데이터베이스(DBMS - Database Management System)
ANSI(표준 SQL) + 확장 SQL
데이터베이스화
과거 수기(장부) --> 프로그램화거쳐(ERP) :90~00 --> Extended ERP
사람(직원 - 고객) - 돈 - 물건
Extended ERP : 고객 - 물건(회사) - CRM(고객관계관리)
ERP 구축 - (기존 업무였던 것을 컴퓨터화 시킨다!)
ERP : insert/ update / delete
Extended ERP : select
mariadb 접속
-u 사용자명 -p 데이터베이스명 -> 로그인과 동시에 데이터베이스명 접근 가능함
database의 함수
- 단일행 함수 ==> 1개의 데이터당 1개의 결과 나옴(어제 말한 것들이 단일행)
information - 시스템 정보
Numeric - 수학 함수
String - 문자열 함수 (가장 핵심 1)
Date - 날짜 처리 함수 (핵심 2)
Control - 제어 함수 (3) - if , ifnull + 산술 연산 처리
if ~ else if ~ else(switch case) 도 있다.
그룹함수 ==> 여러개의 데이터를 넣어서 1개의 결과가 나옴
case ~ when : 선택적 조건
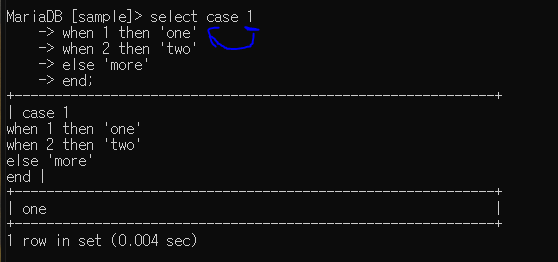
when = case 느낌
명 바꾸려면 end 뒤에 써주기
응용 - 영어로 된 직책을 한글로 바꿔 출력하는 case
select empno, ename,
case job
when 'CLERK' then '사원'
when 'ANALYST' then '분석'
when 'MANAGER' then '관리'
when 'PRESIDENT' then '대표'
else '영업'
end '직책'
from emp
order by 3;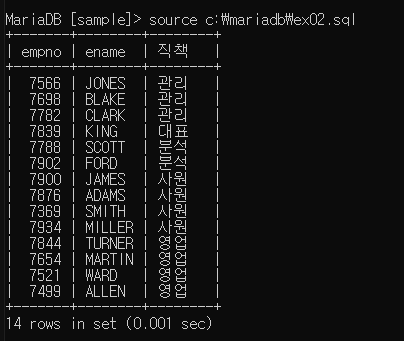
응용 - 인상급여 출력하는 case
select empno '번호', ename '이름', truncate(sal, 0) '현재급여',
case deptno
when 10 then truncate((sal * 1.1), 0)
when 20 then truncate((sal * 1.2), 0)
when 30 then truncate((sal * 1.3), 0)
when 40 then '인상 없음'
end '인상 급여'
from emp
order by 3;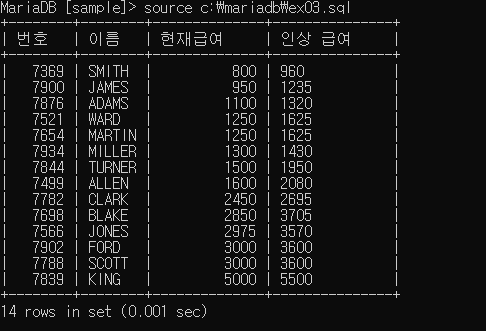
그룹 함수
그룹화(ex> 부서별, 직책별 등) - group by 컬럼명
개념과 같이 사용
데이터 개수 - count
최대값 / 최소값 - min / max
합 - sum
평균 - avg
분산 / 표준편차
count : 행 개수 출력
count를 사용하면 null을 제외한 개수가 출력된다.
*를 사용하면 테이블 전체를 대상으로 비교하여 가장 많은 개수가 출력된다.
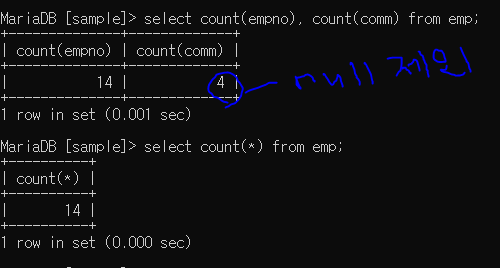
중요!!!!!!!!!!!!!
모르는 데이터베이스 접근할 때
select * from 테이블명; --> 절대 치기 말기( 몇개가 나올지 몰라서 )
desc 테이블명;
select count(*) from 테이블명;
select 컬럼명 ... from 테이블명 limit 5; --> 이런식으로 써주기
max / min : 최대 , 최소값
그룹함수는 일반내용을 같이 쓸 경우 출력 정보가 잘못되어 나올 수가 있다.
ex> 최대값, 사원이름을 같이 출력하고 싶을 때 일반적인 나열로 쓸 경우 정보가 제대로 나오지 않음
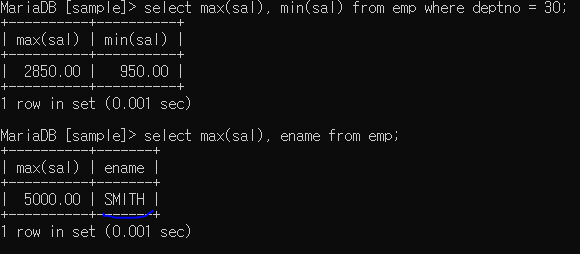
KING이 나와야 하는데 SMITH가 나오는 모습
sum / avg : 합계 / 평균
sum
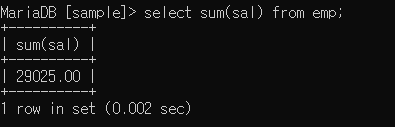
avg
평균 계산할 때는 기본적으로 null 빼고 계산한다.
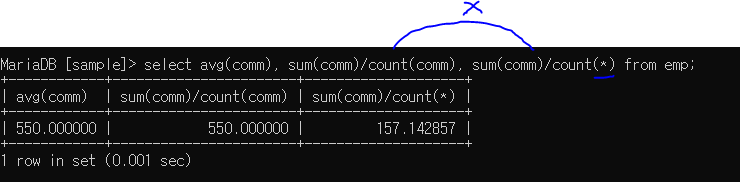
2번째로 나눌 때는 null을 제외한 평균 값, (*)는 전체를 포함하기 때문에 평균 값이 다르게 나오는 것임 (어느 쪽이 틀린 것이 아닌 상황에 따라 다름)
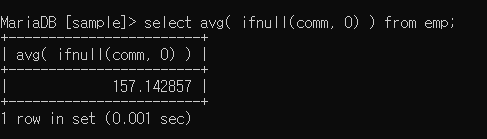
ifnull로 처리하면 마지막과 같이 나온다.
group by (그룹화)
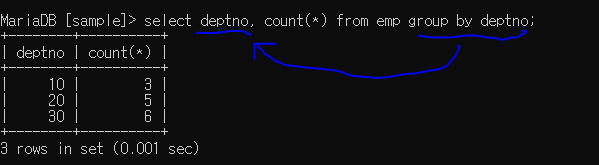
중요!!!
그룹화 뒤에 나온 컬럼명은 앞에다 쓰면 의미가 있다. (그룹 함수를 쓸 경우 거기에 맞춰서 정보가 출력됨)
그룹화 뒤에 나온 컬럼명 외 다른 컬럼명을 앞에다 쓰면 처리 시 에러 발생할 수 있음.
추가로 그룹화는 정렬화가 추가되어 있음!ex> group by deptno의 count(*)를 deptno에 맞게 보여준다는 뜻
ex> 직책 별 최대 급여 출력
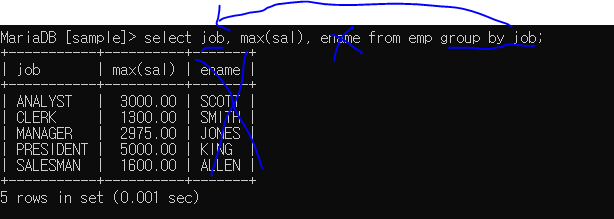
1. 그룹화 된 job에 맞게 max(sal) 출력되고, 앞에 job을 쓸경우 거기에 맞게 나열되어 출력.
2. ename은 그룹회 된 컬럼이 아니므로 그냥 쓸 경우 의미가 없다.(출력 오류 발생 가능)
집합으로 그룹화하기
홀로 그룹화하는 것이 아닌 여러개의 컬럼을 묶어서 그룹화 시켜 출력할 수 있다.
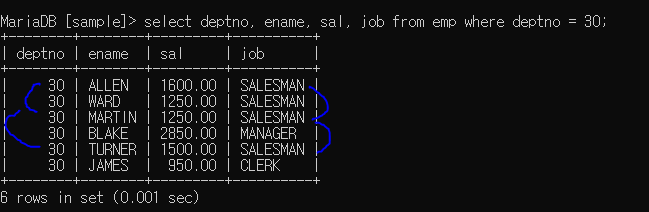
30 부서의 salesman 연봉 합 : 5600
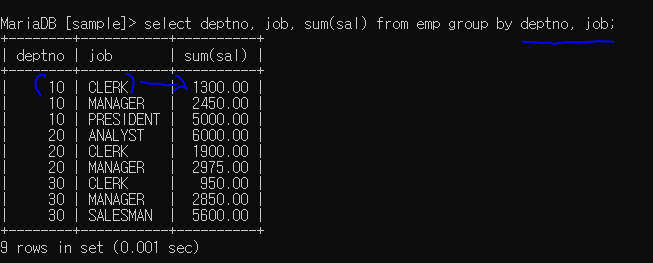
deptno의 job에 대한 봉급 합계를 구해서 출력한 것
30 salesman 을 같이 묶어서 sum(sal)을 사용한 것 : 위의 연봉합과 결과값 같음
정렬화가 추가되어 있다는 것 확인..
where절 뒤에는 그룹화 쓸 수 없다.
정확히는 where절 뒤에 그룹함수를 사용할 경우 그룹화를 사용할 수 없다.
having 을 사용하여 뒤에 조건을 적어 줌
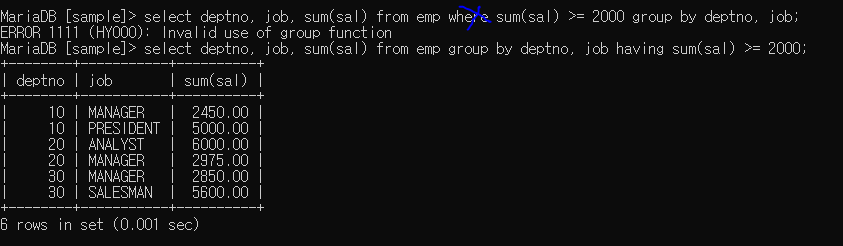
그룹함수를 쓰지 않고는 사용 가능하다. (결과는 당연히 다름)
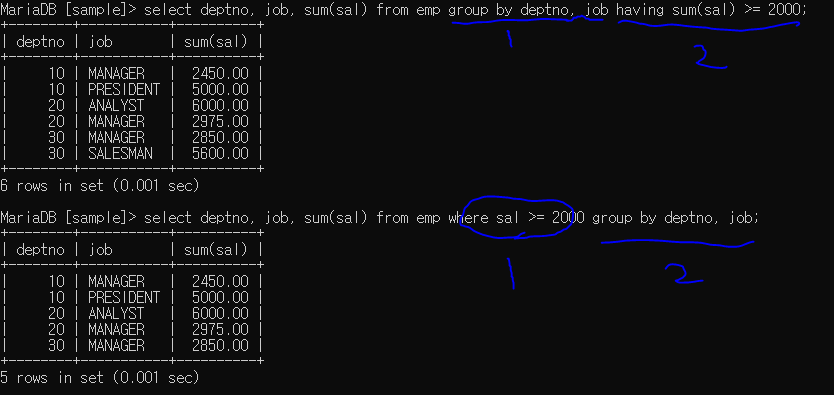
순서 잘 파악하기
1번은 먼저 그룹을 시킨 후 having을 통하여 조건 수행후 출력(그룹화하고 sal 수행, 그 후 2000 이상만 남기고 출력에서 제외)
2번은 조건 수행 후 group을 통하여 묶는 것 (salesman은 봉급 2000이상이 없기때문에 먼저 제거되어 아예 그룹화 되지 않음)
서브쿼리
- 쿼리 안에 쿼리
단일행 : 1행 1열의 결과 가지고 다시 쿼리 (비교 연산자만 사용 가능)
복수행 : 여러행 1열의 결과 가지고 다시 쿼리
- 최고 급여 받는 사원정보 호출 (단일행)
- 최고 급여 계산
- 그 급여를 받는 사원 (서브쿼리)
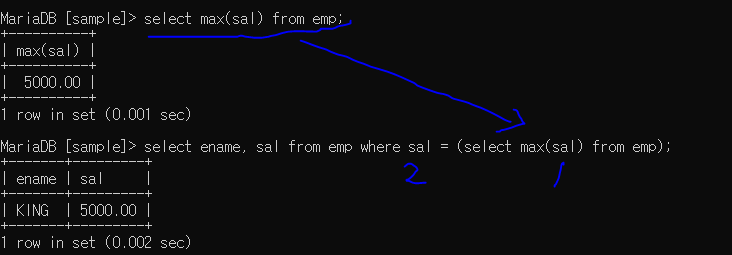
1. 뒤의 () 안의 내용 먼저 계산
2. 후의 where sal = 문 계산
(tip. 비교연산 사용할 때 <= ,>= 써야 자기 포함한 결과 나온다.)
복수행 : 부서별 최고급여를 받는 사원 출력 (in 사용)
1. 부서별 최고급여
2. 이 급여를 받는 사원
1번의 코드 : select max(sal) from emp group by deptno
2번의 코드 :
select empno, ename, sal
from emp
where sal in (select max(sal) from emp group by deptno);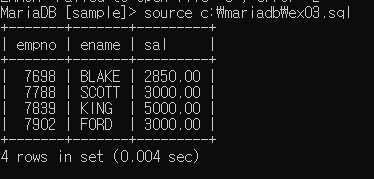
복수행 2 : (20번 부서의 속한 사원들의 '직책')과 같은 사원들 출력
- 20번 부서 사원들 직책만 뽑기
- 그 직책을 가지는 사원들 모두 출력
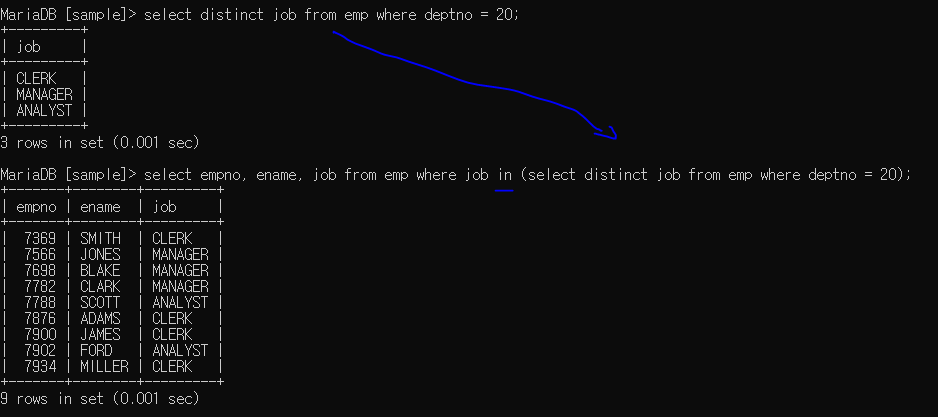
다양한 목록형
모든 사원 월급
- 컬럼명 < Any ~~ : ~~ 최대값보다 작은 값들만 출력
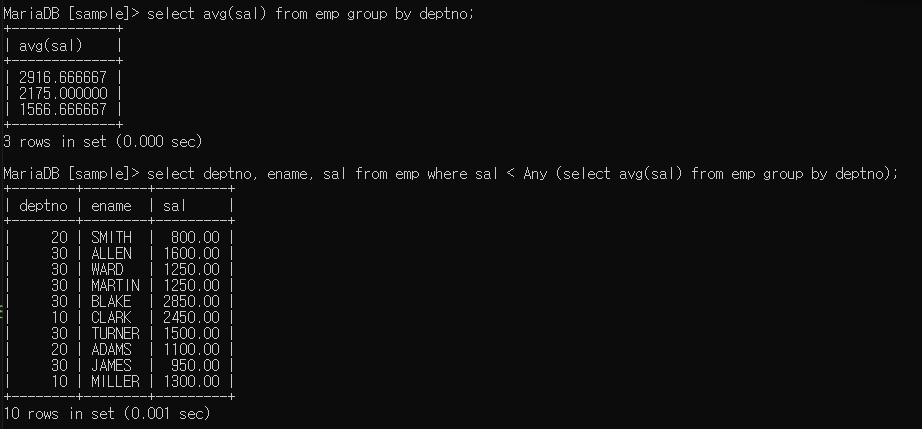
2916.66666(최대값) 보다 작은 값들만 출력
- 컬럼명 > Any ~~ : ~~의 최솟값보다 큰 값들만 출력
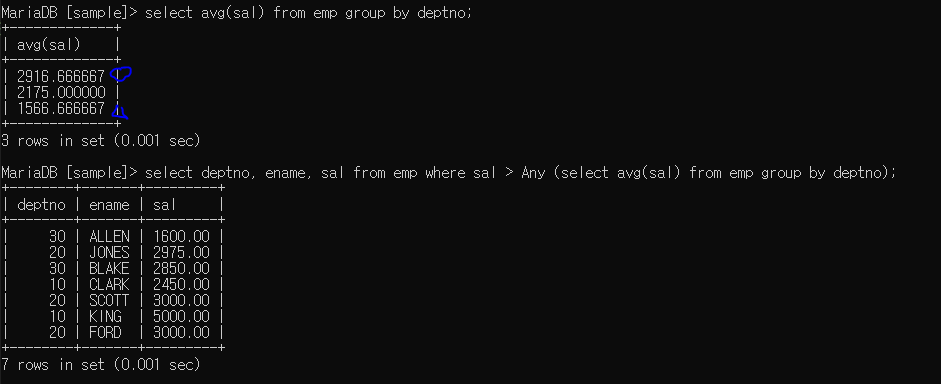
1566.66666(최소값) 보다 큰 값들만 출력됨
- 컬럼명 < ALL ~~ : ~~ 보다 작은 값들 출력
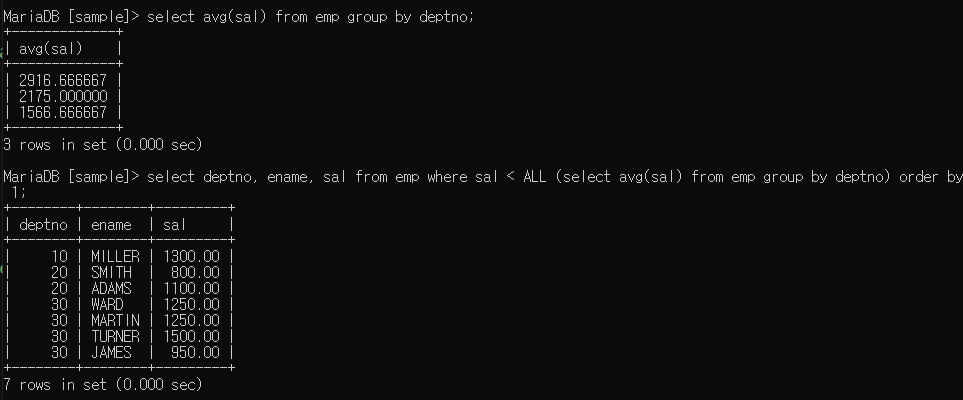
1566.6666(최소값) 보다 작은 값만 출력
- 컬럼명 > ALL ~~ : ~~ 보다 큰 값들 출력
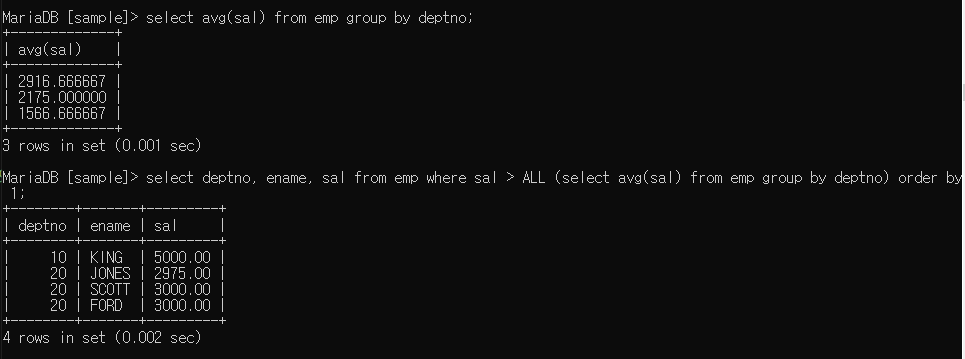
2916.66666(최대값) 보다 큰 값들만 출력
join : 두 개 이상의 테이블 합치는 것
두 테이블 곱하고 조건으로 필터링시킴 (테이블 간 컬럼이 일치할 경우 사용)
select from emp cross join dept; ) (= select from emp inner join dept;)
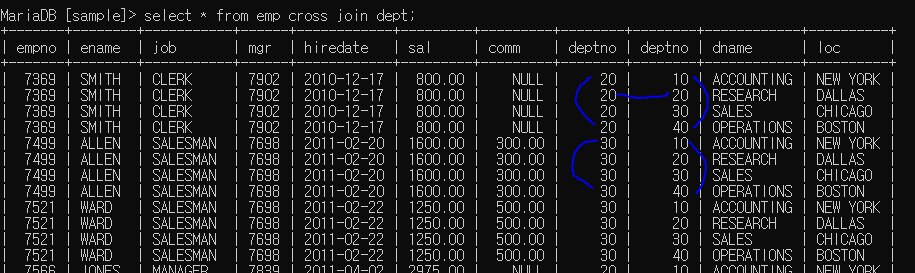
조건 필터링하기
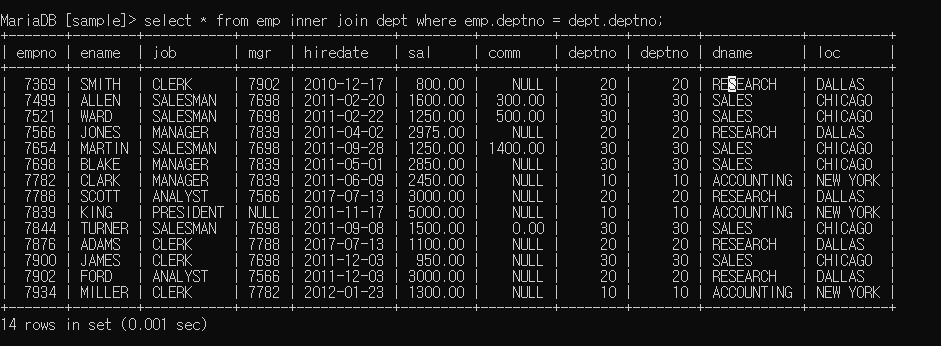
emp의 deptno와 dept의 deptno의 값이 같은 것만 필터링하여 출력한 것

and를 사용하여 추가로 필터링 가능

arias를 사용하여 테이블명을 바꿔서 짧게 쓰기도 가능(변수와 유사기능)
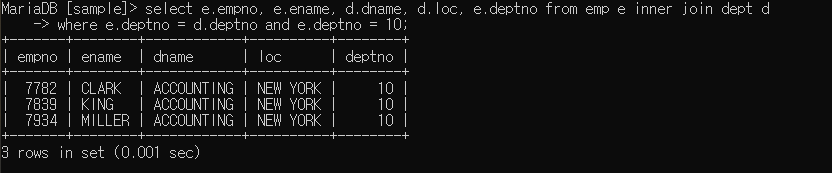
중복 컬럼 방지를 위하여 가능한 전 컬럼에 테이블.컬럼명을 써주는 게 좋다( 테이블명은 arias로 짧게)
select e.empno, e.ename, d.dname, d.loc, e.deptno
from emp e inner join dept d
on (e.deptno = d.deptno)
where e.deptno = 10;on을 사용하여 where이 안헷갈리게끔 사용 가능
응용 - 직책이 clerk인 사원의 번호, 이름, 직책, 부서이름, 부서지역 출력
select e.empno, e.ename, e.job, d.dname, d.loc, e.deptno
-> from emp e inner join dept d
-> on (e.deptno = d.deptno)
-> where e.job = 'clerk';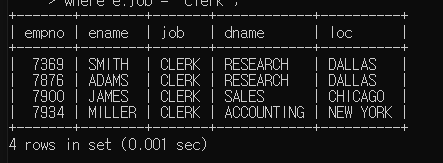
non-equi-join
두 개의 테이블 간에 칼럼 값들이 서로 정확하게 일치하지 않을때 사용
select *
from emp e inner join salgrade s
on (e.sal >= s.losal and e.sal <= s.hisal)
-- on (e.sal between s.losal and s.hisal) --> 이렇게도 사용 가능, 이러한 조건을 써주는 이유는 중복 값을 제거하기 위함
where e.deptno =10;
응용 : 입사년도가 2011년인 사원에 대한 사원번호 이름 급여 급여등급 입사일 출력
select e.deptno, e.ename, e.sal, s.grade, e.hiredate
from emp e inner join salgrade s
on (e.sal >= s.losal and e.sal <= s.hisal)
where e.hiredate like "2011%";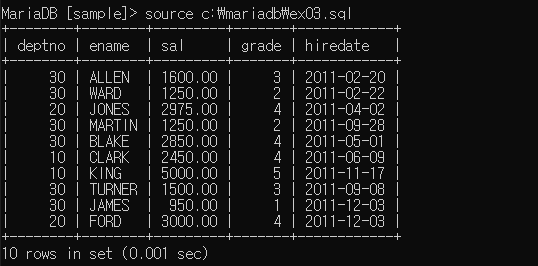
중첩 join 가능
중첩 join 가능함
select e.empno, e.ename, e.sal, s.grade, d.dname, d.loc
from emp e inner join dept d
on (e.deptno = d.deptno)
inner join salgrade s
on (e.sal between s.losal and s.hisal)
order by 5;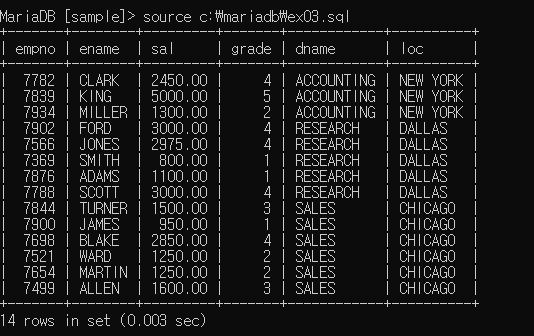
한번에 몰아쓰기
select e.empno, e.ename, e.sal, s.grade, d.dname, d.loc
from emp e inner join dept d inner join salgrade s
on (e.deptno = d.deptno and e.sal between s.losal and s.hisal)
order by 5;
결과 값 위와 동일
outer join
= 한 쪽 정보 완전히 출력하고 나머지와 비교하여 연결(연결되지 않은 정보는 null)
right outer join - 오른쪽 중심(이쪽 데이터는 다 출력 됨)의 왼쪽 연결
left outer join - 왼쪽 중심의 오른쪽 연결
full outer join - 양쪽 다 확인
select d.deptno, d.dname, e.empno, e.ename
from emp e right outer join dept d
on(e.deptno = d.deptno);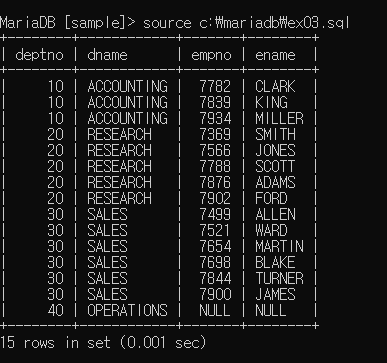
오른쪽 중심이라 데이터는 다 나오지만(40까지) 40의 연결할 수 있는 정보가 없어 null출력
사원이 없는 부서를 출력하고 싶을 때 (40번 보스턴지역 부서는 사원이 없음)
select d.deptno, d.dname, d.loc
from dept d left outer join emp e
on(e.deptno = d.deptno)
where e.empno is null; --> 사원번호가 null인경우 출력(연결되지 않은 정보는 null 출력되므로)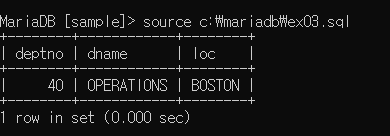
self join : 한 테이블 내부 join
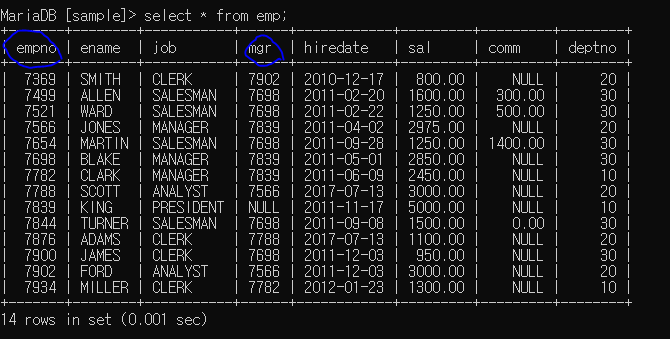
비슷한 두 테이블로 인하여 self join 사용해야함
select e.empno, e.ename '사원', e.mgr, m.ename '관리자'
from emp e inner join emp m
on (e.mgr = m.empno)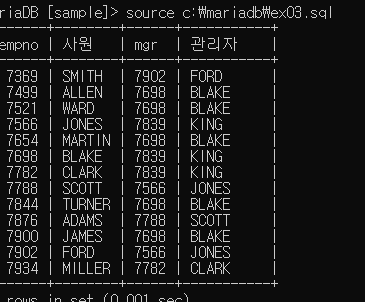
e.mgr = m.empno (e.mgr
내일 퀴즈 11시 10분 ...
클래스/ 객체에서 나오는 기본형태 (책 약 217까지)
