리소스를 Vertical 하게 늘리는 것이 아닌 Horizontal, 즉 노드의 수를 늘리는 전략을 사용하며 노드마다 무거운 Forwarder Agent를 두기엔 어려움이 발생하였다.
경우에 따라 중앙 서버가 아닌 Edge 서버/장비나 임베디드 시스템에도 도입해야할 경우 Ruby로 작성된 Fluentd Agent를 구동하기엔 무거울 수 있다.

이러한 이유로 플러그인과 생태계가 매우 풍부한 Fluentd를 중앙 Aggregator 서버로 두고, 각 노드에 배치되는 로그 수집 및 Downstream Forwarding Agent를 Fluentd가 아닌 더 가벼운 FluentBit를 사용하도록 하는 것이 Best Practice이다.
Fluentd가 중앙 Aggregator, 유연성 및 플러그인 확장성을 위해 설계되었다면 FluentBit는 더 적은 Footprint, 즉 경량화와 Edge Collector, 효율성 중심으로 설계됐다고 말할 수 있다.
FluentBit는 기존 Ruby로 작성된 Fluentd와 다르게 C로 작성되었으며, 때문에 단일 바이너리 파일로 배포되며 의존성이 거의 없지만 Fluentd와 비교하였을때 지원하지 않은 플러그인이 있거나 더 작은 생태계를 가지고 있다.
하지만 앞서 언급하였듯 둘의 구조적 철학 자체가 다르고, Fluentd를 Aggregator 서버로, FluentBit를 경략 로그 수집/Forwarder Agent로 사용하는 것이 적합한 상호보완 관계이다.
- Fluentd - Unified Logging Layer(Aggregator)
- FluentBit - Lightweight Edge Collector/Forwarder Agent
FluentBit도 Fluentd 및 CNCF 산하의 프로젝트이며, 자세한 내용은 FluentBit 문서를 참조하면 좋을 것이다. 앞서 언급한 내용이 모두 소개되어있다.
2-5. K8s/EKS 환경에서의 FluentBit와 CloudWatch Logs Output
FluentBit가 각광받는 이유는 Kubernetes 환경에서 매우 현실적으로 작용할 수 있다는 점이 아닐까 싶다.
Pod는 수시로 생성되고 사라지며 노드의 수가 매우 많아지고, 각 노드에서 /var/log/containers/*.log와 같은 컨테이너 로그를 Tailing하여 로그를 수집해야 한다. 이 작업은 노드 입장에서 보면 CPU/메모리를 조금이라도 덜 먹는 것이 중요할 것이다.
이는 Fast and Lightweight를 모토로 하는 FluentBit와 적합하며, 각 노드에 FluentBit DaemonSet을 배포하고 컨테이너 로그(CRI 로깅 포맷이 따로 존재한다.)를 수집하고 적절하게 Forwarding 하도록 구성하면 된다.
필자는 아키텍처에서 FluentBit 및 Downstream 백엔드를 CloudWatch Logs로 사용하기로 결정하였는데, 별도의 애플리케이션을 운영할 필요 없이 IRSA만 간단하게 구성해주면 쉽게 로그를 확인할 수 있을 뿐만 아니라 Live Tail, CloudWatch Logs Insights와 같이 고급 기능을 활용할 수도 있다.
필요시 Forwarding Backend를 S3 Bucket으로 구성하거나 CloudWatch Logs를 S3 Bucket으로 Export하여 아카이빙 할 수도 있을 것이다.
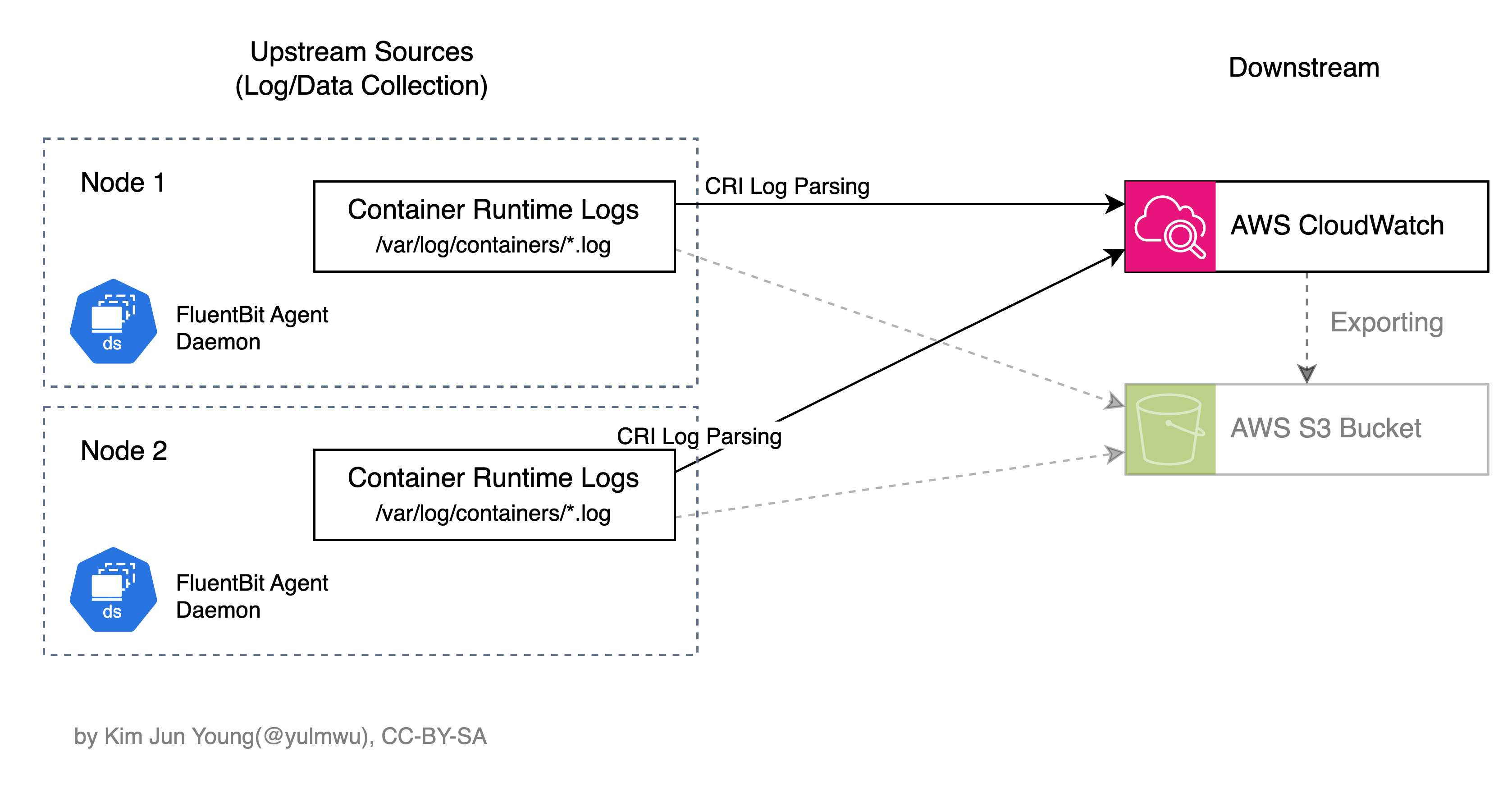
3. FluentBit 도입하기
Kubernetes에서 이러한 용도로 FluentBit를 설치하려고 하는 경우엔 크게 직접 DaemonSet을 배포하는 방식과 FluentBit Operator를 설치하는 방식이 있다.
둘 모두 같은 FluentBit Agent지만, 후자는 FluentBit, FluentBitInput, FluentBitFilter, FluentBitOutput와 같은 CR을 사용하여 Operator가 자동으로 Config 및 DaemonSet을 생성한다.
이러한 방식은 리소스 분리가 쉽고 Operator가 Reconcile 해주기 때문에 Kubernetes 철학과 GitOps에 더 유리하지만, 필자는 간단하게 배포가 가능한 DaemonSet으로 직접 배포하는 방식을 선택하였다.
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluent-bit-cloudwatch
namespace: logging
spec:
selector:
matchLabels:
app: fluent-bit-cloudwatch
template:
metadata:
labels:
app: fluent-bit-cloudwatch
spec:
serviceAccountName: fluent-bit-cloudwatch
terminationGracePeriodSeconds: 30
containers:
- name: fluent-bit
image: amazon/aws-for-fluent-bit:3.2.2
imagePullPolicy: IfNotPresent
env:
- name: AWS_REGION
value: "ap-northeast-2"
- name: LOG_GROUP_NAME
value: "/aws/eks/smctf-dev/logs"
- name: LOG_STREAM_PREFIX
value: "k8s"
resources:
limits:
cpu: 200m
memory: 200Mi
requests:
cpu: 50m
memory: 100Mi
volumeMounts:
- name: varlog
mountPath: /var/log
readOnly: true
- name: fluentbit-pos
mountPath: /var/log/fluent-bit
- name: fluentbit-config
mountPath: /fluent-bit/etc/fluent-bit.conf
subPath: fluent-bit.conf
- name: fluentbit-config
mountPath: /fluent-bit/etc/parsers.conf
subPath: parsers.conf
volumes:
- name: varlog
hostPath:
path: /var/log
type: DirectoryOrCreate
- name: fluentbit-pos
hostPath:
path: /var/log/fluent-bit
type: DirectoryOrCreate
- name: fluentbit-config
configMap:
name: fluent-bit-config이때 마운팅되는 볼륨은 /var/log를 비롯한 FluentBit 설정 파일(fluentbit-config), Tailing 시 마지막 위치를 기록하기 위한 fluentbit-pos 등을 마운팅한다.
이로 인해 HostPath 접근이 필수적으로 요구되므로 관련 컴플라이언스가 있을 경우 제한될 수 있다. 이 경우 OpenTelemetry Collector나 stdout/stderr 기반 로그 수집 등의 솔루션을 고려해볼 수 있다.
Kubernetes API Server에서 직접 수집하거나 Sidecar로 배포하여 수집할 수도 있겠지만 이는 효율적이지 못한 편이다.
amazon/aws-for-fluent-bit:3.2.2는 AWS CloudWatch Logs로 전송하기 위한 cloudwatch_logs Plugin을 포함하는 이미지이다. 블로그를 작성하는 현 시점 FluentBit의 최신 버전은 4.2지만, 해당 이미지는 현 시점 3.x 버전 밖에 지원하지 않으니 참고하자.
필자가 판단하기에 3.x 버전으로도 충분한 기능을 사용할 수 있으므로 그대로 사용하였다.
3-1. FluentBit Config
위 DaemonSet Spec에서 사용된 ConfigMap의 구성은 아래와 같다. 전체적인 ConfigMap과 SA/ClusterRole 등을 확인하려면 아래의 레포지토리를 참조하자.
Parser
# parsers.conf
[PARSER]
Name cri
Format regex
Regex ^(?<time>[^ ]+) (?<stream>stdout|stderr) (?<logtag>P|F) (?<log>.*)$
Time_Key time
Time_Format %Y-%m-%dT%H:%M:%S.%L%zKubernetes Containerd에서 사용되는 CRI(Container Runtime Interface) 로그 형태는 아래와 같고, 이를 해석하기 위한 Regex를 포함한다. (P는 Partial, F는 Full로 완전한 로그 행인지를 나타낸다.)
2026-03-08T01:12:45.123456789+00:00 stdout F Hello, World!CRI 로그 Parser는 기본적으로 내장되어 있지만, 포스팅에서 소개를 위해 작성하였다. 멀티라인을 포함한 내장 Parser는 아래의 문서에서 확인할 수 있다.
Service
# fluent-bit.conf
[SERVICE]
Flush 1
Daemon Off
Log_Level info
Parsers_File parsers.confService는 FluentBit의 전체적인 프로세스 동작을 구성하는 Block이다. Flush는 Buffer를 Output으로 Flush하는 Clock 주기로, Output Block 내에 명시되는 Buffer Interval과는 다르다. 이 구성에선 1초마다 Output Plugin을 실행한다.
Daemon 옵션은 FluentBit를 백그라운드 Daemon으로 실행할지 여부이다. Kubernetes에선 항상 Off로, PID 1 프로세스가 FluentBit여야 Pod Lifecycle이 정상적으로 동작하기 때문이다. Sidecar로 실행한다고 하더라도 PID 1인 Foreground로 올려야한다.
Input
[INPUT]
Name tail
Path /var/log/containers/*.log
Tag kube.*
Parser cri
Mem_Buf_Limit 10MB
Skip_Long_Lines On
DB /var/log/fluent-bit/fluent-bit-pos.dbInput Block에선 FluentBit가 어느 Upstream에서 로그를 수집할지, 어떻게 수집할지 등을 정의한다.
이 구성에선 File을 Tailing(tail)하여 새 로그가 Append 될때 자동으로 읽는다. 이때 마지막 위치 Offset을 저장하기 위해 별도의 경량 DB를 사용한다. (fluent-bit-pos.db)
Kubernetes 노드에서 모든 컨테이너 로그가 저장되는 위치는 /var/log/containers/*.log로, 아래와 같은 형식으로 지정된다.
/var/log/containers/nginx-abc123_default_nginx-123.log (Symlink)
/var/log/pods/<podUID>/<container>/0.logTag는 이후 Filter와 Output에서 매칭에 사용되는 값으로, kube.*로 지정해두었다면 *는 Placeholder와 같이 동작하여 아래와 같은 Tag가 생성된다.
/var/log/containers/nginx_default_nginx.log
-> kube.var.log.containers.nginx_default_nginx.log그 외의 옵션은 분량상 따로 설명하진 않겠지만, 궁금하다면 문서를 참조하길 바란다.
Filters
[FILTER]
Name kubernetes
Match kube.*
Kube_URL https://kubernetes.default.svc:443
Kube_Tag_Prefix kube.var.log.containers.
Merge_Log On
K8S-Logging.Parser On
K8S-Logging.Exclude On이는 앞서 Input에서 붙은 kube. 태그를 가진 로그에만 적용되는 Filter이다. 이후 Filter나 Output에서도 `Match kube.`를 사용하여 동일한 Pipeline 흐름을 처리할 수 있다.
Kube_Tag_Prefix는 Tag에서 Pod 정보를 추출하기 위한 Prefix로 만약 아래와 같은 로그 파일과 태그가 만들어졌다면,
/var/log/containers/nginx-abc_default_nginx-123.log
-> Tag : kube.var.log.containers.nginx-abc_default_nginx-123.log위 Tag에서 Pod, Namespace 및 Container를 추출하고 이를 바탕으로 Kubernetes API를 통해 메타데이터를 첨부한다. (이때 메타데이터를 캐싱하기 때문에 큰 부하가 발생하진 않는다.)
이 외의 옵션은 마찬가지로 직접 찾아보길 바란다.
[FILTER]
Name grep
Match kube.*
Regex kubernetes['namespace_name'] ^backend$앞서 Kubernetes Filter를 통해 해당 로그에 Pod의 Kubernetes 메타데이터가 추가된다. 이때 Backend Namespace만 통과되도록 구성하였다.
Output
[OUTPUT]
Name cloudwatch_logs
Match kube.*
region ${AWS_REGION}
log_group_name ${LOG_GROUP_NAME}
log_stream_prefix ${LOG_STREAM_PREFIX}
auto_create_group true마지막으로 Output은 kube.* 태그와 매칭되는 로그를 cloudwatch_logs Plugin을 통해 CloudWatch Logs로 전송한다. FluentBit 자체는 해당 Plugin을 포함하지 않지만, AWS에서 빌드한 amazon/aws-for-fluent-bit는 해당 Plugin을 기본적으로 포함한다.
${...}는 자동으로 환경 변수로 치환되며, 필자가 Helm Chart에 아래와 같이 포함하도록 하였다.
env:
AWS_REGION: "ap-northeast-2"
LOG_GROUP_NAME: "/aws/eks/smctf-dev/logs"
LOG_STREAM_PREFIX: "k8s"3-2. SA, Role 및 IRSA 구성
마지막으로 중요한 점이 빠져있는데, CloudWatch Logs에 접근하기 위해 IRSA 등의 IAM 권한을 요구한다. 필자는 IRSA를 구성하였기 때문에 아래와 같이 구성하였고, 추가적으로 Kubernetes API에 접근하여 메타데이터를 가져오기 위한 ClusterRole도 추가하여 Binding 하였다.
# Source: smctf-observability/templates/01-serviceaccounts.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluent-bit-cloudwatch
namespace: logging
annotations:
eks.amazonaws.com/role-arn: arn:aws:iam::<ACCOUNT_ID>:role/smctf-dev-irsa-fluentbit
labels:
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/instance: smctf-ob
---
# Source: smctf-observability/templates/11-fluentbit-rbac.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: fluent-bit-cloudwatch
rules:
- apiGroups: [""]
resources: ["pods", "namespaces"]
verbs: ["get", "list", "watch"]
---
# Source: smctf-observability/templates/11-fluentbit-rbac.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: fluent-bit-cloudwatch
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: fluent-bit-cloudwatch
subjects:
- kind: ServiceAccount
name: fluent-bit-cloudwatch
namespace: loggingIRSA에 대한 Terraform IaC는 아래의 레포지토리를 참조하면 좋을 것 같다.
4. 동작 확인
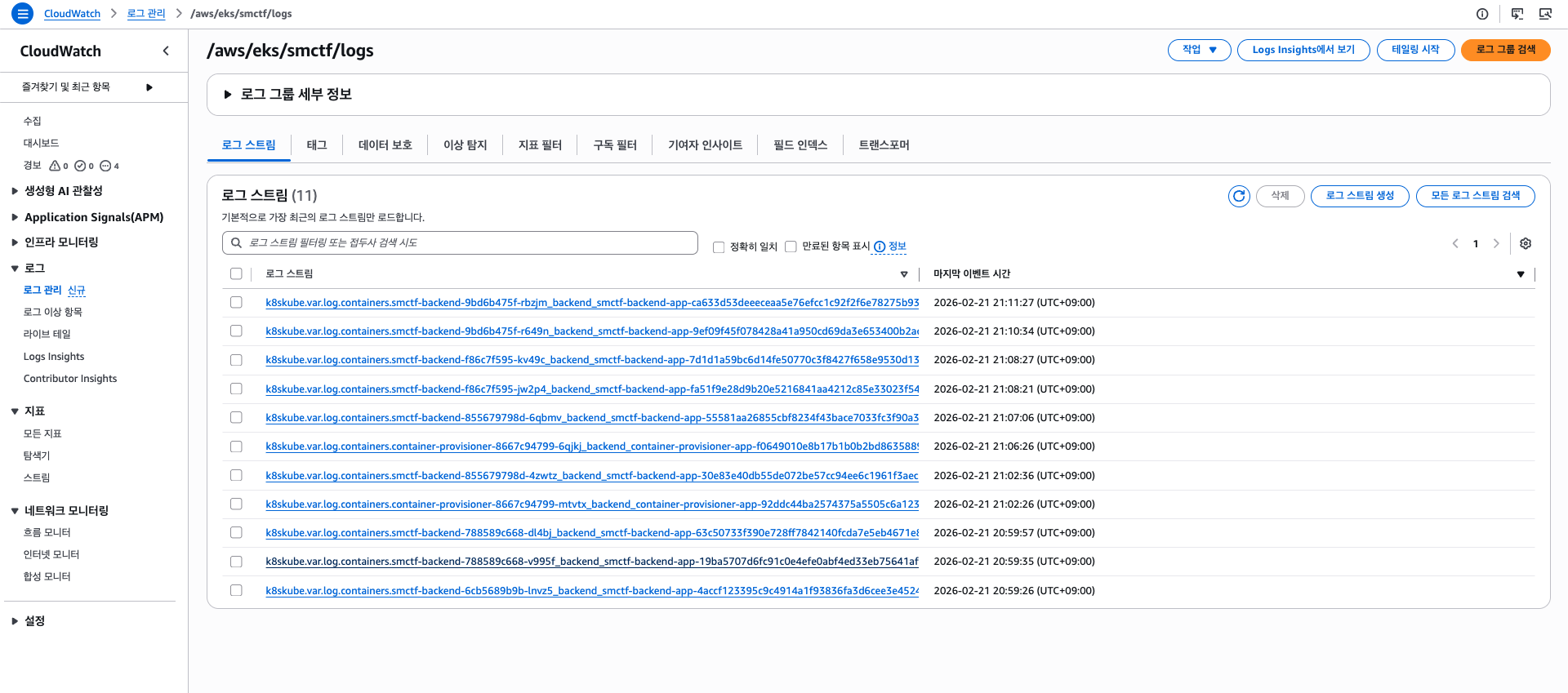
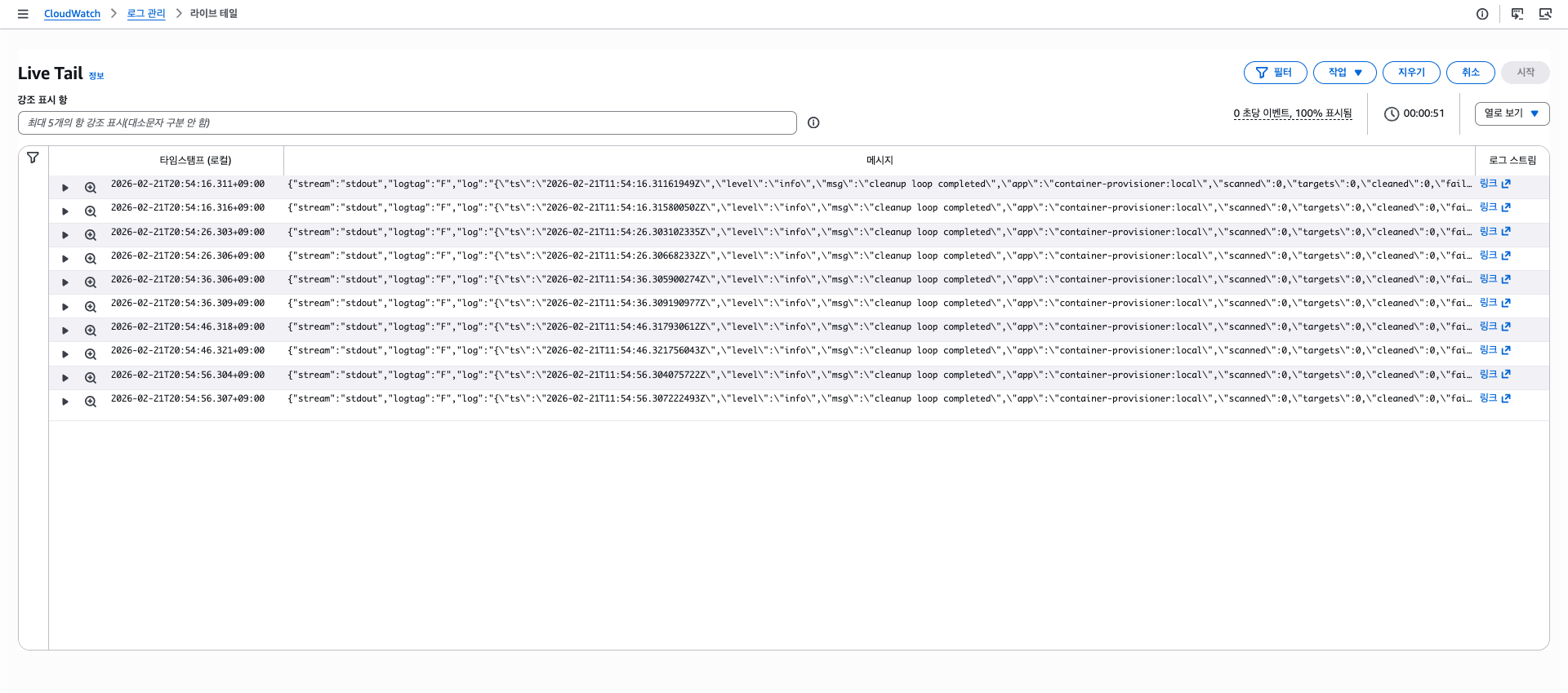
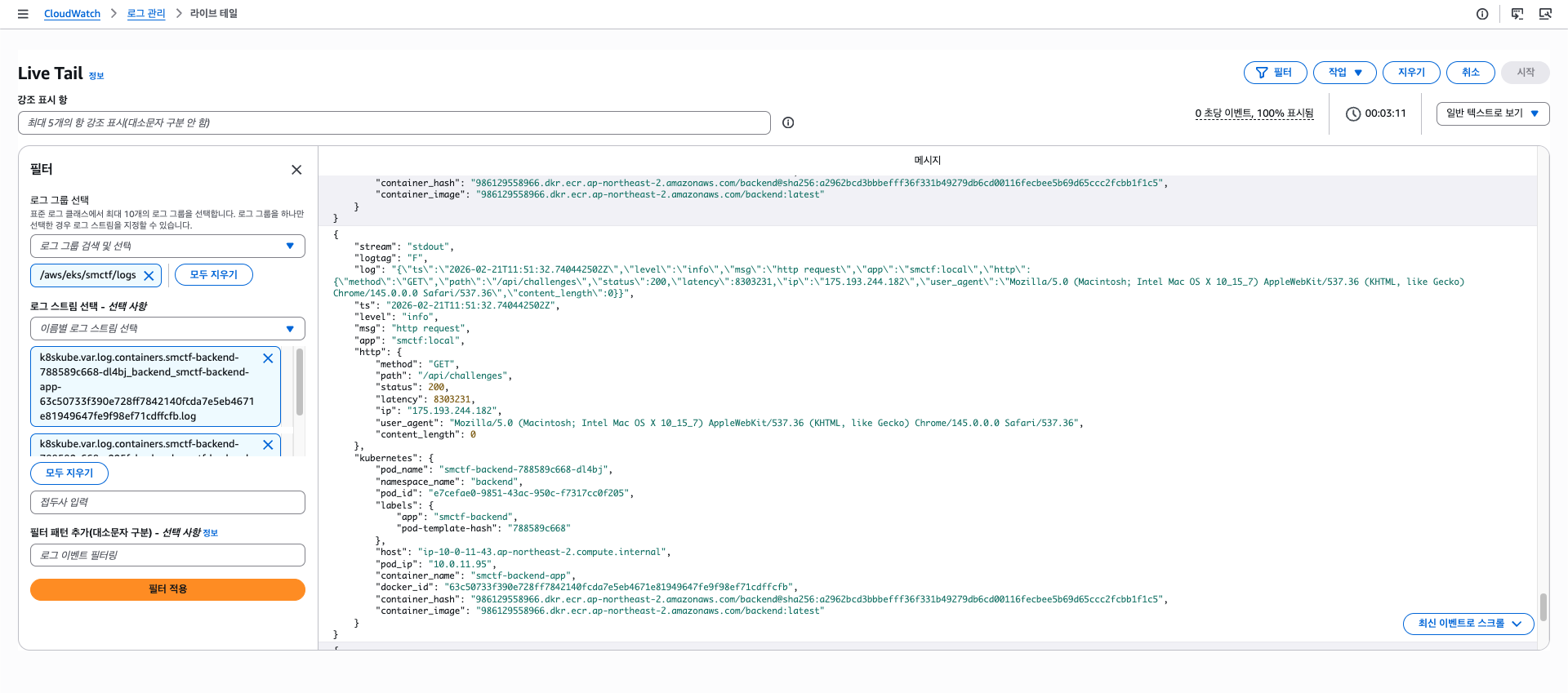
위와 같이 로그의 Raw 문자열과 파싱된 값, Kubernetes 메타데이터 등 세부적인 내용이 포함되어 기록되는 모습을 볼 수 있다.
