0. Overview
쿠버네티스에선 컨트롤러를 통해 클러스터의 리소스나 상태를 원하는 상태로 수렴하려는 특징을 가지고 있다.
A controller tracks at least one Kubernetes resource type. These objects have a spec field that represents the desired state. The controller(s) for that resource are responsible for making the current state come closer to that desired state.
The controller might carry the action out itself; more commonly, in Kubernetes, a controller will send messages to the API server that have useful side effects.
출처: https://kubernetes.io/docs/concepts/architecture/controller
쿠버네티스에선 상태를 선언하고, 이러한 컨트롤러를 루프(Reconcile Loop)로 돌려 의도한 상태에 가깝게 만드는데, 이를 컨트롤러 패턴이라고 부른다.
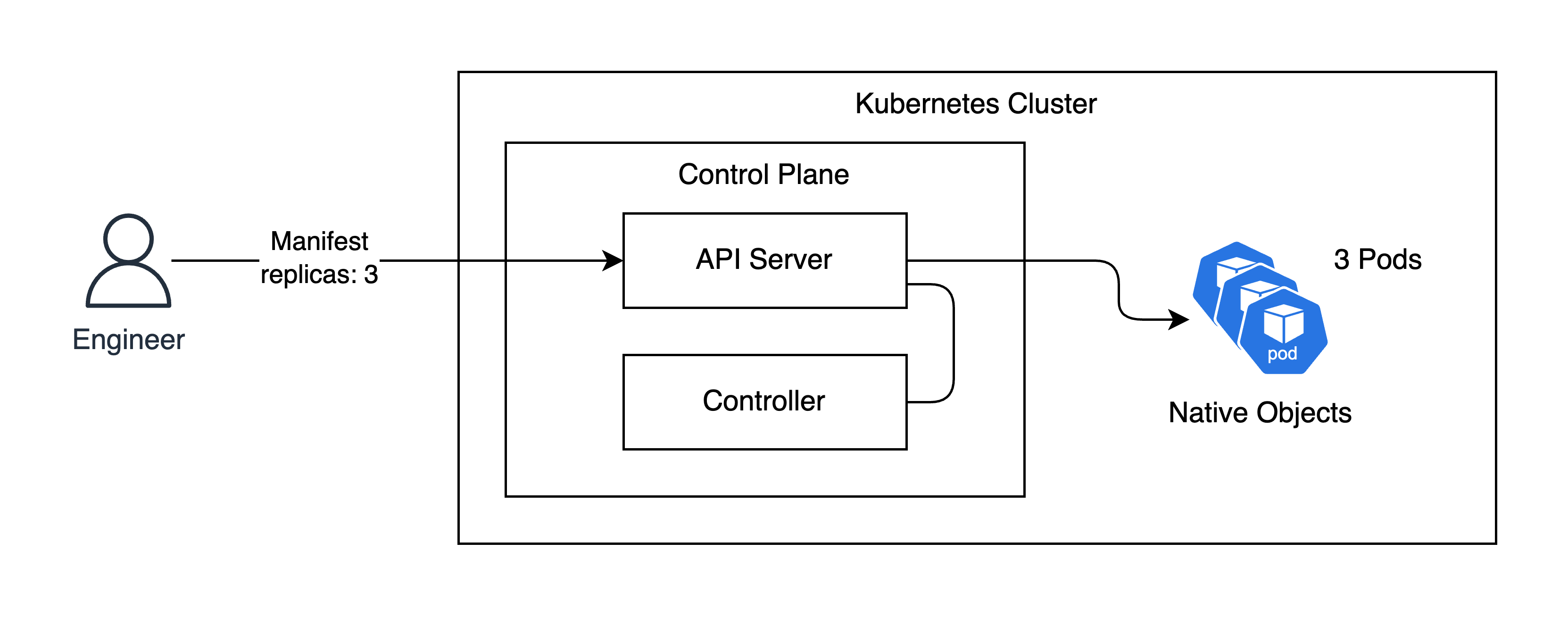
웬만한 서비스 환경이라면 이러한 네이티브 오브젝트를 사용하여 인프라를 운영할 수 있다.
하지만 복잡한 상태의 Stateful 애플리케이션이나, 설정이 자주 변경되어 ConfigMap 등을 하나하나 수정 후 Deployment/파드를 수동으로 재시작하는 등의 쿠버네티스 네이티브 오브젝트로는 어려움이 있는 경우가 있다.
첫번째 예시로 MySQL, PostgreSQL 등의 DB 클러스터를 운영할 때 DB 특성 상 Stateful 애플리케이션으로 운영해야 한다.
물론 StatefulSet과 같은 네이티브 오브젝트가 있겠지만 제한이 있고, DB와 같이 Primary/Replica 구성, Failover 시 대처, 백업/복구 등에서 쿠버네티스 네이티브 오브젝트를 수동으로 다뤄야한다.
일반적인 클라우드 환경에선 Stateful한 데이터베이스는 주로 클라우드에서 제공되는 편이고, 쿠버네티스에선 Stateless 애플리케이션을 올리는 것이 적절하다.
AWS 기준 RDS, DocumentDB, DynamoDB, OpenSearch(ElasticSearch), 그리고 인메모리 NoSQL의 대표적인 Redis (OSS)는 ElastiCache과 같은 완전 관리형 서비스로 제공된다.
또한 ConfigMap, Secret, PVC 등의 설정 값이 자주 변경될 때 이를 적용하기 위해 파드를 수동으로 재시작하는 등의 귀찮은 작업을 거쳐야 한다.
위와 같은 시나리오의 공통점이 있는데, 바로 Day 2 Operation(운영, 최적화 등)에 대한 이야기라는 것이다.
(물론 Helm과 같이 Day 1 Operation(설치, 구성)은 가능하였지만 지속적인 Day 2 Operation은 수동으로 했어야 하였다)
1. What is Operator?
하지만 그러한 Day 2 Operation에 대해 쿠버네티스 네이티브 오브젝트를 통해 다루긴 어려웠는데, 그래서 복잡한 Day 2 Operation에서 운영자(Operator)의 Operational Knowledge를 컨트롤러 자체에 코드로 옮기자는 개념이 바로 Operator 패턴이다.
Operational Knowledge
필자가 한글로 번역하진 않았지만, 쉽게 말해 운영 시 필요한 메뉴얼이나 노하우라 생각하면 편할 것이다.
실제로 여기엔 장애 발생 시 Failover, 백업/복구, 버전 업그레이드 등의 운영자가 수동으로 하던 절차를 말한다.
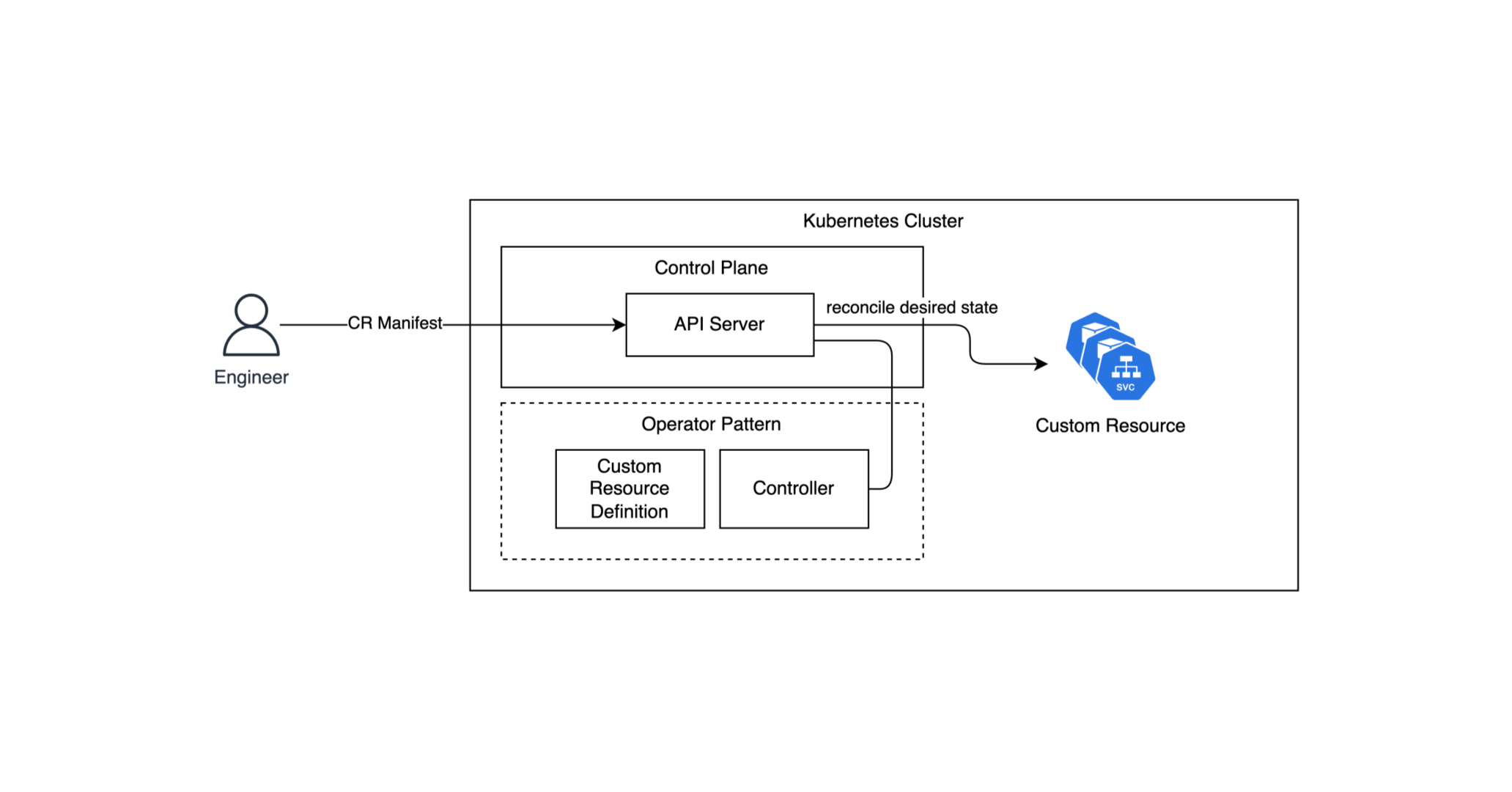
Operator는 쿠버네티스의 컨트롤러를 확장하여 CRD(Custom Resource Definition)로 선언된 애플리케이션을 Reconcile(선언된 상태에 맞도록 관찰하여 수렴해나가는 것) 한다.
다르게 말하여 쿠버네티스에 포함되지 않는 운영 로직을 CRD 객체로 확장하여 선언하고, 컨트롤러 Reconcile Loop 모델을 사용자가 확장하여 운영을 자동화하는 것이다. (CRD를 바탕으로 생성되는 리소스를 CR, Custom Resource라 부른다)
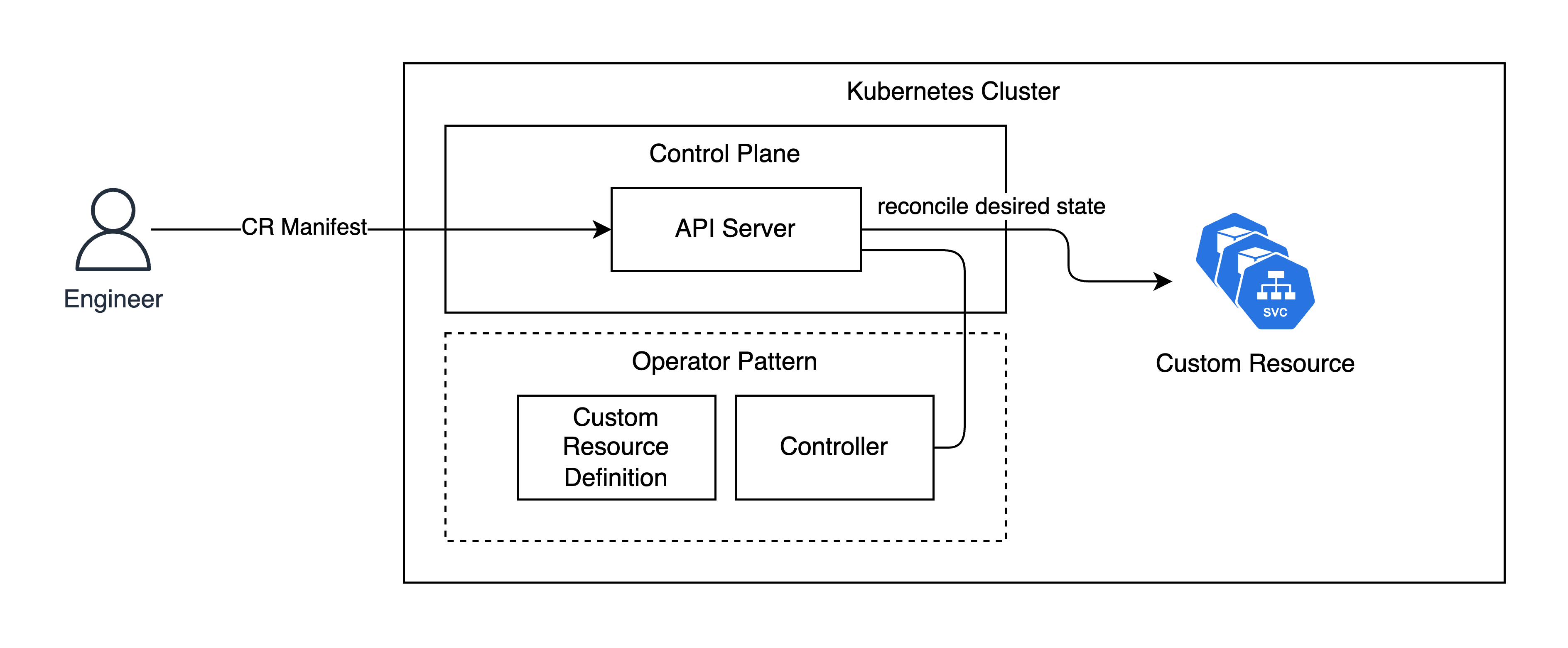
CRD(Custom Resource Definition)와 컨트롤러는 포스팅 후반에서 Go 언어를 사용하여 제작 후 배포해보도록 하고, 예시의 CR(Custom Resource) 매니페스트는 아래와 같다.
apiVersion: database.example.com/v1
kind: SampleDB
metadata:
name: my-db
spec:
version: "1.2.3"
replicas: 3
backupSchedule: "0 2 * * *"이를 위해선 CRD와 이 CR 매니페스트를 보고 Operation 동작(StatefulSet, PVC, Service 자동 생성/조정, 버전 업그레이드, 백업 등 자동화)을 위한 비즈니스 로직은 Operator 컨트롤러를 통해 구현된다.
2. Example: Prometheus Operator
Prometheus는 쿠버네티스 모니터링 시스템으로, 리소스나 애플리케이션의 매트릭을 모니터링하고 관리하는 도구이다.
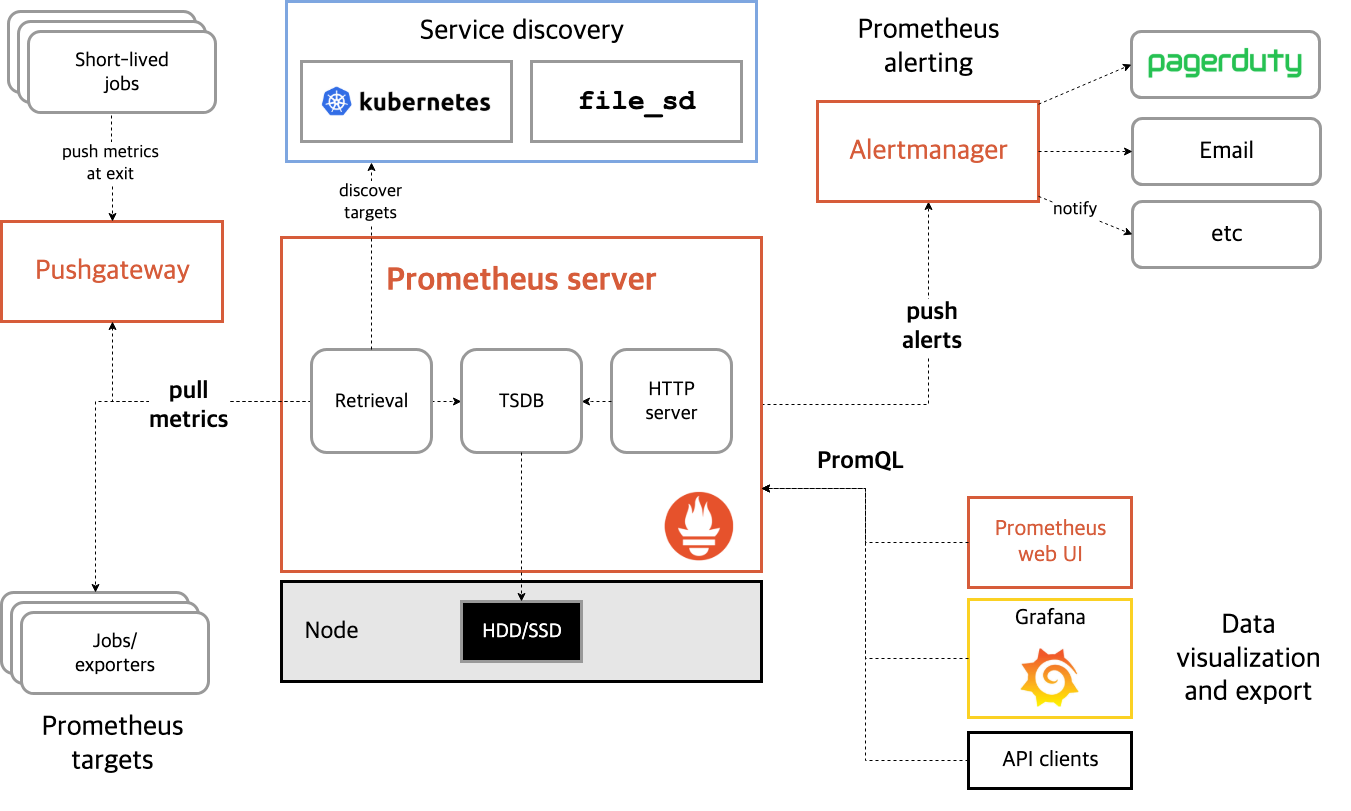
출처: https://prometheus.io/docs/introduction/overview
위 아키텍처와 같이 꽤나 복잡한 구조를 가지는데, 만약 이를 쿠버네티스에 적용하려면 수많은 Deployment, StatefulSet, ConfigMap, Secret, Service 등의 리소스를 직접 운영해야 하며 설정 변경 후엔 수동으로 업데이트해야 한다.
그래서 Prometheus Operator는 Prometheus, Alertmanager, ServiceMonitor, PodMonitor, PrometheusRule과 같은 CRD를 제공하며, 사용자는 Prometheus CR을 선언하고 Prometheus Operator가 이를 Reconcile Loop하며 리소스를 자동으로 업데이트한다.
(1) Helm Installation
Prometheus를 설치하기 위해 아래의 Helm 차트를 업데이트한다.
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update그리고 Prometheus Stack Helm 템플릿에 값을 넣어주기 위해 아래와 같은 YAML 파일을 작성하자.
# kps-values.yaml
global:
rbac:
create: true
prometheus:
service:
type: ClusterIP
prometheusSpec:
retention: 15d
scrapeInterval: 30s
evaluationInterval: 30s
storageSpec:
volumeClaimTemplate:
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 20Gi
# storageClassName: gp3
serviceMonitorSelector: {}
serviceMonitorNamespaceSelector: {}
podMonitorSelector: {}
podMonitorNamespaceSelector: {}
probeSelector: {}
probeNamespaceSelector: {}
scrapeConfigSelector: {}
scrapeConfigNamespaceSelector: {}
alertmanager:
alertmanagerSpec:
replicas: 1
grafana:
adminUser: admin
service:
type: ClusterIP
defaultDashboardsEnabled: true
kube-state-metrics:
enabled: true
nodeExporter:
enabled: true그리고 아래의 Helm 명령어로 Prometheus Stack을 설치한다.
kubectl create namespace monitoring # 필수는 아니지만 네임스페이스 분리를 통해 깔끔하게 작업한다.
helm install kps prometheus-community/kube-prometheus-stack \
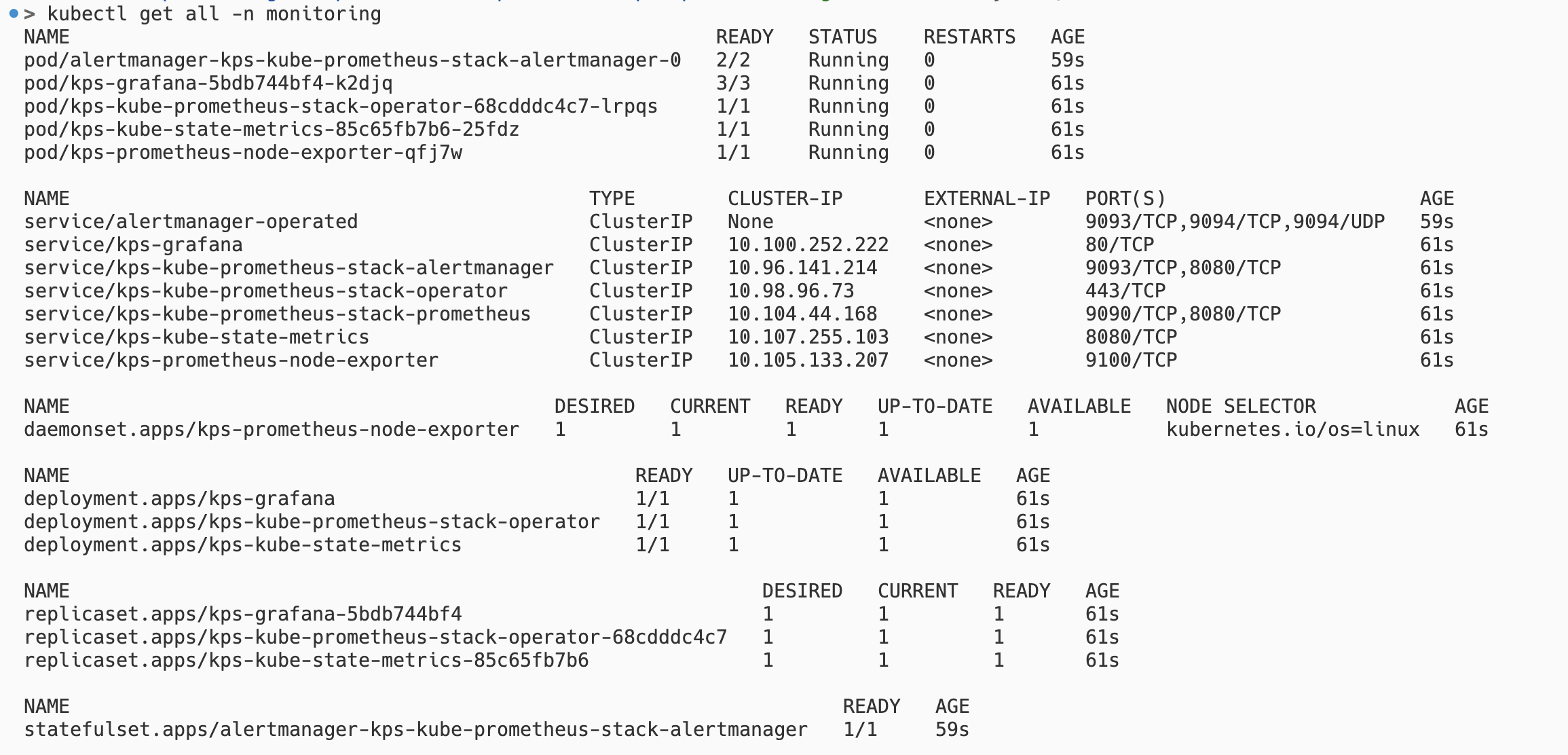
-n monitoring -f kps-values.yaml그리고 kubectl get all -n monitoring 명령어를 통해 Prometheus 리소스를 확인해보자.
다음으로 Grafana로 접속해보자. Grafana는 Prometheus 등을 시각화 및 모니터링 할 수 있는 도구이다.
kubectl port-forward -n monitoring svc/kps-grafana 3000:80
# Grafana password (admin:password=prom-operator)
kubectl --namespace monitoring get secrets kps-grafana -o jsonpath="{.data.admin-password}" | base64 -d ; echoport-forward 명령어를 통해 접속해보자. 패스워드는 Secrets에 저장되어 있고, 기본 패스워드는 prom-operator이다.
접속 후 로그인을 해보면 위와 같이 나오는 것을 볼 수 있다. Prometheus와 Grafana에 대해 자세히 다루는 것은 아니므로 더 이상 다루진 않겠다.
(2) Deployment Example App
다음으로 Prometheus CR인 ServiceMonitor를 적용해보기 전에 Deployment를 하나 만들어주겠다.
# deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: example-app
namespace: default
labels: { app: example-app }
spec:
replicas: 1
selector:
matchLabels: { app: example-app }
template:
metadata:
labels: { app: example-app }
spec:
containers:
- name: app
image: rlawnsdud/demo
ports:
- containerPort: 8080
env:
- name: HOST
value: "0.0.0.0"
- name: PORT
value: "8080"
---
apiVersion: v1
kind: Service
metadata:
name: example-app
namespace: default
labels: { app: example-app }
spec:
selector: { app: example-app }
ports:
- name: http
port: 8080
targetPort: 8080여기까지 만들었다면 아직 Grafana Prometheus 대시보드에 데이터가 없을 것이다.
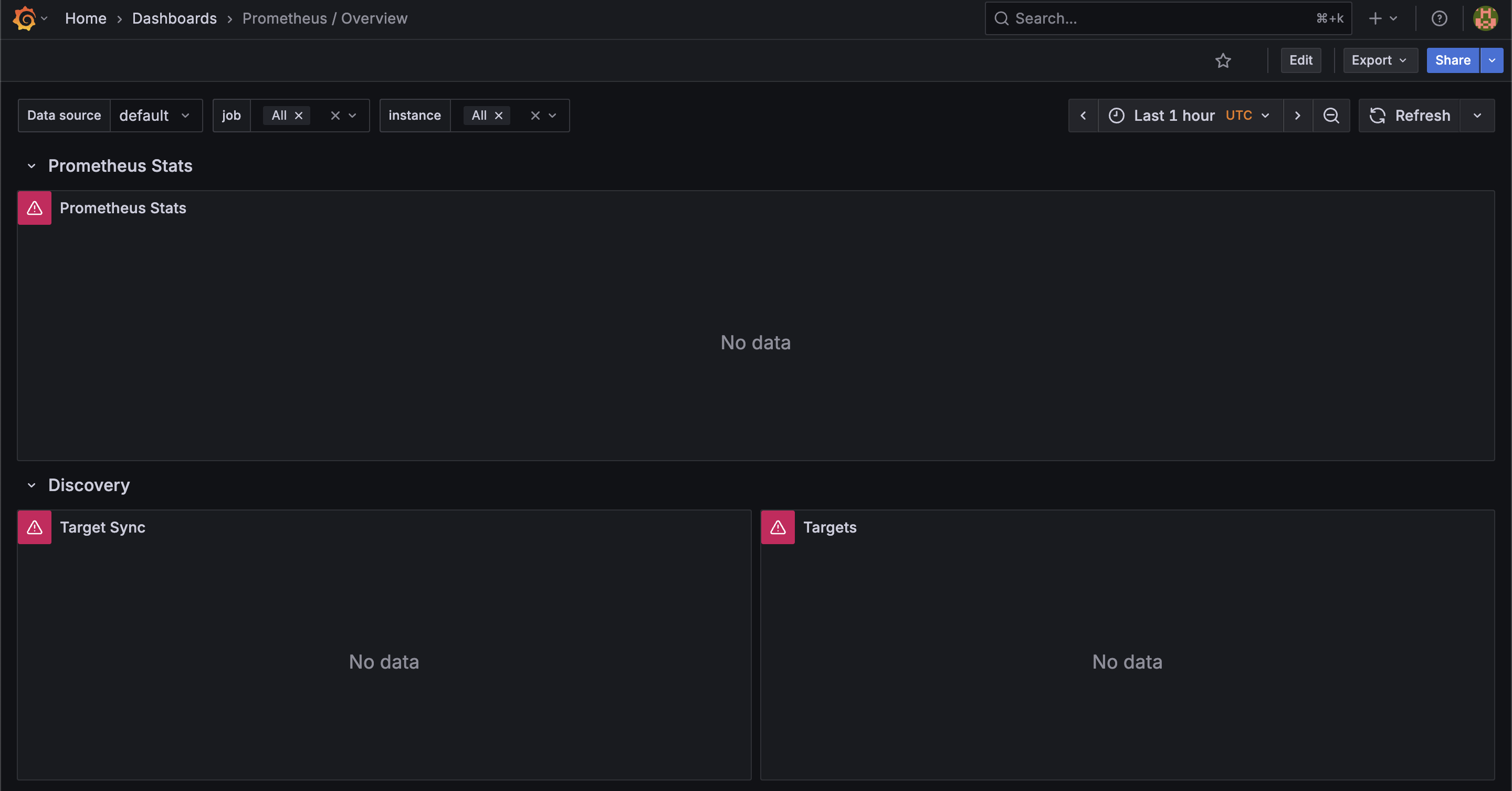
이제 ServiceMonitor나 PodMonitor와 같은 Prometheus CR을 만들어줘야 하는데, 아래와 같은 매니페스트 파일을 만들고 적용해보자.
# service-monitor.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: example-app
namespace: default
labels:
release: kps
app: example-app
spec:
selector:
matchLabels:
app: example-app
namespaceSelector:
matchNames: ["default"]
endpoints:
- port: http
interval: 30s
path: /metricskubectl apply -f deployment.yaml
kubectl apply -f service-monitor.yaml그리고 kubectl get servicemonitor --all-namespaces 명령어를 통해 CR이 잘 만들어졌는지 확인해보자.
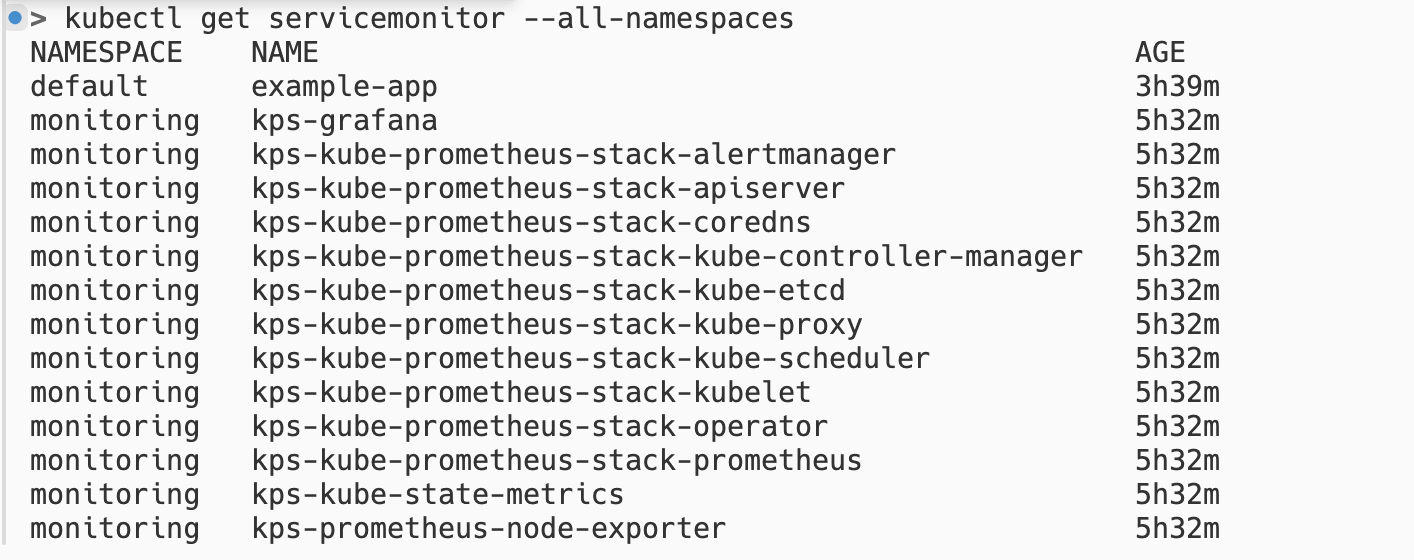
사진과 같이 default 네임스페이스에 example-app의 ServiceMonitor CR이 만들어진 것을 볼 수 있다. Grafana 대시보드에서도 마찬가지로 확인해볼 수 있다.
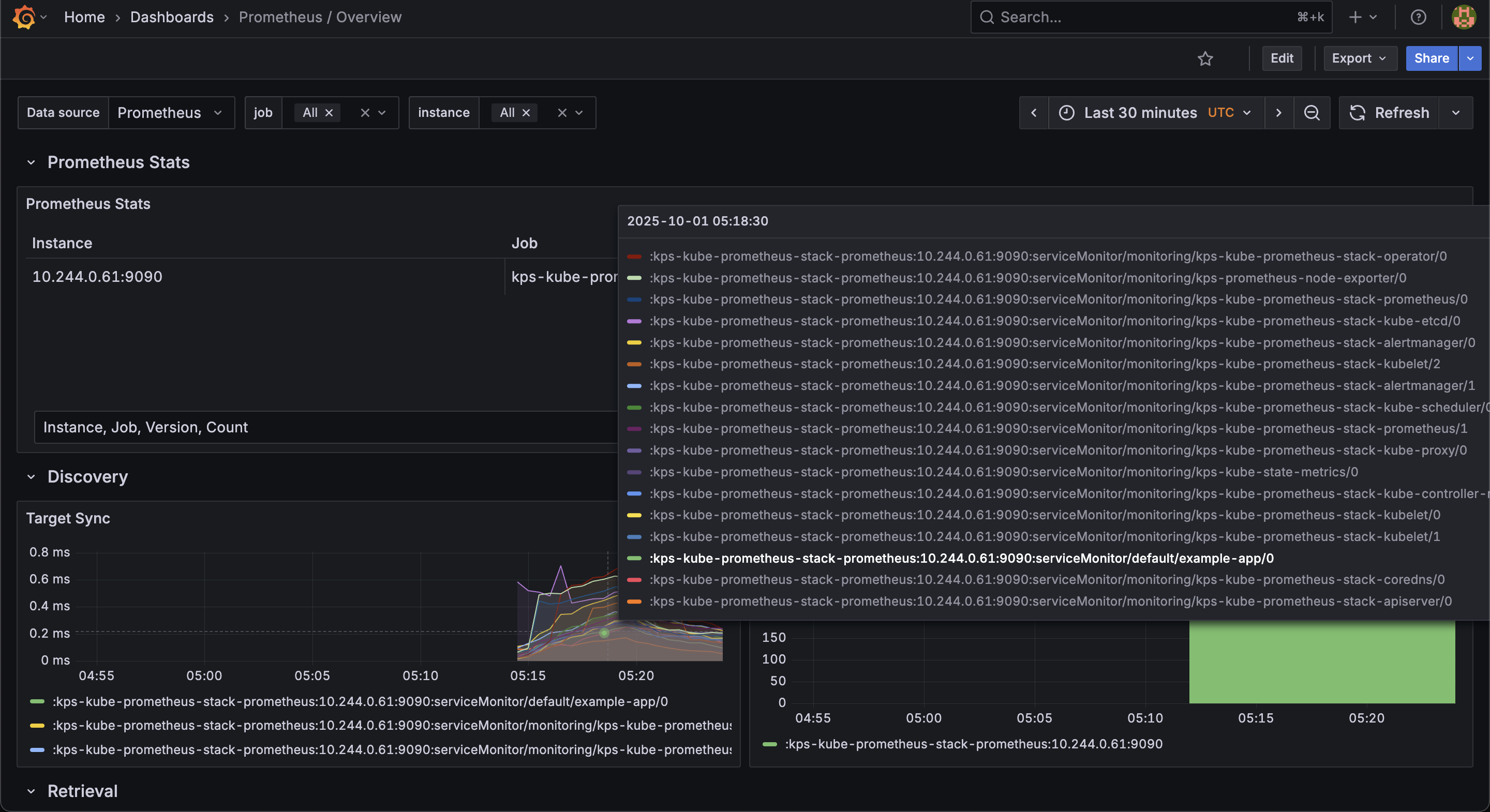
여기서 핵심은 ServiceMonitor CR을 만들고 적용했을 때 Prometheus가 업데이트되었고 이를 통해 매트릭을 확인할 수 있었다는 것이다.
그 이유는 Prometheus Operator의 컨트롤러 덕분으로, Prometheus Operator 레포지토리에서 Go 언어로 작성된 컨트롤러를 확인할 수 있다.
Prometheus Operator를 Helm을 통해 설치하고 ServiceMonitor CR을 선언하여 실습해보았다면, 다음엔 직접 Operator를 만들어볼 것이다.
직접 Operator를 만들고 SDK 등을 사용하여 Controller를 전부 만드는 것은 일반적인 상황에선 쉽지 않은 일이며, 보통은 Prometheus Operator나 (클라우드에서 제공하지 않는 경우) DB Operator 처럼 Third Party로 제공되는 Operator를 사용하는 편이다.
이 내용은 다음 포스팅에서 확인해볼 수 있다.
