데이터 분석의 길을 찾아..
👆특정 범위의 데이터값을 가져오는 함수
✌ stack() 함수 다시 정리해
내가 받을 데이터는

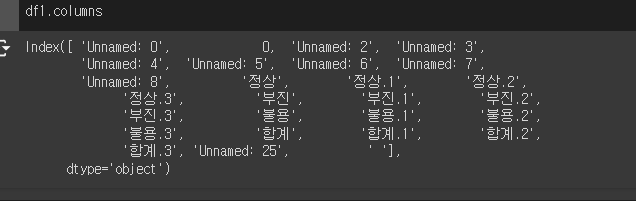
컬럼명이 중복되거나, 날짜가 컬럼으로 들어가는 등의 오류가 있다!
데이터 전처리 순서는 크게
1. Column 을 다시 재 정의 하자 !
2. Column 값에 지정된 날짜 데이터를 재배치하자!
1. Column 명을 재정의
pd.read_excel('Data05.xlsx',skiprows=1)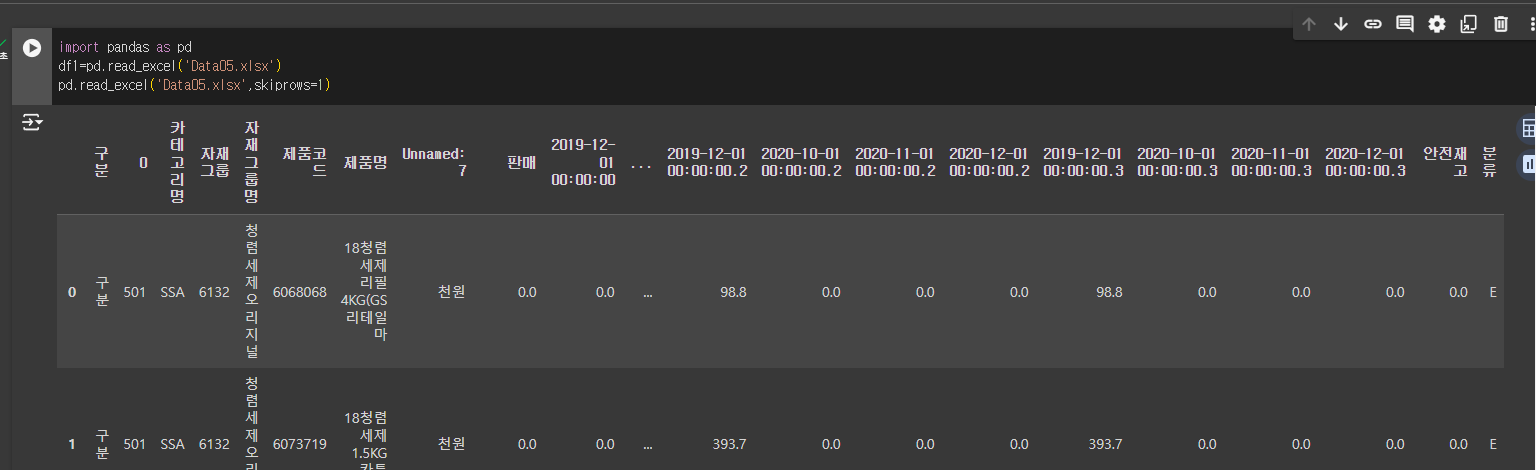 첫번째행을 skip 하여 다음 행이 첫번째 행으로 지정
첫번째행을 skip 하여 다음 행이 첫번째 행으로 지정
* 여기서 특정 행 의 데이터를 가져오고 싶을 땐?
df1.iloc[:][ : ] range 값을 지정해주는 것이다.
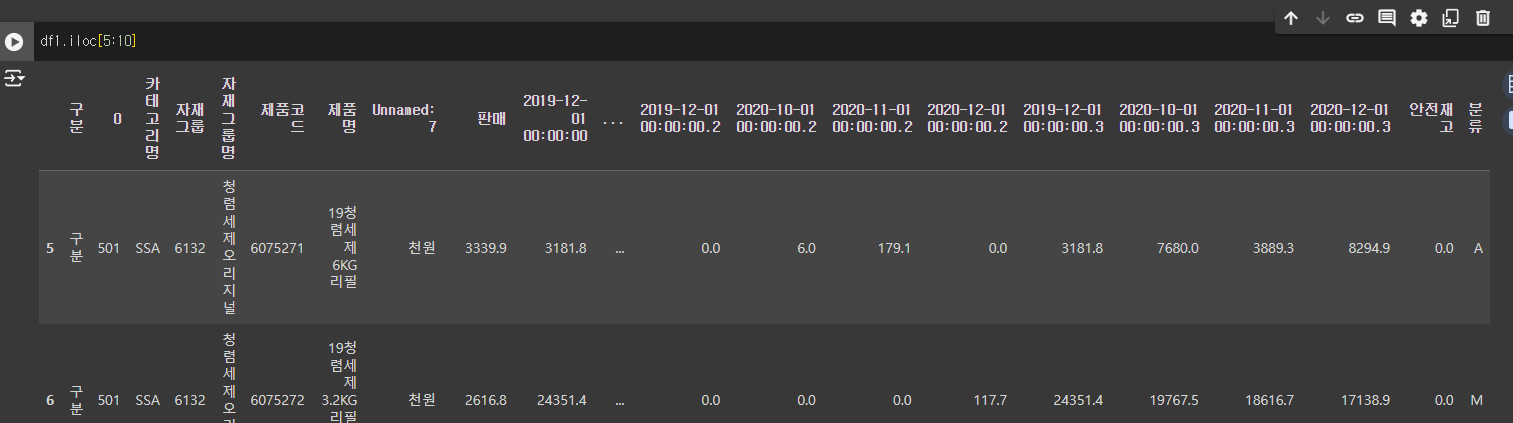
iloc[5:10]
5부터 9 까지의 행의 데이터를 가져온다.
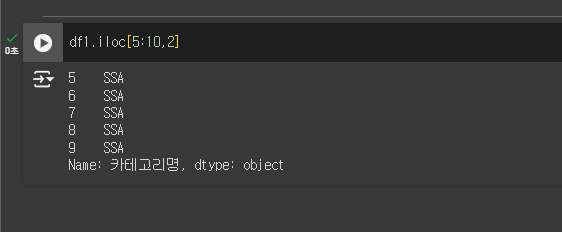
iloc[행:행 , 열:열 ]
행의 데이터를 지정한 후의 index 값을 지정하면, 특정 열에 해당하는 데이터 만 가져오게 된다.
2. 👌이젠, 날짜 데이터를 재배치 할 것이다.
보기와 같이, 판매 값 부터 날짜 데이터가 있는 것을 볼 수 있다.
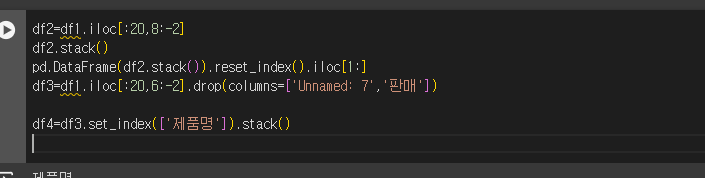
df1.iloc[:20,8:-2]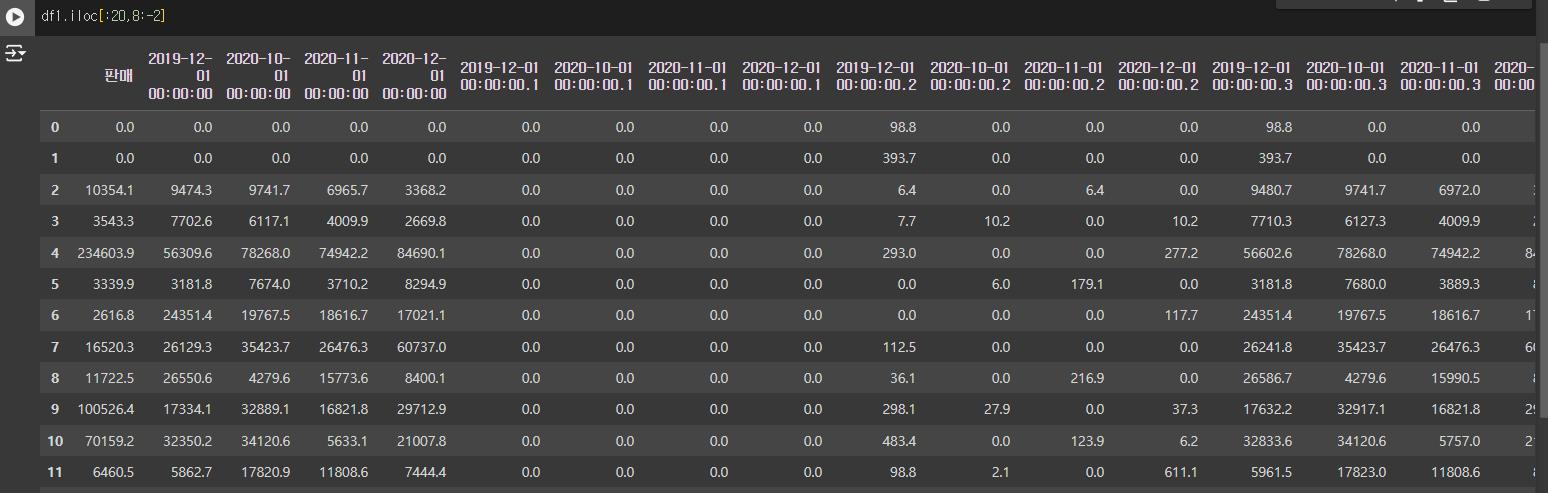
판매 데이터 값에서 날짜 데이터 추출까지!
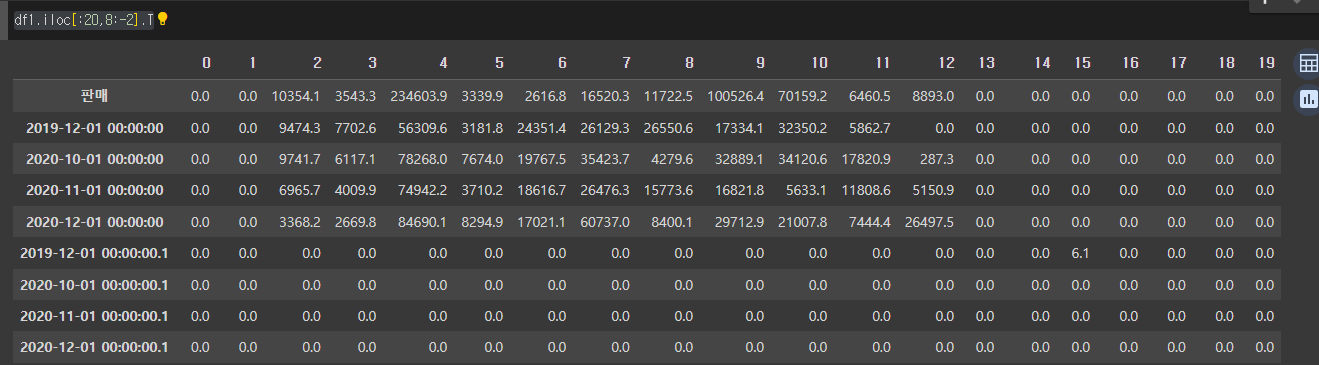
df1.iloc[:20,8:-2].TTraspose
T를 이용해 Transpose 를 해주었다. 행과 열을 바꾸는 역할이다.
그러나, 날짜 데이터가 행 Column 에 들어갔을 뿐, 이것을 우리가 원하는 형식의 데이터가 아니다!
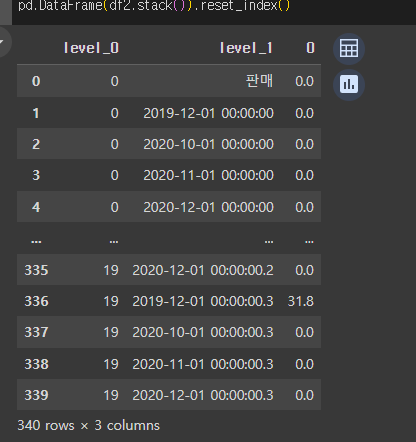
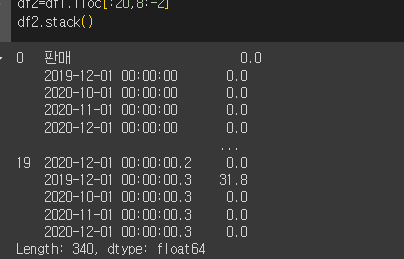
Stack 함수
data 를 Column 형태로 쌓아 올렸다... 어떤 형식인걸까?
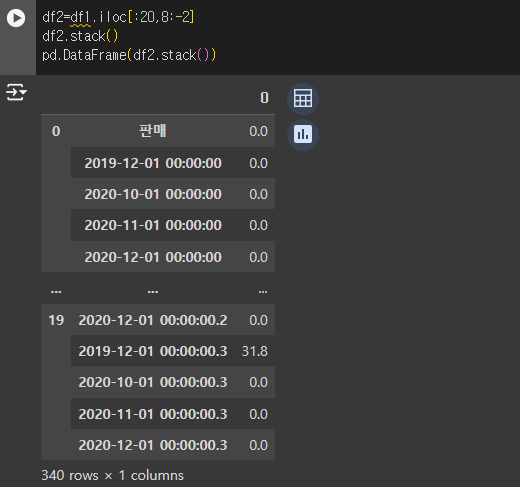
행이 총 20개로 한 행에 데이터가 여러개 쌓인 모습을 볼 수 있다.
우리는 이것을 Stack() 함수를 이용해 Column 형태로 쌓아 올렸다 고 표현한다.
Stack( ) 함수
pd.DataFrame(df2.stack()).reset_index()
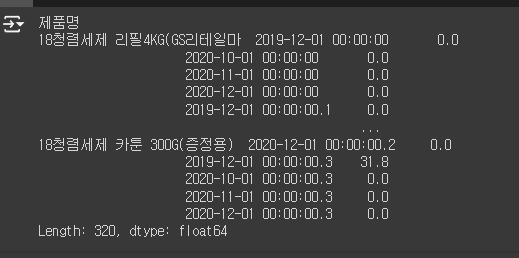
필요없는 컬럼명을 drop 하고 SetIndex 를 제품명으로 한 결과.