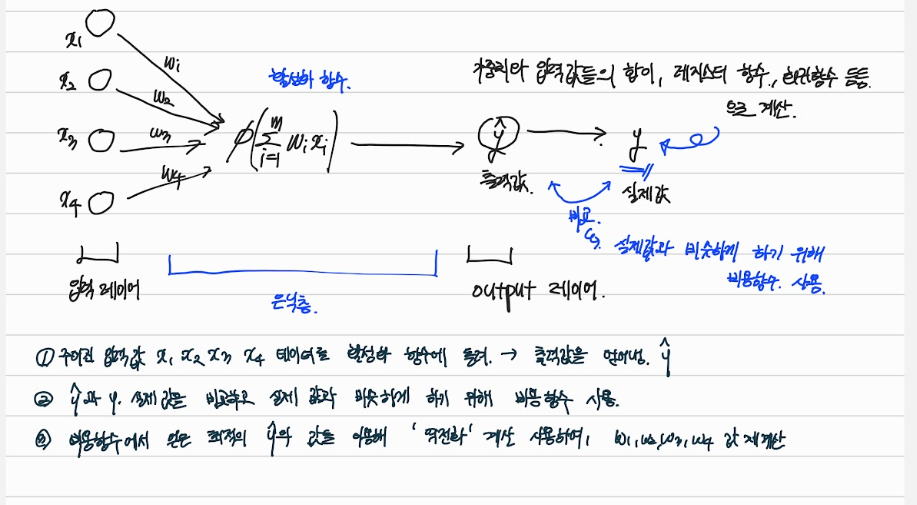
- 입력 레이어들의 값을 "은닉층"에서 활성화 함수에 넣어 얻은 출력값
- 출력값과 실제값을 비교하고 실제 값과 비슷하게 하기 위한, 비용함수를 사용
- 비용함수에서 얻은 최적의 출력값을 이용해 '역전화' 계산을 사용하셔 가중치 값들을 다시 계산하여, 출력값과 실제값을 비슷하게 맞추는 과정
- 맞추면서 만들어진 머신러닝 모델 !!
Artificial Neural Network 를 만들어보자!
기본적인 setting
import numpy as np
import pandas as pd
import tensorflow as tf데이터 전처리 과정
데이터 전처리 과정은, 주어지는 데이터들이 내가 원하는 형식으로 주어지지 않기 때문에 , 내 맞춤형으로 바꿔줘야 한다.
이부분은 pandas 를 공부하면서 더 알아가봐야 할 것 같다.
dataset = pd.read_csv('Churn_Modelling.csv')
# 이름과 번호를 제외한 데이터
X = dataset.iloc[:, 3:-1].values
#이탈률
y = dataset.iloc[:, -1].valuesX 에는, csv 파일에 4번째 행부터 마지막 전까지 값을 가져오고
y 에는, 은행 이탈률 값을 저장해놓았다.


가져온 데이터를 이제 변환해보자!
성별, 사는 지역 과 같은 데이터는 데이터 모델링에 필요한 데이터의 특성이다.
하지만 문자열 데이터 로 되어있기 때문에 우리가 , 쉽게 데이터 분석에 가져오기가 힘들어진다.
어떻게 하면 될까?
범주형 데이터 (성별, 사는 지역) 데이터를 원-핫 코딩을 해서 데이터 형식을 바꿔보자
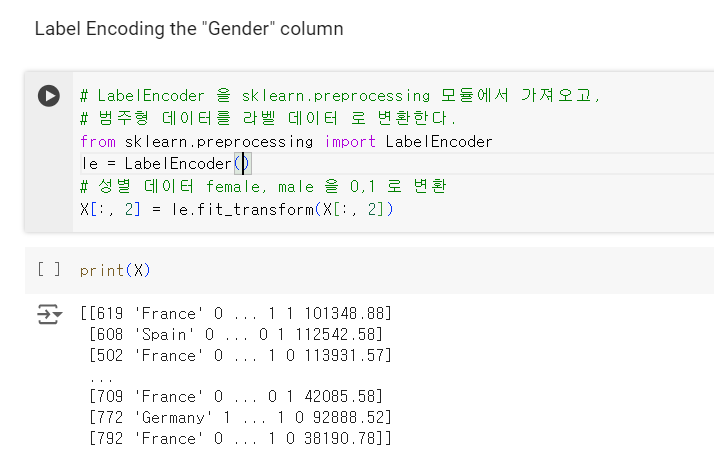
먼저 , 성별 데이터

남자와 여자를 0,1 로 라벨 데이터로 변환
그 다음으로, 나라 데이터
나라 데이터 같은 경우는, 0,1 로 나타내기 어려우니
001 , 101, 111 이진 벡터로 표현하면 된다.
데이터 전처리 과정 중, 필요한 단계 1
우리는 출력값과 실제값이 비슷한지 확인해야 한다!
그러기 위해 학습 데이터와 , 테스트해볼 데이터가 필요하다.
# 데이터를 무작위로 학습 세트와 테스트 세트로 나눈다.
from sklearn.model_selection import train_test_split
# 학습 데이터는 80, 훈련 데이터는 20%
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)데이터를 무작위로 학습세트와 , 테스트 세트로 나눈후,
학습 데이터는 80 %, 훈련 데이터는 20%로 나눈다. 이건 test_size 매개변수를 이용할 것
데이터 전처리 과정 중 , 필요한 단계 2
데이터들을 정규화 하여야 한다.
위의 언급한 단계 중, 비용함수를 통해 최적의 y 값을 찾아낼 때, 우리는 경사하강법의 함수를 이용하게 된다.
데이터들을 정규화 해야, 경사하강법의 input 값이 취우쳐지지 않아, 옳바른 결과값을 출력가능한데, 정규화 하지 않으면, 값이 취우쳐지지는 불상사가 생기게 된다.
그러기에 우리는 머신러닝 모델을 만들기전에
데이터를 "정규화" 하는 과정이 필요로 하게 된다.
# 데이터픞 표준화하는 과정
# 데이터의 평균을 0, 표준편차를 1로
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
# 데이터의 평균과 표준편차를 계산, 학습용데이터에 대해 사용
X_train = sc.fit_transform(X_train)
print(X_train)
# 이미 계산된 평균과 표준편차를 사용해 데이터를 변환
# 테스트 데이터에 대해 사용한다.
X_test = sc.transform(X_test)
print(X_test)인공 신경망을 만들어보자 - 구조 정의 단계
ann = tf.keras.models.Sequential()
# ann.add : 텐서 플로우를 사용하여, 인공 신경망의 레이어를 추가하는 것
# tf.keras.layers.Dense 밀집 레이어를 의미, 레이어의 뉴런 노드 수, 활성화 함수 relu : ReLu 활성화 함수
# 입력이 0보다 작으면, 0출력, 0보다 크면 입력 값을 그대로 출력
ann.add(tf.keras.layers.Dense(units=9, activation='relu'))
ann.add(tf.keras.layers.Dense(units=9, activation='relu'))
# 마지막 출력층 값 ->출력증 값이 이진 변수로 1로 변경
# 만약 출력층 값이, abc 와 같이 이진 변수가 아닐 경우에는 1 이 아닌 3 으로 ,,
ann.add(tf.keras.layers.Dense(units=1, activation='sigmoid'))
# 모델이 학습할 때 , 가중치를 조정하는 방법 optimizer , adam 은 최적화 알고리즘 : 학습을 더 빠르고 효율적으로
# loss: 모델이 예측한 값과 실제 값의 차이를 계산, binary_crossentropy : 이진 분류 문제에 적합한 손실 함
ann.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])# 학습할 입력데이터, 학습용 정답 레이블, 모델이 한 번에 학습할 데이터의 샘플 수 :32 , 32개의 샘플을 한번에 처리
# 에포크 수 : 전체 데이터 셋에 대해 학습을 반복하는 횟
ann.fit(X_train ,y_train, batch_size = 32, epochs = 150)# 예측 메소드의 입력값은 2d 배열이여야 한다.
# sc.transform : 정규화하는 과정
# 마지막 ann 을 만들때의 함수가 시그노이드 함수 -> 확률 로 값을 출력해
# 0.5 확률보다 아래니까 떠날 확률은 낮다!!!
print(ann.predict(sc.transform([[1, 0, 0, 600, 1, 40, 3, 60000, 2, 1, 1, 50000]])))
