0. Overview
쿠버네티스의 장점이라 하면 컨테이너화된 애플리케이션에 대해 복잡한 운영을 쉽게 관리하고, 고가용성, 오토 힐링 및 효율적인 리소스 사용과 확장성 등의 장점이 있을 것이다.
개인적으론 그 중 확장성이 쿠버네티스의 큰 장점이라 생각하는데, 그 중 리소스를 필요에 따라 자동으로 조절하는 오토스케일링(Auto Scaling)이 대표적인 기능이라 볼 수 있다.
오토스케일링을 통해 필요한 자원 만큼만 사용하여 요금을 내는 클라우드 환경을 효율적으로 사용할 수 있고, 트래픽이 늘어나거나 줄어들었을 때 자동으로 조정되기 때문에 필수적인 기능이라 볼 수 있다.
쿠버네티스에선 크게 3가지 오토스케일링 기능이 있는데, 파드의 수를 수평적으로 오토스케일링하는 HPA(Horizontal Pod AutoScaler)과 파드의 CPU/메모리 리소스 요청과 제한을 수직적으로 오토스케일링하는 VPA(Vertical Pod AutoScaler)가 있다.
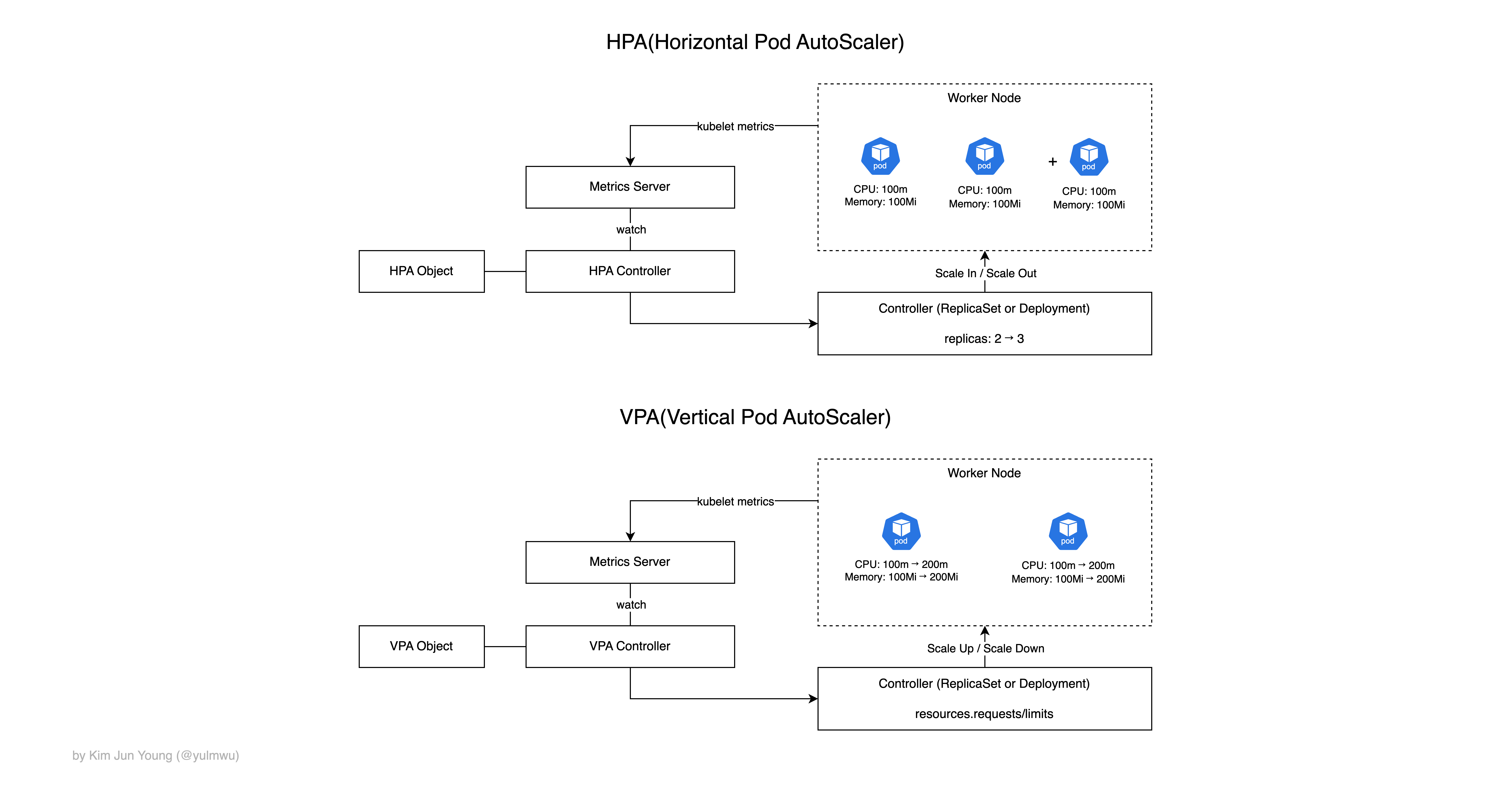
그리고 마지막으로 클러스터의 노드를 수평적으로 늘리거나 줄여 오토스케일링하는 CA(Cluster AutoScaler)가 있다. Cluster AutoScaler는 주로 클라우드 환경에서 많이 사용되며, 실제 서비스에선 주로 HPA + CA 조합으로 사용한다.
(노드의 수는 그대로인데 파드만 늘어나면 Pending 상태로 멈춰서 크게 의미가 없음)
이 포스팅에선 HPA(Horizontal Pod AutoScaler)만 다룬다.
VPA는 실제 서비스에선 사용 빈도가 상대적으로 낮은데, 크게 아래와 같은 이유가 있다.
- HPA와 충돌 가능성이 있음(HPA의 스케일 인/아웃 조건이 리소스 사용량을 바탕으로 하는데 VPA는 그 요청/제한 값을 조절함)
- VPA가 값을 조정하면 해당 파드는 재생성이 필요함. 때문에 무중단 서비스에선 부담이 될 수 있음
대신 VPA는 파드 사용량을 관찰하여 추천 값을 계산해주는데, 이렇게 계산만 하고 수동으로 업데이트하는 경우도 있다.
1. What is HPA(Horizontal Pod AutoScaler)?
앞서 설명하였듯 HPA는 파드의 수(spec.replicas)를 조정하는 수평적 오토스케일링 기능이라 설명하였다.
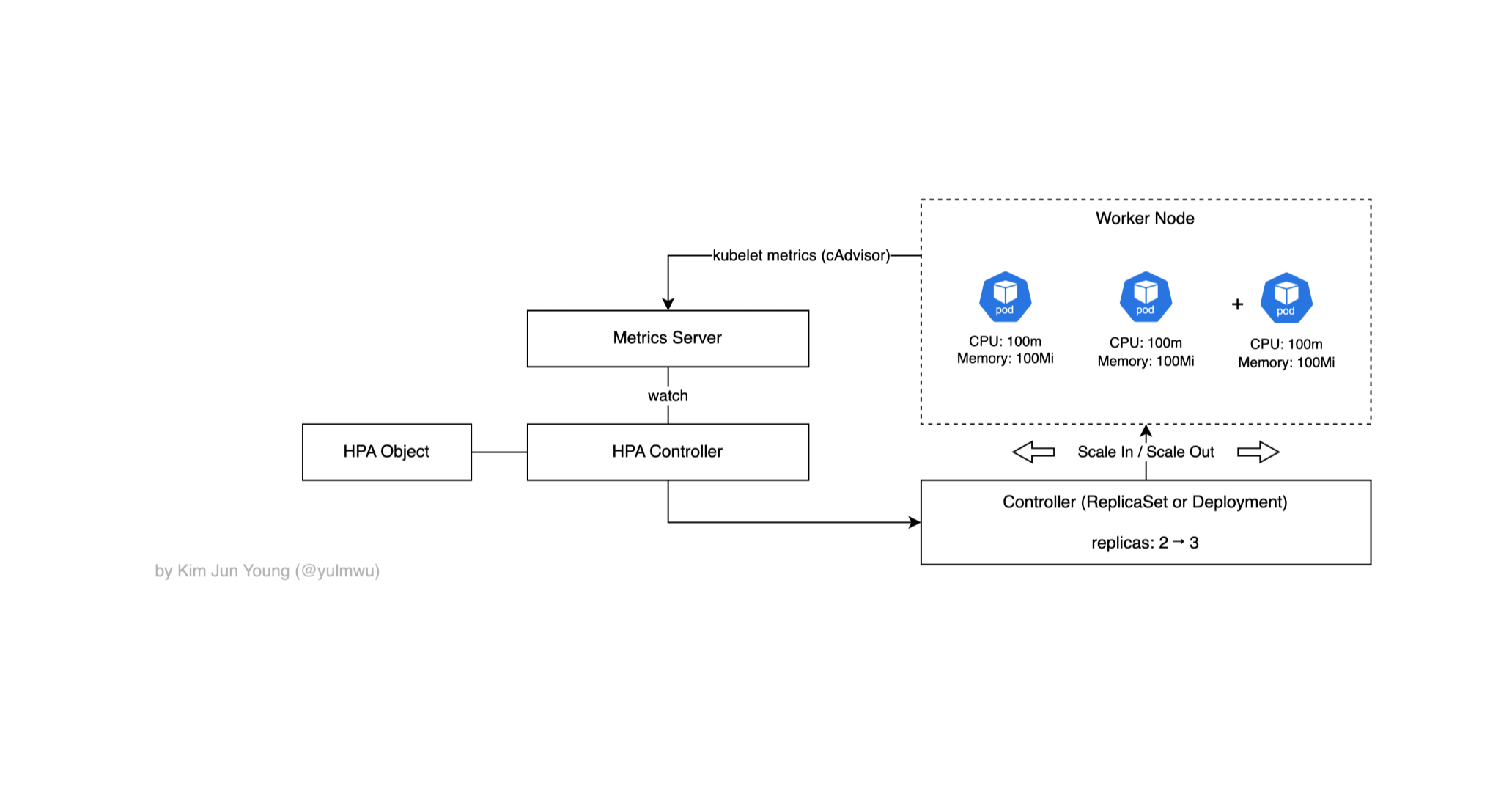
실습에 앞서 간단하게 동작 과정을 살펴보자. 일단 HPA는 오토스케일링 기준이나 관련 값을 지정하는 HorizontalPodAutoscaler 리소스(오브젝트)가 있고, 실질적인 오토스케일링은 HPA Controller가 담당한다.
HPA Controller는 Metrics Server에서 메트릭 값을 가져오는데, Metrics Server가 직접 노드의 메트릭을 수집하진 않는다.
워커 노드의 kubelet 내부적으로 존재하는 cAdvisor(Container Advisor)에서 메트릭을 수집하고, Metrics Server는 kubelet에서 가져온 데이터를 정리하여 metrics.k8s.io로 API를 노출한다.
이렇게 수집된 메트릭을 바탕으로 HPA Controller가 파드의 수를 줄이거나 늘린다. (스케일 인/스케일 아웃)
VPA도 동작 과정 자체는 비슷하다. 하지만 HPA와는 다르게 파드의 수를 조정하지 않고 파드의 리소스 요청/제한 값을 늘리는 것이다.
Metric Source Types
HPA에서 메트릭 타입을 지정할 수 있는데, 크게 Resource, Pods, Object, External로 설정할 수 있다.
Resource Metrics
말 그대로 파드의 리소스 사용량을 기준으로 하는데, 여기엔 CPU/메모리와 같은 기본적인 리소스를 말한다.
해당 메트릭의 소스(출처)는 kubelet(cAdvisor) → Metrics Server 이다. 리소스 메트릭 타겟에서 기준을 정할 때 Utilization과 AverageValue를 지정할 수 있다.
Utilization
먼저 Utilization은 각 파드가 요청한 리소스(requests) 대비 실제 사용률(%)을 기준으로 스케일링한다.
먼저 HPA에서 정의한 target.averageUtilization(%) 값과 파드들의 requests 평균 값을 곱하여 타겟 값을 정한다. 예를 들어 target.averageUtilization가 50%이고, 파드의 requests의 평균 값이 100이라면 타겟 값은 50이 된다.
이제 Metrics Server에서 수집된 지표의 평균으로 아래와 같이 계산된다.
예를 들어 파드들의 Metrics에 평균을 계산한 AverageMetrics가 200이 되었고 현재 2개의 파드가 있다고 가정하면
즉 총 8개의 파드가 필요하게 되고, 현재 2개의 파드가 존재하므로 6개의 파드가 추가적으로 만들어지게 된다.
AverageValue
Utilization은 HPA에 명시된 사용률 %(target.averageUtilization)와 파드들의 requests 평균 값을 통해 타겟 값을 설정하였다면, AverageValue는 그 목표하는 타겟 값을 직접 명시한다. (target.averageValue)
예를 들어 아까의 상황에서 target.averageValue를 50으로 설정한다면
위 식이 바로 계산되어 오토스케일링 하는 것이다. 때문에 Utilization은 파드에 requests가 명시가 되어 있어야 타겟 값을 구할 수 있지만, AverageValue는 측정된 평균값(AverageMetrics)을 바탕으로 계산되기 때문이다.
갑자기 수학이 나와 당혹스러울 수 있지만 해당 실습에선 Utilization 타입을 사용해볼 예정이고, 자세한 내용은 포함하지 않고 오토스케일링이 잘 되는지 확인해볼 것이다.
Pods, Object, External Metrics
각각 아래와 같은 기능을 바탕으로 판단한다.
- Pods Metrics: 파드에서 따로 제공되는 지표로, Prometheus Adapter나 CloudWatch Adapter 등에서 제공하는 Custom Metrics API에서 수집한다. 타겟의 타입은 파드 별 측정 값을 평균으로 한
AverageValue만 사용된다. - Object Metrics: 특정 쿠버네티스 오브젝트(서비스, Ingress 등)에서 제공하는 지표를 기준으로 한다.
- External Metrics: 클러스터 외부 시스템 등에서 제공하는 지표로, 메시지 브로커의 메시지 수 등의 지표를 기준으로 한다.
해당 Metrics는 Metrics Server에서 수집하는 것이 아닌 Custom Metrics API에서 수집된다.
앞서 말했듯 해당 포스팅에선 위와 같은 기능은 다루지 않고, Resource Metrics만 다뤄보겠다.
2. HPA Example
(1) EKS Cluster
실습은 AWS EKS를 통해 진행하겠다. 아래의 Cluster Config를 작성하여 클러스터와 노드를 만들어주자.
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: eks-test
region: ap-northeast-2
version: "1.33"
vpc:
cidr: 10.0.0.0/16
managedNodeGroups:
- name: ng-public
instanceTypes: ["t3.small"]
desiredCapacity: 1
minSize: 1
maxSize: 1
privateNetworking: false
labels: { nodegroup: public }eksctl create cluster -f cluster-config.yml
aws eks update-kubeconfig --name eks-test --region ap-northeast-2클러스터를 만들면 Metrics Server 애드온이 설치될 것이다. 만약 설치되어 있지 않다면 아래의 명령어를 통해 Metrics Server를 설치하자.
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml이미 설치되어 있는 상태에서 실행하면 꼬일 수 있으니 kubectl top node 등의 명령어로 Available 한지 확인해보자.
(2) Deployment
그리고 테스트해볼 Deployment와 서비스(ClusterIP 또는 NodePort)를 만들어주겠다.
# testapp-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: hpa-test
spec:
replicas: 1
selector:
matchLabels:
app: hpa-test
template:
metadata:
labels:
app: hpa-test
spec:
containers:
- name: app
image: rlawnsdud/testapp:latest
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
env:
- name: PORT
value: "80"
- name: APP_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
resources:
requests:
cpu: "100m"
memory: "128Mi"
limits:
cpu: "500m"
memory: "256Mi"
readinessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 2
periodSeconds: 5
livenessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 10
periodSeconds: 10여기서 spec.containers.resources를 보면 CPU/메모리 요청 값은 각각 100m, 128Mi로 설정해두었다. readinessProbe와 livenessProbe는 Health Check를 하기 위해 적어두었고, 당장은 없어도 된다.
그리고 NodePort 또는 ClusterIP 타입의 서비스를 만들자.
# testapp-service.yaml
apiVersion: v1
kind: Service
metadata:
name: hpa-test
spec:
selector:
app: hpa-test
ports:
- name: http
port: 80
targetPort: 80
type: NodePort
잘 만들어졌다. 이제 HPA를 만들고 파드에 부하를 줘서 오토스케일링이 잘 되는지 확인해보겠다.
(3) HPA
# testapp-hpa.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: hpa-test
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: hpa-test
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
# - type: Resource
# resource:
# name: memory
# target:
# type: AverageValue
# averageValue: "200Mi"
behavior:
scaleUp:
stabilizationWindowSeconds: 0
policies:
- type: Percent
value: 100
periodSeconds: 60
- type: Pods
value: 4
periodSeconds: 60
selectPolicy: Max
scaleDown:
stabilizationWindowSeconds: 60
policies:
- type: Percent
value: 50
periodSeconds: 60
selectPolicy: MaxMetrics 타입은 Resource, 타겟 타입은 Utilization로 해두었고 50%를 넘었을 때 오토스케일링 되게 해두었다.
그리고 behavior는 오토스케일링에서 어떻게 동작하는지 선언할 수 있는데, 예를 들어 분당 파드의 몇 % 까지 스케일 아웃이 될 수 있는지, 분당 몇 % 까지 스케일 인이 될 수 있는지 등을 선언한다. (스케일 정책)
(scaleUp, scaleDown 이라는 네이밍을 사용했지만 다른 의미이다.)
적용해보고 kubectl get hpa 명령어를 통해 잘 작동하는지 확인해보자.

(4) HPA Testing
이제 파드에 부하를 주면서 CPU 사용률을 올려야 하는데, 간단하게 alpine에서 stress-ng라는 패키지를 통해 CPU 부하를 줘보겠다.
kubectl exec -it hpa-test-85b9f8ffbf-zpd2j -- sh
# alpine
apk add --no-cache stress-ng아래와 같은 명령어를 통해 CPU 부하를 줄 수 있다.
stress-ng --cpu 1 --cpu-load 40 --timeout 60s우리는 CPU 최대 값을 500m으로 설정하였는데, 그럼 --cpu-load 40로 점유율 40%를 차지하게 되면 실질적으로 약 200m의 리소스를 차지하게 된다.
HPA Utilization에선 100m(requests)의 50%, 즉 50m을 넘었을 때 오토스케일링이 되도록 하였으므로 이론상 아래의 계산식을 통해 총 4개의 파드가 만들어져야 한다.
직접 확인해보자. 만들어둔 파드에 exec로 접속하여 stress-ng로 부하를 주자.

그리고 watch -n 1 ... 명령어를 통해 파드와 HPA를 모니터링해보자.

이런식으로 스케일 아웃이 잘 되는 것을 볼 수 있다. 그런데 예상한건 4개의 파드가 존재해야 하지만, 실제론 5+α개의 파드가 만들어진걸 볼 수 있다.
stress-ng 명령어를 실행할 때 발생하는 부하와 여러 요소를 고려하지 않았기 때문인데, 완벽하게 계산하긴 힘드니 일단은 "오토스케일링이 잘 된다" 정도로 이해하면 좋을 것 같다.
그리고 시간이 지나면 아래와 같이 스케일 인이 되면서 파드가 다시 1개로 유지되는 것을 볼 수 있다.

이상으로 HPA에 대해 간단히 알아보았다. 추후 VPA나 CA(Cluster AutoScaler)에 대해서도 다뤄보도록 하겠다.
끝.
