0. Overview
Kubernetes에서 전통적으로 파드 오토스케일링을 위해 VPA 또는 HPA를 사용한다. 하지만 이는 CPU 점유율이나 메모리 사용량과 같은 Pod 내부의 리소스 메트릭을 기반으로 스케일링된다.
하지만 MSA이나 Event Driven 아키텍처에서는 Kafka(Lag 메트릭), RabbitMQ, Redis Stream, AWS SQS나 백로그 DB 등의 큐의 적체량과 같이 메시지나 이벤트 큐 기반으로 부하가 결정되는 경우가 대부분이다.
이러한 메트릭을 기반으로 오토스케일링을 구현하려면 Prometheus Adapter나 직접 Metrics API를 구축해야 한다. 하지만 이를 직접 구축하기엔 복잡하고, Prometheus Adapter를 사용하는 것 또한 쉽지 않다.
1. What is KEDA ?
이러한 문제를 쉽게 해결하기 위해 KEDA(Kubernetes Event-driven Autoscaling)를 사용해볼 수 있다. KEDA는 앞서 언급한 다양한 이벤트 소스에서 직접 메트릭을 수집하고, 이를 External Metric 형태로 만들어 이를 바탕으로 HPA가 동작할 수 있도록 한다.
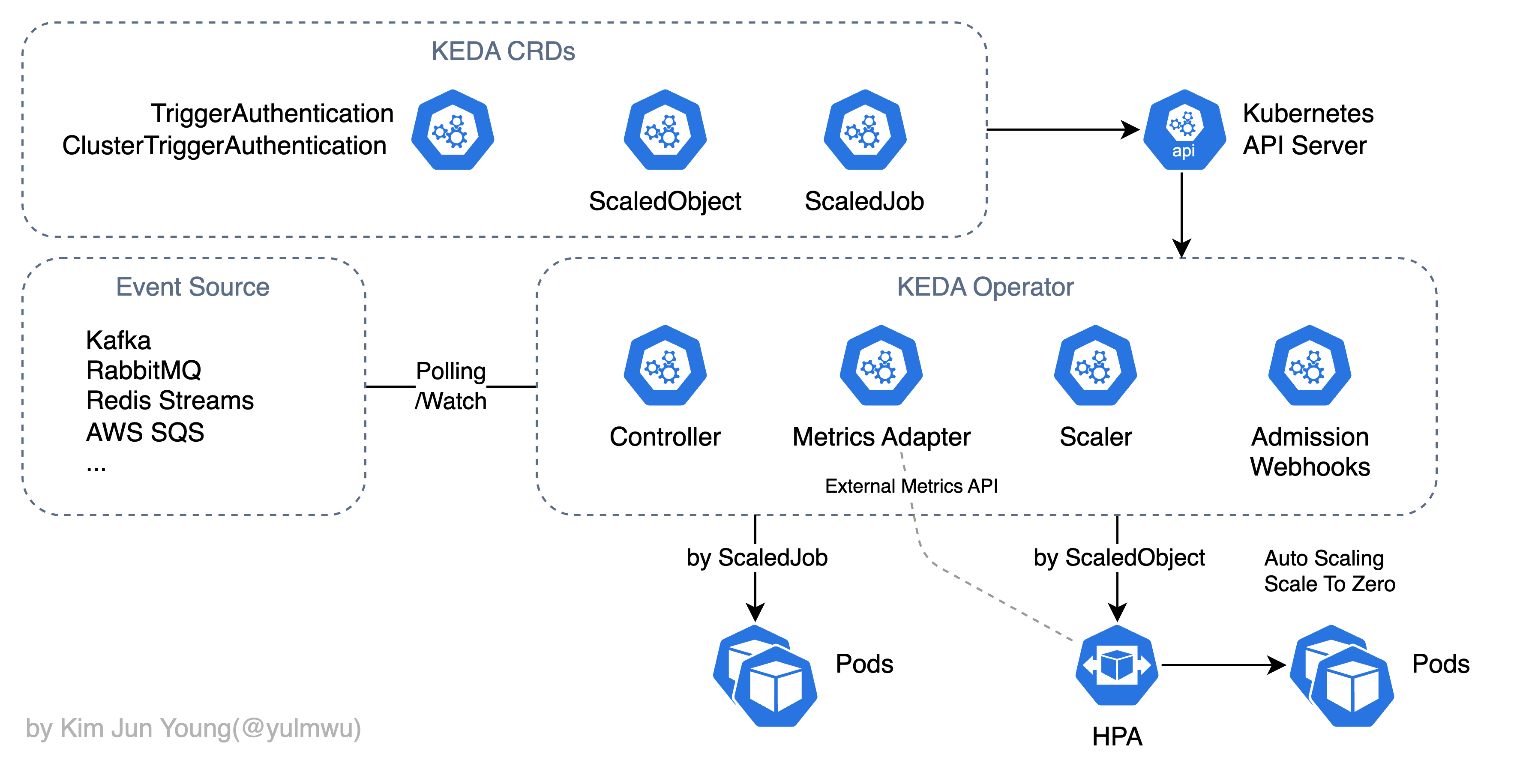
자세한 동작 과정은 위와 같다. 복잡하지는 않은데, 방금 말했 듯 KEDA Operator가 이벤트 소스를 (대부분) Polling하거나 Watch 하여 메트릭을 수집하고, 이를 바탕으로 HPA를 생성하여 파드(워크로드) 스케일링을 진행한다. (자체적으로 External Metrics API를 구성한다.)
이는 일반적으로 HPA 처럼 사용되는 ScaledObject CRD 기준이고, 다른 Scaled 관련 CRD로는 ScaledJob이 있다. 이는 단기성/배치성 작업(Job)을 자동으로 생성하는 리소스이다. (다만 이는 HPA를 통하지 않고 KEDA Operator 자체적으로 생성한다.)
외부(이벤트 소스)의 메트릭을 기반으로 동작하기 때문에, 파드의 메트릭을 기반으로 하는 HPA에서 자체적으로는 어려웠던 Scale to Zero가 가능하며, 실제 동작에서는 HPA를 그대로 사용한다는 점에서 기존에 HPA 리소스를 KEDA로 마이그레이션 할 수 있다.
즉 KEDA는 External Metrics Provider + HPA/배치성 Job 생성 기능을 가진 도구라는 것이다.
백문이 불여일견, 직접 실습해보도록 하자. 실습에서는 KEDA를 통해 AWS SQS 큐의 메트릭을 기준으로 오토스케일링이 되는지 확인해볼 것이다. AWS MSK(Kafka)는 구성 방법이 좀 더 복잡한데, 이는 추후 따로 포스팅해보겠다.
2. KEDA Demo
예제로 살표볼 아키텍처는 아래와 같다. 이렇게 메시지/이벤트 큐나 데이터 스트리밍 플랫폼의 메트릭을 기반으로 오토스케일링 한다는 것은 대부분 컨슈머 파드를 오토스케일링 한다는 의미인데, 컨슈머를 구현하는 것은 이 포스팅의 범위를 벗어나기 때문에 생략하겠다.
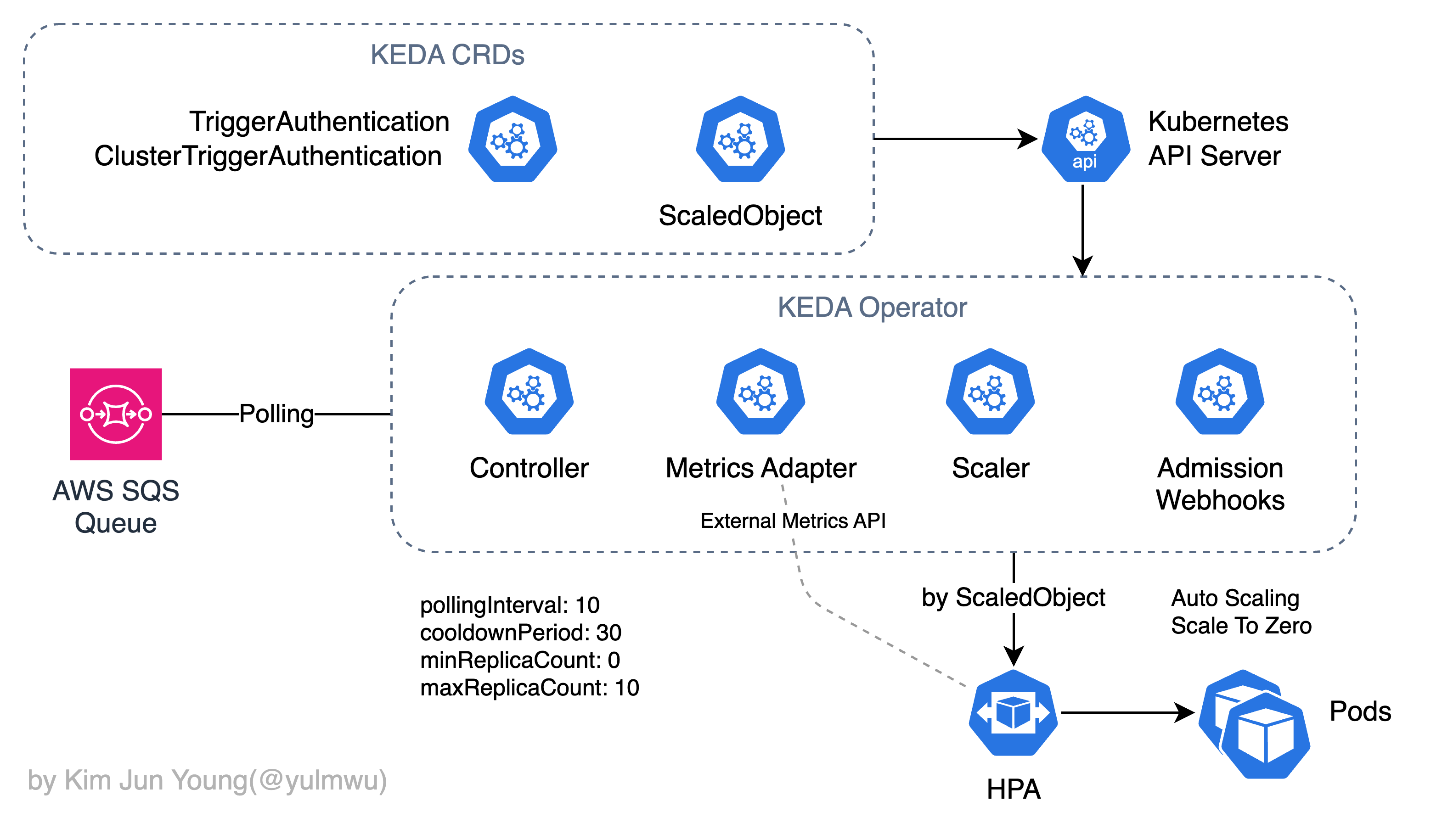
(1) AWS SQS Queue
실습을 위해서 AWS SQS 큐를 하나 만들어주자. 아래와 같이 콘솔에서 만들어도 되고, Terraform과 같은 IaC 도구를 사용해도 되지만 간단하게 아래의 명령어를 통해서도 생성할 수 있다.
SQS_QUEUE_NAME="keda-demo-queue"
aws sqs create-queue --queue-name "$SQS_QUEUE_NAME" --region "ap-northeast-2"
SQS_QUEUE_URL=$(aws sqs get-queue-url \
--queue-name "$SQS_QUEUE_NAME" \
--region "ap-northeast-2" \
--query 'QueueUrl' --output text)
부가적인 옵션들은 모두 기본 값으로 두고, DLQ 또한 구성하지 않았다. SQS에 대한 주제가 아니기 때문에 큐만 깡통으로 만들어주자. (https://sqs.ap-northeast-2.amazonaws.com/986129558966/keda-demo-queue)
(2) EKS Cluster
EKS(Kubernetes) 클러스터는 eksctl 및 ClusterConfig 매니페스트를 작성하여 프로비저닝하였다.
# cluster.yaml
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: demo-cluster
region: ap-northeast-2
version: "1.33"
vpc:
cidr: 10.1.0.0/16
nat:
gateway: Single
iam:
withOIDC: true
managedNodeGroups:
- name: ng-1
instanceType: t3.medium
desiredCapacity: 1
privateNetworking: false
iam:
withAddonPolicies:
ebs: trueeksctl create cluster -f cluster.yaml
aws eks update-kubeconfig --name demo-cluster --region ap-northeast-2
kubectl get nodes인스턴스 타입별로 허용되는 최대 파드의 수가 제한되어 있으니 참고하자. 하나의 t3.medium은 최대 17개의 파드를 수용할 수 있다. 실습에 있어 문제가 될 수는 아니니 필요 시 인스턴스 타입을 업그레이드하거나 노드의 수를 늘리자.
(3) Installing KEDA and IRSA
KEDA는 아래와 같이 Helm Chart로 설치할 수 있다.
helm repo add kedacore https://kedacore.github.io/charts
helm repo update
helm install keda kedacore/keda --namespace keda --create-namespace그리고 KEDA가 SQS 큐에 접근할 수 있도록 IAM 권한이 필요한데, 이는 IRSA로 해결할 수 있다. 아래와 같은 명령어를 실행하자.
(keda-sqs-scaler-policy.json)
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "ReadSqsQueueAttributesForScaling",
"Effect": "Allow",
"Action": ["sqs:GetQueueAttributes", "sqs:GetQueueUrl"],
"Resource": "*"
}
]
}
실습의 편의를 위해 "Resource": "*"로 두었지만, 실제 환경에서는 SQS 큐의 ARN으로 설정해두는 것이 바람직하다.
ACCOUNT_ID=$(aws sts get-caller-identity --query 'Account' --output text)
aws iam create-policy \
--policy-name "KedaSqsScalerPolicy" \
--policy-document file://keda-sqs-scaler-policy.json \
--query 'Policy.Arn' --output text
eksctl create iamserviceaccount \
--cluster demo-cluster \
--namespace keda \
--name keda-operator \
--role-name "keda-operator-role" \
--attach-policy-arn "arn:aws:iam::${ACCOUNT_ID}:policy/KedaSqsScalerPolicy" \
--role-only \
--approve \
--region ap-northeast-2
helm upgrade --install keda kedacore/keda \
--namespace keda \
--create-namespace \
--set podIdentity.aws.irsa.enabled=true \
--set podIdentity.aws.irsa.roleArn="arn:aws:iam::${ACCOUNT_ID}:role/keda-operator-role"(4) Application
예제로 사용할 Application은 아래와 같다. Deployment 하나를 만드는데, replicas는 0으로 두자. KEDA를 통해 Scale to Zero가 동작하는지 확인해볼 것이다.
# application.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: demo-worker
spec:
replicas: 0
selector:
matchLabels:
app: demo-worker
template:
metadata:
labels:
app: demo-worker
spec:
containers:
- name: pause
image: registry.k8s.io/pause:3.9kubectl apply -f application.yaml(5) TriggerAuthN, ScaledObject
다음으로 TriggerAuthentication(또는 ClusterTriggerAuthentication) CRD는 인증 정보를 관리하기 위한 CRD인데, 아래와 같이 작성할 수 있다.
# trigger-authn.yaml
apiVersion: keda.sh/v1alpha1
kind: TriggerAuthentication
metadata:
name: aws-irsa-keda-operator
spec:
podIdentity:
provider: aws
identityOwner: keda이렇게하면 인증 주체가 KEDA, 즉 KEDA Operator에 할당된 IAM 역할(IRSA)를 그대로 사용하겠다는 의미가 된다. 다음으로 ScaledObject CRD를 살펴보자.
# scaled-object.yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: sqs-scaledobject
spec:
scaleTargetRef:
name: demo-worker
pollingInterval: 10
cooldownPeriod: 30
minReplicaCount: 0
maxReplicaCount: 5
triggers:
- type: aws-sqs-queue
authenticationRef:
name: aws-irsa-keda-operator
metadata:
queueURL: "https://sqs.ap-northeast-2.amazonaws.com/<ACCOUNT_ID>/keda-demo-queue"
queueLength: "5"
activationQueueLength: "0"
awsRegion: "ap-northeast-2"여기서 중요하게 살펴볼 것은 queueLength와 activationQueueLength인데, 각각 아래와 같은 역할을 한다. 다른 필드에 대해선 공식 문서를 참조하길 바란다.
queueLength— 파드 1개가 담당할 수 있다고 가정하는 메시지 수를 의미한다.activationQueueLength— Scale to Zero 상태에서 언제 스케일링을 시작할지를 나타내는 필드로, 0으로 설정한다는 것은 메시지가 하나라도 발생했을 때 즉시 스케일 아웃이 된다는 의미이다. (활성화 이후의 replica 계산에는 관여하지 않는다.)
kubectl apply -f trigger-authn.yaml
kubectl apply -f scaled-object.yaml
kubectl -n keda get pods
kubectl -n keda logs keda-operator-...만약 성공적으로 잘 설치되었다면 아래와 같이 에러 메시지가 나타나지 않아야 한다. AWS STS 관련 에러나 Access Denied가 발생한다면 IRSA가 제대로 적용되지 않았다는 의미이니 빠진 부분이 없나 확인해보자.

(6) Testing
이제 kubectl get pods -w 명령어를 실행해두고, 아래와 같이 SQS 큐에 메시지 30개를 보내보자. (KEDA 기본 값은 Pending 상태 및 In Flight 상태를 포함한다. 또한 제공되는 메트릭인 메시지의 수는 대략적인 수치로, replica 계산에서 이론과 정확하지 않을 수 있다.)
for i in $(seq 1 30); do
aws sqs send-message --queue-url "$SQS_QUEUE_URL" --message-body "msg-$i" --region "ap-northeast-2" >/dev/null
done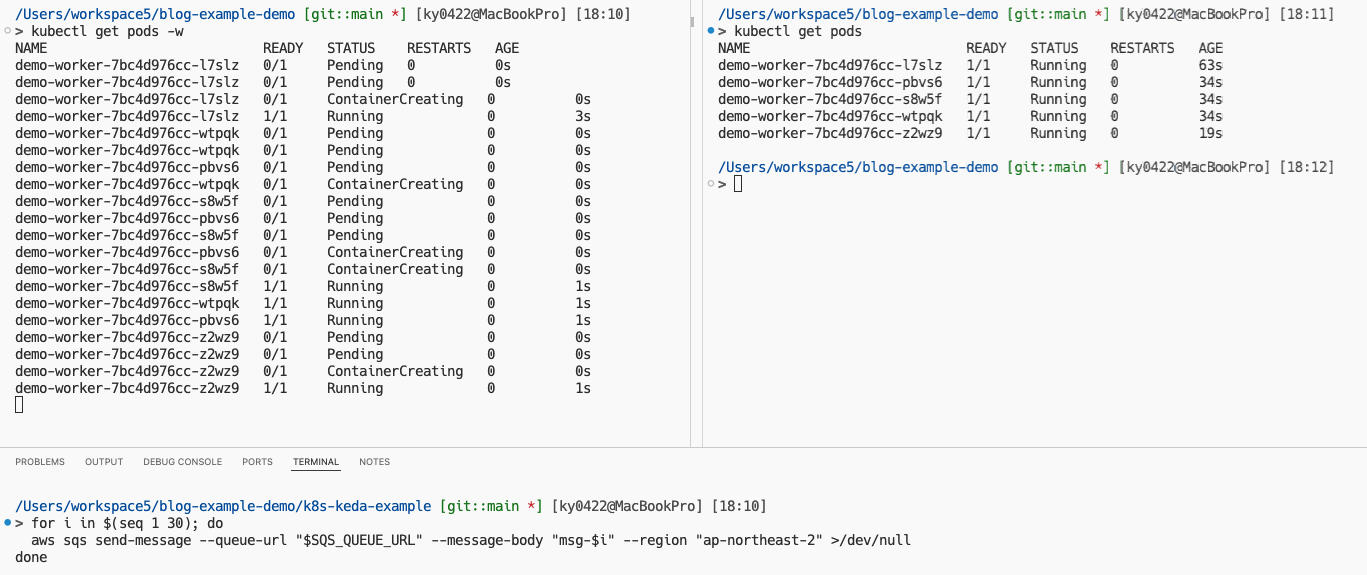
그러면 위와 같이 곧바로 파드가 생성되는 것을 볼 수 있다. Prometheus 등을 거치지 않고 SQS 메트릭을 직접 Polling하기 때문에 매우 빠르게 적용되는 것을 볼 수 있다. 현재는 maxReplicaCount: 5로 제한을 걸어뒀기 때문에 5개의 파드가 생성되었는데, 이론상 아래의 공식을 따르기 때문에 총 6개의 파드가 생성되어야 할 것이다.
desiredReplicas = ceil(messages_count / queueLength)
ceil(30 / 5) = 6이를 확인해보기 위해 maxReplicaCount를 10으로 늘려보자. 단, t3.medium 인스턴스의 최대 파드 수 제한으로 Too Many Pods가 발생할 수 있다. 하지만 이론상 6개의 파드가 생성되어야 하기 때문에 그냥 진행하겠다.

kubectl apply -f sqs/scaled-object.yaml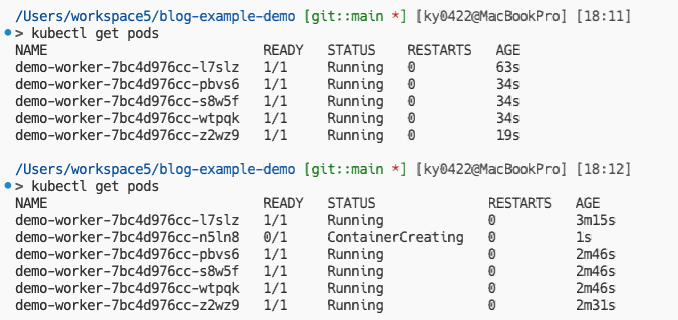
그러면 위와 같이 총 6개의 파드가 생성되는 것을 볼 수 있다. 마지막으로 메시지를 전부 삭제(Purge)하여 Scale to Zero가 동작하는지 확인해보자. 실제 운영 환경에선 메시지가 성공적으로 컨슈밍 되었다고 가정하는 것이다.
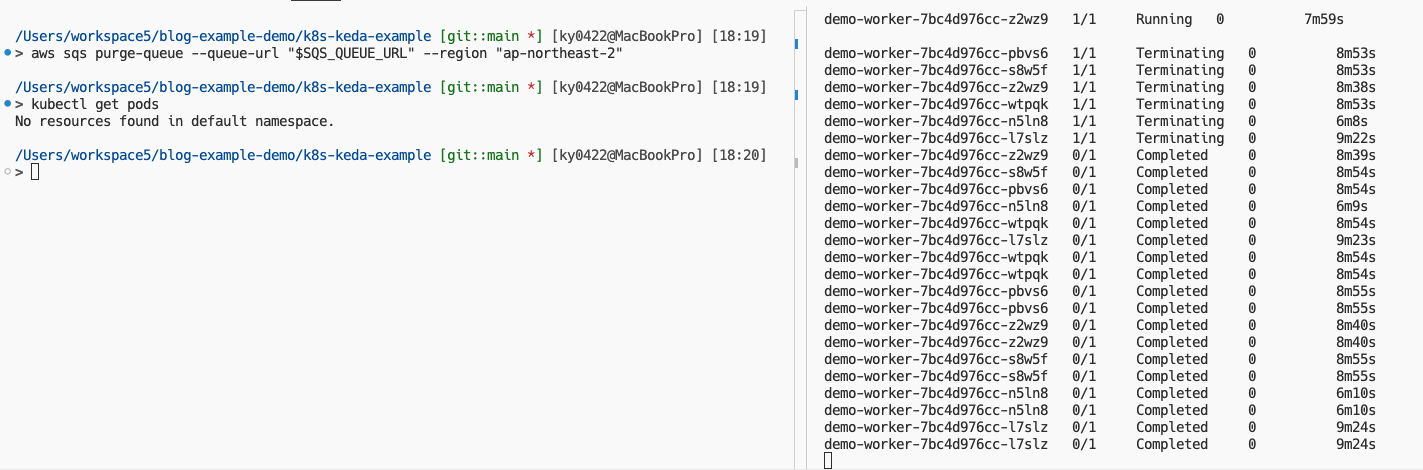
그럼 위와 같이 모든 파드가 종료되는 것을 확인해볼 수 있다. 지금까지 KEDA를 사용하여 AWS SQS 큐 메시지 수 기반의 오토스케일링을 실습해보았는데, 다음엔 SQS 큐가 아닌 Kafka(MSK)를 기반으로 KEDA를 구성하는 방법을 포스팅해보겠다.
